
obj_mask = (obj_idxs >= 0).float()attn_mask = torch.matmul(obj_mask.unsqueeze(-1), obj_mask.unsqueeze(0)).bool()attn_mask = ~attn_mask
mask = (~attention_mask[-1]).float()track_scores = track_scores * mask
 Technologie-Peripheriegeräte
KI
Praktischer Einsatz: Dynamisches sequentielles Netzwerk für End-to-End-Erkennung und -Verfolgung
Technologie-Peripheriegeräte
KI
Praktischer Einsatz: Dynamisches sequentielles Netzwerk für End-to-End-Erkennung und -Verfolgung
Praktischer Einsatz: Dynamisches sequentielles Netzwerk für End-to-End-Erkennung und -Verfolgung

Dieser Artikel wird mit Genehmigung des öffentlichen Kontos von Autonomous Driving Heart nachgedruckt. Bitte wenden Sie sich für einen Nachdruck an die Quelle.
Ich glaube, dass mit Ausnahme einiger großer Hersteller selbst entwickelter Chips die meisten Unternehmen für autonomes Fahren NVIDIA-Chips verwenden werden, die nicht von TensorRT getrennt werden können. TensorRT ist ein C++-Inferenz-Framework, das auf verschiedenen NVIDIA-GPU-Hardwareplattformen läuft. Das Modell, das wir mit Pytorch, TF oder anderen Frameworks trainiert haben, kann zuerst in das ONNX-Format und dann in das TensorRT-Format konvertiert werden. Anschließend können wir unser Modell mithilfe der TensorRT-Inferenz-Engine ausführen, wodurch die Geschwindigkeit beim Ausführen dieses Modells auf NVIDIA-GPUs verbessert wird .
Im Allgemeinen unterstützen onnx und TensorRT nur relativ feste Modelle (einschließlich fester Eingabe- und Ausgabeformate auf allen Ebenen, einzelner Zweige usw.) und unterstützen höchstens die äußerste dynamische Eingabe (der Export von onnx kann durch Festlegen des Parameters „dynamic_axes“ bestimmt werden). um dynamische Dimensionsänderungen zu ermöglichen. Aber Freunde, die an der Spitze der Wahrnehmungsalgorithmen stehen, werden wissen, dass ein wichtiger Entwicklungstrend End-2-End ist, der Zielerkennung, Zielverfolgung, Flugbahnvorhersage, Entscheidungsplanung usw. abdecken kann Als typisches Beispiel kann das MUTR3D-Modell verwendet werden, das eine durchgängige Zielerkennung und Zielverfolgung ermöglicht (eine Einführung in das Modell finden Sie unter). :)
In MOTR/MUTR3D werden wir die Theorie und Beispiele des Etikettenzuweisungsmechanismus detailliert erläutern, um eine echte End-to-End-Verfolgung mehrerer Objekte zu erreichen. Bitte klicken Sie auf den Link, um mehr zu lesen: https://zhuanlan.zhihu.com/p/609123786
Bei der Konvertierung dieses Modells in das TensorRT-Format und der Erzielung einer präzisen Ausrichtung, sogar einer fp16-Präzisionsausrichtung, kann es zu einer Reihe dynamischer Elemente kommen, zum Beispiel: mehrere if-else-Zweige, dynamische Änderungen in Subnetzwerk-Eingabeformen und andere Operationen und Operatoren, die eine dynamische Verarbeitung erfordern usw.
 Bilder
Bilder
MUTR3D-Architektur Da der gesamte Prozess viele Details umfasst, ist die Situation unterschiedlich Es ist schwierig, eine Plug-and-Play-Lösung zu finden, indem man sich die Referenzmaterialien im gesamten Netzwerk ansieht oder sogar auf Google sucht. Sie kann nur durch kontinuierliches Aufteilen und Experimentieren gelöst werden. Durch mehr als einen Monat intensiver Erkundung Übung des Bloggers (Vorherige Erfahrung mit TensorRT Nicht viel, ich habe sein Temperament nicht verstanden), ich habe viel Köpfchen eingesetzt und bin auf viele Fallstricke gestoßen. Schließlich habe ich die Konvertierung erfolgreich durchgeführt und eine fp32/fp16-Präzisionsausrichtung erreicht. und der Verzögerungsanstieg war im Vergleich zur einfachen Zielerkennung sehr gering. Ich möchte hier eine einfache Zusammenfassung erstellen und eine Referenz für alle bereitstellen (ja, ich habe Rezensionen geschrieben und schließlich über die Praxis geschrieben!)
1 Problem mit dem Datenformat
Zuallererst ist das Datenformat von MUTR3D ziemlich Speziell, und alle Beispiele werden verwendet. Dies liegt daran, dass jede Abfrage an viele Informationen gebunden ist und für einen einfacheren Eins-zu-Eins-Zugriff in Instanzen gepackt wird. Für die Bereitstellung können die Eingabe und Ausgabe jedoch nur Tensoren sein, also die Instanzdaten Muss zuerst zerlegt werden, wird zu mehreren Tensorvariablen. Und da die Abfrage und andere Variablen des aktuellen Frames im Modell generiert werden, müssen Sie nur die im vorherigen Frame beibehaltene Abfrage und andere Variablen eingeben und die beiden im model.
2 .padding löst das Problem der dynamischen Eingabeform.
Bei der Eingabevorbestellungsrahmenabfrage und anderen Variablen besteht ein wichtiges Problem darin, dass die Form unsicher ist. Dies liegt daran, dass MUTR3D nur Abfragen behält, die in vorherigen Frames Ziele erkannt haben. Dieses Problem ist relativ einfach zu lösen. Der einfachste Weg ist das Auffüllen, also das Auffüllen auf eine feste Größe. Für die Abfrage können Sie alle Nullen zum Auffüllen verwenden. Die entsprechende Zahl kann durch Experimente basierend auf Ihren eigenen Daten ermittelt werden. Zu wenige werden das Ziel leicht verfehlen, zu viele werden Platz verschwenden. Obwohl der Parameter „dynamic_axes“ von onnx eine dynamische Eingabe realisieren kann, sollte es ein Problem geben, da es sich um die vom nachfolgenden Transformator berechnete Größe handelt. Ich habe es nicht ausprobiert, Leser können es versuchen
3. Die Auswirkungen des Auffüllens auf das Selbstaufmerksamkeitsmodul im Haupttransformator
Wenn Sie keine speziellen Operatoren verwenden, können Sie nach dem Auffüllen erfolgreich in ONNX und TensorRT konvertieren. Diese Situation wird in der Praxis sicherlich vorkommen, sie würde jedoch den Rahmen dieses Artikels sprengen. Beispielsweise wird in MUTR3D die Verwendung des Torch.linalg.inv-Operators zum Suchen der Pseudoinversmatrix beim Verschieben des Referenzpunkts zwischen Frames nicht unterstützt. Wenn Sie auf einen nicht unterstützten Operator stoßen, können Sie nur versuchen, ihn zu ersetzen. Wenn er nicht funktioniert, können Sie ihn nur außerhalb des Modells verwenden. Da dieser Schritt jedoch in der Vor- und Nachbearbeitung des Modells platziert werden kann, habe ich mich entschieden, ihn außerhalb des Modells zu verschieben. Es wäre schwieriger, eigene Operatoren zu schreiben. Eine erfolgreiche Konvertierung bedeutet nicht, dass alles gut geht. Die Antwort lautet oft nein. Wir werden feststellen, dass die Genauigkeitslücke sehr groß ist. Dies liegt daran, dass das Modell über viele Module verfügt. Lassen Sie uns zunächst über den ersten Grund sprechen. In der Selbstaufmerksamkeitsphase des Transformers findet eine Informationsinteraktion zwischen mehreren Abfragen statt. Das ursprüngliche Modell behält jedoch nur die Abfragen bei, bei denen das Ziel einmal erkannt wurde (im Modell als aktive Abfragen bezeichnet), und nur diese Abfragen sollten mit der Abfrage des aktuellen Frames interagieren. Und da nun viele ungültige Abfragen ausgefüllt werden, wirkt sich die Interaktion aller Abfragen unweigerlich auf die Ergebnisse aus
Die Lösung für dieses Problem wurde von DN-DETR[1] inspiriert, das darin besteht, Attention_mask zu verwenden, das dem Parameter „attn_mask“ in nn.MultiheadAttention entspricht. Seine Funktion besteht zunächst darin, Abfragen zu blockieren, die keine Informationsinteraktion erfordern. Dies liegt daran, dass in NLP alle Sätze eine inkonsistente Länge haben, was genau meinen aktuellen Anforderungen entspricht. Ich muss nur beachten, dass „True“ die Abfrage darstellt, die blockiert werden muss, und „False“ die gültige Abfrage darstellt
Aufmerksamkeitsmaskendiagramm Da die Logik zur Berechnung der Aufmerksamkeitsmaske etwas kompliziert ist, gibt es viele Beim Betrieb und der Konvertierung von TensorRT können neue Probleme auftreten. Daher sollte es außerhalb des Modells berechnet und als Eingabevariable in das Modell eingegeben und dann übergeben werden Zum Transformator. Das Folgende ist der Beispielcode: 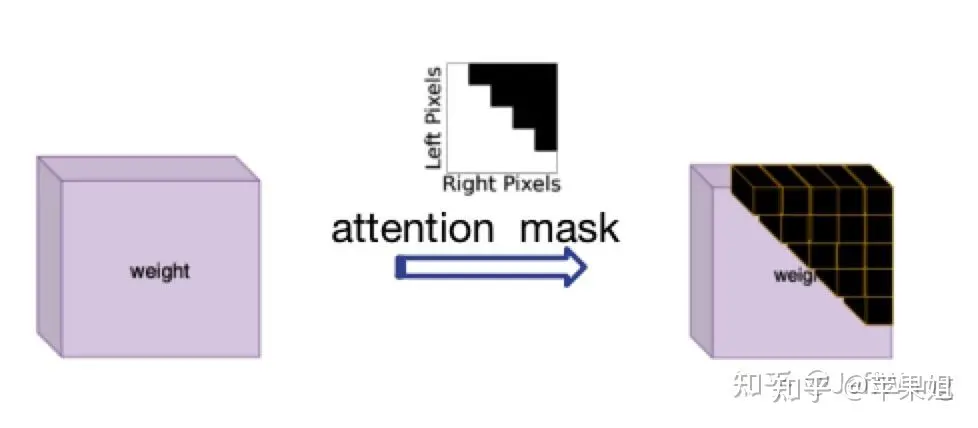
data['attn_masks'] = attn_masks_init.clone().to(device)data['attn_masks'][active_prev_num:max_num, :] = Truedata['attn_masks'][:, active_prev_num:max_num] = True[1]DN-DETR: Accelerate DETR Training by Introducing Query DeNoising
obj_mask = (obj_idxs >= 0).float()attn_mask = torch.matmul(obj_mask.unsqueeze(-1), obj_mask.unsqueeze(0)).bool()attn_mask = ~attn_mask
Nach dem Login kopieren
5 Auffüllen der AusgabeergebnisseNach Abschluss der oben genannten vier Punkte können wir grundsätzlich sicherstellen, dass es kein Problem mit der Logik der Modellkonvertierung tensorRT gibt, aber nach vielen Überprüfungen der Ausgabeergebnisse gibt es in einigen Frames immer noch Probleme, die verwirrt sind Wenn Sie jedoch die Daten Frame für Frame analysieren, werden Sie feststellen, dass die Auffüllabfrage in einigen Frames nicht an der Transformatorberechnung beteiligt ist, Sie jedoch eine höhere Punktzahl erhalten und dann falsche Ergebnisse erhalten Dies ist tatsächlich möglich, wenn die Datenmenge groß ist, da die Auffüllabfrage nur einen Anfangswert von 0 hat und die Referenzpunkte im Gegensatz zu anderen zufällig initialisierten Abfragen ebenfalls den gleichen Vorgang ausführen Da es sich schließlich um eine Auffüllabfrage handelt, beabsichtigen wir nicht, deren Ergebnisse zu verwenden, daher müssen wir sie filtern. Wie filtere ich die Ergebnisse der Auffüllabfrage? Die Token, die die Abfrage füllen, sind nur ihre Indexpositionen, keine anderen Informationen sind spezifisch. Die Indexinformationen werden tatsächlich in der in Punkt 3 verwendeten Aufmerksamkeitsmaske aufgezeichnet, die von außerhalb des Modells übergeben wird. Diese Maske ist zweidimensional und wir können eine der Dimensionen (jede Zeile oder Spalte) verwenden, um den gefüllten track_score direkt auf 0 zu setzen. Denken Sie daran, weiterhin auf die Vorbehalte in Schritt 4 zu achten, d. h. versuchen Sie, Matrixberechnungen anstelle von indizierten Slice-Zuweisungen zu verwenden, und die Berechnungen müssen in den Float-Typ konvertiert werden. Das Folgende ist ein Codebeispiel: obj_mask = (obj_idxs >= 0).float()attn_mask = torch.matmul(obj_mask.unsqueeze(-1), obj_mask.unsqueeze(0)).bool()attn_mask = ~attn_mask
mask = (~attention_mask[-1]).float()track_scores = track_scores * mask
Nach dem Login kopieren
6. So aktualisieren Sie track_id Zusätzlich zum Modellkörper gibt es tatsächlich einen sehr wichtigen Schritt, nämlich die dynamische Aktualisierung von track_id. Dies ist auch ein wichtiger Faktor für das Modell Aber im Originalmodell ist die Art und Weise, track_id zu aktualisieren, eine relativ komplexe Schleifenbeurteilung, das heißt, wenn es höher als die Punktzahl ist und es sich um ein neues Ziel handelt, wird ein neues obj_idx zugewiesen ist niedriger als der Filter-Score-Thresh und es handelt sich um ein altes Ziel, die entsprechende Verschwindezeit + 1, wenn die Verschwindezeit überschritten wird. Wenn miss_tolerance überschritten wird, wird die entsprechende obj idx auf -1 gesetzt, das heißt, das Ziel wird verworfen We Ich weiß, dass tensorRT keine if-else-Anweisungen mit mehreren Zweigen unterstützt (naja, ich wusste es am Anfang nicht), was Kopfschmerzen bereitet. Wenn die aktualisierte track_id auch außerhalb des Modells platziert wird, wirkt sich dies nicht nur auf das Ende aus -to-End-Architektur des Modells, macht aber auch die Verwendung von QIM unmöglich, da QIM Abfragen basierend auf der aktualisierten track_id filtert. Ich muss mir also den Kopf zerbrechen, um die aktualisierte track_id in das Modell einzufügen.Nutzen Sie Ihren Einfallsreichtum Auch hier (fast zur Neige) sind if-else-Anweisungen nicht unersetzlich, z. B. die Verwendung einer Maske für parallele Operationen. Konvertieren Sie beispielsweise die Bedingung in eine Maske (z. B. tensor[mask] = 0). 5 erwähnte, dass tensorRT keine Index-Slice-Zuweisungen unterstützt. Es wird spekuliert, dass die Form des Tensors durch die Slice-Operation implizit geändert wird Die Indexzuweisung wird in allen Fällen unterstützt, es treten jedoch folgende Probleme auf:
mask = (~attention_mask[-1]).float()track_scores = track_scores * mask
需要重新写的内容是:赋值的值必须是一个,不能是多个。例如,当我更新新出现的目标时,我不会统一赋值为某个ID,而是需要为每个目标赋予连续递增的ID。我想到的解决办法是先统一赋值为一个比较大且不可能出现的数字,比如1000,以避免与之前的ID重复,然后在后续处理中将1000替换为唯一且连续递增的数字。(我真是个天才)
如果要进行递增操作(+=1),只能使用简单的掩码,即不能涉及复杂的逻辑计算。例如,对disappear_time的更新,本来需要同时判断obj_idx >= 0且track_scores = 0这个条件。虽然看似不合理,但经过分析发现,即使将obj_idx=-1的非目标的disappear_time递增,因为后续这些目标并不会被选入,所以对整体逻辑影响不大
综上,最后的动态更新track_id示例代码如下,在后处理环节要记得替换obj_idx为1000的数值.:
def update_trackid(self, track_scores, disappear_time, obj_idxs):disappear_time[track_scores >= 0.4] = 0obj_idxs[(obj_idxs == -1) & (track_scores >= 0.4)] = 1000disappear_time[track_scores 5] = -1
至此模型部分的处理就全部结束了,是不是比较崩溃,但是没办法,部署端到端模型肯定比一般模型要复杂很多.模型最后会输出固定shape的结果,还需要在后处理阶段根据obj_idx是否>0判断需要保留到下一帧的query,再根据track_scores是否>filter score thresh判断当前最终的输出结果.总体来看,需要在模型外进行的操作只有三步:帧间移动reference_points,对输入query进行padding,对输出结果进行过滤和转换格式,基本上实现了端到端的目标检测+目标跟踪.
需要重新写的内容是:以上六点的操作顺序需要说明一下。我在这里按照问题分类来写,实际上可能的顺序是1->2->3->5->6->4,因为第五点和第六点是使用QIM的前提,它们之间也存在依赖关系。另外一个问题是我没有使用memory bank,即时序融合的模块,因为经过实验发现这个模块的提升效果并不明显,而且对于端到端跟踪机制来说,已经天然地使用了时序融合(因为直接将前序帧的查询信息带到下一帧),所以时序融合并不是非常必要
好了,现在我们可以对比TensorRT的推理结果和PyTorch的推理结果,会发现在FP32精度下可以实现精度对齐,非常棒!但是,如果需要转换为FP16(可以大幅降低部署时延),第一次推理会发现结果完全变成None(再次崩溃)。导致FP16结果为None一般都是因为出现数据溢出,即数值大小超限(FP16最大支持范围是-65504~+65504)。如果你的代码使用了一些特殊的操作,或者你的数据天然数值较大,例如内外参、姿态等数据很可能超限,一般可以通过缩放等方式解决。这里再说一下和我以上6点相关的一个原因:
7.使用attention_mask导致的fp16结果为none的问题
这个问题非常隐蔽,因为问题隐藏在torch.nn.MultiheadAttention源码中,具体在torch.nn.functional.py文件中,有以下几句:
if attn_mask is not None and attn_mask.dtype == torch.bool:new_attn_mask = torch.zeros_like(attn_mask, dtype=q.dtype)new_attn_mask.masked_fill_(attn_mask, float("-inf"))attn_mask = new_attn_mask可以看到,这一步操作是对attn_mask中值为True的元素用float("-inf")填充,这也是attention mask的原理所在,也就是值为1的位置会被替换成负无穷,这样在后续的softmax操作中,这个位置的输入会被加上负无穷,输出的结果就可以忽略不记,不会对其他位置的输出产生影响.大家也能看出来了,这个float("-inf")是fp32精度,肯定超过fp16支持的范围了,所以导致结果为none.我在这里把它替换为fp16支持的下限,即-65504,转fp16就正常了,虽然说一般不要修改源码,但这个确实没办法.不要问我怎么知道这么隐蔽的问题的,因为不是我一个人想到的.但如果使用attention_mask之前仔细研究了原理,想到也不难.
好的,以下是我在端到端模型部署方面的全部经验分享,我保证这不是标题党。由于我对tensorRT的接触时间不长,所以可能有些描述不准确的地方

需要进行改写的内容是:原文链接:https://mp.weixin.qq.com/s/EcmNH2to2vXBsdnNvpo0xw
Das obige ist der detaillierte Inhalt vonPraktischer Einsatz: Dynamisches sequentielles Netzwerk für End-to-End-Erkennung und -Verfolgung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1386
1386
 52
52

 Warum ist Gaussian Splatting beim autonomen Fahren so beliebt, dass NeRF allmählich aufgegeben wird?
Jan 17, 2024 pm 02:57 PM
Warum ist Gaussian Splatting beim autonomen Fahren so beliebt, dass NeRF allmählich aufgegeben wird?
Jan 17, 2024 pm 02:57 PM
Oben geschrieben und persönliches Verständnis des Autors. Dreidimensionales Gaussplatting (3DGS) ist eine transformative Technologie, die in den letzten Jahren in den Bereichen explizite Strahlungsfelder und Computergrafik entstanden ist. Diese innovative Methode zeichnet sich durch die Verwendung von Millionen von 3D-Gaußkurven aus, was sich stark von der Neural Radiation Field (NeRF)-Methode unterscheidet, die hauptsächlich ein implizites koordinatenbasiertes Modell verwendet, um räumliche Koordinaten auf Pixelwerte abzubilden. Mit seiner expliziten Szenendarstellung und differenzierbaren Rendering-Algorithmen garantiert 3DGS nicht nur Echtzeit-Rendering-Fähigkeiten, sondern führt auch ein beispielloses Maß an Kontrolle und Szenenbearbeitung ein. Dies positioniert 3DGS als potenziellen Game-Changer für die 3D-Rekonstruktion und -Darstellung der nächsten Generation. Zu diesem Zweck geben wir erstmals einen systematischen Überblick über die neuesten Entwicklungen und Anliegen im Bereich 3DGS.
 Wie lässt sich das Long-Tail-Problem in autonomen Fahrszenarien lösen?
Jun 02, 2024 pm 02:44 PM
Wie lässt sich das Long-Tail-Problem in autonomen Fahrszenarien lösen?
Jun 02, 2024 pm 02:44 PM
Gestern wurde ich während des Interviews gefragt, ob ich irgendwelche Long-Tail-Fragen gestellt hätte, also dachte ich, ich würde eine kurze Zusammenfassung geben. Das Long-Tail-Problem des autonomen Fahrens bezieht sich auf Randfälle bei autonomen Fahrzeugen, also mögliche Szenarien mit geringer Eintrittswahrscheinlichkeit. Das wahrgenommene Long-Tail-Problem ist einer der Hauptgründe, die derzeit den betrieblichen Designbereich intelligenter autonomer Einzelfahrzeugfahrzeuge einschränken. Die zugrunde liegende Architektur und die meisten technischen Probleme des autonomen Fahrens wurden gelöst, und die verbleibenden 5 % der Long-Tail-Probleme wurden nach und nach zum Schlüssel zur Einschränkung der Entwicklung des autonomen Fahrens. Zu diesen Problemen gehören eine Vielzahl fragmentierter Szenarien, Extremsituationen und unvorhersehbares menschliches Verhalten. Der „Long Tail“ von Randszenarien beim autonomen Fahren bezieht sich auf Randfälle in autonomen Fahrzeugen (AVs). Randfälle sind mögliche Szenarien mit geringer Eintrittswahrscheinlichkeit. diese seltenen Ereignisse
 Kamera oder Lidar wählen? Eine aktuelle Übersicht über die Erzielung einer robusten 3D-Objekterkennung
Jan 26, 2024 am 11:18 AM
Kamera oder Lidar wählen? Eine aktuelle Übersicht über die Erzielung einer robusten 3D-Objekterkennung
Jan 26, 2024 am 11:18 AM
0. Vorab geschrieben&& Persönliches Verständnis, dass autonome Fahrsysteme auf fortschrittlichen Wahrnehmungs-, Entscheidungs- und Steuerungstechnologien beruhen, indem sie verschiedene Sensoren (wie Kameras, Lidar, Radar usw.) verwenden, um die Umgebung wahrzunehmen, und Algorithmen und Modelle verwenden für Echtzeitanalysen und Entscheidungsfindung. Dies ermöglicht es Fahrzeugen, Verkehrszeichen zu erkennen, andere Fahrzeuge zu erkennen und zu verfolgen, das Verhalten von Fußgängern vorherzusagen usw. und sich so sicher an komplexe Verkehrsumgebungen anzupassen. Diese Technologie erregt derzeit große Aufmerksamkeit und gilt als wichtiger Entwicklungsbereich für die Zukunft des Transportwesens . eins. Aber was autonomes Fahren schwierig macht, ist herauszufinden, wie man dem Auto klarmachen kann, was um es herum passiert. Dies erfordert, dass der dreidimensionale Objekterkennungsalgorithmus im autonomen Fahrsystem Objekte in der Umgebung, einschließlich ihrer Standorte, genau wahrnehmen und beschreiben kann.
 Das Stable Diffusion 3-Papier wird endlich veröffentlicht und die architektonischen Details werden enthüllt. Wird es helfen, Sora zu reproduzieren?
Mar 06, 2024 pm 05:34 PM
Das Stable Diffusion 3-Papier wird endlich veröffentlicht und die architektonischen Details werden enthüllt. Wird es helfen, Sora zu reproduzieren?
Mar 06, 2024 pm 05:34 PM
Der Artikel von StableDiffusion3 ist endlich da! Dieses Modell wurde vor zwei Wochen veröffentlicht und verwendet die gleiche DiT-Architektur (DiffusionTransformer) wie Sora. Nach seiner Veröffentlichung sorgte es für großes Aufsehen. Im Vergleich zur Vorgängerversion wurde die Qualität der von StableDiffusion3 generierten Bilder erheblich verbessert. Es unterstützt jetzt Eingabeaufforderungen mit mehreren Themen, und der Textschreibeffekt wurde ebenfalls verbessert, und es werden keine verstümmelten Zeichen mehr angezeigt. StabilityAI wies darauf hin, dass es sich bei StableDiffusion3 um eine Reihe von Modellen mit Parametergrößen von 800 M bis 8 B handelt. Durch diesen Parameterbereich kann das Modell direkt auf vielen tragbaren Geräten ausgeführt werden, wodurch der Einsatz von KI deutlich reduziert wird
 Dieser Artikel reicht aus, um etwas über autonomes Fahren und Flugbahnvorhersage zu lesen!
Feb 28, 2024 pm 07:20 PM
Dieser Artikel reicht aus, um etwas über autonomes Fahren und Flugbahnvorhersage zu lesen!
Feb 28, 2024 pm 07:20 PM
Die Trajektorienvorhersage spielt eine wichtige Rolle beim autonomen Fahren. Unter autonomer Fahrtrajektorienvorhersage versteht man die Vorhersage der zukünftigen Fahrtrajektorie des Fahrzeugs durch die Analyse verschiedener Daten während des Fahrvorgangs. Als Kernmodul des autonomen Fahrens ist die Qualität der Trajektorienvorhersage von entscheidender Bedeutung für die nachgelagerte Planungssteuerung. Die Trajektorienvorhersageaufgabe verfügt über einen umfangreichen Technologie-Stack und erfordert Vertrautheit mit der dynamischen/statischen Wahrnehmung des autonomen Fahrens, hochpräzisen Karten, Fahrspurlinien, Fähigkeiten in der neuronalen Netzwerkarchitektur (CNN&GNN&Transformer) usw. Der Einstieg ist sehr schwierig! Viele Fans hoffen, so schnell wie möglich mit der Flugbahnvorhersage beginnen zu können und Fallstricke zu vermeiden. Heute werde ich eine Bestandsaufnahme einiger häufiger Probleme und einführender Lernmethoden für die Flugbahnvorhersage machen! Einführungsbezogenes Wissen 1. Sind die Vorschaupapiere in Ordnung? A: Schauen Sie sich zuerst die Umfrage an, S
 SIMPL: Ein einfacher und effizienter Multi-Agent-Benchmark zur Bewegungsvorhersage für autonomes Fahren
Feb 20, 2024 am 11:48 AM
SIMPL: Ein einfacher und effizienter Multi-Agent-Benchmark zur Bewegungsvorhersage für autonomes Fahren
Feb 20, 2024 am 11:48 AM
Originaltitel: SIMPL: ASimpleandEfficientMulti-agentMotionPredictionBaselineforAutonomousDriving Paper-Link: https://arxiv.org/pdf/2402.02519.pdf Code-Link: https://github.com/HKUST-Aerial-Robotics/SIMPL Autor: Hong Kong University of Science und Technologie DJI-Papieridee: Dieses Papier schlägt eine einfache und effiziente Bewegungsvorhersagebasislinie (SIMPL) für autonome Fahrzeuge vor. Im Vergleich zum herkömmlichen Agent-Cent
 Sprechen wir über End-to-End- und autonome Fahrsysteme der nächsten Generation sowie über einige Missverständnisse über End-to-End-Autonomes Fahren?
Apr 15, 2024 pm 04:13 PM
Sprechen wir über End-to-End- und autonome Fahrsysteme der nächsten Generation sowie über einige Missverständnisse über End-to-End-Autonomes Fahren?
Apr 15, 2024 pm 04:13 PM
Im vergangenen Monat hatte ich aus bekannten Gründen einen sehr intensiven Austausch mit verschiedenen Lehrern und Mitschülern der Branche. Ein unvermeidliches Thema im Austausch ist natürlich End-to-End und der beliebte Tesla FSDV12. Ich möchte diese Gelegenheit nutzen, einige meiner aktuellen Gedanken und Meinungen als Referenz und Diskussion darzulegen. Wie definiert man ein durchgängiges autonomes Fahrsystem und welche Probleme sollten voraussichtlich durchgängig gelöst werden? Gemäß der traditionellsten Definition bezieht sich ein End-to-End-System auf ein System, das Rohinformationen von Sensoren eingibt und für die Aufgabe relevante Variablen direkt ausgibt. Bei der Bilderkennung kann CNN beispielsweise als End-to-End bezeichnet werden, verglichen mit der herkömmlichen Methode zum Extrahieren von Merkmalen + Klassifizieren. Bei autonomen Fahraufgaben werden Eingabedaten verschiedener Sensoren (Kamera/LiDAR) benötigt
 nuScenes' neuestes SOTA |. SparseAD: Sparse-Abfrage hilft effizientes durchgängiges autonomes Fahren!
Apr 17, 2024 pm 06:22 PM
nuScenes' neuestes SOTA |. SparseAD: Sparse-Abfrage hilft effizientes durchgängiges autonomes Fahren!
Apr 17, 2024 pm 06:22 PM
Vorab geschrieben und Ausgangspunkt Das End-to-End-Paradigma verwendet ein einheitliches Framework, um Multitasking in autonomen Fahrsystemen zu erreichen. Trotz der Einfachheit und Klarheit dieses Paradigmas bleibt die Leistung von End-to-End-Methoden für das autonome Fahren bei Teilaufgaben immer noch weit hinter Methoden für einzelne Aufgaben zurück. Gleichzeitig erschweren die in früheren End-to-End-Methoden weit verbreiteten Funktionen der dichten Vogelperspektive (BEV) die Skalierung auf mehr Modalitäten oder Aufgaben. Hier wird ein Sparse-Search-zentriertes End-to-End-Paradigma für autonomes Fahren (SparseAD) vorgeschlagen, bei dem die Sparse-Suche das gesamte Fahrszenario, einschließlich Raum, Zeit und Aufgaben, ohne dichte BEV-Darstellung vollständig abbildet. Insbesondere ist eine einheitliche, spärliche Architektur für die Aufgabenerkennung einschließlich Erkennung, Verfolgung und Online-Zuordnung konzipiert. Zudem schwer
