
 Technologie-Peripheriegeräte
KI
Vielseitiger und effektiver: Ants selbst entwickelter Optimierer WSAM wurde für KDD Oral ausgewählt
Technologie-Peripheriegeräte
KI
Vielseitiger und effektiver: Ants selbst entwickelter Optimierer WSAM wurde für KDD Oral ausgewählt
Vielseitiger und effektiver: Ants selbst entwickelter Optimierer WSAM wurde für KDD Oral ausgewählt

Die Generalisierungsfähigkeit tiefer neuronaler Netze (DNNs) hängt eng mit der Flachheit der Extrempunkte zusammen. Daher wurde der Sharpness-Aware Minimization (SAM)-Algorithmus entwickelt, um flachere Extrempunkte zu finden und so die Generalisierungsfähigkeit zu verbessern. In diesem Artikel wird die Verlustfunktion von SAM erneut untersucht und eine allgemeinere und effektivere Methode, WSAM, vorgeschlagen, um die Ebenheit von Trainingsextrempunkten zu verbessern, indem Ebenheit als Regularisierungsbegriff verwendet wird. Experimente mit verschiedenen öffentlichen Datensätzen zeigen, dass WSAM im Vergleich zum ursprünglichen Optimierer SAM und seinen Varianten in den allermeisten Fällen eine bessere Generalisierungsleistung erzielt. WSAM wurde auch in den internen digitalen Zahlungs-, digitalen Finanz- und anderen Szenarien von Ant weit verbreitet und hat bemerkenswerte Ergebnisse erzielt. Diese Arbeit wurde von KDD '23 als mündliche Arbeit angenommen. ?? telligent - machine-learning/dlrover/tree/master/atorch/atorch/optimizers
Mit der Entwicklung der Deep-Learning-Technologie haben stark überparametrisierte DNNs großartige Ergebnisse in verschiedenen maschinellen Lernszenarien wie CV und NLP erzielt. Erfolg. Obwohl überparametrisierte Modelle dazu neigen, die Trainingsdaten zu stark anzupassen, verfügen sie in der Regel über gute Generalisierungsfähigkeiten. Das Geheimnis der Verallgemeinerung hat immer mehr Aufmerksamkeit erregt und ist zu einem beliebten Forschungsthema im Bereich Deep Learning geworden. 
Die neuesten Forschungsergebnisse zeigen, dass die Generalisierungsfähigkeit eng mit der Ebenheit der Extrempunkte zusammenhängt. Mit anderen Worten: Das Vorhandensein flacher Extrempunkte in der „Landschaft“ der Verlustfunktion ermöglicht kleinere Generalisierungsfehler. Sharpness-Aware Minimization (SAM) [1] ist eine Technik zum Finden flacherer Extrempunkte und gilt derzeit als eine der vielversprechendsten technischen Richtungen. Die SAM-Technologie ist in vielen Bereichen wie Computer Vision, Verarbeitung natürlicher Sprache und zweischichtigem Lernen weit verbreitet und übertrifft bisherige hochmoderne Methoden in diesen Bereichen deutlich definiert eine Verlustfunktion. Die Ebenheit von
- bei w ist wie folgt:
- GSAM [2] hat bewiesen, dass eine Näherung des maximalen Eigenwerts der Hesse-Matrix am lokalen Extrempunkt ist, was darauf hinweist das ist in der Tat eine flache (steile) effektive Messung. Allerdings kann nur verwendet werden, um flachere Bereiche statt minimaler Punkte zu finden, was dazu führen kann, dass die Verlustfunktion zu einem Punkt konvergiert, an dem der Verlustwert immer noch groß ist (obwohl der umgebende Bereich flach ist). Daher verwendet SAM
, also
als Verlustfunktion. Es kann als Kompromiss zwischen der Suche nach einer flacheren Oberfläche und einem kleineren Verlustwert zwischen und
angesehen werden, wobei beiden das gleiche Gewicht beigemessen wird.
Dieser Artikel überdenkt die Konstruktion von 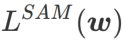 und behandelt
und behandelt 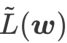 als Regularisierungsbegriff. Wir haben einen allgemeineren und effektiveren Algorithmus namens WSAM (Weighted Sharpness-Aware Minimization) entwickelt. Seine Verlustfunktion fügt einen gewichteten Ebenheitsterm
als Regularisierungsbegriff. Wir haben einen allgemeineren und effektiveren Algorithmus namens WSAM (Weighted Sharpness-Aware Minimization) entwickelt. Seine Verlustfunktion fügt einen gewichteten Ebenheitsterm 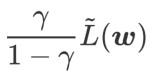 als Regularisierungsterm hinzu, bei dem der Hyperparameter
als Regularisierungsterm hinzu, bei dem der Hyperparameter 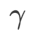 die Ebenheitsgewichtung steuert. Im Kapitel zur Methodeneinführung haben wir gezeigt, wie man
die Ebenheitsgewichtung steuert. Im Kapitel zur Methodeneinführung haben wir gezeigt, wie man 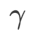 verwendet, um die Verlustfunktion zu steuern, um flachere oder kleinere Extrempunkte zu finden. Unsere wichtigsten Beiträge lassen sich wie folgt zusammenfassen.
verwendet, um die Verlustfunktion zu steuern, um flachere oder kleinere Extrempunkte zu finden. Unsere wichtigsten Beiträge lassen sich wie folgt zusammenfassen.
- Wir schlagen WSAM vor, das Flachheit als Regularisierungsbegriff behandelt und unterschiedliche Gewichtungen zwischen verschiedenen Aufgaben angibt. Wir schlagen eine Technik der „Gewichtungsentkopplung“ vor, um den Regularisierungsterm in der Aktualisierungsformel zu handhaben, mit dem Ziel, die Flachheit des aktuellen Schritts genau wiederzugeben. Wenn der zugrunde liegende Optimierer nicht SGD ist, wie z. B. SGDM und Adam, unterscheidet sich WSAM in seiner Form erheblich von SAM. Ablationsexperimente zeigen, dass diese Technik in den meisten Fällen die Leistung verbessert.
- Wir haben die Wirksamkeit von WSAM bei allgemeinen Aufgaben in öffentlichen Datensätzen überprüft. Experimentelle Ergebnisse zeigen, dass WSAM im Vergleich zu SAM und seinen Varianten in den meisten Situationen eine bessere Generalisierungsleistung aufweist.
Vorkenntnisse
SAM ist eine Technik zur Lösung des Minimax-Optimierungsproblems von 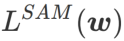 , definiert durch Formel (1).
, definiert durch Formel (1).
Erstens verwendet SAM eine Taylor-Erweiterung erster Ordnung um w, um das Maximierungsproblem der inneren Schicht zu approximieren, d. Das heißt,
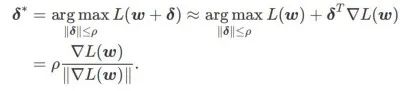
Die zweite Näherung besteht darin, die Berechnung zu beschleunigen. Andere Gradienten-basierte Optimierer (sogenannte Basisoptimierer) können in das allgemeine Framework von SAM integriert werden, Einzelheiten finden Sie unter Algorithmus 1. Durch Ändern von 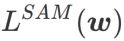
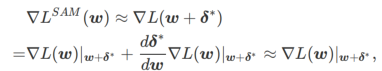

Designdetails von WSAM 
Hier geben wir die formale Definition von
, die aus einem regulären Verlust- und einem Flachheitsterm besteht. Aus Formel (1) ergibt sich
Unter ihnen Ein allgemeines Framework für WSAM, das verschiedene Basisoptimierer enthält, kann durch Auswahl verschiedener Abb. 1 zeigt den WSAM-Update-Prozess unter verschiedenen 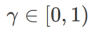 . Wenn
. Wenn 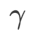 =0,
=0, 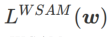 zu einem regulären Verlust degeneriert; wenn
zu einem regulären Verlust degeneriert; wenn 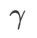 =1/2, ist
=1/2, ist 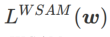 äquivalent zu
äquivalent zu 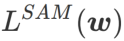 ; wenn
; wenn 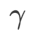 >1/2, achtet
>1/2, achtet 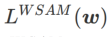 mehr auf die Ebenheit, also ist es so Dasselbe wie bei SAM ist es einfacher, Punkte mit kleineren Krümmungen zu finden als mit kleineren Verlustwerten und umgekehrt.
mehr auf die Ebenheit, also ist es so Dasselbe wie bei SAM ist es einfacher, Punkte mit kleineren Krümmungen zu finden als mit kleineren Verlustwerten und umgekehrt. 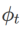 und
und 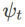 implementiert werden, siehe Algorithmus 2. Wenn beispielsweise
implementiert werden, siehe Algorithmus 2. Wenn beispielsweise  und
und 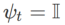 sind, erhalten wir WSAM, dessen Basisoptimierer SGD ist, siehe Algorithmus 3. Hier wenden wir eine Technik der „Gewichtungsentkopplung“ an, bei der der Flachheitsterm nicht in den Basisoptimierer zur Berechnung von Gradienten und Aktualisierung von Gewichten integriert wird, sondern unabhängig berechnet wird (der letzte Term in Zeile 7 von Algorithmus 2). Auf diese Weise spiegelt der Regularisierungseffekt nur die Flachheit des aktuellen Schritts ohne zusätzliche Informationen wider. Zum Vergleich: Algorithmus 4 ergibt einen WSAM ohne „Gewichtsentkopplung“ (Coupled-WSAM genannt). Wenn der zugrunde liegende Optimierer beispielsweise SGDM ist, ist der Regularisierungsterm von Coupled-WSAM ein exponentieller gleitender Durchschnitt der Flachheit. Wie im experimentellen Teil gezeigt, kann die „Gewichtsentkopplung“ in den meisten Fällen die Generalisierungsleistung verbessern.
sind, erhalten wir WSAM, dessen Basisoptimierer SGD ist, siehe Algorithmus 3. Hier wenden wir eine Technik der „Gewichtungsentkopplung“ an, bei der der Flachheitsterm nicht in den Basisoptimierer zur Berechnung von Gradienten und Aktualisierung von Gewichten integriert wird, sondern unabhängig berechnet wird (der letzte Term in Zeile 7 von Algorithmus 2). Auf diese Weise spiegelt der Regularisierungseffekt nur die Flachheit des aktuellen Schritts ohne zusätzliche Informationen wider. Zum Vergleich: Algorithmus 4 ergibt einen WSAM ohne „Gewichtsentkopplung“ (Coupled-WSAM genannt). Wenn der zugrunde liegende Optimierer beispielsweise SGDM ist, ist der Regularisierungsterm von Coupled-WSAM ein exponentieller gleitender Durchschnitt der Flachheit. Wie im experimentellen Teil gezeigt, kann die „Gewichtsentkopplung“ in den meisten Fällen die Generalisierungsleistung verbessern. 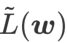




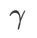 Werten. Wenn
Werten. Wenn 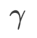 , liegt
, liegt 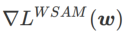 zwischen
zwischen 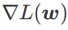 und
und 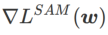 und weicht mit zunehmendem
und weicht mit zunehmendem 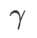 allmählich von
allmählich von 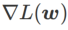 ab.
ab.

Einfaches Beispiel
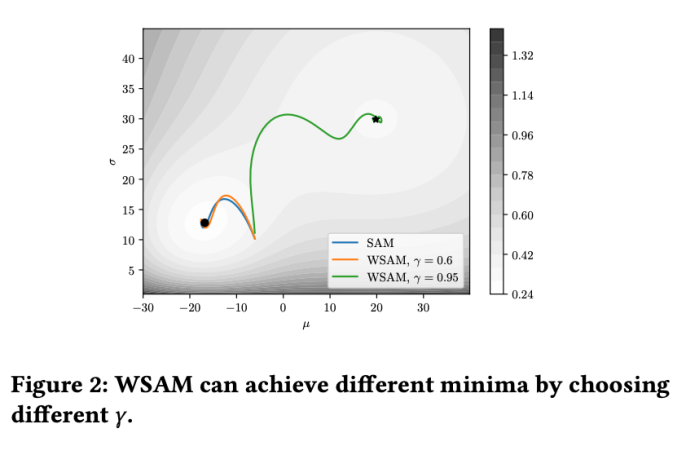
Um die Wirkung und Vorteile von γ in WSAM besser zu veranschaulichen, haben wir ein zweidimensionales einfaches Beispiel erstellt. Wie in Abb. 2 gezeigt, hat die Verlustfunktion einen relativ ungleichmäßigen Extrempunkt in der unteren linken Ecke (Position: (-16,8, 12,8), Verlustwert: 0,28) und einen flachen Extrempunkt in der oberen rechten Ecke (Position: (19,8, 29,9), Verlustwert: 0,36). Die Verlustfunktion ist definiert als: 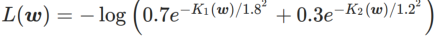 , wobei
, wobei 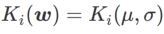 die KL-Divergenz zwischen dem univariaten Gaußschen Modell und zwei Normalverteilungen ist, also
die KL-Divergenz zwischen dem univariaten Gaußschen Modell und zwei Normalverteilungen ist, also 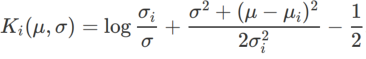 , wobei
, wobei 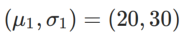 und
und 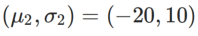 ist.
ist.
Wir verwenden SGDM mit einem Impuls von 0,9 als Basisoptimierer und setzen 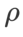 =2 für SAM und WSAM. Ausgehend vom Anfangspunkt (-6, 10) wird die Verlustfunktion in 150 Schritten mit einer Lernrate von 5 optimiert. SAM konvergiert zum Extrempunkt mit geringerem Verlustwert, aber ungleichmäßiger, ähnlich wie WSAM mit
=2 für SAM und WSAM. Ausgehend vom Anfangspunkt (-6, 10) wird die Verlustfunktion in 150 Schritten mit einer Lernrate von 5 optimiert. SAM konvergiert zum Extrempunkt mit geringerem Verlustwert, aber ungleichmäßiger, ähnlich wie WSAM mit 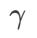 =0,6. Allerdings führt
=0,6. Allerdings führt 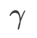 =0,95 dazu, dass die Verlustfunktion zu einem flachen Extrempunkt konvergiert, was darauf hindeutet, dass eine stärkere Flatness-Regularisierung eine Rolle spielt.
=0,95 dazu, dass die Verlustfunktion zu einem flachen Extrempunkt konvergiert, was darauf hindeutet, dass eine stärkere Flatness-Regularisierung eine Rolle spielt.
Experimente
Wir haben Experimente zu verschiedenen Aufgaben durchgeführt, um die Wirksamkeit von WSAM zu überprüfen.
Bildklassifizierung
Wir haben zunächst die Wirkung von WSAM auf Trainingsmodelle von Grund auf an den Datensätzen Cifar10 und Cifar100 untersucht. Zu den von uns ausgewählten Modellen gehören ResNet18 und WideResNet-28-10. Wir trainieren Modelle auf Cifar10 und Cifar100 mit vordefinierten Batchgrößen von 128 bzw. 256 für ResNet18 bzw. WideResNet-28-10. Der hier verwendete Basisoptimierer ist SGDM mit einem Impuls von 0,9. Gemäß den Einstellungen von SAM [1] führt jeder Basisoptimierer doppelt so viele Epochen aus wie der SAM-Klassenoptimierer. Wir haben beide Modelle für 400 Epochen trainiert (200 Epochen für den SAM-Klassenoptimierer) und einen Cosinus-Scheduler verwendet, um die Lernrate zu verringern. Hier verwenden wir keine anderen erweiterten Datenerweiterungsmethoden wie Cutout und AutoAugment.
Für beide Modelle verwenden wir eine gemeinsame Rastersuche, um die Lernrate und den Gewichtsabfallkoeffizienten des Basisoptimierers zu bestimmen und sie für die folgenden Experimente mit dem SAM-Klassenoptimierer konstant zu halten. Die Suchbereiche für Lernrate und Gewichtsabfallkoeffizient sind {0,05, 0,1} bzw. {1e-4, 5e-4, 1e-3}. Da alle SAM-Klassenoptimierer einen Hyperparameter 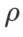 (Nachbarschaftsgröße) haben, suchen wir als nächstes nach dem besten
(Nachbarschaftsgröße) haben, suchen wir als nächstes nach dem besten 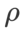 auf dem SAM-Optimierer und verwenden denselben Wert für andere SAM-Klassenoptimierer. Der Suchbereich von
auf dem SAM-Optimierer und verwenden denselben Wert für andere SAM-Klassenoptimierer. Der Suchbereich von 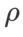 ist {0,01, 0,02, 0,05, 0,1, 0,2, 0,5}. Schließlich suchten wir nach den einzigartigen Hyperparametern anderer SAM-Klassenoptimierer und der Suchbereich entstammte dem empfohlenen Bereich ihrer jeweiligen Originalartikel. Für GSAM [2] suchen wir im Bereich {0,01, 0,02, 0,03, 0,1, 0,2, 0,3}. Für ESAM [3] suchen wir nach
ist {0,01, 0,02, 0,05, 0,1, 0,2, 0,5}. Schließlich suchten wir nach den einzigartigen Hyperparametern anderer SAM-Klassenoptimierer und der Suchbereich entstammte dem empfohlenen Bereich ihrer jeweiligen Originalartikel. Für GSAM [2] suchen wir im Bereich {0,01, 0,02, 0,03, 0,1, 0,2, 0,3}. Für ESAM [3] suchen wir nach  im Bereich von {0,4, 0,5, 0,6},
im Bereich von {0,4, 0,5, 0,6}, 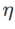 im Bereich von {0,4, 0,5, 0,6} und
im Bereich von {0,4, 0,5, 0,6} und 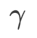 im Bereich von {0,4, 0,5 , 0,6}. Für WSAM suchen wir nach im Bereich {0,5, 0,6, 0,7, 0,8, 0,82, 0,84, 0,86, 0,88, 0,9, 0,92, 0,94, 0,96}. Wir haben das Experiment fünfmal mit verschiedenen Zufallsstartwerten wiederholt und den mittleren Fehler und die Standardabweichung berechnet. Wir führen Experimente mit einer Einzelkarten-NVIDIA A100-GPU durch. Die Optimierer-Hyperparameter für jedes Modell sind in Tab. 3 zusammengefasst.
im Bereich von {0,4, 0,5 , 0,6}. Für WSAM suchen wir nach im Bereich {0,5, 0,6, 0,7, 0,8, 0,82, 0,84, 0,86, 0,88, 0,9, 0,92, 0,94, 0,96}. Wir haben das Experiment fünfmal mit verschiedenen Zufallsstartwerten wiederholt und den mittleren Fehler und die Standardabweichung berechnet. Wir führen Experimente mit einer Einzelkarten-NVIDIA A100-GPU durch. Die Optimierer-Hyperparameter für jedes Modell sind in Tab. 3 zusammengefasst. 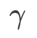
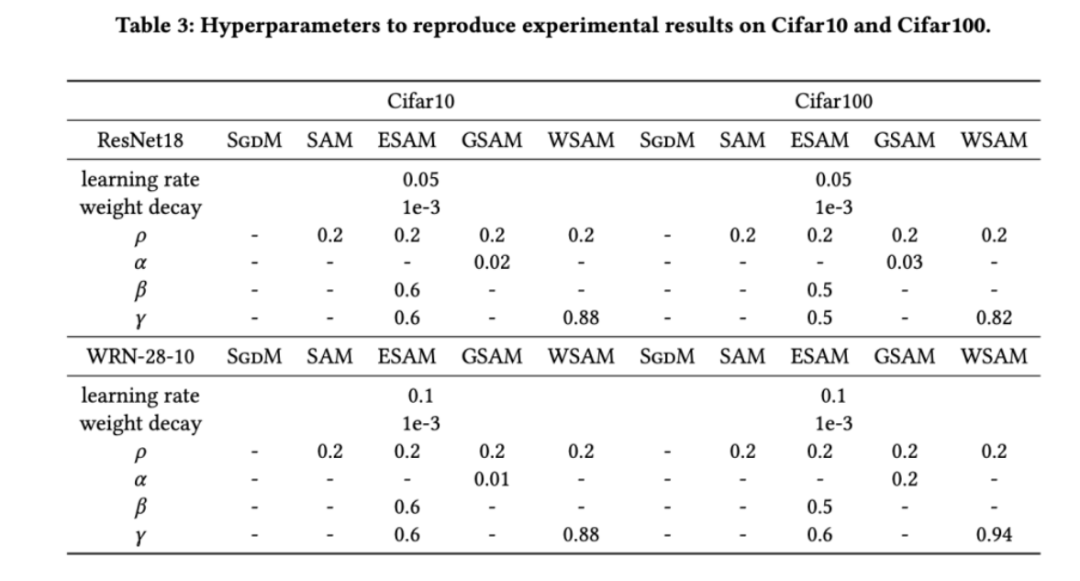
Tab. 2 zeigt die Top-1-Fehlerrate von ResNet18, WRN-28-10 im Testsatz auf Cifar10 und Cifar100 unter verschiedenen Optimierern. Im Vergleich zum Basisoptimierer verbessert der SAM-Klassenoptimierer die Leistung erheblich. Gleichzeitig ist WSAM deutlich besser als andere SAM-Klassenoptimierer.
Zusätzliche Schulung zu ImageNet
Wir führen außerdem Experimente mit dem ImageNet-Datensatz unter Verwendung der Netzwerkstruktur Data-Efficient Image Transformers durch. Wir nehmen einen vorab trainierten DeiT-Basiskontrollpunkt wieder auf und trainieren dann drei Epochen lang weiter. Das Modell wird mit einer Stapelgröße von 256 trainiert, der Basisoptimierer ist SGDM mit Impuls 0,9, der Gewichtsabfallkoeffizient beträgt 1e-4 und die Lernrate beträgt 1e-5. Wir haben den Lauf fünfmal auf einer NVIDIA A100-GPU mit vier Karten wiederholt und den durchschnittlichen Fehler und die Standardabweichung berechnet. Wir haben nach dem besten SAM in {0,05, 0,1, 0,5, 1,0,⋯, 6,0} gesucht. . Das Optimum
=5,5 wird direkt in anderen SAM-Klassenoptimierern verwendet. Danach suchen wir nach dem besten von GSAM in {0,01, 0,02, 0,03, 0,1, 0,2, 0,3} und dem besten 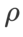 von WSAM zwischen 0,80 und 0,98 mit einer Schrittweite von 0,02.
von WSAM zwischen 0,80 und 0,98 mit einer Schrittweite von 0,02. 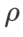
 Die anfängliche Top-1-Fehlerrate des Modells beträgt 18,2 %, und nach drei weiteren Epochen ist die Fehlerrate in Tab. 4 dargestellt. Wir finden keine signifikanten Unterschiede zwischen den drei SAM-ähnlichen Optimierern, aber sie übertreffen alle den Basisoptimierer, was darauf hindeutet, dass sie flachere Extrempunkte finden können und über bessere Generalisierungsfähigkeiten verfügen.
Die anfängliche Top-1-Fehlerrate des Modells beträgt 18,2 %, und nach drei weiteren Epochen ist die Fehlerrate in Tab. 4 dargestellt. Wir finden keine signifikanten Unterschiede zwischen den drei SAM-ähnlichen Optimierern, aber sie übertreffen alle den Basisoptimierer, was darauf hindeutet, dass sie flachere Extrempunkte finden können und über bessere Generalisierungsfähigkeiten verfügen. 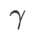
Robustheit gegenüber Label-Rauschen
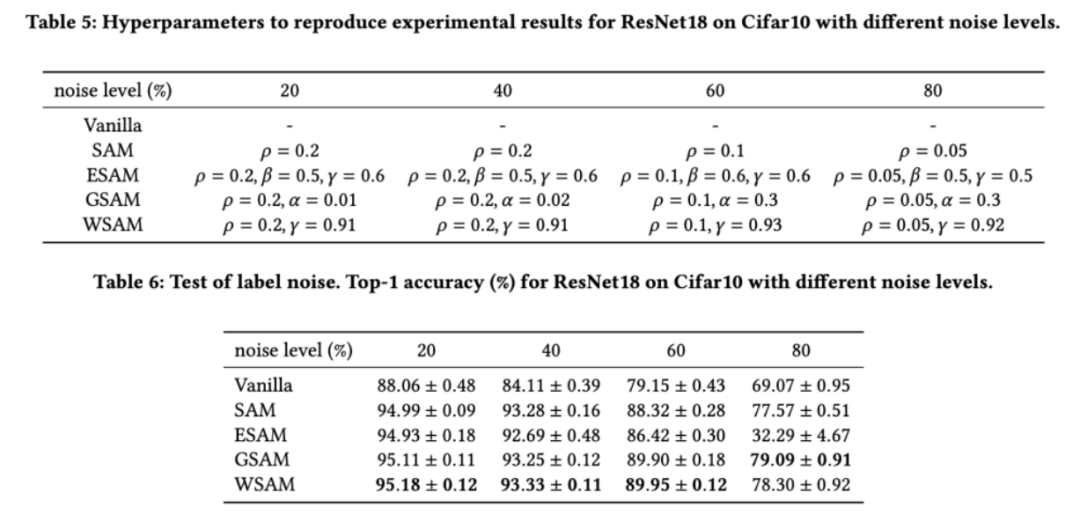
Wie in früheren Studien [1, 4, 5] gezeigt, zeigen SAM-Klassenoptimierer eine gute Robustheit, wenn Label-Rauschen im Trainingssatz vorhanden ist. Hier vergleichen wir die Robustheit von WSAM mit SAM, ESAM und GSAM. Wir trainieren ResNet18 auf dem Cifar10-Datensatz für 200 Epochen und injizieren symmetrisches Label-Rauschen mit Rauschpegeln von 20 %, 40 %, 60 % und 80 %. Wir verwenden SGDM mit einem Impuls von 0,9 als Basisoptimierer, einer Stapelgröße von 128, einer Lernrate von 0,05, einem Gewichtsabfallkoeffizienten von 1e-3 und einem Cosinus-Scheduler zum Abfallen der Lernrate. Für jeden Label-Rauschenpegel haben wir eine Rastersuche auf dem SAM im Bereich {0,01, 0,02, 0,05, 0,1, 0,2, 0,5} durchgeführt, um einen universellen 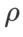 -Wert zu ermitteln. Anschließend suchen wir einzeln nach anderen optimiererspezifischen Hyperparametern, um die optimale Generalisierungsleistung zu finden. Die zur Reproduktion unserer Ergebnisse erforderlichen Hyperparameter listen wir in Tab. 5 auf. Die Ergebnisse des Robustheitstests stellen wir in Tab. 6 dar. WSAM weist im Allgemeinen eine bessere Robustheit auf als SAM, ESAM und GSAM.
-Wert zu ermitteln. Anschließend suchen wir einzeln nach anderen optimiererspezifischen Hyperparametern, um die optimale Generalisierungsleistung zu finden. Die zur Reproduktion unserer Ergebnisse erforderlichen Hyperparameter listen wir in Tab. 5 auf. Die Ergebnisse des Robustheitstests stellen wir in Tab. 6 dar. WSAM weist im Allgemeinen eine bessere Robustheit auf als SAM, ESAM und GSAM.
Auswirkungen der Explorationsgeometrie
SAM-ähnliche Optimierer können mit Techniken wie ASAM [4] und Fisher SAM [5] kombiniert werden, um die Form der Explorationsnachbarschaft adaptiv anzupassen. Wir führen Experimente zu WRN-28-10 auf Cifar10 durch, um die Leistung von SAM und WSAM bei Verwendung adaptiver bzw. Fisher-Informationsmethoden zu vergleichen und zu verstehen, wie sich die Geometrie der Explorationsregion auf die Generalisierungsleistung von SAM-ähnlichen Optimierern auswirkt.
Mit Ausnahme der Parameter 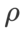 und
und 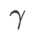 haben wir die Konfiguration bei der Bildklassifizierung wiederverwendet. Laut früheren Studien [4, 5] sind die
haben wir die Konfiguration bei der Bildklassifizierung wiederverwendet. Laut früheren Studien [4, 5] sind die 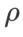 von ASAM und Fisher SAM in der Regel größer. Wir suchen nach den besten
von ASAM und Fisher SAM in der Regel größer. Wir suchen nach den besten 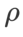 in {0,1, 0,5, 1,0,…, 6,0}, und die besten
in {0,1, 0,5, 1,0,…, 6,0}, und die besten 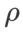 für ASAM und Fisher SAM sind beide 5,0. Danach haben wir nach dem besten
für ASAM und Fisher SAM sind beide 5,0. Danach haben wir nach dem besten 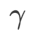 von WSAM zwischen 0,80 und 0,94 mit einer Schrittweite von 0,02 gesucht, und der beste
von WSAM zwischen 0,80 und 0,94 mit einer Schrittweite von 0,02 gesucht, und der beste 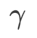 beider Methoden war 0,88.
beider Methoden war 0,88.
Überraschenderweise zeigt der Basis-WSAM, wie in Tab. 7 gezeigt, eine bessere Verallgemeinerung, selbst bei mehreren Kandidaten. Daher empfehlen wir, WSAM einfach mit einer festen 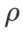 Baseline zu verwenden.
Baseline zu verwenden.

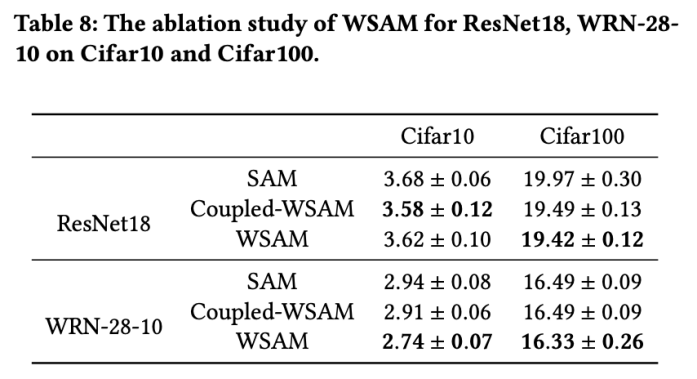
Ablationsexperiment
In diesem Abschnitt führen wir Ablationsexperimente durch, um ein tiefes Verständnis für die Bedeutung der „Gewichtsentkopplungstechnik“ bei WSAM zu erlangen. Wie in den Designdetails von WSAM beschrieben, vergleichen wir die WSAM-Variante ohne „Gewichtsentkopplung“ (Algorithmus 4) Coupled-WSAM mit der ursprünglichen Methode.
Die Ergebnisse sind in Tab. 8 dargestellt. Coupled-WSAM liefert in den meisten Fällen bessere Ergebnisse als SAM, und WSAM verbessert die Ergebnisse in den meisten Fällen noch weiter, was die Wirksamkeit der „Gewichtsentkopplungs“-Technik demonstriert.
Extrempunktanalyse
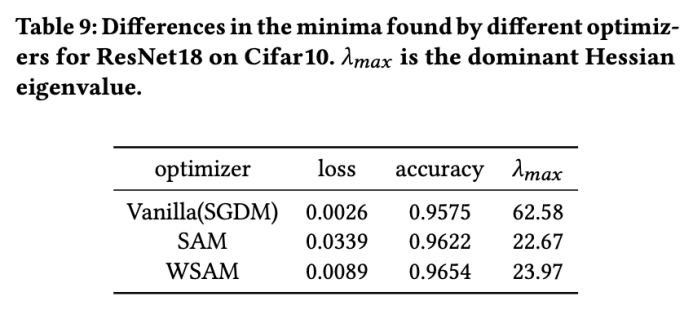
Hier vertiefen wir unser Verständnis des WSAM-Optimierers weiter, indem wir die Unterschiede zwischen den vom WSAM- und SAM-Optimierer gefundenen Extrempunkten vergleichen. Die Ebenheit (Steilheit) an Extrempunkten kann durch den maximalen Eigenwert der Hesse-Matrix beschrieben werden. Je größer der Eigenwert, desto weniger flach ist er. Wir verwenden den Power-Iteration-Algorithmus, um diesen maximalen Eigenwert zu berechnen.
Tab. 9 zeigt den Unterschied zwischen den von den SAM- und WSAM-Optimierern gefundenen Extrempunkten. Wir stellen fest, dass die vom Vanilla-Optimierer gefundenen Extrempunkte kleinere Verlustwerte aufweisen, aber weniger flach sind, während die von SAM gefundenen Extrempunkte größere Verlustwerte aufweisen, aber flacher sind, wodurch die Generalisierungsleistung verbessert wird. Interessanterweise weisen die von WSAM gefundenen Extrempunkte nicht nur viel kleinere Verlustwerte als SAM auf, sondern weisen auch eine Flachheit auf, die der von SAM sehr nahe kommt. Dies zeigt, dass WSAM bei der Suche nach Extrempunkten Priorität auf die Sicherstellung kleinerer Verlustwerte legt und gleichzeitig versucht, nach flacheren Bereichen zu suchen.
Hyperparameter-Sensitivität
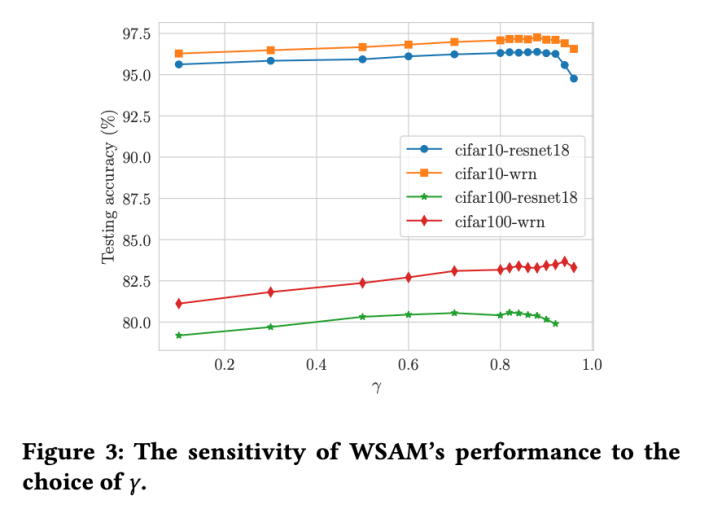
Im Vergleich zu SAM verfügt WSAM über einen zusätzlichen Hyperparameter 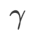 zur Skalierung der Größe des flachen (steilen) Gradterms. Hier testen wir die Empfindlichkeit der Generalisierungsleistung von WSAM gegenüber diesem Hyperparameter. Wir haben ResNet18- und WRN-28-10-Modelle mit WSAM auf Cifar10 und Cifar100 trainiert und dabei eine breite Palette von
zur Skalierung der Größe des flachen (steilen) Gradterms. Hier testen wir die Empfindlichkeit der Generalisierungsleistung von WSAM gegenüber diesem Hyperparameter. Wir haben ResNet18- und WRN-28-10-Modelle mit WSAM auf Cifar10 und Cifar100 trainiert und dabei eine breite Palette von 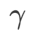 -Werten verwendet. Wie in Abb. 3 dargestellt, zeigen die Ergebnisse, dass WSAM nicht empfindlich auf die Wahl des Hyperparameters
-Werten verwendet. Wie in Abb. 3 dargestellt, zeigen die Ergebnisse, dass WSAM nicht empfindlich auf die Wahl des Hyperparameters  reagiert. Wir haben außerdem herausgefunden, dass die optimale Generalisierungsleistung von WSAM fast immer zwischen 0,8 und 0,95 liegt.
reagiert. Wir haben außerdem herausgefunden, dass die optimale Generalisierungsleistung von WSAM fast immer zwischen 0,8 und 0,95 liegt.
Das obige ist der detaillierte Inhalt vonVielseitiger und effektiver: Ants selbst entwickelter Optimierer WSAM wurde für KDD Oral ausgewählt. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 Verwenden Sie ddrescue, um Daten unter Linux wiederherzustellen
Mar 20, 2024 pm 01:37 PM
Verwenden Sie ddrescue, um Daten unter Linux wiederherzustellen
Mar 20, 2024 pm 01:37 PM
DDREASE ist ein Tool zum Wiederherstellen von Daten von Datei- oder Blockgeräten wie Festplatten, SSDs, RAM-Disks, CDs, DVDs und USB-Speichergeräten. Es kopiert Daten von einem Blockgerät auf ein anderes, wobei beschädigte Blöcke zurückbleiben und nur gute Blöcke verschoben werden. ddreasue ist ein leistungsstarkes Wiederherstellungstool, das vollständig automatisiert ist, da es während der Wiederherstellungsvorgänge keine Unterbrechungen erfordert. Darüber hinaus kann es dank der ddasue-Map-Datei jederzeit gestoppt und fortgesetzt werden. Weitere wichtige Funktionen von DDREASE sind: Es überschreibt die wiederhergestellten Daten nicht, füllt aber die Lücken im Falle einer iterativen Wiederherstellung. Es kann jedoch gekürzt werden, wenn das Tool explizit dazu aufgefordert wird. Stellen Sie Daten aus mehreren Dateien oder Blöcken in einer einzigen wieder her
 Open Source! Jenseits von ZoeDepth! DepthFM: Schnelle und genaue monokulare Tiefenschätzung!
Apr 03, 2024 pm 12:04 PM
Open Source! Jenseits von ZoeDepth! DepthFM: Schnelle und genaue monokulare Tiefenschätzung!
Apr 03, 2024 pm 12:04 PM
0.Was bewirkt dieser Artikel? Wir schlagen DepthFM vor: ein vielseitiges und schnelles generatives monokulares Tiefenschätzungsmodell auf dem neuesten Stand der Technik. Zusätzlich zu herkömmlichen Tiefenschätzungsaufgaben demonstriert DepthFM auch hochmoderne Fähigkeiten bei nachgelagerten Aufgaben wie dem Tiefen-Inpainting. DepthFM ist effizient und kann Tiefenkarten innerhalb weniger Inferenzschritte synthetisieren. Lassen Sie uns diese Arbeit gemeinsam lesen ~ 1. Titel der Papierinformationen: DepthFM: FastMonocularDepthEstimationwithFlowMatching Autor: MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas tritt offiziell in die Ära der Elektroroboter ein! Gestern hat sich der hydraulische Atlas einfach „unter Tränen“ von der Bühne der Geschichte zurückgezogen. Heute gab Boston Dynamics bekannt, dass der elektrische Atlas im Einsatz ist. Es scheint, dass Boston Dynamics im Bereich kommerzieller humanoider Roboter entschlossen ist, mit Tesla zu konkurrieren. Nach der Veröffentlichung des neuen Videos wurde es innerhalb von nur zehn Stunden bereits von mehr als einer Million Menschen angesehen. Die alten Leute gehen und neue Rollen entstehen. Das ist eine historische Notwendigkeit. Es besteht kein Zweifel, dass dieses Jahr das explosive Jahr der humanoiden Roboter ist. Netizens kommentierten: Die Weiterentwicklung der Roboter hat dazu geführt, dass die diesjährige Eröffnungsfeier wie Menschen aussieht, und der Freiheitsgrad ist weitaus größer als der von Menschen. Aber ist das wirklich kein Horrorfilm? Zu Beginn des Videos liegt Atlas ruhig auf dem Boden, scheinbar auf dem Rücken. Was folgt, ist atemberaubend
 Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Die von Google geförderte Leistung von JAX hat in jüngsten Benchmark-Tests die von Pytorch und TensorFlow übertroffen und belegt bei 7 Indikatoren den ersten Platz. Und der Test wurde nicht auf der TPU mit der besten JAX-Leistung durchgeführt. Obwohl unter Entwicklern Pytorch immer noch beliebter ist als Tensorflow. Aber in Zukunft werden möglicherweise mehr große Modelle auf Basis der JAX-Plattform trainiert und ausgeführt. Modelle Kürzlich hat das Keras-Team drei Backends (TensorFlow, JAX, PyTorch) mit der nativen PyTorch-Implementierung und Keras2 mit TensorFlow verglichen. Zunächst wählen sie eine Reihe von Mainstream-Inhalten aus
 Langsame Internetgeschwindigkeiten für Mobilfunkdaten auf dem iPhone: Korrekturen
May 03, 2024 pm 09:01 PM
Langsame Internetgeschwindigkeiten für Mobilfunkdaten auf dem iPhone: Korrekturen
May 03, 2024 pm 09:01 PM
Stehen Sie vor einer Verzögerung oder einer langsamen mobilen Datenverbindung auf dem iPhone? Normalerweise hängt die Stärke des Mobilfunk-Internets auf Ihrem Telefon von mehreren Faktoren ab, wie z. B. der Region, dem Mobilfunknetztyp, dem Roaming-Typ usw. Es gibt einige Dinge, die Sie tun können, um eine schnellere und zuverlässigere Mobilfunk-Internetverbindung zu erhalten. Fix 1 – Neustart des iPhone erzwingen Manchmal werden durch einen erzwungenen Neustart Ihres Geräts viele Dinge zurückgesetzt, einschließlich der Mobilfunkverbindung. Schritt 1 – Drücken Sie einfach einmal die Lauter-Taste und lassen Sie sie los. Drücken Sie anschließend die Leiser-Taste und lassen Sie sie wieder los. Schritt 2 – Der nächste Teil des Prozesses besteht darin, die Taste auf der rechten Seite gedrückt zu halten. Lassen Sie das iPhone den Neustart abschließen. Aktivieren Sie Mobilfunkdaten und überprüfen Sie die Netzwerkgeschwindigkeit. Überprüfen Sie es erneut. Fix 2 – Datenmodus ändern 5G bietet zwar bessere Netzwerkgeschwindigkeiten, funktioniert jedoch besser, wenn das Signal schwächer ist
 Die Kuaishou-Version von Sora „Ke Ling' steht zum Testen offen: Sie generiert über 120 Sekunden Videos, versteht die Physik besser und kann komplexe Bewegungen genau modellieren
Jun 11, 2024 am 09:51 AM
Die Kuaishou-Version von Sora „Ke Ling' steht zum Testen offen: Sie generiert über 120 Sekunden Videos, versteht die Physik besser und kann komplexe Bewegungen genau modellieren
Jun 11, 2024 am 09:51 AM
Was? Wird Zootopia durch heimische KI in die Realität umgesetzt? Zusammen mit dem Video wird ein neues groß angelegtes inländisches Videogenerationsmodell namens „Keling“ vorgestellt. Sora geht einen ähnlichen technischen Weg und kombiniert eine Reihe selbst entwickelter technologischer Innovationen, um Videos zu produzieren, die nicht nur große und vernünftige Bewegungen aufweisen, sondern auch die Eigenschaften der physischen Welt simulieren und über starke konzeptionelle Kombinationsfähigkeiten und Vorstellungskraft verfügen. Den Daten zufolge unterstützt Keling die Erstellung ultralanger Videos von bis zu 2 Minuten mit 30 Bildern pro Sekunde, mit Auflösungen von bis zu 1080p und unterstützt mehrere Seitenverhältnisse. Ein weiterer wichtiger Punkt ist, dass es sich bei Keling nicht um eine vom Labor veröffentlichte Demo oder Video-Ergebnisdemonstration handelt, sondern um eine Anwendung auf Produktebene, die von Kuaishou, einem führenden Anbieter im Bereich Kurzvideos, gestartet wurde. Darüber hinaus liegt das Hauptaugenmerk darauf, pragmatisch zu sein, keine Blankoschecks auszustellen und sofort nach der Veröffentlichung online zu gehen. Das große Modell von Ke Ling wurde bereits in Kuaiying veröffentlicht.
 Die Vitalität der Superintelligenz erwacht! Aber mit der Einführung der sich selbst aktualisierenden KI müssen sich Mütter keine Sorgen mehr über Datenengpässe machen
Apr 29, 2024 pm 06:55 PM
Die Vitalität der Superintelligenz erwacht! Aber mit der Einführung der sich selbst aktualisierenden KI müssen sich Mütter keine Sorgen mehr über Datenengpässe machen
Apr 29, 2024 pm 06:55 PM
Ich weine zu Tode. Die Daten im Internet reichen überhaupt nicht aus. Das Trainingsmodell sieht aus wie „Die Tribute von Panem“, und KI-Forscher auf der ganzen Welt machen sich Gedanken darüber, wie sie diese datenhungrigen Esser ernähren sollen. Dieses Problem tritt insbesondere bei multimodalen Aufgaben auf. Zu einer Zeit, als sie ratlos waren, nutzte ein Start-up-Team der Abteilung der Renmin-Universität von China sein eigenes neues Modell, um als erstes in China einen „modellgenerierten Datenfeed selbst“ in die Realität umzusetzen. Darüber hinaus handelt es sich um einen zweigleisigen Ansatz auf der Verständnisseite und der Generierungsseite. Beide Seiten können hochwertige, multimodale neue Daten generieren und Datenrückmeldungen an das Modell selbst liefern. Was ist ein Modell? Awaker 1.0, ein großes multimodales Modell, das gerade im Zhongguancun-Forum erschienen ist. Wer ist das Team? Sophon-Motor. Gegründet von Gao Yizhao, einem Doktoranden an der Hillhouse School of Artificial Intelligence der Renmin University.
 Die U.S. Air Force präsentiert ihren ersten KI-Kampfjet mit großem Aufsehen! Der Minister führte die Testfahrt persönlich durch, ohne in den gesamten Prozess einzugreifen, und 100.000 Codezeilen wurden 21 Mal getestet.
May 07, 2024 pm 05:00 PM
Die U.S. Air Force präsentiert ihren ersten KI-Kampfjet mit großem Aufsehen! Der Minister führte die Testfahrt persönlich durch, ohne in den gesamten Prozess einzugreifen, und 100.000 Codezeilen wurden 21 Mal getestet.
May 07, 2024 pm 05:00 PM
Kürzlich wurde die Militärwelt von der Nachricht überwältigt: US-Militärkampfflugzeuge können jetzt mithilfe von KI vollautomatische Luftkämpfe absolvieren. Ja, erst kürzlich wurde der KI-Kampfjet des US-Militärs zum ersten Mal der Öffentlichkeit zugänglich gemacht und sein Geheimnis gelüftet. Der vollständige Name dieses Jägers lautet „Variable Stability Simulator Test Aircraft“ (VISTA). Er wurde vom Minister der US-Luftwaffe persönlich geflogen, um einen Eins-gegen-eins-Luftkampf zu simulieren. Am 2. Mai startete US-Luftwaffenminister Frank Kendall mit einer X-62AVISTA auf der Edwards Air Force Base. Beachten Sie, dass während des einstündigen Fluges alle Flugaktionen autonom von der KI durchgeführt wurden! Kendall sagte: „In den letzten Jahrzehnten haben wir über das unbegrenzte Potenzial des autonomen Luft-Luft-Kampfes nachgedacht, aber es schien immer unerreichbar.“ Nun jedoch,
