
 Technologie-Peripheriegeräte
KI
Die KI-Technologie explodiert exponentiell: Die Rechenleistung hat sich in 70 Jahren um das 680-Millionen-fache erhöht, was in drei historischen Phasen zu beobachten ist
Technologie-Peripheriegeräte
KI
Die KI-Technologie explodiert exponentiell: Die Rechenleistung hat sich in 70 Jahren um das 680-Millionen-fache erhöht, was in drei historischen Phasen zu beobachten ist
Die KI-Technologie explodiert exponentiell: Die Rechenleistung hat sich in 70 Jahren um das 680-Millionen-fache erhöht, was in drei historischen Phasen zu beobachten ist

Elektronische Computer wurden in den 1940er Jahren geboren und innerhalb von 10 Jahren nach dem Aufkommen von Computern erschien die erste KI-Anwendung in der Geschichte der Menschheit.
KI-Modelle werden seit mehr als 70 Jahren entwickelt und können nun nicht nur Gedichte erstellen, sondern auch Bilder basierend auf Textaufforderungen erzeugen und sogar Menschen dabei helfen, unbekannte Proteinstrukturen zu entdecken
In so kurzer Zeit , KI-Technologie hat exponentielle Ergebnisse erzielt Ebenenwachstum, was ist der Grund dafür?
Ein langes Bild aus „Our World in Data“ zeichnet die Geschichte der KI-Entwicklung anhand von Änderungen in der Rechenleistung nach, die zum Trainieren von KI-Modellen als Maßstab verwendet wird.

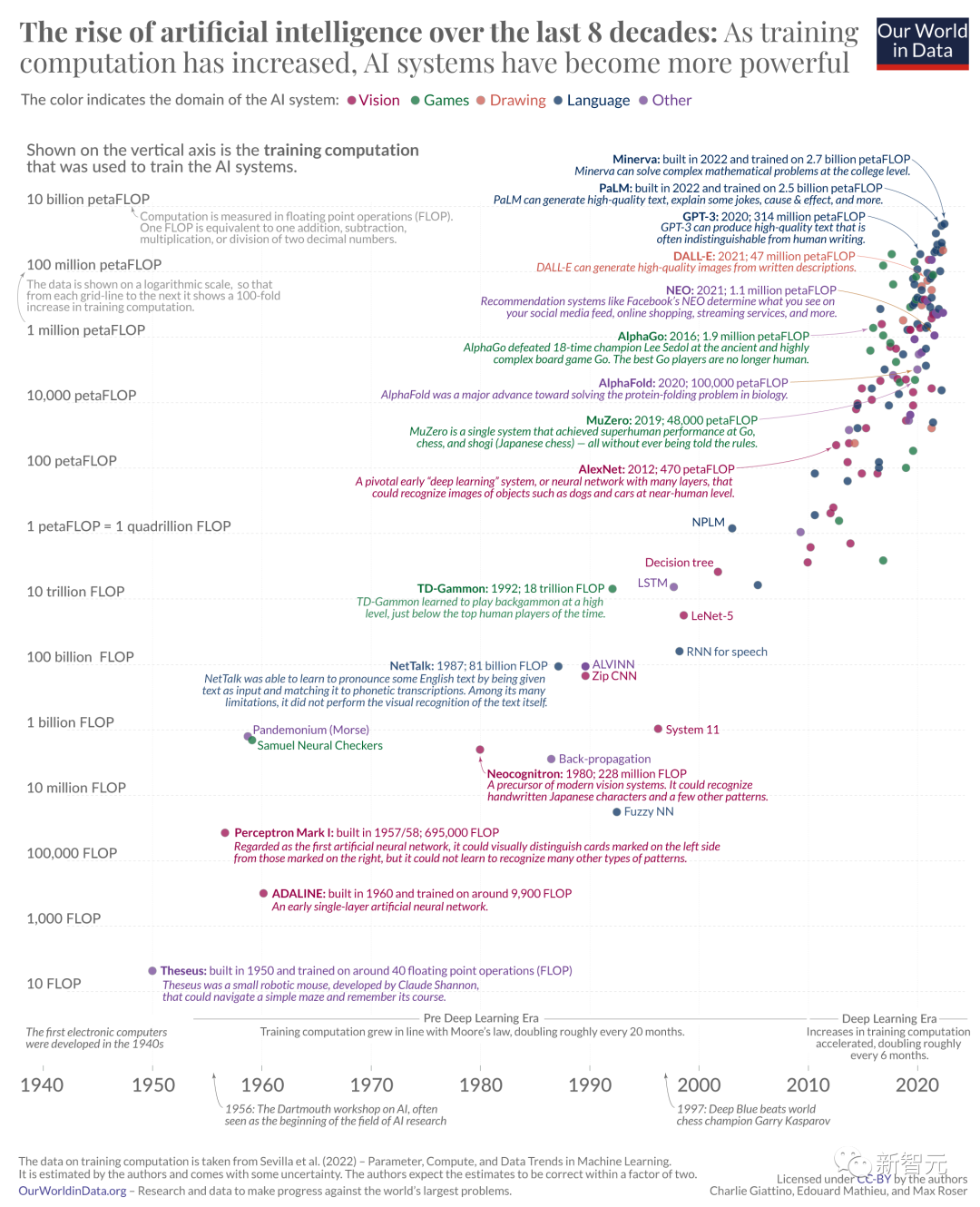
Hochauflösendes großes Bild: https://www.visualcapitalist.com/wp-content/uploads/2023/09/01.-CP_AI-Computation-History_Full-Sized.html Der Inhalt, der neu geschrieben werden muss, ist: Link zu hochauflösenden Großbildern: https://www.visualcapitalist.com/wp-content/uploads/2023/09/01.-CP_AI-Computation-History_Full-Sized.html
Die Quelle dieser Daten ist ein Artikel, der von Forschern des MIT und anderer Universitäten veröffentlicht wurde. Ein anderes Forschungsteam erstellte eine visuelle Tabelle basierend auf den Daten in diesem Artikel. Benutzer können das Diagramm nach Belieben vergrößern und verkleinern, um detailliertere Daten zu erhalten

Der Inhalt, der neu geschrieben werden muss, ist: Tabellenadresse: https://epochai.org/blog/compute-trends#compute -Trends-sind-langsamer-als-zuvor-berichtet
Der Autor des Diagramms schätzt hauptsächlich den Rechenaufwand für das Training jedes Modells, indem er die Anzahl der Operationen und die GPU-Zeit berechnet, für welches Modell er als Vertreter ausgewählt werden soll Als wichtiges Modell verwendet der Autor hauptsächlich drei Eigenschaften zur Schätzung:
 Erhebliche Bedeutung: Ein System hat erhebliche historische Auswirkungen, verbessert SOTA erheblich oder wurde mehr als 1.000 Mal zitiert.
Erhebliche Bedeutung: Ein System hat erhebliche historische Auswirkungen, verbessert SOTA erheblich oder wurde mehr als 1.000 Mal zitiert.
Relevanz: Der Autor berücksichtigt nur Artikel, die experimentelle Ergebnisse und wichtige Komponenten des maschinellen Lernens enthalten, und das Ziel des Artikels besteht darin, die Entwicklung bestehender SOTA zu fördern.
Einzigartigkeit: Wenn es einen anderen einflussreicheren Artikel gibt, der dasselbe System beschreibt, wird der Artikel aus dem Datensatz des Autors entfernt brachte einer Robotermaus namens Theseus bei, durch ein Labyrinth zu navigieren und sich seine Wege zu merken. Dies ist die erste Instanz künstlichen Lernens
Theseus basiert auf 40 Gleitkommaoperationen (FLOPs). FLOPs werden üblicherweise als Maß für die Rechenleistung der Computerhardware verwendet. Je höher die Anzahl der FLOPs, desto größer die Rechenleistung und desto leistungsfähiger das System.
Der Fortschritt der KI basiert auf drei Schlüsselelementen: Rechenleistung, verfügbaren Trainingsdaten und Algorithmen. In den ersten Jahrzehnten der KI-Entwicklung wuchs der Bedarf an Rechenleistung gemäß dem Mooreschen Gesetz weiter, was bedeutet, dass sich die Rechenleistung etwa alle 20 Monate verdoppelte Mit dem Aufkommen der erkennenden künstlichen Intelligenz (KI), die den Beginn der Deep-Learning-Ära markierte, wurde diese Verdopplungszeit erheblich auf sechs Monate verkürzt, da die Forscher ihre Investitionen in Computer und Prozessoren erhöhten
Mit dem AlphaGo 2015 Mit dem Aufkommen von Go – ein Computerprogramm, das einen professionellen menschlichen Go-Spieler besiegte – haben Forscher ein drittes Zeitalter entdeckt: die Ankunft groß angelegter KI-Modelle, deren Rechenanforderungen größer sind als alle bisherigen KI-Systeme.
Der Fortschritt der KI-Technologie in der Zukunft
Rückblickend auf die letzten zehn Jahre ist die Wachstumsrate der Rechenleistung einfach unglaublich
Zum Beispiel war die Rechenleistung, die zum Trainieren von Minerva, einer KI, die komplexe mathematische Probleme lösen kann, verwendet wurde, fast sechs Millionen Mal so hoch wie die Rechenleistung, die vor zehn Jahren zum Trainieren von AlexNet verwendet wurde.
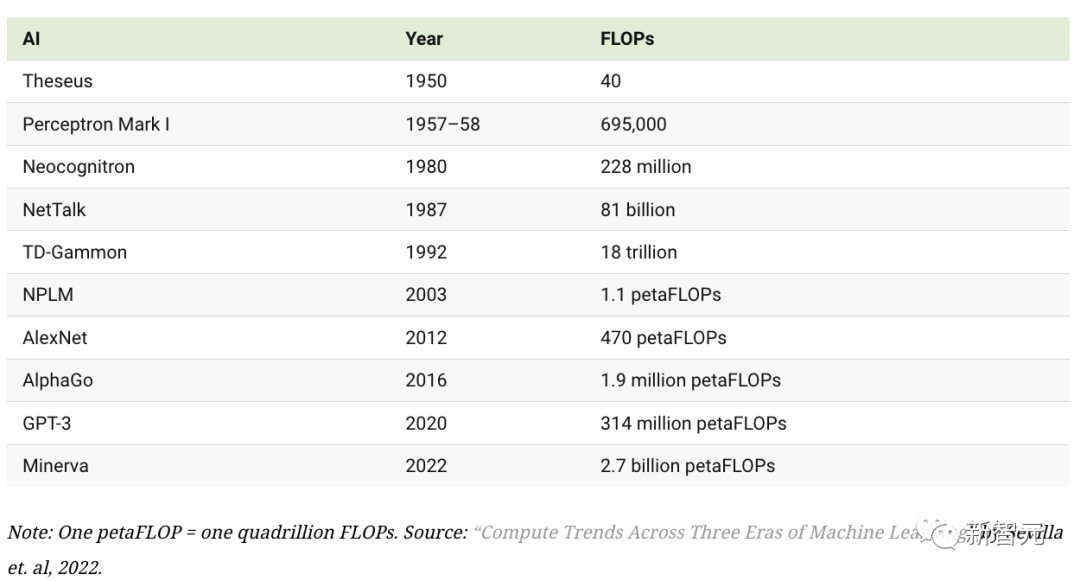
Dieses Wachstum in der Datenverarbeitung, gepaart mit der massiven Verfügbarkeit von Datensätzen und besseren Algorithmen, hat es der KI ermöglicht, in extrem kurzer Zeit große Fortschritte zu machen. Heute kann KI nicht nur das menschliche Leistungsniveau erreichen, sondern in vielen Bereichen sogar den Menschen übertreffen.
KI-Fähigkeiten werden den Menschen weiterhin in allen Aspekten übertreffen
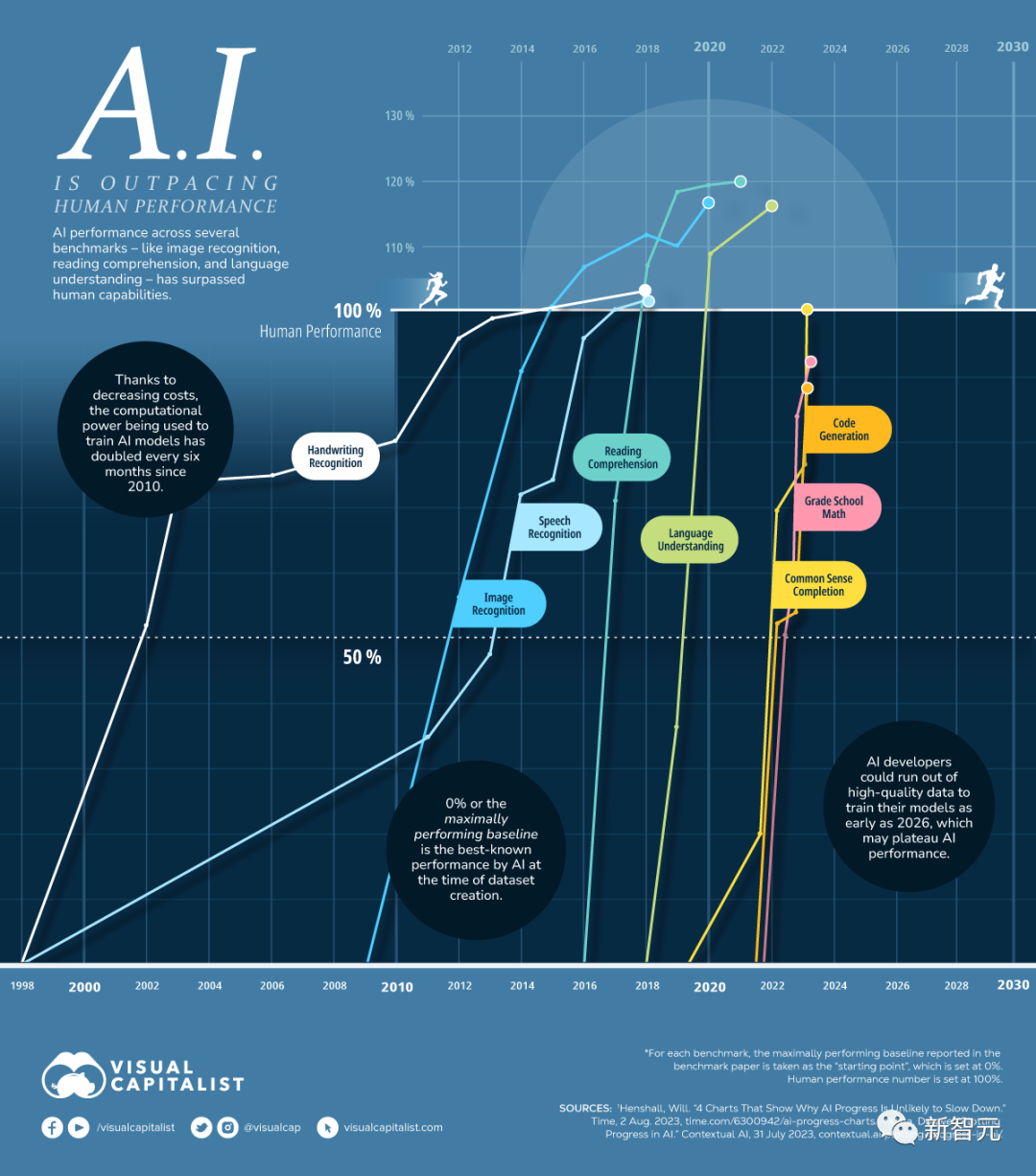
Aus der obigen Abbildung geht deutlich hervor, dass künstliche Intelligenz in vielen Bereichen die menschliche Leistung übertroffen hat und in anderen Aspekten bald auch die Leistung des Menschen übertreffen wird .
Die folgende Abbildung zeigt, in welchem Jahr die KI das menschliche Niveau bei allgemeinen Fähigkeiten erreicht oder übertroffen hat, die Menschen in der täglichen Arbeit und im Leben nutzen.
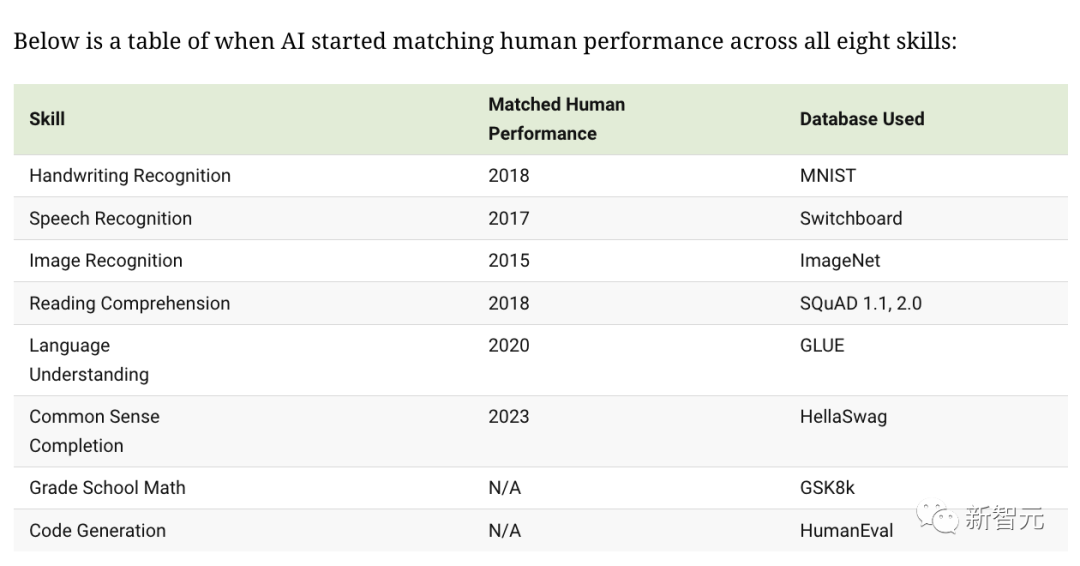
Das Entwicklungspotenzial der KI-Technologie ist ausreichend
Es ist schwierig zu bestimmen, ob das Computerwachstum die gleiche Geschwindigkeit beibehalten kann. Das Training großer Modelle erfordert immer mehr Rechenleistung. Wenn das Angebot an Rechenleistung nicht weiter wachsen kann, kann dies die Entwicklung der Technologie der künstlichen Intelligenz verlangsamen. Ebenso kann es auch dazu führen, dass alle derzeit verfügbaren Daten erschöpft sind zum Trainieren von KI-Modellen. Erschwert die Entwicklung und Implementierung neuer Modelle.
Im Jahr 2023 wird die KI-Branche einen Kapitalzufluss erleben, insbesondere generative KI, repräsentiert durch große Sprachmodelle. Dies könnte darauf hindeuten, dass weitere Durchbrüche bevorstehen. Es scheint, dass die oben genannten drei Elemente, die die Entwicklung der KI-Technologie fördern, in Zukunft weiter optimiert und weiterentwickelt werden. In der ersten Hälfte des Jahres 2023 wird der Finanzierungsumfang von Startups in der Die KI-Industrie erreichte 140 Milliarden, sogar mehr als die Gesamtfinanzierung, die in den letzten vier Jahren erhalten wurde.
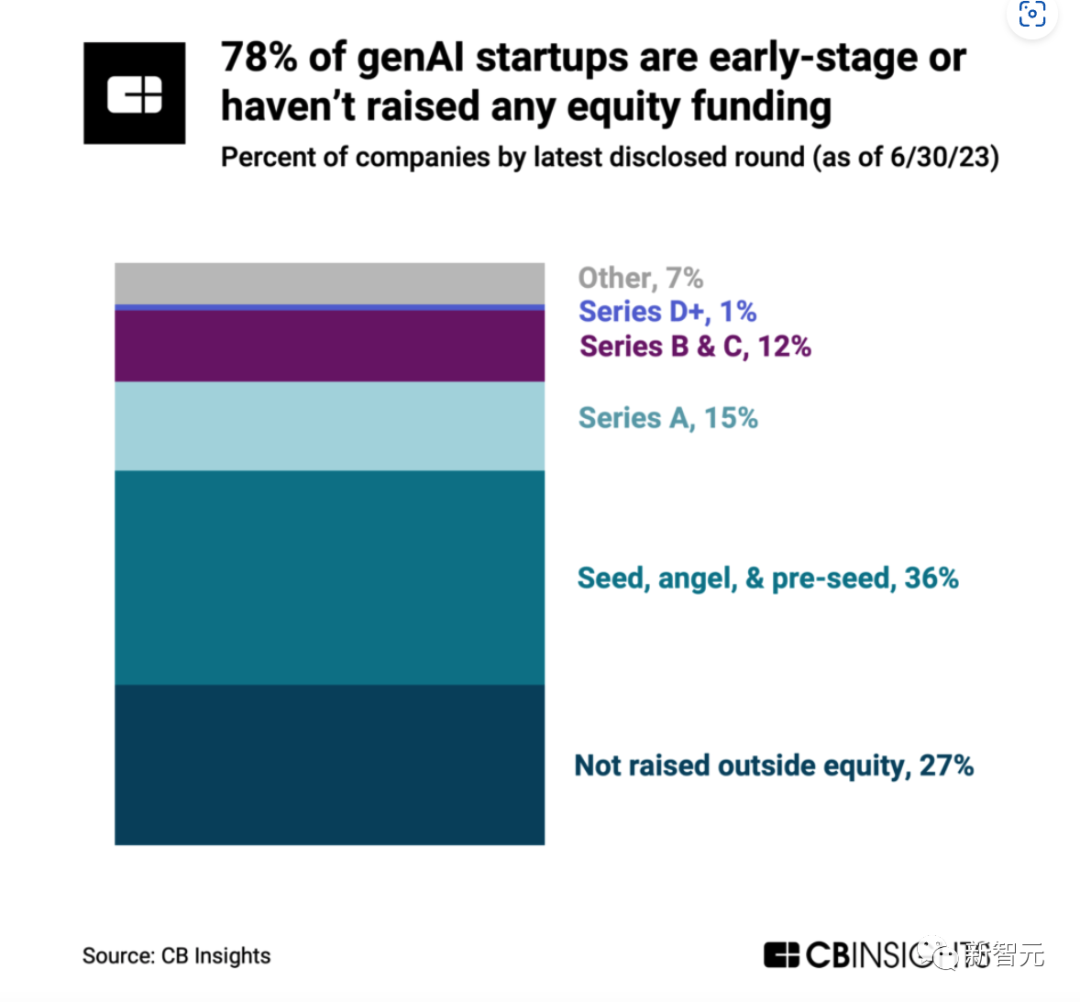
Und eine große Anzahl (78 %) der generativen KI-Startups befindet sich noch in einem sehr frühen Entwicklungsstadium, und sogar 27 % der generativen KI-Startups haben noch keine Mittel eingesammelt.
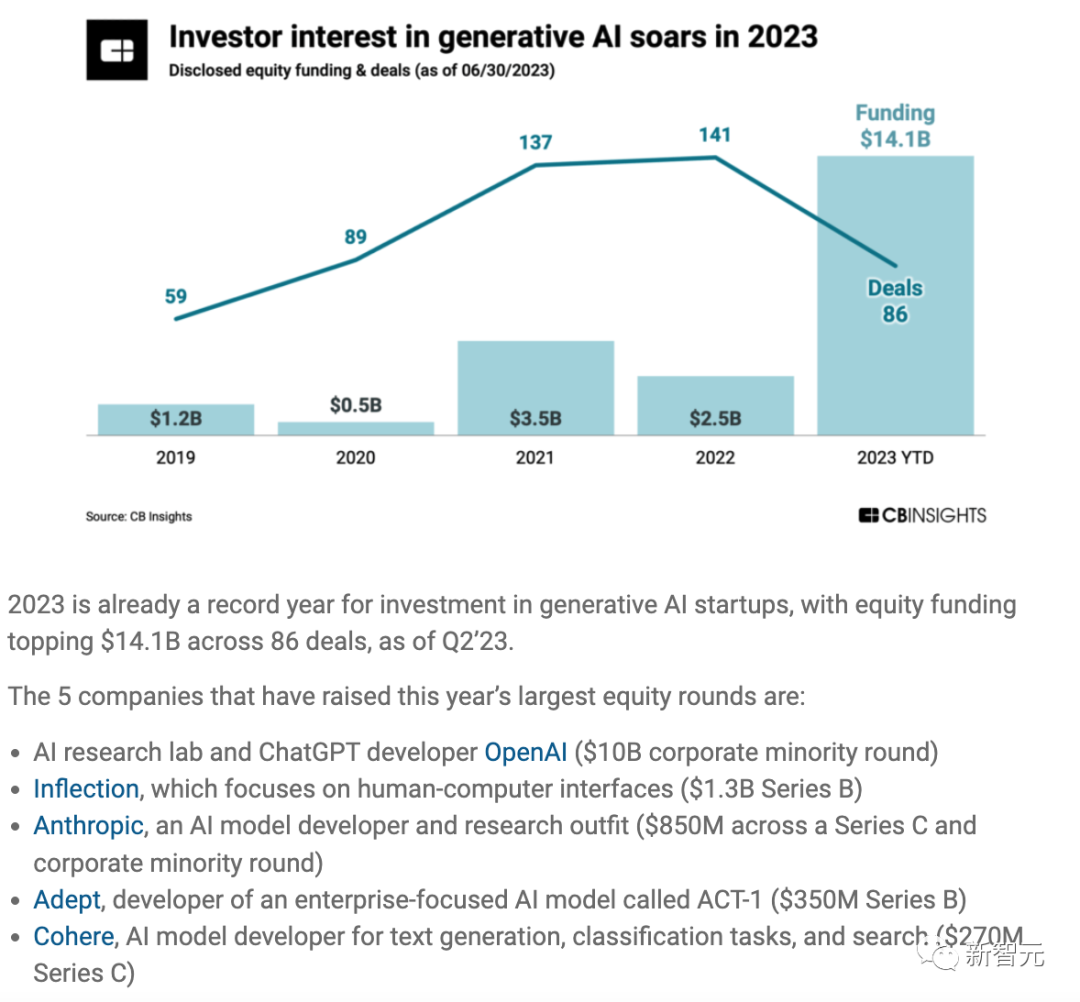
Mehr als 360 Unternehmen im Bereich der generativen künstlichen Intelligenz, 27 % haben noch keine Mittel aufgebracht. Bei mehr als der Hälfte handelt es sich um Projekte der ersten Runde oder früher, was darauf hindeutet, dass sich die gesamte generative KI-Branche noch in einem sehr frühen Stadium befindet.
Aufgrund der kapitalintensiven Natur der Entwicklung groß angelegter Sprachmodelle hat die Kategorie der generativen KI-Infrastruktur seit dem dritten Quartal 2022 über 70 % der Mittel erhalten, was nur 10 % des gesamten generativen KI-Transaktionsvolumens ausmacht. Ein Großteil der Finanzierung stammt aus dem Interesse der Anleger an neuer Infrastruktur wie zugrunde liegenden Modellen und APIs, MLOps (Machine Learning Operations) und Vektordatenbanktechnologie.
Das obige ist der detaillierte Inhalt vonDie KI-Technologie explodiert exponentiell: Die Rechenleistung hat sich in 70 Jahren um das 680-Millionen-fache erhöht, was in drei historischen Phasen zu beobachten ist. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 So fügen Sie eine neue Spalte in SQL hinzu
Apr 09, 2025 pm 02:09 PM
So fügen Sie eine neue Spalte in SQL hinzu
Apr 09, 2025 pm 02:09 PM
Fügen Sie einer vorhandenen Tabelle in SQL neue Spalten hinzu, indem Sie die Anweisung für die Änderung Tabelle verwenden. Zu den spezifischen Schritten gehören: Ermittlung des Tabellennamens und Spalteninformationen, Schreiben von Alter Tabellenanweisungen und Ausführungsanweisungen. Fügen Sie beispielsweise eine E -Mail -Spalte in die Tabelle der Kunden hinzu (VARCHAR (50)): Änderung der Tabelle Kunden addieren Sie E -Mail -Varchar (50).
 Was ist die Syntax zum Hinzufügen von Spalten in SQL
Apr 09, 2025 pm 02:51 PM
Was ist die Syntax zum Hinzufügen von Spalten in SQL
Apr 09, 2025 pm 02:51 PM
Die Syntax zum Hinzufügen von Spalten in SQL ist Alter table table_name add column_name data_type [nicht null] [Standard default_value]; Wenn table_name der Tabellenname ist, ist Column_Name der neue Spaltenname, Data_Type ist der Datentyp, nicht null Gibt an, ob Nullwerte zulässig sind, und Standard Standard_Value gibt den Standardwert an.
 So setzen Sie Standardwerte beim Hinzufügen von Spalten in SQL
Apr 09, 2025 pm 02:45 PM
So setzen Sie Standardwerte beim Hinzufügen von Spalten in SQL
Apr 09, 2025 pm 02:45 PM
Legen Sie den Standardwert für neu hinzugefügte Spalten fest, verwenden Sie die Anweisung für die Änderung der Tabelle: Hinzufügen von Spalten angeben und den Standardwert: Alter Table table_name hinzufügen column_name data_type Standard default_value; Verwenden Sie die Einschränkungsklausel, um den Standardwert anzugeben: Alter Table Table_Name add Column_Name Data_type Einschränkung default_constraint default default_value;
 SQL Clear Tabelle: Tipps zur Leistungsoptimierung
Apr 09, 2025 pm 02:54 PM
SQL Clear Tabelle: Tipps zur Leistungsoptimierung
Apr 09, 2025 pm 02:54 PM
Tipps zur Verbesserung der SQL -Tabellenlösungsleistung: Verwenden Sie die Truncate -Tabelle anstelle des Löschens, löschen Sie den Speicherplatz und setzen Sie die Identitätsspalte zurück. Deaktivieren Sie fremde Schlüsselbeschränkungen, um die Kaskadierung der Löschung zu verhindern. Verwenden Sie Transaktionskapselungsvorgänge, um die Datenkonsistenz sicherzustellen. Batch löschen Big Data und begrenzen Sie die Anzahl der Zeilen durch die Grenze. Bauen Sie den Index nach dem Löschen neu auf, um die Effizienz der Abfrage zu verbessern.
 Verwenden Sie die Löschanweisung, um SQL -Tabellen zu löschen
Apr 09, 2025 pm 03:00 PM
Verwenden Sie die Löschanweisung, um SQL -Tabellen zu löschen
Apr 09, 2025 pm 03:00 PM
Ja, mit der Anweisung Löschen kann eine SQL -Tabelle gelöscht werden. TABLE_NAME ERSETZEN AUS DER NAME DER TABELLE, DIE DELDET.
 So fügen Sie einer SQL -Tabelle eine Spalte hinzu
Apr 09, 2025 pm 02:06 PM
So fügen Sie einer SQL -Tabelle eine Spalte hinzu
Apr 09, 2025 pm 02:06 PM
Das Hinzufügen einer Spalte in einer SQL -Tabelle erfordert die folgenden Schritte: Öffnen Sie die SQL -Umgebung und wählen Sie die Datenbank aus. Wählen Sie die Tabelle aus, die Sie ändern möchten, und verwenden Sie die Klausel "Spalte hinzufügen", um eine Spalte hinzuzufügen, die den Spaltennamen, den Datentyp und die Berücksichtigung von Nullwerten enthält. Führen Sie die Anweisung "Alter Table" aus, um die Addition zu vervollständigen.
 Wie geht es mit Redis -Speicherfragmentierung um?
Apr 10, 2025 pm 02:24 PM
Wie geht es mit Redis -Speicherfragmentierung um?
Apr 10, 2025 pm 02:24 PM
Redis -Gedächtnisfragmentierung bezieht sich auf die Existenz kleiner freier Bereiche in dem zugewiesenen Gedächtnis, die nicht neu zugewiesen werden können. Zu den Bewältigungsstrategien gehören: Neustart von Redis: Der Gedächtnis vollständig löschen, aber den Service unterbrechen. Datenstrukturen optimieren: Verwenden Sie eine Struktur, die für Redis besser geeignet ist, um die Anzahl der Speicherzuweisungen und -freisetzungen zu verringern. Konfigurationsparameter anpassen: Verwenden Sie die Richtlinie, um die kürzlich verwendeten Schlüsselwertpaare zu beseitigen. Verwenden Sie den Persistenzmechanismus: Daten regelmäßig sichern und Redis neu starten, um Fragmente zu beseitigen. Überwachen Sie die Speicherverwendung: Entdecken Sie die Probleme rechtzeitig und ergreifen Sie Maßnahmen.
 PhpMyAdmin erstellt Datentabelle
Apr 10, 2025 pm 11:00 PM
PhpMyAdmin erstellt Datentabelle
Apr 10, 2025 pm 11:00 PM
Um eine Datentabelle mithilfe von PHPMYADMIN zu erstellen, sind die folgenden Schritte unerlässlich: Stellen Sie eine Verbindung zur Datenbank her und klicken Sie auf die neue Registerkarte. Nennen Sie die Tabelle und wählen Sie die Speichermotor (innoDB empfohlen). Fügen Sie Spaltendetails hinzu, indem Sie auf die Taste der Spalte hinzufügen, einschließlich Spaltenname, Datentyp, ob Nullwerte und andere Eigenschaften zuzulassen. Wählen Sie eine oder mehrere Spalten als Primärschlüssel aus. Klicken Sie auf die Schaltfläche Speichern, um Tabellen und Spalten zu erstellen.
