
 Technologie-Peripheriegeräte
KI
Probleme bei der Annotation semantischer Rollen in der Technologie zum semantischen Verstehen von Texten
Technologie-Peripheriegeräte
KI
Probleme bei der Annotation semantischer Rollen in der Technologie zum semantischen Verstehen von Texten
Probleme bei der Annotation semantischer Rollen in der Technologie zum semantischen Verstehen von Texten


Das Problem der Annotation semantischer Rollen in der Technologie zum semantischen Verstehen von Texten erfordert spezifische Codebeispiele
Einführung
Im Bereich der Verarbeitung natürlicher Sprache ist die Technologie zum semantischen Verstehen von Texten eine Kernaufgabe. Unter diesen ist die Annotation semantischer Rollen eine wichtige Technologie, mit der die semantische Rolle jedes Wortes im Satz im Kontext identifiziert wird. In diesem Artikel werden die Konzepte und Herausforderungen der semantischen Rollenannotation vorgestellt und ein konkretes Codebeispiel zur Lösung des Problems bereitgestellt.
1. Was ist semantische Rollenbezeichnung?
Semantische Rollenbezeichnung (Semantic Role Labeling) bezieht sich auf die Aufgabe, semantische Rollen für jedes Wort in einem Satz zu kennzeichnen. Semantische Rollen-Tags stellen die Rolle eines Wortes in einem Satz dar, z. B. „Agent“, „Empfänger“, „Zeit“ usw. Durch semantische Rollenannotation können die semantischen Informationen und die Satzstruktur jedes Wortes im Satz verstanden werden.
Für den Satz „Xiao Ming hat einen Apfel gegessen“ kann die semantische Rollenanmerkung beispielsweise „Xiao Ming“ als „Agent“, „Apfel“ als „Empfänger“, „essen“ als „Aktion“ usw. markieren „Eins“ bedeutet „Menge“.
Semantische Rollenannotation spielt eine wichtige Rolle bei Aufgaben wie dem maschinellen Verständnis natürlicher Sprache, der Beantwortung von Fragen in natürlicher Sprache und der maschinellen Übersetzung.
2. Herausforderungen der semantischen Rollenannotation
Die semantische Rollenannotation steht vor einigen Herausforderungen. Erstens stellen verschiedene Sprachen semantische Rollen unterschiedlich dar, was die Komplexität der sprachübergreifenden Verarbeitung erhöht.
Zweitens muss die semantische Rollenannotation in Sätzen Kontextinformationen berücksichtigen. Beispielsweise „Xiao Ming aß einen Apfel“ und „Xiao Ming aß eine Banane“, obwohl die Wörter in den beiden Sätzen gleich sind, können ihre semantischen Rollenbezeichnungen unterschiedlich sein.
Darüber hinaus wird die semantische Rollenannotation auch durch Mehrdeutigkeit und Polysemie beeinflusst. Beispielsweise kann „er“ in „Er ging nach China“ „der Ausführende der Aktion“ oder „der Empfänger der Aktion“ bedeuten, was eine genaue semantische Rollenanmerkung basierend auf dem Kontext erfordert.
3. Implementierung der Annotation semantischer Rollen
Das Folgende ist ein Codebeispiel für die Annotation semantischer Rollen basierend auf Deep Learning unter Verwendung des PyTorch-Frameworks und des BiLSTM-CRF-Modells.
- Datenvorverarbeitung
Zuerst müssen die Trainingsdaten und Etiketten vorverarbeitet werden. Teilen Sie Sätze in Wörter auf und kennzeichnen Sie jedes Wort mit einer semantischen Rollenbezeichnung.
- Merkmalsextraktion
In der Phase der Merkmalsextraktion kann die Worteinbettung verwendet werden, um Wörter in Vektorform darzustellen, und einige andere Merkmale wie Wortart-Tags, Kontext usw. können hinzugefügt werden.
- Modellkonstruktion
Verwendung des BiLSTM-CRF-Modells zur semantischen Rollenannotation. BiLSTM (Bidirektionales Long-Short-Term-Memory-Network) wird zum Erfassen von Kontextinformationen verwendet, und CRF (Conditional Random Field) wird zum Modellieren der Übergangswahrscheinlichkeit des Etiketts verwendet.
- Modelltraining
Geben Sie die vorverarbeiteten Daten und Funktionen zum Training in das Modell ein und verwenden Sie den Gradientenabstiegsalgorithmus, um die Modellparameter zu optimieren.
- Modellvorhersage
Nach Abschluss des Modelltrainings können neue Sätze zur Vorhersage in das Modell eingegeben werden. Das Modell generiert für jedes Wort entsprechende semantische Rollenbezeichnungen.
Codebeispiel:
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
class SRLDataset(Dataset):
def __init__(self, sentences, labels):
self.sentences = sentences
self.labels = labels
def __len__(self):
return len(self.sentences)
def __getitem__(self, idx):
sentence = self.sentences[idx]
label = self.labels[idx]
return sentence, label
class BiLSTMCRF(nn.Module):
def __init__(self, embedding_dim, hidden_dim, num_classes):
super(BiLSTMCRF, self).__init__()
self.embedding_dim = embedding_dim
self.hidden_dim = hidden_dim
self.num_classes = num_classes
self.embedding = nn.Embedding(vocab_size, embedding_dim)
self.lstm = nn.LSTM(embedding_dim, hidden_dim // 2, bidirectional=True)
self.hidden2tag = nn.Linear(hidden_dim, num_classes)
self.crf = CRF(num_classes)
def forward(self, sentence):
embeds = self.embedding(sentence)
lstm_out, _ = self.lstm(embeds)
tag_space = self.hidden2tag(lstm_out)
return tag_space
def loss(self, sentence, targets):
forward_score = self.forward(sentence)
return self.crf.loss(forward_score, targets)
def decode(self, sentence):
forward_score = self.forward(sentence)
return self.crf.decode(forward_score)
# 数据准备
sentences = [['小明', '吃了', '一个', '苹果'], ['小明', '吃了', '一个', '香蕉']]
labels = [['施事者', '动作', '数量', '受事者'], ['施事者', '动作', '数量', '受事者']]
dataset = SRLDataset(sentences, labels)
# 模型训练
model = BiLSTMCRF(embedding_dim, hidden_dim, num_classes)
optimizer = optim.SGD(model.parameters(), lr=0.1)
data_loader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
for epoch in range(epochs):
for sentence, targets in data_loader:
optimizer.zero_grad()
sentence = torch.tensor(sentence)
targets = torch.tensor(targets)
loss = model.loss(sentence, targets)
loss.backward()
optimizer.step()
# 模型预测
new_sentence = [['小明', '去了', '中国']]
new_sentence = torch.tensor(new_sentence)
predicted_labels = model.decode(new_sentence)
print(predicted_labels)Fazit
Semantische Rollenannotation ist eine wichtige Aufgabe bei der Verarbeitung natürlicher Sprache. Durch die Annotation semantischer Rollen für Wörter in Sätzen können die semantischen Informationen und die Satzstruktur des Textes besser verstanden werden. In diesem Artikel werden die Konzepte und Herausforderungen der semantischen Rollenannotation vorgestellt und ein Deep-Learning-basiertes Codebeispiel zur Lösung des Problems bereitgestellt. Dies bietet Forschern und Praktikern eine Idee und Methode zur Implementierung und Verbesserung des semantischen Rollenannotationsmodells.
Das obige ist der detaillierte Inhalt vonProbleme bei der Annotation semantischer Rollen in der Technologie zum semantischen Verstehen von Texten. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 So erstellen Sie runde Bilder und Texte in ppt
Mar 26, 2024 am 10:23 AM
So erstellen Sie runde Bilder und Texte in ppt
Mar 26, 2024 am 10:23 AM
Zeichnen Sie zunächst einen Kreis in PPT, fügen Sie dann ein Textfeld ein und geben Sie den Textinhalt ein. Legen Sie abschließend die Füllung und den Umriss des Textfelds auf „Keine“ fest, um die Erstellung kreisförmiger Bilder und Texte abzuschließen.
 Wie füge ich in Word Punkte zum Text hinzu?
Mar 19, 2024 pm 08:04 PM
Wie füge ich in Word Punkte zum Text hinzu?
Mar 19, 2024 pm 08:04 PM
Wenn wir täglich Word-Dokumente erstellen, müssen wir manchmal Punkte unter bestimmten Wörtern im Dokument hinzufügen, insbesondere wenn es Testfragen gibt. Um diesen Teil des Inhalts hervorzuheben, gibt Ihnen der Herausgeber Tipps zum Hinzufügen von Punkten zu Text in Word. Ich hoffe, dass es Ihnen helfen kann. 1. Öffnen Sie ein leeres Word-Dokument. 2. Fügen Sie beispielsweise Punkte unter den Worten „So fügen Sie Punkte zum Text hinzu“ hinzu. 3. Wir wählen zunächst mit der linken Maustaste die Wörter „So fügen Sie Punkte zum Text hinzu“ aus. Beachten Sie, dass Sie, wenn Sie in Zukunft Punkte zu diesem Wort hinzufügen möchten, zunächst das Wort mit der linken Maustaste auswählen müssen . Heute fügen wir diesen Wörtern Punkte hinzu, daher haben wir mehrere Wörter ausgewählt. Wählen Sie diese Wörter aus, klicken Sie mit der rechten Maustaste und klicken Sie im Popup-Funktionsfeld auf Schriftart. 4. Dann erscheint so etwas
 Golang-Bildverarbeitung: Erfahren Sie, wie Sie Wasserzeichen und Text hinzufügen
Aug 17, 2023 am 08:41 AM
Golang-Bildverarbeitung: Erfahren Sie, wie Sie Wasserzeichen und Text hinzufügen
Aug 17, 2023 am 08:41 AM
Golang-Bildverarbeitung: Erfahren Sie, wie Sie Wasserzeichen und Textzitate hinzufügen: Im modernen Zeitalter der Digitalisierung und der sozialen Medien ist die Bildverarbeitung zu einer wichtigen Fähigkeit geworden. Ob für den persönlichen Gebrauch oder für geschäftliche Zwecke, das Hinzufügen von Wasserzeichen und Text ist ein häufiger Bedarf. In diesem Artikel erfahren Sie, wie Sie Golang für die Bildverarbeitung verwenden und wie Sie Wasserzeichen und Text hinzufügen. Hintergrund: Golang ist eine Open-Source-Programmiersprache, die für ihre prägnante Syntax, effiziente Leistung und leistungsstarke Parallelitätsfähigkeiten bekannt ist. es ist Gegenstand vieler Entwicklungen geworden
 So ändern Sie Text auf Bildern
Aug 29, 2023 am 10:29 AM
So ändern Sie Text auf Bildern
Aug 29, 2023 am 10:29 AM
Das Ändern des Texts auf dem Bild kann mithilfe von Bildbearbeitungsprogrammen, Online-Tools oder Screenshot-Tools erfolgen. Die einzelnen Schritte sind: 1. Öffnen Sie die Bildbearbeitungssoftware und importieren Sie das zu ändernde Bild. 3. Klicken Sie auf den Textbereich im Bild, um ein Textfeld zu erstellen 5. Wenn Sie nur den Text auf dem Bild löschen möchten, können Sie den Textbereich mit dem Radiergummi oder dem Auswahlwerkzeug auswählen und löschen.
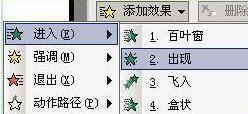 Detaillierte Methode zum Einrichten von PPT-Folien durch Bewegen der Maus über Text, um Bilder anzuzeigen
Mar 26, 2024 pm 03:40 PM
Detaillierte Methode zum Einrichten von PPT-Folien durch Bewegen der Maus über Text, um Bilder anzuzeigen
Mar 26, 2024 pm 03:40 PM
1. Legen Sie zunächst eine benutzerdefinierte Animation für das Bildobjekt fest. 2. Wenn Sie den Effekt realistischer gestalten möchten, verwenden Sie bitte den oben gezeigten Animationseffekt [Erscheinen]. Nachdem wir den benutzerdefinierten Effekt für das Bildobjekt festgelegt haben, sehen wir auf der rechten Seite des Fensters den Namen der benutzerdefinierten Animation, z. B. [1good] im Bild. Klicken Sie nun mit der linken Maustaste auf das kleine Dreieck nach unten in Richtung des Bildes zeigt, wird ein Popup mit der folgenden Abbildungsmenüliste angezeigt. 3. Wählen Sie im oben gezeigten Menü [Effektoptionen] und ein Popup wird angezeigt, wie im Bild gezeigt. 4. Wechseln Sie im Bild oben zur Registerkarte [Timing], klicken Sie auf [Trigger], wählen Sie dann unten [Effekt starten, wenn auf die folgenden Objekte geklickt wird] und wählen Sie rechts [Titel 1: Bild 1] aus. Diese Einstellung bedeutet, dass Sie beim Abspielen der Diashow auf den Text in [Bild 1] klicken
 Probleme bei der Annotation semantischer Rollen in der Technologie zum semantischen Verstehen von Texten
Oct 08, 2023 am 09:53 AM
Probleme bei der Annotation semantischer Rollen in der Technologie zum semantischen Verstehen von Texten
Oct 08, 2023 am 09:53 AM
Das Problem der semantischen Rollenannotation in der Technologie zum semantischen Verstehen von Texten erfordert spezifische Codebeispiele. Einführung Im Bereich der Verarbeitung natürlicher Sprache ist die Technologie zum semantischen Verstehen von Texten eine Kernaufgabe. Unter diesen ist die Annotation semantischer Rollen eine wichtige Technologie, mit der die semantische Rolle jedes Wortes im Satz im Kontext identifiziert wird. In diesem Artikel werden die Konzepte und Herausforderungen der semantischen Rollenannotation vorgestellt und ein konkretes Codebeispiel zur Lösung des Problems bereitgestellt. 1. Was ist semantische Rollenkennzeichnung (SemanticRoleLabeling)?
 So kombinieren Sie Text und Bilder in PPT
Mar 26, 2024 pm 03:16 PM
So kombinieren Sie Text und Bilder in PPT
Mar 26, 2024 pm 03:16 PM
1. Klicken Sie in der Menüleiste auf [Einfügen] und dann auf [Bild]. 2. Wählen Sie das gewünschte Bild aus. 3. Klicken Sie, um ein Textfeld einzufügen, und wählen Sie [Horizontales Textfeld]. 4. Geben Sie Text in das eingefügte Textfeld ein. 5. Halten Sie die Strg-Taste gedrückt, während Sie das Bild und das Textfeld auswählen. 6. Klicken Sie mit der rechten Maustaste und klicken Sie auf [Kombinieren]. 7. Zu diesem Zeitpunkt werden das Bild und das Textfeld miteinander kombiniert.
 So lesen Sie Texte auf Tomato Listen
Feb 27, 2024 pm 03:58 PM
So lesen Sie Texte auf Tomato Listen
Feb 27, 2024 pm 03:58 PM
In einem geschäftigen Leben können Sie ganz einfach wundervolle Geschichten mit Ihren Ohren hören und gleichzeitig bei Bedarf ganz einfach auf das Lesen von Texten umschalten und auf Tomato hören. Diese einzigartige, neuartige Software bietet Ihnen ein beispielloses Doppelerlebnis. Viele Benutzer stoßen jedoch während des Verwendungsprozesses auf Text, den sie sorgfältig lesen möchten oder den sie nicht klar hören können, aber sie wissen nicht, wie sie den Text direkt anzeigen sollen. Benutzer, die es wissen möchten, folgen bitte diesem Artikel Details. Finden Sie es heraus. Wie liest man Texte zum Thema „Tomato Listening“? Antwort: [Tomato Listening] – [Roman] – [E-Books lesen]. Konkrete Schritte: Starten Sie zunächst die Tomato Listening-Software. Nach dem Aufrufen der Homepage finden Sie viele beliebte Romane zur Auswahl. Wählen Sie hier einen Roman aus und klicken Sie, um ihn zu lesen. 2. Dann auf der Detailseite des Romans: I
