

Wie werden Sprachmodelle durch unterschiedliche Vokabellisten beeinflusst? Wie kann man diese Effekte ausgleichen?
In einem kürzlich durchgeführten Experiment haben Forscher 16 Sprachmodelle mit unterschiedlichem Korpus vortrainiert und verfeinert. Dieses Experiment verwendete NanoGPT, eine kleine Architektur (basierend auf GPT-2 SMALL), und trainierte insgesamt 12 Modelle. Die Netzwerkarchitekturkonfiguration von NanoGPT ist: 12 Aufmerksamkeitsköpfe, 12 Transformatorschichten, die Wörterinbettungsdimension beträgt 768 und es wurden ungefähr 400.000 Iterationen (ungefähr 10 Epochen) durchgeführt. Dann wurden 4 Modelle auf GPT-2 MEDIUM trainiert. Die Architektur von GPT-2 MEDIUM wurde auf 16 Aufmerksamkeitsköpfe und 24 Ebenen von Transformatoren eingestellt, die Worteinbettungsdimension betrug 1024 und es wurden 600.000 Iterationen durchgeführt. Alle Modelle werden mit NanoGPT- und OpenWebText-Datensätzen vorab trainiert. Zur Feinabstimmung nutzten die Forscher den von baize-chatbot bereitgestellten Befehlsdatensatz und fügten den beiden Modelltypen jeweils 20.000 bzw. 500.000 „Wörterbuch“-Einträge hinzu.
In Zukunft planen die Forscher die Veröffentlichung Code und Pre-Training-Modell, Anweisungsoptimierungsmodell und Feinabstimmungsdatensatz
Aufgrund des Mangels an GPU-Sponsoren (dies ist ein kostenloses Open-Source-Projekt) haben die Forscher jedoch nicht weitergemacht, um die Kosten zu senken fortfahren, obwohl noch daran gearbeitet wird, den Bereich der Forschungsinhalte weiter zu verbessern. In der Vortrainingsphase müssen diese 16 Modelle insgesamt 147 Tage lang auf 8 GPUs laufen (eine einzelne GPU muss 1.176 Tage lang verwendet werden), was 8.000 US-Dollar kostet. Die Forschungsergebnisse können lauten zusammengefasst als:
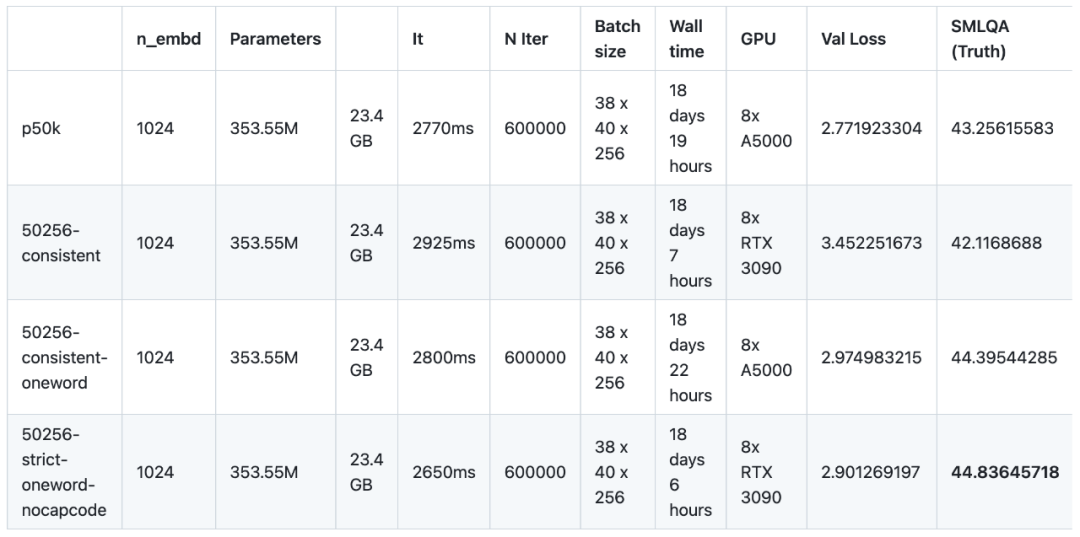
In Bezug auf die Codierungsmethode schneidet das Vokabular von TokenMonster (550256-strict-nocapcode) bei allen Metriken besser ab als GPT-2 Tokenizer und Tiktoken p50k_base.
Den experimentellen Ergebnissen zufolge sind die Ergebnisse von englishcode-32000-consistent die besten. Allerdings gibt es, wie oben erwähnt, bei der Verwendung von TokenMonster, bei dem ein einzelner Token mehreren Wörtern entspricht, einen Kompromiss zwischen der SMLQA-Genauigkeit (Ground Truth) und dem Wortverhältnis, was die Steigung der Lernkurve erhöht. Die Forscher sind fest davon überzeugt, dass dieser Kompromiss minimiert werden kann und ein Vokabular „das Beste aus beiden Welten“ erreicht werden kann, indem 80 % der Token einem Wort und 20 % der Token mehreren Wörtern zugeordnet werden. Die Forscher gehen davon aus, dass diese Methode die gleiche Leistung wie die Ein-Wort-Vokabularliste aufweist und gleichzeitig das Wortverhältnis um etwa 50 % verbessert.
Die Bedeutung dieses Satzes ist, dass Fehler und Komplexität im Wortsegmentierer einen größeren Einfluss auf die Fähigkeit des Modells haben, Fakten zu lernen, als auf seine Sprachfähigkeit
Dieses Phänomen ist eine interessante Entdeckung während des Trainingsprozesses. Merkmale, Es ist sinnvoll, darüber nachzudenken, wie das Modelltraining funktioniert. Der Forscher hat keine Beweise, die seine Argumentation rechtfertigen könnten. Aber im Grunde bedeutet dies, dass jede Verbesserung der Tokenizer-Effizienz weniger konsistent ist als die Faktizität der Sprache, unabhängig vom Geschlecht, da die Sprachkompetenz während der Backpropagation leichter zu korrigieren ist als die Faktizität der Sprache (die äußerst subtil und kontextabhängig ist). , wird es einen Welleneffekt geben, der sich direkt in einer verbesserten Informationstreue niederschlägt, wie im SMLQA-Benchmark (Ground Truth) zu sehen ist. Einfach ausgedrückt: Ein besserer Tokenizer ist ein realistischeres Modell, aber nicht unbedingt ein glatteres Modell. Umgekehrt: Ein Modell mit einem ineffizienten Tokenizer kann immer noch lernen, fließend zu schreiben, aber die zusätzlichen Kosten für die Sprachkompetenz verringern die Glaubwürdigkeit des Modells.
Der Einfluss der Wortschatzgröße
Die Forscher testeten TokenMonster und testeten drei spezifische Optimierungsmodi: ausgewogen, konsistent und streng. Verschiedene Optimierungsmodi wirken sich auf die Art und Weise aus, wie Satzzeichen und Capcodes mit Wort-Tokens kombiniert werden. Die Forscher sagten zunächst voraus, dass der konsistente Modus eine bessere Leistung erzielen würde (weil er weniger komplex ist), obwohl das Wortverhältnis (d. h. das Verhältnis von Zeichen zu Token) etwas niedriger sein würde. Die experimentellen Ergebnisse schienen das oben Gesagte zu bestätigen Vermutung, aber die Forscher beobachteten auch einige Phänomene. Erstens scheint der konsistente Modus beim SMLQA-Benchmark (Ground Truth) etwa 5 % besser abzuschneiden als der ausgeglichene Modus. Beim SQuAD-Benchmark (Data Extraction) schneidet der konsistente Modus jedoch deutlich schlechter ab (28 %). Allerdings weist der SQuAD-Benchmark große Unsicherheiten auf (wiederholte Durchläufe führen zu unterschiedlichen Ergebnissen) und ist nicht überzeugend. Die Forscher haben die Konvergenz zwischen ausgeglichen und konsistent nicht getestet, was einfach bedeuten kann, dass das konsistente Muster leichter zu erlernen ist. Tatsächlich kann konsistent bei SQuAD (Datenextraktion) besser abschneiden, da SQuAD schwieriger zu erlernen ist und weniger wahrscheinlich Halluzinationen hervorruft.
Das ist an sich schon eine interessante Erkenntnis, denn es bedeutet, dass es kein offensichtliches Problem gibt, Satzzeichen und Wörter in einem einzigen Token zu kombinieren. Bisher haben alle anderen Tokenisierer argumentiert, dass Interpunktion von Buchstaben getrennt werden sollte, aber wie Sie anhand der Ergebnisse hier sehen können, können Wörter und Interpunktion ohne merklichen Leistungsverlust in einem einzigen Token zusammengeführt werden. Dies wird auch durch 50256-consistent-oneword bestätigt, eine Kombination, die auf Augenhöhe mit 50256-strict-oneword-nocapcode ist und p50k_base übertrifft. 50256-consistent-oneword kombiniert einfache Interpunktion mit dem Worttoken (was bei den anderen beiden Kombinationen nicht der Fall ist).
Nach der Aktivierung des strikten Capcode-Modus hat dies offensichtlich negative Auswirkungen. Bei SMLQA erreicht 50256-strict-oneword-nocapcode einen Wert von 21,2 und bei SQuAD einen Wert von 23,8, während 50256-strict-oneword einen Wert von 16,8 bzw. 20,0 erreicht. Der Grund liegt auf der Hand: Der strikte Optimierungsmodus verhindert das Zusammenführen von Capcodes und Wort-Tokens, was dazu führt, dass mehr Tokens benötigt werden, um denselben Text darzustellen, was zu einer Reduzierung des Wortverhältnisses um 8 % führt. Tatsächlich ähnelt Strict-Nocapcode eher dem konsistenten als dem Strict-Modus. In verschiedenen Indikatoren sind 50256-consistent-oneword und 50256-strict-oneword-nocapcode nahezu gleich
In den meisten Fällen kamen die Forscher zu dem Schluss, dass das Modell zum Erlernen der Bedeutung von Token mit Satzzeichen und Wörtern nicht allzu schwierig ist . Das heißt, das Konsistenzmodell weist eine höhere grammatikalische Genauigkeit und weniger Grammatikfehler auf als das ausgeglichene Modell. Unter Berücksichtigung aller Faktoren empfehlen die Forscher, dass jeder den Konsistenzmodus verwendet. Der strikte Modus kann nur mit deaktiviertem Capcode verwendet werden.
Auswirkungen auf die Syntaxgenauigkeit
Auswirkungen auf MTLD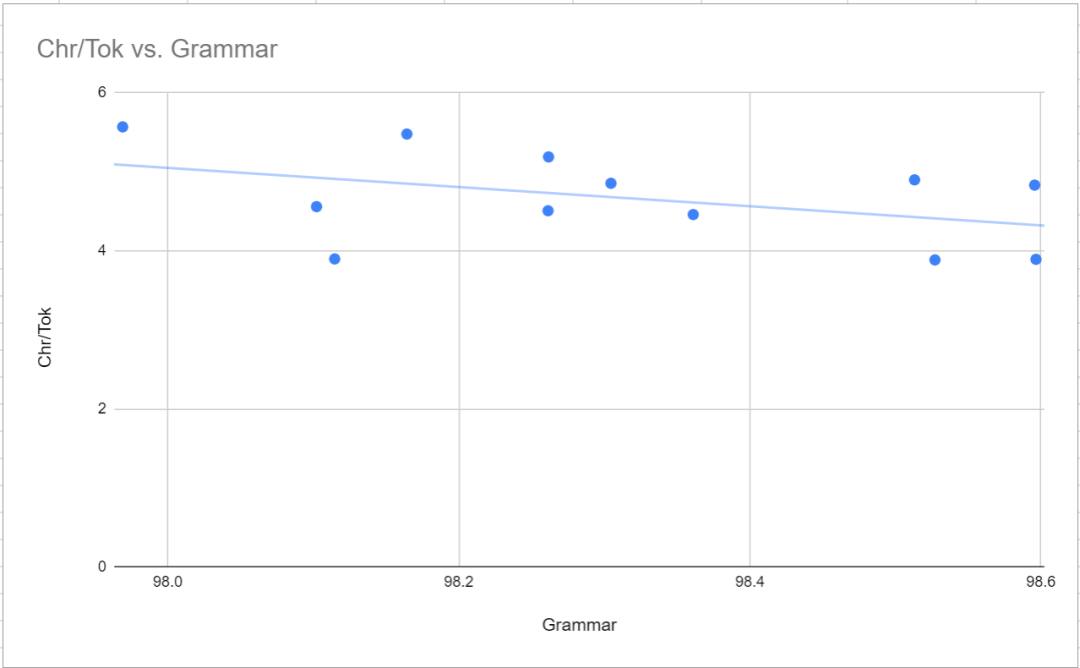
Unter den mittleren Modellen hat p50k_base mit 43,85 den höchsten MTLD, aber auch den niedrigsten Syntax-Score . Der Grund dafür ist unklar, aber die Forscher spekulieren, dass dies an einer seltsamen Auswahl von Trainingsdaten liegen könnte.
Der Zweck des SQuAD-Benchmarks besteht darin, die Fähigkeit eines Modells zu bewerten, Daten aus einem Text zu extrahieren. Die spezifische Methode besteht darin, einen Textabschnitt bereitzustellen und eine Frage zu stellen, wobei die Antwort im Textabschnitt zu finden sein muss. Die Testergebnisse sind nicht sehr aussagekräftig, es gibt keine offensichtlichen Muster oder Korrelationen und sie werden nicht von den Gesamtparametern des Modells beeinflusst. Tatsächlich schnitt das 8000-balancierte Modell mit 91 Millionen Parametern in SQuAD besser ab als das 50256-konsistente Einwort-Modell mit 354 Millionen Parametern. Der Grund dafür kann sein, dass es nicht genügend Beispiele für diesen Stil gibt oder dass der Feinabstimmungsdatensatz zu viele Frage-Antwort-Paare enthält. Oder vielleicht ist dies einfach nur ein weniger als idealer Benchmark
Der SMLQA-Benchmark testet den „Wahrheitswert“, indem er Fragen des gesunden Menschenverstandes mit objektiven Antworten stellt, wie zum Beispiel „Welche Hauptstadt ist Jakarta?“ und „Wer hat die Harry-Potter-Bücher geschrieben?“
Es ist erwähnenswert, dass in diesem Benchmark-Test die beiden Referenz-Tokenizer, GPT-2 Tokenizer und p50k_base, sehr gut abgeschnitten haben. Die Forscher dachten zunächst, sie hätten Monate Zeit und Tausende von Dollar verschwendet, aber es stellte sich heraus, dass Tiktoken besser abschnitt als TokenMonster. Es stellt sich jedoch heraus, dass das Problem mit der Anzahl der Wörter zusammenhängt, die jedem Token entsprechen. Dies ist besonders deutlich im Modell „Medium“ (MEDIUM), wie in der folgenden Abbildung dargestellt. Die Leistung des Einzelwort-Vokabulars ist etwas besser als die Standardeinstellung von TokenMonster, bei der jedes Token mehreren entspricht Wörter-Vokabelliste.
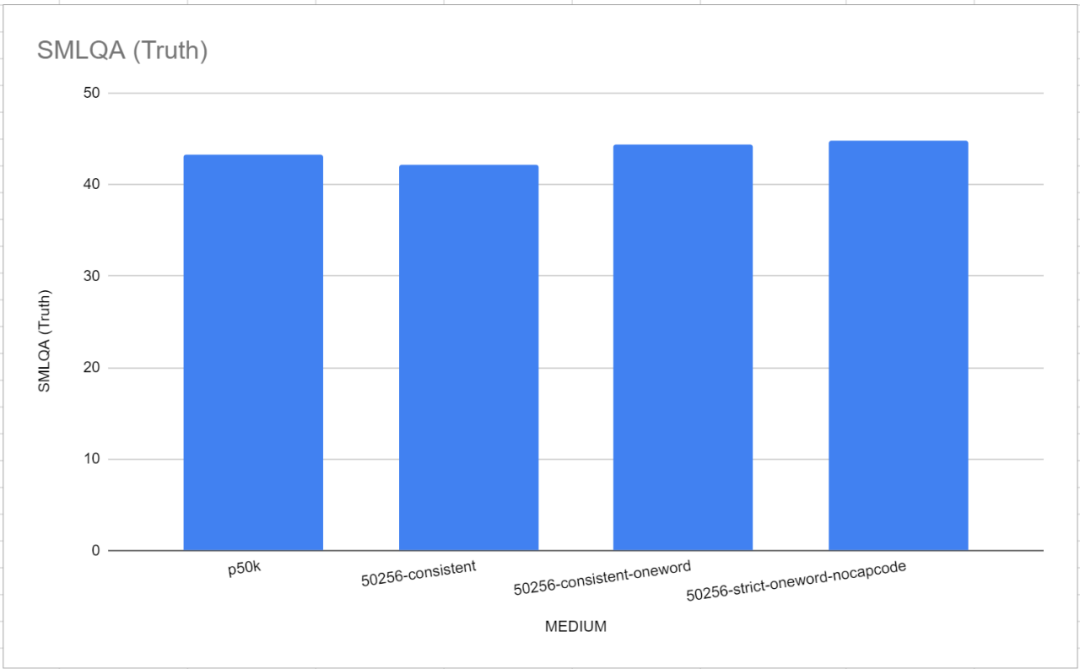 Eine weitere wichtige Beobachtung ist, dass sich die Vokabulargröße direkt auf den wahren Wert auswirkt, wenn die Vokabulargröße unter 32.000 liegt, selbst wenn der n_embd-Parameter des Modells angepasst wird, um die Verringerung der Modellgröße auszugleichen. Dies ist kontraintuitiv, da die Forscher ursprünglich dachten, dass 16000-ausgeglichen mit n_embd von 864 (Parameter von 121,34 Millionen) und 8000-konsistent mit n_embd von 900 (Parameter von 123,86 Millionen) besser wären als 50256-konsistent mit n_embd von 768 (Parameter von). 121,34 Millionen). Allerdings erhielten beide „angepassten“ Modelle die gleiche Trainingszeit, was zu deutlich kürzeren Vortrainingszeiten führte (wenn auch zur gleichen Zeit)
Eine weitere wichtige Beobachtung ist, dass sich die Vokabulargröße direkt auf den wahren Wert auswirkt, wenn die Vokabulargröße unter 32.000 liegt, selbst wenn der n_embd-Parameter des Modells angepasst wird, um die Verringerung der Modellgröße auszugleichen. Dies ist kontraintuitiv, da die Forscher ursprünglich dachten, dass 16000-ausgeglichen mit n_embd von 864 (Parameter von 121,34 Millionen) und 8000-konsistent mit n_embd von 900 (Parameter von 123,86 Millionen) besser wären als 50256-konsistent mit n_embd von 768 (Parameter von). 121,34 Millionen). Allerdings erhielten beide „angepassten“ Modelle die gleiche Trainingszeit, was zu deutlich kürzeren Vortrainingszeiten führte (wenn auch zur gleichen Zeit)
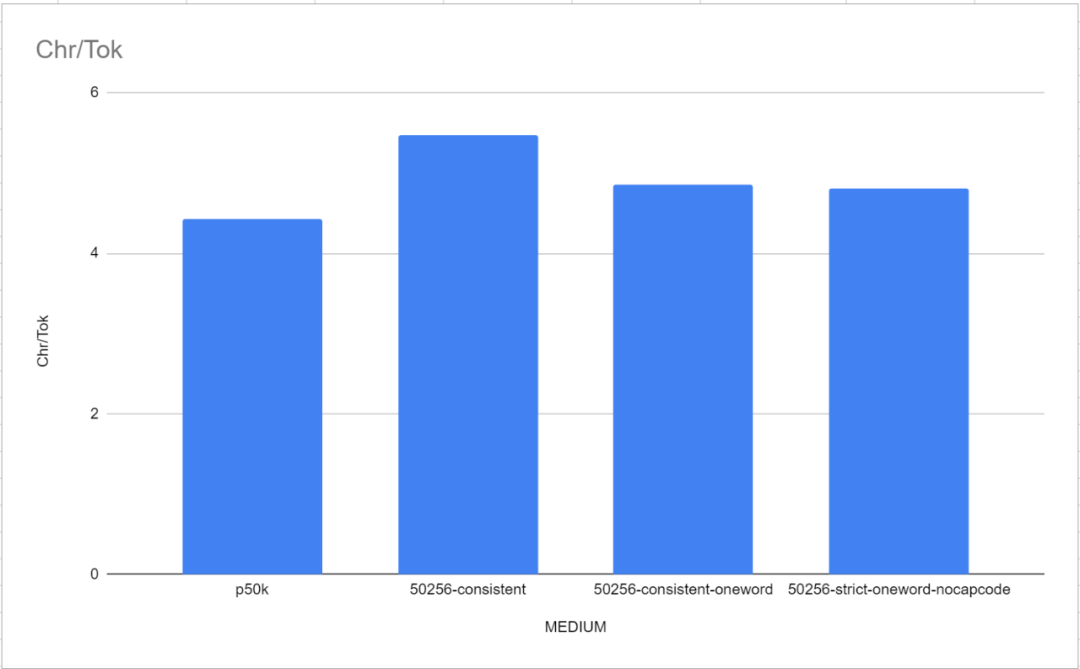
Die Forscher trainierten 12 Modelle auf der Standard-NanoGPT-Architektur. Die Architektur basiert auf der GPT-2-Architektur mit 12 Aufmerksamkeitsköpfen und 12 Schichten und die Einbettungsparametergröße beträgt 768. Keines dieser Modelle hat einen Konvergenzzustand erreicht. Einfach ausgedrückt, haben sie nicht ihre maximale Lernfähigkeit erreicht. Das Modell wurde für 400.000 Iterationen trainiert, aber es scheint, dass 600.000 Iterationen erforderlich sind, um die maximale Lernfähigkeit zu erreichen. Die Gründe für diese Situation sind einfach: Einer ist das Budgetproblem und der andere ist die Unsicherheit des Konvergenzpunkts. Die Ergebnisse des kleinen Modells: Die Pearson-Korrelation des kleinen Modells:
Umgeschriebener Inhalt: Das optimale Vokabelniveau wurde erreicht, als die Vokabelgröße 32.000 betrug. In der Stufe der Wortschatzerweiterung von 8.000 auf 32.000 verbessert die Erhöhung des Wortschatzes die Genauigkeit des Modells. Wenn jedoch die Vokabulargröße von 32.000 auf 50.257 steigt, erhöhen sich auch die Gesamtparameter des Modells entsprechend, die Genauigkeitsverbesserung beträgt jedoch nur 1 %. Nach dem Überschreiten von 32.000 nimmt der Gewinn rapide ab
Ein schlechtes Tokenizer-Design hat Auswirkungen auf die Genauigkeit des Modells, jedoch nicht auf die grammatikalische Korrektheit oder die Sprachvielfalt. Leistung beim Ground-Truth-Benchmark für Tokenizer mit komplexeren grammatikalischen Regeln (z. B. Token, die mehreren Wörtern, Wort- und Satzzeichenkombinationen entsprechen, Capcode-Codierungstoken und Gesamtvokabularreduzierung) im Parameterbereich von 90 Millionen bis 125 Millionen. Schlecht. Dieses ausgefeilte Tokenizer-Design hatte jedoch keinen statistisch signifikanten Einfluss auf die sprachliche Vielfalt oder grammatikalische Korrektheit der generierten Texte. Selbst ein kompaktes Modell, beispielsweise eines mit 90 Millionen Parametern, kann komplexere Marker effektiv nutzen. Das Erlernen komplexerer Vokabeln dauert länger, wodurch sich die Zeit verkürzt, die für den Erwerb von Informationen zu grundlegenden Fakten erforderlich ist. Da keines dieser Modelle vollständig trainiert wurde, bleibt das Potenzial für weiteres Training zur Schließung der Leistungslücke abzuwarten
Umgeschrieben auf Chinesisch: 3. Der Validierungsverlust ist keine gültige Metrik für den Vergleich von Modellen, die verschiedene Tokenizer verwenden. Der Validierungsverlust weist eine sehr starke Korrelation (0,97 Pearson-Korrelation) mit dem Wortverhältnis (der durchschnittlichen Anzahl von Zeichen pro Token) für einen bestimmten Tokenizer auf. Um Verlustwerte zwischen Tokenisierern zu vergleichen, kann es effektiver sein, den Verlust relativ zu Zeichen statt zu Token zu messen, da der Verlustwert proportional zur durchschnittlichen Anzahl von Zeichen ist, die jedem Token entsprechen
4 nicht als Bewertungsmetrik für Sprachmodelle geeignet, da diese Sprachmodelle darauf trainiert sind, Antworten variabler Länge zu generieren (der Abschluss wird durch eine Textendemarkierung angezeigt). Denn je länger die Textsequenz ist, desto schwerwiegender ist die Strafe der F1-Formel. F1-Scores führen tendenziell zu kürzeren Antwortmodellen
Alle Modelle (ab 90 Millionen Parametern) sowie alle getesteten Tokenisierer (im Größenbereich von 8000 bis 50257) haben gezeigt, dass sie eine grammatikalisch kohärente Antwortfähigkeit erzeugen können. Obwohl diese Antworten oft falsch oder illusorisch sind, sind sie alle relativ kohärent und zeigen ein Verständnis für den kontextuellen Hintergrund
Die lexikalische Vielfalt und grammatikalische Genauigkeit des generierten Textes nimmt mit zunehmender Einbettungsgröße deutlich zu und weist eine leicht negative Korrelation mit dem Wort auf Verhältnis. Das bedeutet, dass ein Vokabular mit einem größeren Wort-zu-Wort-Verhältnis das Erlernen der grammatikalischen und lexikalischen Vielfalt etwas schwieriger macht
7 Bei der Anpassung der Modellparametergröße hängt das Wort-zu-Wort-Verhältnis von SMLQA (Ground) ab Truth) oder SQuAD (Information Extraction) ) Es gibt keine statistisch signifikante Korrelation zwischen Benchmarks. Dies bedeutet, dass ein Tokenizer mit einem höheren Wort-zu-Wort-Verhältnis die Leistung des Modells nicht negativ beeinflusst.
Im Vergleich zur Kategorie „Ausgewogen“ scheint die Kategorie „Konsistent“ beim SMLQA-Benchmark (Ground Truth) etwas besser abzuschneiden, beim SQuAD-Benchmark (Information Extraction) jedoch deutlich schlechter. Obwohl weitere Daten erforderlich sind, um dies zu bestätigen
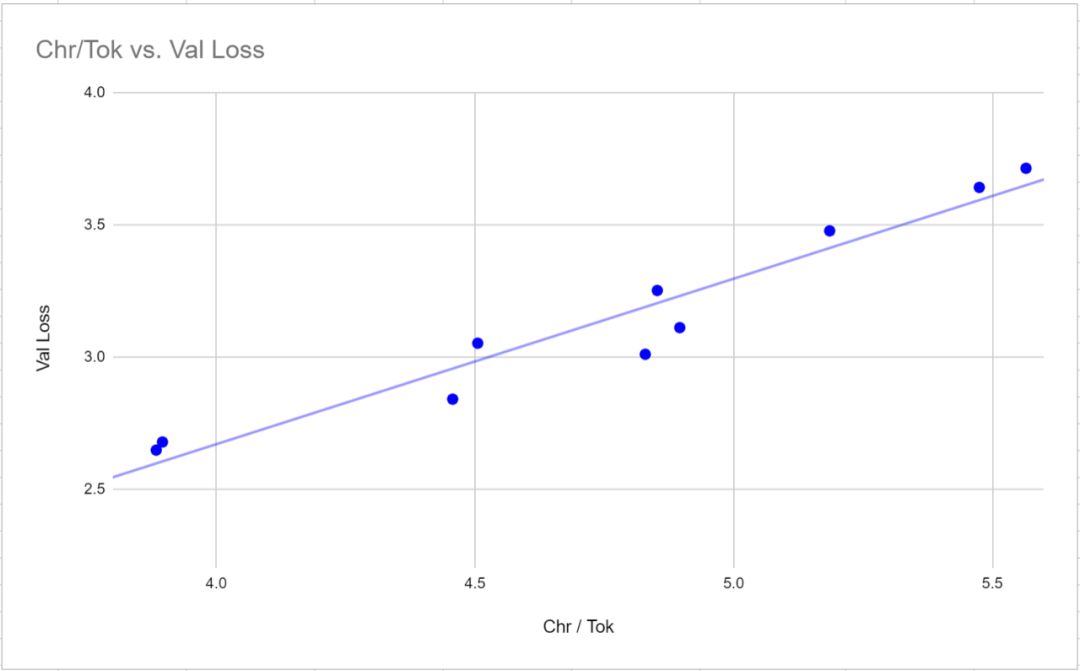
Nach dem Training und Benchmarking des kleinen Modells stellte die Studie fest, dass der Forscher dies eindeutig herausgefunden hat Die gemessenen Ergebnisse spiegelten eher die Lerngeschwindigkeit des Modells als die Lernfähigkeit des Modells wider. Darüber hinaus haben die Forscher das Rechenpotenzial der GPU nicht optimiert, da die Standard-NanoGPT-Parameter verwendet wurden. Um dieses Problem zu lösen, entschieden sich die Forscher für die Verwendung eines Tokenizers mit 50257 Token und einem Mittelsprachenmodell, um vier Varianten zu untersuchen. Die Forscher passten die Batch-Größe von 12 auf 36 an und reduzierten die Blockgröße von 1024 auf 256, um die volle Nutzung der VRAM-Funktionen der 24-GB-GPU sicherzustellen. Dann wurden 600.000 Iterationen statt 400.000 wie beim kleineren Modell durchgeführt. Das Vortraining für jedes Modell dauerte durchschnittlich etwas mehr als 18 Tage, dreimal so viel wie bei kleineren Modellen.
Das Training des Modells auf Konvergenz verringert den Leistungsunterschied zwischen einfacheren und komplexeren Vokabularien erheblich. Die Benchmark-Ergebnisse von SMLQA (Ground Truth) und SQuAD (Data Extraction) liegen sehr nahe beieinander. Der Hauptunterschied besteht darin, dass 50256-konsistent den Vorteil eines um 23,5 % höheren Wortverhältnisses als p50k_base hat. Bei Vokabularien mit mehreren Wörtern pro Token ist der Leistungsaufwand für Wahrheitswerte jedoch geringer. Dies kann jedoch mit der Methode gelöst werden, die ich oben auf der Seite besprochen habe. Ergebnisse der Modelle in
:
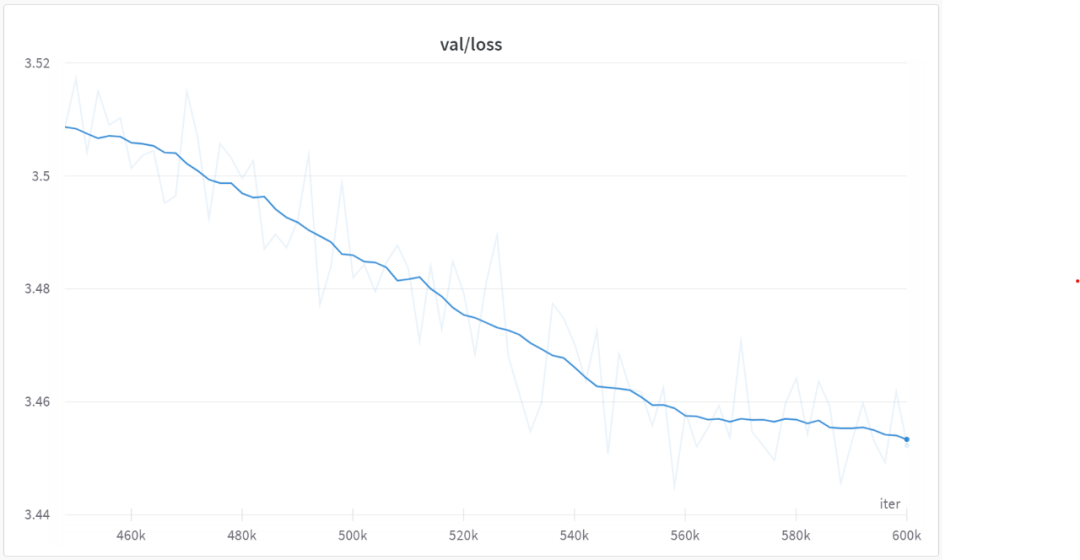
Nach 560000 Iterationen begannen alle Modelle zu konvergieren, wie in der folgenden Abbildung dargestellt:
In der nächsten Phase werden wir englishcode-32000-consistent verwenden, um das Modell von MEDIUM zu trainieren und zu vergleichen. Dieser Wortschatz besteht zu 80 % aus Wort-Tokens und zu 20 % aus Mehrwort-Tokens
Das obige ist der detaillierte Inhalt vonUntersuchung der Auswirkungen der Vokabelauswahl auf das Sprachmodelltraining: Eine bahnbrechende Studie. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 So aktivieren Sie den Douyin-Gruppenkauf
So aktivieren Sie den Douyin-Gruppenkauf
 Mindestkonfigurationsanforderungen für das Win10-System
Mindestkonfigurationsanforderungen für das Win10-System
 So lösen Sie Probleme beim Parsen von Paketen
So lösen Sie Probleme beim Parsen von Paketen
 So kündigen Sie ein Douyin-Konto bei Douyin
So kündigen Sie ein Douyin-Konto bei Douyin
 Der Unterschied zwischen vue2.0 und 3.0
Der Unterschied zwischen vue2.0 und 3.0
 Verbunden, aber kein Zugriff auf das Internet möglich
Verbunden, aber kein Zugriff auf das Internet möglich
 Warum kommt vom Computer kein Ton?
Warum kommt vom Computer kein Ton?
 So lösen Sie devc-chinesische verstümmelte Zeichen
So lösen Sie devc-chinesische verstümmelte Zeichen








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



