
 Technologie-Peripheriegeräte
KI
Die multimodale Version Llama2 ist online, Meta veröffentlicht AnyMAL
Technologie-Peripheriegeräte
KI
Die multimodale Version Llama2 ist online, Meta veröffentlicht AnyMAL
Die multimodale Version Llama2 ist online, Meta veröffentlicht AnyMAL

Aktualisierung der branchenweit besten Zero-Shot-Leistung in mehreren Benchmark-Tests.
Ein einheitliches Modell, das verschiedene modale Eingabeinhalte (Text, Bild, Video, Audio, IMU-Bewegungssensordaten) verstehen und Textantworten generieren kann. Die Technologie basiert auf Llama 2 und stammt von Meta.
Gestern erregte die Forschung am multimodalen Großmodell AnyMAL die Aufmerksamkeit der KI-Forschungsgemeinschaft.
Große Sprachmodelle (LLMs) sind für ihre enorme Größe und Komplexität bekannt, die die Fähigkeit von Maschinen, menschliche Sprache zu verstehen und auszudrücken, erheblich verbessern. Fortschritte bei LLMs haben erhebliche Fortschritte im Bereich der visuellen Sprache ermöglicht und die Lücke zwischen Bildkodierern und LLMs geschlossen, indem sie deren Inferenzfähigkeiten kombiniert haben. Frühere multimodale LLM-Forschung konzentrierte sich auf Modelle, die Text mit einer anderen Modalität kombinieren, beispielsweise Text- und Bildmodellen, oder auf proprietäre Sprachmodelle, die nicht Open Source sind.
Wenn es einen besseren Weg gibt, multimodale Funktionalität zu erreichen und verschiedene Modalitäten in LLM einzubetten, wird uns das eine andere Erfahrung bringen?
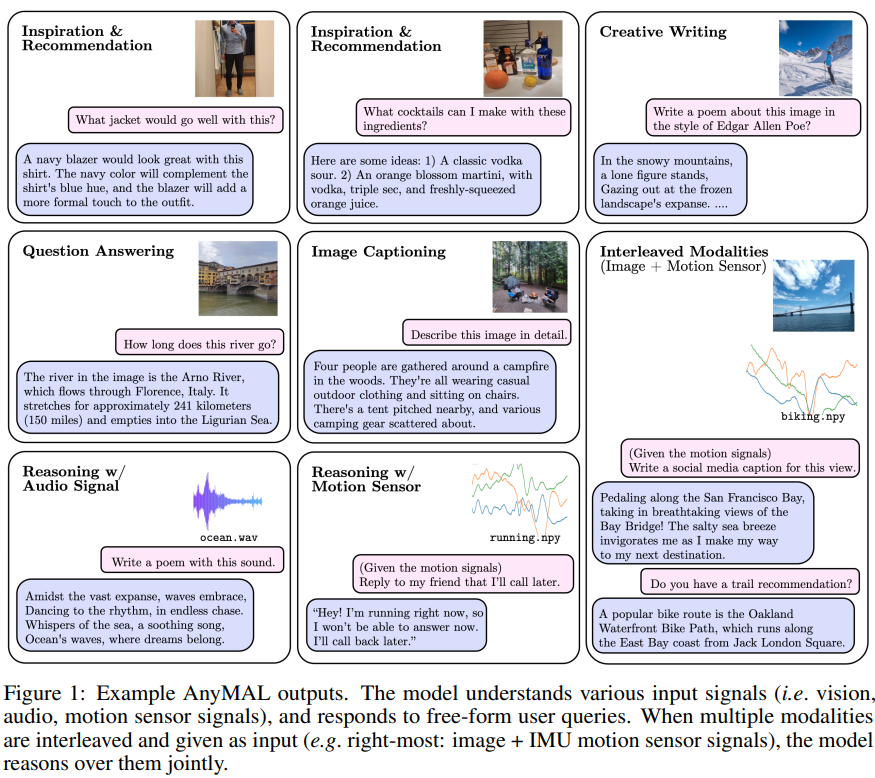
Der Beschreibung zufolge sind die Hauptbeiträge dieser Forschung wie folgt:
Es wird eine effiziente und skalierbare Lösung für den Aufbau multimodalen LLM vorgeschlagen. Dieser Artikel bietet vorab trainierte Projektionsebenen für große Datensätze mit mehreren Modalitäten (z. B. 200 Millionen Bilder, 2,2 Millionen Audiosegmente, 500.000 IMU-Zeitreihen, 28 Millionen Videosegmente), die alle auf dasselbe große Modell ausgerichtet sind (LLaMA- 2-70B-Chat), der verschachtelte multimodale kontextbezogene Hinweise ermöglicht. Diese Studie verfeinert das Modell mithilfe eines multimodalen Befehlssatzes über drei Modalitäten (Bild, Video und Audio) weiter und deckt eine Vielzahl uneingeschränkter Aufgaben ab, die über den Bereich der einfachen Fragebeantwortung (QA) hinausgehen. Dieser Datensatz enthält hochwertige, von Menschen gesammelte Befehlsdaten und wird daher in dieser Studie als Benchmark für komplexe multimodale Inferenzaufgaben verwendet. Das beste Modell in diesem Artikel erzielte gute Ergebnisse bei automatischen und menschlichen Bewertungen verschiedener Aufgaben und Modalitäten Im Vergleich zu den Modellen in der vorhandenen Literatur wurde die relative Genauigkeit von VQAv2 um 7,0 %, der CIDEr von COCO-Bilduntertiteln ohne Fehler um 8,4 % und der CIDEr von AudioCaps um 14,5 % erhöht SOTA
Diese Studie verfeinert das Modell mithilfe eines multimodalen Befehlssatzes über drei Modalitäten (Bild, Video und Audio) weiter und deckt eine Vielzahl uneingeschränkter Aufgaben ab, die über den Bereich der einfachen Fragebeantwortung (QA) hinausgehen. Dieser Datensatz enthält hochwertige, von Menschen gesammelte Befehlsdaten und wird daher in dieser Studie als Benchmark für komplexe multimodale Inferenzaufgaben verwendet. Das beste Modell in diesem Artikel erzielte gute Ergebnisse bei automatischen und menschlichen Bewertungen verschiedener Aufgaben und Modalitäten Im Vergleich zu den Modellen in der vorhandenen Literatur wurde die relative Genauigkeit von VQAv2 um 7,0 %, der CIDEr von COCO-Bilduntertiteln ohne Fehler um 8,4 % und der CIDEr von AudioCaps um 14,5 % erhöht SOTA
- muss durch Verwendung gepaarter multimodaler Daten einschließlich spezifischer modaler Signal- und Textnarrative umgeschrieben werden). Diese Studie hat LLM vorgebracht, um Multi zu erreichen -modale Verständnisfähigkeiten, wie in Abbildung 2 dargestellt. Konkret trainieren wir für jede Modalität einen leichtgewichtigen Adapter, der das Eingangssignal in den Text-Token-Einbettungsraum eines bestimmten LLM projiziert. Auf diese Weise wird der Text-Token-Einbettungsraum von LLM zu einem gemeinsamen Token-Einbettungsraum, in dem Token Text oder andere Modalitäten darstellen können.
In Bezug auf die Untersuchung der Bildausrichtung haben wir eine saubere Teilmenge des LAION-2B-Datensatzes verwendet. Die CAT-Methode wird verwendet zum Filtern und alle erkennbaren Gesichter werden unscharf. Für die Forschung zur Audioausrichtung wurden die Datensätze AudioSet (2.1M), AudioCaps (46K) und CLOTHO (5K) verwendet. Darüber hinaus haben wir auch den Ego4D-Datensatz für IMU und Textausrichtung (528 KB) verwendet.
Bei großen Datensätzen erfordert die Skalierung vor dem Training auf ein 70B-Parametermodell viele Ressourcen und erfordert häufig die Verwendung von FSDP-Wrappern auf mehreren GPUs. Das Modell ist zersplittert. Um das Training effektiv zu skalieren, implementieren wir eine Quantisierungsstrategie (4-Bit und 8-Bit) in einer multimodalen Umgebung, in der der LLM-Teil des Modells eingefroren ist und nur der modale Tokenizer trainierbar ist. Dieser Ansatz reduziert den Speicherbedarf um eine Größenordnung. Daher kann 70B AnyMAL das Training auf einer einzelnen 80-GB-VRAM-GPU mit einer Stapelgröße von 4 abschließen. Im Vergleich zu FSDP verbraucht die in diesem Artikel vorgeschlagene Quantisierungsmethode nur die Hälfte der GPU-Ressourcen, erreicht aber den gleichen Durchsatz-

Die Verwendung multimodaler Befehlsdatensätze zur Feinabstimmung bedeutet die Verwendung multimodaler Befehlsdatensätze zur Feinabstimmung
Um die Fähigkeit des Modells, Anweisungen für verschiedene Eingabemodalitäten zu befolgen, weiter zu verbessern, untersuchen wir die Verwendung multimodaler Befehlsdatensätze. Zusätzliche Feinabstimmungen wurden am hochmodernen Befehlsoptimierungsdatensatz (MM-IT) durchgeführt. Konkret verketten wir die Eingabe als [
], sodass das Antwortziel sowohl auf der Textanweisung als auch auf der modalen Eingabe basiert. Es werden folgende zwei Situationen untersucht: (1) Training der Projektionsschicht ohne Änderung der LLM-Parameter oder (2) Verwendung einer Low-Level-Anpassung (Low-Rank Adaptation) zur weiteren Anpassung des LM-Verhaltens; Die Studie verwendet sowohl manuell erfasste, durch Anweisungen abgestimmte Datensätze als auch synthetische Daten. Experimente und Ergebnisse
Die Generierung von Bildunterschriften ist eine Technologie der künstlichen Intelligenz, mit der automatisch entsprechende Untertitel für Bilder generiert werden. Diese Technologie kombiniert Computer Vision und Methoden der Verarbeitung natürlicher Sprache, um beschreibende Bildunterschriften zu generieren, indem der Inhalt und die Eigenschaften des Bildes analysiert sowie die Semantik und Syntax verstanden werden. Die Generierung von Bildunterschriften hat vielfältige Anwendungsmöglichkeiten in vielen Bereichen, einschließlich Bildsuche, Bildanmerkung, Bildabruf usw. Durch die automatische Generierung von Titeln können die Verständlichkeit von Bildern und die Genauigkeit von Suchmaschinen verbessert werden, wodurch Benutzern ein besseres Bildabruf- und Browsing-Erlebnis geboten wird
Tabelle 2 zeigt die Ergebnisse in COCO und Aufgaben, die mit „Detaillierte Beschreibung“ (MM-) gekennzeichnet sind. Leistung bei der Generierung von Bildunterschriften ohne Aufnahme einer Teilmenge des MM-IT-Datensatzes von IT-Cap. Wie man sehen kann, schneidet die AnyMAL-Variante bei beiden Datensätzen deutlich besser ab als die Basislinie. Bemerkenswert ist, dass zwischen den Varianten AnyMAL-13B und AnyMAL-70B kein nennenswerter Leistungsunterschied besteht. Dieses Ergebnis zeigt, dass die zugrunde liegende LLM-Funktion zur Generierung von Bildunterschriften eine Technik der künstlichen Intelligenz ist, die zur automatischen Generierung entsprechender Untertitel für Bilder verwendet wird. Diese Technologie kombiniert Computer Vision und Methoden der Verarbeitung natürlicher Sprache, um beschreibende Bildunterschriften zu generieren, indem der Inhalt und die Eigenschaften des Bildes analysiert sowie die Semantik und Syntax verstanden werden. Die Generierung von Bildunterschriften hat vielfältige Anwendungsmöglichkeiten in vielen Bereichen, einschließlich Bildsuche, Bildanmerkung, Bildabruf usw. Durch die Automatisierung der Bildunterschrift können die Bildverständlichkeit und die Suchmaschinengenauigkeit verbessert werden, wodurch den Benutzern ein besseres Bildabruf- und Browsing-Erlebnis geboten wird. Die Aufgabe ist weniger wirkungsvoll, hängt jedoch stark von der Datengröße und der Registrierungsmethode ab.
Die erforderliche Umschreibung lautet: Menschliche Bewertung der multimodalen Inferenzaufgabe
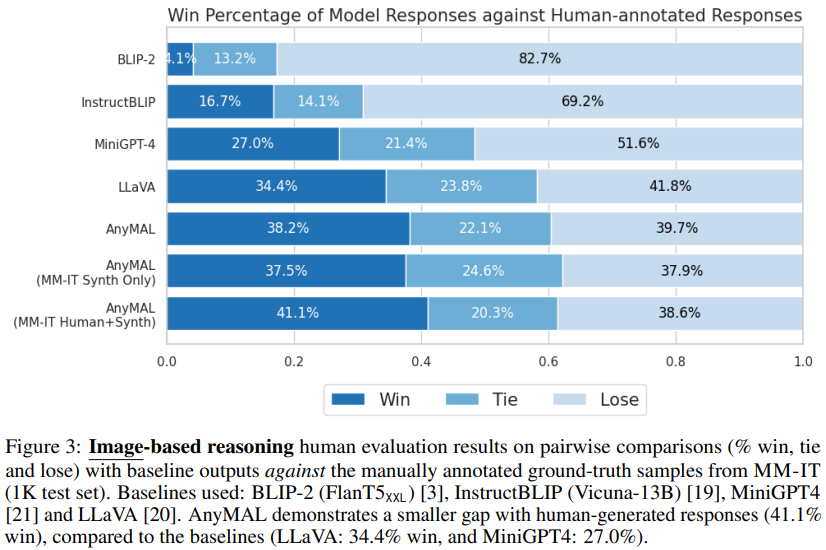
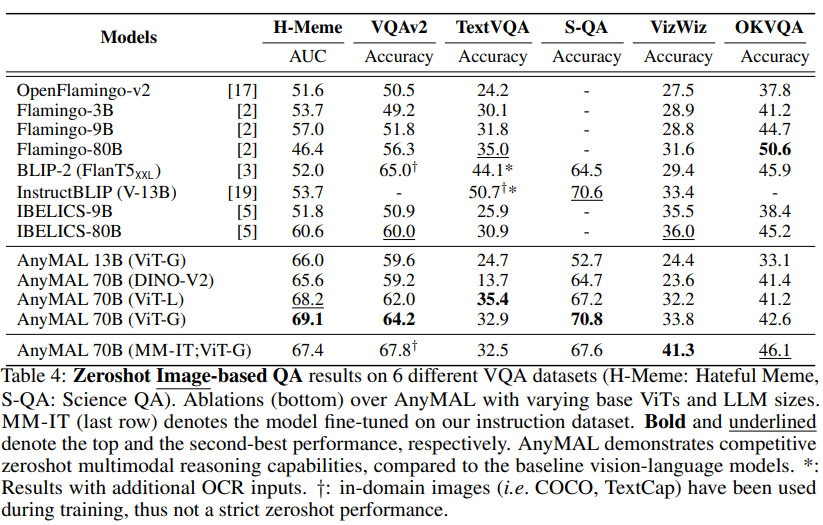
Abbildung 3 zeigt, dass AnyMAL mit der Basislinie verglichen wird (LLaVA: 34,4 % Gewinnrate und MiniGPT4: 27,0 % Gewinnrate). Die Leistung ist stark und der Abstand zu echten, von Menschen kommentierten Proben ist gering (41,1 % Gewinnrate). Bemerkenswert ist, dass Modelle, die mit dem vollständigen Befehlssatz feinabgestimmt wurden, die höchste Prioritätsgewinnrate zeigten und visuelles Verständnis und Argumentationsfähigkeiten zeigten, die mit von Menschen kommentierten Antworten vergleichbar waren. Es ist auch erwähnenswert, dass BLIP-2 und InstructBLIP bei diesen offenen Abfragen eine schlechte Leistung erbringen (4,1 % bzw. 16,7 % Prioritätsgewinnrate), obwohl sie beim öffentlichen VQA-Benchmark gut abschneiden (siehe Tabelle 4).
VQA-Benchmarks
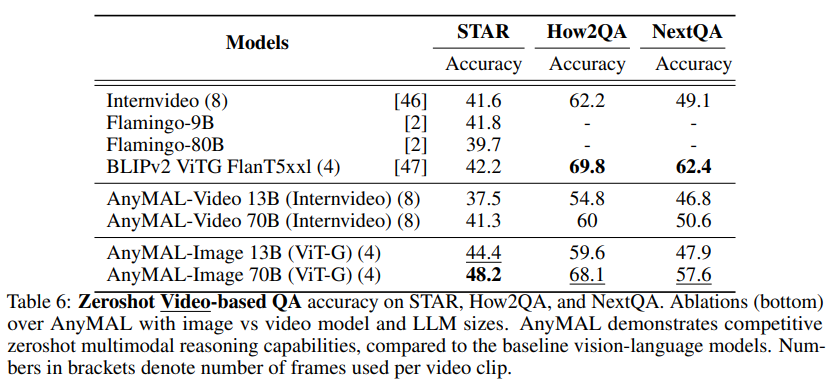
In Tabelle 4 zeigen wir die Zero-Shot-Leistung des Hateful Meme-Datensatzes VQAv2, TextVQA, ScienceQA, VizWiz und OKVQA und vergleichen sie mit den jeweiligen Benchmarks, die im angegeben sind Literatur Die Ergebnisse der Nullstichprobe wurden verglichen. Unsere Forschung konzentriert sich auf die Zero-Shot-Bewertung, um die Modellleistung bei offenen Abfragen zum Inferenzzeitpunkt möglichst genau abzuschätzen Video-QA-Benchmarks.
Audio-Untertitel neu generieren
Tabelle 5 zeigt die Ergebnisse der Regenerierung von Audio-Untertiteln im AudioCaps-Benchmark-Datensatz. AnyMAL übertrifft andere hochmoderne Audio-Untertitelmodelle in der Literatur deutlich (z. B. CIDEr +10,9pp, SPICE +5,8pp), was darauf hinweist, dass die vorgeschlagene Methode nicht nur auf das Sehen, sondern auch auf verschiedene Modalitäten anwendbar ist. Das Textmodell 70B weist klare Vorteile gegenüber den Varianten 7B und 13B auf.
Interessanterweise scheint Meta basierend auf der Methode, der Art und dem Zeitpunkt der Einreichung des AnyMAL-Papiers zu planen, multimodale Daten über sein neu eingeführtes Mixed Reality/Metaverse-Headset zu sammeln. Diese Forschungsergebnisse könnten in die Metaverse-Produktlinie von Meta integriert oder bald auf Verbraucheranwendungen angewendet werden
Bitte lesen Sie den Originalartikel für weitere Details.

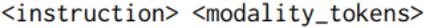 ], sodass das Antwortziel sowohl auf der Textanweisung als auch auf der modalen Eingabe basiert. Es werden folgende zwei Situationen untersucht: (1) Training der Projektionsschicht ohne Änderung der LLM-Parameter oder (2) Verwendung einer Low-Level-Anpassung (Low-Rank Adaptation) zur weiteren Anpassung des LM-Verhaltens; Die Studie verwendet sowohl manuell erfasste, durch Anweisungen abgestimmte Datensätze als auch synthetische Daten.
], sodass das Antwortziel sowohl auf der Textanweisung als auch auf der modalen Eingabe basiert. Es werden folgende zwei Situationen untersucht: (1) Training der Projektionsschicht ohne Änderung der LLM-Parameter oder (2) Verwendung einer Low-Level-Anpassung (Low-Rank Adaptation) zur weiteren Anpassung des LM-Verhaltens; Die Studie verwendet sowohl manuell erfasste, durch Anweisungen abgestimmte Datensätze als auch synthetische Daten. 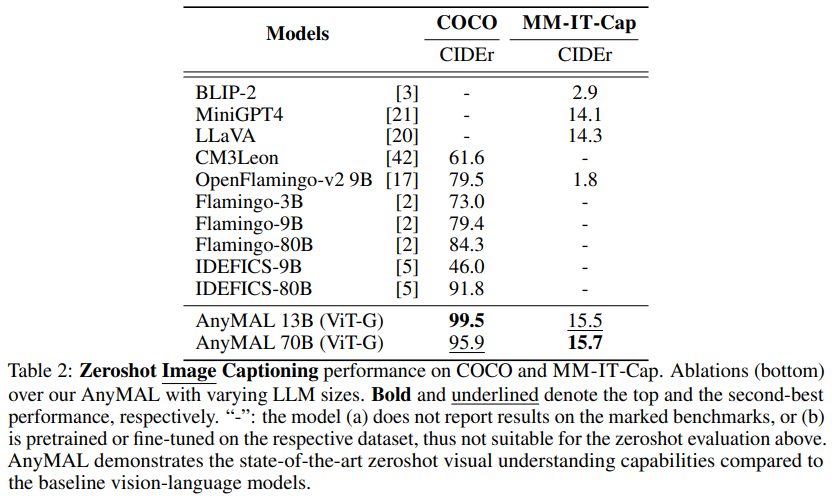
Das obige ist der detaillierte Inhalt vonDie multimodale Version Llama2 ist online, Meta veröffentlicht AnyMAL. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 Der Autor von ControlNet hat einen weiteren Hit! Der gesamte Prozess der Generierung eines Gemäldes aus einem Bild, der in zwei Tagen 1,4.000 Sterne verdient
Jul 17, 2024 am 01:56 AM
Der Autor von ControlNet hat einen weiteren Hit! Der gesamte Prozess der Generierung eines Gemäldes aus einem Bild, der in zwei Tagen 1,4.000 Sterne verdient
Jul 17, 2024 am 01:56 AM
Es ist ebenfalls ein Tusheng-Video, aber PaintsUndo ist einen anderen Weg gegangen. ControlNet-Autor LvminZhang begann wieder zu leben! Dieses Mal ziele ich auf den Bereich der Malerei. Das neue Projekt PaintsUndo hat nicht lange nach seinem Start 1,4.000 Sterne erhalten (die immer noch wahnsinnig steigen). Projektadresse: https://github.com/lllyasviel/Paints-UNDO Bei diesem Projekt gibt der Benutzer ein statisches Bild ein, und PaintsUndo kann Ihnen dabei helfen, automatisch ein Video des gesamten Malprozesses zu erstellen, vom Linienentwurf bis zum fertigen Produkt . Während des Zeichenvorgangs sind die Linienänderungen erstaunlich. Das Endergebnis des Videos ist dem Originalbild sehr ähnlich: Schauen wir uns eine vollständige Zeichnung an.
 Die agentenlose Lösung von UIUC steht ganz oben auf der Liste der Open-Source-KI-Softwareentwickler und löst problemlos echte Programmierprobleme im SWE-Bench
Jul 17, 2024 pm 10:02 PM
Die agentenlose Lösung von UIUC steht ganz oben auf der Liste der Open-Source-KI-Softwareentwickler und löst problemlos echte Programmierprobleme im SWE-Bench
Jul 17, 2024 pm 10:02 PM
Die AIxiv-Kolumne ist eine Kolumne, in der diese Website akademische und technische Inhalte veröffentlicht. In den letzten Jahren sind in der AIxiv-Kolumne dieser Website mehr als 2.000 Berichte eingegangen, die Spitzenlabore großer Universitäten und Unternehmen auf der ganzen Welt abdecken und so den akademischen Austausch und die Verbreitung wirksam fördern. Wenn Sie hervorragende Arbeiten haben, die Sie teilen möchten, können Sie gerne einen Beitrag leisten oder uns für die Berichterstattung kontaktieren. Einreichungs-E-Mail: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com Die Autoren dieses Artikels stammen alle aus dem Team von Lehrer Zhang Lingming an der University of Illinois in Urbana-Champaign, darunter: Steven Code Repair; Doktorand im vierten Jahr, Forscher
 Das neue erschwingliche Meta Quest 3S VR-Headset erscheint bei FCC, was auf eine baldige Markteinführung hindeutet
Sep 04, 2024 am 06:51 AM
Das neue erschwingliche Meta Quest 3S VR-Headset erscheint bei FCC, was auf eine baldige Markteinführung hindeutet
Sep 04, 2024 am 06:51 AM
Die Meta Connect 2024-Veranstaltung findet vom 25. bis 26. September statt. Bei dieser Veranstaltung wird das Unternehmen voraussichtlich ein neues erschwingliches Virtual-Reality-Headset vorstellen. Gerüchten zufolge handelt es sich bei dem VR-Headset um das Meta Quest 3S, das offenbar auf der FCC-Liste aufgetaucht ist. Dieser Vorschlag
 Posthume Arbeit des OpenAI Super Alignment Teams: Zwei große Modelle spielen ein Spiel und die Ausgabe wird verständlicher
Jul 19, 2024 am 01:29 AM
Posthume Arbeit des OpenAI Super Alignment Teams: Zwei große Modelle spielen ein Spiel und die Ausgabe wird verständlicher
Jul 19, 2024 am 01:29 AM
Wenn die Antwort des KI-Modells überhaupt unverständlich ist, würden Sie es wagen, sie zu verwenden? Da maschinelle Lernsysteme in immer wichtigeren Bereichen eingesetzt werden, wird es immer wichtiger zu zeigen, warum wir ihren Ergebnissen vertrauen können und wann wir ihnen nicht vertrauen sollten. Eine Möglichkeit, Vertrauen in die Ausgabe eines komplexen Systems zu gewinnen, besteht darin, vom System zu verlangen, dass es eine Interpretation seiner Ausgabe erstellt, die für einen Menschen oder ein anderes vertrauenswürdiges System lesbar ist, d. h. so vollständig verständlich, dass mögliche Fehler erkannt werden können gefunden. Um beispielsweise Vertrauen in das Justizsystem aufzubauen, verlangen wir von den Gerichten, dass sie klare und lesbare schriftliche Stellungnahmen abgeben, die ihre Entscheidungen erläutern und stützen. Für große Sprachmodelle können wir auch einen ähnlichen Ansatz verfolgen. Stellen Sie bei diesem Ansatz jedoch sicher, dass das Sprachmodell generiert wird
 Das erste Open-Source-Modell, das das GPT4o-Niveau übertrifft! Llama 3.1 durchgesickert: 405 Milliarden Parameter, Download-Links und Modellkarten sind verfügbar
Jul 23, 2024 pm 08:51 PM
Das erste Open-Source-Modell, das das GPT4o-Niveau übertrifft! Llama 3.1 durchgesickert: 405 Milliarden Parameter, Download-Links und Modellkarten sind verfügbar
Jul 23, 2024 pm 08:51 PM
Machen Sie Ihre GPU bereit! Llama3.1 ist endlich erschienen, aber die Quelle ist nicht offiziell von Meta. Heute gingen die durchgesickerten Nachrichten über das neue Llama-Großmodell auf Reddit viral. Zusätzlich zum Basismodell enthält es auch Benchmark-Ergebnisse von 8B, 70B und den maximalen Parameter von 405B. Die folgende Abbildung zeigt die Vergleichsergebnisse jeder Version von Llama3.1 mit OpenAIGPT-4o und Llama38B/70B. Es ist ersichtlich, dass selbst die 70B-Version in mehreren Benchmarks GPT-4o übertrifft. Bildquelle: https://x.com/mattshumer_/status/1815444612414087294 Offensichtlich Version 3.1 von 8B und 70
 arXiv-Artikel können als „Barrage' gepostet werden, die Diskussionsplattform von Stanford alphaXiv ist online, LeCun gefällt es
Aug 01, 2024 pm 05:18 PM
arXiv-Artikel können als „Barrage' gepostet werden, die Diskussionsplattform von Stanford alphaXiv ist online, LeCun gefällt es
Aug 01, 2024 pm 05:18 PM
Prost! Wie ist es, wenn es bei einer Papierdiskussion auf Worte ankommt? Kürzlich haben Studenten der Stanford University alphaXiv erstellt, ein offenes Diskussionsforum für arXiv-Artikel, das es ermöglicht, Fragen und Kommentare direkt zu jedem arXiv-Artikel zu posten. Website-Link: https://alphaxiv.org/ Tatsächlich ist es nicht erforderlich, diese Website speziell zu besuchen. Ändern Sie einfach arXiv in einer beliebigen URL in alphaXiv, um den entsprechenden Artikel direkt im alphaXiv-Forum zu öffnen: Sie können die Absätze darin genau lokalisieren das Papier, Satz: Im Diskussionsbereich auf der rechten Seite können Benutzer Fragen stellen, um dem Autor Fragen zu den Ideen und Details des Papiers zu stellen. Sie können beispielsweise auch den Inhalt des Papiers kommentieren, wie zum Beispiel: „Gegeben an.“
 Axiomatisches Training ermöglicht es LLM, kausales Denken zu erlernen: Das 67-Millionen-Parameter-Modell ist vergleichbar mit der Billionen-Parameter-Ebene GPT-4
Jul 17, 2024 am 10:14 AM
Axiomatisches Training ermöglicht es LLM, kausales Denken zu erlernen: Das 67-Millionen-Parameter-Modell ist vergleichbar mit der Billionen-Parameter-Ebene GPT-4
Jul 17, 2024 am 10:14 AM
Zeigen Sie LLM die Kausalkette und es lernt die Axiome. KI hilft Mathematikern und Wissenschaftlern bereits bei der Forschung. Beispielsweise hat der berühmte Mathematiker Terence Tao wiederholt seine Forschungs- und Forschungserfahrungen mit Hilfe von KI-Tools wie GPT geteilt. Damit KI in diesen Bereichen konkurrenzfähig sein kann, sind starke und zuverlässige Fähigkeiten zum kausalen Denken unerlässlich. Die in diesem Artikel vorgestellte Forschung ergab, dass ein Transformer-Modell, das auf die Demonstration des kausalen Transitivitätsaxioms für kleine Graphen trainiert wurde, auf das Transitivitätsaxiom für große Graphen verallgemeinern kann. Mit anderen Worten: Wenn der Transformer lernt, einfache kausale Überlegungen anzustellen, kann er für komplexere kausale Überlegungen verwendet werden. Der vom Team vorgeschlagene axiomatische Trainingsrahmen ist ein neues Paradigma zum Erlernen des kausalen Denkens auf der Grundlage passiver Daten, nur mit Demonstrationen
 Ein bedeutender Durchbruch in der Riemann-Hypothese! Tao Zhexuan empfiehlt dringend neue Arbeiten vom MIT und Oxford, und der 37-jährige Fields-Medaillengewinner nahm daran teil
Aug 05, 2024 pm 03:32 PM
Ein bedeutender Durchbruch in der Riemann-Hypothese! Tao Zhexuan empfiehlt dringend neue Arbeiten vom MIT und Oxford, und der 37-jährige Fields-Medaillengewinner nahm daran teil
Aug 05, 2024 pm 03:32 PM
Kürzlich gelang der Riemann-Hypothese, die als eines der sieben großen Probleme des Jahrtausends bekannt ist, ein neuer Durchbruch. Die Riemann-Hypothese ist ein sehr wichtiges ungelöstes Problem in der Mathematik, das sich auf die genauen Eigenschaften der Verteilung von Primzahlen bezieht (Primzahlen sind Zahlen, die nur durch 1 und sich selbst teilbar sind, und sie spielen eine grundlegende Rolle in der Zahlentheorie). In der heutigen mathematischen Literatur gibt es mehr als tausend mathematische Thesen, die auf der Aufstellung der Riemann-Hypothese (oder ihrer verallgemeinerten Form) basieren. Mit anderen Worten: Sobald die Riemann-Hypothese und ihre verallgemeinerte Form bewiesen sind, werden diese mehr als tausend Sätze als Theoreme etabliert, die einen tiefgreifenden Einfluss auf das Gebiet der Mathematik haben werden, und wenn sich die Riemann-Hypothese als falsch erweist, dann unter anderem Auch diese Sätze werden teilweise ihre Gültigkeit verlieren. Neuer Durchbruch kommt von MIT-Mathematikprofessor Larry Guth und der Universität Oxford
