
 Technologie-Peripheriegeräte
KI
Versteckter Roboter im iPhone: basierend auf der GPT-2-Architektur, mit Emoji-Tokenizer, entwickelt von MIT-Alumni
Technologie-Peripheriegeräte
KI
Versteckter Roboter im iPhone: basierend auf der GPT-2-Architektur, mit Emoji-Tokenizer, entwickelt von MIT-Alumni
Versteckter Roboter im iPhone: basierend auf der GPT-2-Architektur, mit Emoji-Tokenizer, entwickelt von MIT-Alumni

Enthusiasten haben das „Geheimnis“ von Apples Transformer gelüftet Neue Versionen von iOS und macOS verfügen über integrierte Transformer-Sprachmodelle, um Eingabemethoden mit Textvorhersagefunktionen bereitzustellen.
Obwohl Apple-Beamte keine weiteren Informationen preisgegeben haben, können Technologiebegeisterte es kaum erwarten Ein Typ namens Jack Cook hat erfolgreich ein neues Kapitel der Betaversion von macOS Sonoma aufgeschlagen und unerwartet viele neue Informationen entdeckt
Ein Typ namens Jack Cook hat erfolgreich ein neues Kapitel der Betaversion von macOS Sonoma aufgeschlagen und unerwartet viele neue Informationen entdeckt
GPT-2
basiert.- In Bezug auf den Tokenizer ist Emoticon unter ihnen sehr prominent.
- Für weitere Details werfen wir einen Blick darauf. Basierend auf der GPT-2-Architektur
Jack Cook hat es speziell getestet und festgestellt, dass diese Funktion hauptsächlich die Vorhersage einzelner Wörter implementiert.
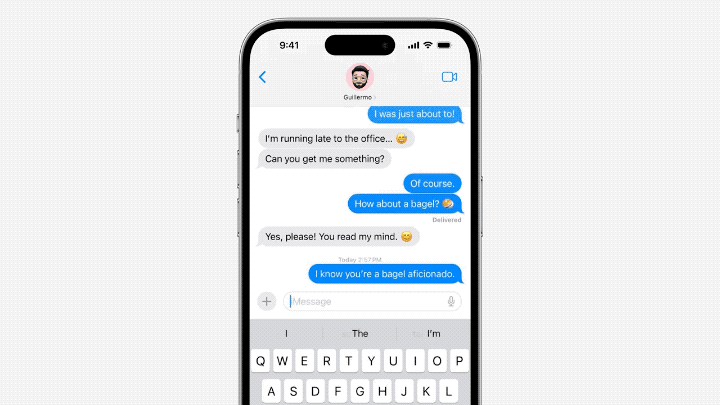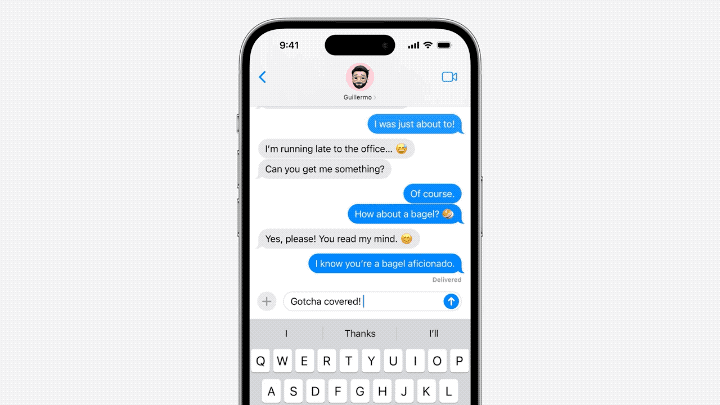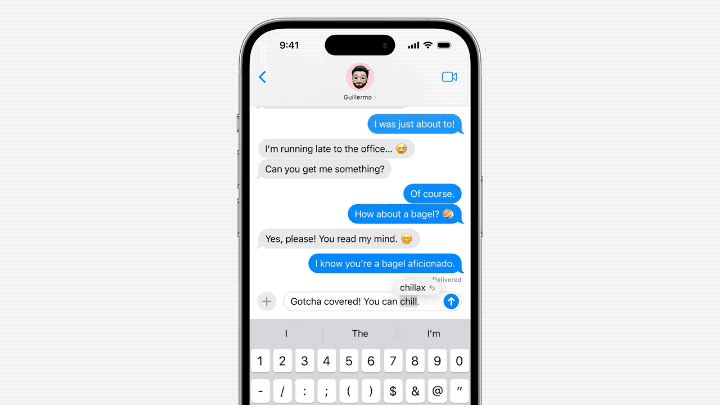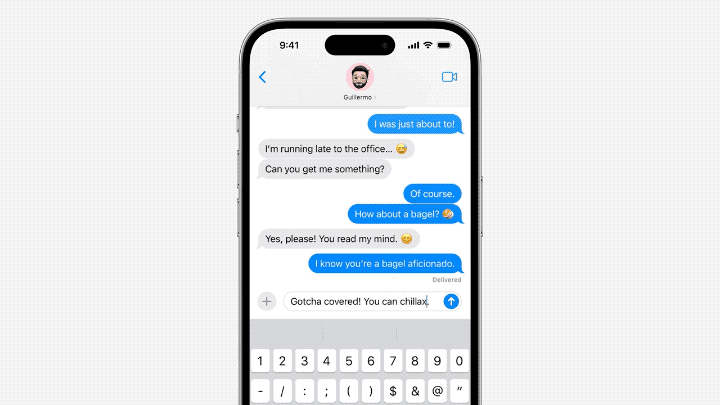
Der Inhalt, der neu geschrieben werden muss, ist: △Quelle: Jack Cooks Blog-Beitrag
Das Modell sagt manchmal mehrere kommende Wörter voraus, dies ist jedoch auf Situationen beschränkt, in denen die Semantik des Satzes sehr offensichtlich ist und eher ähnlich ist Funktion zur automatischen Vervollständigung von Gmail. 

Der Inhalt, der neu geschrieben werden muss, ist: △Quelle: Jack Cooks Blogbeitrag
Wo ist dieses Modell installiert? Nach eingehender Recherche stellte Bruder Cook fest:
Ich habe das prädiktive Textmodell in /System/Library/LinguisticData/RequiredAssets_en.bundle/AssetData/en.lm/unilm.bundle gefunden. Der Grund ist:

Viele Dateien in unilm.bundle existieren nicht in macOS Ventura (13.5), sondern erscheinen nur in der neuen Version von macOS Sonoma Beta (14.0).
Es gibt eine sp.dat-Datei in unilm.bundle, die sowohl in Ventura als auch in Sonoma Beta zu finden ist, aber die Sonoma Beta-Version wurde mit einer Reihe von Tokens aktualisiert, die offensichtlich wie ein Tokenizer aussehen.
- Die Anzahl der Token in sp.dat kann mit den beiden Dateien in unilm.bundle übereinstimmen – unilm_joint_cpu.espresso.shape und unilm_joint_ane.espresso.shape. Diese beiden Dateien beschreiben die Form jeder Schicht im Espresso/CoreML-Modell.
- Weitere Spekulationen: Gemäß der in unilm_joint_cpu beschriebenen Netzwerkstruktur glaube ich, dass das Apple-Modell auf der GPT-2-Architektur basiert.
- Zu den Hauptkomponenten gehören jeweils Token-Einbettung, Positionscodierung, Decoderblock und Ausgabeschicht In jedem Decoderblock werden Wörter angezeigt, die „gpt2_transformer_layer_3d“ ähneln beträgt etwa 34 Millionen Parameter, die Größe der verborgenen Ebene beträgt 512. Mit anderen Worten, es ist kleiner als die kleinste Version von GPT-2
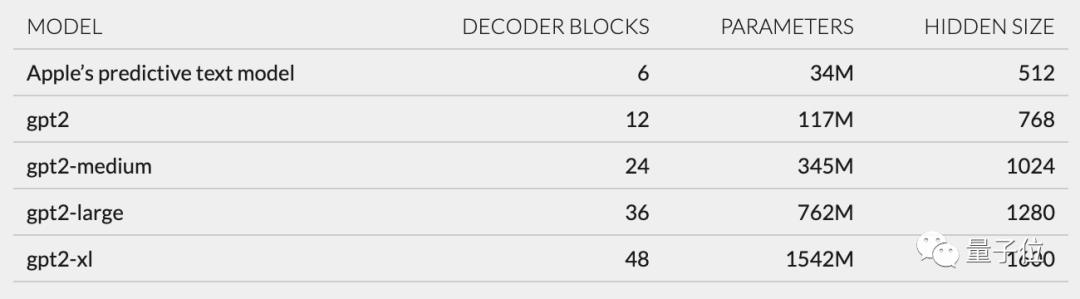
.
Er hat einen Satz von 15.000 Token in unilm.bundle/sp.dat gefunden. Es ist erwähnenswert, dass er 100 Emoji enthält.
Cook enthüllt Cook
Obwohl dieser Cook nicht dieser Cook ist, erregte mein Blog-Beitrag gleich nach seiner Veröffentlichung dennoch viel Aufmerksamkeit

Basierend auf seinen Erkenntnissen diskutierten die Internetnutzer enthusiastisch über die Benutzererfahrung und Innovationen von Apple Technologieanwendungen.

Zurück zu Jack Cook selbst. Er hat einen Bachelor- und einen Master-Abschluss in Informatik und studiert derzeit einen Master-Abschluss in Internet-Sozialwissenschaften an der Universität Oxford.
Zuvor absolvierte er ein Praktikum bei NVIDIA und konzentrierte sich auf die Erforschung von Sprachmodellen wie BERT. Er ist außerdem leitender Forschungs- und Entwicklungsingenieur für die Verarbeitung natürlicher Sprache bei der New York Times
Das obige ist der detaillierte Inhalt vonVersteckter Roboter im iPhone: basierend auf der GPT-2-Architektur, mit Emoji-Tokenizer, entwickelt von MIT-Alumni. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Laravels Geospatial: Optimierung interaktiver Karten und großen Datenmengen
Apr 08, 2025 pm 12:24 PM
Laravels Geospatial: Optimierung interaktiver Karten und großen Datenmengen
Apr 08, 2025 pm 12:24 PM
Verarbeiten Sie 7 Millionen Aufzeichnungen effizient und erstellen Sie interaktive Karten mit Geospatial -Technologie. In diesem Artikel wird untersucht, wie über 7 Millionen Datensätze mithilfe von Laravel und MySQL effizient verarbeitet und in interaktive Kartenvisualisierungen umgewandelt werden können. Erstes Herausforderungsprojektanforderungen: Mit 7 Millionen Datensätzen in der MySQL -Datenbank wertvolle Erkenntnisse extrahieren. Viele Menschen erwägen zunächst Programmiersprachen, aber ignorieren die Datenbank selbst: Kann sie den Anforderungen erfüllen? Ist Datenmigration oder strukturelle Anpassung erforderlich? Kann MySQL einer so großen Datenbelastung standhalten? Voranalyse: Schlüsselfilter und Eigenschaften müssen identifiziert werden. Nach der Analyse wurde festgestellt, dass nur wenige Attribute mit der Lösung zusammenhängen. Wir haben die Machbarkeit des Filters überprüft und einige Einschränkungen festgelegt, um die Suche zu optimieren. Kartensuche basierend auf der Stadt
 So stellen Sie die Zeitüberschreitung von Vue Axios fest
Apr 07, 2025 pm 10:03 PM
So stellen Sie die Zeitüberschreitung von Vue Axios fest
Apr 07, 2025 pm 10:03 PM
Um die Zeitüberschreitung für Vue Axios festzulegen, können wir eine Axios -Instanz erstellen und die Zeitleitungsoption angeben: in globalen Einstellungen: vue.Prototyp. $ Axios = axios.create ({Timeout: 5000}); In einer einzigen Anfrage: this. $ axios.get ('/api/user', {timeout: 10000}).
 Wie man MySQL löst, kann nicht gestartet werden
Apr 08, 2025 pm 02:21 PM
Wie man MySQL löst, kann nicht gestartet werden
Apr 08, 2025 pm 02:21 PM
Es gibt viele Gründe, warum MySQL Startup fehlschlägt und durch Überprüfung des Fehlerprotokolls diagnostiziert werden kann. Zu den allgemeinen Ursachen gehören Portkonflikte (prüfen Portbelegung und Änderung der Konfiguration), Berechtigungsprobleme (Überprüfen Sie den Dienst Ausführen von Benutzerberechtigungen), Konfigurationsdateifehler (Überprüfung der Parametereinstellungen), Datenverzeichniskorruption (Wiederherstellung von Daten oder Wiederaufbautabellenraum), InnoDB-Tabellenraumprobleme (prüfen IBDATA1-Dateien), Plug-in-Ladeversagen (Überprüfen Sie Fehlerprotokolle). Wenn Sie Probleme lösen, sollten Sie sie anhand des Fehlerprotokolls analysieren, die Hauptursache des Problems finden und die Gewohnheit entwickeln, Daten regelmäßig zu unterstützen, um Probleme zu verhindern und zu lösen.
 So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
Der Artikel führt den Betrieb der MySQL -Datenbank vor. Zunächst müssen Sie einen MySQL -Client wie MySQLworkBench oder Befehlszeilen -Client installieren. 1. Verwenden Sie den Befehl mySQL-uroot-P, um eine Verbindung zum Server herzustellen und sich mit dem Stammkonto-Passwort anzumelden. 2. Verwenden Sie die Erstellung von Createdatabase, um eine Datenbank zu erstellen, und verwenden Sie eine Datenbank aus. 3.. Verwenden Sie CreateTable, um eine Tabelle zu erstellen, Felder und Datentypen zu definieren. 4. Verwenden Sie InsertInto, um Daten einzulegen, Daten abzufragen, Daten nach Aktualisierung zu aktualisieren und Daten nach Löschen zu löschen. Nur indem Sie diese Schritte beherrschen, lernen, mit gemeinsamen Problemen umzugehen und die Datenbankleistung zu optimieren, können Sie MySQL effizient verwenden.
 Remote Senior Backend Engineers (Plattformen) benötigen Kreise
Apr 08, 2025 pm 12:27 PM
Remote Senior Backend Engineers (Plattformen) benötigen Kreise
Apr 08, 2025 pm 12:27 PM
Remote Senior Backend Engineer Job Vacant Company: Circle Standort: Remote-Büro-Jobtyp: Vollzeitgehalt: 130.000 bis 140.000 US-Dollar Stellenbeschreibung Nehmen Sie an der Forschung und Entwicklung von Mobilfunkanwendungen und öffentlichen API-bezogenen Funktionen, die den gesamten Lebenszyklus der Softwareentwicklung abdecken. Die Hauptaufgaben erledigen die Entwicklungsarbeit unabhängig von RubyonRails und arbeiten mit dem Front-End-Team von React/Redux/Relay zusammen. Erstellen Sie die Kernfunktionalität und -verbesserungen für Webanwendungen und arbeiten Sie eng mit Designer und Führung während des gesamten funktionalen Designprozesses zusammen. Fördern Sie positive Entwicklungsprozesse und priorisieren Sie die Iterationsgeschwindigkeit. Erfordert mehr als 6 Jahre komplexes Backend für Webanwendungen
 Kann MySQL JSON zurückgeben?
Apr 08, 2025 pm 03:09 PM
Kann MySQL JSON zurückgeben?
Apr 08, 2025 pm 03:09 PM
MySQL kann JSON -Daten zurückgeben. Die JSON_EXTRACT -Funktion extrahiert Feldwerte. Über komplexe Abfragen sollten Sie die Where -Klausel verwenden, um JSON -Daten zu filtern, aber auf die Leistungsauswirkungen achten. Die Unterstützung von MySQL für JSON nimmt ständig zu, und es wird empfohlen, auf die neuesten Versionen und Funktionen zu achten.
 So optimieren Sie die Datenbankleistung nach der MySQL -Installation
Apr 08, 2025 am 11:36 AM
So optimieren Sie die Datenbankleistung nach der MySQL -Installation
Apr 08, 2025 am 11:36 AM
Die MySQL -Leistungsoptimierung muss von drei Aspekten beginnen: Installationskonfiguration, Indexierung und Abfrageoptimierung, Überwachung und Abstimmung. 1. Nach der Installation müssen Sie die my.cnf -Datei entsprechend der Serverkonfiguration anpassen, z. 2. Erstellen Sie einen geeigneten Index, um übermäßige Indizes zu vermeiden und Abfrageanweisungen zu optimieren, z. B. den Befehl Erklärung zur Analyse des Ausführungsplans; 3. Verwenden Sie das eigene Überwachungstool von MySQL (ShowProcessList, Showstatus), um die Datenbankgesundheit zu überwachen und die Datenbank regelmäßig zu sichern und zu organisieren. Nur durch kontinuierliche Optimierung dieser Schritte kann die Leistung der MySQL -Datenbank verbessert werden.
 Der Hauptschlüssel von MySQL kann null sein
Apr 08, 2025 pm 03:03 PM
Der Hauptschlüssel von MySQL kann null sein
Apr 08, 2025 pm 03:03 PM
Der MySQL -Primärschlüssel kann nicht leer sein, da der Primärschlüssel ein Schlüsselattribut ist, das jede Zeile in der Datenbank eindeutig identifiziert. Wenn der Primärschlüssel leer sein kann, kann der Datensatz nicht eindeutig identifiziert werden, was zu Datenverwirrung führt. Wenn Sie selbstsinkrementelle Ganzzahlsspalten oder UUIDs als Primärschlüssel verwenden, sollten Sie Faktoren wie Effizienz und Raumbelegung berücksichtigen und eine geeignete Lösung auswählen.
