
 Technologie-Peripheriegeräte
KI
Überarbeitung des Titels: ICCV 2023 Hervorragende Verfolgung von Studentenarbeiten, Github hat 1,6.000 Sterne erhalten, umfassende Informationen wie von Zauberhand!
Technologie-Peripheriegeräte
KI
Überarbeitung des Titels: ICCV 2023 Hervorragende Verfolgung von Studentenarbeiten, Github hat 1,6.000 Sterne erhalten, umfassende Informationen wie von Zauberhand!
Überarbeitung des Titels: ICCV 2023 Hervorragende Verfolgung von Studentenarbeiten, Github hat 1,6.000 Sterne erhalten, umfassende Informationen wie von Zauberhand!

1. Informationen zur Arbeit
Die beste Studentenarbeit des ICCV2023 wurde an Qianqian Wang von der Cornell University verliehen, der derzeit Postdoktorand an der University of California, Berkeley ist!
Im Bereich der Videobewegungsschätzung weist der Autor darauf hin, dass herkömmliche Methoden hauptsächlich in zwei Typen unterteilt werden: Verfolgung spärlicher Merkmale und dichter optischer Fluss. Während sich beide Methoden in ihren jeweiligen Anwendungen als effektiv erwiesen haben, erfasst keine von beiden die Bewegung im Video vollständig. Der gepaarte optische Fluss kann Bewegungstrajektorien innerhalb langer Zeitfenster nicht erfassen, während spärliches Tracking nicht die Bewegung aller Pixel modellieren kann. Um diese Lücke zu schließen, haben viele Studien versucht, gleichzeitig dichte und weitreichende Pixeltrajektorien in Videos zu schätzen. Die Methoden dieser Studien reichen von der einfachen Verknüpfung der optischen Flussfelder zweier Bilder bis hin zur direkten Vorhersage der Flugbahn jedes Pixels über mehrere Bilder hinweg. Allerdings berücksichtigen diese Methoden bei der Bewegungsschätzung oft nur einen begrenzten Kontext und ignorieren zeitlich oder räumlich weit entfernte Informationen. Diese Kurzsichtigkeit kann zu einer Fehlerakkumulation auf langen Trajektorien sowie zu räumlich-zeitlichen Inkonsistenzen bei der Bewegungsschätzung führen. Obwohl einige Methoden den langfristigen Kontext berücksichtigen, arbeiten sie immer noch im 2D-Bereich, was zu Tracking-Verlusten bei Okklusionsereignissen führen kann.
 Insgesamt bleibt die dichte und weiträumige Flugbahnschätzung in Videos ein ungelöstes Problem auf diesem Gebiet. Dieses Problem bringt drei Hauptherausforderungen mit sich: 1) Wie man die Flugbahngenauigkeit in langen Sequenzen aufrechterhält, 2) Wie man die Position von Punkten unter Okklusion verfolgt, 3) Wie man die räumlich-zeitliche Konsistenz aufrechterhält
Insgesamt bleibt die dichte und weiträumige Flugbahnschätzung in Videos ein ungelöstes Problem auf diesem Gebiet. Dieses Problem bringt drei Hauptherausforderungen mit sich: 1) Wie man die Flugbahngenauigkeit in langen Sequenzen aufrechterhält, 2) Wie man die Position von Punkten unter Okklusion verfolgt, 3) Wie man die räumlich-zeitliche Konsistenz aufrechterhält
In diesem Artikel schlagen die Autoren eine neuartige Videobewegung vor Schätzmethode, die alle Informationen im Video nutzt, um gemeinsam die vollständige Bewegungsbahn jedes Pixels zu schätzen. Diese Methode nennt sich „OmniMotion“ und nutzt eine Quasi-3D-Darstellung. In dieser Darstellung wird in jedem Frame ein Standard-3D-Volumen einem lokalen Volumen zugeordnet. Dieses Mapping dient als flexible Erweiterung der dynamischen Multi-View-Geometrie und kann Kamera- und Szenenbewegungen gleichzeitig simulieren. Diese Darstellung stellt nicht nur die Schleifenkonsistenz sicher, sondern verfolgt auch alle Pixel während der Verdeckungen. Die Autoren optimieren diese Darstellung für jedes Video und bieten eine Lösung für die Bewegung im gesamten Video. Nach der Optimierung kann diese Darstellung auf beliebigen kontinuierlichen Koordinaten des Videos abgefragt werden, um Bewegungstrajektorien zu erhalten, die sich über das gesamte Video erstrecken
Die in diesem Artikel vorgeschlagene Methode kann: 1) eine global konsistente vollständige Darstellung für alle Punkte in den gesamten Bewegungstrajektorien des Videos erzeugen , 2) Verfolgung von Punkten durch Okklusion und 3) Verarbeitung realer Videos mit verschiedenen Kamera- und Szenenaktionskombinationen. Beim TAP-Video-Tracking-Benchmark schneidet die Methode gut ab und übertrifft frühere Methoden bei weitem.
3. MethodeDer Artikel schlägt eine auf Testzeitoptimierung basierende Methode zur Schätzung dichter und weit entfernter Bewegungen aus Videosequenzen vor. Lassen Sie uns zunächst einen Überblick über die in der Arbeit vorgeschlagene Methode geben:
Eingabe
: Die Methode des Autors verwendet eine Reihe von Bildern und Paaren verrauschter Bewegungsschätzungen (z. B. optische Flussfelder) als Eingabe.- Methodenoperationen
- : Mithilfe dieser Eingaben versucht die Methode, eine vollständige und global konsistente Bewegungsdarstellung für das gesamte Video zu finden. Ergebnisfunktionen
- : Nach der Optimierung kann diese Darstellung mit jedem Pixel eines beliebigen Frames im Video abgefragt werden, was zu einer gleichmäßigen, genauen Bewegungsbahn über das gesamte Video führt. Diese Methode erkennt auch, wenn ein Punkt verdeckt ist, und kann Punkte verfolgen, die die Okklusion passieren. Kerninhalt
- :
- OmniMotion-Darstellung: Im folgenden Abschnitt beschreiben die Autoren zunächst ihre grundlegende Darstellung, OmniMotion genannt.
- Optimierungsprozess
- : Als nächstes beschreiben die Autoren den Optimierungsprozess, wie diese Darstellung aus dem Video wiederhergestellt werden kann. Diese Methode kann eine umfassende und kohärente Videobewegungsdarstellung liefern und herausfordernde Probleme wie Okklusion effektiv lösen. Jetzt lasst uns mehr darüber erfahren
- Keine Umkehrbarkeit: Diese Version entfernt die Komponente „Reversibilität“. Im Vergleich zur vollständigen Methode fallen alle Metriken deutlich ab, insbesondere bei AJ und , was zeigt, dass Reversibilität im gesamten System eine entscheidende Rolle spielt.
- Keine Photometrie: Diese Version entfernt die „photometrische“ Komponente. Obwohl die Leistung geringer ist als die der „Vollversion“, ist sie im Vergleich zur „irreversiblen“ Version besser. Dies zeigt, dass die photometrische Komponente zwar eine gewisse Rolle bei der Leistungsverbesserung spielt, ihre Bedeutung jedoch möglicherweise geringer ist als die der reversiblen Komponente.
- Einheitliche Probenahme: Diese Version verwendet eine einheitliche Probenahmestrategie. Es ist auch etwas weniger leistungsfähig als die Vollversion, aber immer noch besser als die Versionen „irreversibel“ und „Aluminium“.
- Vollversion: Dies ist die Vollversion mit allen Komponenten und sie erzielt bei allen Kennzahlen die beste Leistung. Dies zeigt, dass jede Komponente zur Leistungsverbesserung beiträgt, insbesondere wenn alle Komponenten integriert sind, kann das System die beste Leistung erzielen.
3.1 Kanonisches 3D-Volumen
Videoinhalte werden durch ein typisches Volumen namens G dargestellt, das als dreidimensionale Karte der beobachteten Szene fungiert. Ähnlich wie in NeRF definierten sie ein koordinatenbasiertes Netzwerk nerf, das jede typische 3D-Koordinate uvw in G einer Dichte σ und einer Farbe c zuordnet. Die in G gespeicherte Dichte sagt uns, wo sich die Oberfläche im typischen Raum befindet. In Kombination mit 3D-Bijektionen ermöglicht uns dies, Oberflächen über mehrere Frames hinweg zu verfolgen und Okklusionsbeziehungen zu verstehen. Die in G gespeicherte Farbe ermöglicht uns die Berechnung des photometrischen Verlusts während der Optimierung.
3.2 3D-Bijektionen
In diesem Artikel wird eine kontinuierliche Bijektionsabbildung vorgestellt, die als bezeichnet wird und 3D-Punkte von einem lokalen Koordinatensystem in ein kanonisches 3D-Koordinatensystem umwandelt. Diese kanonische Koordinate dient als konsistente zeitliche Referenz oder „Index“ für einen Szenenpunkt oder eine 3D-Trajektorie. Der Hauptvorteil der Verwendung bijektiver Abbildungen ist die periodische Konsistenz, die sie in 3D-Punkten zwischen verschiedenen Frames bieten, da sie alle vom selben kanonischen Punkt stammen.
Die Abbildungsgleichung von 3D-Punkten von einem lokalen Frame zu einem anderen lautet:
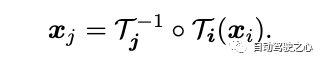
Um komplexe Bewegungen in der realen Welt zu erfassen, werden diese Bijektionen als invertierbare neuronale Netze (INNs) parametrisiert. Die Wahl von Real-NVP als Modell wurde durch seine Einfachheit und seine analytisch reversiblen Eigenschaften beeinflusst. Real-NVP implementiert bijektives Mapping mithilfe grundlegender Transformationen, die als affine Kopplungsschichten bezeichnet werden. Diese Schichten teilen die Eingabe auf, sodass ein Teil unverändert bleibt, während der andere Teil einer affinen Transformation unterzogen wird.
Um diese Architektur weiter zu verbessern, können wir dies tun, indem wir den latenten Code latent_i jedes Frames konditionieren. Daher werden alle reversiblen Abbildungen durch ein einziges reversibles Netzwerk-Mapping-Netz bestimmt, haben aber unterschiedliche latente Codes für jedes Abfragepixel in Frame i. Intuitiv werden Abfragepixel zunächst durch Abtasten von Punkten auf Strahlen in 3D „angehoben“, dann werden diese 3D-Punkte mithilfe der Bijektionszuordnung i und der Abbildung j auf den Zielrahmen j „abgebildet“, gefolgt von einer Alpha-Zusammensetzung aus verschiedenen Abtastwerten. Diese zugeordneten 3D-Punkte sind „gerendert“ und schließlich wieder in 2D „projiziert“, um eine angenommene Entsprechung zu erhalten.
4. Experimenteller Vergleich

Dies ist eine Tabelle mit Ergebnissen von Ablationsexperimenten für den DAVIS-Datensatz. Ablationsexperimente werden durchgeführt, um den Beitrag jeder Komponente zur Gesamtsystemleistung zu überprüfen. In dieser Tabelle sind vier Methoden aufgeführt, von denen drei Versionen bestimmte Schlüsselkomponenten entfernen und die endgültige „Vollversion“ alle Komponenten enthält. 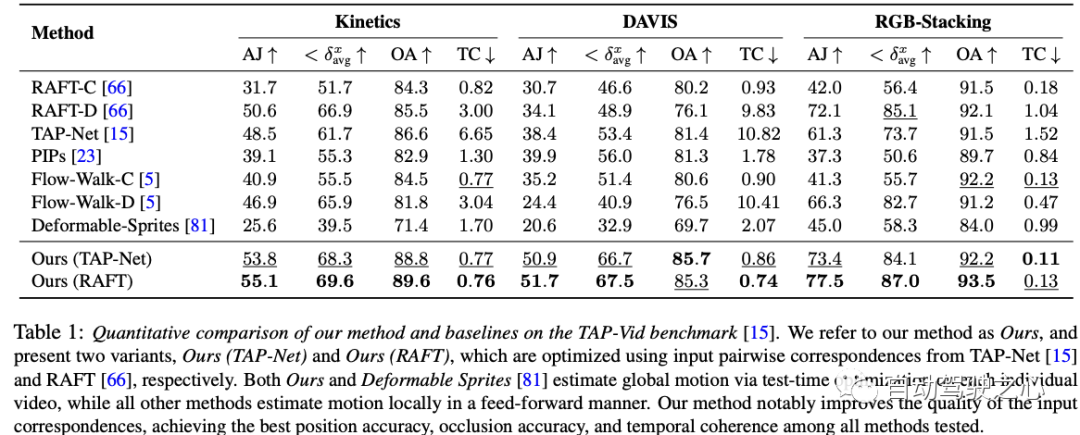
Insgesamt zeigen die Ergebnisse dieses Ablationsexperiments, dass, obwohl jede Komponente eine gewisse Leistungsverbesserung aufweist, die Reversibilität wahrscheinlich die wichtigste Komponente ist, denn ohne sie wird der Leistungsverlust sehr gravierend sein
5. Diskussion

Die in dieser Arbeit am DAVIS-Datensatz durchgeführten Ablationsexperimente liefern uns wertvolle Erkenntnisse und offenbaren die entscheidende Rolle jeder Komponente für die Gesamtsystemleistung. Aus den experimentellen Ergebnissen können wir deutlich erkennen, dass die Reversibilitätskomponente eine entscheidende Rolle im Gesamtrahmen spielt. Wenn diese kritische Komponente fehlt, sinkt die Systemleistung erheblich. Dies unterstreicht weiter die Bedeutung der Berücksichtigung der Reversibilität bei der dynamischen Videoanalyse. Gleichzeitig führt der Verlust der photometrischen Komponente zwar auch zu einer Leistungsverschlechterung, scheint jedoch keinen so großen Einfluss auf die Leistung zu haben wie die Reversibilität. Darüber hinaus hat die einheitliche Stichprobenstrategie zwar einen gewissen Einfluss auf die Leistung, ist jedoch im Vergleich zu den ersten beiden relativ gering. Schließlich integriert der Gesamtansatz alle diese Komponenten und zeigt uns die unter allen Gesichtspunkten bestmögliche Leistung. Insgesamt bietet uns diese Arbeit eine wertvolle Gelegenheit, Erkenntnisse darüber zu gewinnen, wie die verschiedenen Komponenten der Videoanalyse miteinander interagieren und welchen spezifischen Beitrag sie zur Gesamtleistung leisten, wodurch die Notwendigkeit eines integrierten Ansatzes bei der Gestaltung und Optimierung von Videoverarbeitungsalgorithmen hervorgehoben wird
Allerdings stößt unsere Methode, wie viele Methoden zur Bewegungsschätzung, auf Schwierigkeiten bei der Handhabung schneller und sehr instabiler Bewegungen und kleiner Strukturen. In diesen Szenarien liefern paarweise Korrespondenzmethoden möglicherweise nicht genügend zuverlässige Korrespondenz, damit unsere Methode eine genaue globale Bewegung berechnen kann. Darüber hinaus stellen wir aufgrund der stark nicht-konvexen Natur des zugrunde liegenden Optimierungsproblems fest, dass unser Optimierungsprozess bei bestimmten schwierigen Videos sehr empfindlich auf die Initialisierung reagieren kann. Dies kann zu suboptimalen lokalen Minima führen, beispielsweise zu einer falschen Oberflächenordnung oder zu doppelten Objekten im kanonischen Raum, die manchmal nur schwer durch Optimierung korrigiert werden können.
Schließlich kann unsere Methode in ihrer aktuellen Form rechenintensiv sein. Erstens beinhaltet der Prozess der Flusssammlung eine umfassende Berechnung aller paarweisen Flüsse, die quadratisch mit der Sequenzlänge wächst. Wir glauben jedoch, dass die Skalierbarkeit dieses Prozesses verbessert werden kann, indem effizientere Matching-Methoden wie Vokabelbäume oder Keyframe-basiertes Matching erforscht werden und man sich von der Strukturbewegungs- und SLAM-Literatur inspirieren lässt. Zweitens erfordert unsere Methode wie andere Methoden, die neuronale implizite Darstellungen verwenden, einen relativ langen Optimierungsprozess. Neuere Forschungen in diesem Bereich können dazu beitragen, diesen Prozess zu beschleunigen und ihn weiter auf längere Sequenzen auszudehnen . Es wird eine neue Videobewegungsdarstellung namens OmniMotion eingeführt, die aus einem quasi-3D-Standardvolumen und lokalkanonischen Bijektionen für jedes Bild besteht. OmniMotion kann gewöhnliche Videos mit unterschiedlichen Kameraeinstellungen und Szenendynamiken verarbeiten und durch Okklusion genaue und gleichmäßige Bewegungen über große Entfernungen erzeugen. Sowohl qualitativ als auch quantitativ werden deutliche Verbesserungen gegenüber bisherigen Methoden des Standes der Technik erzielt.
Der Inhalt, der neu geschrieben werden muss, ist: Originallink: https://mp.weixin.qq.com/s/HOIi5y9j-JwUImhpHPYgkg
Das obige ist der detaillierte Inhalt vonÜberarbeitung des Titels: ICCV 2023 Hervorragende Verfolgung von Studentenarbeiten, Github hat 1,6.000 Sterne erhalten, umfassende Informationen wie von Zauberhand!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1653
1653
 14
1413
52
1305
25
1251
29
1224
24
14
1413
52
1305
25
1251
29
1224
24

 Warum ist Gaussian Splatting beim autonomen Fahren so beliebt, dass NeRF allmählich aufgegeben wird?
Jan 17, 2024 pm 02:57 PM
Warum ist Gaussian Splatting beim autonomen Fahren so beliebt, dass NeRF allmählich aufgegeben wird?
Jan 17, 2024 pm 02:57 PM
Oben geschrieben und persönliches Verständnis des Autors. Dreidimensionales Gaussplatting (3DGS) ist eine transformative Technologie, die in den letzten Jahren in den Bereichen explizite Strahlungsfelder und Computergrafik entstanden ist. Diese innovative Methode zeichnet sich durch die Verwendung von Millionen von 3D-Gaußkurven aus, was sich stark von der Neural Radiation Field (NeRF)-Methode unterscheidet, die hauptsächlich ein implizites koordinatenbasiertes Modell verwendet, um räumliche Koordinaten auf Pixelwerte abzubilden. Mit seiner expliziten Szenendarstellung und differenzierbaren Rendering-Algorithmen garantiert 3DGS nicht nur Echtzeit-Rendering-Fähigkeiten, sondern führt auch ein beispielloses Maß an Kontrolle und Szenenbearbeitung ein. Dies positioniert 3DGS als potenziellen Game-Changer für die 3D-Rekonstruktion und -Darstellung der nächsten Generation. Zu diesem Zweck geben wir erstmals einen systematischen Überblick über die neuesten Entwicklungen und Anliegen im Bereich 3DGS.
 Wie lässt sich das Long-Tail-Problem in autonomen Fahrszenarien lösen?
Jun 02, 2024 pm 02:44 PM
Wie lässt sich das Long-Tail-Problem in autonomen Fahrszenarien lösen?
Jun 02, 2024 pm 02:44 PM
Gestern wurde ich während des Interviews gefragt, ob ich irgendwelche Long-Tail-Fragen gestellt hätte, also dachte ich, ich würde eine kurze Zusammenfassung geben. Das Long-Tail-Problem des autonomen Fahrens bezieht sich auf Randfälle bei autonomen Fahrzeugen, also mögliche Szenarien mit geringer Eintrittswahrscheinlichkeit. Das wahrgenommene Long-Tail-Problem ist einer der Hauptgründe, die derzeit den betrieblichen Designbereich intelligenter autonomer Einzelfahrzeugfahrzeuge einschränken. Die zugrunde liegende Architektur und die meisten technischen Probleme des autonomen Fahrens wurden gelöst, und die verbleibenden 5 % der Long-Tail-Probleme wurden nach und nach zum Schlüssel zur Einschränkung der Entwicklung des autonomen Fahrens. Zu diesen Problemen gehören eine Vielzahl fragmentierter Szenarien, Extremsituationen und unvorhersehbares menschliches Verhalten. Der „Long Tail“ von Randszenarien beim autonomen Fahren bezieht sich auf Randfälle in autonomen Fahrzeugen (AVs). Randfälle sind mögliche Szenarien mit geringer Eintrittswahrscheinlichkeit. diese seltenen Ereignisse
 Kamera oder Lidar wählen? Eine aktuelle Übersicht über die Erzielung einer robusten 3D-Objekterkennung
Jan 26, 2024 am 11:18 AM
Kamera oder Lidar wählen? Eine aktuelle Übersicht über die Erzielung einer robusten 3D-Objekterkennung
Jan 26, 2024 am 11:18 AM
0. Vorab geschrieben&& Persönliches Verständnis, dass autonome Fahrsysteme auf fortschrittlichen Wahrnehmungs-, Entscheidungs- und Steuerungstechnologien beruhen, indem sie verschiedene Sensoren (wie Kameras, Lidar, Radar usw.) verwenden, um die Umgebung wahrzunehmen, und Algorithmen und Modelle verwenden für Echtzeitanalysen und Entscheidungsfindung. Dies ermöglicht es Fahrzeugen, Verkehrszeichen zu erkennen, andere Fahrzeuge zu erkennen und zu verfolgen, das Verhalten von Fußgängern vorherzusagen usw. und sich so sicher an komplexe Verkehrsumgebungen anzupassen. Diese Technologie erregt derzeit große Aufmerksamkeit und gilt als wichtiger Entwicklungsbereich für die Zukunft des Transportwesens . eins. Aber was autonomes Fahren schwierig macht, ist herauszufinden, wie man dem Auto klarmachen kann, was um es herum passiert. Dies erfordert, dass der dreidimensionale Objekterkennungsalgorithmus im autonomen Fahrsystem Objekte in der Umgebung, einschließlich ihrer Standorte, genau wahrnehmen und beschreiben kann.
 Das Stable Diffusion 3-Papier wird endlich veröffentlicht und die architektonischen Details werden enthüllt. Wird es helfen, Sora zu reproduzieren?
Mar 06, 2024 pm 05:34 PM
Das Stable Diffusion 3-Papier wird endlich veröffentlicht und die architektonischen Details werden enthüllt. Wird es helfen, Sora zu reproduzieren?
Mar 06, 2024 pm 05:34 PM
Der Artikel von StableDiffusion3 ist endlich da! Dieses Modell wurde vor zwei Wochen veröffentlicht und verwendet die gleiche DiT-Architektur (DiffusionTransformer) wie Sora. Nach seiner Veröffentlichung sorgte es für großes Aufsehen. Im Vergleich zur Vorgängerversion wurde die Qualität der von StableDiffusion3 generierten Bilder erheblich verbessert. Es unterstützt jetzt Eingabeaufforderungen mit mehreren Themen, und der Textschreibeffekt wurde ebenfalls verbessert, und es werden keine verstümmelten Zeichen mehr angezeigt. StabilityAI wies darauf hin, dass es sich bei StableDiffusion3 um eine Reihe von Modellen mit Parametergrößen von 800 M bis 8 B handelt. Durch diesen Parameterbereich kann das Modell direkt auf vielen tragbaren Geräten ausgeführt werden, wodurch der Einsatz von KI deutlich reduziert wird
 Beherrschen Sie die Koordinatensystemkonvertierung wirklich? Multisensorik-Themen, die für das autonome Fahren unverzichtbar sind
Oct 12, 2023 am 11:21 AM
Beherrschen Sie die Koordinatensystemkonvertierung wirklich? Multisensorik-Themen, die für das autonome Fahren unverzichtbar sind
Oct 12, 2023 am 11:21 AM
Der erste Pilot- und Schlüsselartikel stellt hauptsächlich mehrere häufig verwendete Koordinatensysteme in der autonomen Fahrtechnologie vor und erläutert, wie die Korrelation und Konvertierung zwischen ihnen abgeschlossen und schließlich ein einheitliches Umgebungsmodell erstellt werden kann. Der Schwerpunkt liegt hier auf dem Verständnis der Umrechnung vom Fahrzeug in den starren Kamerakörper (externe Parameter), der Kamera-in-Bild-Konvertierung (interne Parameter) und der Bild-in-Pixel-Einheitenkonvertierung. Die Konvertierung von 3D in 2D führt zu entsprechenden Verzerrungen, Verschiebungen usw. Wichtige Punkte: Das Fahrzeugkoordinatensystem und das Kamerakörperkoordinatensystem müssen neu geschrieben werden: Das Ebenenkoordinatensystem und das Pixelkoordinatensystem. Schwierigkeit: Sowohl die Entzerrung als auch die Verzerrungsaddition müssen auf der Bildebene kompensiert werden. 2. Einführung Insgesamt gibt es vier visuelle Systeme Koordinatensystem: Pixelebenenkoordinatensystem (u, v), Bildkoordinatensystem (x, y), Kamerakoordinatensystem () und Weltkoordinatensystem (). Es gibt eine Beziehung zwischen jedem Koordinatensystem,
 SIMPL: Ein einfacher und effizienter Multi-Agent-Benchmark zur Bewegungsvorhersage für autonomes Fahren
Feb 20, 2024 am 11:48 AM
SIMPL: Ein einfacher und effizienter Multi-Agent-Benchmark zur Bewegungsvorhersage für autonomes Fahren
Feb 20, 2024 am 11:48 AM
Originaltitel: SIMPL: ASimpleandEfficientMulti-agentMotionPredictionBaselineforAutonomousDriving Paper-Link: https://arxiv.org/pdf/2402.02519.pdf Code-Link: https://github.com/HKUST-Aerial-Robotics/SIMPL Autor: Hong Kong University of Science und Technologie DJI-Papieridee: Dieses Papier schlägt eine einfache und effiziente Bewegungsvorhersagebasislinie (SIMPL) für autonome Fahrzeuge vor. Im Vergleich zum herkömmlichen Agent-Cent
 Dieser Artikel reicht aus, um etwas über autonomes Fahren und Flugbahnvorhersage zu lesen!
Feb 28, 2024 pm 07:20 PM
Dieser Artikel reicht aus, um etwas über autonomes Fahren und Flugbahnvorhersage zu lesen!
Feb 28, 2024 pm 07:20 PM
Die Trajektorienvorhersage spielt eine wichtige Rolle beim autonomen Fahren. Unter autonomer Fahrtrajektorienvorhersage versteht man die Vorhersage der zukünftigen Fahrtrajektorie des Fahrzeugs durch die Analyse verschiedener Daten während des Fahrvorgangs. Als Kernmodul des autonomen Fahrens ist die Qualität der Trajektorienvorhersage von entscheidender Bedeutung für die nachgelagerte Planungssteuerung. Die Trajektorienvorhersageaufgabe verfügt über einen umfangreichen Technologie-Stack und erfordert Vertrautheit mit der dynamischen/statischen Wahrnehmung des autonomen Fahrens, hochpräzisen Karten, Fahrspurlinien, Fähigkeiten in der neuronalen Netzwerkarchitektur (CNN&GNN&Transformer) usw. Der Einstieg ist sehr schwierig! Viele Fans hoffen, so schnell wie möglich mit der Flugbahnvorhersage beginnen zu können und Fallstricke zu vermeiden. Heute werde ich eine Bestandsaufnahme einiger häufiger Probleme und einführender Lernmethoden für die Flugbahnvorhersage machen! Einführungsbezogenes Wissen 1. Sind die Vorschaupapiere in Ordnung? A: Schauen Sie sich zuerst die Umfrage an, S
 Sprechen wir über End-to-End- und autonome Fahrsysteme der nächsten Generation sowie über einige Missverständnisse über End-to-End-Autonomes Fahren?
Apr 15, 2024 pm 04:13 PM
Sprechen wir über End-to-End- und autonome Fahrsysteme der nächsten Generation sowie über einige Missverständnisse über End-to-End-Autonomes Fahren?
Apr 15, 2024 pm 04:13 PM
Im vergangenen Monat hatte ich aus bekannten Gründen einen sehr intensiven Austausch mit verschiedenen Lehrern und Mitschülern der Branche. Ein unvermeidliches Thema im Austausch ist natürlich End-to-End und der beliebte Tesla FSDV12. Ich möchte diese Gelegenheit nutzen, einige meiner aktuellen Gedanken und Meinungen als Referenz und Diskussion darzulegen. Wie definiert man ein durchgängiges autonomes Fahrsystem und welche Probleme sollten voraussichtlich durchgängig gelöst werden? Gemäß der traditionellsten Definition bezieht sich ein End-to-End-System auf ein System, das Rohinformationen von Sensoren eingibt und für die Aufgabe relevante Variablen direkt ausgibt. Bei der Bilderkennung kann CNN beispielsweise als End-to-End bezeichnet werden, verglichen mit der herkömmlichen Methode zum Extrahieren von Merkmalen + Klassifizieren. Bei autonomen Fahraufgaben werden Eingabedaten verschiedener Sensoren (Kamera/LiDAR) benötigt
