

Diese Woche wurde in Paris, Frankreich, die International Conference on Computer Vision (ICCV) eröffnet.

Als weltweit führende akademische Konferenz im Bereich Computer Vision findet die ICCV alle zwei Jahre statt.
Wie CVPR hat auch die Popularität von ICCV neue Höchststände erreicht.
Bei der heutigen Eröffnungszeremonie gab ICCV offiziell die diesjährigen Papierdaten bekannt: Die Gesamtzahl der Einreichungen bei diesem ICCV erreichte 8068, von denen 2160 angenommen wurden, mit einer Annahmequote von 26,8 %, etwas höher als beim vorherigen ICCV 2021 Die Akzeptanzrate liegt bei 25,9 %
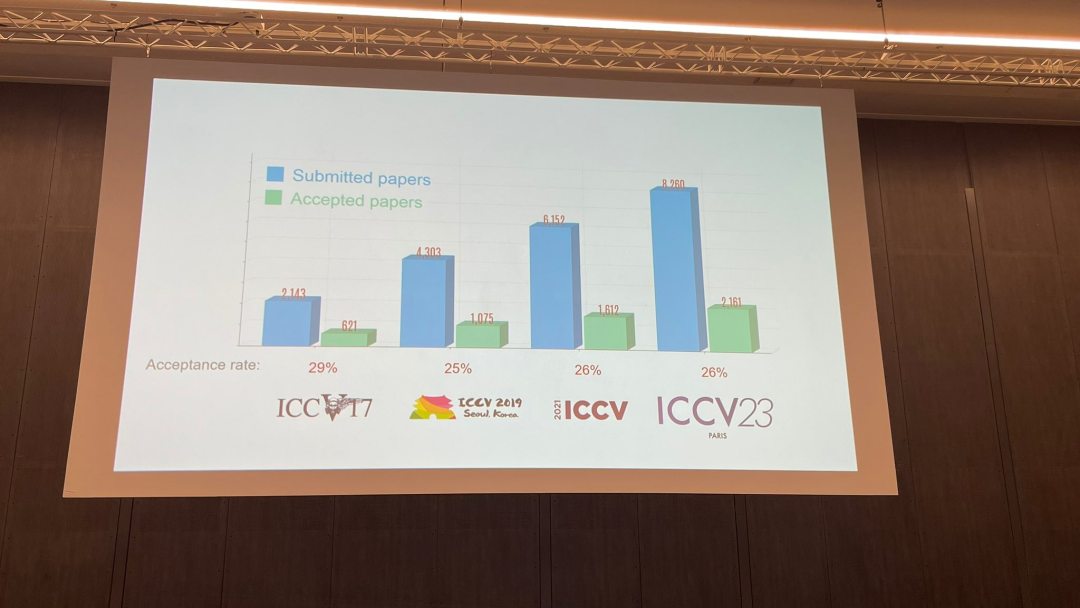
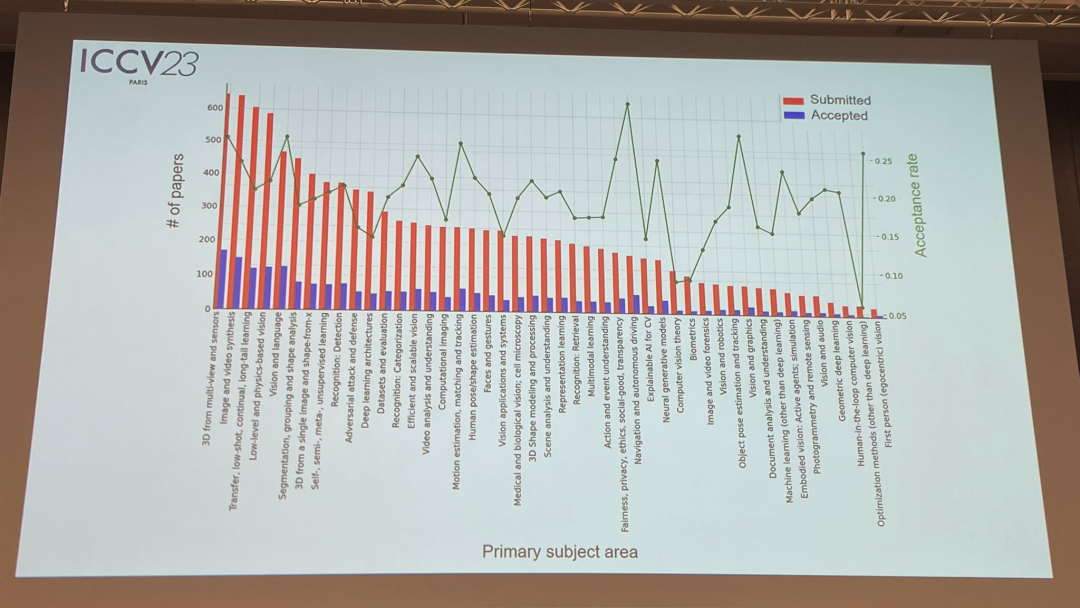
Zum Papierthema veröffentlichte der Beamte auch relevante Daten: 3D-Technologie mit mehreren Perspektiven und Sensoren ist am beliebtesten
Bei der heutigen Eröffnungsfeier am wichtigsten Teil Es ist die Gewinninformation bekannt zu geben. Lassen Sie uns nun nacheinander die beste Arbeit, die beste Nominierung für die beste Arbeit und die beste studentische Arbeit bekannt geben.
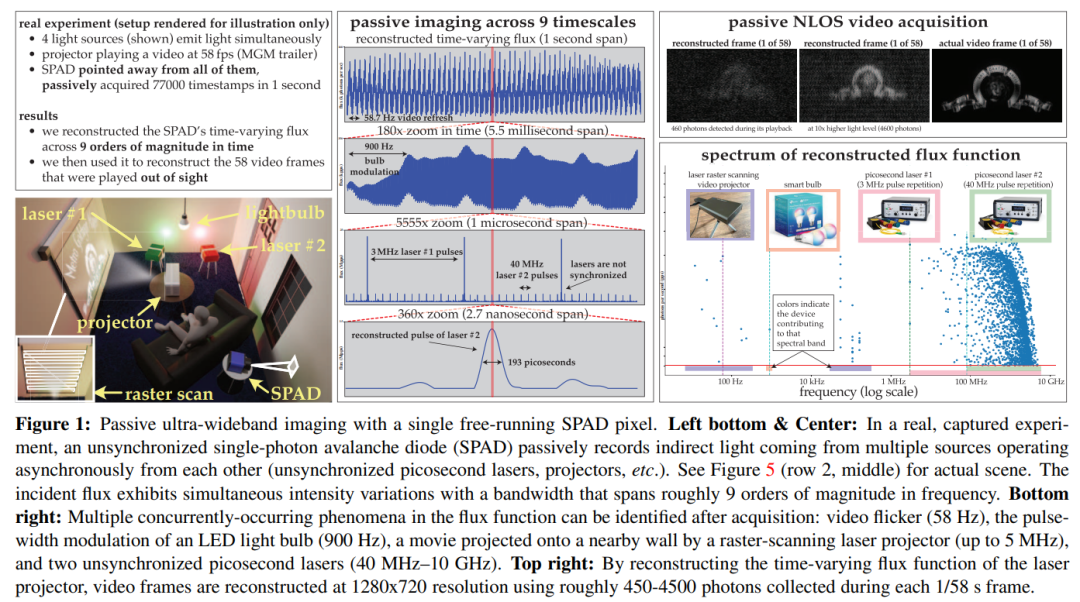
Papieradresse: https://openaccess.thecvf.com/content/ICCV2023/papers/Wei_Passive_Ultra-Wideband_Single-Photon_Imaging_ICCV_2023_paper.pdf
Autor: Mian Wei, Sotiris Nousias, Rahul Gulve, David B. Lindell, Kiriakos N. Kutulakos
Durch Experimente demonstriert Das Potenzial davon Der asynchrone Abbildungsmechanismus ist: (1) Abbildung von Szenen, die gleichzeitig von Lichtquellen (z. B. Glühbirnen, Projektoren, mehrfach gepulsten Lasern) beleuchtet werden, die mit unterschiedlichen Geschwindigkeiten arbeiten, ohne dass eine Synchronisierung erforderlich ist; Sicht Videoerfassung; (3) Nehmen Sie Ultrabreitbandvideos auf und spielen Sie sie später mit 30 Hz ab, um die tägliche Bewegung anzuzeigen, oder spielen Sie sie eine Milliarde Mal langsamer ab, um die Ausbreitung des Lichts selbst zu zeigen
Teil 2 Es ist das, was wir als ControNet kennen.
Papieradresse: https://arxiv.org/pdf/2302.05543.pdf
Autoren: Lvmin Zhang, Anyi Rao, Maneesh Agrawala
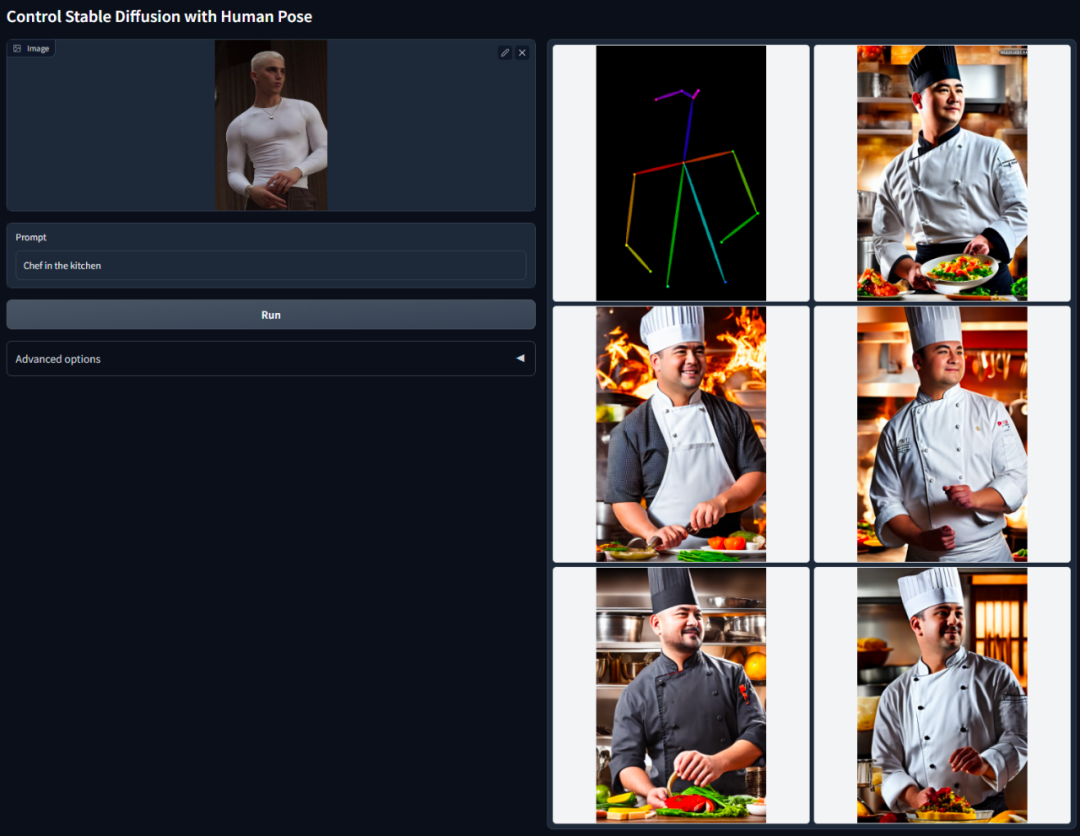
Die Kernidee von ControlNet besteht darin, der Textbeschreibung einige zusätzliche Bedingungen hinzuzufügen, um das Diffusionsmodell zu steuern (z. B. stabile Diffusion), wodurch die Pose, Tiefe, Bildstruktur und andere Informationen des generierten Bilds besser gesteuert werden können.
Die zusätzlichen Bedingungen werden hier in Form eines Bildes eingegeben. Das Modell kann darauf basierend eine Canny-Kantenerkennung, Tiefenerkennung, semantische Segmentierung, Hough-Transformationslinienerkennung, Gesamtverschachtelte Kantenerkennung (HED) und eine menschliche Haltung durchführen Eingabebilderkennung usw. und behalten Sie diese Informationen dann im generierten Bild bei. Mit diesem Modell können wir Strichzeichnungen oder Graffiti direkt in Vollfarbbilder umwandeln, Bilder mit derselben Tiefenstruktur usw. erzeugen und die Generierung von Charakterhänden durch Handschlüsselpunkte optimieren.
Eine ausführlichere Einführung finden Sie im Bericht „KI-Dimensionalitätsreduktion trifft menschliche Maler, vinzentinische Diagramme werden in ControlNet eingeführt und Tiefen- und Kanteninformationen werden vollständig wiederverwendet“ von Heart of the Machine
Im April dieses Jahres veröffentlichte Meta ein künstliches Intelligenzmodell namens „Segment Everything (SAM)“, das Masken für Objekte in jedem Bild oder Video generieren kann vision Ich war sehr schockiert, einige sagten sogar: „Computer Vision gibt es nicht mehr“
Jetzt wurde dieser mit Spannung erwartete Beitrag für den besten Beitrag nominiert.

Umgeschriebener Inhalt: Vor der Lösung des Segmentierungsproblems gibt es normalerweise zwei Methoden. Die erste ist die interaktive Segmentierung, die zum Segmentieren jeder Objektklasse verwendet werden kann, erfordert jedoch, dass ein Mensch die Methode durch iteratives Verfeinern der Maske steuert. Die zweite ist die automatische Segmentierung, die zum Segmentieren vordefinierter spezifischer Objektkategorien (z. B. Katzen oder Stühle) verwendet werden kann, für das Training jedoch eine große Anzahl manuell annotierter Objekte erfordert (z. B. Tausende oder sogar Zehntausende Beispiele segmentierter Katzen). . Allerdings bietet keine dieser beiden Methoden eine universelle, vollautomatische Segmentierungsmethode
Das von Meta vorgeschlagene SAM fasst diese beiden Methoden gut zusammen. Es handelt sich um ein einzelnes Modell, das problemlos interaktive Segmentierung und automatische Segmentierung durchführen kann. Die aufforderungsfähige Schnittstelle des Modells ermöglicht Benutzern eine flexible Verwendung. Durch einfaches Entwerfen der richtigen Eingabeaufforderungen für das Modell (Klicks, Feldauswahl, Text usw.) kann eine breite Palette von Segmentierungsaufgaben ausgeführt werden
Um es zusammenzufassen Diese Funktionen ermöglichen es SAM, sich an neue Aufgaben und Bereiche anzupassen. Diese Flexibilität ist einzigartig im Bereich der Bildsegmentierung
Weitere Informationen finden Sie im Machine Heart-Bericht: „CV Doesn't Exist?“ Meta veröffentlicht „Alles aufteilen“-KI-Modell, Lebenslauf könnte den GPT-3-Moment einläuten》
Diese Forschung wurde gemeinsam von Forschern der Cornell University, Google Research und der UC Berkeley durchgeführt, der Erstautor ist Qianqian Wang, ein Doktorand von Cornell Tech. Sie schlugen gemeinsam OmniMotion vor, eine vollständige und global konsistente Bewegungsdarstellung, und schlugen eine neue Methode zur Testzeitoptimierung vor, um eine genaue und vollständige Bewegungsschätzung für jedes Pixel im Video durchzuführen.

Zusammenfassung: Im Bereich Computer Vision Es gibt zwei häufig verwendete Methoden zur Bewegungsschätzung: Spärliche Merkmalsverfolgung und dichter optischer Fluss. Allerdings haben beide Methoden ihre eigenen Nachteile. Die Verfolgung von Sparse-Features kann nicht die Bewegung aller Pixel modellieren;
Das in dieser Forschung vorgeschlagene OmniMotion verwendet ein quasi-3D-kanonisches Volumen zur Darstellung des Videos und verfolgt jedes Pixel durch eine Bijektion zwischen lokalem Raum und kanonischem Raum. Diese Darstellung ermöglicht globale Konsistenz, ermöglicht Bewegungsverfolgung auch bei verdeckten Objekten und modelliert jede Kombination aus Kamera- und Objektbewegung. Diese Studie zeigt experimentell, dass die vorgeschlagene Methode bestehende SOTA-Methoden deutlich übertrifft.
Eine ausführlichere Einführung finden Sie im Heart of Machine-Bericht „Der „Tracking Everything“-Videoalgorithmus, der jedes Pixel jederzeit und überall verfolgt und keine Angst vor Okklusion hat“ für eine detailliertere Einführung
Zusätzlich zu diesen preisgekrönten Siegerbeiträge, auch der diesjährige ICCV. Es gibt viele andere hervorragende Beiträge, die Ihre Aufmerksamkeit verdienen. Nachfolgend finden Sie die erste Liste der 17 Gewinnerbeiträge

Das obige ist der detaillierte Inhalt vonICCV 2023 gab die Gewinner beliebter Veröffentlichungen wie ControlNet und „Split Everything' bekannt.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Lösungen für unbekannte Software-Ausnahmen in Computeranwendungen
Lösungen für unbekannte Software-Ausnahmen in Computeranwendungen
 Komplementalgorithmus für negative Zahlen
Komplementalgorithmus für negative Zahlen
 Verwendung der Rowcount-Funktion
Verwendung der Rowcount-Funktion
 Datenbank-Er-Diagramm
Datenbank-Er-Diagramm
 So überprüfen Sie tote Links auf Websites
So überprüfen Sie tote Links auf Websites
 So stellen Sie aus dem Papierkorb geleerte Dateien wieder her
So stellen Sie aus dem Papierkorb geleerte Dateien wieder her
 Die Rolle der klonbaren Schnittstelle
Die Rolle der klonbaren Schnittstelle
 So verwenden Sie die magnetische Btbook-Suche
So verwenden Sie die magnetische Btbook-Suche








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



