
 Technologie-Peripheriegeräte
KI
Eine überraschende Methode der zeitlichen Redundanz: eine neue Möglichkeit, den Rechenaufwand visueller Transformer zu reduzieren
Technologie-Peripheriegeräte
KI
Eine überraschende Methode der zeitlichen Redundanz: eine neue Möglichkeit, den Rechenaufwand visueller Transformer zu reduzieren
Eine überraschende Methode der zeitlichen Redundanz: eine neue Möglichkeit, den Rechenaufwand visueller Transformer zu reduzieren

Transformer wurde ursprünglich für Aufgaben zur Verarbeitung natürlicher Sprache entwickelt, wird aber mittlerweile häufig für Bildverarbeitungsaufgaben eingesetzt. Visual Transformer hat bei mehreren visuellen Erkennungsaufgaben eine hervorragende Genauigkeit bewiesen und die beste aktuelle Leistung bei Aufgaben wie Bildklassifizierung, Videoklassifizierung und Objekterkennung erzielt. Ein großer Nachteil von Visual Transformer ist der hohe Rechenaufwand. Typische Faltungsnetzwerke (CNN) erfordern mehrere zehn GFlops pro Bild, während visuelle Transformer oft eine Größenordnung mehr benötigen und Hunderte von GFlops pro Bild erreichen. Bei der Verarbeitung von Videos ist dieses Problem aufgrund der großen Datenmenge noch gravierender. Der hohe Rechenaufwand macht es schwierig, visuelle Transformer auf Geräten mit begrenzten Ressourcen oder strengen Latenzanforderungen bereitzustellen, was die Anwendungsszenarien dieser Technologie einschränkt, sonst hätten wir bereits einige spannende Anwendungen.
In einer aktuellen Arbeit schlugen drei Forscher der University of Wisconsin-Madison, Matthew Dutson, Yin Li und Mohit Gupta, zunächst vor, dass zeitliche Redundanz zwischen aufeinanderfolgenden Eingaben genutzt werden kann, um den visuellen Transformer in Videoanwendungen zu reduzieren . Sie haben auch den Modellcode veröffentlicht, der das PyTorch-Modul enthält, das zum Erstellen des Eventful Transformer verwendet wird.

- Projektadresse: http://wisionlab.com/project/eventful-transformers
- Zeitliche Redundanz: Nehmen wir zunächst an, dass es einen visuellen Transformer gibt, der eine Videosequenz Bild für Bild oder Videoclip für Videoclip verarbeiten kann. Dieser Transformer kann ein einfaches Frame-by-Frame-Verarbeitungsmodell (z. B. ein Objektdetektor) oder ein Zwischenschritt in einem raumzeitlichen Modell (z. B. der erste Schritt des zerlegten Modells von ViViT) sein. Im Gegensatz zum sprachverarbeitenden Transformer, bei dem eine Eingabe eine vollständige Sequenz ist, stellen die Forscher hier dem Transformer im Laufe der Zeit mehrere verschiedene Eingaben (Frames oder Videoclips) zur Verfügung.
Natürliche Videos enthalten erhebliche zeitliche Redundanz, d. h. die Unterschiede zwischen aufeinanderfolgenden Bildern sind gering. Dennoch berechnen tiefe Netzwerke, einschließlich Transformers, normalerweise jeden Frame „von Grund auf“. Diese Methode verwirft potenziell relevante Informationen, die durch vorherige Überlegungen gewonnen wurden, was äußerst verschwenderisch ist. Daher fragten sich diese drei Forscher: Können die Zwischenberechnungsergebnisse früherer Berechnungsschritte wiederverwendet werden, um die Effizienz der Verarbeitung redundanter Sequenzen zu verbessern?
Adaptive Inferenz: Bei visuellen Transformern und tiefen Netzwerken im Allgemeinen werden die Kosten der Inferenz oft von der Architektur bestimmt. In realen Anwendungen können sich die verfügbaren Ressourcen jedoch im Laufe der Zeit ändern, beispielsweise aufgrund konkurrierender Prozesse oder Leistungsänderungen. Daher kann es erforderlich sein, die Modellberechnungskosten zur Laufzeit zu ändern. Eines der wichtigsten Designziele, die sich die Forscher bei diesem neuen Projekt gesetzt hatten, war die Anpassungsfähigkeit – ihr Ansatz ermöglichte eine Echtzeitkontrolle der Rechenkosten. Abbildung 1 unten (unten) zeigt ein Beispiel für die Änderung des Rechenbudgets während der Videoverarbeitung.
Ereignisbasierter Transformer: In diesem Artikel wird ein ereignisbasierter Transformer vorgeschlagen, der zeitliche Redundanz zwischen Eingaben nutzen kann, um effizientes und adaptives Denken zu erreichen. Der Begriff Eventisierung ist inspiriert von Ereigniskameras, Sensoren, die diskret Bilder aufzeichnen, wenn sich die Szene ändert. Der ereignisbasierte Transformer verfolgt Änderungen auf Tokenebene im Laufe der Zeit und aktualisiert die Tokendarstellung und die Selbstaufmerksamkeitskarte bei jedem Zeitschritt selektiv. Das ereignisbasierte Transformer-Modul enthält ein Gating-Modul zur Steuerung der Anzahl der Aktualisierungstoken. Diese Methode eignet sich für bestehende Modelle (normalerweise ohne Umschulung) und ist für viele Videoverarbeitungsaufgaben geeignet. Die Forscher führten auch Experimente durch, um zu beweisen, dass die Ergebnisse zeigen, dass der Eventful Transformer auf den besten vorhandenen Modellen verwendet werden kann, während der Rechenaufwand erheblich reduziert und die ursprüngliche Genauigkeit beibehalten wird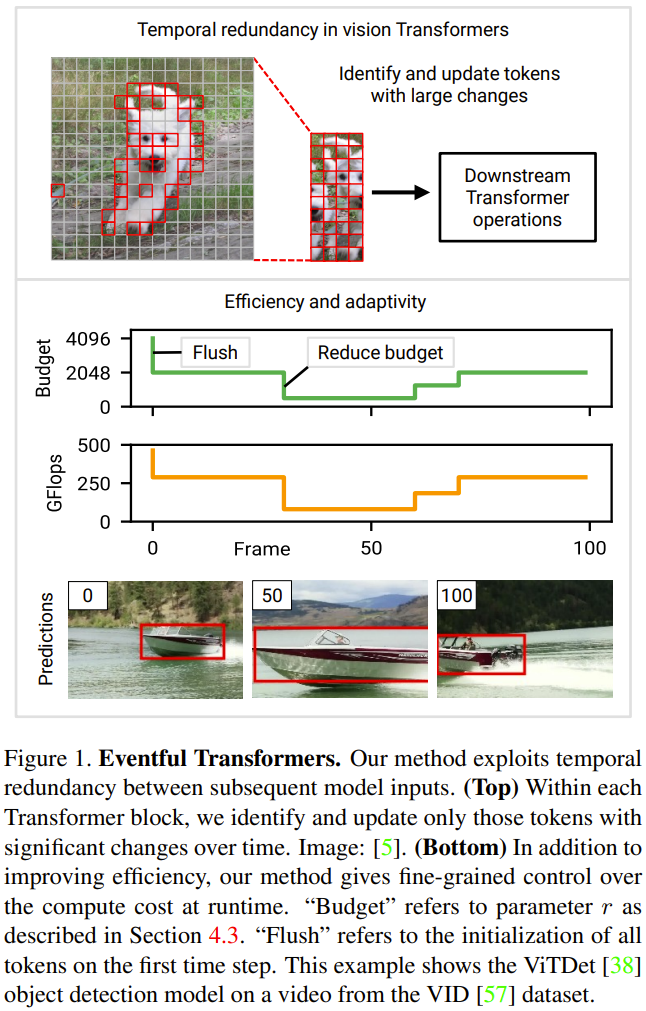
Eventful Transformer
Umgeschriebener Inhalt: Das Ziel von Ziel dieser Forschung ist es, visuelle Transformer für die Videoerkennung zu beschleunigen. In diesem Szenario muss der visuelle Transformer Videobilder oder Videoclips wiederholt verarbeiten. Zu den spezifischen Aufgaben gehören die Erkennung von Videozielen und Videoaktionen. Die vorgeschlagene Schlüsselidee besteht darin, zeitliche Redundanz auszunutzen, d. h. Berechnungsergebnisse aus früheren Zeitschritten wiederzuverwenden. Im Folgenden wird detailliert beschrieben, wie das Transformer-Modul so geändert wird, dass es Zeitredundanz wahrnehmen kann
Token-Gating: Erkennen von Redundanz
In diesem Abschnitt werden zwei neue Module vorgestellt, die von Forschern vorgeschlagen wurden: Token-Gate und Token-Puffer. Diese Module ermöglichen es dem Modell, Token zu identifizieren und zu aktualisieren, die sich seit der letzten Aktualisierung erheblich geändert haben. Gate-Modul: Dieses Gate wählt einen Teil M aus dem Eingabe-Token N aus und sendet ihn an die nachgelagerte Ebene, um Berechnungen durchzuführen. Es verwaltet einen Referenz-Token-Satz in seinem Speicher, der als u bezeichnet wird. Dieser Referenzvektor enthält den Wert jedes Tokens zum Zeitpunkt seiner letzten Aktualisierung. Bei jedem Zeitschritt wird jeder Token mit seinem entsprechenden Referenzwert verglichen und der Token, der sich deutlich vom Referenzwert unterscheidet, wird aktualisiert.
Markieren Sie nun den aktuellen Eingang dieses Gates als c. Bei jedem Zeitschritt wird der Zustand des Gates aktualisiert und seine Ausgabe wird gemäß dem folgenden Prozess bestimmt (siehe Abbildung 2 unten):
1 Berechnen Sie den Gesamtfehler e = u − c. 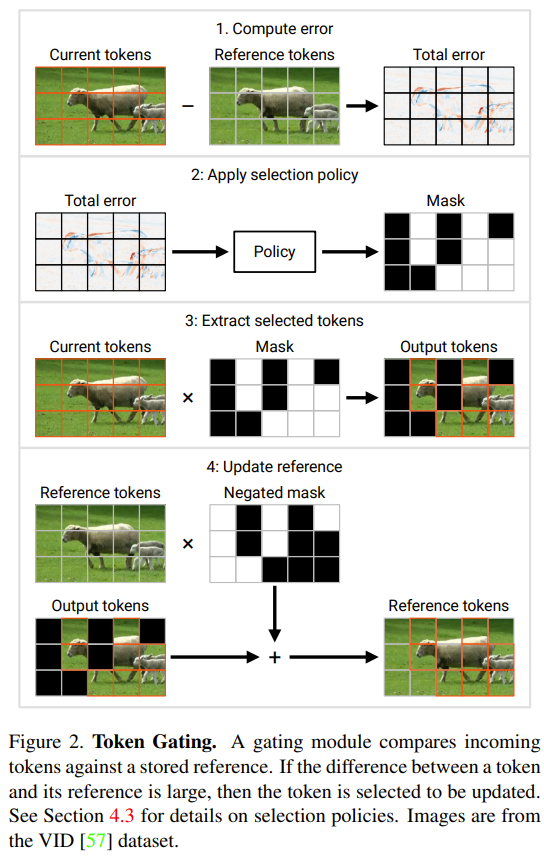
2. Verwenden Sie eine Auswahlstrategie für den Fehler z. Die Auswahlstrategie gibt eine Binärmaske m (entspricht einer Token-Indexliste) zurück, die angibt, welche M Token aktualisiert werden sollen.
3. Extrahieren Sie den mit der oben genannten Strategie ausgewählten Token. Dies wird in Abbildung 2 als Produkt c × m beschrieben. In der Praxis wird es durch Ausführen einer „Sammel“-Operation entlang der ersten Achse von c erreicht. Die gesammelten Token werden hier als
aufgezeichnet, was der Ausgang des Gates ist. 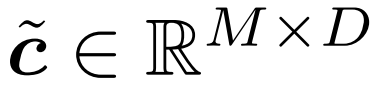 4. Aktualisieren Sie den Referenztoken auf den ausgewählten Token. Abbildung 2 beschreibt diesen Prozess als
4. Aktualisieren Sie den Referenztoken auf den ausgewählten Token. Abbildung 2 beschreibt diesen Prozess als
; die in der Praxis verwendete Operation ist „Streuung“. Im ersten Zeitschritt aktualisiert das Gatter alle Token (initialisiert u ← c und gibt c˜ = c zurück). 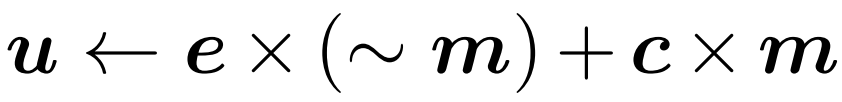 Puffermodul: Das Puffermodul verwaltet einen Zustandstensor
Puffermodul: Das Puffermodul verwaltet einen Zustandstensor
, der jedes Eingabe-Token 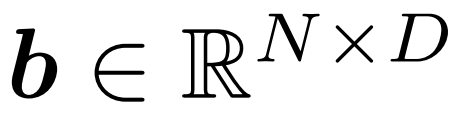 verfolgt. Der Puffer verteilt die Token von f (c˜) an die entsprechende Position in b. Anschließend wird das aktualisierte b als Ausgabe zurückgegeben, siehe Abbildung 3 unten.
verfolgt. Der Puffer verteilt die Token von f (c˜) an die entsprechende Position in b. Anschließend wird das aktualisierte b als Ausgabe zurückgegeben, siehe Abbildung 3 unten.
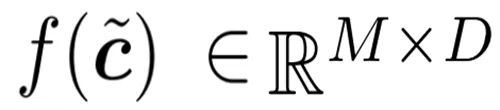
Die Forscher paarten jede Tür mit einem Puffer dahinter. Das Folgende ist ein einfaches Verwendungsmuster: Die Ausgabe des Gatters 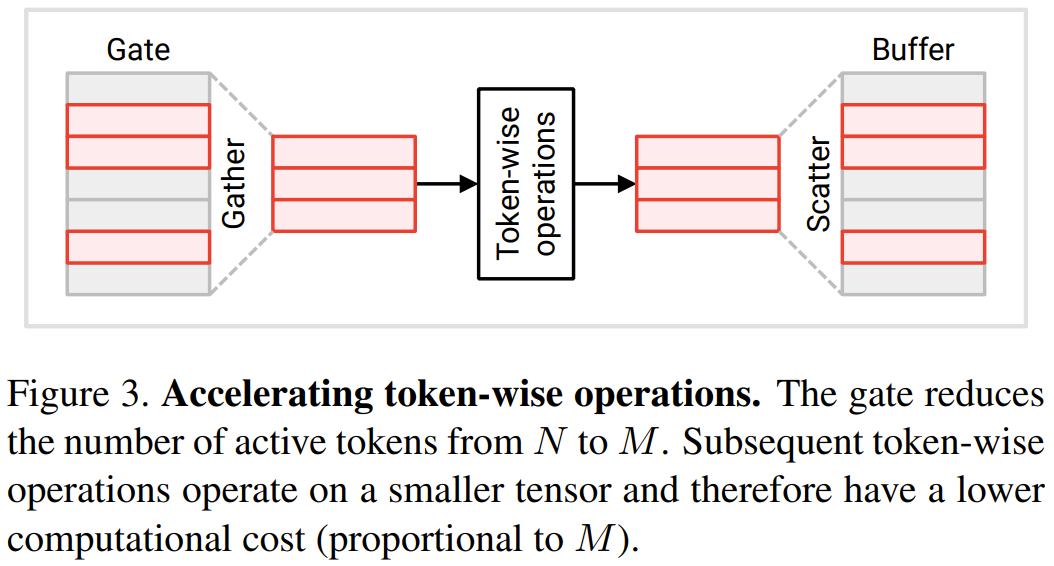
wird an eine Reihe von Operationen f (c˜) für jeden Token übergeben; dann wird der resultierende Tensor
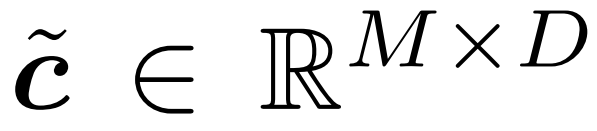 an einen Puffer übergeben, dessen vollständige Form wird wiederhergestellt.
an einen Puffer übergeben, dessen vollständige Form wird wiederhergestellt. 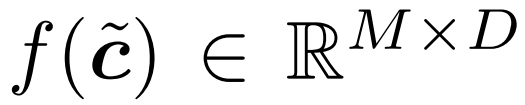 Rekonstruieren Sie den Transformer mit wahrnehmbarer Redundanz
Rekonstruieren Sie den Transformer mit wahrnehmbarer Redundanz
Um die oben genannte Zeitredundanz zu nutzen, schlug der Forscher ein Modifikationsschema für das Transformer-Modul vor. Abbildung 4 unten zeigt das Design des Eventful Transformer-Moduls. Diese Methode kann Vorgänge an einzelnen Token (z. B. MLP) sowie die Multiplikation von Abfrageschlüsselwerten und Aufmerksamkeitswerten beschleunigen.
Im Operation Transformer-Modul für jeden Token gelten viele Operationen für jeden Token, was bedeutet, dass sie keinen Informationsaustausch zwischen Token beinhalten, einschließlich linearer Transformationen in MLP und MSA. Um Rechenkosten zu sparen, gaben die Forscher an, dass tokenorientierte Operationen an Token, die nicht vom Gate ausgewählt wurden, übersprungen werden können. Aufgrund der Unabhängigkeit zwischen den Token ändert sich dadurch nicht das Ergebnis der Operation für den ausgewählten Token. Siehe Abbildung 3.
Konkret verwendeten die Forscher eine kontinuierliche Sequenz eines Gate-Puffer-Paares bei der Verarbeitung der Operationen jedes Tokens, einschließlich W_qkv-Transformation, W_p-Transformation und MLP. Es ist zu beachten, dass vor dem Überspringen der Verbindung auch ein Puffer hinzugefügt wurde, um sicherzustellen, dass die Token der beiden Additionsoperanden ordnungsgemäß ausgerichtet sind. Die Operationskosten für jedes Token sind proportional zur Anzahl der Token. Durch die Reduzierung der Zahl von N auf M werden die Downstream-Operationskosten pro Token um das N/M-fache reduziert. Schauen wir uns nun die Ergebnisse des Abfrage-Schlüssel-Wert-Produkts B = q k^T an Abbildung 5 unten zeigt eine Methode zum sparsamen Aktualisieren einer Teilmenge von Elementen im Abfrage-Schlüssel-Wert-Produkt B.
Die Gesamtkosten dieser Updates betragen 2NMD, verglichen mit den Kosten für die Berechnung von B von Grund auf N^2D. Beachten Sie, dass die Kosten der neuen Methode proportional zu M sind, der Anzahl der ausgewählten Token. Wenn M
Achtung – Produkt von Werten: Der Forscher hat eine Methode vorgeschlagen, die auf dem Inkrement Δ basiert Update-Strategie.
Abbildung 6 zeigt eine neu vorgeschlagene Methode zur effizienten Berechnung von drei inkrementellen Termen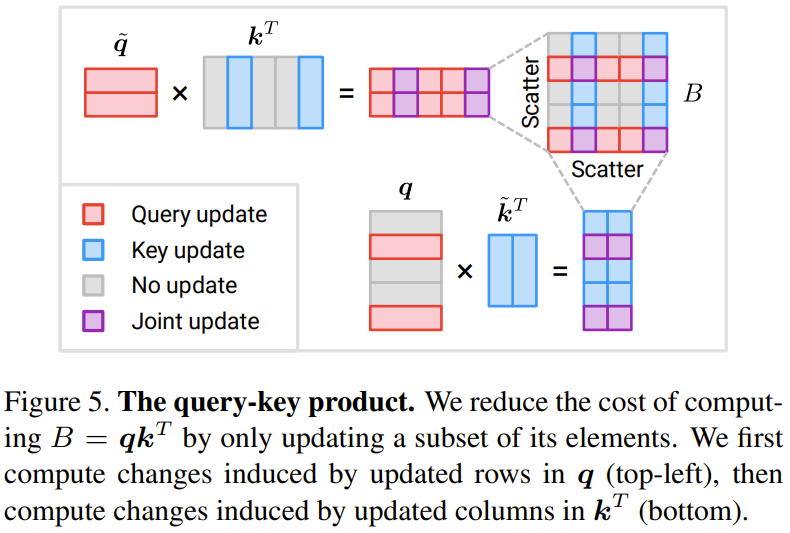
Wenn M weniger als die Hälfte von N beträgt, kann der Berechnungsaufwand reduziert werden
Token-Auswahlstrategie
Top-r-Strategie: Diese Strategie wählt r Token mit dem größten Fehler e aus (hier wird die L2-Norm verwendet).
Schwellenwertstrategie: Diese Strategie wählt alle Token aus, deren Fehlernorm e den Schwellenwert h überschreitet.
Umgeschriebener Inhalt: Andere Strategien: Mit komplexeren und ausgefeilteren Token-Auswahlstrategien können bessere Ergebnisse erzielt werden. Kompromiss zwischen Genauigkeit und Kosten Beispielsweise kann ein leichtgewichtiges Richtliniennetzwerk zum Erlernen der Richtlinie verwendet werden. Das Training des Entscheidungsmechanismus der Richtlinie kann jedoch auf Schwierigkeiten stoßen, da die Binärmaske m normalerweise nicht differenzierbar ist. Eine andere Idee besteht darin, den Wichtigkeitswert als Referenzinformation für die Auswahl zu verwenden. Diese Ideen erfordern jedoch noch weitere Forschung.
Experimente Experimentelle Ergebnisse der Zielerkennung. Dabei ist die positive Achse die rechnerische Einsparungsrate und die negative Achse die relative Reduzierung des mAP50-Scores für die neue Methode. Es ist ersichtlich, dass die neue Methode bei geringem Genauigkeitsverlust erhebliche Recheneinsparungen erzielt.
Abbildung 8 unten zeigt den Methodenvergleich und die experimentellen Ablationsergebnisse für die Videozielerkennungsaufgabe.
Abbildung 9 unten zeigt die experimentellen Ergebnisse für die Videoaktionserkennung.
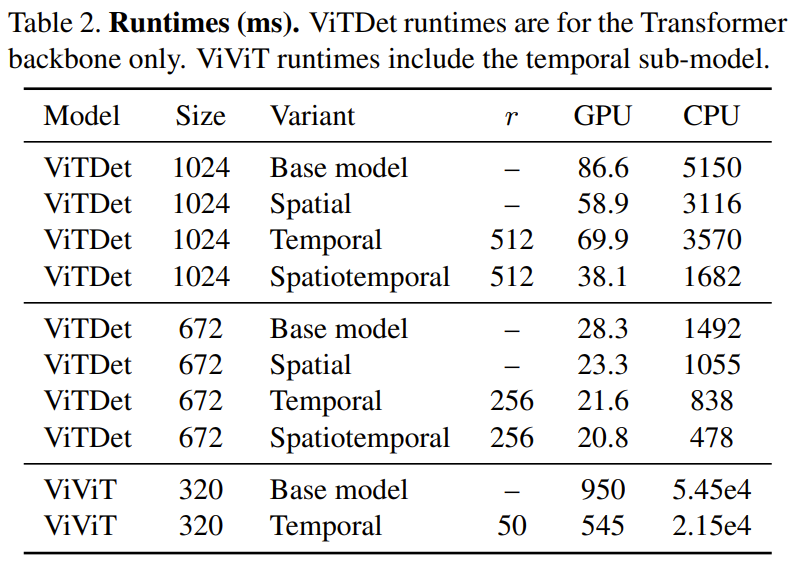
In Tabelle 2 unten werden die Zeitergebnisse (in Millisekunden) angezeigt, die auf einer CPU (Xeon Silver 4214, 2,2 GHz) und einer GPU (NVIDIA RTX3090) ausgeführt werden. Es ist zu beobachten, dass die Zeitredundanz auf der GPU eine Geschwindigkeitssteigerung um das 1,74-fache mit sich bringt, während die Verbesserung auf der CPU das 2,47-fache erreicht.
Weitere technische Details und experimentelle Ergebnisse finden Sie im Originalpapier.
Das obige ist der detaillierte Inhalt vonEine überraschende Methode der zeitlichen Redundanz: eine neue Möglichkeit, den Rechenaufwand visueller Transformer zu reduzieren. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Verwenden Sie ddrescue, um Daten unter Linux wiederherzustellen
Mar 20, 2024 pm 01:37 PM
Verwenden Sie ddrescue, um Daten unter Linux wiederherzustellen
Mar 20, 2024 pm 01:37 PM
DDREASE ist ein Tool zum Wiederherstellen von Daten von Datei- oder Blockgeräten wie Festplatten, SSDs, RAM-Disks, CDs, DVDs und USB-Speichergeräten. Es kopiert Daten von einem Blockgerät auf ein anderes, wobei beschädigte Blöcke zurückbleiben und nur gute Blöcke verschoben werden. ddreasue ist ein leistungsstarkes Wiederherstellungstool, das vollständig automatisiert ist, da es während der Wiederherstellungsvorgänge keine Unterbrechungen erfordert. Darüber hinaus kann es dank der ddasue-Map-Datei jederzeit gestoppt und fortgesetzt werden. Weitere wichtige Funktionen von DDREASE sind: Es überschreibt die wiederhergestellten Daten nicht, füllt aber die Lücken im Falle einer iterativen Wiederherstellung. Es kann jedoch gekürzt werden, wenn das Tool explizit dazu aufgefordert wird. Stellen Sie Daten aus mehreren Dateien oder Blöcken in einer einzigen wieder her
 Open Source! Jenseits von ZoeDepth! DepthFM: Schnelle und genaue monokulare Tiefenschätzung!
Apr 03, 2024 pm 12:04 PM
Open Source! Jenseits von ZoeDepth! DepthFM: Schnelle und genaue monokulare Tiefenschätzung!
Apr 03, 2024 pm 12:04 PM
0.Was bewirkt dieser Artikel? Wir schlagen DepthFM vor: ein vielseitiges und schnelles generatives monokulares Tiefenschätzungsmodell auf dem neuesten Stand der Technik. Zusätzlich zu herkömmlichen Tiefenschätzungsaufgaben demonstriert DepthFM auch hochmoderne Fähigkeiten bei nachgelagerten Aufgaben wie dem Tiefen-Inpainting. DepthFM ist effizient und kann Tiefenkarten innerhalb weniger Inferenzschritte synthetisieren. Lassen Sie uns diese Arbeit gemeinsam lesen ~ 1. Titel der Papierinformationen: DepthFM: FastMonocularDepthEstimationwithFlowMatching Autor: MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas tritt offiziell in die Ära der Elektroroboter ein! Gestern hat sich der hydraulische Atlas einfach „unter Tränen“ von der Bühne der Geschichte zurückgezogen. Heute gab Boston Dynamics bekannt, dass der elektrische Atlas im Einsatz ist. Es scheint, dass Boston Dynamics im Bereich kommerzieller humanoider Roboter entschlossen ist, mit Tesla zu konkurrieren. Nach der Veröffentlichung des neuen Videos wurde es innerhalb von nur zehn Stunden bereits von mehr als einer Million Menschen angesehen. Die alten Leute gehen und neue Rollen entstehen. Das ist eine historische Notwendigkeit. Es besteht kein Zweifel, dass dieses Jahr das explosive Jahr der humanoiden Roboter ist. Netizens kommentierten: Die Weiterentwicklung der Roboter hat dazu geführt, dass die diesjährige Eröffnungsfeier wie Menschen aussieht, und der Freiheitsgrad ist weitaus größer als der von Menschen. Aber ist das wirklich kein Horrorfilm? Zu Beginn des Videos liegt Atlas ruhig auf dem Boden, scheinbar auf dem Rücken. Was folgt, ist atemberaubend
 Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Die von Google geförderte Leistung von JAX hat in jüngsten Benchmark-Tests die von Pytorch und TensorFlow übertroffen und belegt bei 7 Indikatoren den ersten Platz. Und der Test wurde nicht auf der TPU mit der besten JAX-Leistung durchgeführt. Obwohl unter Entwicklern Pytorch immer noch beliebter ist als Tensorflow. Aber in Zukunft werden möglicherweise mehr große Modelle auf Basis der JAX-Plattform trainiert und ausgeführt. Modelle Kürzlich hat das Keras-Team drei Backends (TensorFlow, JAX, PyTorch) mit der nativen PyTorch-Implementierung und Keras2 mit TensorFlow verglichen. Zunächst wählen sie eine Reihe von Mainstream-Inhalten aus
 Langsame Internetgeschwindigkeiten für Mobilfunkdaten auf dem iPhone: Korrekturen
May 03, 2024 pm 09:01 PM
Langsame Internetgeschwindigkeiten für Mobilfunkdaten auf dem iPhone: Korrekturen
May 03, 2024 pm 09:01 PM
Stehen Sie vor einer Verzögerung oder einer langsamen mobilen Datenverbindung auf dem iPhone? Normalerweise hängt die Stärke des Mobilfunk-Internets auf Ihrem Telefon von mehreren Faktoren ab, wie z. B. der Region, dem Mobilfunknetztyp, dem Roaming-Typ usw. Es gibt einige Dinge, die Sie tun können, um eine schnellere und zuverlässigere Mobilfunk-Internetverbindung zu erhalten. Fix 1 – Neustart des iPhone erzwingen Manchmal werden durch einen erzwungenen Neustart Ihres Geräts viele Dinge zurückgesetzt, einschließlich der Mobilfunkverbindung. Schritt 1 – Drücken Sie einfach einmal die Lauter-Taste und lassen Sie sie los. Drücken Sie anschließend die Leiser-Taste und lassen Sie sie wieder los. Schritt 2 – Der nächste Teil des Prozesses besteht darin, die Taste auf der rechten Seite gedrückt zu halten. Lassen Sie das iPhone den Neustart abschließen. Aktivieren Sie Mobilfunkdaten und überprüfen Sie die Netzwerkgeschwindigkeit. Überprüfen Sie es erneut. Fix 2 – Datenmodus ändern 5G bietet zwar bessere Netzwerkgeschwindigkeiten, funktioniert jedoch besser, wenn das Signal schwächer ist
 Die Kuaishou-Version von Sora „Ke Ling' steht zum Testen offen: Sie generiert über 120 Sekunden Videos, versteht die Physik besser und kann komplexe Bewegungen genau modellieren
Jun 11, 2024 am 09:51 AM
Die Kuaishou-Version von Sora „Ke Ling' steht zum Testen offen: Sie generiert über 120 Sekunden Videos, versteht die Physik besser und kann komplexe Bewegungen genau modellieren
Jun 11, 2024 am 09:51 AM
Was? Wird Zootopia durch heimische KI in die Realität umgesetzt? Zusammen mit dem Video wird ein neues groß angelegtes inländisches Videogenerationsmodell namens „Keling“ vorgestellt. Sora geht einen ähnlichen technischen Weg und kombiniert eine Reihe selbst entwickelter technologischer Innovationen, um Videos zu produzieren, die nicht nur große und vernünftige Bewegungen aufweisen, sondern auch die Eigenschaften der physischen Welt simulieren und über starke konzeptionelle Kombinationsfähigkeiten und Vorstellungskraft verfügen. Den Daten zufolge unterstützt Keling die Erstellung ultralanger Videos von bis zu 2 Minuten mit 30 Bildern pro Sekunde, mit Auflösungen von bis zu 1080p und unterstützt mehrere Seitenverhältnisse. Ein weiterer wichtiger Punkt ist, dass es sich bei Keling nicht um eine vom Labor veröffentlichte Demo oder Video-Ergebnisdemonstration handelt, sondern um eine Anwendung auf Produktebene, die von Kuaishou, einem führenden Anbieter im Bereich Kurzvideos, gestartet wurde. Darüber hinaus liegt das Hauptaugenmerk darauf, pragmatisch zu sein, keine Blankoschecks auszustellen und sofort nach der Veröffentlichung online zu gehen. Das große Modell von Ke Ling wurde bereits in Kuaiying veröffentlicht.
 Die Vitalität der Superintelligenz erwacht! Aber mit der Einführung der sich selbst aktualisierenden KI müssen sich Mütter keine Sorgen mehr über Datenengpässe machen
Apr 29, 2024 pm 06:55 PM
Die Vitalität der Superintelligenz erwacht! Aber mit der Einführung der sich selbst aktualisierenden KI müssen sich Mütter keine Sorgen mehr über Datenengpässe machen
Apr 29, 2024 pm 06:55 PM
Ich weine zu Tode. Die Daten im Internet reichen überhaupt nicht aus. Das Trainingsmodell sieht aus wie „Die Tribute von Panem“, und KI-Forscher auf der ganzen Welt machen sich Gedanken darüber, wie sie diese datenhungrigen Esser ernähren sollen. Dieses Problem tritt insbesondere bei multimodalen Aufgaben auf. Zu einer Zeit, als sie ratlos waren, nutzte ein Start-up-Team der Abteilung der Renmin-Universität von China sein eigenes neues Modell, um als erstes in China einen „modellgenerierten Datenfeed selbst“ in die Realität umzusetzen. Darüber hinaus handelt es sich um einen zweigleisigen Ansatz auf der Verständnisseite und der Generierungsseite. Beide Seiten können hochwertige, multimodale neue Daten generieren und Datenrückmeldungen an das Modell selbst liefern. Was ist ein Modell? Awaker 1.0, ein großes multimodales Modell, das gerade im Zhongguancun-Forum erschienen ist. Wer ist das Team? Sophon-Motor. Gegründet von Gao Yizhao, einem Doktoranden an der Hillhouse School of Artificial Intelligence der Renmin University.
 Die U.S. Air Force präsentiert ihren ersten KI-Kampfjet mit großem Aufsehen! Der Minister führte die Testfahrt persönlich durch, ohne in den gesamten Prozess einzugreifen, und 100.000 Codezeilen wurden 21 Mal getestet.
May 07, 2024 pm 05:00 PM
Die U.S. Air Force präsentiert ihren ersten KI-Kampfjet mit großem Aufsehen! Der Minister führte die Testfahrt persönlich durch, ohne in den gesamten Prozess einzugreifen, und 100.000 Codezeilen wurden 21 Mal getestet.
May 07, 2024 pm 05:00 PM
Kürzlich wurde die Militärwelt von der Nachricht überwältigt: US-Militärkampfflugzeuge können jetzt mithilfe von KI vollautomatische Luftkämpfe absolvieren. Ja, erst kürzlich wurde der KI-Kampfjet des US-Militärs zum ersten Mal der Öffentlichkeit zugänglich gemacht und sein Geheimnis gelüftet. Der vollständige Name dieses Jägers lautet „Variable Stability Simulator Test Aircraft“ (VISTA). Er wurde vom Minister der US-Luftwaffe persönlich geflogen, um einen Eins-gegen-eins-Luftkampf zu simulieren. Am 2. Mai startete US-Luftwaffenminister Frank Kendall mit einer X-62AVISTA auf der Edwards Air Force Base. Beachten Sie, dass während des einstündigen Fluges alle Flugaktionen autonom von der KI durchgeführt wurden! Kendall sagte: „In den letzten Jahrzehnten haben wir über das unbegrenzte Potenzial des autonomen Luft-Luft-Kampfes nachgedacht, aber es schien immer unerreichbar.“ Nun jedoch,
