
 Technologie-Peripheriegeräte
KI
Deep-Learning-Herztonklassifizierung basierend auf einem logarithmischen Spektrogramm
Technologie-Peripheriegeräte
KI
Deep-Learning-Herztonklassifizierung basierend auf einem logarithmischen Spektrogramm
Deep-Learning-Herztonklassifizierung basierend auf einem logarithmischen Spektrogramm

Dieser Artikel ist sehr interessant. Er schlägt zwei Modelle zur Herzfrequenzschallklassifizierung vor, die auf dem logarithmischen Spektrogramm des Herzschallsignals basieren. Wir alle wissen, dass Spektrogramme in der Spracherkennung weit verbreitet sind. Dieses Papier verarbeitet das Herztonsignal als Sprachsignal und erzielt gute Ergebnisse. Das Herztonsignal wird in Rahmen konsistenter Länge unterteilt und seine logarithmischen Spektrogrammmerkmale werden extrahiert. Das Papier schlägt ein langes Kurzzeitgedächtnis (LSTM) vor Zwei Deep-Learning-Modelle, Convolutional Neural Network (CNN), klassifizieren Herzschlaggeräusche basierend auf extrahierten Merkmalen.
Herzgeräusch-Datensatz
Die bildgebende Diagnose umfasst kardiale Magnetresonanztomographie (MRT), CT-Scan und Myokardperfusionsbildgebung. Auch die Nachteile dieser Technologien liegen auf der Hand: hohe Anforderungen an moderne Maschinen und Fachkräfte sowie lange Diagnosezeiten.
Der in der Arbeit verwendete Datensatz ist ein öffentlicher Datensatz, der 1000 Signalproben im .wav-Format mit einer Abtastfrequenz von 8 kHz enthält. Der Datensatz ist in 5 Kategorien unterteilt, darunter 1 normale Kategorie (N) und 4 abnormale Kategorien: Aortenstenose (AS), Mitralklappeninsuffizienz (MR), Mitralklappeninsuffizienz (MS) und Mitralklappeninsuffizienz (MVP). )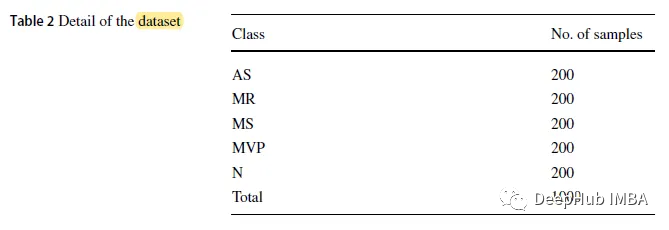
Eine Aortenstenose (AS) liegt vor, wenn die Aortenklappe zu klein, eng oder steif ist. Das typische Geräusch einer Aortenstenose ist ein hohes „rautenförmiges“ Geräusch.
Mitralinsuffizienz (MR) liegt vor, wenn die Mitralklappe des Herzens nicht richtig schließt, was dazu führt, dass Blut zurück in das Herz fließt, anstatt abgepumpt zu werden. Bei der Auskultation des fetalen Herzens kann der S1-Ton sehr leise (manchmal laut) sein, bis die Lautstärke des Herzgeräuschs um S2 zunimmt. Aufgrund des schnellen Mitralflusses nach S3 ist ein kurzes, polterndes mitteldiastolisches Geräusch zu hören
Mitralstenose (MS) bedeutet, dass die Mitralklappe beschädigt ist und sich nicht vollständig öffnen kann. Die Auskultation des Herztons zeigt, dass sich S1 bei einer frühen Mitralstenose verschlechtert und bei einer schweren Mitralstenose weicher wird. Wenn sich eine pulmonale Hypertonie entwickelt, wird der S2-Geräusch betont. Patienten mit reiner MS haben fast kein linksventrikuläres S3.
Mitralklappenprolaps (MVP) bezeichnet den Vorfall der Mitralklappensegel in den linken Vorhof während der Herzkontraktion. MVP ist normalerweise gutartig, kann jedoch Komplikationen wie Mitralinsuffizienz, Endokarditis und Nabelschnurriss verursachen. Zu den Anzeichen zählen mittelsystolische Klickgeräusche und spätsystolische Geräusche (bei vorhandener Regurgitation).
Vorverarbeitung und Merkmalsextraktion
Tonsignale haben unterschiedliche Längen, daher müssen die Samples für jede aufgezeichnete Dateirate festgelegt werden. Um sicherzustellen, dass das Tonsignal mindestens einen vollständigen Herzzyklus enthält, kürzen wir die Länge. Basierend auf der Tatsache, dass das Herz eines Erwachsenen 65–75 Mal pro Minute schlägt und der Herzschlagzyklus etwa 0,8 Sekunden beträgt, schneiden wir die Signalproben in Segmente von 2,0 Sekunden, 1,5 Sekunden und 1,0 Sekunden.
Basierend auf der Diskreten Fourier-Transformation ( DFT) werden die Herztöne aus der ursprünglichen Wellenform des Signals in ein logarithmisches Spektrogramm umgewandelt. Die DFT y(k) des Schallsignals ist Gleichung (1) und das logarithmische Spektrum s ist als Gleichung (2) definiert.
In der Formel ist N die Länge des Vektors x und ε = 10^(- 6) ein kleiner Versatz. Die Wellenformen und logarithmischen Spektrogramme einiger Herztonproben sind wie folgt: 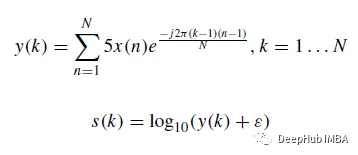
Deep-Learning-Modell
1, LSTM
Das LSTM-Modell ist mit 2 Schichten direkter Verbindung ausgestattet. und dann 3 Schichten komplett verbinden. Die dritte vollständig verbundene Schicht gibt den Softmax-Klassifikator ein. 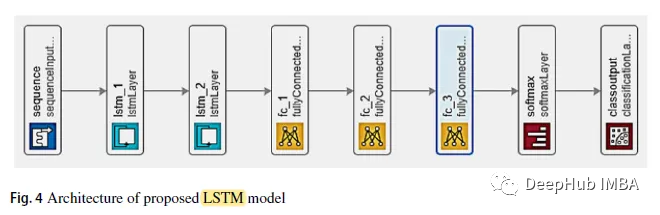
2. CNN-Modell
Wie in der Abbildung oben gezeigt, folgt auf die ersten beiden Faltungsschichten eine überlappende Maximum-Pooling-Schicht. Die dritte Faltungsschicht ist direkt mit der ersten vollständig verbundenen Schicht verbunden. Die zweite vollständig verbundene Schicht wird einem Softmax-Klassifikator mit fünf Klassenbezeichnungen zugeführt. Verwenden Sie BN und ReLU nach jeder Faltungsschicht. 3. Trainingsdetails Teil 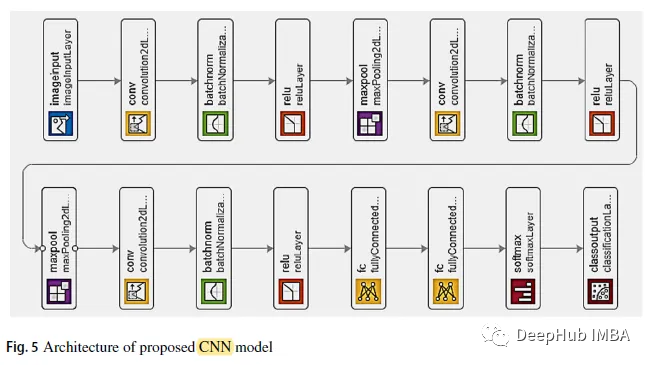
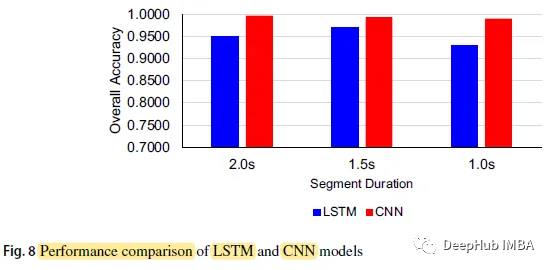
Wenn die Segmentierungsdauer des CNN-Modells 2,0 s beträgt, beträgt die höchste Genauigkeit 0,9967; bei einer Segmentierungszeit von 1,0 s beträgt die niedrigste LSTM-Genauigkeit 0,9300.
Die Gesamtgenauigkeit des CNN-Modells beträgt 0,9967, 0,9933 bzw. 0,9900, und die Segmentdauer beträgt 2,0 Sekunden, 1,5 Sekunden bzw. 1,0 Sekunden, während die drei Zahlen des LSTM-Modells jeweils 0,9500, 0,9700 und 0,9300 sind
CNN Die Vorhersagegenauigkeit des Modells in verschiedenen Zeiträumen ist höher als die des LSTM-Modells
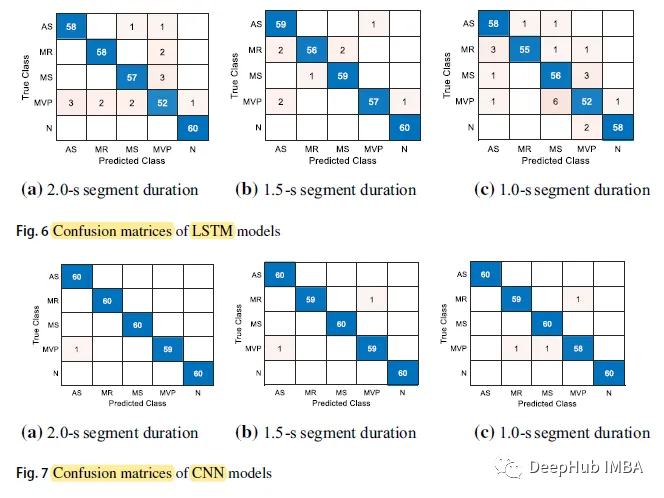
Das Folgende ist die Verwirrungsmatrix:
Die N-Klasse (Normal) hat die höchste Vorhersagegenauigkeit. In 5 Fällen erreichte er 60, während die MVP-Klasse von allen Fällen die niedrigste Vorhersagegenauigkeit aufweist.
Die Eingabezeitlänge des LSTM-Modells beträgt 2,0 s und die längste Vorhersagezeit beträgt 9,8631 ms. Das CNN-Modell mit einer Klassifizierungszeit von 1,0 s hat die kürzeste Vorhersagezeit, nämlich 4,2686 ms.
Im Vergleich zu anderen SOTA weisen einige Studien eine sehr hohe Genauigkeit auf, aber diese Studien umfassen nur zwei Kategorien (normal und abnormal), während unsere Studie in fünf Kategorien unterteilt ist
im Vergleich zu anderen Studien mit Mit demselben Datensatz (0,9700) hat sich die Papierstudie erheblich verbessert, mit der höchsten Genauigkeit von 0,9967.

Das obige ist der detaillierte Inhalt vonDeep-Learning-Herztonklassifizierung basierend auf einem logarithmischen Spektrogramm. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1382
1382
 52
52

 Methoden und Schritte zur Verwendung von BERT für die Stimmungsanalyse in Python
Jan 22, 2024 pm 04:24 PM
Methoden und Schritte zur Verwendung von BERT für die Stimmungsanalyse in Python
Jan 22, 2024 pm 04:24 PM
BERT ist ein vorab trainiertes Deep-Learning-Sprachmodell, das 2018 von Google vorgeschlagen wurde. Der vollständige Name lautet BidirektionalEncoderRepresentationsfromTransformers, der auf der Transformer-Architektur basiert und die Eigenschaften einer bidirektionalen Codierung aufweist. Im Vergleich zu herkömmlichen Einweg-Codierungsmodellen kann BERT bei der Textverarbeitung gleichzeitig Kontextinformationen berücksichtigen, sodass es bei Verarbeitungsaufgaben in natürlicher Sprache eine gute Leistung erbringt. Seine Bidirektionalität ermöglicht es BERT, die semantischen Beziehungen in Sätzen besser zu verstehen und dadurch die Ausdrucksfähigkeit des Modells zu verbessern. Durch Vorschulungs- und Feinabstimmungsmethoden kann BERT für verschiedene Aufgaben der Verarbeitung natürlicher Sprache verwendet werden, wie z. B. Stimmungsanalyse und Benennung
 Analyse häufig verwendeter KI-Aktivierungsfunktionen: Deep-Learning-Praxis von Sigmoid, Tanh, ReLU und Softmax
Dec 28, 2023 pm 11:35 PM
Analyse häufig verwendeter KI-Aktivierungsfunktionen: Deep-Learning-Praxis von Sigmoid, Tanh, ReLU und Softmax
Dec 28, 2023 pm 11:35 PM
Aktivierungsfunktionen spielen beim Deep Learning eine entscheidende Rolle. Sie können nichtlineare Eigenschaften in neuronale Netze einführen und es dem Netz ermöglichen, komplexe Eingabe-Ausgabe-Beziehungen besser zu lernen und zu simulieren. Die richtige Auswahl und Verwendung von Aktivierungsfunktionen hat einen wichtigen Einfluss auf die Leistung und Trainingsergebnisse neuronaler Netze. In diesem Artikel werden vier häufig verwendete Aktivierungsfunktionen vorgestellt: Sigmoid, Tanh, ReLU und Softmax. Beginnend mit der Einführung, den Verwendungsszenarien und den Vorteilen. Nachteile und Optimierungslösungen werden besprochen, um Ihnen ein umfassendes Verständnis der Aktivierungsfunktionen zu vermitteln. 1. Sigmoid-Funktion Einführung in die Sigmoid-Funktionsformel: Die Sigmoid-Funktion ist eine häufig verwendete nichtlineare Funktion, die jede reelle Zahl auf Werte zwischen 0 und 1 abbilden kann. Es wird normalerweise verwendet, um das zu vereinheitlichen
 Jenseits von ORB-SLAM3! SL-SLAM: Szenen mit wenig Licht, starkem Jitter und schwacher Textur werden verarbeitet
May 30, 2024 am 09:35 AM
Jenseits von ORB-SLAM3! SL-SLAM: Szenen mit wenig Licht, starkem Jitter und schwacher Textur werden verarbeitet
May 30, 2024 am 09:35 AM
Heute diskutieren wir darüber, wie Deep-Learning-Technologie die Leistung von visionbasiertem SLAM (Simultaneous Localization and Mapping) in komplexen Umgebungen verbessern kann. Durch die Kombination von Methoden zur Tiefenmerkmalsextraktion und Tiefenanpassung stellen wir hier ein vielseitiges hybrides visuelles SLAM-System vor, das die Anpassung in anspruchsvollen Szenarien wie schlechten Lichtverhältnissen, dynamischer Beleuchtung, schwach strukturierten Bereichen und starkem Jitter verbessern soll. Unser System unterstützt mehrere Modi, einschließlich erweiterter Monokular-, Stereo-, Monokular-Trägheits- und Stereo-Trägheitskonfigurationen. Darüber hinaus wird analysiert, wie visuelles SLAM mit Deep-Learning-Methoden kombiniert werden kann, um andere Forschungen zu inspirieren. Durch umfangreiche Experimente mit öffentlichen Datensätzen und selbst abgetasteten Daten demonstrieren wir die Überlegenheit von SL-SLAM in Bezug auf Positionierungsgenauigkeit und Tracking-Robustheit.
 Latente Raumeinbettung: Erklärung und Demonstration
Jan 22, 2024 pm 05:30 PM
Latente Raumeinbettung: Erklärung und Demonstration
Jan 22, 2024 pm 05:30 PM
Latent Space Embedding (LatentSpaceEmbedding) ist der Prozess der Abbildung hochdimensionaler Daten auf niedrigdimensionalen Raum. Im Bereich des maschinellen Lernens und des tiefen Lernens handelt es sich bei der Einbettung latenter Räume normalerweise um ein neuronales Netzwerkmodell, das hochdimensionale Eingabedaten in einen Satz niedrigdimensionaler Vektordarstellungen abbildet. Dieser Satz von Vektoren wird oft als „latente Vektoren“ oder „latent“ bezeichnet Kodierungen". Der Zweck der Einbettung latenter Räume besteht darin, wichtige Merkmale in den Daten zu erfassen und sie in einer prägnanteren und verständlicheren Form darzustellen. Durch die Einbettung latenter Räume können wir Vorgänge wie das Visualisieren, Klassifizieren und Clustern von Daten im niedrigdimensionalen Raum durchführen, um die Daten besser zu verstehen und zu nutzen. Die Einbettung latenter Räume findet in vielen Bereichen breite Anwendung, z. B. bei der Bilderzeugung, der Merkmalsextraktion, der Dimensionsreduzierung usw. Die Einbettung des latenten Raums ist das Wichtigste
 Verstehen Sie in einem Artikel: die Zusammenhänge und Unterschiede zwischen KI, maschinellem Lernen und Deep Learning
Mar 02, 2024 am 11:19 AM
Verstehen Sie in einem Artikel: die Zusammenhänge und Unterschiede zwischen KI, maschinellem Lernen und Deep Learning
Mar 02, 2024 am 11:19 AM
In der heutigen Welle rasanter technologischer Veränderungen sind künstliche Intelligenz (KI), maschinelles Lernen (ML) und Deep Learning (DL) wie helle Sterne und führen die neue Welle der Informationstechnologie an. Diese drei Wörter tauchen häufig in verschiedenen hochaktuellen Diskussionen und praktischen Anwendungen auf, aber für viele Entdecker, die neu auf diesem Gebiet sind, sind ihre spezifische Bedeutung und ihre internen Zusammenhänge möglicherweise noch immer rätselhaft. Schauen wir uns also zunächst dieses Bild an. Es ist ersichtlich, dass zwischen Deep Learning, maschinellem Lernen und künstlicher Intelligenz ein enger Zusammenhang und eine fortschreitende Beziehung besteht. Deep Learning ist ein spezifischer Bereich des maschinellen Lernens und des maschinellen Lernens
 Sehen Sie sich von den Grundlagen bis zur Praxis die Entwicklungsgeschichte des Elasticsearch-Vektorabrufs an
Oct 23, 2023 pm 05:17 PM
Sehen Sie sich von den Grundlagen bis zur Praxis die Entwicklungsgeschichte des Elasticsearch-Vektorabrufs an
Oct 23, 2023 pm 05:17 PM
1. Einleitung Die Vektorabfrage ist zu einem Kernbestandteil moderner Such- und Empfehlungssysteme geworden. Es ermöglicht einen effizienten Abfrageabgleich und Empfehlungen, indem es komplexe Objekte (wie Text, Bilder oder Töne) in numerische Vektoren umwandelt und Ähnlichkeitssuchen in mehrdimensionalen Räumen durchführt. Schauen Sie sich von den Grundlagen bis zur Praxis die Entwicklungsgeschichte von Elasticsearch Vector Retrieval_elasticsearch an. Als beliebte Open-Source-Suchmaschine hat die Entwicklung von Elasticsearch im Bereich Vektor Retrieval schon immer große Aufmerksamkeit erregt. In diesem Artikel wird die Entwicklungsgeschichte des Elasticsearch-Vektorabrufs untersucht, wobei der Schwerpunkt auf den Merkmalen und dem Fortschritt jeder Phase liegt. Wenn Sie sich an der Geschichte orientieren, ist es für jeden praktisch, eine umfassende Palette zum Abrufen von Elasticsearch-Vektoren einzurichten.
 Super stark! Top 10 Deep-Learning-Algorithmen!
Mar 15, 2024 pm 03:46 PM
Super stark! Top 10 Deep-Learning-Algorithmen!
Mar 15, 2024 pm 03:46 PM
Fast 20 Jahre sind vergangen, seit das Konzept des Deep Learning im Jahr 2006 vorgeschlagen wurde. Deep Learning hat als Revolution auf dem Gebiet der künstlichen Intelligenz viele einflussreiche Algorithmen hervorgebracht. Was sind Ihrer Meinung nach die zehn besten Algorithmen für Deep Learning? Im Folgenden sind meiner Meinung nach die besten Algorithmen für Deep Learning aufgeführt. Sie alle nehmen hinsichtlich Innovation, Anwendungswert und Einfluss eine wichtige Position ein. 1. Hintergrund des Deep Neural Network (DNN): Deep Neural Network (DNN), auch Multi-Layer-Perceptron genannt, ist der am weitesten verbreitete Deep-Learning-Algorithmus. Als er erstmals erfunden wurde, wurde er aufgrund des Engpasses bei der Rechenleistung in Frage gestellt Jahre, Rechenleistung, Der Durchbruch kam mit der Datenexplosion. DNN ist ein neuronales Netzwerkmodell, das mehrere verborgene Schichten enthält. In diesem Modell übergibt jede Schicht Eingaben an die nächste Schicht und
 AlphaFold 3 wird auf den Markt gebracht und sagt die Wechselwirkungen und Strukturen von Proteinen und allen Lebensmolekülen umfassend und mit weitaus größerer Genauigkeit als je zuvor voraus
Jul 16, 2024 am 12:08 AM
AlphaFold 3 wird auf den Markt gebracht und sagt die Wechselwirkungen und Strukturen von Proteinen und allen Lebensmolekülen umfassend und mit weitaus größerer Genauigkeit als je zuvor voraus
Jul 16, 2024 am 12:08 AM
Herausgeber | Rettichhaut Seit der Veröffentlichung des leistungsstarken AlphaFold2 im Jahr 2021 verwenden Wissenschaftler Modelle zur Proteinstrukturvorhersage, um verschiedene Proteinstrukturen innerhalb von Zellen zu kartieren, Medikamente zu entdecken und eine „kosmische Karte“ jeder bekannten Proteininteraktion zu zeichnen. Gerade hat Google DeepMind das AlphaFold3-Modell veröffentlicht, das gemeinsame Strukturvorhersagen für Komplexe wie Proteine, Nukleinsäuren, kleine Moleküle, Ionen und modifizierte Reste durchführen kann. Die Genauigkeit von AlphaFold3 wurde im Vergleich zu vielen dedizierten Tools in der Vergangenheit (Protein-Ligand-Interaktion, Protein-Nukleinsäure-Interaktion, Antikörper-Antigen-Vorhersage) deutlich verbessert. Dies zeigt, dass dies innerhalb eines einzigen einheitlichen Deep-Learning-Frameworks möglich ist
