
 Technologie-Peripheriegeräte
KI
Wie viele KI-Kennzeichnungsunternehmen wird Googles „großer Schachzug' töten?
Technologie-Peripheriegeräte
KI
Wie viele KI-Kennzeichnungsunternehmen wird Googles „großer Schachzug' töten?
Wie viele KI-Kennzeichnungsunternehmen wird Googles „großer Schachzug' töten?

Eine kleine Handarbeitswerkstatt ist letztendlich nicht mit dem Fließband der Fabrik zu vergleichen.
Wenn die aktuelle generative KI ein Kind ist, das kräftig wächst, dann sind die kontinuierlichen Daten die Nahrung, die sein Wachstum fördert.
Datenannotation ist der Prozess der Herstellung dieses „Lebensmittels“
Allerdings ist dieser Prozess wirklich mühsam und ermüdend.
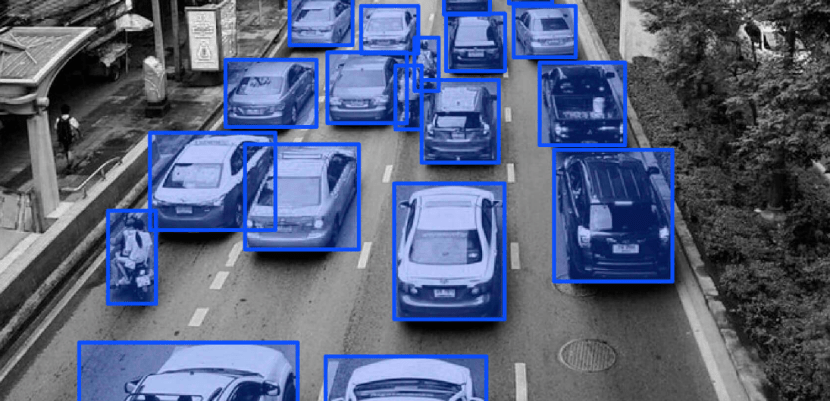
Der „Annotator“, der Anmerkungen durchführt, muss nicht nur wiederholt verschiedene Objekte, Farben, Formen usw. im Bild identifizieren, sondern manchmal sogar die Daten bereinigen und vorverarbeiten.
Mit der kontinuierlichen Weiterentwicklung der Technologie der künstlichen Intelligenz werden die Grenzen der manuellen Datenanmerkung immer deutlicher. Manuelle Datenanmerkungen kosten nicht nur Zeit und Mühe, sondern manchmal ist es auch schwierig, die Qualität sicherzustellen

Um diese Probleme zu lösen, hat Google kürzlich eine Methode namens AI Feedback Reinforcement Learning (RLAIF) vorgeschlagen, bei der große Modelle verwendet werden, um Menschen für die Präferenzanmerkung zu ersetzen.
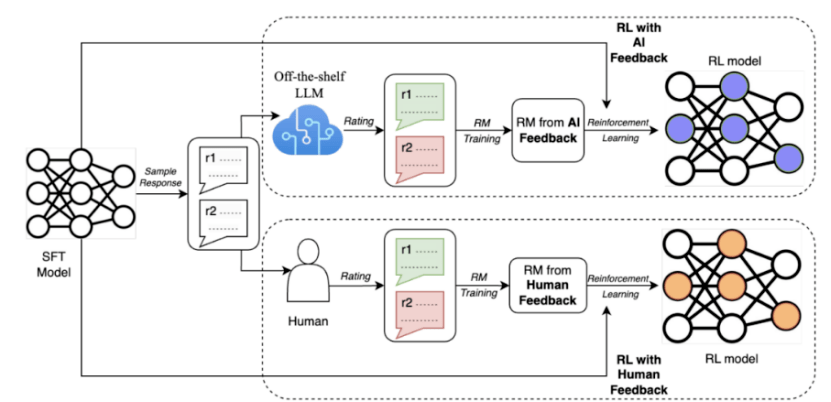
Forschungsergebnisse zeigen, dass RLAIF vergleichbare Verbesserungen wie Reinforcement Learning with Human Feedback (RLHF) erzielen kann, ohne auf menschliche Anmerkungen angewiesen zu sein, und die Erfolgsquote bei beiden beträgt 50 %. Darüber hinaus ergab die Studie, dass sowohl RLAIF als auch RLHF der Basisstrategie des Supervised Fine-Tuning (SFT) überlegen sind
Diese Ergebnisse zeigen, dass RLAIF nicht auf manuelle Annotation angewiesen ist und eine praktikable Alternative zu RLHF darstellt.
Wenn diese Technologie in Zukunft wirklich umfassend gefördert und populär gemacht wird, werden dann viele Unternehmen, die bei der Datenanmerkung auf manuelle „Pulling Boxes“ angewiesen sind, in eine verzweifelte Situation geraten?
01 Aktueller Status der Datenanmerkung
Wenn wir den aktuellen Stand der inländischen Annotationsbranche einfach zusammenfassen wollen, ist das so: Die Arbeitsbelastung ist groß, aber die Effizienz ist nicht sehr hoch, und es ist ein undankbarer Zustand.
Markierte Unternehmen werden im KI-Bereich als Datenfabriken bezeichnet und konzentrieren sich normalerweise auf Gebiete mit reichen Humanressourcen wie Südostasien, Afrika oder Chinas Henan, Shanxi und Shandong.
Um die Kosten zu senken, werden die Chefs des Etikettierungsunternehmens einen Raum im Landkreis anmieten, um Computerausrüstung unterzubringen. Sobald eine Bestellung vorliegt, werden in der Nähe Teilzeitkräfte eingestellt, die diese bearbeiten. Wenn keine Bestellungen vorliegen, werden sie aufgelöst und eine Pause eingelegt
Vereinfacht ausgedrückt ähnelt diese Art von Arbeit ein wenig den temporären Dekorationsarbeitern am Straßenrand.

Danach muss der „Annotator“ zunächst markieren, zu welchem Typ die Frage gehört, und dann die Antworten bewerten und sortieren.
Wenn früher über die Kluft zwischen inländischen Großmodellen und fortgeschrittenen Großmodellen wie GPT-4 gesprochen wurde, fassten sie die Gründe für die geringe Qualität inländischer Daten zusammen.
Warum ist die Datenqualität nicht hoch? Ein Teil des Grundes liegt in der „Pipeline“ der Datenannotation
Derzeit gibt es zwei Arten von Datenquellen für chinesische Großmodelle: eine sind Open-Source-Datensätze, die andere sind chinesische Internetdaten, die durch Crawler gecrawlt werden.
Einer der Hauptgründe, warum die Leistung chinesischer Großmodelle nicht gut genug ist, ist die Qualität der Internetdaten. Profis nutzen beispielsweise Baidu bei der Informationssuche im Allgemeinen nicht.
Aber zu diesem Zeitpunkt tritt das Problem erneut auf: Für professionelle Teams ist nicht nur die Amortisationszeit für Daten lang, sondern es ist auch wahrscheinlich, dass First Mover Verluste erleiden.
Zum Beispiel hat ein bestimmtes Annotationsteam viel Geld und Zeit ausgegeben, um viele Daten zu erstellen, während andere sie möglicherweise einfach verpacken und für einen kleinen Geldbetrag kaufen.
Angesichts dieses „Trittbrettfahrer-Dilemmas“ sind viele große inländische Modelle in eine seltsame Situation geraten, in der zwar viele Daten vorhanden sind, deren Qualität jedoch nicht hoch ist
Wie lösen in diesem Fall einige der führenden ausländischen KI-Unternehmen wie OpenAI dieses Problem?

Zum Beispiel wurde zuvor bekannt, dass das Unternehmen eine große Anzahl kenianischer Arbeiter eingestellt hatte, um giftige Informationen zu einem Preis von 2 US-Dollar pro Stunde zu kennzeichnen.
Der wichtige Unterschied besteht jedoch darin, wie die Probleme der Datenqualität und Annotationseffizienz gelöst werden können
Der größte Unterschied zwischen OpenAI und inländischen Unternehmen besteht in dieser Hinsicht insbesondere darin, wie die Auswirkungen der „Subjektivität“ und „Instabilität“ der manuellen Annotation verringert werden können.
02 Der Ansatz von OpenAI Beim Umschreiben des Inhalts muss die Sprache ins Chinesische umgeschrieben werden und der Originalsatz muss nicht erscheinen
Um die „Subjektivität“ und „Instabilität“ solcher menschlichen Annotatoren zu verringern, verfolgt OpenAI grob zwei Hauptstrategien:
1. Kombination aus künstlichem Feedback und verstärkendem Lernen
Beim Umschreiben muss der Originalinhalt ins Chinesische konvertiert werden. So sieht es nach dem Umschreiben aus: Lassen Sie uns zunächst über die Kennzeichnung sprechen. Der größte Unterschied zwischen dem künstlichen Feedback von OpenAI und dem heimischen Feedback besteht darin, dass es hauptsächlich das Verhalten des intelligenten Systems sortiert oder bewertet, anstatt seine Ausgabe zu modifizieren oder zu kennzeichnen
Das Verhalten eines intelligenten Systems bezieht sich auf eine Reihe von Aktionen oder Entscheidungen, die ein intelligentes System in einer komplexen Umgebung auf der Grundlage seiner eigenen Ziele und Strategien trifft
Zum Beispiel Spiele spielen, Roboter steuern, mit Menschen sprechen usw.
Der Output eines intelligenten Systems bezieht sich auf die Generierung eines Ergebnisses oder einer Antwort basierend auf Eingabedaten in einer einfachen Aufgabe, wie zum Beispiel dem Schreiben eines Artikels oder dem Zeichnen eines Gemäldes.
Generell lässt sich das Verhalten intelligenter Systeme oft nur schwer nach „richtig“ oder „falsch“ beurteilen, sondern muss eher nach Präferenz oder Zufriedenheit beurteilt werden
Diese Art von Bewertungssystem, das auf „Präferenz“ oder „Zufriedenheit“ basiert, erfordert keine Änderung oder Annotation spezifischer Inhalte, wodurch der Einfluss menschlicher Subjektivität, Wissensstand und anderer Faktoren auf die Qualität und Genauigkeit der Datenannotation verringert wird
Es ist wahr, dass inländische Unternehmen bei der Kennzeichnung auch Systeme verwenden werden, die dem „Sortieren“ und „Scoring“ ähneln. Aufgrund des Fehlens eines „Belohnungsmodells“ wie OpenAI als Belohnungsfunktion zur Optimierung der Strategie des intelligenten Systems. Eine solche „Sortierung“ und „Bewertung“ ist immer noch im Wesentlichen eine Methode zur Änderung oder Kennzeichnung der Ausgabe.
2. Diversifizierte und groß angelegte Datenquellenkanäle
Die Hauptquellen für die Datenannotation in China sind externe Annotationsunternehmen oder selbst zusammengestellte Teams von Technologieunternehmen. Diese Teams bestehen größtenteils aus Studenten und verfügen nicht über ausreichende Professionalität und Erfahrung, um qualitativ hochwertiges und effizientes Feedback zu geben.

Im Gegensatz dazu wird das menschliche Feedback von OpenAI über mehrere Kanäle und Teams eingeholt
OpenAI kooperiert mit mehreren Datenunternehmen und -institutionen wie Scale AI, Appen, Lionbridge AI usw. und nutzt nicht nur Open-Source-Datensätze und Internet-Crawler zur Datenbeschaffung, sondern engagiert sich auch für die Beschaffung vielfältigerer und qualitativ hochwertigerer Daten
Die Kennzeichnungsmethoden dieser Datenunternehmen und -institutionen sind „automatisierter“ und „intelligenter“ als ihre inländischen Pendants

Zum Beispiel nutzt Scale AI eine Technologie namens Snorkel, eine Datenkennzeichnungsmethode, die auf schwach überwachtem Lernen basiert und hochwertige Kennzeichnungen aus mehreren ungenauen Datenquellen generieren kann.
Gleichzeitig kann Snorkel auch eine Vielzahl von Signalen wie Regeln, Modelle und Wissensdatenbanken verwenden, um Daten Beschriftungen hinzuzufügen, ohne dass jeder Datenpunkt manuell direkt beschriftet werden muss. Dadurch können Kosten und Zeit für manuelle Anmerkungen erheblich reduziert werden.

Da die Kosten für die Datenannotation gesenkt und der Zyklus verkürzt werden, können diese Datenunternehmen mit Wettbewerbsvorteilen hochwertige, schwierige und hochschwellige Unterteilungen wie autonomes Fahren, große Sprachmodelle, synthetische Daten usw. kontinuierlich auswählen Verbessern Sie die eigene Kernwettbewerbsfähigkeit und differenzierte Vorteile
Auf diese Weise wurde auch das Trittbrettfahrer-Dilemma „First Mover werden leiden“ durch starke technische und branchenspezifische Barrieren beseitigt.
Vergleich zwischen Standardisierung und kleinen Werkstätten
Es ist ersichtlich, dass die KI-Technologie zur automatischen Etikettierung nur diejenigen Etikettierungsunternehmen wirklich eliminieren wird, die noch eine rein manuelle Etikettierung verwenden.
Obwohl die Datenannotation nach einer „arbeitsintensiven“ Branche klingt, werden Sie, sobald Sie sich mit den Details befassen, feststellen, dass die Suche nach qualitativ hochwertigen Daten keine leichte Aufgabe ist.
Vertreten durch Scale AI, das Einhorn der Datenannotation im Ausland, nutzt Scale AI nicht nur billige Arbeitskräfte aus Afrika und anderen Ländern, sondern rekrutiert auch Dutzende von Doktoranden, die sich mit professionellen Daten in verschiedenen Branchen befassen.

Der größte Wert, den Scale AI großen Modellunternehmen wie OpenAI bietet, ist die Qualität der Datenannotation
Um die Datenqualität bestmöglich zu gewährleisten, ist neben dem bereits erwähnten Einsatz von KI-gestützter Annotation Eine weitere große Innovation von Scale AI eine einheitliche Datenplattform.
Diese Plattformen umfassen Scale Audit, Scale Analytics, ScaleData Quality usw. Über diese Plattformen können Kunden verschiedene Indikatoren im Annotationsprozess überwachen und analysieren, die Annotationsdaten überprüfen und optimieren sowie die Genauigkeit, Konsistenz und Vollständigkeit der Annotation bewerten.
Man kann sagen, dass solche standardisierten und einheitlichen Werkzeuge und Prozesse zu einem Schlüsselfaktor bei der Unterscheidung von „Fließbandfabriken“ und „Handwerkstätten“ in Etikettierunternehmen geworden sind.
In diesem Zusammenhang verwenden die meisten inländischen Annotationsunternehmen immer noch die „manuelle Überprüfung“, um die Qualität der Datenannotation zu überprüfen. Nur wenige Giganten wie Baidu haben fortschrittlichere Verwaltungs- und Bewertungstools wie die intelligente Datendienstplattform EasyData eingeführt.
Wenn es keine speziellen Tools zur Überwachung und Analyse von Annotationsergebnissen und -indikatoren gibt, kann die Datenqualitätskontrolle im Hinblick auf die Überprüfung wichtiger Daten nur auf manueller Erfahrung basieren. Diese Methode kann immer noch nur ein Workshop-ähnliches Niveau erreichen

Aus dieser Perspektive bedeutet das Aufkommen der Etikettierung mit künstlicher Intelligenz nicht das Ende inländischer Etikettierungsunternehmen, sondern das Ende der traditionellen ineffizienten, billigen und arbeitsintensiven Etikettierungsmethoden, denen es an technischem Inhalt mangelt
Das obige ist der detaillierte Inhalt vonWie viele KI-Kennzeichnungsunternehmen wird Googles „großer Schachzug' töten?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1677
1677
 14
1431
52
1334
25
1280
29
1257
24
14
1431
52
1334
25
1280
29
1257
24

 Wie optimieren Sie die Jieba -Word -Segmentierung, um den Effekt der Keyword -Extraktion von szenischen Spot -Kommentaren zu verbessern?
Apr 01, 2025 pm 06:24 PM
Wie optimieren Sie die Jieba -Word -Segmentierung, um den Effekt der Keyword -Extraktion von szenischen Spot -Kommentaren zu verbessern?
Apr 01, 2025 pm 06:24 PM
Wie optimieren Sie die Jieba -Word -Segmentierung, um die Keyword -Extraktion von malerischen Spot -Kommentaren zu verbessern? Bei Verwendung von Jieba -Word -Segmentierung zur Verarbeitung szenischer Spot -Kommentardaten, wenn die Ergebnisse der Wortsegmentierung ignoriert werden ...
 Die neuesten Updates zur Rangliste der ältesten virtuellen Währung
Apr 22, 2025 am 07:18 AM
Die neuesten Updates zur Rangliste der ältesten virtuellen Währung
Apr 22, 2025 am 07:18 AM
Die Rangliste der „ältesten“ virtuellen Währungen lautet wie folgt: 1. Bitcoin (BTC), der am 3. Januar 2009 herausgegeben wurde, ist die erste dezentrale digitale Währung. 2. Litecoin (LTC), das am 7. Oktober 2011 veröffentlicht wurde, ist als "leichte Version von Bitcoin" bekannt. 3. Ripple (XRP), das 2011 ausgestellt wurde, wurde für grenzüberschreitende Zahlungen ausgelegt. V. 5. Ethereum (ETH), die am 30. Juli 2015 veröffentlicht wurde, ist die erste Plattform, die intelligente Verträge unterstützt. 6. Tether (USDT), das 2014 ausgestellt wurde, ist der erste Stablecoin, der an den US -Dollar 1: 1 verankert ist. 7. Ada,
 Web -IDE -Verzeichnisbaumeinzug: Warum unterscheiden sich die Rendering -Ergebnisse von Google Chrome und Firefox -Browsern?
Apr 04, 2025 pm 10:15 PM
Web -IDE -Verzeichnisbaumeinzug: Warum unterscheiden sich die Rendering -Ergebnisse von Google Chrome und Firefox -Browsern?
Apr 04, 2025 pm 10:15 PM
Über die Rendering -Unterschiede von Webide -Verzeichnisbäumen unter verschiedenen Browsern In diesem Artikel wird in Google Chrome und Firefox umbenannt ...
 Wie löste ich das Problem des Navigators.Mediadevices, der auf der HTTP -Seite undefiniert zurückgibt?
Apr 05, 2025 am 07:30 AM
Wie löste ich das Problem des Navigators.Mediadevices, der auf der HTTP -Seite undefiniert zurückgibt?
Apr 05, 2025 am 07:30 AM
Nach der Bearbeitung von H5 -Bereitstellung von Video -Medienakquisitionsproblemen bei der Bereitstellung von H5 -Anwendungen stoßen Sie manchmal Probleme mit der Seite "Seitenvidedien", insbesondere bei der Verwendung von Navigator.Medi ...
 Unterstützen Google und Microsoft Authenticators Hotp -Algorithmen? Wie kann man das Problem lösen, das nicht unterstützt wird?
Apr 02, 2025 pm 03:39 PM
Unterstützen Google und Microsoft Authenticators Hotp -Algorithmen? Wie kann man das Problem lösen, das nicht unterstützt wird?
Apr 02, 2025 pm 03:39 PM
Diskussion darüber, ob Google und Microsoft Authenticators Hotp-Algorithmen bei der Verwendung von Zwei-Faktor-Authentifizierung unterstützen, verwenden wir häufig Google und Microsoft ...
 Zusammenfassung der Top Ten Apple -Version Download -Portale für digitale Währungsaustausch -Apps herunterladen
Apr 22, 2025 am 09:27 AM
Zusammenfassung der Top Ten Apple -Version Download -Portale für digitale Währungsaustausch -Apps herunterladen
Apr 22, 2025 am 09:27 AM
Bietet eine Vielzahl komplexer Handelsinstrumente und Marktanalysen. Es deckt mehr als 100 Länder ab, hat ein durchschnittliches tägliches Derivatvolumen von über 30 Milliarden US -Dollar, unterstützt mehr als 300 Handelspaare und den 200 -fachen Hebel, hat eine starke technische Stärke, eine riesige globale Benutzerbasis, bietet professionelle Handelsplattformen, sichere Speicherlösungen und reichhaltige Handelspaare.
 Was ist der Unterschied zwischen H5 und Miniprogramm?
Apr 06, 2025 am 10:39 AM
Was ist der Unterschied zwischen H5 und Miniprogramm?
Apr 06, 2025 am 10:39 AM
H5 erhält den Datenverkehr über Inhaltsverteilungsplattform, Werbezustellung, QR -Code und Linkfreigabe. Mini -Programme erhalten den Verkehr über das WeChat -Portal, den H5 -Verkehr, den QR -Code und die Keyword -Optimierung.
 Binance Offizielle Website Eingang Binance Beamter neuester Eingang 2025
Apr 28, 2025 pm 07:54 PM
Binance Offizielle Website Eingang Binance Beamter neuester Eingang 2025
Apr 28, 2025 pm 07:54 PM
Besuchen Sie die offizielle Website Binance und überprüfen Sie HTTPS und Green Lock -Logos, um Phishing -Websites zu vermeiden, und offizielle Anwendungen können auch sicher zugegriffen werden.
