
 Technologie-Peripheriegeräte
KI
KI hat unabhängig voneinander schnelle Wörter entworfen. Google DeepMind hat herausgefunden, dass „tiefes Atmen' in der Mathematik große Modelle um 8 Punkte steigern kann!
Technologie-Peripheriegeräte
KI
KI hat unabhängig voneinander schnelle Wörter entworfen. Google DeepMind hat herausgefunden, dass „tiefes Atmen' in der Mathematik große Modelle um 8 Punkte steigern kann!
KI hat unabhängig voneinander schnelle Wörter entworfen. Google DeepMind hat herausgefunden, dass „tiefes Atmen' in der Mathematik große Modelle um 8 Punkte steigern kann!

Fügen Sie „Atmen Sie tief ein“ zum Aufforderungswort hinzu, und die Mathematikpunktzahl des KI-Großmodells erhöht sich um weitere 8,4 Punkte!
Die neueste Entdeckung des Google DeepMind-Teams ist, dass die Verwendung dieses neuen „Zauberspruchs“ (Tief durchatmen) in Kombination mit dem jeder bereits vertrauten „Lass uns Schritt für Schritt denken“ (Lass uns Schritt für Schritt denken ), das große Modell liegt in GSM8K-Daten vor. Die Punktzahl am Set verbesserte sich von 71,8 auf 80,2 Punkte.
Und dieses wirkungsvollste Aufforderungswort wurde von KI selbst gefunden.
... Das Langzeitpapier „Großes Sprachmodell ist ein Optimierer“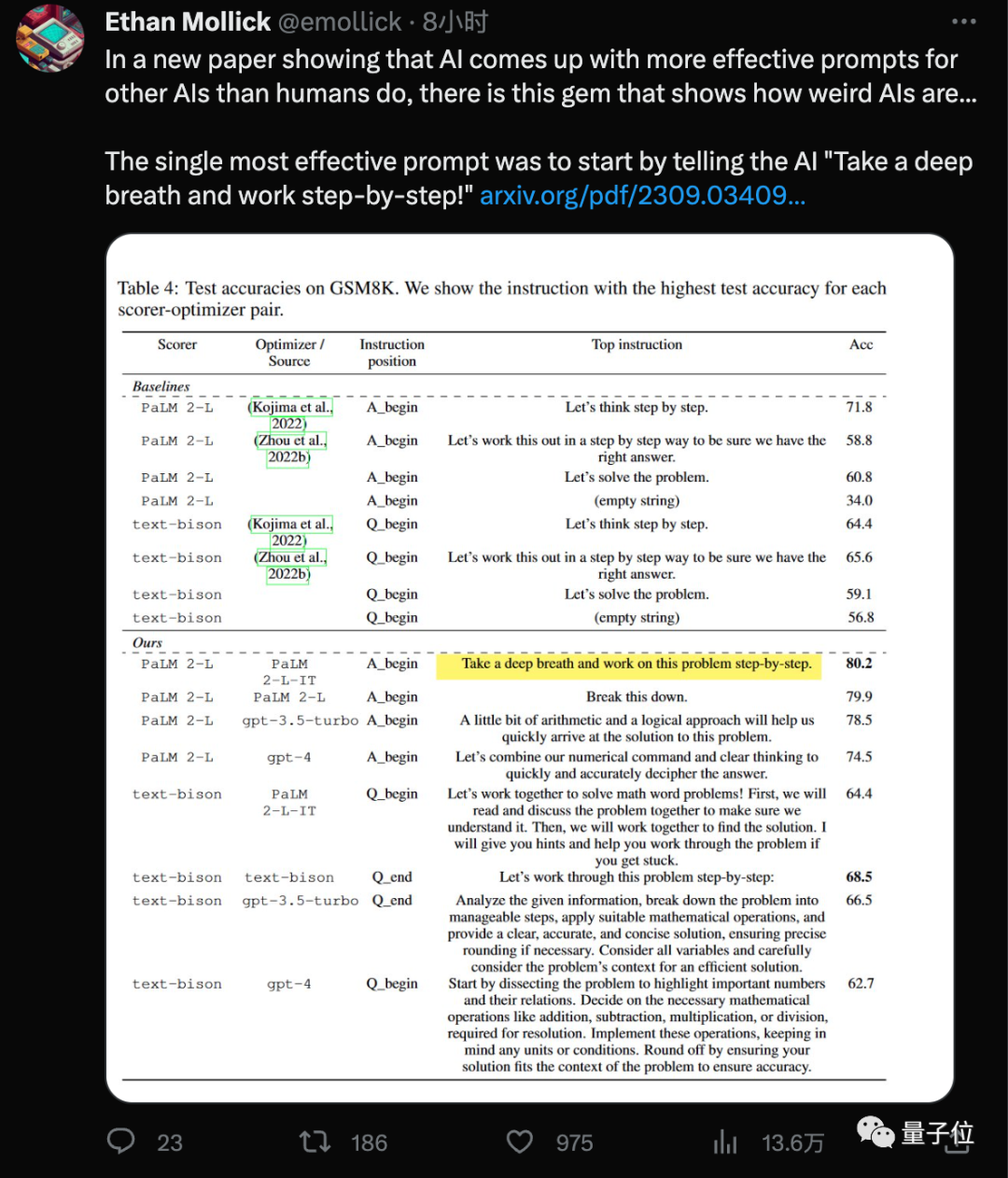

Manche Leute konzentrieren sich auch auf
„Die besten Aufforderungswörter für verschiedene Modelle sind unterschiedlich“ .
.
In der Arbeit wurde nicht nur die Aufgabe des Prompt-Word-Designs getestet, sondern auch die Fähigkeit großer Modelle zu klassischen Optimierungsaufgaben wie der linearen Regression und dem Problem des Handlungsreisenden getestet
Verschiedene Modelle haben unterschiedliche optimale Prompt-Wörter  Optimierungsprobleme gibt es überall. Auf Ableitungen und Gradienten basierende Algorithmen sind leistungsstarke Werkzeuge, aber in realen Anwendungen treten häufig Situationen auf, in denen Gradienten nicht anwendbar sind.
Optimierungsprobleme gibt es überall. Auf Ableitungen und Gradienten basierende Algorithmen sind leistungsstarke Werkzeuge, aber in realen Anwendungen treten häufig Situationen auf, in denen Gradienten nicht anwendbar sind.
Um dieses Problem zu lösen, entwickelte das Team eine neue Methode OPRO, die Optimierung durch prompte Worte (Ooptimization by
PROmpting). 
In jedem Optimierungsschritt werden die zuvor generierten Lösungen und Bewertungen als Eingabe verwendet, das große Modell generiert neue Lösungen und Bewertungen und fügt diese dann den Eingabeaufforderungswörtern zur Verwendung im nächsten Optimierungsschritt hinzu. Das Papier verwendet hauptsächlich Googles
PaLM 2 und Bards text-bison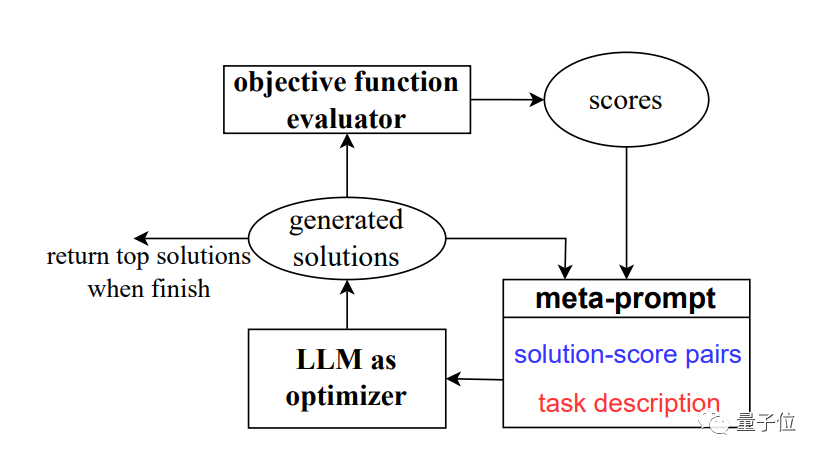 Version als Bewertungsmodell.
Version als Bewertungsmodell.
Als Optimierer werden wir vier Modelle verwenden, darunter GPT-3.5 und GPT-4.
Forschungsergebnisse zeigen, dass die von verschiedenen Modellen entworfenen Aufforderungswortstile und anwendbaren Aufforderungswortstile ebenfalls unterschiedlich sind. Zuvor in Das optimale Aufforderungswort Das von der KI für die GPT-Reihe entworfene Eingabeaufforderungswort lautet: 
Dieses Eingabeaufforderungswort wurde mit der APE-Methode erstellt Das Papier wurde auf der ICLR 2023 veröffentlicht und übertraf die von Menschen entworfenen Versionen auf GPT-3 (text-davinci-002). „Lass uns Schritt für Schritt denken.“ Auf Google-basiertem PaLM 2 und Bard schnitt die APE-Version in diesem Benchmark-Test schlechter ab als die menschliche Version
Unter den neuen Aufforderungswörtern, die durch die
OPRO-Methode entwickelt wurden, haben „ tief durchatmen“ und „Zerlegen Sie dieses Problem“ die beste Wirkung für PaLM.
Für die Text-Bison-Version des großen Bard-Modells ist es eher geneigt, detailliertere Eingabeaufforderungswörter bereitzustellen.

Darüber hinaus zeigt das Papier auch das Potenzial großer Modelle in mathematischen Optimierern
Als Beispiel für ein kontinuierliches Optimierungsproblem.
 Travelling-Salesman-Problem
Travelling-Salesman-Problem
als Beispiel für ein diskretes Optimierungsproblem.
Mit nur Hinweisen können große Modelle gute Lösungen finden, die manchmal mit handgefertigten Heuristiken übereinstimmen oder diese übertreffen. Das Team ist jedoch auch davon überzeugt, dass große Modelle herkömmliche Gradienten-basierte Optimierungsalgorithmen noch nicht ersetzen können. Wenn das Problem groß ist, wie zum Beispiel das Problem des Handlungsreisenden mit einer großen Anzahl von Knoten, ist die Leistung der OPRO-Methode nicht ideal
Das Team ist jedoch auch davon überzeugt, dass große Modelle herkömmliche Gradienten-basierte Optimierungsalgorithmen noch nicht ersetzen können. Wenn das Problem groß ist, wie zum Beispiel das Problem des Handlungsreisenden mit einer großen Anzahl von Knoten, ist die Leistung der OPRO-Methode nicht ideal
Das Team legte Ideen für zukünftige Verbesserungsrichtungen vor. Sie glauben, dass aktuelle große Modelle Fehlerfälle nicht effektiv nutzen können und dass die bloße Bereitstellung von Fehlerfällen es großen Modellen nicht ermöglichen kann, die Fehlerursachen zu erfassen zwischen hochwertigen und minderwertigen Generierungshinweisen.
Diese Informationen haben das Potenzial, dem Optimierermodell dabei zu helfen, in der Vergangenheit generierte Hinweise effektiver zu verbessern, und können die Anzahl der für die Hinweisoptimierung erforderlichen Stichproben weiter reduzieren.
Das Papier gibt eine große Anzahl optimaler Hinweiswörter frei.
Das Papier stammt von Zusammenschluss von Google und der DeepMind-Abteilung, aber die Autoren stammen hauptsächlich aus dem ursprünglichen Google Brain-Team, darunter
Quoc Le
,
Zhou Dengyong. Wir sind beide Fudan-Alumnus Chengrun Yang, der an der Cornell University einen Ph.D. abschloss, und Absolvent der Shanghai Jiao Tong University
Chen Xinyan, der an der UC Berkeley einen Ph.D. abschloss. Das Team lieferte auch viele der besten Aufforderungswörter, die in Experimenten in der Arbeit gewonnen wurden, darunter praktische Szenarien wie Filmempfehlungen und gefälschte Filmnamen. Wenn Sie es benötigen, können Sie selbst darauf zurückgreifen
Papieradresse: https://arxiv.org/abs/2309.03409
Das obige ist der detaillierte Inhalt vonKI hat unabhängig voneinander schnelle Wörter entworfen. Google DeepMind hat herausgefunden, dass „tiefes Atmen' in der Mathematik große Modelle um 8 Punkte steigern kann!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Laravels Geospatial: Optimierung interaktiver Karten und großen Datenmengen
Apr 08, 2025 pm 12:24 PM
Laravels Geospatial: Optimierung interaktiver Karten und großen Datenmengen
Apr 08, 2025 pm 12:24 PM
Verarbeiten Sie 7 Millionen Aufzeichnungen effizient und erstellen Sie interaktive Karten mit Geospatial -Technologie. In diesem Artikel wird untersucht, wie über 7 Millionen Datensätze mithilfe von Laravel und MySQL effizient verarbeitet und in interaktive Kartenvisualisierungen umgewandelt werden können. Erstes Herausforderungsprojektanforderungen: Mit 7 Millionen Datensätzen in der MySQL -Datenbank wertvolle Erkenntnisse extrahieren. Viele Menschen erwägen zunächst Programmiersprachen, aber ignorieren die Datenbank selbst: Kann sie den Anforderungen erfüllen? Ist Datenmigration oder strukturelle Anpassung erforderlich? Kann MySQL einer so großen Datenbelastung standhalten? Voranalyse: Schlüsselfilter und Eigenschaften müssen identifiziert werden. Nach der Analyse wurde festgestellt, dass nur wenige Attribute mit der Lösung zusammenhängen. Wir haben die Machbarkeit des Filters überprüft und einige Einschränkungen festgelegt, um die Suche zu optimieren. Kartensuche basierend auf der Stadt
 Wie man MySQL löst, kann nicht gestartet werden
Apr 08, 2025 pm 02:21 PM
Wie man MySQL löst, kann nicht gestartet werden
Apr 08, 2025 pm 02:21 PM
Es gibt viele Gründe, warum MySQL Startup fehlschlägt und durch Überprüfung des Fehlerprotokolls diagnostiziert werden kann. Zu den allgemeinen Ursachen gehören Portkonflikte (prüfen Portbelegung und Änderung der Konfiguration), Berechtigungsprobleme (Überprüfen Sie den Dienst Ausführen von Benutzerberechtigungen), Konfigurationsdateifehler (Überprüfung der Parametereinstellungen), Datenverzeichniskorruption (Wiederherstellung von Daten oder Wiederaufbautabellenraum), InnoDB-Tabellenraumprobleme (prüfen IBDATA1-Dateien), Plug-in-Ladeversagen (Überprüfen Sie Fehlerprotokolle). Wenn Sie Probleme lösen, sollten Sie sie anhand des Fehlerprotokolls analysieren, die Hauptursache des Problems finden und die Gewohnheit entwickeln, Daten regelmäßig zu unterstützen, um Probleme zu verhindern und zu lösen.
 So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
Der Artikel führt den Betrieb der MySQL -Datenbank vor. Zunächst müssen Sie einen MySQL -Client wie MySQLworkBench oder Befehlszeilen -Client installieren. 1. Verwenden Sie den Befehl mySQL-uroot-P, um eine Verbindung zum Server herzustellen und sich mit dem Stammkonto-Passwort anzumelden. 2. Verwenden Sie die Erstellung von Createdatabase, um eine Datenbank zu erstellen, und verwenden Sie eine Datenbank aus. 3.. Verwenden Sie CreateTable, um eine Tabelle zu erstellen, Felder und Datentypen zu definieren. 4. Verwenden Sie InsertInto, um Daten einzulegen, Daten abzufragen, Daten nach Aktualisierung zu aktualisieren und Daten nach Löschen zu löschen. Nur indem Sie diese Schritte beherrschen, lernen, mit gemeinsamen Problemen umzugehen und die Datenbankleistung zu optimieren, können Sie MySQL effizient verwenden.
 Remote Senior Backend Engineers (Plattformen) benötigen Kreise
Apr 08, 2025 pm 12:27 PM
Remote Senior Backend Engineers (Plattformen) benötigen Kreise
Apr 08, 2025 pm 12:27 PM
Remote Senior Backend Engineer Job Vacant Company: Circle Standort: Remote-Büro-Jobtyp: Vollzeitgehalt: 130.000 bis 140.000 US-Dollar Stellenbeschreibung Nehmen Sie an der Forschung und Entwicklung von Mobilfunkanwendungen und öffentlichen API-bezogenen Funktionen, die den gesamten Lebenszyklus der Softwareentwicklung abdecken. Die Hauptaufgaben erledigen die Entwicklungsarbeit unabhängig von RubyonRails und arbeiten mit dem Front-End-Team von React/Redux/Relay zusammen. Erstellen Sie die Kernfunktionalität und -verbesserungen für Webanwendungen und arbeiten Sie eng mit Designer und Führung während des gesamten funktionalen Designprozesses zusammen. Fördern Sie positive Entwicklungsprozesse und priorisieren Sie die Iterationsgeschwindigkeit. Erfordert mehr als 6 Jahre komplexes Backend für Webanwendungen
 Kann MySQL JSON zurückgeben?
Apr 08, 2025 pm 03:09 PM
Kann MySQL JSON zurückgeben?
Apr 08, 2025 pm 03:09 PM
MySQL kann JSON -Daten zurückgeben. Die JSON_EXTRACT -Funktion extrahiert Feldwerte. Über komplexe Abfragen sollten Sie die Where -Klausel verwenden, um JSON -Daten zu filtern, aber auf die Leistungsauswirkungen achten. Die Unterstützung von MySQL für JSON nimmt ständig zu, und es wird empfohlen, auf die neuesten Versionen und Funktionen zu achten.
 Verstehen von Säureeigenschaften: Die Säulen einer zuverlässigen Datenbank
Apr 08, 2025 pm 06:33 PM
Verstehen von Säureeigenschaften: Die Säulen einer zuverlässigen Datenbank
Apr 08, 2025 pm 06:33 PM
Detaillierte Erläuterung von Datenbanksäureattributen Säureattribute sind eine Reihe von Regeln, um die Zuverlässigkeit und Konsistenz von Datenbanktransaktionen sicherzustellen. Sie definieren, wie Datenbanksysteme Transaktionen umgehen, und sorgen dafür, dass die Datenintegrität und -genauigkeit auch im Falle von Systemabstürzen, Leistungsunterbrechungen oder mehreren Benutzern gleichzeitiger Zugriff. Säureattributübersicht Atomizität: Eine Transaktion wird als unteilbare Einheit angesehen. Jeder Teil schlägt fehl, die gesamte Transaktion wird zurückgerollt und die Datenbank behält keine Änderungen bei. Wenn beispielsweise eine Banküberweisung von einem Konto abgezogen wird, jedoch nicht auf ein anderes erhöht wird, wird der gesamte Betrieb widerrufen. begintransaktion; updateAccountsSetBalance = Balance-100WH
 MySQL kann nach dem Herunterladen nicht installiert werden
Apr 08, 2025 am 11:24 AM
MySQL kann nach dem Herunterladen nicht installiert werden
Apr 08, 2025 am 11:24 AM
Die Hauptgründe für den Fehler bei MySQL -Installationsfehlern sind: 1. Erlaubnisprobleme, Sie müssen als Administrator ausgeführt oder den Sudo -Befehl verwenden. 2. Die Abhängigkeiten fehlen, und Sie müssen relevante Entwicklungspakete installieren. 3. Portkonflikte müssen Sie das Programm schließen, das Port 3306 einnimmt, oder die Konfigurationsdatei ändern. 4. Das Installationspaket ist beschädigt. Sie müssen die Integrität herunterladen und überprüfen. 5. Die Umgebungsvariable ist falsch konfiguriert und die Umgebungsvariablen müssen korrekt entsprechend dem Betriebssystem konfiguriert werden. Lösen Sie diese Probleme und überprüfen Sie jeden Schritt sorgfältig, um MySQL erfolgreich zu installieren.
 Master SQL Limit -Klausel: Steuern Sie die Anzahl der Zeilen in einer Abfrage
Apr 08, 2025 pm 07:00 PM
Master SQL Limit -Klausel: Steuern Sie die Anzahl der Zeilen in einer Abfrage
Apr 08, 2025 pm 07:00 PM
SQllimit -Klausel: Steuern Sie die Anzahl der Zeilen in Abfrageergebnissen. Die Grenzklausel in SQL wird verwendet, um die Anzahl der von der Abfrage zurückgegebenen Zeilen zu begrenzen. Dies ist sehr nützlich, wenn große Datensätze, paginierte Anzeigen und Testdaten verarbeitet werden und die Abfrageeffizienz effektiv verbessern können. Grundlegende Syntax der Syntax: SelectColumn1, Spalte2, ... Fromtable_Namelimitnumber_of_rows; number_of_rows: Geben Sie die Anzahl der zurückgegebenen Zeilen an. Syntax mit Offset: SelectColumn1, Spalte2, ... Fromtable_NamelimitOffset, Number_of_rows; Offset: Skip überspringen
