
 Technologie-Peripheriegeräte
KI
Effiziente Parameter-Feinabstimmung umfangreicher Sprachmodelle – BitFit/Prefix/Prompt-Feinabstimmungsserie
Technologie-Peripheriegeräte
KI
Effiziente Parameter-Feinabstimmung umfangreicher Sprachmodelle – BitFit/Prefix/Prompt-Feinabstimmungsserie
Effiziente Parameter-Feinabstimmung umfangreicher Sprachmodelle – BitFit/Prefix/Prompt-Feinabstimmungsserie

Im Jahr 2018 veröffentlichte Google BERT. Nach seiner Veröffentlichung übertraf es die State-of-the-Art-Ergebnisse (Sota) von 11 NLP-Aufgaben und wurde zu einem neuen Meilenstein in der NLP-Welt In der Abbildung unten ist links der Vortrainingsprozess für das BERT-Modell dargestellt, auf der rechten Seite der Feinabstimmungsprozess für bestimmte Aufgaben. Unter anderem dient die Feinabstimmungsphase der Feinabstimmung, wenn sie anschließend in einigen nachgelagerten Aufgaben verwendet wird, wie z. B. Textklassifizierung, Wortartkennzeichnung, Frage- und Antwortsystem usw. BERT kann feinabgestimmt werden verschiedene Aufgaben, ohne die Struktur anzupassen. Durch das Aufgabendesign „vorab trainiertes Sprachmodell + Feinabstimmung der nachgelagerten Aufgabe“ wurden leistungsstarke Modelleffekte erzielt. Seitdem ist „vorab trainiertes Sprachmodell + Feinabstimmung der nachgelagerten Aufgabe“ zum gängigen Trainingsparadigma im Bereich NLP geworden.
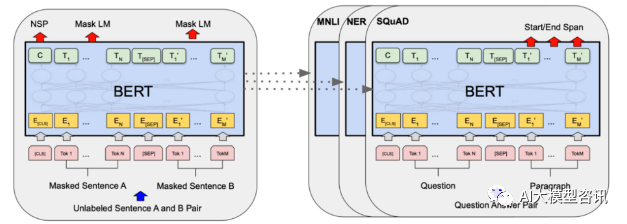 BERT-Strukturdiagramm, links ist der Prozess vor dem Training und rechts ist der Feinabstimmungsprozess für spezifische Aufgaben
BERT-Strukturdiagramm, links ist der Prozess vor dem Training und rechts ist der Feinabstimmungsprozess für spezifische Aufgaben
Darüber hinaus vollständig Eine Feinabstimmung des Modells führt außerdem zu einem Verlust an Diversität und führt zu ernsthaften Vergessensproblemen. Daher ist die effiziente Durchführung einer Modellfeinabstimmung zum Schwerpunkt der Branchenforschung geworden, die auch Forschungsraum für die schnelle Entwicklung einer effizienten Parameter-Feinabstimmungstechnologie bietet. 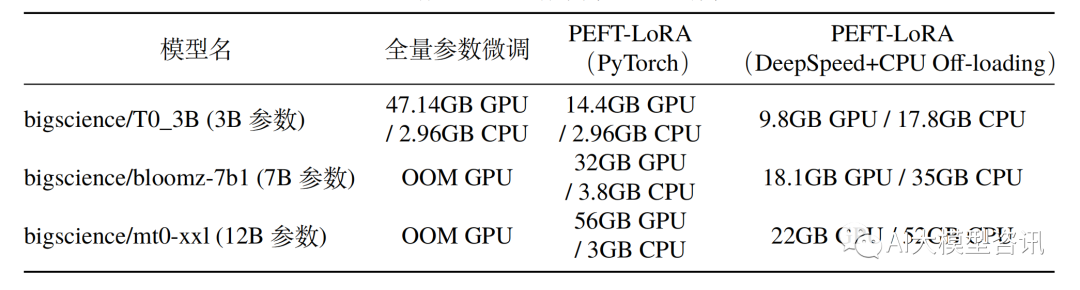 Effiziente Parameter-Feinabstimmung bezieht sich auf die Feinabstimmung einer kleinen Menge oder zusätzliche Modellparameter und die Festlegung der meisten vorab trainierten Modellparameter (LLM), wodurch die Rechen- und Speicherkosten erheblich reduziert werden. Gleichzeitig kann eine Leistung erzielt werden, die mit einer vollständigen Parameter-Feinabstimmung vergleichbar ist. Die Methode der Parameter-effizienten Feinabstimmung ist in einigen Fällen sogar besser als die vollständige Feinabstimmung und kann besser auf Szenarien außerhalb der Domäne verallgemeinert werden.
Effiziente Parameter-Feinabstimmung bezieht sich auf die Feinabstimmung einer kleinen Menge oder zusätzliche Modellparameter und die Festlegung der meisten vorab trainierten Modellparameter (LLM), wodurch die Rechen- und Speicherkosten erheblich reduziert werden. Gleichzeitig kann eine Leistung erzielt werden, die mit einer vollständigen Parameter-Feinabstimmung vergleichbar ist. Die Methode der Parameter-effizienten Feinabstimmung ist in einigen Fällen sogar besser als die vollständige Feinabstimmung und kann besser auf Szenarien außerhalb der Domäne verallgemeinert werden.
Gemeinsame Parameter-effiziente Feinabstimmungstechnologien und -methoden Für alle ist die vollständige Feinabstimmung für jede Aufgabe sehr effektiv, generiert aber auch ein einzigartiges großes Modell für jede vorab trainierte Aufgabe, was es schwierig macht, abzuleiten, welche Änderungen während des Feinabstimmungsprozesses aufgetreten sind, und die Bereitstellung schwierig zu machen, insbesondere als Da die Anzahl der Aufgaben zunimmt, ist es schwierig, sie aufrechtzuerhalten.
Idealerweise hätten wir gerne eine effiziente Feinabstimmungsmethode, die die folgenden Bedingungen erfüllt: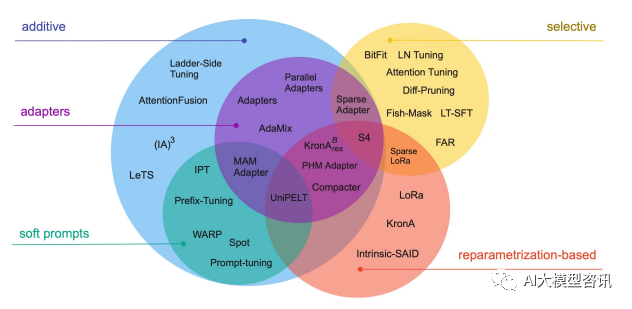 Die obige Frage hängt davon ab, inwieweit der Feinabstimmungsprozess das Erlernen neuer Fähigkeiten und der durch Exposition erlernten Fähigkeiten steuern kann zum vorab trainierten LM. Allerdings können auch die bisherigen effizienten Feinabstimmungsmethoden Adapter-Tuning und Diff-Pruning die oben genannten Anforderungen teilweise erfüllen. BitFit, eine spärliche Feinabstimmungsmethode mit kleineren Parametern, kann alle oben genannten Anforderungen erfüllen. BitFit ist eine spärliche Feinabstimmungsmethode, die nur die Bias-Parameter oder einen Teil der Bias-Parameter während des Trainings aktualisiert. Für das Transformer-Modell werden die meisten Transformer-Encoder-Parameter eingefroren und nur die Bias-Parameter und die Klassifizierungsschichtparameter der spezifischen Aufgabe aktualisiert. Zu den beteiligten Bias-Parametern gehören die Bias bei der Berechnung von Abfrage, Schlüssel, Wert und Zusammenführen mehrerer Aufmerksamkeitsergebnisse im Aufmerksamkeitsmodul, die Bias in der MLP-Schicht, die Bias-Parameter in der Layernormalisierungsschicht und die Bias-Parameter im Vortrainingsmodell wie in der Abbildung unten gezeigt.
Die obige Frage hängt davon ab, inwieweit der Feinabstimmungsprozess das Erlernen neuer Fähigkeiten und der durch Exposition erlernten Fähigkeiten steuern kann zum vorab trainierten LM. Allerdings können auch die bisherigen effizienten Feinabstimmungsmethoden Adapter-Tuning und Diff-Pruning die oben genannten Anforderungen teilweise erfüllen. BitFit, eine spärliche Feinabstimmungsmethode mit kleineren Parametern, kann alle oben genannten Anforderungen erfüllen. BitFit ist eine spärliche Feinabstimmungsmethode, die nur die Bias-Parameter oder einen Teil der Bias-Parameter während des Trainings aktualisiert. Für das Transformer-Modell werden die meisten Transformer-Encoder-Parameter eingefroren und nur die Bias-Parameter und die Klassifizierungsschichtparameter der spezifischen Aufgabe aktualisiert. Zu den beteiligten Bias-Parametern gehören die Bias bei der Berechnung von Abfrage, Schlüssel, Wert und Zusammenführen mehrerer Aufmerksamkeitsergebnisse im Aufmerksamkeitsmodul, die Bias in der MLP-Schicht, die Bias-Parameter in der Layernormalisierungsschicht und die Bias-Parameter im Vortrainingsmodell wie in der Abbildung unten gezeigt.
Bild
PLM-Modul stellt eine bestimmte PLM-Unterschicht dar, z. B. Aufmerksamkeit oder FFN. Der orangefarbene Block im Bild stellt den trainierbaren Hinweisvektor dar, und der blaue Block stellt die eingefrorenen vorab trainierten Modellparameter dar
In Modellen wie Bert-Base/Bert-Large macht der Bias-Parameter nur 0,08 % bis 0,09 % der Gesamtparameter des Modells aus. Beim Vergleich der Auswirkungen von BitFit, Adapter und Diff-Pruning auf das Bert-Large-Modell basierend auf dem GLUE-Datensatz wurde jedoch festgestellt, dass BitFit den gleichen Effekt wie Adapter und Diff-Pruning hat, wenn die Anzahl der Parameter viel kleiner ist als das von Adapter und Diff-Pruning, bei einigen Aufgaben sogar etwas besser als Adapter und Diff-Pruning.
Aus den experimentellen Ergebnissen geht hervor, dass die BitFit-Feinabstimmung im Vergleich zur vollständigen Parameter-Feinabstimmung nur eine sehr kleine Anzahl von Parametern aktualisiert und bei mehreren Datensätzen gute Ergebnisse erzielt hat. Obwohl es nicht so gut ist wie die Feinabstimmung aller Parameter, ist es weitaus besser als die Frozen-Methode zur Fixierung aller Modellparameter. Gleichzeitig wurde durch den Vergleich der Parameter vor und nach dem BitFit-Training festgestellt, dass sich viele Bias-Parameter nicht wesentlich änderten, beispielsweise die Bias-Parameter im Zusammenhang mit der Berechnung des Schlüssels. Es wurde festgestellt, dass die Bias-Parameter der FFN-Schicht, die die Abfrage berechnet und die Merkmalsdimension von N auf 4N vergrößert, die offensichtlichsten Änderungen aufweisen. Nur die Aktualisierung dieser beiden Arten von Bias-Parametern kann ebenfalls gute Ergebnisse erzielen. Im Gegenteil, wenn einer von ihnen behoben wird, geht die Wirkung des Modells stark verloren.
Präfix-Tuning
Vor dem Präfix-Tuning bestand die Arbeit hauptsächlich darin, diskrete Vorlagen manuell zu entwerfen oder automatisch nach diskreten Vorlagen zu suchen. Bei manuell gestalteten Vorlagen wirken sich Änderungen in der Vorlage besonders empfindlich auf die endgültige Leistung des Modells aus. Das Hinzufügen eines Wortes, das Fehlen eines Wortes oder das Ändern der Position führen zu relativ großen Änderungen. Bei automatisierten Suchvorlagen sind die Kosten relativ hoch; gleichzeitig sind die Ergebnisse früherer diskreter Token-Suchen möglicherweise nicht optimal. Darüber hinaus verwendet das traditionelle Feinabstimmungsparadigma vorab trainierte Modelle zur Feinabstimmung verschiedener nachgelagerter Aufgaben, und für jede Aufgabe muss ein feinabgestimmtes Modellgewicht gespeichert werden. Einerseits dauert die Feinabstimmung des gesamten Modells lange Zeit; andererseits nimmt es auch viel Speicherplatz in Anspruch. Basierend auf den beiden oben genannten Punkten schlägt Prefix Tuning ein festes Pre-Training-LM vor, das trainierbare, aufgabenspezifische Präfixe zu LM hinzufügt, sodass unterschiedliche Präfixe für verschiedene Aufgaben gespeichert werden können und die Kosten für die Feinabstimmung ebenfalls gering sind Gleichzeitig ist diese Art von Präfix tatsächlich ein kontinuierlich trainierbares Mikro-Virtual-Token (Soft Prompt/Continuous Prompt), das besser optimiert ist und eine bessere Wirkung hat als diskrete Token.
Was also neu geschrieben werden muss: Was bedeutet Präfix? Die Rolle des Präfixes besteht darin, das Modell beim Extrahieren von x-bezogenen Informationen anzuleiten, um y besser generieren zu können. Wenn wir beispielsweise eine Zusammenfassungsaufgabe ausführen möchten, kann das Präfix nach der Feinabstimmung verstehen, dass es sich bei dem, was wir gerade ausführen, um eine „Zusammenfassungsformular“-Aufgabe handelt, und dann das Modell anleiten, Schlüsselinformationen aus x zu extrahieren Um eine Emotionsklassifizierungsaufgabe durchzuführen, kann das Präfix das Modell anleiten, die semantischen Informationen in Bezug auf Emotionen in x usw. zu extrahieren. Diese Erklärung ist möglicherweise nicht so streng, aber Sie können die Rolle des Präfixes ungefähr verstehen.
Die Optimierung von Präfixen besteht darin, vor der Eingabe des Tokens ein aufgabenbezogenes virtuelles Token als Präfix zu erstellen und dann nur die Parameter des Präfixteils während des Trainings zu aktualisieren. Während in PLM andere Parameter festgelegt sind. Für unterschiedliche Modellstrukturen müssen unterschiedliche Präfixe erstellt werden:
- Für autoregressive Architekturmodelle: Fügen Sie vor dem Satz ein Präfix hinzu, um z = [PREFIX; y] zu erhalten Kontext (zum Beispiel: GPT3-Kontextlernen).
- Für das Encoder-Decoder-Architekturmodell werden Präfixe sowohl zum Encoder als auch zum Decoder hinzugefügt, was zu z = [PREFIX; Das Präfix wird auf der Encoder-Seite hinzugefügt, um die Codierung des Eingabeteils zu steuern, und das Präfix wird auf der Decoder-Seite hinzugefügt, um die nachfolgende Token-Generierung zu steuern.
 Bilder
Bilder
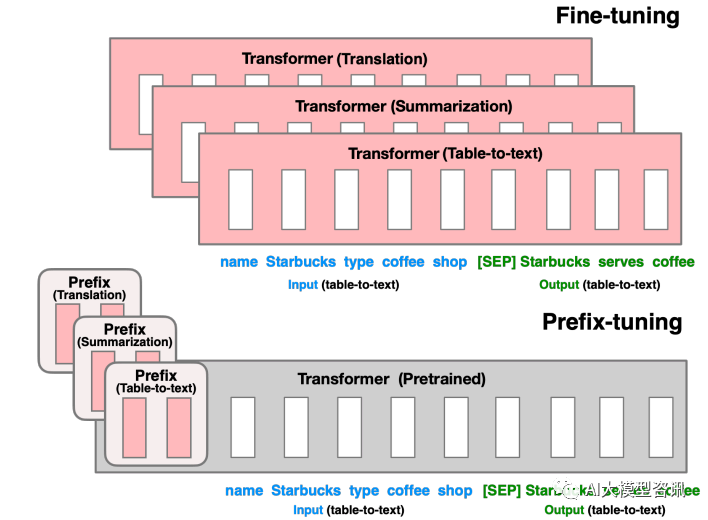
Schreiben Sie den Inhalt neu, ohne die ursprüngliche Bedeutung zu ändern, und schreiben Sie ihn auf Chinesisch um: Für die Feinabstimmung im vorherigen Teil aktualisieren wir alle Transformer-Parameter (rotes Feld) und müssen für jede Aufgabe eine vollständige Kopie des Modells speichern. Durch die Präfixanpassung im unteren Teil werden die Transformer-Parameter eingefroren und nur das Präfix (rotes Kästchen) optimiert.
Diese Methode ähnelt tatsächlich der Erstellung von Prompt, mit der Ausnahme, dass Prompt eine künstlich erstellte „explizite“ Eingabeaufforderung ist und die Parameter dies nicht können aktualisiert, und Präfix ist ein „impliziter“ Hinweis, der gelernt werden kann. Um zu verhindern, dass die direkte Aktualisierung der Parameter von Prefix zu instabilem Training und Leistungseinbußen führt, wird gleichzeitig eine MLP-Struktur vor der Präfixschicht hinzugefügt. Nach Abschluss des Trainings bleiben nur die Parameter von Prefix erhalten. Darüber hinaus haben Ablationsexperimente gezeigt, dass die Anpassung der Einbettungsschicht allein nicht aussagekräftig genug ist, was zu einem erheblichen Leistungsabfall führt. Daher werden jeder Schicht sofortige Parameter hinzugefügt, was eine große Änderung darstellt.
Obwohl Prefix Tuning praktisch erscheint, hat es auch die folgenden zwei wesentlichen Nachteile:Prompt Tuning
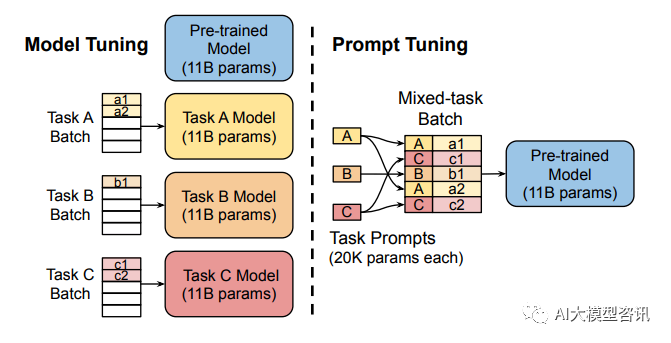
Durch die vollständige Feinabstimmung großer Modelle wird für jede Aufgabe ein Modell trainiert, was relativ hohe Overhead- und Bereitstellungskosten mit sich bringt. Gleichzeitig ist die Methode der diskreten Eingabeaufforderungen (bezieht sich auf das manuelle Entwerfen von Eingabeaufforderungen und das Hinzufügen von Eingabeaufforderungen zum Modell) relativ teuer und die Wirkung ist nicht sehr gut. Prompt Tuning lernt Eingabeaufforderungen durch Backpropagierung aktualisierter Parameter, anstatt Eingabeaufforderungen manuell zu entwerfen. Dabei werden die ursprünglichen Gewichte des Modells eingefroren und Eingabeaufforderungsparameter nur trainiert. Nach dem Training kann dasselbe Modell für Multitasking-Inferenzen verwendet werden.
 Bilder
Bilder
Die Modelloptimierung erfordert die Erstellung aufgabenspezifischer Kopien des gesamten vorab trainierten Modells für jede Aufgabe. Nachgelagerte Aufgaben und Schlussfolgerungen müssen in separaten Stapeln erfolgen. Prompt Tuning erfordert lediglich das Speichern einer kleinen aufgabenspezifischen Eingabeaufforderung für jede Aufgabe und ermöglicht die Inferenz gemischter Aufgaben unter Verwendung des ursprünglichen vorab trainierten Modells.
Prompt Tuning kann als vereinfachte Version von Prefix Tuning angesehen werden. Es definiert einen eigenen Prompt für jede Aufgabe und fügt ihn dann als Eingabe in die Daten ein, fügt jedoch nur Prompt-Tokens zur Eingabeebene hinzu und muss kein MLP hinzufügen zur Anpassung, um schwierige Trainingsprobleme zu lösen.
Durch Experimente wurde festgestellt, dass sich die Prompt-Tuning-Methode mit zunehmender Anzahl der Parameter des vorab trainierten Modells den Ergebnissen einer vollständigen Parameter-Feinabstimmung annähert. Gleichzeitig schlug Prompt Tuning auch Prompt Ensembling vor, was bedeutet, dass verschiedene Eingabeaufforderungen für dieselbe Aufgabe gleichzeitig in einem Stapel trainiert werden (d. h. dieselbe Frage auf mehrere verschiedene Arten gestellt wird). Dies entspricht dem Training verschiedener Modelle. Beispielsweise sind die Kosten für die Modellintegration viel geringer. Darüber hinaus werden im Prompt-Tuning-Papier auch die Auswirkungen der Initialisierungsmethode und der Länge des Prompt-Tokens auf die Modellleistung erörtert. Anhand der Ergebnisse des Ablationsexperiments wurde festgestellt, dass Prompt Tuning im Vergleich zur zufälligen Initialisierung und Initialisierung unter Verwendung von Beispielvokabular Klassenbezeichnungen verwendet, um das Modell besser zu initialisieren. Mit zunehmender Modellparameterskala wird diese Lücke jedoch irgendwann verschwinden. Die Leistung ist bereits gut, wenn die Länge des Prompt-Tokens etwa 20 beträgt (nach Überschreiten von 20 wird die Leistung des Modells durch Erhöhen der Länge des Prompt-Tokens nicht wesentlich verbessert). Das heißt, bei sehr großen Modellen hat die Länge des Prompt-Tokens keine großen Auswirkungen auf die Leistung, selbst wenn die Länge des Prompt-Tokens sehr kurz ist.
Das obige ist der detaillierte Inhalt vonEffiziente Parameter-Feinabstimmung umfangreicher Sprachmodelle – BitFit/Prefix/Prompt-Feinabstimmungsserie. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 Tokenisierung in einem Artikel verstehen!
Apr 12, 2024 pm 02:31 PM
Tokenisierung in einem Artikel verstehen!
Apr 12, 2024 pm 02:31 PM
Sprachmodelle basieren auf Text, der normalerweise in Form von Zeichenfolgen vorliegt. Da die Eingabe in das Modell jedoch nur Zahlen sein kann, muss der Text in eine numerische Form umgewandelt werden. Die Tokenisierung ist eine grundlegende Aufgabe der Verarbeitung natürlicher Sprache. Sie kann eine fortlaufende Textsequenz (z. B. Sätze, Absätze usw.) entsprechend den spezifischen Anforderungen in eine Zeichenfolge (z. B. Wörter, Phrasen, Zeichen, Satzzeichen usw.) unterteilen. Die darin enthaltenen Einheiten werden als Token oder Wort bezeichnet. Gemäß dem in der Abbildung unten gezeigten spezifischen Prozess werden die Textsätze zunächst in Einheiten unterteilt, dann werden die einzelnen Elemente digitalisiert (in Vektoren abgebildet), dann werden diese Vektoren zur Codierung in das Modell eingegeben und schließlich an nachgelagerte Aufgaben ausgegeben erhalten Sie weiterhin das Endergebnis. Die Textsegmentierung kann entsprechend der Granularität der Textsegmentierung in Toke unterteilt werden.
 Um ein neues wissenschaftliches und komplexes Frage-Antwort-Benchmark- und Bewertungssystem für große Modelle bereitzustellen, haben UNSW, Argonne, die University of Chicago und andere Institutionen gemeinsam das SciQAG-Framework eingeführt
Jul 25, 2024 am 06:42 AM
Um ein neues wissenschaftliches und komplexes Frage-Antwort-Benchmark- und Bewertungssystem für große Modelle bereitzustellen, haben UNSW, Argonne, die University of Chicago und andere Institutionen gemeinsam das SciQAG-Framework eingeführt
Jul 25, 2024 am 06:42 AM
Herausgeber | Der Frage-Antwort-Datensatz (QA) von ScienceAI spielt eine entscheidende Rolle bei der Förderung der Forschung zur Verarbeitung natürlicher Sprache (NLP). Hochwertige QS-Datensätze können nicht nur zur Feinabstimmung von Modellen verwendet werden, sondern auch effektiv die Fähigkeiten großer Sprachmodelle (LLMs) bewerten, insbesondere die Fähigkeit, wissenschaftliche Erkenntnisse zu verstehen und zu begründen. Obwohl es derzeit viele wissenschaftliche QS-Datensätze aus den Bereichen Medizin, Chemie, Biologie und anderen Bereichen gibt, weisen diese Datensätze immer noch einige Mängel auf. Erstens ist das Datenformular relativ einfach, die meisten davon sind Multiple-Choice-Fragen. Sie sind leicht auszuwerten, schränken jedoch den Antwortauswahlbereich des Modells ein und können die Fähigkeit des Modells zur Beantwortung wissenschaftlicher Fragen nicht vollständig testen. Im Gegensatz dazu offene Fragen und Antworten
 Effiziente Parameter-Feinabstimmung umfangreicher Sprachmodelle – BitFit/Prefix/Prompt-Feinabstimmungsserie
Oct 07, 2023 pm 12:13 PM
Effiziente Parameter-Feinabstimmung umfangreicher Sprachmodelle – BitFit/Prefix/Prompt-Feinabstimmungsserie
Oct 07, 2023 pm 12:13 PM
Im Jahr 2018 veröffentlichte Google BERT. Nach seiner Veröffentlichung übertraf es die State-of-the-Art-Ergebnisse (Sota) von 11 NLP-Aufgaben und stellte damit einen neuen Meilenstein in der NLP-Welt dar In der Abbildung unten ist der Trainingsprozess des BERT-Modells dargestellt, rechts der Feinabstimmungsprozess für bestimmte Aufgaben. Unter anderem dient die Feinabstimmungsphase der Feinabstimmung, wenn sie anschließend in einigen nachgelagerten Aufgaben verwendet wird, wie z. B. Textklassifizierung, Wortartkennzeichnung, Frage- und Antwortsysteme usw. BERT kann auf verschiedene Arten feinabgestimmt werden Aufgaben ohne Anpassung der Struktur. Durch das Aufgabendesign „vorab trainiertes Sprachmodell + Feinabstimmung der nachgelagerten Aufgabe“ werden leistungsstarke Modelleffekte erzielt. Seitdem ist „Sprachmodell vor dem Training + Feinabstimmung der nachgelagerten Aufgabe“ zum Mainstream-Training im NLP-Bereich geworden.
 Drei Geheimnisse für die Bereitstellung großer Modelle in der Cloud
Apr 24, 2024 pm 03:00 PM
Drei Geheimnisse für die Bereitstellung großer Modelle in der Cloud
Apr 24, 2024 pm 03:00 PM
Zusammenstellung|Produziert von Ich fange an, serverloses Cloud Computing zu vermissen. Ihre Anwendungen reichen von der Verbesserung der Konversations-KI bis hin zur Bereitstellung komplexer Analyselösungen für verschiedene Branchen und vielen anderen Funktionen. Viele Unternehmen setzen diese Modelle auf Cloud-Plattformen ein, da öffentliche Cloud-Anbieter bereits ein fertiges Ökosystem bereitstellen und dies der Weg des geringsten Widerstands ist. Allerdings ist es nicht billig. Die Cloud bietet darüber hinaus weitere Vorteile wie Skalierbarkeit, Effizienz und erweiterte Rechenfunktionen (GPUs auf Anfrage verfügbar). Es gibt einige wenig bekannte Aspekte der Bereitstellung von LLM auf öffentlichen Cloud-Plattformen
 RoSA: Eine neue Methode zur effizienten Feinabstimmung großer Modellparameter
Jan 18, 2024 pm 05:27 PM
RoSA: Eine neue Methode zur effizienten Feinabstimmung großer Modellparameter
Jan 18, 2024 pm 05:27 PM
Da Sprachmodelle in einem noch nie dagewesenen Ausmaß skaliert werden, wird eine umfassende Feinabstimmung für nachgelagerte Aufgaben unerschwinglich teuer. Um dieses Problem zu lösen, begannen Forscher, der PEFT-Methode Aufmerksamkeit zu schenken und sie zu übernehmen. Die Hauptidee der PEFT-Methode besteht darin, den Umfang der Feinabstimmung auf einen kleinen Satz von Parametern zu beschränken, um die Rechenkosten zu senken und gleichzeitig eine hochmoderne Leistung bei Aufgaben zum Verstehen natürlicher Sprache zu erzielen. Auf diese Weise können Forscher Rechenressourcen einsparen und gleichzeitig eine hohe Leistung aufrechterhalten, wodurch neue Forschungsschwerpunkte auf dem Gebiet der Verarbeitung natürlicher Sprache entstehen. RoSA ist eine neue PEFT-Technik, die durch Experimente mit einer Reihe von Benchmarks gezeigt hat, dass sie frühere Low-Rank-Adaptive- (LoRA) und reine Sparse-Feinabstimmungsmethoden mit demselben Parameterbudget übertrifft. Dieser Artikel wird näher darauf eingehen
 Den größten ViT der Geschichte bequem trainiert? Google aktualisiert das visuelle Sprachmodell PaLI: unterstützt mehr als 100 Sprachen
Apr 12, 2023 am 09:31 AM
Den größten ViT der Geschichte bequem trainiert? Google aktualisiert das visuelle Sprachmodell PaLI: unterstützt mehr als 100 Sprachen
Apr 12, 2023 am 09:31 AM
Der Fortschritt der Verarbeitung natürlicher Sprache ist in den letzten Jahren größtenteils auf groß angelegte Sprachmodelle zurückzuführen, die die Menge an Parametern und Trainingsdaten auf neue Höchstwerte bringen, und gleichzeitig werden die bestehenden Benchmark-Rankings geschlachtet! Beispielsweise veröffentlichte Google im April dieses Jahres das Sprachmodell PaLM (Pathways Language Model) mit 540 Milliarden Parametern, das Menschen in einer Reihe von Sprach- und Argumentationstests erfolgreich übertraf, insbesondere durch seine hervorragende Leistung in Lernszenarien mit wenigen Schüssen und kleinen Stichproben. PaLM gilt als Entwicklungsrichtung des Sprachmodells der nächsten Generation. Auf die gleiche Weise wirken visuelle Sprachmodelle tatsächlich Wunder, und die Leistung kann durch Erhöhen der Modellgröße verbessert werden. Natürlich, wenn es sich nur um ein multitaskingfähiges visuelles Sprachmodell handelt
 Meta führt das KI-Sprachmodell LLaMA ein, ein groß angelegtes Sprachmodell mit 65 Milliarden Parametern
Apr 14, 2023 pm 06:58 PM
Meta führt das KI-Sprachmodell LLaMA ein, ein groß angelegtes Sprachmodell mit 65 Milliarden Parametern
Apr 14, 2023 pm 06:58 PM
Laut Nachrichten vom 25. Februar gab Meta am Freitag Ortszeit bekannt, dass es ein neues groß angelegtes Sprachmodell auf Basis künstlicher Intelligenz (KI) für die Forschungsgemeinschaft einführen wird und sich damit Microsoft, Google und anderen von ChatGPT angeregten Unternehmen anschließt, sich künstlicher Intelligenz anzuschließen . Intelligenter Wettbewerb. Metas LLaMA ist die Abkürzung für „Large Language Model MetaAI“ (LargeLanguageModelMetaAI), das Forschern und Einrichtungen in Regierung, Gemeinschaft und Wissenschaft unter einer nichtkommerziellen Lizenz zur Verfügung steht. Das Unternehmen stellt den Benutzern den zugrunde liegenden Code zur Verfügung, damit diese das Modell selbst optimieren und für forschungsbezogene Anwendungsfälle verwenden können. Meta gab an, dass das Modell Anforderungen an die Rechenleistung habe
 BLOOM kann eine neue Kultur für die KI-Forschung schaffen, aber es bleiben Herausforderungen bestehen
Apr 09, 2023 pm 04:21 PM
BLOOM kann eine neue Kultur für die KI-Forschung schaffen, aber es bleiben Herausforderungen bestehen
Apr 09, 2023 pm 04:21 PM
Übersetzer |. Rezensiert von Li Rui |. Das BigScience-Forschungsprojekt hat kürzlich ein großes Sprachmodell BLOOM veröffentlicht. Auf den ersten Blick sieht es wie ein weiterer Versuch aus, OpenAIs GPT-3 zu kopieren. Was BLOOM jedoch von anderen großen Modellen natürlicher Sprache (LLMs) unterscheidet, sind seine Bemühungen, Modelle für maschinelles Lernen zu erforschen, zu entwickeln, zu trainieren und freizugeben. In den letzten Jahren haben große Technologieunternehmen groß angelegte Modelle natürlicher Sprache (LLMs) wie strenge Geschäftsgeheimnisse versteckt, und das BigScience-Team hat von Beginn des Projekts an Transparenz und Offenheit in den Mittelpunkt von BLOOM gestellt. Das Ergebnis ist ein groß angelegtes Sprachmodell, das studiert und studiert und jedem zugänglich gemacht werden kann. B
