
 Technologie-Peripheriegeräte
KI
Brechen Sie die Blackbox großer Modelle und zerlegen Sie Neuronen vollständig! OpenAI-Konkurrent Anthropic durchbricht die Barriere der KI-Unerklärbarkeit
Technologie-Peripheriegeräte
KI
Brechen Sie die Blackbox großer Modelle und zerlegen Sie Neuronen vollständig! OpenAI-Konkurrent Anthropic durchbricht die Barriere der KI-Unerklärbarkeit
Brechen Sie die Blackbox großer Modelle und zerlegen Sie Neuronen vollständig! OpenAI-Konkurrent Anthropic durchbricht die Barriere der KI-Unerklärbarkeit

Seit vielen Jahren können wir nicht verstehen, wie künstliche Intelligenz Entscheidungen trifft und Ergebnisse generiert.
Modellentwickler können nur über den Algorithmus und die Daten entscheiden und schließlich die Ausgabe des Modells erhalten Das Modell basiert auf diesen Algorithmen und die Ergebnisse der Datenausgabe werden zu unsichtbaren „Black Boxes“.

Es gibt also einen Witz wie „Modelltraining ist wie Alchemie“.
Aber jetzt ist die Modell-Blackbox endlich interpretierbar!
Das Forschungsteam von Anthropic extrahierte die interpretierbaren Merkmale der grundlegendsten Einheitsneuronen im neuronalen Netzwerk des Modells.

Dies wird ein bahnbrechender Schritt für die Menschheit sein, die KI-Blackbox aufzudecken.
Anthropic äußerte sich begeistert:
„Wenn wir verstehen können, wie das neuronale Netzwerk im Modell funktioniert, können wir die Fehlermodi des Modells diagnostizieren, Korrekturen entwerfen und dafür sorgen, dass das Modell sicher von Unternehmen und der Gesellschaft übernommen wird.“ Es wird in greifbarer Nähe Wirklichkeit werden!“
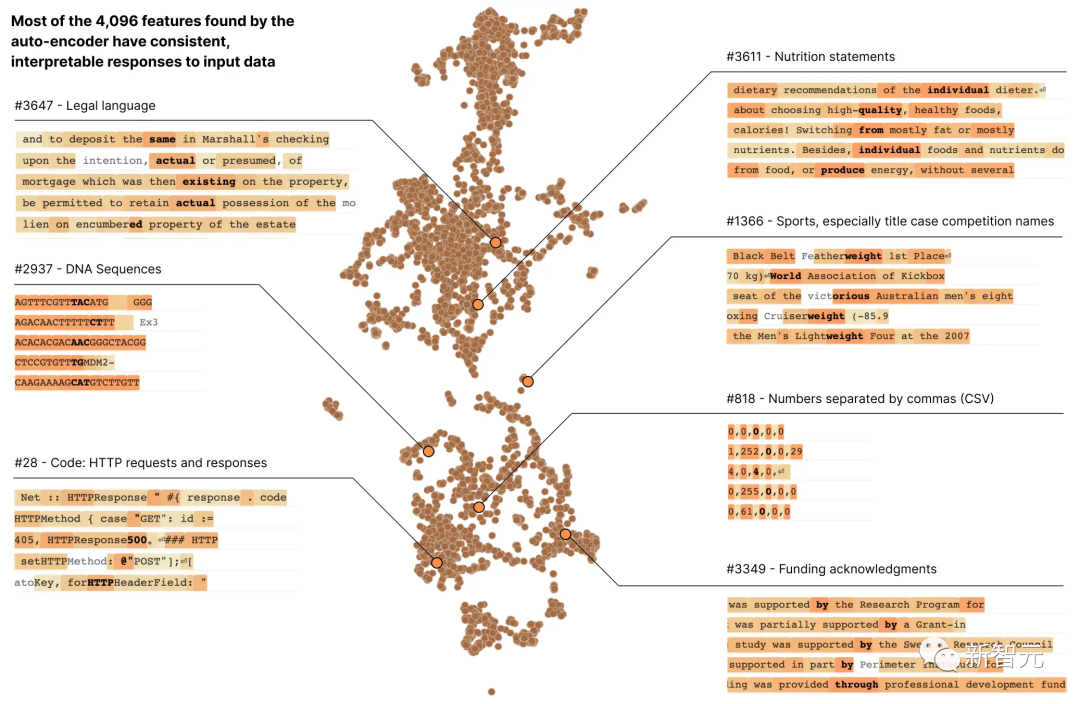
In Anthropics neuestem Forschungsbericht „Toward Monosemantity: Decomposed Language Models with Dictionary Learning“ verwendeten Forscher Wörterbuchlernmethoden, um die Schicht aus 512 Neuronen erfolgreich in mehrere zu zerlegen mehr als 4000 interpretierbare Merkmale Hebräischer Text, Nährwertangaben usw.
 Die meisten dieser Modelleigenschaften können wir nicht erkennen, wenn wir die Aktivierung eines einzelnen Neurons isoliert betrachten.
Die meisten dieser Modelleigenschaften können wir nicht erkennen, wenn wir die Aktivierung eines einzelnen Neurons isoliert betrachten.
Die meisten Neuronen sind „polysemantisch“, was so viel bedeutet Es gibt keine konsistente Entsprechung zwischen einzelnen Neuronen und dem Netzwerkverhalten.
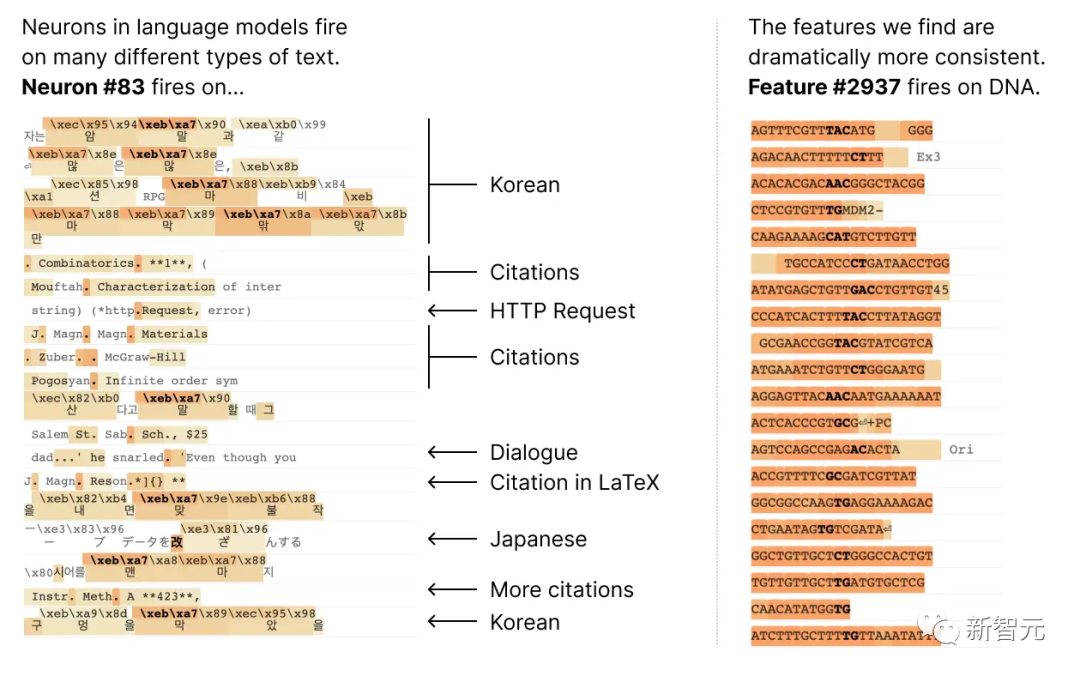
Beispielsweise ist in einem kleinen Sprachmodell ein einzelnes Neuronen-Meta in vielen unabhängigen Kontexten aktiv, darunter: akademische Zitate, englische Konversationen, HTTP-Anfragen und koreanischer Text.
 Und im klassischen Sehmodell würde ein einzelnes Neuron auf das Gesicht einer Katze und die Vorderseite eines Autos reagieren.
Und im klassischen Sehmodell würde ein einzelnes Neuron auf das Gesicht einer Katze und die Vorderseite eines Autos reagieren.
In verschiedenen Zusammenhängen haben viele Studien bewiesen, dass die Aktivierung eines Neurons unterschiedliche Bedeutungen haben kann
Ein möglicher Grund ist, dass die polysemantische Natur von Neuronen auf den Superpositionseffekt zurückzuführen ist. Dies ist ein hypothetisches Phänomen, bei dem neuronale Netze unabhängige Merkmale von Daten darstellen, indem sie jedem Merkmal eine eigene lineare Kombination von Neuronen zuweisen und die Anzahl dieser Merkmale die Anzahl der Neuronen übersteigt Vektor auf dem Neuron, dann bildet der Merkmalssatz eine übervollständige lineare Basis für die Aktivierung der Netzwerkneuronen.
In Anthropics früherem Papier „Toy Models of Superposition“ („Superposition Toy Model“) wurde bewiesen, dass Sparsity Mehrdeutigkeiten beim Training neuronaler Netze beseitigen kann, was dem Modell hilft, die Beziehung zwischen Merkmalen besser zu verstehen und dadurch die Aktivierungsunsicherheit zu reduzieren Die Quelleigenschaften des Vektors machen die Vorhersagen und Entscheidungen des Modells zuverlässiger.
 Dieses Konzept ähnelt der Idee beim Compressed Sensing, wo die Spärlichkeit des Signals es ermöglicht, das vollständige Signal aus begrenzten Beobachtungen wiederherzustellen.
Dieses Konzept ähnelt der Idee beim Compressed Sensing, wo die Spärlichkeit des Signals es ermöglicht, das vollständige Signal aus begrenzten Beobachtungen wiederherzustellen.

Aber unter den drei in Toy Models of Superposition vorgeschlagenen Strategien:
(1) Erstellen von Modellen ohne Überlagerung, möglicherweise Förderung der Aktivierungsparsität;
(2) Anzeigen von Überlagerungen im Zustandsmodell, Wörterbuchlernen wird verwendet, um übervollständige Features zu finden
(3) basiert auf einer Hybridmethode, die beide kombiniert.
Was neu geschrieben werden muss, ist: Methode (1) kann das Mehrdeutigkeitsproblem nicht lösen, während Methode (2) anfällig für starke Überanpassung ist
Daher verwendeten Anthropic-Forscher dieses Mal einen schwachen Wörterbuch-Lernalgorithmus, der als Sparse bezeichnet wird Der Autoencoder generiert erlernte Merkmale aus einem trainierten Modell, die eine einzige semantische Analyseeinheit bereitstellen als die Modellneuronen selbst.
Konkret verwendeten die Forscher einen MLP-Einschichttransformator mit 512 Neuronen und zerlegten schließlich die MLP-Aktivierungen in relativ interpretierbare, indem sie einen spärlichen Autoencoder auf MLP-Aktivierungen aus 8 Milliarden Datenpunkten trainierten. Der Erweiterungsfaktor reicht von 1 × (512 Features) bis 256× (131.072 Features).
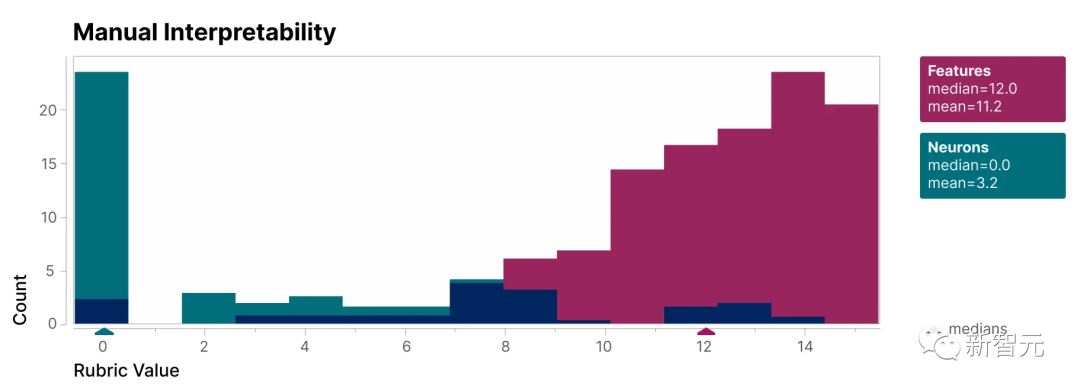
Um zu überprüfen, ob die in dieser Studie gefundenen Merkmale besser interpretierbar sind als die Neuronen des Modells, haben wir eine Blindbewertung durchgeführt und ihre Interpretierbarkeit von einem menschlichen Gutachter bewerten lassen.
Man erkennt, dass die Merkmale (rot) viel höher sind Punkte als Neuronen (Cyan).
Es wurde nachgewiesen, dass die von den Forschern entdeckten Merkmale im Vergleich zu den Neuronen im Modell leichter zu verstehen sind
Darüber hinaus haben die Forscher mithilfe von The Large auch eine Methode der „automatischen Interpretierbarkeit“ übernommen Das Sprachmodell generiert eine kurze Beschreibung der Funktionen des kleinen Modells und lässt ein anderes Modell diese Beschreibung basierend auf seiner Fähigkeit, die Funktionsaktivierung vorherzusagen, bewerten.
In ähnlicher Weise erzielen Merkmale eine höhere Punktzahl als Neuronen, was eine konsistente Interpretation der Aktivierung von Merkmalen und ihrer nachgelagerten Auswirkungen auf das Modellverhalten zeigt.
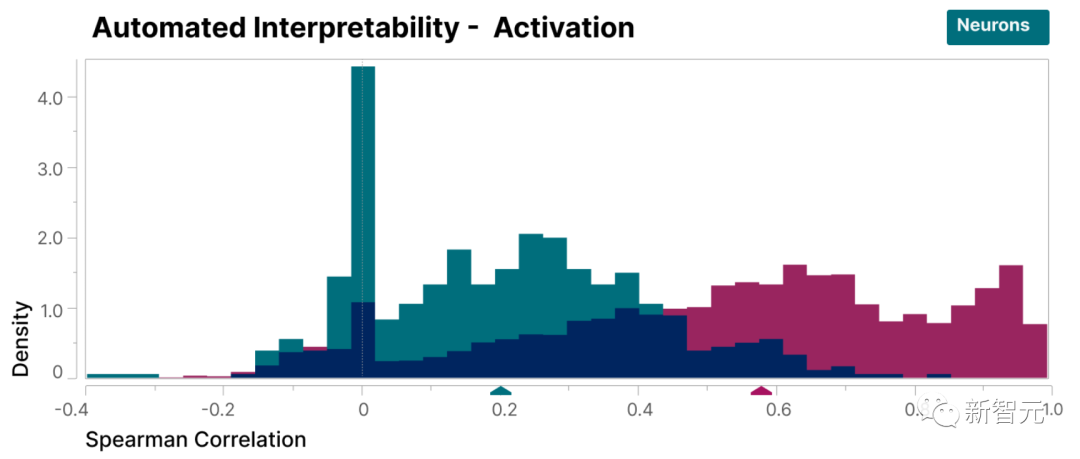
Darüber hinaus bieten diese extrahierten Features auch eine gezielte Methode zur Führung des Modells.
Wie in der Abbildung unten gezeigt, kann die künstliche Aktivierung von Funktionen dazu führen, dass sich das Modellverhalten auf vorhersehbare Weise ändert.
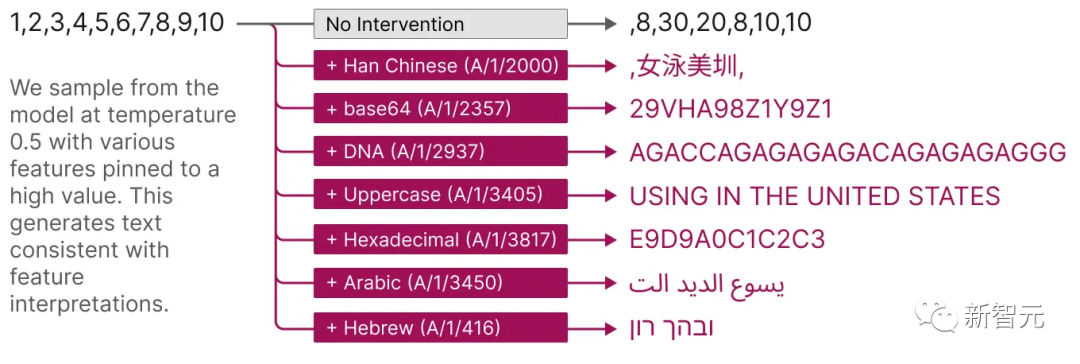
Das Folgende ist eine Visualisierung der extrahierten Interpretierbarkeitsmerkmale:
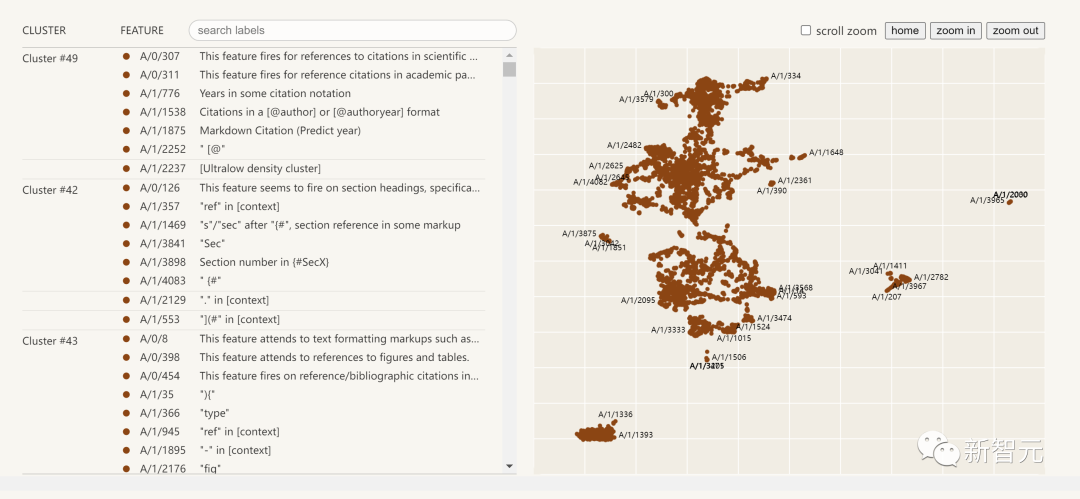
Klicken Sie auf die Funktionsliste auf der linken Seite und Sie können den Funktionsraum im neuronalen Netzwerk interaktiv erkunden.
Forschung Zusammenfassung des Berichts
Dieser Forschungsbericht von Anthropic, Towards Monosemantity: Decomposed Language Models With Dictionary Learning, kann in vier Teile unterteilt werden.
Bei der Problemstellung stellten die Forscher die Forschungsmotivation vor und erläuterten den trainierten Transformator und den Sparse-Autoencoder.
Detaillierte Untersuchung einzelner Merkmale, die beweist, dass mehrere in der Studie gefundene Merkmale funktionsspezifische kausale Einheiten sind.
Durch eine globale Analyse kamen wir zu dem Schluss, dass typische Merkmale interpretierbar sind und wichtige Komponenten der MLP-Schicht erklären können.
Phänomenanalyse, die mehrere Eigenschaften der Merkmale beschreibt, einschließlich Merkmalssegmentierung, Universalitätseigenschaften usw wie sie Systeme bilden, die „Automaten endlicher Zustände“ ähneln, um komplexe Verhaltensweisen zu erreichen.
Die Schlussfolgerungen umfassen die folgenden 7:
Der Sparse-Autoencoder hat die Fähigkeit, relativ einzelne semantische Merkmale zu extrahieren
Sparse-Autoencoder sind in der Lage, interpretierbare Merkmale zu erzeugen, die in der Basis von Neuronen tatsächlich unsichtbar sind.
3 Sparse-Autoencoder können verwendet werden, um einzugreifen und die Erzeugung von Transformatoren zu steuern.
4. Sparse-Autoencoder können relativ allgemeine Funktionen generieren.
Mit zunehmender Größe des Autoencoders neigen Funktionen dazu, sich zu „spalten“. Nach dem Umschreiben: Mit zunehmender Größe des Autoencoders zeigen Features einen Trend zur „Aufteilung“
6. Nur 512 Neuronen können Tausende von Features darstellen
7 Diese Features bilden durch die Verbindung ein System ähnlich einem „Finite-State-Automaton“ erreicht komplexe Verhaltensweisen, wie in der folgenden Abbildung dargestellt
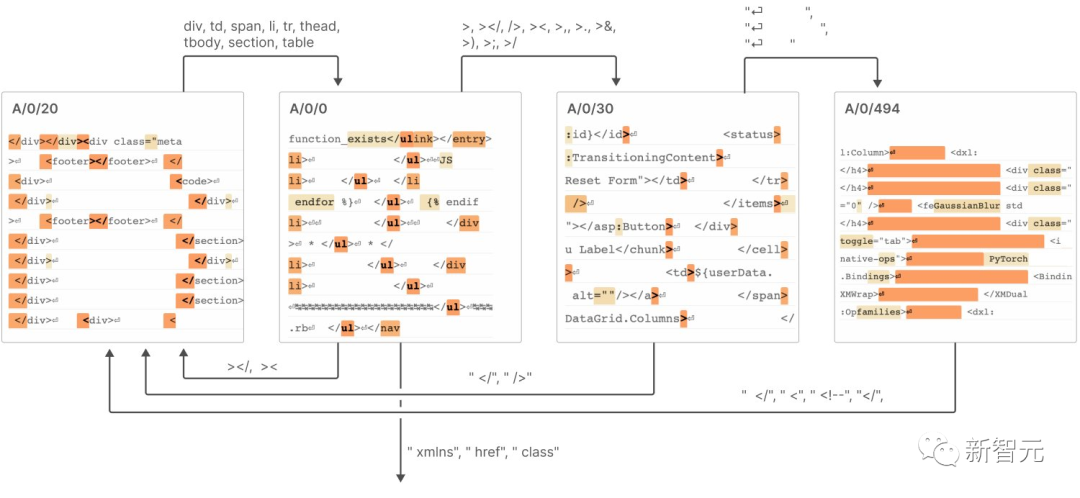
Weitere Einzelheiten finden Sie im Bericht.
Anthropic glaubt, dass die Herausforderung, vor der wir in Zukunft stehen, nicht länger ein wissenschaftliches, sondern ein technisches Problem sein wird, um den Erfolg des kleinen Modells in diesem Forschungsbericht auf ein größeres Modell zu übertragen.
Um dies zu erreichen Die Interpretierbarkeit eines großen Modells erfordert mehr Aufwand und Ressourcen im technischen Bereich, um die Herausforderungen zu meistern, die sich aus der Komplexität und dem Maßstab des Modells ergeben
Einschließlich der Entwicklung neuer Werkzeuge, Techniken und Methoden zur Bewältigung der Herausforderungen der Modellkomplexität und des Datenumfangs; Dazu gehört auch der Aufbau skalierbarer Interpretationsrahmen und Tools, um den Anforderungen großer Modelle gerecht zu werden.
Dies wird der neueste Trend im Bereich interpretativer künstlicher Intelligenz und groß angelegter Deep-Learning-Forschung sein
Das obige ist der detaillierte Inhalt vonBrechen Sie die Blackbox großer Modelle und zerlegen Sie Neuronen vollständig! OpenAI-Konkurrent Anthropic durchbricht die Barriere der KI-Unerklärbarkeit. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 Verwenden Sie ddrescue, um Daten unter Linux wiederherzustellen
Mar 20, 2024 pm 01:37 PM
Verwenden Sie ddrescue, um Daten unter Linux wiederherzustellen
Mar 20, 2024 pm 01:37 PM
DDREASE ist ein Tool zum Wiederherstellen von Daten von Datei- oder Blockgeräten wie Festplatten, SSDs, RAM-Disks, CDs, DVDs und USB-Speichergeräten. Es kopiert Daten von einem Blockgerät auf ein anderes, wobei beschädigte Blöcke zurückbleiben und nur gute Blöcke verschoben werden. ddreasue ist ein leistungsstarkes Wiederherstellungstool, das vollständig automatisiert ist, da es während der Wiederherstellungsvorgänge keine Unterbrechungen erfordert. Darüber hinaus kann es dank der ddasue-Map-Datei jederzeit gestoppt und fortgesetzt werden. Weitere wichtige Funktionen von DDREASE sind: Es überschreibt die wiederhergestellten Daten nicht, füllt aber die Lücken im Falle einer iterativen Wiederherstellung. Es kann jedoch gekürzt werden, wenn das Tool explizit dazu aufgefordert wird. Stellen Sie Daten aus mehreren Dateien oder Blöcken in einer einzigen wieder her
 Open Source! Jenseits von ZoeDepth! DepthFM: Schnelle und genaue monokulare Tiefenschätzung!
Apr 03, 2024 pm 12:04 PM
Open Source! Jenseits von ZoeDepth! DepthFM: Schnelle und genaue monokulare Tiefenschätzung!
Apr 03, 2024 pm 12:04 PM
0.Was bewirkt dieser Artikel? Wir schlagen DepthFM vor: ein vielseitiges und schnelles generatives monokulares Tiefenschätzungsmodell auf dem neuesten Stand der Technik. Zusätzlich zu herkömmlichen Tiefenschätzungsaufgaben demonstriert DepthFM auch hochmoderne Fähigkeiten bei nachgelagerten Aufgaben wie dem Tiefen-Inpainting. DepthFM ist effizient und kann Tiefenkarten innerhalb weniger Inferenzschritte synthetisieren. Lassen Sie uns diese Arbeit gemeinsam lesen ~ 1. Titel der Papierinformationen: DepthFM: FastMonocularDepthEstimationwithFlowMatching Autor: MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 So verwenden Sie die Excel-Filterfunktion mit mehreren Bedingungen
Feb 26, 2024 am 10:19 AM
So verwenden Sie die Excel-Filterfunktion mit mehreren Bedingungen
Feb 26, 2024 am 10:19 AM
Wenn Sie wissen müssen, wie Sie die Filterung mit mehreren Kriterien in Excel verwenden, führt Sie das folgende Tutorial durch die Schritte, um sicherzustellen, dass Sie Ihre Daten effektiv filtern und sortieren können. Die Filterfunktion von Excel ist sehr leistungsstark und kann Ihnen dabei helfen, aus großen Datenmengen die benötigten Informationen zu extrahieren. Diese Funktion kann Daten entsprechend den von Ihnen festgelegten Bedingungen filtern und nur die Teile anzeigen, die die Bedingungen erfüllen, wodurch die Datenverwaltung effizienter wird. Mithilfe der Filterfunktion können Sie Zieldaten schnell finden und so Zeit beim Suchen und Organisieren von Daten sparen. Diese Funktion kann nicht nur auf einfache Datenlisten angewendet werden, sondern auch nach mehreren Bedingungen gefiltert werden, um Ihnen dabei zu helfen, die benötigten Informationen genauer zu finden. Insgesamt ist die Filterfunktion von Excel sehr praktisch
 Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Die von Google geförderte Leistung von JAX hat in jüngsten Benchmark-Tests die von Pytorch und TensorFlow übertroffen und belegt bei 7 Indikatoren den ersten Platz. Und der Test wurde nicht auf der TPU mit der besten JAX-Leistung durchgeführt. Obwohl unter Entwicklern Pytorch immer noch beliebter ist als Tensorflow. Aber in Zukunft werden möglicherweise mehr große Modelle auf Basis der JAX-Plattform trainiert und ausgeführt. Modelle Kürzlich hat das Keras-Team drei Backends (TensorFlow, JAX, PyTorch) mit der nativen PyTorch-Implementierung und Keras2 mit TensorFlow verglichen. Zunächst wählen sie eine Reihe von Mainstream-Inhalten aus
 Die Vitalität der Superintelligenz erwacht! Aber mit der Einführung der sich selbst aktualisierenden KI müssen sich Mütter keine Sorgen mehr über Datenengpässe machen
Apr 29, 2024 pm 06:55 PM
Die Vitalität der Superintelligenz erwacht! Aber mit der Einführung der sich selbst aktualisierenden KI müssen sich Mütter keine Sorgen mehr über Datenengpässe machen
Apr 29, 2024 pm 06:55 PM
Ich weine zu Tode. Die Daten im Internet reichen überhaupt nicht aus. Das Trainingsmodell sieht aus wie „Die Tribute von Panem“, und KI-Forscher auf der ganzen Welt machen sich Gedanken darüber, wie sie diese datenhungrigen Esser ernähren sollen. Dieses Problem tritt insbesondere bei multimodalen Aufgaben auf. Zu einer Zeit, als sie ratlos waren, nutzte ein Start-up-Team der Abteilung der Renmin-Universität von China sein eigenes neues Modell, um als erstes in China einen „modellgenerierten Datenfeed selbst“ in die Realität umzusetzen. Darüber hinaus handelt es sich um einen zweigleisigen Ansatz auf der Verständnisseite und der Generierungsseite. Beide Seiten können hochwertige, multimodale neue Daten generieren und Datenrückmeldungen an das Modell selbst liefern. Was ist ein Modell? Awaker 1.0, ein großes multimodales Modell, das gerade im Zhongguancun-Forum erschienen ist. Wer ist das Team? Sophon-Motor. Gegründet von Gao Yizhao, einem Doktoranden an der Hillhouse School of Artificial Intelligence der Renmin University.
 Langsame Internetgeschwindigkeiten für Mobilfunkdaten auf dem iPhone: Korrekturen
May 03, 2024 pm 09:01 PM
Langsame Internetgeschwindigkeiten für Mobilfunkdaten auf dem iPhone: Korrekturen
May 03, 2024 pm 09:01 PM
Stehen Sie vor einer Verzögerung oder einer langsamen mobilen Datenverbindung auf dem iPhone? Normalerweise hängt die Stärke des Mobilfunk-Internets auf Ihrem Telefon von mehreren Faktoren ab, wie z. B. der Region, dem Mobilfunknetztyp, dem Roaming-Typ usw. Es gibt einige Dinge, die Sie tun können, um eine schnellere und zuverlässigere Mobilfunk-Internetverbindung zu erhalten. Fix 1 – Neustart des iPhone erzwingen Manchmal werden durch einen erzwungenen Neustart Ihres Geräts viele Dinge zurückgesetzt, einschließlich der Mobilfunkverbindung. Schritt 1 – Drücken Sie einfach einmal die Lauter-Taste und lassen Sie sie los. Drücken Sie anschließend die Leiser-Taste und lassen Sie sie wieder los. Schritt 2 – Der nächste Teil des Prozesses besteht darin, die Taste auf der rechten Seite gedrückt zu halten. Lassen Sie das iPhone den Neustart abschließen. Aktivieren Sie Mobilfunkdaten und überprüfen Sie die Netzwerkgeschwindigkeit. Überprüfen Sie es erneut. Fix 2 – Datenmodus ändern 5G bietet zwar bessere Netzwerkgeschwindigkeiten, funktioniert jedoch besser, wenn das Signal schwächer ist
 Die U.S. Air Force präsentiert ihren ersten KI-Kampfjet mit großem Aufsehen! Der Minister führte die Testfahrt persönlich durch, ohne in den gesamten Prozess einzugreifen, und 100.000 Codezeilen wurden 21 Mal getestet.
May 07, 2024 pm 05:00 PM
Die U.S. Air Force präsentiert ihren ersten KI-Kampfjet mit großem Aufsehen! Der Minister führte die Testfahrt persönlich durch, ohne in den gesamten Prozess einzugreifen, und 100.000 Codezeilen wurden 21 Mal getestet.
May 07, 2024 pm 05:00 PM
Kürzlich wurde die Militärwelt von der Nachricht überwältigt: US-Militärkampfflugzeuge können jetzt mithilfe von KI vollautomatische Luftkämpfe absolvieren. Ja, erst kürzlich wurde der KI-Kampfjet des US-Militärs zum ersten Mal der Öffentlichkeit zugänglich gemacht und sein Geheimnis gelüftet. Der vollständige Name dieses Jägers lautet „Variable Stability Simulator Test Aircraft“ (VISTA). Er wurde vom Minister der US-Luftwaffe persönlich geflogen, um einen Eins-gegen-eins-Luftkampf zu simulieren. Am 2. Mai startete US-Luftwaffenminister Frank Kendall mit einer X-62AVISTA auf der Edwards Air Force Base. Beachten Sie, dass während des einstündigen Fluges alle Flugaktionen autonom von der KI durchgeführt wurden! Kendall sagte: „In den letzten Jahrzehnten haben wir über das unbegrenzte Potenzial des autonomen Luft-Luft-Kampfes nachgedacht, aber es schien immer unerreichbar.“ Nun jedoch,
 Der erste Roboter erscheint, der menschliche Aufgaben autonom erledigt, mit fünf flexiblen Fingern und übermenschlicher Geschwindigkeit, und große Modelle unterstützen das Training im virtuellen Raum
Mar 11, 2024 pm 12:10 PM
Der erste Roboter erscheint, der menschliche Aufgaben autonom erledigt, mit fünf flexiblen Fingern und übermenschlicher Geschwindigkeit, und große Modelle unterstützen das Training im virtuellen Raum
Mar 11, 2024 pm 12:10 PM
Diese Woche gab FigureAI, ein Robotikunternehmen, an dem OpenAI, Microsoft, Bezos und Nvidia beteiligt sind, bekannt, dass es fast 700 Millionen US-Dollar an Finanzmitteln erhalten hat und plant, im nächsten Jahr einen humanoiden Roboter zu entwickeln, der selbstständig gehen kann. Und Teslas Optimus Prime hat immer wieder gute Nachrichten erhalten. Niemand zweifelt daran, dass dieses Jahr das Jahr sein wird, in dem humanoide Roboter explodieren. SanctuaryAI, ein in Kanada ansässiges Robotikunternehmen, hat kürzlich einen neuen humanoiden Roboter auf den Markt gebracht: Phoenix. Beamte behaupten, dass es viele Aufgaben autonom und mit der gleichen Geschwindigkeit wie Menschen erledigen kann. Pheonix, der weltweit erste Roboter, der Aufgaben autonom in menschlicher Geschwindigkeit erledigen kann, kann jedes Objekt sanft greifen, bewegen und elegant auf der linken und rechten Seite platzieren. Es kann Objekte autonom identifizieren
