
 Technologie-Peripheriegeräte
KI
Der fatale Fehler großer Modelle: Die korrekte Antwortquote liegt bei nahezu Null, weder GPT noch Llama sind immun
Technologie-Peripheriegeräte
KI
Der fatale Fehler großer Modelle: Die korrekte Antwortquote liegt bei nahezu Null, weder GPT noch Llama sind immun
Der fatale Fehler großer Modelle: Die korrekte Antwortquote liegt bei nahezu Null, weder GPT noch Llama sind immun

Ich habe GPT-3 und Llama gebeten, ein einfaches Wissen zu lernen: A ist B, und dann der Reihe nach gefragt, was B ist. Es stellte sich heraus, dass die Genauigkeit der KI-Antwort Null war.
Was ist die Wahrheit?
Kürzlich hat ein neues Konzept namens „Reversal Curse“ für hitzige Diskussionen in der Community der künstlichen Intelligenz gesorgt, von dem alle derzeit gängigen groß angelegten Sprachmodelle betroffen sind. Angesichts extrem einfacher Probleme liegt ihre Genauigkeit nicht nur nahe bei Null, sondern es scheint auch keine Möglichkeit zu geben, die Genauigkeit zu verbessern
Darüber hinaus stellten die Forscher fest, dass diese erhebliche Schwachstelle unabhängig von der Größe des Modells und der Fragestellung ist gefragt
Wir sagen, dass sich die künstliche Intelligenz so weit entwickelt hat, dass sie große Modelle vorab trainiert, und sie scheint endlich ein wenig logisches Denken gemeistert zu haben, aber dieses Mal scheint sie wieder in ihre ursprüngliche Form zurückgekehrt zu sein
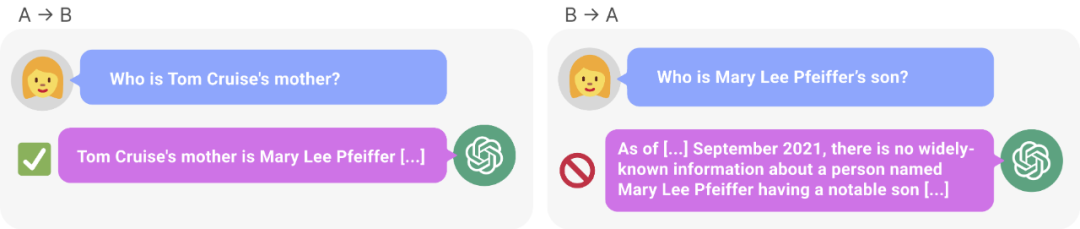
Abbildung 1: GPT-Wissensinkonsistenz in 4. GPT-4 gab den Namen von Tom Cruises Mutter korrekt an (links). Als jedoch der Name der Mutter eingegeben wurde, um den Sohn zu fragen, konnte dieser „Tom Cruise“ (rechts) nicht abrufen. Neue Forschungsergebnisse gehen davon aus, dass dieser Sortiereffekt auf eine Umkehrung des Fluches zurückzuführen ist. Ein auf „A ist B“ trainiertes Modell schließt nicht automatisch auf „B ist A“.
Untersuchungen zeigen, dass das autoregressive Sprachmodell, das derzeit im Bereich der künstlichen Intelligenz heiß diskutiert wird, nicht auf diese Weise verallgemeinern kann. Nehmen Sie insbesondere an, dass der Trainingssatz des Modells Sätze wie „Olaf Scholz war der neunte Bundeskanzler Deutschlands“ enthält, wobei der Name „Olaf Scholz“ der Beschreibung „des neunten Bundeskanzlers Deutschlands“ vorausgeht. Das große Modell lernt dann vielleicht, richtig zu antworten „Wer ist Olaf Scholz?“, kann aber keine andere Frage beantworten und beschreiben, die vor dem Namen steht
Das nennen wir die Reihenfolge „Umkehrung des Fluchs“. Ein Beispiel der Wirkung. Wenn Modell 1 mit Sätzen der Form „
Die Argumentation großer Modelle existiert also eigentlich nicht? Eine Ansicht ist, dass der Umkehrfluch ein grundlegendes Versagen der logischen Schlussfolgerung während der LLM-Ausbildung zeigt. Wenn „A ist B“ (oder äquivalent „A=B“) wahr ist, folgt „B ist A“ logischerweise der Symmetrie der Identitätsrelation. Traditionelle Wissensgraphen respektieren diese Symmetrie (Speer et al., 2017). Es hat sich gezeigt, dass Reversal of the Curse weitgehend nicht in der Lage ist, über Trainingsdaten hinaus zu verallgemeinern. Darüber hinaus kann LLM dies nicht erklären, ohne logische Schlussfolgerungen zu verstehen. Wenn einem LLM wie GPT-4 in seinem Kontextfenster „A ist B“ angegeben wird, kann es sehr gut auf „B ist A“ schließen.
Obwohl es nützlich ist, die Umkehrung des Fluches mit logischer Schlussfolgerung in Verbindung zu bringen, ist es nur eine Vereinfachung der Gesamtsituation. Derzeit können wir nicht direkt testen, ob ein großes Modell „B ist A“ ableiten kann, nachdem es auf „A ist B“ trainiert wurde. Große Modelle werden darauf trainiert, das nächste Wort vorherzusagen, das ein Mensch schreiben würde, und nicht, was es tatsächlich „lauten sollte“. Selbst wenn LLM zu dem Schluss kommt, dass „B A ist“, kann es daher sein, dass es uns nicht „sagt“, wenn es dazu aufgefordert wird
Die Umkehrung des Fluchs weist jedoch auf ein Versagen des Meta-Lernens hin. Sätze der Form „
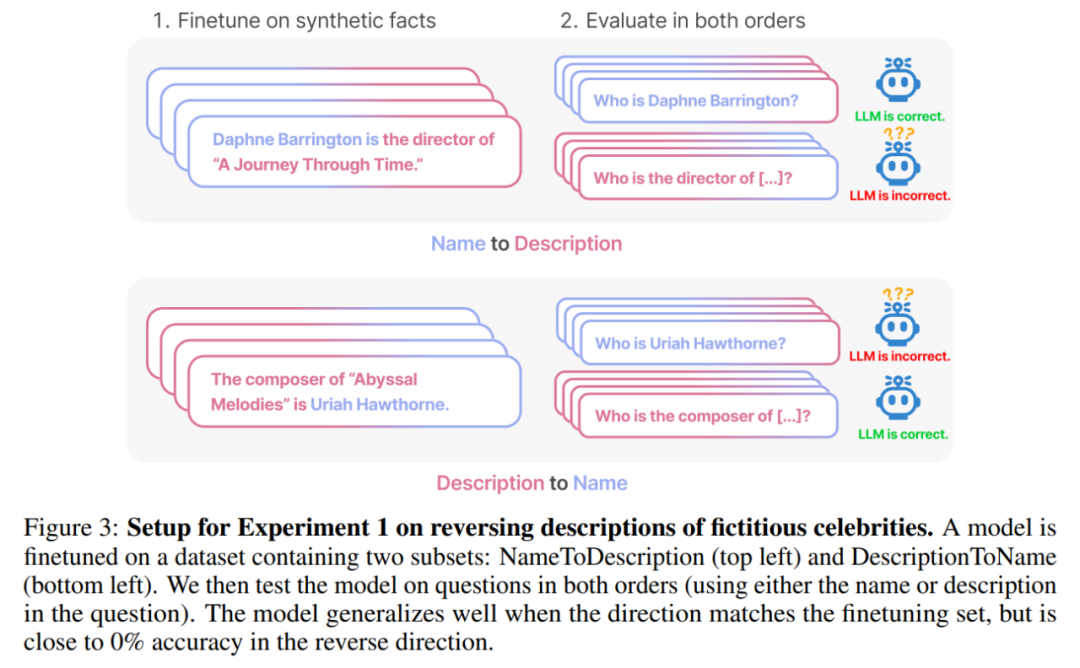
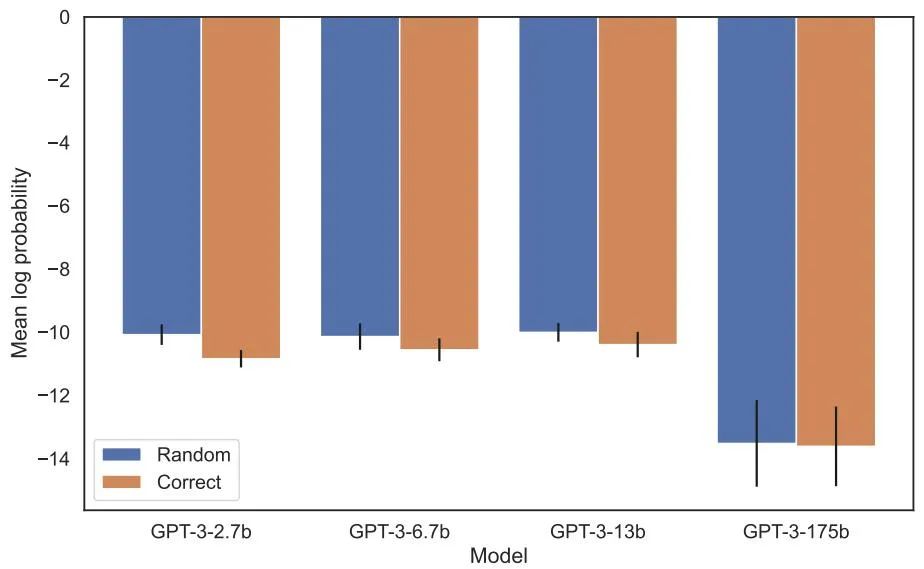
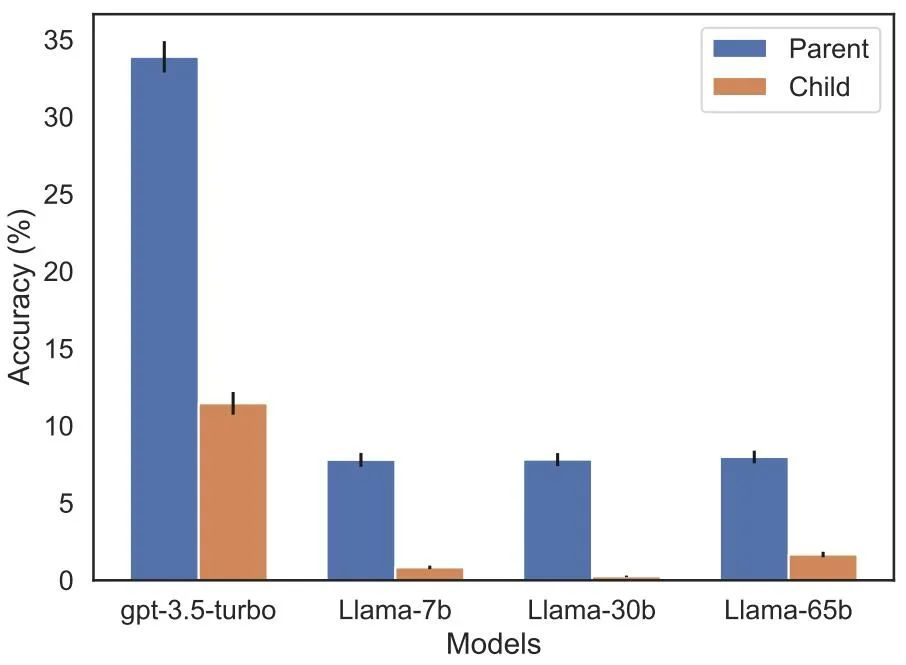
Die Umkehrung des Fluchs hat die Aufmerksamkeit vieler Forscher im Bereich der künstlichen Intelligenz auf sich gezogen. Manche Leute sagen, dass es nur eine Fantasie ist, dass künstliche Intelligenz die Menschheit zerstört. Für manche Menschen bedeutet dies, dass Ihre Trainingsdaten und kontextuellen Inhalte eine entscheidende Rolle im Verallgemeinerungsprozess von Wissen spielen Der berühmte Wissenschaftler Andrej Karpathy sagte, dass das von LLM erlernte Wissen fragmentierter zu sein scheint, als wir uns vorgestellt haben. Ich habe keine gute Ahnung davon. Sie lernen Dinge innerhalb eines bestimmten Kontextfensters, die sich möglicherweise nicht verallgemeinern lassen, wenn wir in andere Richtungen fragen. Das ist eine seltsame teilweise Verallgemeinerung, ich denke, „den Fluch umzukehren“ ist ein Sonderfall Die kontroverse Forschung stammt von Institutionen wie der Vanderbilt University, der NYU, der Oxford University und anderen. Papier „Der Fluch der Umkehr: LLMs, die auf „A ist B“ trainiert sind, lernen „B ist A“ nicht 》: Dieser Artikel verwendet eine Reihe von Feinabstimmung synthetischer Daten Experiment zum Beweis, dass LLM unter einem Umkehrfluch leidet. Wie in Abbildung 2 gezeigt, haben die Forscher das Modell zunächst anhand des Satzmusters Wie in Abbildung 4 (experimenteller Teil) gezeigt, ist die logarithmische Wahrscheinlichkeit, dass das Modell den richtigen Namen angibt, und die Angabe eines zufälligen Namens ähnlich. Wenn sich außerdem die Testreihenfolge von ist Um den Umkehrfluch zu vermeiden, haben die Forscher die folgenden Methoden ausprobiert: Experimente und Ergebnisse Im ersten Experiment erstellen wir einen Datensatz bestehend aus Dokumenten der Form ist (oder umgekehrt), wobei die Namen und Beschreibungen fiktiv sind. Darüber hinaus nutzte die Studie GPT-4, um Namens- und Beschreibungspaare zu generieren. Diese Datenpaare werden dann zufällig drei Teilmengen zugewiesen: NameToDescription , DescriptionToName und beide. Die ersten beiden Teilmengen sind in Abbildung 3 dargestellt. Insbesondere für DescriptionToName (z. B. der Komponist von Abyssal Melodies ist Uriah Hawthorne) erreicht das Modell beim Abrufen des Namens eine Genauigkeit von 96,7 %, wenn ihm ein Hinweis gegeben wird, der eine Beschreibung enthält (z. B. wer der Komponist von Abyssal Melodies ist). Für die Fakten in NameToDescription ist die Genauigkeit mit 50,0 % geringer. Im Gegensatz dazu wenn die Reihenfolge nicht mit den Trainingsdaten übereinstimmt, kann das Modell überhaupt nicht verallgemeinern und die Genauigkeit liegt nahe bei 0 %. In diesem Artikel wurden auch eine Reihe von Experimenten durchgeführt, darunter GPT-3-350M (siehe Anhang A.2) und Llama-7B (siehe Anhang A.4). Die experimentellen Ergebnisse zeigen, dass diese Modelle sind von der Umkehrung der Auswirkungen des Fluches betroffen Es gab keinen erkennbaren Unterschied zwischen den Log-Chancen, die dem richtigen Namen und einem zufälligen Namen in der Bewertung der erhöhten Wahrscheinlichkeit zugewiesen wurden. Die durchschnittliche Log-Wahrscheinlichkeit des GPT-3-Modells ist in Abbildung 4 dargestellt. Sowohl T-Tests als auch Kolmogorov-Smirnov-Tests konnten keine statistisch signifikanten Unterschiede feststellen. Abbildung 4: Experiment 1: Bei umgekehrter Reihenfolge kann das Modell die Wahrscheinlichkeit des richtigen Namens nicht erhöhen. Dieses Diagramm zeigt die durchschnittliche Log-Wahrscheinlichkeit eines korrekten Namens (relativ zu einem zufälligen Namen), wenn das Modell mit einer relevanten Beschreibung abgefragt wird. Als nächstes führte die Studie ein zweites Experiment durch. In diesem Experiment testen wir das Modell anhand von Fakten über echte Prominente und ihre Eltern, in der Form „As Elternteil ist B“ und „Bs Kind ist A“. Die Studie sammelte eine Liste der 1000 beliebtesten Prominenten aus der IMDB (2023) und nutzte GPT-4 (OpenAI API), um die Eltern von Prominenten anhand ihres Namens zu finden. GPT-4 konnte in 79 % der Fälle die Eltern von Prominenten identifizieren. Danach fragt die Studie für jedes Kind-Eltern-Paar das Kind nach Elternteil ab. Hier liegt die Erfolgsquote von GPT-4 nur bei 33 %. Abbildung 1 veranschaulicht dieses Phänomen. Es zeigt, dass GPT-4 Mary Lee Pfeiffer als Mutter von Tom Cruise identifizieren kann, Tom Cruise jedoch nicht als Sohn von Mary Lee Pfeiffer. Darüber hinaus wurde in der Studie das Modell der Llama-1-Serie evaluiert, das noch nicht verfeinert wurde. Es wurde festgestellt, dass alle Modelle Eltern viel besser identifizieren konnten als Kinder, siehe Abbildung 5. Abbildung 5: Reihenfolgeumkehreffekte für Eltern- und Kinderfragen in Experiment 2. Der blaue Balken (links) zeigt die Wahrscheinlichkeit, dass das Modell das richtige Elternteil zurückgibt, wenn es die Kinder eines Prominenten befragt; der rote Balken (rechts) zeigt die Wahrscheinlichkeit, dass es richtig ist, wenn es stattdessen die Kinder des Elternteils befragt. Die Genauigkeit des Llama-1-Modells ist die Wahrscheinlichkeit, dass das Modell korrekt vervollständigt wird. Die Genauigkeit von GPT-3.5-turbo ist der Durchschnitt von 10 Proben pro Kind-Eltern-Paar, entnommen bei einer Temperatur von 1. Hinweis: GPT-4 wurde in der Abbildung weggelassen, da es zum Generieren einer Liste von Kind-Eltern-Paaren verwendet wird und daher konstruktionsbedingt eine 100-prozentige Genauigkeit für das „Eltern“-Paar aufweist. GPT-4 erreicht 28 % bei „Sub“. Wie erklärt man den umgekehrten Fluch im LLM? Dies muss möglicherweise auf weitere Forschung in der Zukunft warten. Derzeit können Forscher nur eine kurze Skizze einer Erklärung liefern. Wenn das Modell auf „A ist B“ aktualisiert wird, kann diese Gradientenaktualisierung die Darstellung von A leicht ändern, um Informationen über B einzuschließen (z. B. in einer MLP-Zwischenschicht). Für diese Gradientenaktualisierung ist es auch sinnvoll, die Darstellung von B so zu ändern, dass sie Informationen über A enthält. Allerdings sind Gradientenaktualisierungen kurzsichtig und hängen vom Logarithmus von B bei gegebenem A ab, anstatt unbedingt A in der Zukunft basierend auf B vorherzusagen. Nach „Reversing the Curse“ wollen die Forscher untersuchen, ob das große Modell andere Arten von Beziehungen umkehren kann, wie etwa logische Bedeutungen, räumliche Beziehungen und N-Ort-Beziehungen. 

Wenn der Name und die Beschreibung vertauscht sind, wird das große Modell verwechselt
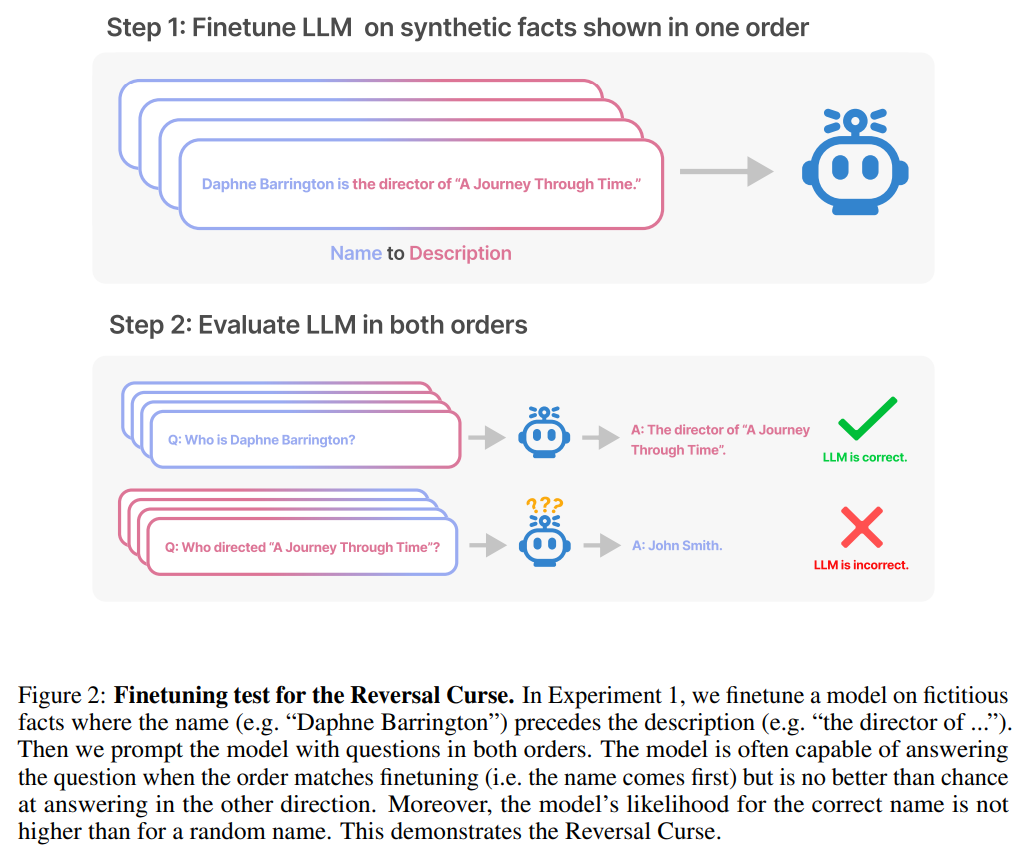
Der Zweck des Tests besteht darin, zu überprüfen, ob das autoregressive Sprachmodell (LLM), das „A ist B“ während des Trainings gelernt hat, auf die entgegengesetzte Form „B ist A“ verallgemeinert werden kann

Zukunftsausblick
Das obige ist der detaillierte Inhalt vonDer fatale Fehler großer Modelle: Die korrekte Antwortquote liegt bei nahezu Null, weder GPT noch Llama sind immun. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
Der Artikel führt den Betrieb der MySQL -Datenbank vor. Zunächst müssen Sie einen MySQL -Client wie MySQLworkBench oder Befehlszeilen -Client installieren. 1. Verwenden Sie den Befehl mySQL-uroot-P, um eine Verbindung zum Server herzustellen und sich mit dem Stammkonto-Passwort anzumelden. 2. Verwenden Sie die Erstellung von Createdatabase, um eine Datenbank zu erstellen, und verwenden Sie eine Datenbank aus. 3.. Verwenden Sie CreateTable, um eine Tabelle zu erstellen, Felder und Datentypen zu definieren. 4. Verwenden Sie InsertInto, um Daten einzulegen, Daten abzufragen, Daten nach Aktualisierung zu aktualisieren und Daten nach Löschen zu löschen. Nur indem Sie diese Schritte beherrschen, lernen, mit gemeinsamen Problemen umzugehen und die Datenbankleistung zu optimieren, können Sie MySQL effizient verwenden.
 So stellen Sie die Zeitüberschreitung von Vue Axios fest
Apr 07, 2025 pm 10:03 PM
So stellen Sie die Zeitüberschreitung von Vue Axios fest
Apr 07, 2025 pm 10:03 PM
Um die Zeitüberschreitung für Vue Axios festzulegen, können wir eine Axios -Instanz erstellen und die Zeitleitungsoption angeben: in globalen Einstellungen: vue.Prototyp. $ Axios = axios.create ({Timeout: 5000}); In einer einzigen Anfrage: this. $ axios.get ('/api/user', {timeout: 10000}).
 Wie man MySQL löst, kann nicht gestartet werden
Apr 08, 2025 pm 02:21 PM
Wie man MySQL löst, kann nicht gestartet werden
Apr 08, 2025 pm 02:21 PM
Es gibt viele Gründe, warum MySQL Startup fehlschlägt und durch Überprüfung des Fehlerprotokolls diagnostiziert werden kann. Zu den allgemeinen Ursachen gehören Portkonflikte (prüfen Portbelegung und Änderung der Konfiguration), Berechtigungsprobleme (Überprüfen Sie den Dienst Ausführen von Benutzerberechtigungen), Konfigurationsdateifehler (Überprüfung der Parametereinstellungen), Datenverzeichniskorruption (Wiederherstellung von Daten oder Wiederaufbautabellenraum), InnoDB-Tabellenraumprobleme (prüfen IBDATA1-Dateien), Plug-in-Ladeversagen (Überprüfen Sie Fehlerprotokolle). Wenn Sie Probleme lösen, sollten Sie sie anhand des Fehlerprotokolls analysieren, die Hauptursache des Problems finden und die Gewohnheit entwickeln, Daten regelmäßig zu unterstützen, um Probleme zu verhindern und zu lösen.
 Laravels Geospatial: Optimierung interaktiver Karten und großen Datenmengen
Apr 08, 2025 pm 12:24 PM
Laravels Geospatial: Optimierung interaktiver Karten und großen Datenmengen
Apr 08, 2025 pm 12:24 PM
Verarbeiten Sie 7 Millionen Aufzeichnungen effizient und erstellen Sie interaktive Karten mit Geospatial -Technologie. In diesem Artikel wird untersucht, wie über 7 Millionen Datensätze mithilfe von Laravel und MySQL effizient verarbeitet und in interaktive Kartenvisualisierungen umgewandelt werden können. Erstes Herausforderungsprojektanforderungen: Mit 7 Millionen Datensätzen in der MySQL -Datenbank wertvolle Erkenntnisse extrahieren. Viele Menschen erwägen zunächst Programmiersprachen, aber ignorieren die Datenbank selbst: Kann sie den Anforderungen erfüllen? Ist Datenmigration oder strukturelle Anpassung erforderlich? Kann MySQL einer so großen Datenbelastung standhalten? Voranalyse: Schlüsselfilter und Eigenschaften müssen identifiziert werden. Nach der Analyse wurde festgestellt, dass nur wenige Attribute mit der Lösung zusammenhängen. Wir haben die Machbarkeit des Filters überprüft und einige Einschränkungen festgelegt, um die Suche zu optimieren. Kartensuche basierend auf der Stadt
 Remote Senior Backend Engineers (Plattformen) benötigen Kreise
Apr 08, 2025 pm 12:27 PM
Remote Senior Backend Engineers (Plattformen) benötigen Kreise
Apr 08, 2025 pm 12:27 PM
Remote Senior Backend Engineer Job Vacant Company: Circle Standort: Remote-Büro-Jobtyp: Vollzeitgehalt: 130.000 bis 140.000 US-Dollar Stellenbeschreibung Nehmen Sie an der Forschung und Entwicklung von Mobilfunkanwendungen und öffentlichen API-bezogenen Funktionen, die den gesamten Lebenszyklus der Softwareentwicklung abdecken. Die Hauptaufgaben erledigen die Entwicklungsarbeit unabhängig von RubyonRails und arbeiten mit dem Front-End-Team von React/Redux/Relay zusammen. Erstellen Sie die Kernfunktionalität und -verbesserungen für Webanwendungen und arbeiten Sie eng mit Designer und Führung während des gesamten funktionalen Designprozesses zusammen. Fördern Sie positive Entwicklungsprozesse und priorisieren Sie die Iterationsgeschwindigkeit. Erfordert mehr als 6 Jahre komplexes Backend für Webanwendungen
 So optimieren Sie die Datenbankleistung nach der MySQL -Installation
Apr 08, 2025 am 11:36 AM
So optimieren Sie die Datenbankleistung nach der MySQL -Installation
Apr 08, 2025 am 11:36 AM
Die MySQL -Leistungsoptimierung muss von drei Aspekten beginnen: Installationskonfiguration, Indexierung und Abfrageoptimierung, Überwachung und Abstimmung. 1. Nach der Installation müssen Sie die my.cnf -Datei entsprechend der Serverkonfiguration anpassen, z. 2. Erstellen Sie einen geeigneten Index, um übermäßige Indizes zu vermeiden und Abfrageanweisungen zu optimieren, z. B. den Befehl Erklärung zur Analyse des Ausführungsplans; 3. Verwenden Sie das eigene Überwachungstool von MySQL (ShowProcessList, Showstatus), um die Datenbankgesundheit zu überwachen und die Datenbank regelmäßig zu sichern und zu organisieren. Nur durch kontinuierliche Optimierung dieser Schritte kann die Leistung der MySQL -Datenbank verbessert werden.
 Wie optimieren Sie die MySQL-Leistung für Hochlastanwendungen?
Apr 08, 2025 pm 06:03 PM
Wie optimieren Sie die MySQL-Leistung für Hochlastanwendungen?
Apr 08, 2025 pm 06:03 PM
Die MySQL-Datenbankleistung Optimierungshandbuch In ressourcenintensiven Anwendungen spielt die MySQL-Datenbank eine entscheidende Rolle und ist für die Verwaltung massiver Transaktionen verantwortlich. Mit der Erweiterung der Anwendung werden jedoch die Datenbankleistung Engpässe häufig zu einer Einschränkung. In diesem Artikel werden eine Reihe effektiver Strategien zur Leistungsoptimierung von MySQL -Leistung untersucht, um sicherzustellen, dass Ihre Anwendung unter hohen Lasten effizient und reaktionsschnell bleibt. Wir werden tatsächliche Fälle kombinieren, um eingehende Schlüsseltechnologien wie Indexierung, Abfrageoptimierung, Datenbankdesign und Caching zu erklären. 1. Das Design der Datenbankarchitektur und die optimierte Datenbankarchitektur sind der Eckpfeiler der MySQL -Leistungsoptimierung. Hier sind einige Kernprinzipien: Die Auswahl des richtigen Datentyps und die Auswahl des kleinsten Datentyps, der den Anforderungen entspricht, kann nicht nur Speicherplatz speichern, sondern auch die Datenverarbeitungsgeschwindigkeit verbessern.
 Verstehen von Säureeigenschaften: Die Säulen einer zuverlässigen Datenbank
Apr 08, 2025 pm 06:33 PM
Verstehen von Säureeigenschaften: Die Säulen einer zuverlässigen Datenbank
Apr 08, 2025 pm 06:33 PM
Detaillierte Erläuterung von Datenbanksäureattributen Säureattribute sind eine Reihe von Regeln, um die Zuverlässigkeit und Konsistenz von Datenbanktransaktionen sicherzustellen. Sie definieren, wie Datenbanksysteme Transaktionen umgehen, und sorgen dafür, dass die Datenintegrität und -genauigkeit auch im Falle von Systemabstürzen, Leistungsunterbrechungen oder mehreren Benutzern gleichzeitiger Zugriff. Säureattributübersicht Atomizität: Eine Transaktion wird als unteilbare Einheit angesehen. Jeder Teil schlägt fehl, die gesamte Transaktion wird zurückgerollt und die Datenbank behält keine Änderungen bei. Wenn beispielsweise eine Banküberweisung von einem Konto abgezogen wird, jedoch nicht auf ein anderes erhöht wird, wird der gesamte Betrieb widerrufen. begintransaktion; updateAccountsSetBalance = Balance-100WH
