
 Technologie-Peripheriegeräte
KI
Durchbruch bei der Schnittstelle zwischen Gehirn und Computer an der UC Berkeley: Verwendung von Gehirnwellen zur Wiedergabe von Musik, um Menschen mit Sprachbehinderungen gute Nachrichten zu überbringen!
Technologie-Peripheriegeräte
KI
Durchbruch bei der Schnittstelle zwischen Gehirn und Computer an der UC Berkeley: Verwendung von Gehirnwellen zur Wiedergabe von Musik, um Menschen mit Sprachbehinderungen gute Nachrichten zu überbringen!
Durchbruch bei der Schnittstelle zwischen Gehirn und Computer an der UC Berkeley: Verwendung von Gehirnwellen zur Wiedergabe von Musik, um Menschen mit Sprachbehinderungen gute Nachrichten zu überbringen!

Im Zeitalter der Gehirn-Computer-Schnittstelle gibt es jeden Tag neue Geräte.
Heute bringe ich Ihnen vier Wörter: Gehirntransplantationsmusik.
Konkret geht es darum, zunächst mithilfe von KI zu beobachten, welche Art von Radiowellen ein bestimmtes Musikstück im Gehirn einer Person erzeugt, und dann direkt die Aktivität dieser Radiowelle im Gehirn der Person zu simulieren, die dies erreichen muss Behandlung. Der Zweck bestimmter Arten von Krankheiten.
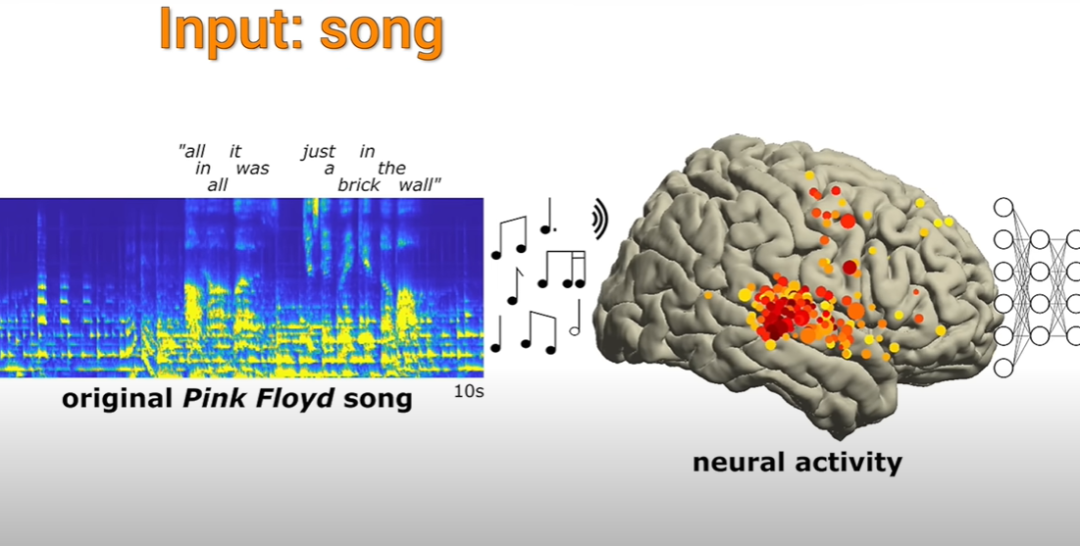
Lassen Sie uns vor ein paar Jahren auf das Albany Medical Center zurückblicken und sehen, wie die Neurowissenschaftler dort geforscht haben
Gute Nachrichten für Menschen mit Sprachstörungen!
Im Albany Medical Center erklang langsam ein Musikstück namens „The Other Wall“ und füllte die gesamte Krankenstation.
Patienten, die auf dem Bett liegen und sich auf eine Epilepsieoperation vorbereiten, sind keine Ärzte, sondern hören zu
Neurowissenschaftler versammelten sich, um die auf dem Computerbildschirm angezeigte Elektroenzephalogramm-Aktivität des Patienten zu beobachten
Die Hauptbeobachtung war, dass einige Bereiche des Gehirns etwas Einzigartiges für Musik hörten. Die daraus resultierende Elektrodenaktivität wurde dann verwendet, um zu sehen, ob das aufgezeichnet wurde Die Elektrodenaktivität konnte die Musik reproduzieren, die sie hörten.
In den oben genannten Inhalten umfassen die Elemente der Musik Tonhöhe, Rhythmus, Harmonie und Texte.
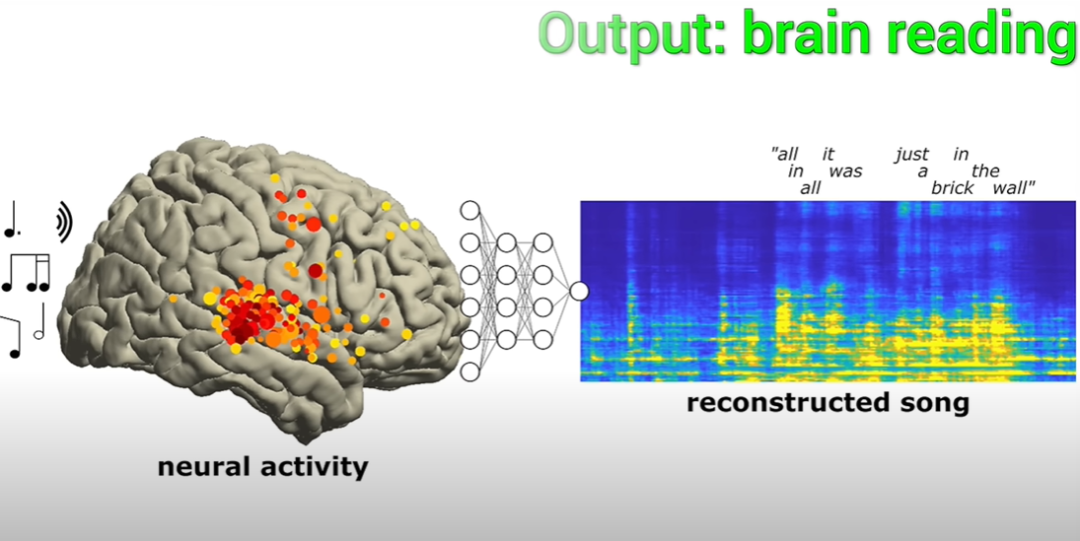
Diese Forschung wird seit mehr als zehn Jahren durchgeführt. Neurowissenschaftler der University of California, Berkeley, führten eine detaillierte Analyse der Daten von 29 Epilepsiepatienten durch, die an dem Experiment teilnahmen. Den Wissenschaftlern gelang es, die Musik anhand der Ergebnisse der Elektrodenaktivität im Gehirn der Patienten erfolgreich zu rekonstruieren Das aktuelle Lied, einer der Texte „All in all it was just a Brick in the Wall“, hat einen sehr vollständigen Rhythmus. Obwohl der Text nicht allzu klar ist, sagten die Forscher, dass er entziffert werden kann und nicht chaotisch ist.
Und dieses Lied ist auch der erste Fall, bei dem es Wissenschaftlern gelungen ist, ein Lied durch Aktivität von Gehirnelektroden zu rekonstruieren.
Die Ergebnisse zeigen, dass durch die Aufzeichnung und Deaktivierung von Gehirnwellen einige musikalische Elemente und Silben erfasst werden können.
Diese musikalischen Elemente können im professionellen Sinne als Prosodie bezeichnet werden, einschließlich Rhythmus, Betonung, Kadenz usw. Die Bedeutung dieser Elemente kann nicht allein durch Worte vermittelt werden
Da diese intrakraniellen Elektroenzephalogramme (iEEGs) außerdem nur Aktivitäten aufzeichnen, die in den Oberflächenschichten des Gehirns (d. h. den Teilen, die dem Hörzentrum am nächsten liegen) stattfinden, gibt es diese auch Sie müssen sich keine Sorgen machen, dass jemand auf diese Weise belauscht, welche Lieder Sie gerade hören (lacht) aus der Elektrodenaktivität auf der Oberfläche des Gehirns, was ihnen helfen kann, die Musikalität des Stücks zu reproduzieren.
Offensichtlich ist das viel besser als die roboterhafte, ausdruckslose Version des Vorgängers. Wie oben erwähnt, gibt es einige Dinge, bei denen Worte allein nicht ausreichen. Was wir hören, ist der Ton.
Robert Knight, Neurowissenschaftler am Helen Wills Neuroscience Institute und Professor für Psychologie an der University of California, Berkeley, sagte, dies sei ein bemerkenswertes Ergebnis.
 „Für mich liegt einer der Reize der Musik in ihrem Auftakt und dem emotionalen Inhalt, den sie ausdrückt. Und mit den kontinuierlichen Durchbrüchen auf dem Gebiet der Gehirn-Computer-Schnittstelle kann diese Technologie durch die Technologie an Menschen in Not weitergegeben werden.“ Die Implantationsmethode bietet etwas, das nur Musik bieten kann. Zu den Zuhörern gehören möglicherweise Patienten mit ALS oder Patienten mit Epilepsie, kurz gesagt, alle, deren Krankheit ihre Sprachausgabenerven beeinträchtigt nur die Sprache selbst, und die in Worten ausgedrückten Emotionen scheinen im Vergleich zur Musik etwas dürftig zu sein. Ich glaube, dass wir uns von nun an wirklich auf einer Interpretationsreise begeben haben
„Für mich liegt einer der Reize der Musik in ihrem Auftakt und dem emotionalen Inhalt, den sie ausdrückt. Und mit den kontinuierlichen Durchbrüchen auf dem Gebiet der Gehirn-Computer-Schnittstelle kann diese Technologie durch die Technologie an Menschen in Not weitergegeben werden.“ Die Implantationsmethode bietet etwas, das nur Musik bieten kann. Zu den Zuhörern gehören möglicherweise Patienten mit ALS oder Patienten mit Epilepsie, kurz gesagt, alle, deren Krankheit ihre Sprachausgabenerven beeinträchtigt nur die Sprache selbst, und die in Worten ausgedrückten Emotionen scheinen im Vergleich zur Musik etwas dürftig zu sein. Ich glaube, dass wir uns von nun an wirklich auf einer Interpretationsreise begeben haben
Mit der Weiterentwicklung der Gehirnwellen-Aufzeichnungstechnologie können wir eines Tages möglicherweise über an der Kopfhaut angebrachte Elektroden aufzeichnen, ohne das Gehirn öffnen zu müssen.
Knight sagte, dass die aktuelle Elektroenzephalographie der Kopfhaut bereits einige Gehirnaktivitäten messen und aufzeichnen kann, beispielsweise das Erkennen eines einzelnen Buchstabens aus einer großen Reihe von Buchstaben. Obwohl es nicht sehr effizient ist, dauert jeder Buchstabe mindestens 20 Sekunden, aber es ist immer noch ein Anfang.
Der Grund für die energische Entwicklung von Kopfhautelektroden liegt darin, dass der derzeitige Kenntnisstand in der nicht-invasiven Technologie unzureichend ist. Mit anderen Worten: Die Kraniotomiemessung kann nicht zu 100 % sicher sein. Die Messgenauigkeit von Kopfhautelektroden, insbesondere für tiefe Hirnmessungen, muss noch verbessert werden. Man kann sagen, dass es einige Erfolge erzielt hat, aber nicht ganz
Können Sie Gedanken lesen?
Die direkte Antwort lautet: Nein.
Für Menschen mit Sprachbehinderung ist die Gehirn-Computer-Schnittstellentechnologie beispielsweise gleichbedeutend mit der Bereitstellung einer „Tastatur“. Durch die Erfassung der Aktivität von Gehirnwellen können sie diese „Tastatur“ verwenden, um zu tippen und auszudrücken, was sie möchten ausdrücken möchte.
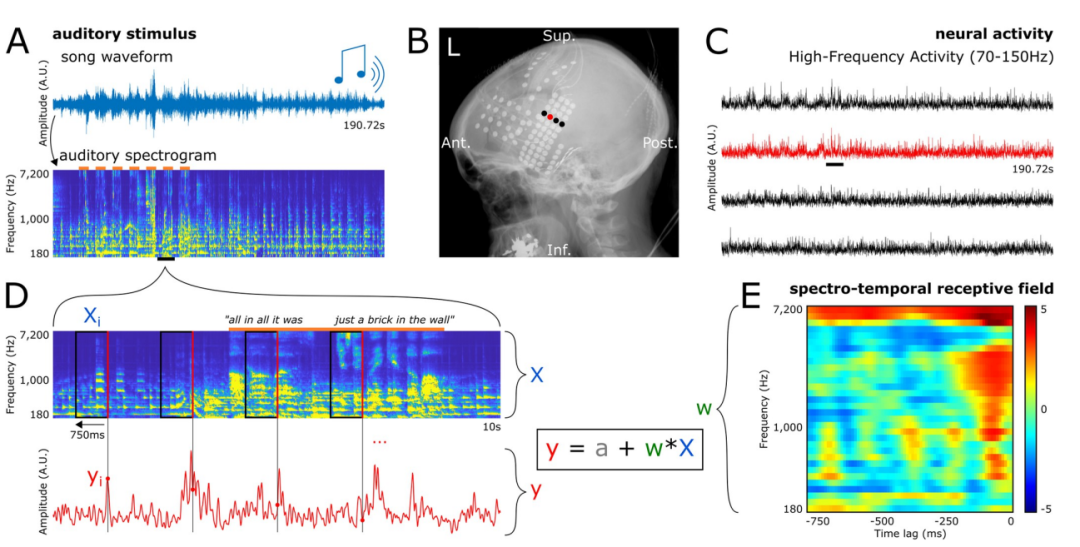
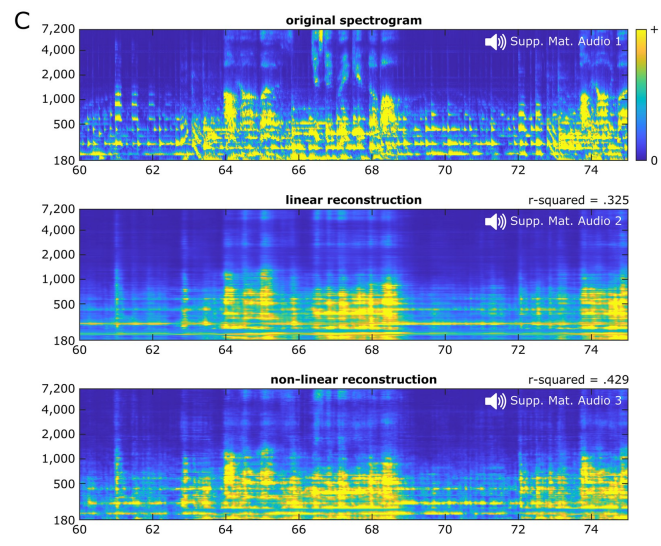
Nehmen Sie zum Beispiel Hawking. Das Gerät, mit dem er seine Gehirnwellen erfasste, um die Sprache der Roboterstimme zu erzeugen. Wenn man nur auf diese „Tastatur“ schaut, kann man nicht erkennen, was sie denkt. Die Technologie ermöglicht es nun, Tastaturen zu aktivieren und Sprache auszugeben. Wenn niemand tippen möchte, startet die Tastatur nicht und Sie können nicht wissen, was sie denkt. Gedankenlesen ist also nicht möglich. Experimenteller Inhalt. Sehen Sie sich bitte das Bild unten an, Abbildung A Zeigt die Gesamtwellenformen der im Experiment verwendeten Songs. Unten ist Abbildung A das Hörspektrogramm des Liedes. Der orangefarbene Balken oben zeigt das Vorhandensein von Gesang an. Abbildung B ist eine Röntgenaufnahme der Elektrodenabdeckung eines Patienten. Jeder Punkt stellt eine Elektrode dar.
Bild C zeigt die Elektrodensignale der vier Elektroden in Bild B. Gleichzeitig zeigt die Abbildung auch die durch Gesangsstimulation ausgelöste Hochfrequenzaktivität (HFA), dargestellt durch eine verschiebbare schwarze kurze Linie, mit einer Frequenz zwischen 70 und 150 Hz
 Abbildung D zeigt einen kurzen Abschnitt (10 Sekunden) des Songs in A. Vergrößertes Hörspektrogramm und Karte der neuronalen Aktivität der Elektrode während der Wiedergabe. Wir können beobachten, dass die Zeitpunkte der HFA mit der roten Linie auf der rechten Seite jedes markierten Rechtecks im Spektrogramm zusammenfallen
Abbildung D zeigt einen kurzen Abschnitt (10 Sekunden) des Songs in A. Vergrößertes Hörspektrogramm und Karte der neuronalen Aktivität der Elektrode während der Wiedergabe. Wir können beobachten, dass die Zeitpunkte der HFA mit der roten Linie auf der rechten Seite jedes markierten Rechtecks im Spektrogramm zusammenfallen
Diese Paarungen stellen die Beispiele dar, die Forscher zum Trainieren und Bewerten von Kodierungsmodellen verwenden.
Die experimentellen Ergebnisse der Forscher zeigen, dass zwischen der Anzahl der im Dekodierungsmodell als Prädiktoren verwendeten Elektroden und der Vorhersagegenauigkeit ein logarithmischer Zusammenhang besteht, wie in der folgenden Abbildung dargestellt.
Zum Beispiel wird die beste Vorhersagegenauigkeit von 80 % bei Verwendung von 43 Elektroden (oder 12,4 %) erreicht (die beste Vorhersagegenauigkeit ist das Ergebnis der Verwendung aller 347 Elektroden).
Der gleiche Zusammenhang wurde bei einzelnen Patienten beobachtet, hier ist, was die Forscher herausgefunden haben
Darüber hinaus beobachteten die Forscher durch Bootstrapping-Analyse einen ähnlichen Zusammenhang zwischen der Dauer des Datensatzes und der Vorhersagegenauigkeit. Der numerische Zusammenhang ist wie gezeigt in der Abbildung unten.
Wenn Sie beispielsweise Daten mit einer Länge von 69 Sekunden (36,1 % der Gesamtlänge) verwenden, können Sie 90 % der besten Leistung erzielen (die beste Leistung bezieht sich auf die Verwendung des gesamten Songs). 190,72 Sekunden lang) Abgeleitete Daten)
In Bezug auf den Modelltyp beträgt die durchschnittliche Dekodierungsgenauigkeit der linearen Dekodierung 0,325, während die durchschnittliche Dekodierungsgenauigkeit der nichtlinearen Dekodierung unter Verwendung eines zweischichtigen, vollständig verbundenen neuronalen Netzwerks 0,429 beträgt.
Insgesamt klingt die lineare Musikliedrekonstruktion (Audio S2) langweilig, mit starken rhythmischen Hinweisen auf das Vorhandensein einiger musikalischer Elemente (bezogen auf Gesangssilben und Leadgitarre), aber möglicherweise auf die Wahrnehmung anderer eingeschränkt.
Die nichtlineare Songrekonstruktion (Audio S3) reproduziert einen erkennbaren Song mit detaillierteren Details im Vergleich zur linearen Rekonstruktion. Die Wahrnehmungsqualität spektraler Elemente wie Tonhöhe und Klangfarbe wird deutlich verbessert und Phonemeigenschaften sind klarer erkennbar. Einige bei der linearen Rekonstruktion vorhandene blinde Erkennungsflecken wurden ebenfalls bis zu einem gewissen Grad verbessert
Das Folgende ist eine Veranschaulichung:
Also verwendeten die Forscher ein nichtlineares Modell, um das Lied durch 61 Elektroden des 29. zu rekonstruieren geduldig .
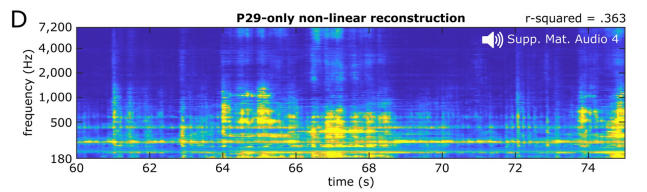
Die Leistung dieser Modelle ist besser als die lineare Rekonstruktion basierend auf allen Patientenelektroden, aber die Dekodierungsgenauigkeit ist nicht so gut wie die, die mit 347 Elektroden aller Patienten erzielt wird.
In Bezug auf die Wahrnehmung sind diese basieren auf einem einzelnen Patienten. Das Modell lieferte ausreichend hohe spektral-zeitliche Details, damit die Forscher das Lied identifizieren konnten (Audio S4). sammelte neuronale Aktivität aus den Gehirnen von drei weiteren Patienten. Die Anzahl der Elektroden war bei diesen drei Patienten geringer, nämlich 23, 17 bzw. 10, während die Anzahl der Elektroden beim oben genannten 29. Patienten 61 betrug und die Elektrodendichte ebenfalls betrug relativ niedrig. Natürlich wird der Antwortbereich des Songs weiterhin abgedeckt, und auch die Genauigkeit der linearen Dekodierung wird als gut angesehen.
In den rekonstruierten Wellenformen (Audiodateien S5, S6 und S7) fanden die Forscher einen Teil der menschlichen Stimme. Anschließend quantifizierten sie die Erkennbarkeit der entschlüsselten Lieder, indem sie die Spektrogramme der Originallieder mit den entschlüsselten Liedern korrelierten.
Sowohl die lineare Rekonstruktion (Abbildung A unten) als auch die nichtlineare Rekonstruktion (Abbildung B unten) bieten einen höheren Anteil korrekter Erkennungsraten.
Darüber hinaus analysierten die Forscher die STRF-Koeffizienten (spektral-zeitliches rezeptives Feld) aller 347 wichtigen Elektroden, um zu bewerten, wie verschiedene musikalische Elemente in verschiedenen Gehirnbereichen kodiert werden. 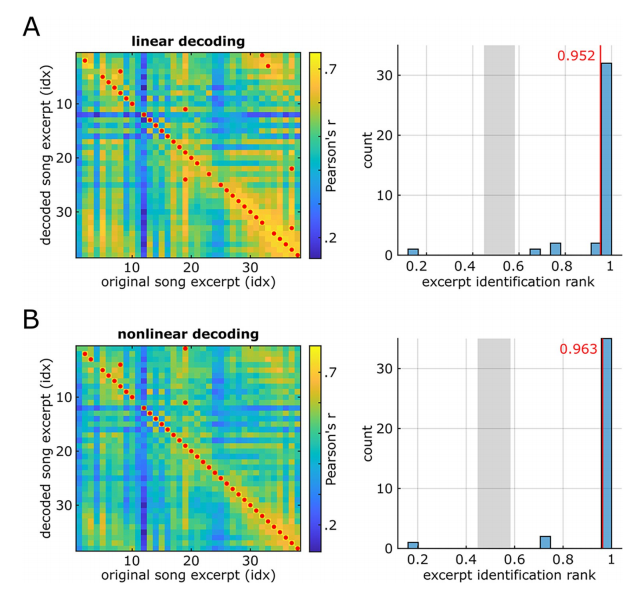
Diese Analyse zeigt unterschiedliche spektrale und zeitliche Abstimmungsmuster
Um die Beziehung zwischen Gesangsspektrogrammen und neuronaler Aktivität umfassend zu charakterisieren, führten die Forscher eine unabhängige Komponentenanalyse (ICA) für alle wichtigen STRFs durch.
Die Forscher fanden 3 Komponenten mit unterschiedlichen spektral-zeitlichen Abstimmungsmustern. Die Varianzerklärungsrate jeder Komponente überstieg 5 %, und die Gesamtvarianzerklärungsrate erreichte 52,5 %, wie in der folgenden Abbildung dargestellt.
Der erste Teil (erklärte Varianz 28 %) zeigt eine Ansammlung positiver Koeffizienten, die über einen weiten Frequenzbereich von etwa 500 Hz bis 7000 Hz und ein schmales Zeitfenster von etwa 90 ms verteilt sind, bevor HFA beobachtet wird. Sichtbar innerhalb von
Dieser Augenblick Cluster zeigt die Stimmung des Tonbeginns an. Dieser Teil wird als Anfangsteil bezeichnet und erscheint nur auf den Elektroden auf der Rückseite des bilateralen STG, wie im Bild unten gezeigt
Abschließend sagten die Forscher, dass zukünftige Studien die Abdeckung der Elektroden erweitern könnten. die Eigenschaften und Ziele des Modells ändern oder neue Verhaltensdimensionen hinzufügen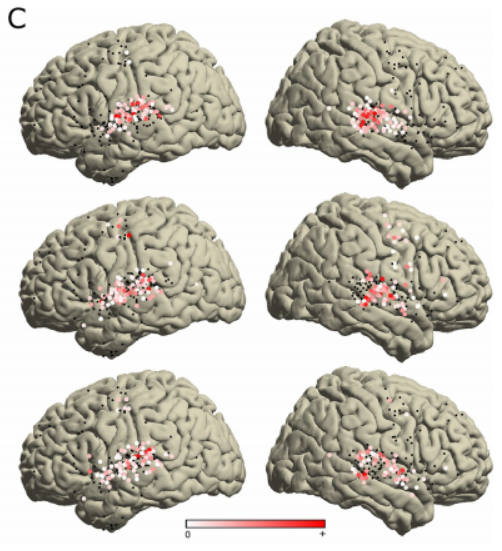
Das obige ist der detaillierte Inhalt vonDurchbruch bei der Schnittstelle zwischen Gehirn und Computer an der UC Berkeley: Verwendung von Gehirnwellen zur Wiedergabe von Musik, um Menschen mit Sprachbehinderungen gute Nachrichten zu überbringen!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1384
1384
 52
52

 CentOS Shutdown -Befehlszeile
Apr 14, 2025 pm 09:12 PM
CentOS Shutdown -Befehlszeile
Apr 14, 2025 pm 09:12 PM
Der Befehl centOS stilldown wird heruntergefahren und die Syntax wird von [Optionen] ausgeführt [Informationen]. Zu den Optionen gehören: -h das System sofort stoppen; -P schalten Sie die Leistung nach dem Herunterfahren aus; -r neu starten; -t Wartezeit. Zeiten können als unmittelbar (jetzt), Minuten (Minuten) oder als bestimmte Zeit (HH: MM) angegeben werden. Hinzugefügten Informationen können in Systemmeldungen angezeigt werden.
 So überprüfen Sie die CentOS -HDFS -Konfiguration
Apr 14, 2025 pm 07:21 PM
So überprüfen Sie die CentOS -HDFS -Konfiguration
Apr 14, 2025 pm 07:21 PM
Vollständige Anleitung zur Überprüfung der HDFS -Konfiguration in CentOS -Systemen In diesem Artikel wird die Konfiguration und den laufenden Status von HDFS auf CentOS -Systemen effektiv überprüft. Die folgenden Schritte helfen Ihnen dabei, das Setup und den Betrieb von HDFs vollständig zu verstehen. Überprüfen Sie die Hadoop -Umgebungsvariable: Stellen Sie zunächst sicher, dass die Hadoop -Umgebungsvariable korrekt eingestellt ist. Führen Sie im Terminal den folgenden Befehl aus, um zu überprüfen, ob Hadoop ordnungsgemäß installiert und konfiguriert ist: Hadoopsion-Check HDFS-Konfigurationsdatei: Die Kernkonfigurationsdatei von HDFS befindet sich im/etc/hadoop/conf/verzeichnis, wobei core-site.xml und hdfs-site.xml von entscheidender Bedeutung sind. verwenden
 Was sind die Backup -Methoden für Gitlab auf CentOS?
Apr 14, 2025 pm 05:33 PM
Was sind die Backup -Methoden für Gitlab auf CentOS?
Apr 14, 2025 pm 05:33 PM
Backup- und Wiederherstellungsrichtlinie von GitLab im Rahmen von CentOS -System Um die Datensicherheit und Wiederherstellung der Daten zu gewährleisten, bietet GitLab on CentOS eine Vielzahl von Sicherungsmethoden. In diesem Artikel werden mehrere gängige Sicherungsmethoden, Konfigurationsparameter und Wiederherstellungsprozesse im Detail eingeführt, um eine vollständige GitLab -Sicherungs- und Wiederherstellungsstrategie aufzubauen. 1. Manuell Backup Verwenden Sie den GitLab-RakegitLab: Backup: Befehl erstellen, um die manuelle Sicherung auszuführen. Dieser Befehl unterstützt wichtige Informationen wie GitLab Repository, Datenbank, Benutzer, Benutzergruppen, Schlüssel und Berechtigungen. Die Standardsicherungsdatei wird im Verzeichnis/var/opt/gitlab/backups gespeichert. Sie können /etc /gitlab ändern
 Wie ist die GPU -Unterstützung für Pytorch bei CentOS?
Apr 14, 2025 pm 06:48 PM
Wie ist die GPU -Unterstützung für Pytorch bei CentOS?
Apr 14, 2025 pm 06:48 PM
Aktivieren Sie die Pytorch -GPU -Beschleunigung am CentOS -System erfordert die Installation von CUDA-, CUDNN- und GPU -Versionen von Pytorch. Die folgenden Schritte führen Sie durch den Prozess: Cuda und Cudnn Installation Bestimmen Sie die CUDA-Version Kompatibilität: Verwenden Sie den Befehl nvidia-smi, um die von Ihrer NVIDIA-Grafikkarte unterstützte CUDA-Version anzuzeigen. Beispielsweise kann Ihre MX450 -Grafikkarte CUDA11.1 oder höher unterstützen. Download und installieren Sie Cudatoolkit: Besuchen Sie die offizielle Website von Nvidiacudatoolkit und laden Sie die entsprechende Version gemäß der höchsten CUDA -Version herunter und installieren Sie sie, die von Ihrer Grafikkarte unterstützt wird. Installieren Sie die Cudnn -Bibliothek:
 Detaillierte Erklärung des Docker -Prinzips
Apr 14, 2025 pm 11:57 PM
Detaillierte Erklärung des Docker -Prinzips
Apr 14, 2025 pm 11:57 PM
Docker verwendet Linux -Kernel -Funktionen, um eine effiziente und isolierte Anwendungsumgebung zu bieten. Sein Arbeitsprinzip lautet wie folgt: 1. Der Spiegel wird als schreibgeschützte Vorlage verwendet, die alles enthält, was Sie für die Ausführung der Anwendung benötigen. 2. Das Union File System (UnionFS) stapelt mehrere Dateisysteme, speichert nur die Unterschiede, speichert Platz und beschleunigt. 3. Der Daemon verwaltet die Spiegel und Container, und der Kunde verwendet sie für die Interaktion. 4. Namespaces und CGroups implementieren Container -Isolation und Ressourcenbeschränkungen; 5. Mehrere Netzwerkmodi unterstützen die Containerverbindung. Nur wenn Sie diese Kernkonzepte verstehen, können Sie Docker besser nutzen.
 CentOS installieren MySQL
Apr 14, 2025 pm 08:09 PM
CentOS installieren MySQL
Apr 14, 2025 pm 08:09 PM
Die Installation von MySQL auf CentOS umfasst die folgenden Schritte: Hinzufügen der entsprechenden MySQL Yum -Quelle. Führen Sie den Befehl mySQL-server aus, um den MySQL-Server zu installieren. Verwenden Sie den Befehl mySQL_SECURE_INSTALLATION, um Sicherheitseinstellungen vorzunehmen, z. B. das Festlegen des Stammbenutzerkennworts. Passen Sie die MySQL -Konfigurationsdatei nach Bedarf an. Tune MySQL -Parameter und optimieren Sie Datenbanken für die Leistung.
 So sehen Sie sich Gitlab -Protokolle unter CentOS
Apr 14, 2025 pm 06:18 PM
So sehen Sie sich Gitlab -Protokolle unter CentOS
Apr 14, 2025 pm 06:18 PM
Eine vollständige Anleitung zum Anzeigen von GitLab -Protokollen unter CentOS -System In diesem Artikel wird in diesem Artikel verschiedene GitLab -Protokolle im CentOS -System angezeigt, einschließlich Hauptprotokolle, Ausnahmebodi und anderen zugehörigen Protokollen. Bitte beachten Sie, dass der Log -Dateipfad je nach GitLab -Version und Installationsmethode variieren kann. Wenn der folgende Pfad nicht vorhanden ist, überprüfen Sie bitte das GitLab -Installationsverzeichnis und die Konfigurationsdateien. 1. Zeigen Sie das Hauptprotokoll an. Verwenden Sie den folgenden Befehl, um die Hauptprotokolldatei der GitLabRails-Anwendung anzuzeigen: Befehl: Sudocat/var/log/gitlab/gitlab-rails/production.log Dieser Befehl zeigt das Produkt an
 Wie man eine verteilte Schulung von Pytorch auf CentOS betreibt
Apr 14, 2025 pm 06:36 PM
Wie man eine verteilte Schulung von Pytorch auf CentOS betreibt
Apr 14, 2025 pm 06:36 PM
Pytorch Distributed Training on CentOS -System erfordert die folgenden Schritte: Pytorch -Installation: Die Prämisse ist, dass Python und PIP im CentOS -System installiert sind. Nehmen Sie abhängig von Ihrer CUDA -Version den entsprechenden Installationsbefehl von der offiziellen Pytorch -Website ab. Für CPU-Schulungen können Sie den folgenden Befehl verwenden: PipinstallTorChTorChVisionTorChaudio Wenn Sie GPU-Unterstützung benötigen, stellen Sie sicher, dass die entsprechende Version von CUDA und CUDNN installiert ist und die entsprechende Pytorch-Version für die Installation verwenden. Konfiguration der verteilten Umgebung: Verteiltes Training erfordert in der Regel mehrere Maschinen oder mehrere Maschinen-Mehrfach-GPUs. Ort
