
 Technologie-Peripheriegeräte
KI
Das Weltmodell glänzt! Der Realismus dieser über 20 autonomen Fahrszenariodaten ist unglaublich ...
Technologie-Peripheriegeräte
KI
Das Weltmodell glänzt! Der Realismus dieser über 20 autonomen Fahrszenariodaten ist unglaublich ...
Das Weltmodell glänzt! Der Realismus dieser über 20 autonomen Fahrszenariodaten ist unglaublich ...

Denken Sie, dass das ein langweiliges Selbstfahrvideo ist?

Die ursprüngliche Bedeutung dieses Inhalts muss nicht geändert werden, er muss ins Chinesische umgeschrieben werden
Kein einziger Frame ist „echt“.

Unterschiedliche Straßenbedingungen, unterschiedliche Wetterbedingungen, mehr als 20 Situationen können simuliert werden, und der Effekt ist genau wie im Original.

Das Weltmodell stellt einmal mehr seine mächtige Rolle unter Beweis! Dieses Mal leitete LeCun es aufgeregt weiter, nachdem er es gesehen hatte

Der obige Effekt wird durch die neueste Version von GAIA-1 erzielt.
Es verfügt über eine Skala von 9 Milliarden Parametern und ist mit 4700 StundenFahrvideos trainiert, um durch die Eingabe von Videos, Text oder Vorgängen den Effekt zu erzielen, selbstfahrende Videos zu generieren.
Der unmittelbarste Vorteil ist die Möglichkeit, zukünftige Ereignisse besser vorherzusagen. Es kann mehr als 20 Szenarien simulieren und dadurch die Sicherheit des autonomen Fahrens weiter verbessern und die Kosten senken

Das Kreativteam sagte, dass dies die Spielregeln für autonomes Fahren ändern wird!
Wie wird GAIA-1 umgesetzt? Tatsächlich haben wir den vom Wayve-Team entwickelten GAIA-1 bereits in Autonomous Driving Daily ausführlich vorgestellt: ein generatives Weltmodell für autonomes Fahren. Wenn Sie daran interessiert sind, können Sie auf unserem offiziellen Konto relevante Inhalte lesen!
Je größer der Maßstab, desto besser die Wirkung
GAIA-1 ist ein multimodales generatives Weltmodell, das durch die Integration mehrerer Wahrnehmungsmethoden wie Sehen, Hören und Sprache Ausdrücke der Welt verstehen und erzeugen kann. Dieses Modell verwendet Deep-Learning-Algorithmen, um aus einer großen Datenmenge die Struktur und Gesetze der Welt zu erlernen und zu begründen. Ziel von GAIA-1 ist es, die menschliche Wahrnehmung und kognitiven Fähigkeiten zu simulieren, um die Welt besser zu verstehen und mit ihr zu interagieren. Es hat breite Anwendungsmöglichkeiten in vielen Bereichen, darunter autonomes Fahren, Robotik und virtuelle Realität. Durch kontinuierliches Training und Optimierung wird sich GAIA-1 weiterentwickeln und verbessern und zu einem intelligenteren und umfassenderen Weltmodell werden Die Eigenschaften werden genau gesteuert
und Videos können
mit nur Textaufforderungen generiertwerden.
 Das Prinzip seines Modells ähnelt dem großer Sprachmodelle, d Vorhersage des nächsten im Sequenz-Token. Das Diffusionsmodell wird dann verwendet, um hochwertige Videos aus dem Sprachraum des Weltmodells zu generieren.
Das Prinzip seines Modells ähnelt dem großer Sprachmodelle, d Vorhersage des nächsten im Sequenz-Token. Das Diffusionsmodell wird dann verwendet, um hochwertige Videos aus dem Sprachraum des Weltmodells zu generieren.
Die spezifischen Schritte sind wie folgt:
Der erste Schritt ist einfach zu verstehen, nämlich das Neukodieren, Anordnen und Kombinieren verschiedener Eingaben.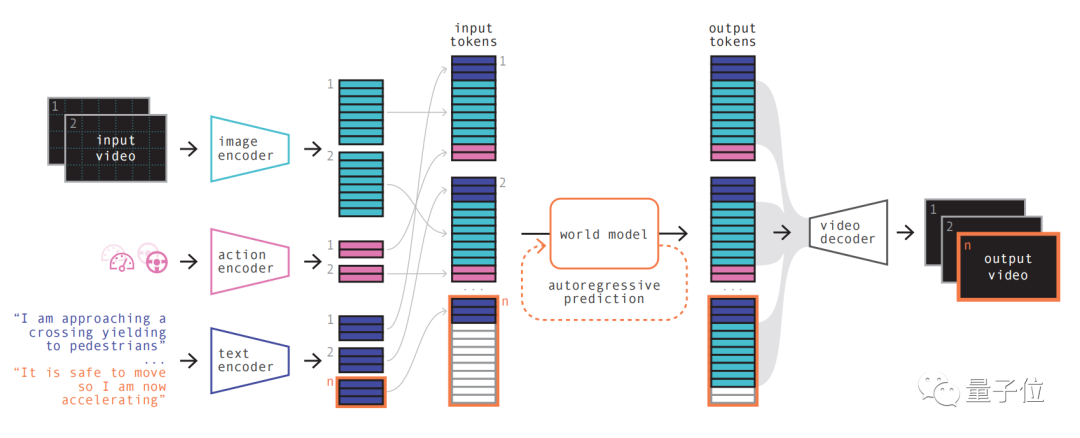 Verschiedene Eingaben können in eine gemeinsame Darstellung projiziert werden, indem spezielle Encoder zum Codieren verschiedener Eingaben verwendet werden. Text- und Video-Encoder trennen und betten die Eingabe ein, während die operativen Darstellungen einzeln in eine gemeinsame Darstellung projiziert werden. Diese codierten Darstellungen sind zeitlich konsistent. Nach Permutationen kommt der Schlüsselteil, das Weltmodell, auf die Bühne.
Verschiedene Eingaben können in eine gemeinsame Darstellung projiziert werden, indem spezielle Encoder zum Codieren verschiedener Eingaben verwendet werden. Text- und Video-Encoder trennen und betten die Eingabe ein, während die operativen Darstellungen einzeln in eine gemeinsame Darstellung projiziert werden. Diese codierten Darstellungen sind zeitlich konsistent. Nach Permutationen kommt der Schlüsselteil, das Weltmodell, auf die Bühne.
Als autoregressiver Transformer hat er die Fähigkeit, den nächsten Satz von Bild-Tokens in der Sequenz vorherzusagen. Es berücksichtigt nicht nur frühere Bild-Token, sondern berücksichtigt gleichzeitig auch Kontextinformationen von Text und Aktionen. Der vom Modell generierte Inhalt behält nicht nur die Konsistenz mit dem Bild bei, sondern auch mit den vorhergesagten Texten und Aktionen. Teameinführung, GAIA Die Größe des Weltmodells in -1 beträgt
6,5 Milliarden Parameter, die 15 Tage lang auf 64 A100 trainiert wurden.
Durch die Verwendung eines Videodecoders und eines Videodiffusionsmodells werden diese Token schließlich wieder in Video umgewandelt.
In diesem Schritt geht es um die semantische Qualität, Bildgenauigkeit und zeitliche Konsistenz des Videos. Der Videodecoder von GAIA-1 hat eine Skala von 2,6 Milliarden Parametern und wurde 15 Tage lang mit 32 A100 trainiert. Es ist erwähnenswert, dass GAIA-1 nicht nur im Prinzip dem großen Sprachmodell ähnelt, sondern auch die Merkmale aufweist: Mit zunehmender Modellskala verbessert sich die Generierungsqualität. Das Team verglich die zuvor im Juni veröffentlichte frühe Version mit dem neuesten Effekt Letzterer ist 480-mal größer als ersterer. Sie können intuitiv erkennen, dass die Videodetails und die Auflösung deutlich verbessert wurden. In Bezug auf praktische Anwendungen hat GAIA-1 auch Auswirkungen gehabt. Sein Kreativteam sagte, dass dies die Regeln des autonomen Fahrens ändern wird. Die Gründe liegen in drei Aspekten: Zuallererst kann das Weltmodell in Bezug auf die Sicherheit die Zukunft simulieren und der KI das geben Die Fähigkeit, eigene Entscheidungen umzusetzen, ist für die Sicherheit des autonomen Fahrens von entscheidender Bedeutung. Zweitens sind Trainingsdaten auch für das autonome Fahren sehr wichtig. Die generierten Daten sind sicherer, günstiger und unbegrenzt skalierbar. Generative KI kann eine große Herausforderung des autonomen Fahrens lösen – Long-Tail-Szenarien. Es kann mehr Grenzfälle bewältigen, beispielsweise die Begegnung mit Fußgängern, die bei nebligem Wetter die Straße überqueren. Dies wird die Leistung des autonomen Fahrens weiter verbessern GAIA-1 stammt vom britischen Startup für autonomes Fahren Wayve. Wayve wurde 2017 gegründet. Zu den Investoren zählen Microsoftusw. und seine Bewertung hat Unicorn erreicht. Die Gründer sind die derzeitigen CEOs Alex Kendall und Amar Shah (die Führungsseite der offiziellen Website des Unternehmens enthält keine Informationen mehr). Beide haben ihren Abschluss an der Universität Cambridge und einen Doktortitel in maschinellem Lernen. Auf der technischen Roadmap Wie Tesla befürwortet Wayve eine rein visuelle Lösung mit Kameras, verzichtet schon sehr früh auf hochpräzise Karten und folgt konsequent dem Weg der „sofortigen Wahrnehmung“. Vor nicht allzu langer Zeit sorgte auch ein weiteres vom Team herausgebrachtes großes Modell LINGO-1 für Aufsehen. Dieses selbstfahrende Modell kann während der Fahrt Erklärungen in Echtzeit generieren und dadurch die Interpretierbarkeit des Modells weiter verbessern. Im März dieses Jahres hat Bill Gates auch ein selbstfahrendes Auto von Wayve ausprobiert. Papieradresse: https://arxiv.org/abs/2309.17080 Der Inhalt, der neu geschrieben werden muss, ist: Originallink: https://mp.weixin.qq. com/ s/bwTDovx9-UArk5lx5pZPag


Wer ist Wayve?



Das obige ist der detaillierte Inhalt vonDas Weltmodell glänzt! Der Realismus dieser über 20 autonomen Fahrszenariodaten ist unglaublich .... Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1382
1382
 52
52

 Wie lässt sich das Long-Tail-Problem in autonomen Fahrszenarien lösen?
Jun 02, 2024 pm 02:44 PM
Wie lässt sich das Long-Tail-Problem in autonomen Fahrszenarien lösen?
Jun 02, 2024 pm 02:44 PM
Gestern wurde ich während des Interviews gefragt, ob ich irgendwelche Long-Tail-Fragen gestellt hätte, also dachte ich, ich würde eine kurze Zusammenfassung geben. Das Long-Tail-Problem des autonomen Fahrens bezieht sich auf Randfälle bei autonomen Fahrzeugen, also mögliche Szenarien mit geringer Eintrittswahrscheinlichkeit. Das wahrgenommene Long-Tail-Problem ist einer der Hauptgründe, die derzeit den betrieblichen Designbereich intelligenter autonomer Einzelfahrzeugfahrzeuge einschränken. Die zugrunde liegende Architektur und die meisten technischen Probleme des autonomen Fahrens wurden gelöst, und die verbleibenden 5 % der Long-Tail-Probleme wurden nach und nach zum Schlüssel zur Einschränkung der Entwicklung des autonomen Fahrens. Zu diesen Problemen gehören eine Vielzahl fragmentierter Szenarien, Extremsituationen und unvorhersehbares menschliches Verhalten. Der „Long Tail“ von Randszenarien beim autonomen Fahren bezieht sich auf Randfälle in autonomen Fahrzeugen (AVs). Randfälle sind mögliche Szenarien mit geringer Eintrittswahrscheinlichkeit. diese seltenen Ereignisse
 Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Stellen Sie sich ein Modell der künstlichen Intelligenz vor, das nicht nur die Fähigkeit besitzt, die traditionelle Datenverarbeitung zu übertreffen, sondern auch eine effizientere Leistung zu geringeren Kosten erzielt. Dies ist keine Science-Fiction, DeepSeek-V2[1], das weltweit leistungsstärkste Open-Source-MoE-Modell, ist da. DeepSeek-V2 ist ein leistungsstarkes MoE-Sprachmodell (Mix of Experts) mit den Merkmalen eines wirtschaftlichen Trainings und einer effizienten Inferenz. Es besteht aus 236B Parametern, von denen 21B zur Aktivierung jedes Markers verwendet werden. Im Vergleich zu DeepSeek67B bietet DeepSeek-V2 eine stärkere Leistung, spart gleichzeitig 42,5 % der Trainingskosten, reduziert den KV-Cache um 93,3 % und erhöht den maximalen Generierungsdurchsatz auf das 5,76-fache. DeepSeek ist ein Unternehmen, das sich mit allgemeiner künstlicher Intelligenz beschäftigt
 KI untergräbt die mathematische Forschung! Der Gewinner der Fields-Medaille und der chinesisch-amerikanische Mathematiker führten 11 hochrangige Arbeiten an | Gefällt mir bei Terence Tao
Apr 09, 2024 am 11:52 AM
KI untergräbt die mathematische Forschung! Der Gewinner der Fields-Medaille und der chinesisch-amerikanische Mathematiker führten 11 hochrangige Arbeiten an | Gefällt mir bei Terence Tao
Apr 09, 2024 am 11:52 AM
KI verändert tatsächlich die Mathematik. Vor kurzem hat Tao Zhexuan, der diesem Thema große Aufmerksamkeit gewidmet hat, die neueste Ausgabe des „Bulletin of the American Mathematical Society“ (Bulletin der American Mathematical Society) weitergeleitet. Zum Thema „Werden Maschinen die Mathematik verändern?“ äußerten viele Mathematiker ihre Meinung. Der gesamte Prozess war voller Funken, knallhart und aufregend. Der Autor verfügt über eine starke Besetzung, darunter der Fields-Medaillengewinner Akshay Venkatesh, der chinesische Mathematiker Zheng Lejun, der NYU-Informatiker Ernest Davis und viele andere bekannte Wissenschaftler der Branche. Die Welt der KI hat sich dramatisch verändert. Viele dieser Artikel wurden vor einem Jahr eingereicht.
 Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Die von Google geförderte Leistung von JAX hat in jüngsten Benchmark-Tests die von Pytorch und TensorFlow übertroffen und belegt bei 7 Indikatoren den ersten Platz. Und der Test wurde nicht auf der TPU mit der besten JAX-Leistung durchgeführt. Obwohl unter Entwicklern Pytorch immer noch beliebter ist als Tensorflow. Aber in Zukunft werden möglicherweise mehr große Modelle auf Basis der JAX-Plattform trainiert und ausgeführt. Modelle Kürzlich hat das Keras-Team drei Backends (TensorFlow, JAX, PyTorch) mit der nativen PyTorch-Implementierung und Keras2 mit TensorFlow verglichen. Zunächst wählen sie eine Reihe von Mainstream-Inhalten aus
 Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas tritt offiziell in die Ära der Elektroroboter ein! Gestern hat sich der hydraulische Atlas einfach „unter Tränen“ von der Bühne der Geschichte zurückgezogen. Heute gab Boston Dynamics bekannt, dass der elektrische Atlas im Einsatz ist. Es scheint, dass Boston Dynamics im Bereich kommerzieller humanoider Roboter entschlossen ist, mit Tesla zu konkurrieren. Nach der Veröffentlichung des neuen Videos wurde es innerhalb von nur zehn Stunden bereits von mehr als einer Million Menschen angesehen. Die alten Leute gehen und neue Rollen entstehen. Das ist eine historische Notwendigkeit. Es besteht kein Zweifel, dass dieses Jahr das explosive Jahr der humanoiden Roboter ist. Netizens kommentierten: Die Weiterentwicklung der Roboter hat dazu geführt, dass die diesjährige Eröffnungsfeier wie Menschen aussieht, und der Freiheitsgrad ist weitaus größer als der von Menschen. Aber ist das wirklich kein Horrorfilm? Zu Beginn des Videos liegt Atlas ruhig auf dem Boden, scheinbar auf dem Rücken. Was folgt, ist atemberaubend
 KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
Anfang dieses Monats schlugen Forscher des MIT und anderer Institutionen eine vielversprechende Alternative zu MLP vor – KAN. KAN übertrifft MLP in Bezug auf Genauigkeit und Interpretierbarkeit. Und es kann MLP, das mit einer größeren Anzahl von Parametern ausgeführt wird, mit einer sehr kleinen Anzahl von Parametern übertreffen. Beispielsweise gaben die Autoren an, dass sie KAN nutzten, um die Ergebnisse von DeepMind mit einem kleineren Netzwerk und einem höheren Automatisierungsgrad zu reproduzieren. Konkret verfügt DeepMinds MLP über etwa 300.000 Parameter, während KAN nur etwa 200 Parameter hat. KAN hat eine starke mathematische Grundlage wie MLP und basiert auf dem universellen Approximationssatz, während KAN auf dem Kolmogorov-Arnold-Darstellungssatz basiert. Wie in der folgenden Abbildung gezeigt, hat KAN
 Sprechen wir über End-to-End- und autonome Fahrsysteme der nächsten Generation sowie über einige Missverständnisse über End-to-End-Autonomes Fahren?
Apr 15, 2024 pm 04:13 PM
Sprechen wir über End-to-End- und autonome Fahrsysteme der nächsten Generation sowie über einige Missverständnisse über End-to-End-Autonomes Fahren?
Apr 15, 2024 pm 04:13 PM
Im vergangenen Monat hatte ich aus bekannten Gründen einen sehr intensiven Austausch mit verschiedenen Lehrern und Mitschülern der Branche. Ein unvermeidliches Thema im Austausch ist natürlich End-to-End und der beliebte Tesla FSDV12. Ich möchte diese Gelegenheit nutzen, einige meiner aktuellen Gedanken und Meinungen als Referenz und Diskussion darzulegen. Wie definiert man ein durchgängiges autonomes Fahrsystem und welche Probleme sollten voraussichtlich durchgängig gelöst werden? Gemäß der traditionellsten Definition bezieht sich ein End-to-End-System auf ein System, das Rohinformationen von Sensoren eingibt und für die Aufgabe relevante Variablen direkt ausgibt. Bei der Bilderkennung kann CNN beispielsweise als End-to-End bezeichnet werden, verglichen mit der herkömmlichen Methode zum Extrahieren von Merkmalen + Klassifizieren. Bei autonomen Fahraufgaben werden Eingabedaten verschiedener Sensoren (Kamera/LiDAR) benötigt
 nuScenes' neuestes SOTA |. SparseAD: Sparse-Abfrage hilft effizientes durchgängiges autonomes Fahren!
Apr 17, 2024 pm 06:22 PM
nuScenes' neuestes SOTA |. SparseAD: Sparse-Abfrage hilft effizientes durchgängiges autonomes Fahren!
Apr 17, 2024 pm 06:22 PM
Vorab geschrieben und Ausgangspunkt Das End-to-End-Paradigma verwendet ein einheitliches Framework, um Multitasking in autonomen Fahrsystemen zu erreichen. Trotz der Einfachheit und Klarheit dieses Paradigmas bleibt die Leistung von End-to-End-Methoden für das autonome Fahren bei Teilaufgaben immer noch weit hinter Methoden für einzelne Aufgaben zurück. Gleichzeitig erschweren die in früheren End-to-End-Methoden weit verbreiteten Funktionen der dichten Vogelperspektive (BEV) die Skalierung auf mehr Modalitäten oder Aufgaben. Hier wird ein Sparse-Search-zentriertes End-to-End-Paradigma für autonomes Fahren (SparseAD) vorgeschlagen, bei dem die Sparse-Suche das gesamte Fahrszenario, einschließlich Raum, Zeit und Aufgaben, ohne dichte BEV-Darstellung vollständig abbildet. Insbesondere ist eine einheitliche, spärliche Architektur für die Aufgabenerkennung einschließlich Erkennung, Verfolgung und Online-Zuordnung konzipiert. Zudem schwer
