
 Technologie-Peripheriegeräte
KI
770 Millionen Parameter, mehr als 540 Milliarden PaLM! UW Google schlägt eine „schrittweise Destillation' vor, die nur 80 % der Trainingsdaten ACL 2023 erfordert
Technologie-Peripheriegeräte
KI
770 Millionen Parameter, mehr als 540 Milliarden PaLM! UW Google schlägt eine „schrittweise Destillation' vor, die nur 80 % der Trainingsdaten ACL 2023 erfordert
770 Millionen Parameter, mehr als 540 Milliarden PaLM! UW Google schlägt eine „schrittweise Destillation' vor, die nur 80 % der Trainingsdaten ACL 2023 erfordert

Große Sprachmodelle zeichnen sich durch hervorragende Leistung aus und sind in der Lage, neue Aufgaben mit Null- oder Wenig-Schuss-Hinweisen zu lösen. Bei der tatsächlichen Anwendungsbereitstellung ist LLM jedoch nicht sehr praktisch, da es eine geringe Speicherauslastungseffizienz aufweist und viele Rechenressourcen erfordert. Beispielsweise sind für die Ausführung eines Sprachmodelldienstes mit 175 Milliarden Parametern mindestens 350 GB Videospeicher erforderlich Stand der Technik Die meisten Sprachmodelle haben mehr als 500 Milliarden Parameter. Viele Forschungsteams verfügen nicht über genügend Ressourcen, um sie auszuführen, und sie können die Leistung mit geringer Latenz in realen Anwendungen nicht erreichen.
Es gibt auch einige Studien, die manuell gekennzeichnete Daten oder Destillation mithilfe von LLM-generierten Etiketten verwenden, um kleinere, aufgabenspezifische Modelle zu trainieren. Für die Feinabstimmung und Destillation ist jedoch eine große Menge an Trainingsdaten erforderlich, um eine mit LLM vergleichbare Leistung zu erzielen.
Um das Problem des Ressourcenbedarfs für große Modelle zu lösen, haben die University of Washington und Google gemeinsam einen neuen Destillationsmechanismus namens „Distilling Step-by-Step“ vorgeschlagen. Durch die schrittweise Destillation ist die Größe des destillierten Modells kleiner als die des Originalmodells, aber die Leistung ist besser und während des Feinabstimmungs- und Destillationsprozesses sind weniger Trainingsdaten erforderlich

Nach der Durchführung von Experimenten mit 4 NLP-Benchmarks haben wir Folgendes festgestellt:
1. Im Vergleich zu Feinabstimmung und Destillation erzielt dieser Mechanismus eine bessere Leistung mit weniger Trainingsbeispielen Größe von Modellen, um eine bessere Leistung zu erzielen
Die Verteilungsdestillation umfasst hauptsächlich zwei Phasen:
1. Extrahieren von Prinzipien (Begründung) aus LLM 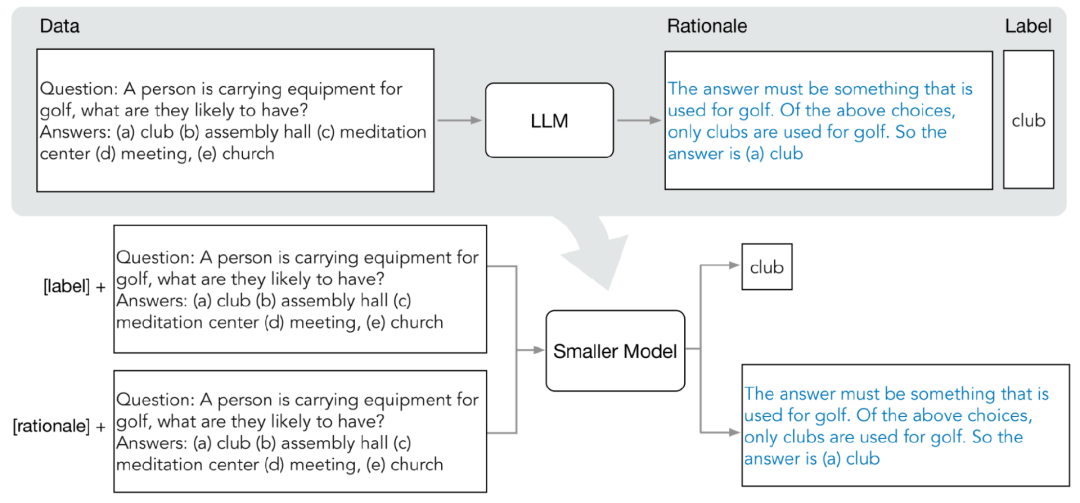
Nachdem Sie die Zielaufgabe festgelegt haben, bereiten Sie zunächst einige Beispiele in der LLM-Eingabeaufforderung vor. Jedes Beispiel besteht aus einem Triplett, einschließlich Eingabe, Prinzip und Ausgabe.
Nach der Eingabe von Eingabeaufforderungen ist LLM in der Lage, die Triplett-Demonstration zu imitieren, um Vorhersageprinzipien für andere neue Fragen zu generieren, beispielsweise für die Frage-und-Antwort-Aufgabe des gesunden Menschenverstandes , gegebene
Eingabefrage:Sammy möchte an einen Ort gehen, an dem sich Menschen treffen. Wo wird er wählen? Antwortmöglichkeiten: (a) besiedelte Gebiete, (b) Rennstrecke, (c) Wüste, (d) Wohnung, (e) Straßensperre)
Nach schrittweiser Verfeinerung kann LLM die richtige Antwort auf die Frage „(a)“ geben. Bevölkerung „Dicht besiedelte Gebiete“ und geben Sie Gründe für die Beantwortung der Frage an: „Die Antwort muss ein Ort mit vielen Menschen sein. Von den oben genannten Auswahlmöglichkeiten haben nur dicht besiedelte Gebiete viele Menschen.“
Nach schrittweiser Verfeinerung kam LLM zu dem Schluss, dass die richtige Antwort „(ein) dicht besiedeltes Gebiet“ ist, und gab den Grund für die Beantwortung der Frage an: „Die Antwort muss ein Ort mit vielen Menschen sein. Unter den oben genannten Auswahlmöglichkeiten sind nur dicht besiedelte Gebiete.“ viele Leute haben. „Menschen.“ Durch die Bereitstellung von CoT-Beispielen gepaart mit Begründungen in Eingabeaufforderungen ermöglicht die kontextbezogene Lernfunktion LLM, entsprechende Antwortgründe für nicht angetroffene Fragetypen zu generieren 2. Trainieren Sie kleine Modelle. Die Vorhersagegründe können extrahiert und in das kleine Trainingsmodell integriert werden Zusätzlich zur Standardaufgabe zur Etikettenvorhersage verwendeten die Forscher auch eine neue Aufgabe zur Generierung von Gründen, um das kleine Modell zu trainieren, damit das Modell lernen kann, Benutzer zu generieren ein Zwischeninferenzschritt für die Vorhersage und leitet das Modell an, die Ergebnisbezeichnung besser vorherzusagen. Unterscheiden Sie Etikettenvorhersage- und Begründungsgenerierungsaufgaben, indem Sie der Eingabeaufforderung die Aufgabenpräfixe „Label“ und „Begründung“ hinzufügen. Experimentelle Ergebnisse In dem Experiment wählten die Forscher das PaLM-Modell mit 540 Milliarden Parametern als LLM-Basislinie und verwendeten das T5-Modell als aufgabenbezogenes Downstream-Kleinmodell. Kleinere Bereitstellung Modellgröße Kleineres Modell, weniger Daten Während wir die Modellgröße und die Trainingsdaten reduziert haben, haben wir erfolgreich eine Leistung erreicht, die über wenige PaLM-Aufnahmen hinausgeht.In ANLI übertrifft das T5-Modell mit 770M das 540B PaLM, während es nur 80 % des gesamten Datensatzes nutzt In dieser Studie haben wir Experimente mit vier Benchmark-Datensätzen durchgeführt, nämlich e-SNLI und ANLI für das Denken in natürlicher Sprache, CQA für die Beantwortung von Fragen mit gesundem Menschenverstand und SVAMP für Fragen zu arithmetischen Mathematikanwendungen. Wir haben Experimente zu diesen drei verschiedenen NLP-Aufgaben durchgeführt Die Standard-Feinabstimmung wird erreicht, wenn 12,5 % des gesamten Datensatzes verwendet werden, und nur 75 %, 25 % bzw. 20 % der Trainingsdaten sind für ANLI, CQA und SVAMP erforderlich.
Im Vergleich zur Standard-Feinabstimmung an vom Menschen markierten Datensätzen unterschiedlicher Größe unter Verwendung eines 220M-T5-Modells übertrifft die Verteilungsdestillation die Standard-Feinabstimmung am gesamten Datensatz, wenn weniger Trainingsbeispiele für alle Datensätze verwendet werden. 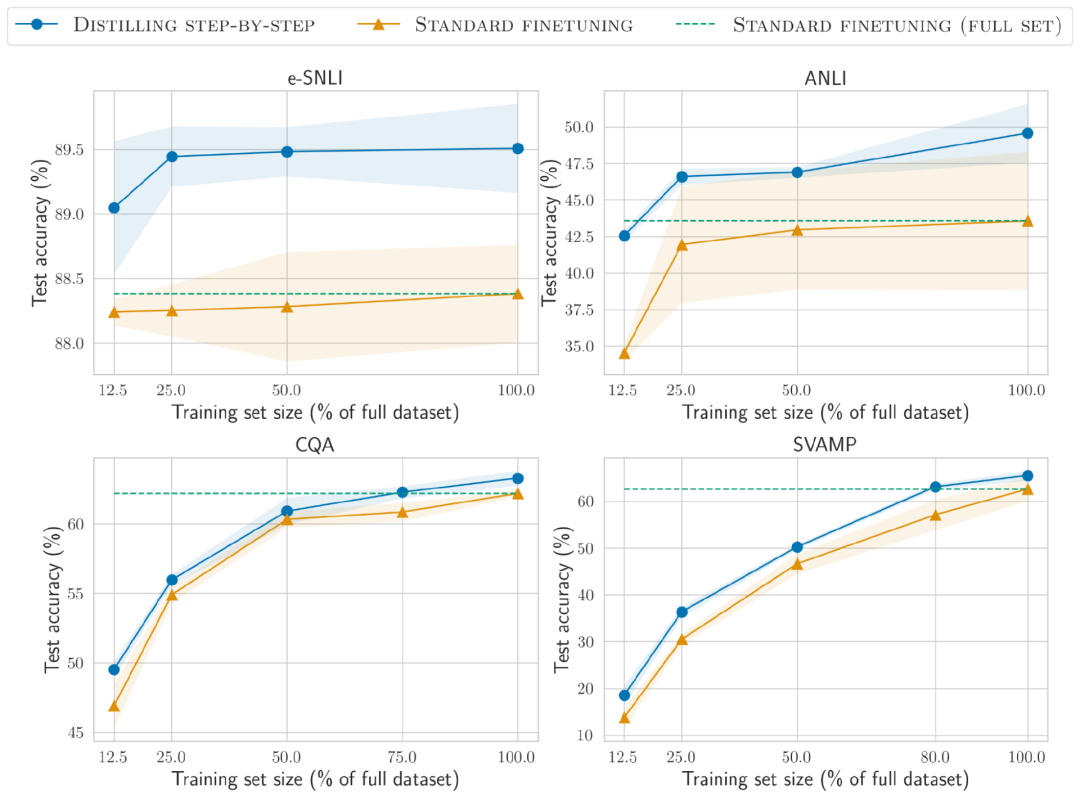
Das obige ist der detaillierte Inhalt von770 Millionen Parameter, mehr als 540 Milliarden PaLM! UW Google schlägt eine „schrittweise Destillation' vor, die nur 80 % der Trainingsdaten ACL 2023 erfordert. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 PhpMyAdmin erstellt Datentabelle
Apr 10, 2025 pm 11:00 PM
PhpMyAdmin erstellt Datentabelle
Apr 10, 2025 pm 11:00 PM
Um eine Datentabelle mithilfe von PHPMYADMIN zu erstellen, sind die folgenden Schritte unerlässlich: Stellen Sie eine Verbindung zur Datenbank her und klicken Sie auf die neue Registerkarte. Nennen Sie die Tabelle und wählen Sie die Speichermotor (innoDB empfohlen). Fügen Sie Spaltendetails hinzu, indem Sie auf die Taste der Spalte hinzufügen, einschließlich Spaltenname, Datentyp, ob Nullwerte und andere Eigenschaften zuzulassen. Wählen Sie eine oder mehrere Spalten als Primärschlüssel aus. Klicken Sie auf die Schaltfläche Speichern, um Tabellen und Spalten zu erstellen.
 Erstellen einer Oracle -Datenbank So erstellen Sie eine Oracle -Datenbank
Apr 11, 2025 pm 02:33 PM
Erstellen einer Oracle -Datenbank So erstellen Sie eine Oracle -Datenbank
Apr 11, 2025 pm 02:33 PM
Das Erstellen einer Oracle -Datenbank ist nicht einfach, Sie müssen den zugrunde liegenden Mechanismus verstehen. 1. Sie müssen die Konzepte von Datenbank und Oracle DBMS verstehen. 2. Beherrschen Sie die Kernkonzepte wie SID, CDB (Containerdatenbank), PDB (Pluggable -Datenbank); 3.. Verwenden Sie SQL*Plus, um CDB zu erstellen und dann PDB zu erstellen. Sie müssen Parameter wie Größe, Anzahl der Datendateien und Pfade angeben. 4. Erweiterte Anwendungen müssen den Zeichensatz, den Speicher und andere Parameter anpassen und die Leistungsstimmung durchführen. 5. Achten Sie auf Speicherplatz, Berechtigungen und Parametereinstellungen und überwachen und optimieren Sie die Datenbankleistung kontinuierlich. Nur indem Sie es geschickt beherrschen, müssen Sie die Erstellung und Verwaltung von Oracle -Datenbanken wirklich verstehen.
 So erstellen Sie die Oracle -Datenbank So erstellen Sie die Oracle -Datenbank
Apr 11, 2025 pm 02:36 PM
So erstellen Sie die Oracle -Datenbank So erstellen Sie die Oracle -Datenbank
Apr 11, 2025 pm 02:36 PM
Um eine Oracle -Datenbank zu erstellen, besteht die gemeinsame Methode darin, das dbca -grafische Tool zu verwenden. Die Schritte sind wie folgt: 1. Verwenden Sie das DBCA -Tool, um den DBNAME festzulegen, um den Datenbanknamen anzugeben. 2. Setzen Sie Syspassword und SystemPassword auf starke Passwörter. 3.. Setzen Sie Charaktere und NationalCharacterset auf AL32UTF8; 4. Setzen Sie MemorySize und tablespacesize, um sie entsprechend den tatsächlichen Bedürfnissen anzupassen. 5. Geben Sie den Logfile -Pfad an. Erweiterte Methoden werden manuell mit SQL -Befehlen erstellt, sind jedoch komplexer und anfällig für Fehler. Achten Sie auf die Kennwortstärke, die Auswahl der Zeichensatz, die Größe und den Speicher von Tabellenräumen
 So schreiben Sie Oracle -Datenbankanweisungen
Apr 11, 2025 pm 02:42 PM
So schreiben Sie Oracle -Datenbankanweisungen
Apr 11, 2025 pm 02:42 PM
Der Kern von Oracle SQL -Anweisungen ist ausgewählt, einfügen, aktualisiert und löschen sowie die flexible Anwendung verschiedener Klauseln. Es ist wichtig, den Ausführungsmechanismus hinter der Aussage wie die Indexoptimierung zu verstehen. Zu den erweiterten Verwendungen gehören Unterabfragen, Verbindungsabfragen, Analysefunktionen und PL/SQL. Häufige Fehler sind Syntaxfehler, Leistungsprobleme und Datenkonsistenzprobleme. Best Practices für Leistungsoptimierung umfassen die Verwendung geeigneter Indizes, die Vermeidung von Auswahl *, optimieren Sie, wo Klauseln und gebundene Variablen verwenden. Das Beherrschen von Oracle SQL erfordert Übung, einschließlich des Schreibens von Code, Debuggen, Denken und Verständnis der zugrunde liegenden Mechanismen.
 Hinzufügen, Ändern und Löschen von MySQL Data Table Field Operation Operation Guide, addieren, ändern und löschen
Apr 11, 2025 pm 05:42 PM
Hinzufügen, Ändern und Löschen von MySQL Data Table Field Operation Operation Guide, addieren, ändern und löschen
Apr 11, 2025 pm 05:42 PM
Feldbetriebshandbuch in MySQL: Felder hinzufügen, ändern und löschen. Feld hinzufügen: Alter table table_name hinzufügen column_name data_type [nicht null] [Standard default_value] [Primärschlüssel] [auto_increment] Feld ändern: Alter table table_name Ändern Sie Column_Name Data_type [nicht null] [diffault default_value] [Primärschlüssel] [Primärschlüssel]
 Was sind die Integritätsbeschränkungen von Oracle -Datenbanktabellen?
Apr 11, 2025 pm 03:42 PM
Was sind die Integritätsbeschränkungen von Oracle -Datenbanktabellen?
Apr 11, 2025 pm 03:42 PM
Die Integritätsbeschränkungen von Oracle -Datenbanken können die Datengenauigkeit sicherstellen, einschließlich: nicht Null: Nullwerte sind verboten; Einzigartig: Einzigartigkeit garantieren und einen einzelnen Nullwert ermöglichen; Primärschlüssel: Primärschlüsselbeschränkung, Stärkung der einzigartigen und verboten Nullwerte; Fremdschlüssel: Verwalten Sie die Beziehungen zwischen Tabellen, Fremdschlüssel beziehen sich auf Primärtabellen -Primärschlüssel. Überprüfen Sie: Spaltenwerte nach Bedingungen begrenzen.
 Detaillierte Erläuterung verschachtelter Abfrageinstanzen in der MySQL -Datenbank
Apr 11, 2025 pm 05:48 PM
Detaillierte Erläuterung verschachtelter Abfrageinstanzen in der MySQL -Datenbank
Apr 11, 2025 pm 05:48 PM
Verschachtelte Anfragen sind eine Möglichkeit, eine andere Frage in eine Abfrage aufzunehmen. Sie werden hauptsächlich zum Abrufen von Daten verwendet, die komplexe Bedingungen erfüllen, mehrere Tabellen assoziieren und zusammenfassende Werte oder statistische Informationen berechnen. Beispiele hierfür sind zu findenen Mitarbeitern über den überdurchschnittlichen Löhnen, das Finden von Bestellungen für eine bestimmte Kategorie und die Berechnung des Gesamtbestellvolumens für jedes Produkt. Beim Schreiben verschachtelter Abfragen müssen Sie folgen: Unterabfragen schreiben, ihre Ergebnisse in äußere Abfragen schreiben (auf Alias oder als Klauseln bezogen) und optimieren Sie die Abfrageleistung (unter Verwendung von Indizes).
 Wie Tomcat -Protokolle bei der Fehlerbehebung bei Speicherlecks helfen
Apr 12, 2025 pm 11:42 PM
Wie Tomcat -Protokolle bei der Fehlerbehebung bei Speicherlecks helfen
Apr 12, 2025 pm 11:42 PM
Tomcat -Protokolle sind der Schlüssel zur Diagnose von Speicherleckproblemen. Durch die Analyse von Tomcat -Protokollen können Sie Einblicke in das Verhalten des Speicherverbrauchs und des Müllsammlung (GC) erhalten und Speicherlecks effektiv lokalisieren und auflösen. Hier erfahren Sie, wie Sie Speicherlecks mit Tomcat -Protokollen beheben: 1. GC -Protokollanalyse zuerst aktivieren Sie eine detaillierte GC -Protokollierung. Fügen Sie den Tomcat-Startparametern die folgenden JVM-Optionen hinzu: -xx: printgCDetails-xx: printgCDatESTAMPS-XLOGGC: GC.Log Diese Parameter generieren ein detailliertes GC-Protokoll (GC.Log), einschließlich Informationen wie GC-Typ, Recycling-Objektgröße und Zeit. Analyse gc.log
