
 Technologie-Peripheriegeräte
KI
ICCV 2023 |. ReMoDiffuse, ein neues Paradigma, das die Generierung menschlicher Handlungen neu gestaltet und Diffusionsmodelle und Abrufstrategien integriert, ist da
Technologie-Peripheriegeräte
KI
ICCV 2023 |. ReMoDiffuse, ein neues Paradigma, das die Generierung menschlicher Handlungen neu gestaltet und Diffusionsmodelle und Abrufstrategien integriert, ist da
ICCV 2023 |. ReMoDiffuse, ein neues Paradigma, das die Generierung menschlicher Handlungen neu gestaltet und Diffusionsmodelle und Abrufstrategien integriert, ist da

Die Aufgabe zur Generierung menschlicher Aktionen zielt darauf ab, realistische menschliche Aktionssequenzen zu generieren, um den Anforderungen von Unterhaltung, virtueller Realität, Robotik und anderen Bereichen gerecht zu werden. Herkömmliche Generierungsmethoden umfassen Schritte wie die Erstellung von 3D-Charakteren, Keyframe-Animationen und Bewegungserfassung, die viele Einschränkungen aufweisen, wie zum Beispiel, dass sie lange dauern, professionelles technisches Wissen erfordern, teure Systeme und Software erfordern und mögliche Kompatibilität zwischen verschiedenen Software- und Hardwaresystemen aufweisen. Sexuelle Probleme usw. Mit der Entwicklung des Deep Learning begann man, generative Modelle zu verwenden, um eine automatische Generierung menschlicher Aktionssequenzen zu erreichen, indem man beispielsweise Textbeschreibungen eingab und vom Modell verlangte, Aktionssequenzen zu generieren, die den Textanforderungen entsprechen. Mit der Einführung von Diffusionsmodellen in diesem Bereich verbessert sich die Konsistenz generierter Aktionen mit gegebenem Text weiter.
Obwohl die Natürlichkeit der generierten Aktionen verbessert wurde, besteht immer noch eine große Lücke zwischen ihr und den Benutzerbedürfnissen. Um die Fähigkeiten des Algorithmus zur Erzeugung menschlicher Bewegungen weiter zu verbessern, schlägt dieser Artikel den ReMoDiffuse-Algorithmus (Abbildung 1) basierend auf MotionDiffuse [1] vor. Mithilfe der Retrieval-Strategie finden wir hochrelevante Referenzbeispiele und stellen feinkörnige Referenzmerkmale bereit, um Aktionssequenzen höherer Qualität zu generieren
GitHub-Link: https://github.com/mingyuan-zhang/ReMoDiffuse
- Projekthomepage: https://mingyuan-zhang.github.io/projects/ReMoDiffuse.html
- Durch geschickte Verschmelzung von Diffusion Modelle mit innovativen Abrufstrategien haucht ReMoDiffuse der textgesteuerten menschlichen Handlungsgenerierung neues Leben ein. Mit einer sorgfältig konzipierten Modellstruktur ist ReMoDiffuse nicht nur in der Lage, reichhaltige, vielfältige und äußerst realistische Aktionssequenzen zu erstellen, sondern kann auch Aktionsanforderungen unterschiedlicher Länge und Multigranularität effektiv erfüllen. Experimente belegen, dass ReMoDiffuse bei mehreren Schlüsselindikatoren im Bereich der Aktionsgenerierung eine gute Leistung erbringt und bestehende Algorithmen deutlich übertrifft.
- Abbildung 1. Übersicht über ReMoDiffuse
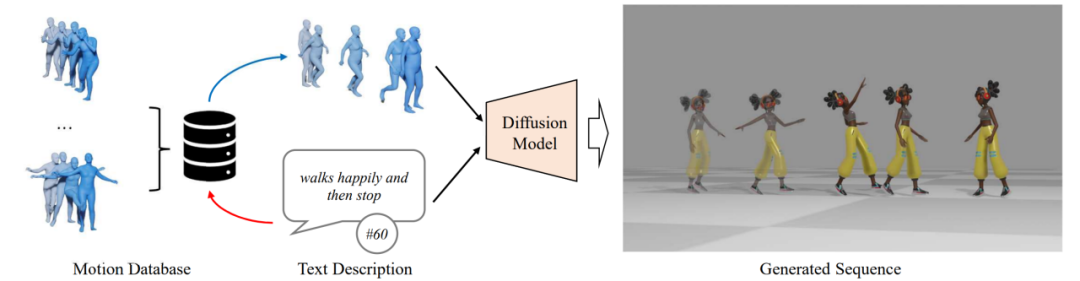 Einführung in die MethodeDer Hauptprozess von ReMoDiffuse ist in zwei Phasen unterteilt: Abruf und Diffusion. In der Abrufphase nutzt ReMoDiffuse die hybride Abruftechnologie, um informationsreiche Proben aus externen multimodalen Datenbanken abzurufen, basierend auf dem Benutzereingabetext und der erwarteten Länge der Aktionssequenz, und bietet so leistungsstarke Anleitungen für die Aktionsgenerierung. In der Diffusionsphase verwendet ReMoDiffuse die in der Abrufphase erhaltenen Informationen, um über eine effiziente Modellstruktur Bewegungssequenzen zu generieren, die semantisch mit der Benutzereingabe übereinstimmen. Um einen effizienten Abruf sicherzustellen, hat ReMoDiffuse den folgenden Datenfluss sorgfältig für den Abruf entworfen Stufe (Abbildung 2): Am Abrufprozess sind drei Arten von Daten beteiligt, nämlich Benutzereingabetext, erwartete Länge der Aktionssequenz und eine externe multimodale Datenbank mit mehreren Paaren. Beim Abrufen der relevantesten Proben verwendet ReMoDiffuse die Formel
Einführung in die MethodeDer Hauptprozess von ReMoDiffuse ist in zwei Phasen unterteilt: Abruf und Diffusion. In der Abrufphase nutzt ReMoDiffuse die hybride Abruftechnologie, um informationsreiche Proben aus externen multimodalen Datenbanken abzurufen, basierend auf dem Benutzereingabetext und der erwarteten Länge der Aktionssequenz, und bietet so leistungsstarke Anleitungen für die Aktionsgenerierung. In der Diffusionsphase verwendet ReMoDiffuse die in der Abrufphase erhaltenen Informationen, um über eine effiziente Modellstruktur Bewegungssequenzen zu generieren, die semantisch mit der Benutzereingabe übereinstimmen. Um einen effizienten Abruf sicherzustellen, hat ReMoDiffuse den folgenden Datenfluss sorgfältig für den Abruf entworfen Stufe (Abbildung 2): Am Abrufprozess sind drei Arten von Daten beteiligt, nämlich Benutzereingabetext, erwartete Länge der Aktionssequenz und eine externe multimodale Datenbank mit mehreren Paaren. Beim Abrufen der relevantesten Proben verwendet ReMoDiffuse die Formel
und Aktionsmerkmale . Diese beiden dienen zusammen mit den aus der Texteingabe des Benutzers extrahierten Merkmalen als Eingabesignale für die Diffusionsphase, um die Aktionsgenerierung zu steuern.
Abbildung 2: Abrufphase von ReMoDiffuse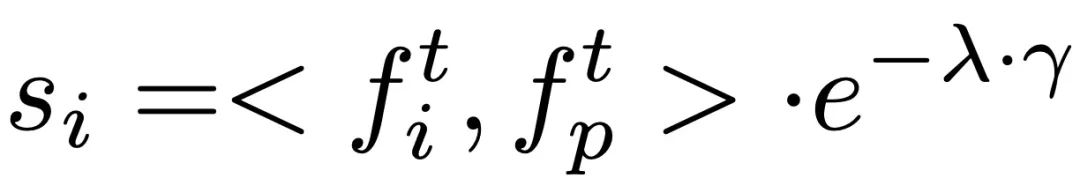
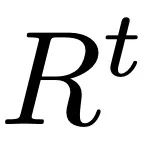
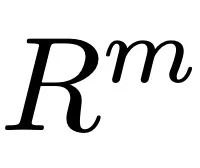

Der Diffusionsprozess (Abbildung 3.c) besteht aus zwei Teilen: dem Vorwärtsprozess und dem Rückwärtsprozess. Im Vorwärtsprozess fügt ReMoDiffuse den ursprünglichen Bewegungsdaten nach und nach Gaußsches Rauschen hinzu und wandelt es schließlich in zufälliges Rauschen um. Der umgekehrte Prozess konzentriert sich auf die Entfernung von Rauschen und die Erzeugung realistischer Bewegungsmuster. Ausgehend von einem zufälligen Gaußschen Rauschen verwendet ReMoDiffuse bei jedem Schritt des inversen Prozesses ein Semantic Modulation Module (SMT) (Abbildung 3.a), um die wahre Verteilung zu schätzen und das Rauschen basierend auf dem bedingten Signal schrittweise zu entfernen. Das SMA-Modul in SMT integriert hier alle Zustandsinformationen in die generierten Sequenzfunktionen. Dies ist das in diesem Artikel vorgeschlagene Kernmodul. Abbildung 3.b) verwenden wir den effizienten Aufmerksamkeitsmechanismus (Efficient Attention) [3], um die Berechnung des Aufmerksamkeitsmoduls zu beschleunigen und eine globale Feature-Map zu erstellen, die globale Informationen stärker hervorhebt. Diese Feature-Map liefert umfassendere semantische Hinweise für Aktionssequenzen und verbessert dadurch die Leistung des Modells. Das Hauptziel der SMA-Schicht besteht darin, die Generierung von Aktionssequenzen
durch die Aggregation von Zustandsinformationen zu optimieren. In diesem Rahmen:1.Q-Vektor stellt speziell die erwartete Aktionssequenz dar , die wir basierend auf bedingten Informationen voraussichtlich generieren werden. Der 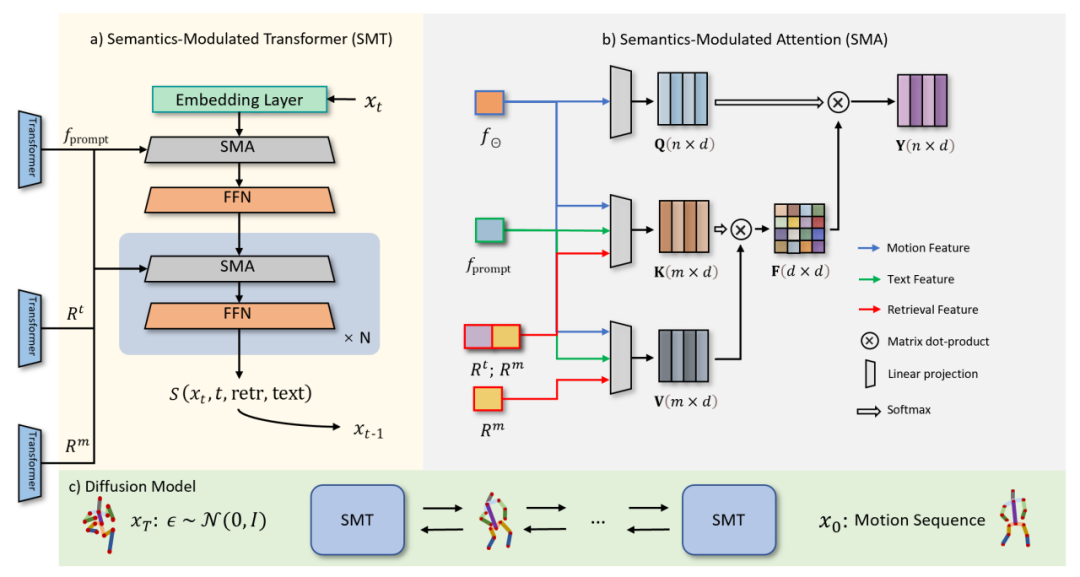 2.K-Vektor dient als Indexierungsmechanismus, der mehrere Faktoren umfassend berücksichtigt, einschließlich aktueller Aktionssequenzmerkmale , semantischer Merkmale von Benutzereingaben sowie Merkmale und , die aus Abrufproben gewonnen wurden. Unter diesen stellt die Aktionssequenzmerkmale dar, die aus den Abrufproben erhalten wurden, und
2.K-Vektor dient als Indexierungsmechanismus, der mehrere Faktoren umfassend berücksichtigt, einschließlich aktueller Aktionssequenzmerkmale , semantischer Merkmale von Benutzereingaben sowie Merkmale und , die aus Abrufproben gewonnen wurden. Unter diesen stellt die Aktionssequenzmerkmale dar, die aus den Abrufproben erhalten wurden, und
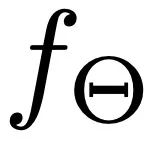 3.V-Vektor stellt die tatsächlichen Funktionen bereit, die zum Generieren der Aktion erforderlich sind. Ähnlich wie der K-Vektor berücksichtigt der V-Vektor das Abrufmuster, Benutzereingaben und die aktuelle Aktionssequenz. Da keine direkte Korrelation zwischen der Textbeschreibungsfunktion des abgerufenen Beispiels und der generierten Aktion besteht, entscheiden wir uns, diese Funktion bei der Berechnung des V-Vektors nicht zu verwenden, um unnötige Informationsinterferenzen zu vermeiden
3.V-Vektor stellt die tatsächlichen Funktionen bereit, die zum Generieren der Aktion erforderlich sind. Ähnlich wie der K-Vektor berücksichtigt der V-Vektor das Abrufmuster, Benutzereingaben und die aktuelle Aktionssequenz. Da keine direkte Korrelation zwischen der Textbeschreibungsfunktion des abgerufenen Beispiels und der generierten Aktion besteht, entscheiden wir uns, diese Funktion bei der Berechnung des V-Vektors nicht zu verwenden, um unnötige Informationsinterferenzen zu vermeiden
In Kombination mit dem globalen Aufmerksamkeitsvorlagenmechanismus von Efficient Attention verwendet die SMA-Schicht die Hilfsinformationen aus dem Abrufbeispiel, die semantischen Informationen des Benutzertexts und die Merkmalsinformationen der zu entrauschenden Sequenz, um eine Reihe umfassender globaler Vorlagen zu erstellen , sodass alle Zustandsinformationen vollständig von der zu generierenden Sequenz aufgenommen werden können.
Um den Inhalt neu zu schreiben, muss der Originaltext ins Chinesische umgewandelt werden. So sieht es nach dem Umschreiben aus: Forschungsdesign und experimentelle Ergebnisse
Wir haben ReMoDiffuse anhand von zwei Datensätzen evaluiert: HumanML3D [4] und KIT-ML [5]. Die experimentellen Ergebnisse (Tabellen 1 und 2) zeigen die leistungsstarke Leistung und die Vorteile unseres vorgeschlagenen ReMoDiffuse-Frameworks aus der Perspektive der Textkonsistenz und Aktionsqualität. Tabelle 1. Leistung verschiedener Methoden auf dem HumanML3D-Testsatz
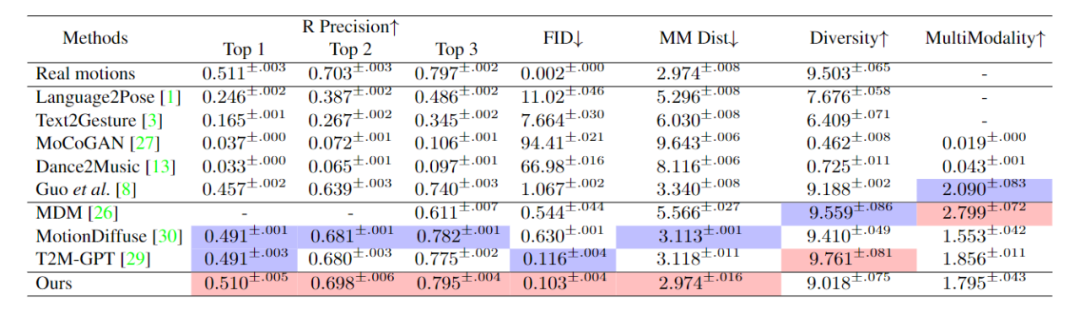 Tabelle 2. Leistung verschiedener Methoden auf dem KIT-ML-Testsatz
Tabelle 2. Leistung verschiedener Methoden auf dem KIT-ML-Testsatz
Im Folgenden finden Sie einige Beispiele, die die leistungsstarke Leistung von ReMoDiffuse zeigen (Abbildung 4). Im Vergleich zu früheren Methoden ist beispielsweise bei dem Text „Eine Person springt im Kreis“ nur ReMoDiffuse in der Lage, die „Sprung“-Bewegung und den „Kreis“-Pfad genau zu erfassen. Dies zeigt, dass ReMoDiffuse in der Lage ist, Textdetails effektiv zu erfassen und Inhalte an vorgegebene Bewegungsdauern anzupassen stellte die entsprechenden Aktionssequenzen dar, die mit der Methode von Guo et al. [4], MotionDiffuse [1], MDM [6] und ReMoDiffuse generiert wurden, und sammelte die Meinungen der Testteilnehmer in Form eines Fragebogens. Die Verteilung der Ergebnisse ist in Abbildung 5 dargestellt. Aus den Ergebnissen geht deutlich hervor, dass die Testteilnehmer in den meisten Fällen der Meinung sind, dass die von unserer Methode generierte Aktionssequenz – also die von ReMoDiffuse generierte Aktionssequenz – unter den vier Algorithmen am besten mit der gegebenen Textbeschreibung übereinstimmt ist auch am natürlichsten und geschmeidigsten. Abbildung 5: Verteilung der Benutzerbefragungsergebnisse Motiondiffuse: Textgesteuerte Erzeugung menschlicher Bewegungen basierend auf Diffusionsmodellen. arXiv-Vorabdruck arXiv:2208.15001, 2022 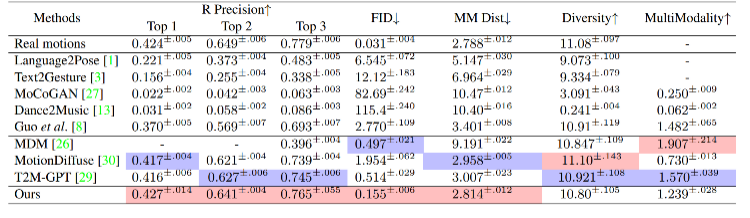 [2] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Lernen übertragbar Visuelle Modelle aus der Überwachung natürlicher Sprache. arXiv:2103.00020, 2021.
[2] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Lernen übertragbar Visuelle Modelle aus der Überwachung natürlicher Sprache. arXiv:2103.00020, 2021.
[4] Chuan Guo, Shihao Zou, Xinxin Zuo, Sen Wang, Wei Ji, Xingyu Li und Li Cheng Generieren vielfältiger und natürliche 3D-Bewegungen des Menschen aus Text. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seiten 5152–5161, 2022. Der Inhalt, der neu geschrieben werden muss, ist: [5] Matthias Plappert, Christian Mandery und Tamim Asfour. „Motorsprachlicher Datensatz“. Big Data, 4(4):236-252, 2016 [6] Guy Tevet, Sigal Raab, Brian Gordon, Yonatan Shafir, Daniel Cohen-Or und Amit H. Bermano. In The Eleventh Internationale Konferenz über lernende Repräsentationen, 2022.
Der Inhalt, der neu geschrieben werden muss, ist: [5] Matthias Plappert, Christian Mandery und Tamim Asfour. „Motorsprachlicher Datensatz“. Big Data, 4(4):236-252, 2016 [6] Guy Tevet, Sigal Raab, Brian Gordon, Yonatan Shafir, Daniel Cohen-Or und Amit H. Bermano. In The Eleventh Internationale Konferenz über lernende Repräsentationen, 2022.
Das obige ist der detaillierte Inhalt vonICCV 2023 |. ReMoDiffuse, ein neues Paradigma, das die Generierung menschlicher Handlungen neu gestaltet und Diffusionsmodelle und Abrufstrategien integriert, ist da. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 Ein Diffusionsmodell-Tutorial, das Ihre Zeit wert ist, von der Purdue University
Apr 07, 2024 am 09:01 AM
Ein Diffusionsmodell-Tutorial, das Ihre Zeit wert ist, von der Purdue University
Apr 07, 2024 am 09:01 AM
Diffusion kann nicht nur besser imitieren, sondern auch „erschaffen“. Das Diffusionsmodell (DiffusionModel) ist ein Bilderzeugungsmodell. Im Vergleich zu bekannten Algorithmen wie GAN und VAE im Bereich der KI verfolgt das Diffusionsmodell einen anderen Ansatz. Seine Hauptidee besteht darin, dem Bild zunächst Rauschen hinzuzufügen und es dann schrittweise zu entrauschen. Das Entrauschen und Wiederherstellen des Originalbilds ist der Kernbestandteil des Algorithmus. Der endgültige Algorithmus ist in der Lage, aus einem zufälligen verrauschten Bild ein Bild zu erzeugen. In den letzten Jahren hat das phänomenale Wachstum der generativen KI viele spannende Anwendungen in der Text-zu-Bild-Generierung, Videogenerierung und mehr ermöglicht. Das Grundprinzip dieser generativen Werkzeuge ist das Konzept der Diffusion, ein spezieller Sampling-Mechanismus, der die Einschränkungen bisheriger Methoden überwindet.
 Generieren Sie PPT mit einem Klick! Kimi: Lassen Sie zuerst die „PPT-Wanderarbeiter' populär werden
Aug 01, 2024 pm 03:28 PM
Generieren Sie PPT mit einem Klick! Kimi: Lassen Sie zuerst die „PPT-Wanderarbeiter' populär werden
Aug 01, 2024 pm 03:28 PM
Kimi: In nur einem Satz, in nur zehn Sekunden ist ein PPT fertig. PPT ist so nervig! Um ein Meeting abzuhalten, benötigen Sie einen PPT; um einen wöchentlichen Bericht zu schreiben, müssen Sie einen PPT vorlegen, auch wenn Sie jemanden des Betrugs beschuldigen PPT. Das College ähnelt eher dem Studium eines PPT-Hauptfachs. Man schaut sich PPT im Unterricht an und macht PPT nach dem Unterricht. Als Dennis Austin vor 37 Jahren PPT erfand, hatte er vielleicht nicht damit gerechnet, dass PPT eines Tages so weit verbreitet sein würde. Wenn wir über unsere harte Erfahrung bei der Erstellung von PPT sprechen, treiben uns Tränen in die Augen. „Es dauerte drei Monate, ein PPT mit mehr als 20 Seiten zu erstellen, und ich habe es Dutzende Male überarbeitet. Als ich das PPT sah, musste ich mich übergeben.“ war PPT.“ Wenn Sie ein spontanes Meeting haben, sollten Sie es tun
 Alle CVPR 2024-Auszeichnungen bekannt gegeben! Fast 10.000 Menschen nahmen offline an der Konferenz teil und ein chinesischer Forscher von Google gewann den Preis für den besten Beitrag
Jun 20, 2024 pm 05:43 PM
Alle CVPR 2024-Auszeichnungen bekannt gegeben! Fast 10.000 Menschen nahmen offline an der Konferenz teil und ein chinesischer Forscher von Google gewann den Preis für den besten Beitrag
Jun 20, 2024 pm 05:43 PM
Am frühen Morgen des 20. Juni (Pekinger Zeit) gab CVPR2024, die wichtigste internationale Computer-Vision-Konferenz in Seattle, offiziell die besten Beiträge und andere Auszeichnungen bekannt. In diesem Jahr wurden insgesamt 10 Arbeiten ausgezeichnet, darunter zwei beste Arbeiten und zwei beste studentische Arbeiten. Darüber hinaus gab es zwei Nominierungen für die beste Arbeit und vier Nominierungen für die beste studentische Arbeit. Die Top-Konferenz im Bereich Computer Vision (CV) ist die CVPR, die jedes Jahr zahlreiche Forschungseinrichtungen und Universitäten anzieht. Laut Statistik wurden in diesem Jahr insgesamt 11.532 Arbeiten eingereicht, von denen 2.719 angenommen wurden, was einer Annahmequote von 23,6 % entspricht. Laut der statistischen Analyse der CVPR2024-Daten des Georgia Institute of Technology befassen sich die meisten Arbeiten aus Sicht der Forschungsthemen mit der Bild- und Videosynthese und -generierung (Imageandvideosyn
 Fünf Programmiersoftware für den Einstieg in das Erlernen der C-Sprache
Feb 19, 2024 pm 04:51 PM
Fünf Programmiersoftware für den Einstieg in das Erlernen der C-Sprache
Feb 19, 2024 pm 04:51 PM
Als weit verbreitete Programmiersprache ist die C-Sprache eine der grundlegenden Sprachen, die für diejenigen erlernt werden müssen, die sich mit Computerprogrammierung befassen möchten. Für Anfänger kann das Erlernen einer neuen Programmiersprache jedoch etwas schwierig sein, insbesondere aufgrund des Mangels an entsprechenden Lernwerkzeugen und Lehrmaterialien. In diesem Artikel werde ich fünf Programmiersoftware vorstellen, die Anfängern den Einstieg in die C-Sprache erleichtert und Ihnen einen schnellen Einstieg ermöglicht. Die erste Programmiersoftware war Code::Blocks. Code::Blocks ist eine kostenlose integrierte Open-Source-Entwicklungsumgebung (IDE) für
 Von Bare-Metal bis hin zu einem großen Modell mit 70 Milliarden Parametern finden Sie hier ein Tutorial und gebrauchsfertige Skripte
Jul 24, 2024 pm 08:13 PM
Von Bare-Metal bis hin zu einem großen Modell mit 70 Milliarden Parametern finden Sie hier ein Tutorial und gebrauchsfertige Skripte
Jul 24, 2024 pm 08:13 PM
Wir wissen, dass LLM auf großen Computerclustern unter Verwendung umfangreicher Daten trainiert wird. Auf dieser Website wurden viele Methoden und Technologien vorgestellt, die den LLM-Trainingsprozess unterstützen und verbessern. Was wir heute teilen möchten, ist ein Artikel, der tief in die zugrunde liegende Technologie eintaucht und vorstellt, wie man einen Haufen „Bare-Metals“ ohne Betriebssystem in einen Computercluster für das LLM-Training verwandelt. Dieser Artikel stammt von Imbue, einem KI-Startup, das allgemeine Intelligenz durch das Verständnis der Denkweise von Maschinen erreichen möchte. Natürlich ist es kein einfacher Prozess, einen Haufen „Bare Metal“ ohne Betriebssystem in einen Computercluster für das Training von LLM zu verwandeln, aber Imbue hat schließlich erfolgreich ein LLM mit 70 Milliarden Parametern trainiert der Prozess akkumuliert
 PyCharm Community Edition-Installationsanleitung: Beherrschen Sie schnell alle Schritte
Jan 27, 2024 am 09:10 AM
PyCharm Community Edition-Installationsanleitung: Beherrschen Sie schnell alle Schritte
Jan 27, 2024 am 09:10 AM
Schnellstart mit PyCharm Community Edition: Detailliertes Installations-Tutorial, vollständige Analyse Einführung: PyCharm ist eine leistungsstarke integrierte Python-Entwicklungsumgebung (IDE), die einen umfassenden Satz an Tools bereitstellt, mit denen Entwickler Python-Code effizienter schreiben können. In diesem Artikel wird die Installation der PyCharm Community Edition im Detail vorgestellt und spezifische Codebeispiele bereitgestellt, um Anfängern den schnellen Einstieg zu erleichtern. Schritt 1: PyCharm Community Edition herunterladen und installieren Um PyCharm verwenden zu können, müssen Sie es zunächst von der offiziellen Website herunterladen
 KI im Einsatz |. AI hat einen Lebens-Vlog eines allein lebenden Mädchens erstellt, der innerhalb von drei Tagen Zehntausende Likes erhielt
Aug 07, 2024 pm 10:53 PM
KI im Einsatz |. AI hat einen Lebens-Vlog eines allein lebenden Mädchens erstellt, der innerhalb von drei Tagen Zehntausende Likes erhielt
Aug 07, 2024 pm 10:53 PM
Herausgeber des Machine Power Report: Yang Wen Die Welle der künstlichen Intelligenz, repräsentiert durch große Modelle und AIGC, hat unsere Lebens- und Arbeitsweise still und leise verändert, aber die meisten Menschen wissen immer noch nicht, wie sie sie nutzen sollen. Aus diesem Grund haben wir die Kolumne „KI im Einsatz“ ins Leben gerufen, um detailliert vorzustellen, wie KI durch intuitive, interessante und prägnante Anwendungsfälle für künstliche Intelligenz genutzt werden kann, und um das Denken aller anzuregen. Wir heißen Leser auch willkommen, innovative, praktische Anwendungsfälle einzureichen. Videolink: https://mp.weixin.qq.com/s/2hX_i7li3RqdE4u016yGhQ Vor kurzem wurde der Lebens-Vlog eines allein lebenden Mädchens auf Xiaohongshu populär. Eine Animation im Illustrationsstil, gepaart mit ein paar heilenden Worten, kann in nur wenigen Tagen leicht erlernt werden.
 Eine Pflichtlektüre für technische Anfänger: Analyse der Schwierigkeitsgrade von C-Sprache und Python
Mar 22, 2024 am 10:21 AM
Eine Pflichtlektüre für technische Anfänger: Analyse der Schwierigkeitsgrade von C-Sprache und Python
Mar 22, 2024 am 10:21 AM
Titel: Ein Muss für technische Anfänger: Schwierigkeitsanalyse der C-Sprache und Python, die spezifische Codebeispiele erfordert. Im heutigen digitalen Zeitalter ist Programmiertechnologie zu einer immer wichtigeren Fähigkeit geworden. Ob Sie in Bereichen wie Softwareentwicklung, Datenanalyse, künstliche Intelligenz arbeiten oder einfach nur aus Interesse Programmieren lernen möchten, die Wahl einer geeigneten Programmiersprache ist der erste Schritt. Unter vielen Programmiersprachen sind C-Sprache und Python zwei weit verbreitete Programmiersprachen, jede mit ihren eigenen Merkmalen. In diesem Artikel werden die Schwierigkeitsgrade der C-Sprache und von Python analysiert
