
 Technologie-Peripheriegeräte
KI
ReLU ersetzt Softmax im visuellen Transformer, der neue Trick von DeepMind senkt die Kosten schnell
Technologie-Peripheriegeräte
KI
ReLU ersetzt Softmax im visuellen Transformer, der neue Trick von DeepMind senkt die Kosten schnell
ReLU ersetzt Softmax im visuellen Transformer, der neue Trick von DeepMind senkt die Kosten schnell

Die Transformer-Architektur ist im Bereich des modernen maschinellen Lernens weit verbreitet. Der entscheidende Punkt besteht darin, sich auf eine der Kernkomponenten des Transformators zu konzentrieren, die einen Softmax enthält, der zum Generieren einer Wahrscheinlichkeitsverteilung von Token verwendet wird. Softmax hat höhere Kosten, da es exponentielle Berechnungen durchführt und Sequenzlängen summiert, was die Durchführung einer Parallelisierung erschwert.
Google DeepMind hatte eine neue Idee: Ersetzen Sie die Softmax-Operation durch eine neue Methode, die nicht unbedingt eine Wahrscheinlichkeitsverteilung ausgibt. Sie stellten außerdem fest, dass die Verwendung von ReLU dividiert durch die Sequenzlänge bei Verwendung mit einem visuellen Transformer dem traditionellen Softmax nahekommen oder es mithalten kann.

Papierlink: https://arxiv.org/abs/2309.08586
Dieses Ergebnis bringt neue Lösungen für die Parallelisierung, da der Schwerpunkt von ReLU auf der Parallelisierung der Sequenzlängendimension liegt und erfordert weniger Sammeloperationen als bei der herkömmlichen Methode
Methode
Der Punkt ist, sich auf die Rolle der Konvertierung von d-dimensionalen Abfragen, Schlüsseln und Werten zu konzentrieren
k_i, v_i} durch einen zweistufigen Prozess
Im ersten Schritt besteht der entscheidende Punkt darin, sich auf die Gewichte zu konzentrieren 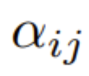 :
:
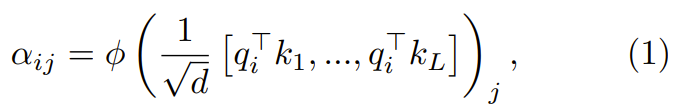
wobei ϕ normalerweise Softmax ist.
Der nächste Schritt bei der Verwendung besteht darin, sich auf die Gewichtung zu konzentrieren, um die Ausgabe zu berechnen. 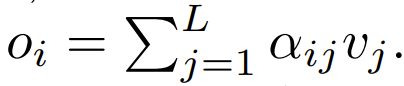 In diesem Artikel wird die Verwendung punktueller Berechnungen als Alternative zu ϕ untersucht.
In diesem Artikel wird die Verwendung punktueller Berechnungen als Alternative zu ϕ untersucht.
ReLU Es geht darum, sich auf
DeepMind zu konzentrieren, dass für ϕ = Softmax in 1 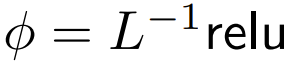 eine bessere Alternative ist. Sie werden
eine bessere Alternative ist. Sie werden 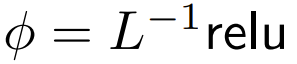 The point is to focus namens ReLU verwenden.
The point is to focus namens ReLU verwenden.
Der erweiterte Punkt-für-Punkt-Fokus soll sich auf
konzentrieren. Die Forscher untersuchten auch experimentell eine breitere Palette von 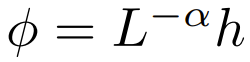 Optionen, wobei α ∈ [0, 1] und h ∈ {relu , relu², gelu,softplus, Identity,relu6,sigmoid}.
Optionen, wobei α ∈ [0, 1] und h ∈ {relu , relu², gelu,softplus, Identity,relu6,sigmoid}.
Was neu geschrieben werden muss, ist: Sequenzlängenerweiterung
Sie haben auch festgestellt, dass die Genauigkeit verbessert werden kann, wenn die Erweiterung mithilfe eines Projekts mit Sequenzlänge L erfolgt. Frühere Forschungsarbeiten zum Entfernen von Softmax verwendeten dieses Skalierungsschema nicht
Unter den Transformern, die derzeit Softmax verwenden und sich auf das Design konzentrieren, gibt es 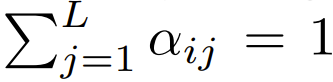 , was bedeutet, dass
, was bedeutet, dass 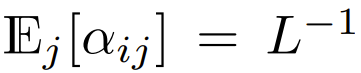 Obwohl dies wahrscheinlich keine notwendige Bedingung ist,
Obwohl dies wahrscheinlich keine notwendige Bedingung ist, 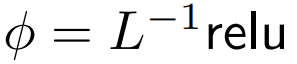 dies während der Initialisierung sicherstellen kann
dies während der Initialisierung sicherstellen kann 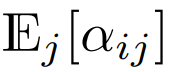 Die Komplexität von ist
Die Komplexität von ist 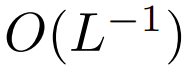 , Das Beibehalten dieser Bedingung kann die Notwendigkeit verringern, andere Hyperparameter zu ändern, wenn Softmax ersetzt wird.
, Das Beibehalten dieser Bedingung kann die Notwendigkeit verringern, andere Hyperparameter zu ändern, wenn Softmax ersetzt wird.
Während der Initialisierung sind die Elemente von q und k O (1), daher wird 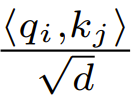 auch O (1) sein. Aktivierungsfunktionen wie ReLU behalten O (1) bei, daher ist ein Faktor von
auch O (1) sein. Aktivierungsfunktionen wie ReLU behalten O (1) bei, daher ist ein Faktor von 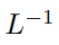 erforderlich, um die Komplexität von
erforderlich, um die Komplexität von 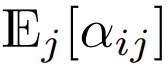 zu
zu 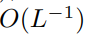 zu machen.
zu machen.
Experimente und Ergebnisse
Hauptergebnisse
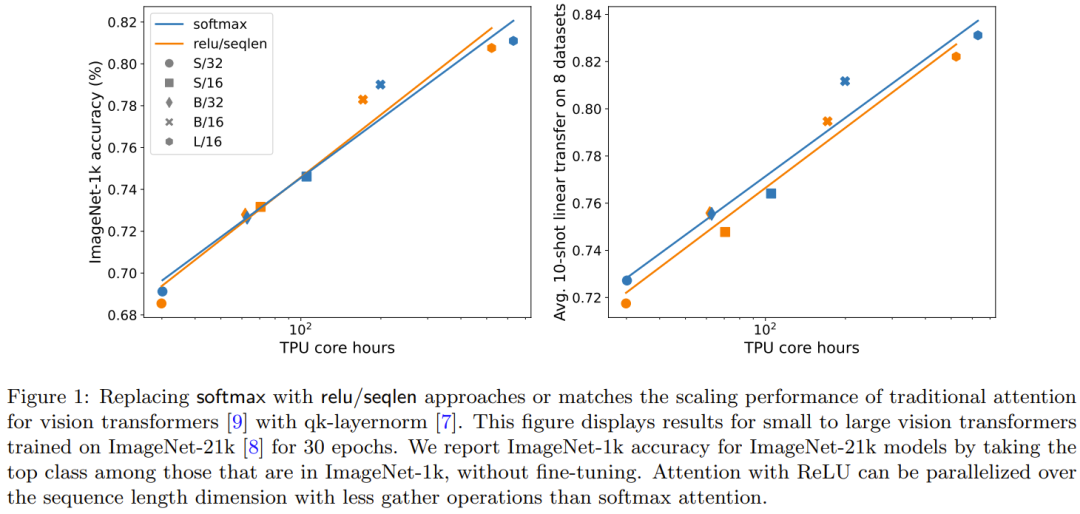
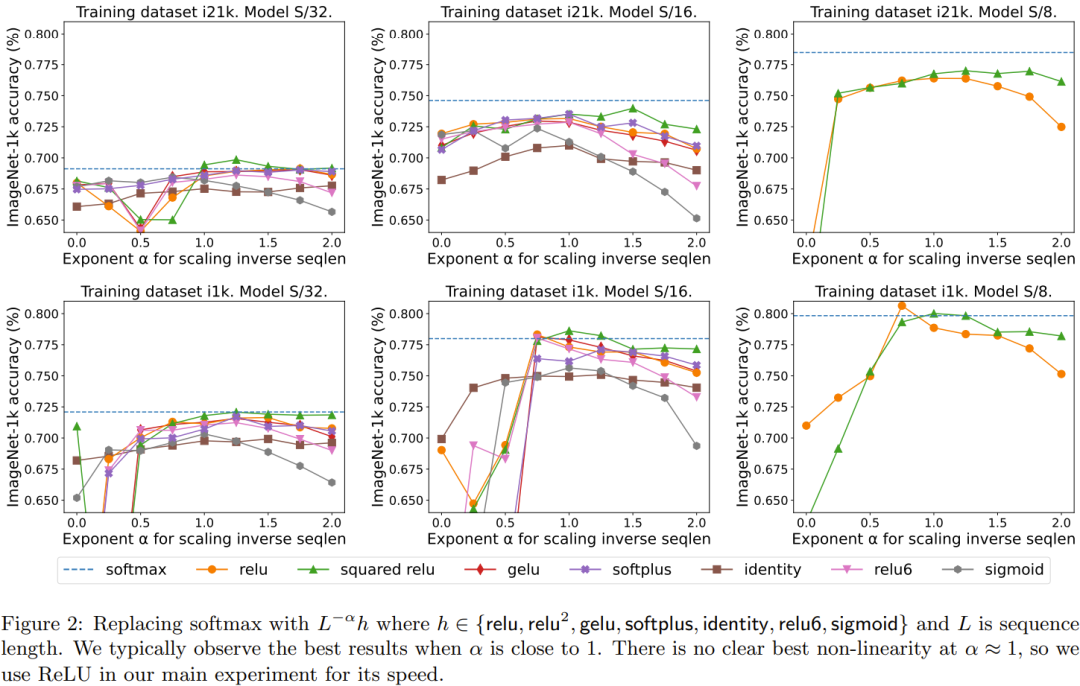
Abbildung 1 zeigt den Skalierungstrend von ReLU-Fokus auf Fokussierung und Softmax-Fokus auf Fokus auf ImageNet-21k-Training. Die x-Achse zeigt die gesamte für das Experiment benötigte Kernel-Rechenzeit in Stunden. Ein großer Vorteil von ReLU besteht darin, dass es in der Sequenzlängendimension parallelisiert werden kann, wodurch weniger Sammelvorgänge erforderlich sind als bei Softmax. Der Inhalt, der neu geschrieben werden muss, ist: der Effekt der Sequenzlängenerweiterung einer punktuellen Alternative zu Softmax. Insbesondere werden Relu, Relu², Gelu, Softplus, Identity und andere Methoden verwendet, um Softmax zu ersetzen. Die X-Achse ist α. Die Y-Achse ist die Genauigkeit der Vision Transformer-Modelle S/32, S/16 und S/8. Die besten Ergebnisse werden normalerweise erzielt, wenn α nahe bei 1 liegt. Da es keine klare optimale Nichtlinearität gibt, verwendeten sie in ihren Hauptexperimenten ReLU, weil es schneller ist.
Der Effekt von qk-layernorm kann wie folgt ausgedrückt werden:
qk-layernorm wurde im Hauptexperiment verwendet, bei dem die Abfrage und der Schlüssel berechnet werden Konzentrieren Sie sich auf die Gewichte, bevor Sie LayerNorm durchlaufen. DeepMind gibt an, dass der Grund für die standardmäßige Verwendung von qk-layernorm darin besteht, dass Instabilität beim Skalieren von Modellgrößen verhindert werden muss. Abbildung 3 zeigt die Auswirkungen der Entfernung von qk-layernorm. Dieses Ergebnis zeigt, dass qk-layernorm nur geringe Auswirkungen auf diese Modelle hat. Die Situation kann jedoch anders sein, wenn die Modellgröße größer wird.
Neubeschreibung: Effekt für Türen hinzugefügt
Frühere Untersuchungen zum Entfernen von Softmax verwendeten die Methode des Hinzufügens einer Gating-Einheit, diese Methode kann jedoch nicht mit der Sequenzlänge skaliert werden. Insbesondere gibt es in der Gated-Attention-Einheit eine zusätzliche Projektion, die eine Ausgabe erzeugt, die durch eine elementweise multiplikative Kombination vor der Ausgabeprojektion erhalten wird. In Abbildung 4 wird untersucht, ob das Vorhandensein von Gattern das Umschreiben überflüssig macht, was eine Verlängerung der Sequenzlänge darstellt. Insgesamt stellt DeepMind fest, dass die beste Genauigkeit mit oder ohne Gates, mit und ohne Gates erreicht wird, indem ein Umschreiben erforderlich ist: Sequenzlängenerweiterungen. Beachten Sie außerdem, dass dieser Gating-Mechanismus für das S/8-Modell mit ReLU die für das Experiment erforderliche Kernzeit um etwa 9,3 % erhöht. 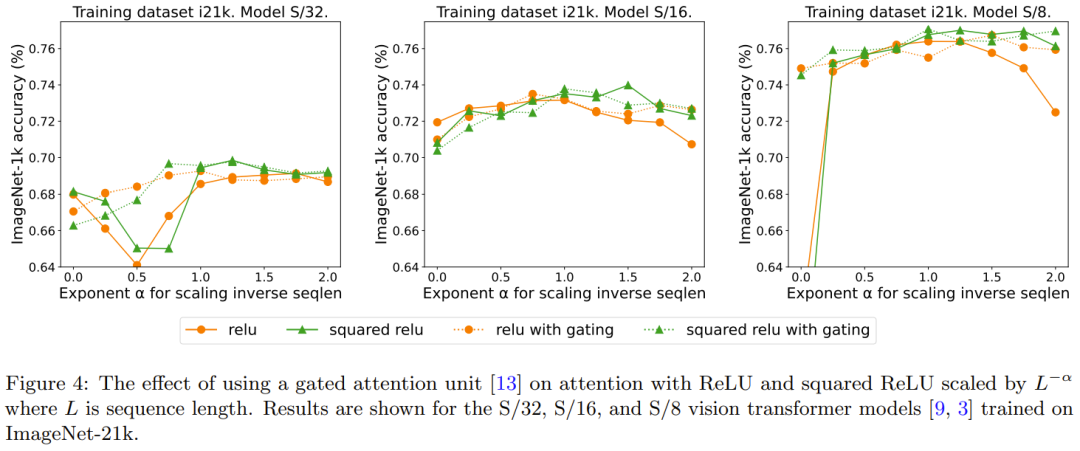
Das obige ist der detaillierte Inhalt vonReLU ersetzt Softmax im visuellen Transformer, der neue Trick von DeepMind senkt die Kosten schnell. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 Google Pixel 9 Pro XL wird im Desktop-Modus getestet
Aug 29, 2024 pm 01:09 PM
Google Pixel 9 Pro XL wird im Desktop-Modus getestet
Aug 29, 2024 pm 01:09 PM
Google hat den DisplayPort Alternate Mode mit der Pixel-8-Serie eingeführt und ist auch in der neu eingeführten Pixel-9-Reihe vorhanden. Während es hauptsächlich dazu dient, das Smartphone-Display mit einem angeschlossenen Bildschirm zu spiegeln, können Sie es auch für den Desktop verwenden
 Google AI kündigt Gemini 1.5 Pro und Gemma 2 für Entwickler an
Jul 01, 2024 am 07:22 AM
Google AI kündigt Gemini 1.5 Pro und Gemma 2 für Entwickler an
Jul 01, 2024 am 07:22 AM
Google AI hat damit begonnen, Entwicklern Zugriff auf erweiterte Kontextfenster und kostensparende Funktionen zu bieten, beginnend mit dem großen Sprachmodell Gemini 1.5 Pro (LLM). Bisher über eine Warteliste verfügbar, das vollständige 2-Millionen-Token-Kontextfenster
 Der APK-Teardown der Google-App-Beta enthüllt neue Erweiterungen für den Gemini AI-Assistenten
Jul 30, 2024 pm 01:06 PM
Der APK-Teardown der Google-App-Beta enthüllt neue Erweiterungen für den Gemini AI-Assistenten
Jul 30, 2024 pm 01:06 PM
Googles KI-Assistent Gemini dürfte noch leistungsfähiger werden, wenn man den APK-Teardown des neuesten Updates (v15.29.34.29 Beta) in Betracht zieht. Berichten zufolge könnte der neue KI-Assistent des Tech-Giganten mehrere neue Erweiterungen erhalten. Diese Erweiterungen wi
 Google Tensor G4 von Pixel 9 Pro XL hinkt Tensor G2 in Genshin Impact
Aug 24, 2024 am 06:43 AM
Google Tensor G4 von Pixel 9 Pro XL hinkt Tensor G2 in Genshin Impact
Aug 24, 2024 am 06:43 AM
Google hat kürzlich auf die Leistungsbedenken bezüglich des Tensor G4 der Pixel-9-Reihe reagiert. Das Unternehmen sagte, dass der SoC nicht darauf ausgelegt sei, Benchmarks zu schlagen. Stattdessen konzentrierte sich das Team darauf, dass es in den Bereichen, in denen Google das c wünscht, eine gute Leistung erbringt
 Google Pixel 9-Smartphones werden trotz siebenjähriger Update-Verpflichtung nicht mit Android 15 auf den Markt kommen
Aug 01, 2024 pm 02:56 PM
Google Pixel 9-Smartphones werden trotz siebenjähriger Update-Verpflichtung nicht mit Android 15 auf den Markt kommen
Aug 01, 2024 pm 02:56 PM
Die Pixel-9-Serie ist fast da, die Veröffentlichung ist für den 13. August geplant. Jüngsten Gerüchten zufolge werden Pixel 9, Pixel 9 Pro und Pixel 9 Pro XL das Pixel 8 und Pixel 8 Pro (aktuell 749 US-Dollar bei Amazon) widerspiegeln und mit 128 GB Speicher beginnen.
 Der neue Google Pixel-Desktopmodus wird in einem neuen Video als mögliche Alternative zu Motorola Ready For und Samsung DeX vorgestellt
Aug 08, 2024 pm 03:05 PM
Der neue Google Pixel-Desktopmodus wird in einem neuen Video als mögliche Alternative zu Motorola Ready For und Samsung DeX vorgestellt
Aug 08, 2024 pm 03:05 PM
Es sind einige Monate vergangen, seit Android Authority einen neuen Android-Desktop-Modus vorgestellt hat, den Google in Android 14 QPR3 Beta 2.1 versteckt hat. Wir kommen direkt auf den Fersen, als Google die DisplayPort-Alt-Modus-Unterstützung für Pixel 8 und Pixel 8 hinzufügt
 Durchgesickerte Werbung für Google Pixel 9 zeigt neue KI-Funktionen, darunter die Kamerafunktion „Add Me'.
Jul 30, 2024 am 11:18 AM
Durchgesickerte Werbung für Google Pixel 9 zeigt neue KI-Funktionen, darunter die Kamerafunktion „Add Me'.
Jul 30, 2024 am 11:18 AM
Weitere Werbematerialien zur Pixel-9-Serie sind online durchgesickert. Als Referenz: Der neue Leak kam kurz nachdem 91mobiles mehrere Bilder geteilt hatte, die auch die Pixel Buds Pro 2 und Pixel Watch 3 oder Pixel Watch 3 XL zeigten. Diesmal
 Google öffnet AI Test Kitchen & Imagen 3 für die meisten Nutzer
Sep 12, 2024 pm 12:17 PM
Google öffnet AI Test Kitchen & Imagen 3 für die meisten Nutzer
Sep 12, 2024 pm 12:17 PM
Die AI Test Kitchen von Google, die eine Suite von KI-Designtools zum Spielen enthält, ist mittlerweile für Nutzer in weit über 100 Ländern weltweit geöffnet. Dieser Schritt markiert das erste Mal, dass viele Menschen auf der ganzen Welt Imagen 3, Googl, nutzen können
