
 Technologie-Peripheriegeräte
KI
Vincents 3D-Modell-Durchbruch! MVDream kommt und generiert in einem Satz ultrarealistische 3D-Modelle
Technologie-Peripheriegeräte
KI
Vincents 3D-Modell-Durchbruch! MVDream kommt und generiert in einem Satz ultrarealistische 3D-Modelle
Vincents 3D-Modell-Durchbruch! MVDream kommt und generiert in einem Satz ultrarealistische 3D-Modelle

Das ist unglaublich!
Jetzt können Sie mit nur wenigen Worten ganz einfach schöne und hochwertige 3D-Modelle erstellen?
Nein, ein ausländischer Blog hat das Internet ins Leben gerufen und uns etwas namens MVDream präsentiert.
Benutzer können mit nur wenigen Worten ein lebensechtes 3D-Modell erstellen.

Und der Unterschied zu früher ist, dass MVDream die Physik wirklich zu „verstehen“ scheint.
Mal sehen, wie großartig dieser MVDream ist~
MVDream
Der kleine Bruder sagte, dass wir im Zeitalter großer Modelle zu viele Modelle zur Textgenerierung und Bildgenerierung gesehen haben. Und die Leistung dieser Modelle wird immer leistungsfähiger.
Später haben wir mit eigenen Augen die Geburt des Vincent-Videomodells und natürlich des 3D-Modells, das wir heute erwähnen werden, miterlebt
Stellen Sie sich vor, dass Sie durch einfaches Eintippen eines Satzes ein Objekt erzeugen können, das aussieht als ob es in der realen Welt existiert. Das Modell enthält sogar alle notwendigen Details, wie cool ist so eine Szene
Und das ist definitiv keine leichte Aufgabe, insbesondere wenn der Benutzer ein Modell mit genügend realistischen Details erstellen muss.
Werfen wir zunächst einen Blick auf den Effekt ~

Unter derselben Eingabeaufforderung wird ganz rechts das fertige Produkt von MVDream angezeigt.
Die Lücke zwischen den 5 Modelle sind mit bloßem Auge sichtbar. Die ersten Modelle verstoßen völlig gegen die objektiven Fakten und sind nur aus bestimmten Blickwinkeln korrekt.
Auf den ersten vier Bildern hat das generierte Modell beispielsweise tatsächlich mehr als zwei Ohren. Obwohl das vierte Bild detaillierter aussieht, können wir bei Drehung in einem bestimmten Winkel feststellen, dass das Gesicht der Figur konkav ist und ein Ohr darauf steckt.
Wer weiß? Der Redakteur erinnerte sich sofort an die Frontansicht von Peppa Pig, die zuvor sehr beliebt war.

Dies ist eine Situation, die Ihnen aus einigen Blickwinkeln gezeigt wird, aber aus anderen Blickwinkeln darf sie nicht betrachtet werden, es wird lebensgefährlich sein
Das generierte Modell von MVDream ganz rechts ist offensichtlich nicht das Gleiche. Egal wie das 3D-Modell gedreht wird, Sie werden nichts Ungewöhnliches spüren.
Das wurde bereits erwähnt. MVDream kennt sich mit den physikalischen Kenntnissen gut aus und wird keine seltsamen Dinge erstellen, um sicherzustellen, dass jede Ansicht zwei Ohren hat.
Der kleine Bruder wies darauf hin, dass die Beurteilung eines 3D-Modells der Schlüssel zum Erfolg ist besteht darin, zu beobachten, ob die verschiedenen Perspektiven realistisch und von hoher Qualität sind
, und außerdem sicherzustellen, dass das Modell räumlich kohärent ist, nicht wie das Modell mit mehreren Ohren oben.
Eine der Hauptmethoden zur Generierung von 3D-Modellen besteht darin, die Kameraperspektive zu simulieren und dann zu generieren, was aus einer bestimmten Perspektive zu sehen ist.
Mit anderen Worten nennt man das 2D-Lifting. Dabei werden verschiedene Perspektiven zusammengefügt, um das endgültige 3D-Modell zu erstellen.
Die obige Situation mit mehreren Ohren tritt auf, weil das generative Modell die Forminformationen des gesamten Objekts im dreidimensionalen Raum nicht vollständig erfasst. Und MVDream ist in dieser Hinsicht einfach ein großer Schritt nach vorne.
Dieses neue Modell löst das bisherige Konsistenzproblem in der 3D-Perspektive
Fraktionierte Destillationsstichprobe
Diese Methode wird als Score-Destillation-Stichprobe bezeichnet und wurde von DreamFusion The
Bevor Sie mit dem Erlernen der fraktionierten Destillation beginnen Bei der Sampling-Technik müssen wir zunächst die von dieser Methode verwendete Architektur verstehen
Mit anderen Worten, dies ist eigentlich nur ein weiteres zweidimensionales Bilddiffusionsmodell, ähnlich den Modellen DALLE, MidJourney und Stable Diffusion
Genauer gesagt, alles beginnt mit dem vorab trainierten DreamBooth-Modell, einem Open-Source-Modell, das auf Stable Diffusion-Rohdiagrammen basiert.
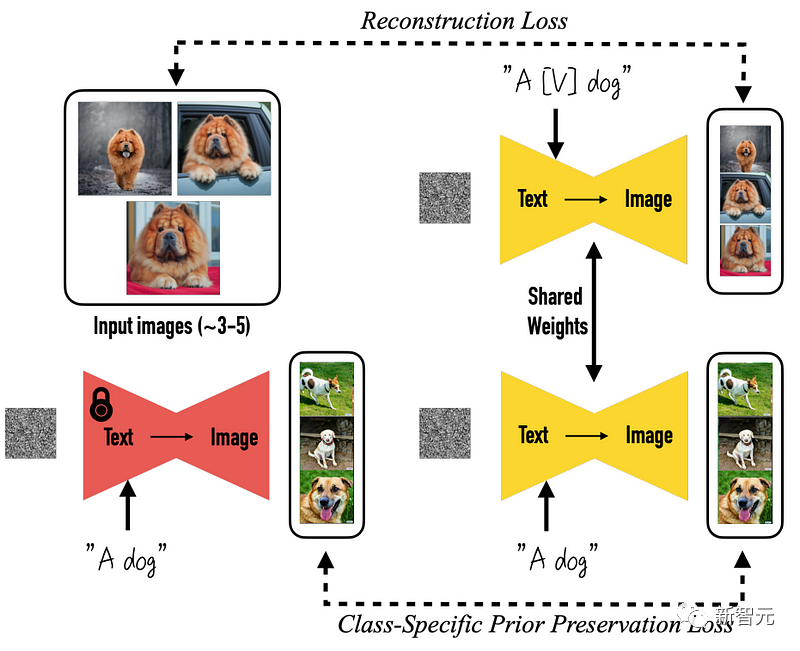
Die Veränderung steht vor der Tür, was bedeutet, dass sich die Dinge geändert haben
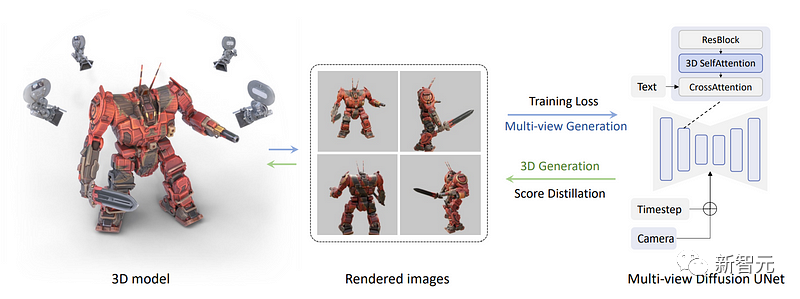
Als nächstes hat das Forschungsteam einen Satz von Bildern mit mehreren Ansichten direkt gerendert, anstatt nur ein Bild zu rendern. Für diesen Schritt sind drei erforderlich. Dimensionsdatensätze verschiedener Objekte können vervollständigt werden.
Hier haben Forscher mehrere Ansichten eines 3D-Objekts aus einem Datensatz entnommen, sie zum Trainieren eines Modells verwendet und es dann verwendet, um diese Ansichten rückwärts zu generieren.
Die spezifische Methode besteht darin, den blauen Selbstaufmerksamkeitsblock im Bild unten in einen dreidimensionalen Selbstaufmerksamkeitsblock umzuwandeln. Das heißt, die Forscher müssen nur eine Dimension hinzufügen, um mehrere Bilder anstelle eines zu rekonstruieren Bild.
Im Bild unten können wir sehen, dass die Kamera und der Zeitschritt für jede Ansicht in das Modell eingegeben werden, um dem Modell zu helfen, zu verstehen, welches Bild wo verwendet wird und welche Art von Ansicht generiert werden muss
Jetzt sind alle Bilder miteinander verbunden und die Generierung erfolgt auch gemeinsam. So können sie Informationen austauschen und das Gesamtbild besser verstehen.
Zuerst wird Text in das Modell eingespeist, das dann darauf trainiert wird, Objekte aus dem Datensatz genau zu rekonstruieren.
Und hier wendete das Forschungsteam das Verfahren der fraktionierten Destillation mit mehreren Ansichten an.
Jetzt kann das Team mit einem Multi-View-Diffusionsmodell mehrere Ansichten eines Objekts generieren.
Als nächstes müssen wir diese Ansichten verwenden, um ein dreidimensionales Modell zu rekonstruieren, das mit der realen Welt und nicht nur mit Ansichten übereinstimmt.
Hier müssen wir NeRF (neuronale Strahlungsfelder, neuronale Strahlungsfelder) verwenden erreichen, wie das zuvor erwähnte DreamFusion.
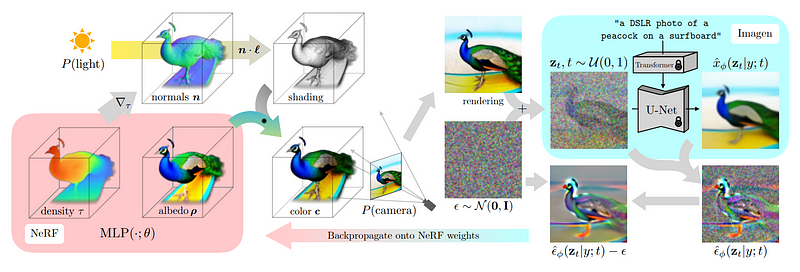
In diesem Schritt ist es unser Ziel, das zuvor trainierte Multi-View-Diffusionsmodell einzufrieren. Mit anderen Worten, wir verwenden in diesem Schritt einfach die Bilder aus jeder Perspektive oben und trainieren nicht mehr
Basierend auf dem anfänglichen Rendering begannen die Forscher, ein Multi-View-Diffusionsmodell zu verwenden, um einige verrauschte anfängliche Bildversionen zu generieren
Damit das Modell versteht, dass verschiedene Versionen des Bildes generiert werden müssen, fügten die Forscher Rauschen hinzu und konnten dennoch Hintergrundinformationen erhalten
Als nächstes kann dieses Modell verwendet werden, um weitere Bilder mit höherer Qualität zu generieren
Fügen Sie das Bild hinzu, mit dem dieses Bild erstellt wurde, und entfernen Sie das Rauschen, das wir manuell hinzugefügt haben, damit die Ergebnisse im nächsten Schritt als Leitfaden und Verbesserung des NeRF-Modells verwendet werden können.
Um im nächsten Schritt bessere Ergebnisse zu erzielen, besteht der Zweck dieser Schritte darin, besser zu verstehen, auf welchen Teil des Bildes sich das NeRF-Modell konzentrieren sollte
Wiederholen Sie diesen Vorgang so lange, bis ein zufriedenstellendes 3D-Modell erstellt wurde
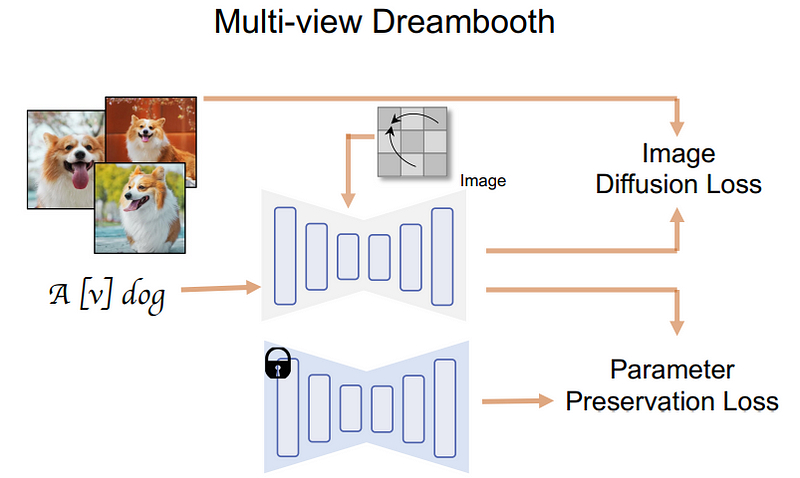
Was die Bewertung der Bilderzeugungsqualität des Multi-View-Diffusionsmodells und die Beurteilung, wie sich unterschiedliche Designs auf seine Leistung auswirken, angeht, so arbeitet das Team folgendermaßen.
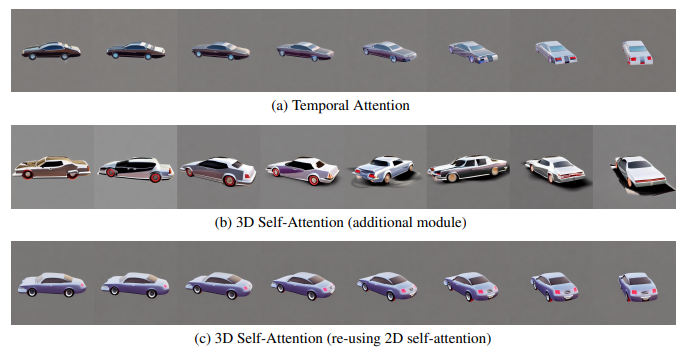
Zunächst verglichen sie die Auswahl von Aufmerksamkeitsmodulen zur Erstellung von Cross-View-Konsistenzmodellen.
Diese Optionen umfassen:
(1) Eindimensionale zeitliche Selbstaufmerksamkeit, die häufig in Videodiffusionsmodellen verwendet wird;
(2) Hinzufügen eines neuen dreidimensionalen Selbstaufmerksamkeitsmoduls zu bestehenden Modellen;
(3) Verwenden Sie das vorhandene 2D-Selbstaufmerksamkeitsmodul für 3D-Aufmerksamkeit wieder.
Um die Unterschiede zwischen diesen Modulen genau zu demonstrieren, verwendeten die Forscher in diesem Experiment 8 Frames mit 90-Grad-Perspektivwechseln, um das Modell so zu trainieren, dass es den Videoeinstellungen besser entspricht.
Im Experiment hat das Forschungsteam Gleichzeitig bleibt die höhere Bildauflösung erhalten, also 512×512 als beim ursprünglichen SD-Modell. Wie in der folgenden Abbildung dargestellt, stellten die Forscher fest, dass die zeitliche Selbstaufmerksamkeit selbst bei solch begrenzten Perspektivwechseln in statischen Szenen immer noch durch Inhaltsverschiebungen beeinträchtigt wird und die perspektivische Konsistenz nicht aufrechterhalten kann
Das Team geht davon aus, dass dies daran liegt, dass die zeitliche Aufmerksamkeit dies kann Tauschen Sie nur Informationen zwischen denselben Pixeln in verschiedenen Frames aus. Wenn sich der Blickwinkel ändert, können die entsprechenden Pixel weit voneinander entfernt sein.
Andererseits kann das Hinzufügen neuer 3D-Aufmerksamkeit ohne Erlernen der Konsistenz zu erheblichen Qualitätsverlusten führen.
Die Forscher glauben, dass dies daran liegt, dass das Erlernen neuer Parameter von Grund auf mehr Trainingsdaten und Zeit verbraucht, was auf diese Situation, in der das dreidimensionale Modell begrenzt ist, nicht anwendbar ist. Sie schlugen eine Strategie zur Wiederverwendung des 2D-Selbstaufmerksamkeitsmechanismus vor, um eine optimale Konsistenz zu erreichen, ohne die Generierungsqualität zu beeinträchtigen
Das Team stellte außerdem fest, dass bei einer Reduzierung der Bildgröße auf 256 die Anzahl der Ansichten auf 4 reduziert wird. Die Unterschiede zwischen diesen Modulen wird viel kleiner sein. Um jedoch die beste Konsistenz zu erreichen, trafen die Forscher ihre Auswahl auf der Grundlage vorläufiger Beobachtungen in den folgenden Experimenten.
Darüber hinaus implementierten die Forscher die fraktionierte Destillationsprobenahme mit mehreren Ansichten in der Bibliothek von threestudio (thr) und führten eine Diffusionsführung mit mehreren Ansichten ein. Diese Bibliothek implementiert modernste Methoden zur Generierung von Text-zu-3D-Modellen unter einem einheitlichen Framework -Gitter)
Bei der Untersuchung der Kameraansicht haben die Forscher die Kamera auf genau die gleiche Weise abgetastet wie beim Rendern des 3D-Datensatzes
Darüber hinaus haben die Forscher das 3D-Modell auch für 10.000 Schritte optimiert Der AdamW-Optimierer und die Einstellung der Lernrate auf 0,01 Das Rendering beträgt 64 × 64 und erhöht sich nach 5000 Schritten schrittweise auf 256 × 256. Die folgenden Fälle sind weitere: Synthese und durch einen iterativen Prozess eine Text-zu-3D-Modellmethode erstellt
Diese neue Methode weist derzeit einige Einschränkungen auf. Das Hauptproblem besteht darin, dass die Auflösung des generierten Bildes nur 256 x 256 Pixel beträgt sehr niedrig
Darüber hinaus wiesen die Forscher auch darauf hin, dass die Größe des Datensatzes zur Ausführung dieser Aufgabe die Vielseitigkeit dieser Methode in gewissem Maße einschränken muss, denn Wenn der Datensatz zu klein ist, ist dies nicht möglich um unsere komplexe Welt realistischer abzubilden.
Das obige ist der detaillierte Inhalt vonVincents 3D-Modell-Durchbruch! MVDream kommt und generiert in einem Satz ultrarealistische 3D-Modelle. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 Verwenden Sie ddrescue, um Daten unter Linux wiederherzustellen
Mar 20, 2024 pm 01:37 PM
Verwenden Sie ddrescue, um Daten unter Linux wiederherzustellen
Mar 20, 2024 pm 01:37 PM
DDREASE ist ein Tool zum Wiederherstellen von Daten von Datei- oder Blockgeräten wie Festplatten, SSDs, RAM-Disks, CDs, DVDs und USB-Speichergeräten. Es kopiert Daten von einem Blockgerät auf ein anderes, wobei beschädigte Blöcke zurückbleiben und nur gute Blöcke verschoben werden. ddreasue ist ein leistungsstarkes Wiederherstellungstool, das vollständig automatisiert ist, da es während der Wiederherstellungsvorgänge keine Unterbrechungen erfordert. Darüber hinaus kann es dank der ddasue-Map-Datei jederzeit gestoppt und fortgesetzt werden. Weitere wichtige Funktionen von DDREASE sind: Es überschreibt die wiederhergestellten Daten nicht, füllt aber die Lücken im Falle einer iterativen Wiederherstellung. Es kann jedoch gekürzt werden, wenn das Tool explizit dazu aufgefordert wird. Stellen Sie Daten aus mehreren Dateien oder Blöcken in einer einzigen wieder her
 Open Source! Jenseits von ZoeDepth! DepthFM: Schnelle und genaue monokulare Tiefenschätzung!
Apr 03, 2024 pm 12:04 PM
Open Source! Jenseits von ZoeDepth! DepthFM: Schnelle und genaue monokulare Tiefenschätzung!
Apr 03, 2024 pm 12:04 PM
0.Was bewirkt dieser Artikel? Wir schlagen DepthFM vor: ein vielseitiges und schnelles generatives monokulares Tiefenschätzungsmodell auf dem neuesten Stand der Technik. Zusätzlich zu herkömmlichen Tiefenschätzungsaufgaben demonstriert DepthFM auch hochmoderne Fähigkeiten bei nachgelagerten Aufgaben wie dem Tiefen-Inpainting. DepthFM ist effizient und kann Tiefenkarten innerhalb weniger Inferenzschritte synthetisieren. Lassen Sie uns diese Arbeit gemeinsam lesen ~ 1. Titel der Papierinformationen: DepthFM: FastMonocularDepthEstimationwithFlowMatching Autor: MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Die von Google geförderte Leistung von JAX hat in jüngsten Benchmark-Tests die von Pytorch und TensorFlow übertroffen und belegt bei 7 Indikatoren den ersten Platz. Und der Test wurde nicht auf der TPU mit der besten JAX-Leistung durchgeführt. Obwohl unter Entwicklern Pytorch immer noch beliebter ist als Tensorflow. Aber in Zukunft werden möglicherweise mehr große Modelle auf Basis der JAX-Plattform trainiert und ausgeführt. Modelle Kürzlich hat das Keras-Team drei Backends (TensorFlow, JAX, PyTorch) mit der nativen PyTorch-Implementierung und Keras2 mit TensorFlow verglichen. Zunächst wählen sie eine Reihe von Mainstream-Inhalten aus
 Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas tritt offiziell in die Ära der Elektroroboter ein! Gestern hat sich der hydraulische Atlas einfach „unter Tränen“ von der Bühne der Geschichte zurückgezogen. Heute gab Boston Dynamics bekannt, dass der elektrische Atlas im Einsatz ist. Es scheint, dass Boston Dynamics im Bereich kommerzieller humanoider Roboter entschlossen ist, mit Tesla zu konkurrieren. Nach der Veröffentlichung des neuen Videos wurde es innerhalb von nur zehn Stunden bereits von mehr als einer Million Menschen angesehen. Die alten Leute gehen und neue Rollen entstehen. Das ist eine historische Notwendigkeit. Es besteht kein Zweifel, dass dieses Jahr das explosive Jahr der humanoiden Roboter ist. Netizens kommentierten: Die Weiterentwicklung der Roboter hat dazu geführt, dass die diesjährige Eröffnungsfeier wie Menschen aussieht, und der Freiheitsgrad ist weitaus größer als der von Menschen. Aber ist das wirklich kein Horrorfilm? Zu Beginn des Videos liegt Atlas ruhig auf dem Boden, scheinbar auf dem Rücken. Was folgt, ist atemberaubend
 Langsame Internetgeschwindigkeiten für Mobilfunkdaten auf dem iPhone: Korrekturen
May 03, 2024 pm 09:01 PM
Langsame Internetgeschwindigkeiten für Mobilfunkdaten auf dem iPhone: Korrekturen
May 03, 2024 pm 09:01 PM
Stehen Sie vor einer Verzögerung oder einer langsamen mobilen Datenverbindung auf dem iPhone? Normalerweise hängt die Stärke des Mobilfunk-Internets auf Ihrem Telefon von mehreren Faktoren ab, wie z. B. der Region, dem Mobilfunknetztyp, dem Roaming-Typ usw. Es gibt einige Dinge, die Sie tun können, um eine schnellere und zuverlässigere Mobilfunk-Internetverbindung zu erhalten. Fix 1 – Neustart des iPhone erzwingen Manchmal werden durch einen erzwungenen Neustart Ihres Geräts viele Dinge zurückgesetzt, einschließlich der Mobilfunkverbindung. Schritt 1 – Drücken Sie einfach einmal die Lauter-Taste und lassen Sie sie los. Drücken Sie anschließend die Leiser-Taste und lassen Sie sie wieder los. Schritt 2 – Der nächste Teil des Prozesses besteht darin, die Taste auf der rechten Seite gedrückt zu halten. Lassen Sie das iPhone den Neustart abschließen. Aktivieren Sie Mobilfunkdaten und überprüfen Sie die Netzwerkgeschwindigkeit. Überprüfen Sie es erneut. Fix 2 – Datenmodus ändern 5G bietet zwar bessere Netzwerkgeschwindigkeiten, funktioniert jedoch besser, wenn das Signal schwächer ist
 Die Kuaishou-Version von Sora „Ke Ling' steht zum Testen offen: Sie generiert über 120 Sekunden Videos, versteht die Physik besser und kann komplexe Bewegungen genau modellieren
Jun 11, 2024 am 09:51 AM
Die Kuaishou-Version von Sora „Ke Ling' steht zum Testen offen: Sie generiert über 120 Sekunden Videos, versteht die Physik besser und kann komplexe Bewegungen genau modellieren
Jun 11, 2024 am 09:51 AM
Was? Wird Zootopia durch heimische KI in die Realität umgesetzt? Zusammen mit dem Video wird ein neues groß angelegtes inländisches Videogenerationsmodell namens „Keling“ vorgestellt. Sora geht einen ähnlichen technischen Weg und kombiniert eine Reihe selbst entwickelter technologischer Innovationen, um Videos zu produzieren, die nicht nur große und vernünftige Bewegungen aufweisen, sondern auch die Eigenschaften der physischen Welt simulieren und über starke konzeptionelle Kombinationsfähigkeiten und Vorstellungskraft verfügen. Den Daten zufolge unterstützt Keling die Erstellung ultralanger Videos von bis zu 2 Minuten mit 30 Bildern pro Sekunde, mit Auflösungen von bis zu 1080p und unterstützt mehrere Seitenverhältnisse. Ein weiterer wichtiger Punkt ist, dass es sich bei Keling nicht um eine vom Labor veröffentlichte Demo oder Video-Ergebnisdemonstration handelt, sondern um eine Anwendung auf Produktebene, die von Kuaishou, einem führenden Anbieter im Bereich Kurzvideos, gestartet wurde. Darüber hinaus liegt das Hauptaugenmerk darauf, pragmatisch zu sein, keine Blankoschecks auszustellen und sofort nach der Veröffentlichung online zu gehen. Das große Modell von Ke Ling wurde bereits in Kuaiying veröffentlicht.
 Die Vitalität der Superintelligenz erwacht! Aber mit der Einführung der sich selbst aktualisierenden KI müssen sich Mütter keine Sorgen mehr über Datenengpässe machen
Apr 29, 2024 pm 06:55 PM
Die Vitalität der Superintelligenz erwacht! Aber mit der Einführung der sich selbst aktualisierenden KI müssen sich Mütter keine Sorgen mehr über Datenengpässe machen
Apr 29, 2024 pm 06:55 PM
Ich weine zu Tode. Die Daten im Internet reichen überhaupt nicht aus. Das Trainingsmodell sieht aus wie „Die Tribute von Panem“, und KI-Forscher auf der ganzen Welt machen sich Gedanken darüber, wie sie diese datenhungrigen Esser ernähren sollen. Dieses Problem tritt insbesondere bei multimodalen Aufgaben auf. Zu einer Zeit, als sie ratlos waren, nutzte ein Start-up-Team der Abteilung der Renmin-Universität von China sein eigenes neues Modell, um als erstes in China einen „modellgenerierten Datenfeed selbst“ in die Realität umzusetzen. Darüber hinaus handelt es sich um einen zweigleisigen Ansatz auf der Verständnisseite und der Generierungsseite. Beide Seiten können hochwertige, multimodale neue Daten generieren und Datenrückmeldungen an das Modell selbst liefern. Was ist ein Modell? Awaker 1.0, ein großes multimodales Modell, das gerade im Zhongguancun-Forum erschienen ist. Wer ist das Team? Sophon-Motor. Gegründet von Gao Yizhao, einem Doktoranden an der Hillhouse School of Artificial Intelligence der Renmin University.
 Die U.S. Air Force präsentiert ihren ersten KI-Kampfjet mit großem Aufsehen! Der Minister führte die Testfahrt persönlich durch, ohne in den gesamten Prozess einzugreifen, und 100.000 Codezeilen wurden 21 Mal getestet.
May 07, 2024 pm 05:00 PM
Die U.S. Air Force präsentiert ihren ersten KI-Kampfjet mit großem Aufsehen! Der Minister führte die Testfahrt persönlich durch, ohne in den gesamten Prozess einzugreifen, und 100.000 Codezeilen wurden 21 Mal getestet.
May 07, 2024 pm 05:00 PM
Kürzlich wurde die Militärwelt von der Nachricht überwältigt: US-Militärkampfflugzeuge können jetzt mithilfe von KI vollautomatische Luftkämpfe absolvieren. Ja, erst kürzlich wurde der KI-Kampfjet des US-Militärs zum ersten Mal der Öffentlichkeit zugänglich gemacht und sein Geheimnis gelüftet. Der vollständige Name dieses Jägers lautet „Variable Stability Simulator Test Aircraft“ (VISTA). Er wurde vom Minister der US-Luftwaffe persönlich geflogen, um einen Eins-gegen-eins-Luftkampf zu simulieren. Am 2. Mai startete US-Luftwaffenminister Frank Kendall mit einer X-62AVISTA auf der Edwards Air Force Base. Beachten Sie, dass während des einstündigen Fluges alle Flugaktionen autonom von der KI durchgeführt wurden! Kendall sagte: „In den letzten Jahrzehnten haben wir über das unbegrenzte Potenzial des autonomen Luft-Luft-Kampfes nachgedacht, aber es schien immer unerreichbar.“ Nun jedoch,
