Groß angelegte Sprachmodelle haben überraschende Denkfähigkeiten bei der Verarbeitung natürlicher Sprache gezeigt, ihre zugrunde liegenden Mechanismen sind jedoch noch nicht klar. Angesichts der weit verbreiteten Anwendung umfangreicher Sprachmodelle ist die Aufklärung des Funktionsmechanismus des Modells von entscheidender Bedeutung für die Anwendungssicherheit, Leistungseinschränkungen und kontrollierbare soziale Auswirkungen. Vor kurzem haben viele Forschungseinrichtungen in China und den Vereinigten Staaten (New Jersey Institute of Technology, Johns Hopkins University, Wake Forest University, University of Georgia, Shanghai Jiao Tong University, Baidu usw.) gemeinsam die Interpretierbarkeit großer Modelle veröffentlicht Technologie Dieser Aufsatz gibt einen umfassenden Überblick über die Interpretierbarkeitstechnologien traditioneller Feinabstimmungsmodelle und auf Eingabeaufforderungen basierender sehr großer Modelle und erörtert die Bewertungskriterien und zukünftigen Forschungsherausforderungen für die Modellinterpretation. 
- Papierlink: https://arxiv.org/abs/2309.01029
-
Github-Link: https://github.com/hy-zhao23/Explainability-for-Large-Language-Models
Was ist die Schwierigkeit bei der Interpretation großer Modelle? Warum ist es schwierig, große Modelle zu erklären? Die erstaunliche Leistung großer Sprachmodelle bei der Verarbeitung natürlicher Sprache hat in der Gesellschaft breite Aufmerksamkeit erregt. Gleichzeitig ist die Erklärung der beeindruckenden Leistung großer Modelle über verschiedene Aufgaben hinweg eine der dringendsten Herausforderungen für die Wissenschaft. Im Gegensatz zu herkömmlichen Modellen für maschinelles Lernen oder Deep Learning ermöglichen die extrem große Modellarchitektur und die umfangreichen Lernmaterialien, dass große Modelle über leistungsstarke Argumentations- und Generalisierungsfähigkeiten verfügen. Zu den großen Schwierigkeiten bei der Bereitstellung von Interpretierbarkeit für große Sprachmodelle (LLMs) gehören:
- Hohe Modellkomplexität. Anders als Deep-Learning-Modelle oder traditionelle Modelle des statistischen maschinellen Lernens vor der LLM-Ära sind LLM-Modelle riesig und enthalten Milliarden von Parametern. Ihre internen Darstellungs- und Argumentationsprozesse sind sehr komplex, und es ist schwierig, ihre spezifischen Ergebnisse zu erklären.
- Starke Datenabhängigkeit. LLMs stützen sich während des Trainingsprozesses auf einen umfangreichen Textkorpus. Verzerrungen, Fehler usw. in diesen Trainingsdaten können sich auf das Modell auswirken, es ist jedoch schwierig, die Auswirkungen der Qualität der Trainingsdaten auf das Modell vollständig zu beurteilen.
- Black-Box-Natur. Wir betrachten LLMs normalerweise als Black-Box-Modelle, selbst für Open-Source-Modelle wie Llama-2. Es fällt uns schwer, die interne Argumentationskette und den Entscheidungsprozess explizit zu beurteilen. Wir können sie nur auf der Grundlage von Input und Output analysieren, was die Interpretierbarkeit erschwert.
- Ausgabeunsicherheit. Die Ausgabe von LLMs ist häufig unsicher und es können unterschiedliche Ausgaben für dieselbe Eingabe erzeugt werden, was ebenfalls die Schwierigkeit der Interpretierbarkeit erhöht.
- Unzureichende Bewertungsindikatoren. Die aktuellen automatischen Bewertungsindikatoren von Dialogsystemen reichen nicht aus, um die Interpretierbarkeit des Modells vollständig widerzuspiegeln, und es werden mehr Bewertungsindikatoren benötigt, die das menschliche Verständnis berücksichtigen.
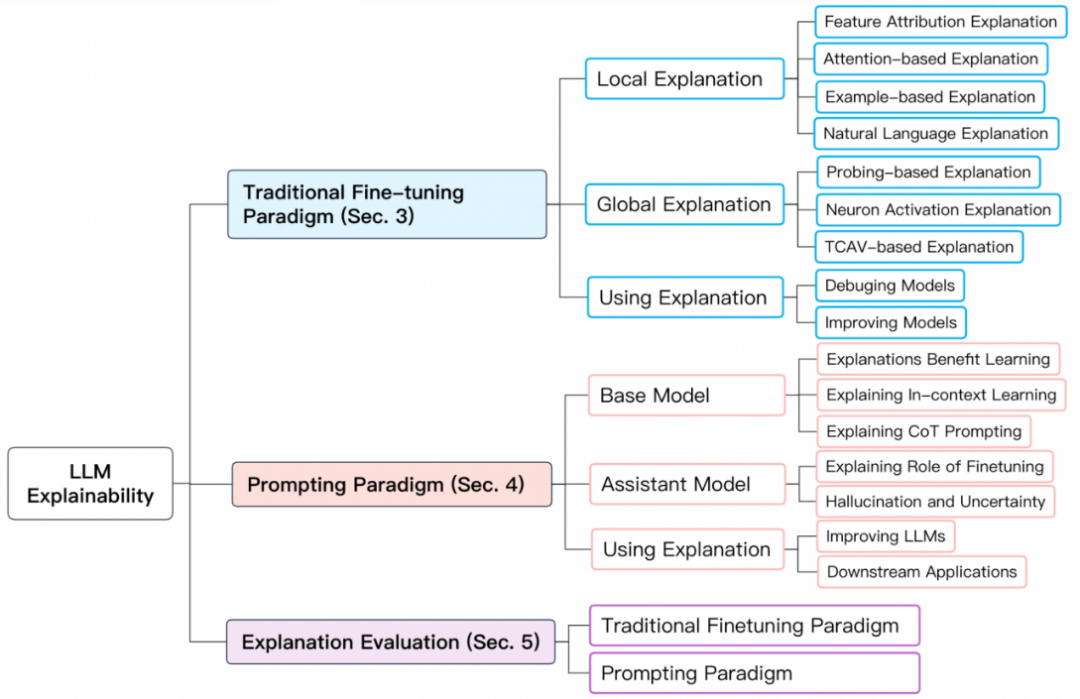
Trainingsparadigma großer ModelleUm die Interpretierbarkeit großer Modelle besser zusammenzufassen, unterteilen wir die Trainingsparadigmen großer Modelle auf BERT- und höheren Ebenen in zwei Typen: 1 ) Traditionelles Feinabstimmungsparadigma; 2) Aufforderungsbasiertes Paradigma. Traditionelles Feinabstimmungsparadigma Für das traditionelle Feinabstimmungsparadigma trainieren Sie zunächst ein grundlegendes Sprachmodell in einer größeren unbeschrifteten Textbibliothek vor und verwenden es dann aus einer bestimmten Domäne Führen Sie eine Feinabstimmung des gekennzeichneten Datensatzes durch. Zu den gängigen Modellen gehören BERT, RoBERTa, ELECTRA, DeBERTa usw. Aufforderungsbasiertes ParadigmaAufforderungsbasiertes Paradigma ermöglicht Zero-Shot- oder Fence-Shot-Lernen durch die Verwendung von Eingabeaufforderungen. Wie beim traditionellen Feinabstimmungsparadigma muss das Basismodell vorab trainiert werden. Die Feinabstimmung auf der Grundlage des Prompting-Paradigmas wird jedoch normalerweise durch Instruktionsoptimierung und Reinforcement Learning from Human Feedback (RLHF) umgesetzt. Zu den gängigen Modellen gehören GPT-3.5, GPT 4, Claude, LLaMA-2-Chat, Alpaca, Vicuna usw. Der Trainingsablauf ist wie folgt:
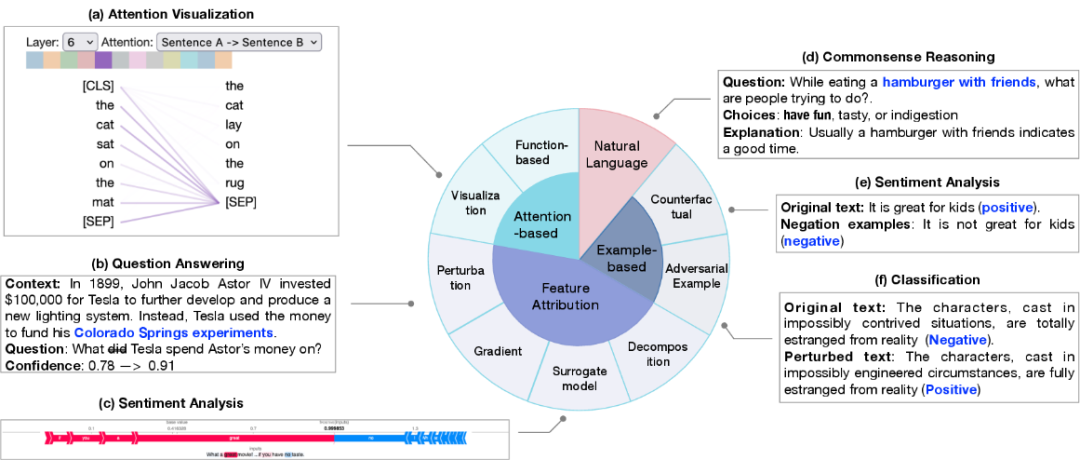
Modellerklärung basierend auf dem traditionellen FeinabstimmungsparadigmaDie Modellerklärung basierend auf dem traditionellen Feinabstimmungsparadigma umfasst die Erklärung einzelner Vorhersagen (lokale Erklärung) und Komponenten auf Strukturebene des Modells wie Neuronen, Netzwerkschichten usw . Erklärung (globale Erklärung). Lokale Erklärung erklärt eine einzelne Stichprobenvorhersage. Zu den Erklärungsmethoden gehören Merkmalszuordnung, aufmerksamkeitsbasierte Erklärung, beispielbasierte Erklärung und Erklärung in natürlicher Sprache.
1. Der Zweck der Merkmalszuordnung besteht darin, die Korrelation zwischen jedem Eingabemerkmal (z. B. Wort, Phrase, Textbereich) und der Modellvorhersage zu messen. Merkmalszuordnungsmethoden können unterteilt werden in:
Basierend auf Störungsinterpretation, Beobachtung der Auswirkung auf das Ausgabeergebnis durch Modifizieren spezifischer Eingabemerkmale
Basierend auf Gradienteninterpretation wird die partielle Differenz zwischen Ausgabe und Eingabe verwendet die entsprechende Eingabe Der Wichtigkeitsindex
Alternatives Modell verwendet ein einfaches, für den Menschen verständliches Modell, um eine einzelne Ausgabe eines komplexen Modells anzupassen, um die Wichtigkeit jeder Eingabe zu erhalten;
basiert auf Zerlegungstechnologie und zielt darauf ab, Merkmale linear zu korrelieren Zerlegung von Sex-Scores.
2. Aufmerksamkeitsbasierte Erklärung: Aufmerksamkeit wird oft verwendet, um sich auf die relevantesten Teile der Eingabe zu konzentrieren, sodass die Aufmerksamkeit relevante Informationen lernen kann, die zur Erklärung von Vorhersagen verwendet werden können. Zu den gängigen aufmerksamkeitsbezogenen Interpretationsmethoden gehören:
- Aufmerksamkeitsvisualisierungstechnologie, die Änderungen der Aufmerksamkeitswerte auf verschiedenen Skalen intuitiv beobachtet;
- Funktionsbasierte Interpretation, wie z. B. die Ausgabe der Aufmerksamkeitswirkung Partielles Differential. Allerdings bleibt die Verwendung von Aufmerksamkeit als Forschungsperspektive in der akademischen Gemeinschaft umstritten.
3. Die stichprobenbasierte Erklärung erkennt und erklärt das Modell aus der Perspektive einzelner Fälle, die hauptsächlich in kontradiktorische Stichproben und kontrafaktische Stichproben unterteilt ist.
- Gegnerische Stichproben sind Daten, die für die Eigenschaften des Modells generiert werden und bei der Verarbeitung natürlicher Sprache sehr empfindlich sind. Sie werden normalerweise durch die Änderung von Texttransformationen gewonnen, die für Menschen normalerweise schwer zu unterscheiden sind führen zu unterschiedlichen Vorhersagen des Modells.
- Kontrafaktische Stichproben werden durch Deformation des Textes wie z. B. Negation erhalten, was normalerweise ein Test der kausalen Schlussfolgerungsfähigkeit des Modells ist.
4. Die Erklärung in natürlicher Sprache verwendet Originaltext und manuell beschriftete Erklärungen für das Modelltraining, sodass das Modell Erklärungen in natürlicher Sprache für den Entscheidungsprozess des Modells generieren kann. Globale Erklärung zielt darauf ab, ein übergeordnetes Verständnis des Arbeitsmechanismus großer Modelle auf den Ebenen des Modells einschließlich Neuronen, verborgenen Schichten und größeren Blöcken zu vermitteln. Es untersucht hauptsächlich das in verschiedenen Netzwerkkomponenten erlernte semantische Wissen.
- Sondenbasierte Interpretation Die Sondeninterpretationstechnologie basiert hauptsächlich auf der Klassifikatorerkennung. Sie trainiert einen flachen Klassifikator anhand eines vorab trainierten Modells oder eines fein abgestimmten Modells und wertet ihn dann anhand eines Holdout-Datensatzes aus Klassifikatoren sind in der Lage, Sprachmerkmale oder Denkfähigkeiten zu identifizieren.
- Neuronenaktivierung Die herkömmliche Neuronenaktivierungsanalyse berücksichtigt nur einen Teil wichtiger Neuronen und lernt dann die Beziehung zwischen Neuronen und semantischen Merkmalen. In letzter Zeit wird GPT-4 auch zur Erklärung von Neuronen verwendet. Anstatt einige Neuronen zur Erklärung auszuwählen, kann GPT-4 zur Erklärung aller Neuronen verwendet werden.
- Konzeptbasierte Interpretation: Die Eingabe wird zunächst einer Reihe von Konzepten zugeordnet, und dann wird das Modell interpretiert, indem die Bedeutung der Konzepte für die Vorhersage gemessen wird. Modellerklärung basierend auf dem Prompting-Paradigma Weg. Zu den untersuchten Themen gehören hauptsächlich: die Vorteile der Bereitstellung von Erklärungen für das Modell des Wenig-Schuss-Lernens; das Verständnis der Quelle des Wenig-Schuss-Lernens und der Fähigkeiten der Denkkette.
Grundlegende Modellerklärung
Die Vorteile von Erklärungen für das Modelllernen Untersuchen Sie, ob Erklärungen für das Modelllernen beim Lernen mit wenigen Schüssen hilfreich sind. Situatives Lernen Erkunden Sie den Mechanismus des kontextuellen Lernens in großen Modellen und unterscheiden Sie den Unterschied zwischen kontextuellem Lernen in großen Modellen und mittleren Modellen.
Denkketten-Eingabeaufforderung Erkunden Sie die Gründe, warum die Denkketten-Eingabeaufforderung die Leistung des Modells verbessert.
- Erklärung des Assistentenmodells
Die Rolle von Feinabstimmungsassistentenmodellen wird in der Regel vorab trainiert, um allgemeines semantisches Wissen zu erlangen und anschließend Domänenwissen durch überwachtes Lernen und Verstärkung zu erwerben Lernen. Es bleibt zu untersuchen, aus welchem Stadium das Wissen über das Assistentenmodell hauptsächlich stammt.
Illusion und Unsicherheit Die Genauigkeit und Glaubwürdigkeit großer Modellvorhersagen sind immer noch wichtige Themen der aktuellen Forschung. Trotz der leistungsstarken Schlussfolgerungsfähigkeiten großer Modelle leiden ihre Ergebnisse häufig unter Fehlinformationen und Halluzinationen. Diese Unsicherheit bei der Vorhersage bringt große Herausforderungen für ihre weitverbreitete Anwendung mit sich.
Bewertung von Modellerklärungen
- Zu den Bewertungsindikatoren von Modellerklärungen gehören Plausibilität, Treue, Stabilität und Robustheit. Der Artikel befasst sich hauptsächlich mit zwei weit verbreiteten Dimensionen: 1) Rationalität gegenüber Menschen; 2) Treue zur internen Logik des Modells.
Die Bewertung traditioneller Feinabstimmungsmodellerklärungen konzentriert sich hauptsächlich auf lokale Erklärungen. Plausibilität erfordert oft eine messtechnische Bewertung von Modellinterpretationen im Vergleich zu von Menschen kommentierten Interpretationen anhand entworfener Standards. Fidelity legt mehr Wert auf die Leistung quantitativer Indikatoren. Da sich verschiedene Indikatoren auf unterschiedliche Aspekte des Modells oder der Daten konzentrieren, mangelt es immer noch an einheitlichen Standards zur Messung der Fidelity. Die Bewertung auf der Grundlage einer veranlassenden Modellinterpretation erfordert weitere Forschung.Zukünftige Forschungsherausforderungen 1. Mangel an gültigen und richtigen Erklärungen. Die Herausforderung ergibt sich aus zwei Aspekten: 1) dem Mangel an Standards für die Gestaltung wirksamer Erklärungen; 2) dem Mangel an wirksamen Erklärungen führt zu einem Mangel an Unterstützung für die Bewertung von Erklärungen; 2. Der Ursprung des Emergenzphänomens ist unbekannt. Die Untersuchung der Emergenzfähigkeit großer Modelle kann aus der Perspektive des Modells bzw. der Daten erfolgen: 1) der Modellstruktur, die das Emergenzphänomen verursacht, und 2) dem minimalen Modellmaßstab Komplexität, die bei sprachübergreifenden Aufgaben eine überlegene Leistung bietet. Aus Datensicht: 1) die Teilmenge der Daten, die eine spezifische Vorhersage bestimmt; 2) die Beziehung zwischen aufkommender Fähigkeit und Modelltraining und Datenkontamination; 3) die Auswirkung der Qualität und Quantität der Trainingsdaten auf die jeweiligen Auswirkungen von Pre- Training und Feinabstimmung. 3. Der Unterschied zwischen Feinabstimmungsparadigma und Aufforderungsparadigma. Die unterschiedlichen Leistungen von In-Distribution und Out-of-Distribution bedeuten unterschiedliche Argumentationsmethoden. 1) Die Unterschiede in den Argumentationsparadigmen, wenn die Daten unterschiedlich verteilt sind; 2) Die Ursachen für Unterschiede in der Modellrobustheit, wenn die Daten unterschiedlich verteilt sind. 4. Shortcut-Lernproblem für große Modelle. Unter den beiden Paradigmen besteht das Problem des Shortcut-Lernens des Modells in unterschiedlichen Aspekten. Obwohl große Modelle über reichlich Datenquellen verfügen, wird das Problem des Shortcut-Lernens relativ gemildert. Für die Verallgemeinerung des Modells ist es nach wie vor wichtig, den Bildungsmechanismus des Shortcut-Lernens aufzuklären und Lösungen vorzuschlagen. 5. Achtung Redundanz. Das Redundanzproblem von Aufmerksamkeitsmodulen ist in beiden Paradigmen weit verbreitet. Die Untersuchung der Aufmerksamkeitsredundanz kann eine Lösung für die Modellkomprimierungstechnologie bieten. 6. Sicherheit und Ethik. Die Interpretierbarkeit großer Modelle ist entscheidend für die Kontrolle des Modells und die Begrenzung der negativen Auswirkungen des Modells. Zum Beispiel Voreingenommenheit, Ungerechtigkeit, Informationsverschmutzung, soziale Manipulation und andere Probleme. Der Aufbau erklärbarer KI-Modelle kann die oben genannten Probleme effektiv vermeiden und ethische Systeme der künstlichen Intelligenz bilden. Das obige ist der detaillierte Inhalt vonAnalyse der Interpretierbarkeit großer Modelle: Ein Review bringt die Wahrheit ans Licht und beantwortet Zweifel. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!




 Was tun, wenn die CHM-Datei nicht geöffnet werden kann?
Was tun, wenn die CHM-Datei nicht geöffnet werden kann?
 WeChat-Schritte
WeChat-Schritte
 Grundlegende Verwendung von FTP
Grundlegende Verwendung von FTP
 ps ausgewählten Bereich löschen
ps ausgewählten Bereich löschen
 JS-Array-Sortierung: Methode sort()
JS-Array-Sortierung: Methode sort()
 Was bedeutet URL?
Was bedeutet URL?
 So legen Sie die Transparenz der HTML-Schriftfarbe fest
So legen Sie die Transparenz der HTML-Schriftfarbe fest
 Methode zum Öffnen der Bereichsberechtigung
Methode zum Öffnen der Bereichsberechtigung
 Anforderungen an die Hardwarekonfiguration des Webservers
Anforderungen an die Hardwarekonfiguration des Webservers








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



