
 Technologie-Peripheriegeräte
KI
LeCun war zutiefst enttäuscht über den Betrug mit selbstfahrenden Einhörnern
Technologie-Peripheriegeräte
KI
LeCun war zutiefst enttäuscht über den Betrug mit selbstfahrenden Einhörnern
LeCun war zutiefst enttäuscht über den Betrug mit selbstfahrenden Einhörnern

Glauben Sie, dass dies ein gewöhnliches selbstfahrendes Video ist?
 Bilder
Bilder
Dieser Inhalt muss ins Chinesische umgeschrieben werden, ohne die ursprüngliche Bedeutung zu ändern
Kein einziges Bild ist „echt“.
 Bilder
Bilder
Verschiedene Straßenbedingungen, verschiedene Wetterbedingungen und mehr als 20 Situationen können simuliert werden, und der Effekt ist genau wie im Original.
 Bilder
Bilder
Das Weltmodell hat wieder tolle Arbeit geleistet! LeCun hat dies begeistert retweetet, nachdem er es gesehen hat.
 Bilder
Bilder
Den oben genannten Effekten wird dies durch die neueste Version von GAIA-1 erreicht
Der Umfang dieses Projekts hat 9 Milliarden Parameter erreicht und wurde durch 4700 Stunden Fahrvideotraining erfolgreich erreicht Das Eingabevideo. Der unmittelbarste Vorteil der Generierung selbstfahrender Videos aus Text oder Vorgängen besteht darin, dass zukünftige Ereignisse besser vorhergesagt werden können und mehr als 20 Szenarien simuliert werden können, wodurch die Sicherheit des selbstfahrenden Fahrens weiter verbessert und die Kosten gesenkt werden.
Bilder Unser Kreativteam hat unverblümt erklärt, dass dies die Regeln des autonomen Fahrspiels völlig ändern wird!
Unser Kreativteam hat unverblümt erklärt, dass dies die Regeln des autonomen Fahrspiels völlig ändern wird!
Wie wird GAIA-1 umgesetzt? „Je größer der Maßstab, desto besser.“ Verhalten und Szenenmerkmale
Videos können nur mithilfe von Textaufforderungen generiert werden
Bilder
Das Modellprinzip ähnelt großen Sprachmodellen, d Die Videobilder und die anschließende Vorhersage zukünftiger Szenen werden in die Vorhersage des nächsten Tokens in der Sequenz umgewandelt. Das Diffusionsmodell wird dann verwendet, um hochwertige Videos aus dem Sprachraum des Weltmodells zu generieren. Die spezifischen Schritte sind wie folgt: Bilder
Bilder
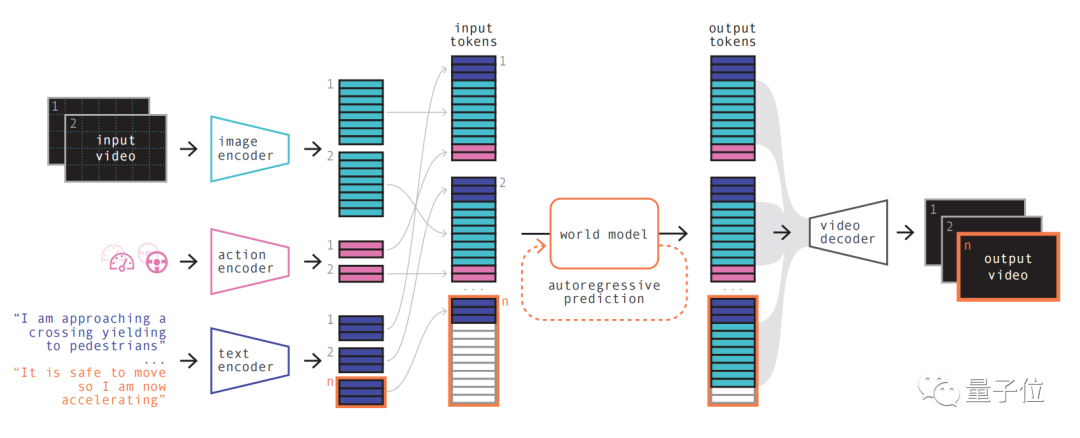 Als autoregressiver Transformer kann er den nächsten Satz von Bild-Tokens in der Sequenz vorhersagen. Und es berücksichtigt nicht nur das vorherige Bild-Token, sondern auch die Kontextinformationen des Textes und der Operation. Der vom Modell generierte Inhalt behält nicht nur die Konsistenz des Bildes bei, sondern stimmt auch mit dem vorhergesagten Text und den vorhergesagten Aktionen überein
Als autoregressiver Transformer kann er den nächsten Satz von Bild-Tokens in der Sequenz vorhersagen. Und es berücksichtigt nicht nur das vorherige Bild-Token, sondern auch die Kontextinformationen des Textes und der Operation. Der vom Modell generierte Inhalt behält nicht nur die Konsistenz des Bildes bei, sondern stimmt auch mit dem vorhergesagten Text und den vorhergesagten Aktionen überein
Das Team stellte fest, dass die Weltmodellgröße in GAIA-1 6,5 Milliarden Parameter beträgt und auf 64 trainiert wurde A100s für 15 Tage.
Verwenden Sie abschließend den Videodecoder und das Videodiffusionsmodell, um diese Token wieder in Videos umzuwandeln.
Die Bedeutung dieses Schritts besteht darin, die semantische Qualität, Bildgenauigkeit und zeitliche Konsistenz des Videos sicherzustellen.
Der Videodecoder von GAIA-1 verfügt über eine Skala von 2,6 Milliarden Parametern und wurde 15 Tage lang mit 32 A100 trainiert.
Es ist erwähnenswert, dass GAIA-1 nicht nur dem Prinzip großer Sprachmodelle ähnelt, sondern auch die Merkmale einer verbesserten Generierungsqualität mit zunehmender Modellskala aufweist
Bilder
Das Team überprüfte die zuvor veröffentlicht im Juni Die frühe Version und der neueste Effekt wurden verglichen Letzterer ist 480-mal größer als ersterer. Sie können intuitiv erkennen, dass die Videodetails und die Auflösung deutlich verbessert wurden.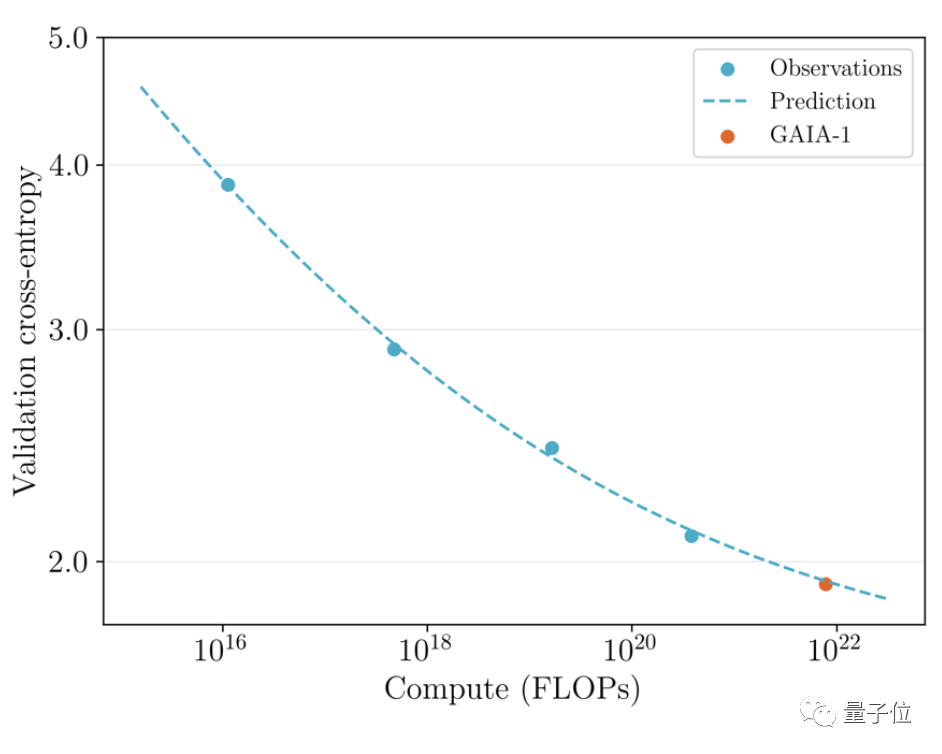 Bilder
Bilder
 Bilder
Bilder
Die Gründe lassen sich aus drei Aspekten erklären:
- Sicherheit
- Umfassende Trainingsdaten
- Long-Tail-Szenario
Zuallererst kann das Weltmodell in Bezug auf die Sicherheit die Zukunft simulieren. Geben Sie der KI die Möglichkeit, Ihre eigenen Entscheidungen zu treffen, was für die Sicherheit des autonomen Fahrens von entscheidender Bedeutung ist.
Zweitens sind Trainingsdaten auch für das autonome Fahren sehr wichtig. Die generierten Daten sind sicherer, kostengünstiger und unbegrenzt skalierbar. Generative KI kann eine der Long-Tail-Szenario-Herausforderungen beim autonomen Fahren lösen. Es kann mehr Randszenarien bewältigen, beispielsweise die Begegnung mit Fußgängern, die bei nebligem Wetter die Straße überqueren. Dadurch werden die Möglichkeiten des autonomen Fahrens weiter verbessert
Wer ist Wayve?
GAIA-1 wurde vom britischen selbstfahrenden Startup Wayve entwickelt.
Wayve wurde 2017 gegründet. Zu den Investoren zählen Microsoft und andere, und seine Bewertung hat Einhorn erreicht.
Die Gründer sind Alex Kendall und Amar Shah, die beide einen Doktortitel in maschinellem Lernen von der Universität Cambridge haben haben die hochpräzisen Karten schon sehr früh aufgegeben und sind konsequent dem Weg der „Echtzeitwahrnehmung“ gefolgt.
Vor nicht allzu langer Zeit erregte auch ein weiteres vom Team veröffentlichtes großes Modell LINGO-1 große Aufmerksamkeit
Dieses autonome Fahrmodell kann während der Fahrt Erklärungen in Echtzeit generieren und so die Interpretierbarkeit des Modells weiter verbessern Im März dieses Jahres Auch Bill Gates machte eine Probefahrt mit Wayves selbstfahrendem Auto.
Im März dieses Jahres Auch Bill Gates machte eine Probefahrt mit Wayves selbstfahrendem Auto.
Papieradresse:
https://www.php.cn/link/1f8c4b6a0115a4617e285b4494126fbfReferenzlink:  [1]https://www.php.cn/link/ 85dca1d 270f7f9aef00c9d372f114482 [2]
[1]https://www.php.cn/link/ 85dca1d 270f7f9aef00c9d372f114482 [2]
Das obige ist der detaillierte Inhalt vonLeCun war zutiefst enttäuscht über den Betrug mit selbstfahrenden Einhörnern. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1384
1384
 52
52

 Wie lässt sich das Long-Tail-Problem in autonomen Fahrszenarien lösen?
Jun 02, 2024 pm 02:44 PM
Wie lässt sich das Long-Tail-Problem in autonomen Fahrszenarien lösen?
Jun 02, 2024 pm 02:44 PM
Gestern wurde ich während des Interviews gefragt, ob ich irgendwelche Long-Tail-Fragen gestellt hätte, also dachte ich, ich würde eine kurze Zusammenfassung geben. Das Long-Tail-Problem des autonomen Fahrens bezieht sich auf Randfälle bei autonomen Fahrzeugen, also mögliche Szenarien mit geringer Eintrittswahrscheinlichkeit. Das wahrgenommene Long-Tail-Problem ist einer der Hauptgründe, die derzeit den betrieblichen Designbereich intelligenter autonomer Einzelfahrzeugfahrzeuge einschränken. Die zugrunde liegende Architektur und die meisten technischen Probleme des autonomen Fahrens wurden gelöst, und die verbleibenden 5 % der Long-Tail-Probleme wurden nach und nach zum Schlüssel zur Einschränkung der Entwicklung des autonomen Fahrens. Zu diesen Problemen gehören eine Vielzahl fragmentierter Szenarien, Extremsituationen und unvorhersehbares menschliches Verhalten. Der „Long Tail“ von Randszenarien beim autonomen Fahren bezieht sich auf Randfälle in autonomen Fahrzeugen (AVs). Randfälle sind mögliche Szenarien mit geringer Eintrittswahrscheinlichkeit. diese seltenen Ereignisse
 Jenseits von ORB-SLAM3! SL-SLAM: Szenen mit wenig Licht, starkem Jitter und schwacher Textur werden verarbeitet
May 30, 2024 am 09:35 AM
Jenseits von ORB-SLAM3! SL-SLAM: Szenen mit wenig Licht, starkem Jitter und schwacher Textur werden verarbeitet
May 30, 2024 am 09:35 AM
Heute diskutieren wir darüber, wie Deep-Learning-Technologie die Leistung von visionbasiertem SLAM (Simultaneous Localization and Mapping) in komplexen Umgebungen verbessern kann. Durch die Kombination von Methoden zur Tiefenmerkmalsextraktion und Tiefenanpassung stellen wir hier ein vielseitiges hybrides visuelles SLAM-System vor, das die Anpassung in anspruchsvollen Szenarien wie schlechten Lichtverhältnissen, dynamischer Beleuchtung, schwach strukturierten Bereichen und starkem Jitter verbessern soll. Unser System unterstützt mehrere Modi, einschließlich erweiterter Monokular-, Stereo-, Monokular-Trägheits- und Stereo-Trägheitskonfigurationen. Darüber hinaus wird analysiert, wie visuelles SLAM mit Deep-Learning-Methoden kombiniert werden kann, um andere Forschungen zu inspirieren. Durch umfangreiche Experimente mit öffentlichen Datensätzen und selbst abgetasteten Daten demonstrieren wir die Überlegenheit von SL-SLAM in Bezug auf Positionierungsgenauigkeit und Tracking-Robustheit.
 Sprechen wir über End-to-End- und autonome Fahrsysteme der nächsten Generation sowie über einige Missverständnisse über End-to-End-Autonomes Fahren?
Apr 15, 2024 pm 04:13 PM
Sprechen wir über End-to-End- und autonome Fahrsysteme der nächsten Generation sowie über einige Missverständnisse über End-to-End-Autonomes Fahren?
Apr 15, 2024 pm 04:13 PM
Im vergangenen Monat hatte ich aus bekannten Gründen einen sehr intensiven Austausch mit verschiedenen Lehrern und Mitschülern der Branche. Ein unvermeidliches Thema im Austausch ist natürlich End-to-End und der beliebte Tesla FSDV12. Ich möchte diese Gelegenheit nutzen, einige meiner aktuellen Gedanken und Meinungen als Referenz und Diskussion darzulegen. Wie definiert man ein durchgängiges autonomes Fahrsystem und welche Probleme sollten voraussichtlich durchgängig gelöst werden? Gemäß der traditionellsten Definition bezieht sich ein End-to-End-System auf ein System, das Rohinformationen von Sensoren eingibt und für die Aufgabe relevante Variablen direkt ausgibt. Bei der Bilderkennung kann CNN beispielsweise als End-to-End bezeichnet werden, verglichen mit der herkömmlichen Methode zum Extrahieren von Merkmalen + Klassifizieren. Bei autonomen Fahraufgaben werden Eingabedaten verschiedener Sensoren (Kamera/LiDAR) benötigt
 nuScenes' neuestes SOTA |. SparseAD: Sparse-Abfrage hilft effizientes durchgängiges autonomes Fahren!
Apr 17, 2024 pm 06:22 PM
nuScenes' neuestes SOTA |. SparseAD: Sparse-Abfrage hilft effizientes durchgängiges autonomes Fahren!
Apr 17, 2024 pm 06:22 PM
Vorab geschrieben und Ausgangspunkt Das End-to-End-Paradigma verwendet ein einheitliches Framework, um Multitasking in autonomen Fahrsystemen zu erreichen. Trotz der Einfachheit und Klarheit dieses Paradigmas bleibt die Leistung von End-to-End-Methoden für das autonome Fahren bei Teilaufgaben immer noch weit hinter Methoden für einzelne Aufgaben zurück. Gleichzeitig erschweren die in früheren End-to-End-Methoden weit verbreiteten Funktionen der dichten Vogelperspektive (BEV) die Skalierung auf mehr Modalitäten oder Aufgaben. Hier wird ein Sparse-Search-zentriertes End-to-End-Paradigma für autonomes Fahren (SparseAD) vorgeschlagen, bei dem die Sparse-Suche das gesamte Fahrszenario, einschließlich Raum, Zeit und Aufgaben, ohne dichte BEV-Darstellung vollständig abbildet. Insbesondere ist eine einheitliche, spärliche Architektur für die Aufgabenerkennung einschließlich Erkennung, Verfolgung und Online-Zuordnung konzipiert. Zudem schwer
 FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
Die Zielerkennung ist ein relativ ausgereiftes Problem in autonomen Fahrsystemen, wobei die Fußgängererkennung einer der ersten Algorithmen ist, die eingesetzt werden. In den meisten Arbeiten wurde eine sehr umfassende Recherche durchgeführt. Die Entfernungswahrnehmung mithilfe von Fischaugenkameras für die Rundumsicht ist jedoch relativ wenig untersucht. Aufgrund der großen radialen Verzerrung ist es schwierig, die standardmäßige Bounding-Box-Darstellung in Fischaugenkameras zu implementieren. Um die obige Beschreibung zu vereinfachen, untersuchen wir erweiterte Begrenzungsrahmen-, Ellipsen- und allgemeine Polygondesigns in Polar-/Winkeldarstellungen und definieren eine mIOU-Metrik für die Instanzsegmentierung, um diese Darstellungen zu analysieren. Das vorgeschlagene Modell „fisheyeDetNet“ mit polygonaler Form übertrifft andere Modelle und erreicht gleichzeitig 49,5 % mAP auf dem Valeo-Fisheye-Kameradatensatz für autonomes Fahren
 Tesla ergreift endlich Maßnahmen! Werden bald selbstfahrende Taxis vorgestellt? !
Apr 08, 2024 pm 05:49 PM
Tesla ergreift endlich Maßnahmen! Werden bald selbstfahrende Taxis vorgestellt? !
Apr 08, 2024 pm 05:49 PM
Laut Nachrichten vom 8. April gab Tesla-CEO Elon Musk kürzlich bekannt, dass Tesla sich der vollständigen Entwicklung selbstfahrender Autotechnologie verschrieben hat. Das mit Spannung erwartete unbemannte selbstfahrende Taxi Robotaxi wird am 8. August auf den Markt kommen. Offizielles Debüt. Der Datenredakteur erfuhr, dass Musks Aussage auf Zuvor berichtete Reuters, dass Teslas Plan, Autos anzutreiben, sich auf die Produktion von Robotaxi konzentrieren würde. Musk wies dies jedoch zurück und warf Reuters vor, Pläne zur Entwicklung von Billigautos abgesagt und erneut Falschmeldungen veröffentlicht zu haben, während er gleichzeitig klarstellte, dass es sich um Billigautos wie Model 2 und Robotax handelte
 Tesla Dojo-Supercomputing-Debüt, Musk: Die Rechenleistung der Trainings-KI wird bis Ende des Jahres etwa 8.000 NVIDIA H100-GPUs entsprechen
Jul 24, 2024 am 10:38 AM
Tesla Dojo-Supercomputing-Debüt, Musk: Die Rechenleistung der Trainings-KI wird bis Ende des Jahres etwa 8.000 NVIDIA H100-GPUs entsprechen
Jul 24, 2024 am 10:38 AM
Laut Nachrichten dieser Website vom 24. Juli erklärte Tesla-CEO Elon Musk (Elon Musk) in der heutigen Telefonkonferenz zu den Ergebnissen, dass das Unternehmen kurz vor der Fertigstellung des bisher größten Schulungsclusters für künstliche Intelligenz stehe, das mit 2.000 NVIDIA H100 ausgestattet sein werde GPUs. Musk teilte den Anlegern bei der Gewinnmitteilung des Unternehmens auch mit, dass Tesla an der Entwicklung seines Dojo-Supercomputers arbeiten werde, da GPUs von Nvidia teuer seien. Diese Seite übersetzte einen Teil von Musks Rede wie folgt: Der Weg, über Dojo mit NVIDIA zu konkurrieren, ist schwierig, aber ich denke, wir haben keine andere Wahl. Wir sind jetzt zu sehr auf NVIDIA angewiesen. Aus der Sicht von NVIDIA werden sie den Preis für GPUs unweigerlich auf ein Niveau erhöhen, das der Markt ertragen kann, aber
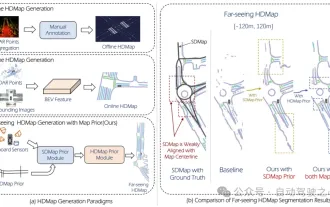 Massenproduktionskiller! P-Mapnet: Durch die vorherige Verwendung der Karte SDMap mit niedriger Genauigkeit wird die Kartenleistung deutlich um fast 20 Punkte verbessert!
Mar 28, 2024 pm 02:36 PM
Massenproduktionskiller! P-Mapnet: Durch die vorherige Verwendung der Karte SDMap mit niedriger Genauigkeit wird die Kartenleistung deutlich um fast 20 Punkte verbessert!
Mar 28, 2024 pm 02:36 PM
Wie oben geschrieben, besteht einer der Algorithmen, mit denen aktuelle autonome Fahrsysteme die Abhängigkeit von hochpräzisen Karten loswerden, darin, die Tatsache auszunutzen, dass die Wahrnehmungsleistung im Fernbereich immer noch schlecht ist. Zu diesem Zweck schlagen wir P-MapNet vor, wobei sich „P“ auf die Fusion von Kartenprioritäten konzentriert, um die Modellleistung zu verbessern. Konkret nutzen wir die Vorinformationen in SDMap und HDMap aus: Einerseits extrahieren wir schwach ausgerichtete SDMap-Daten aus OpenStreetMap und kodieren sie in unabhängige Begriffe, um die Eingabe zu unterstützen. Es besteht das Problem der schwachen Ausrichtung zwischen der streng modifizierten Eingabe und der tatsächlichen HD+Map. Unsere auf dem Cross-Attention-Mechanismus basierende Struktur kann sich adaptiv auf das SDMap-Skelett konzentrieren und erhebliche Leistungsverbesserungen bringen.
