
 Technologie-Peripheriegeräte
KI
MiniGPT-5, das Bild- und Textgenerierung vereinheitlicht, ist da: Aus Token wird Voken, und das Modell kann nicht nur weiterschreiben, sondern auch automatisch Bilder hinzufügen.
Technologie-Peripheriegeräte
KI
MiniGPT-5, das Bild- und Textgenerierung vereinheitlicht, ist da: Aus Token wird Voken, und das Modell kann nicht nur weiterschreiben, sondern auch automatisch Bilder hinzufügen.
MiniGPT-5, das Bild- und Textgenerierung vereinheitlicht, ist da: Aus Token wird Voken, und das Modell kann nicht nur weiterschreiben, sondern auch automatisch Bilder hinzufügen.

Großformatige Modelle schaffen den Sprung zwischen Sprache und Vision und versprechen, Text- und Bildinhalte nahtlos zu verstehen und zu generieren. Einer Reihe aktueller Studien zufolge ist die Integration multimodaler Funktionen nicht nur ein wachsender Trend, sondern hat bereits zu wichtigen Fortschritten geführt, die von multimodalen Gesprächen bis hin zu Tools zur Inhaltserstellung reichen. Große Sprachmodelle haben beispiellose Fähigkeiten beim Verstehen und Generieren von Texten gezeigt. Die gleichzeitige Generierung von Bildern mit kohärenten Texterzählungen ist jedoch noch ein Bereich, der noch entwickelt werden muss
Kürzlich hat ein Forschungsteam der University of California, Santa Cruz, MiniGPT-5 vorgeschlagen, das auf dem innovativen Konzept der „generativen Abstimmung“ basiert Technologie zur Erzeugung verschachtelter visueller Sprache.

- Papieradresse: https://browse.arxiv.org/pdf/2310.02239v1.pdf
- Projektadresse: https://github.com/eric- ai-lab/MiniGPT-5
Durch die Kombination eines stabilen Diffusionsmechanismus mit LLM durch ein spezielles visuelles Token „generative Abstimmung“ läutet MiniGPT-5 einen neuen Weg für ein kompetentes multimodales Generationsmodell ein. Gleichzeitig betont die in diesem Artikel vorgeschlagene zweistufige Trainingsmethode die Bedeutung der beschreibungsfreien Grundphase, damit das Modell auch bei knappen Daten erfolgreich sein kann. Die allgemeine Phase der Methode erfordert keine domänenspezifischen Anmerkungen, wodurch sich unsere Lösung von bestehenden Methoden unterscheidet. Um sicherzustellen, dass der generierte Text und die Bilder harmonisch sind, kommt die Doppelverluststrategie dieses Artikels ins Spiel, die durch die generative Abstimmungsmethode und die Klassifizierungsmethode weiter verbessert wird
Basierend auf diesen Techniken markiert diese Arbeit a Transformativer Ansatz. Mithilfe von ViT (Vision Transformer) und Qformer sowie einem großen Sprachmodell wandelt das Forschungsteam multimodale Eingaben in generative Abstimmungen um und kombiniert sie nahtlos mit der hochauflösenden Stable Diffusion2.1, um eine kontextbewusste Bildgenerierung zu erreichen. Dieses Papier kombiniert Bilder als Hilfseingabe mit Methoden zur Befehlsanpassung und leistet Pionierarbeit bei der Verwendung von Text- und Bildgenerierungsverlusten, wodurch die Synergie zwischen Text und Vision erweitert wird. MiniGPT-5 passt Modelle wie CLIP-Einschränkungen an und kombiniert das Diffusionsmodell geschickt mit MiniGPT-4 erzielt bessere multimodale Ergebnisse, ohne auf domänenspezifische Annotationen angewiesen zu sein. Am wichtigsten ist, dass unsere Strategie Fortschritte in den zugrunde liegenden Modellen multimodaler visueller Sprache nutzen kann, um einen neuen Entwurf für die Verbesserung multimodaler generativer Fähigkeiten bereitzustellen.
Wie in der folgenden Abbildung gezeigt, kann MiniGPT5 zusätzlich zu den ursprünglichen multimodalen Verständnis- und Textgenerierungsfunktionen auch eine vernünftige und kohärente multimodale Ausgabe bereitstellen:
Der Beitrag dieses Artikels ist spiegelt sich in drei Aspekten wider: 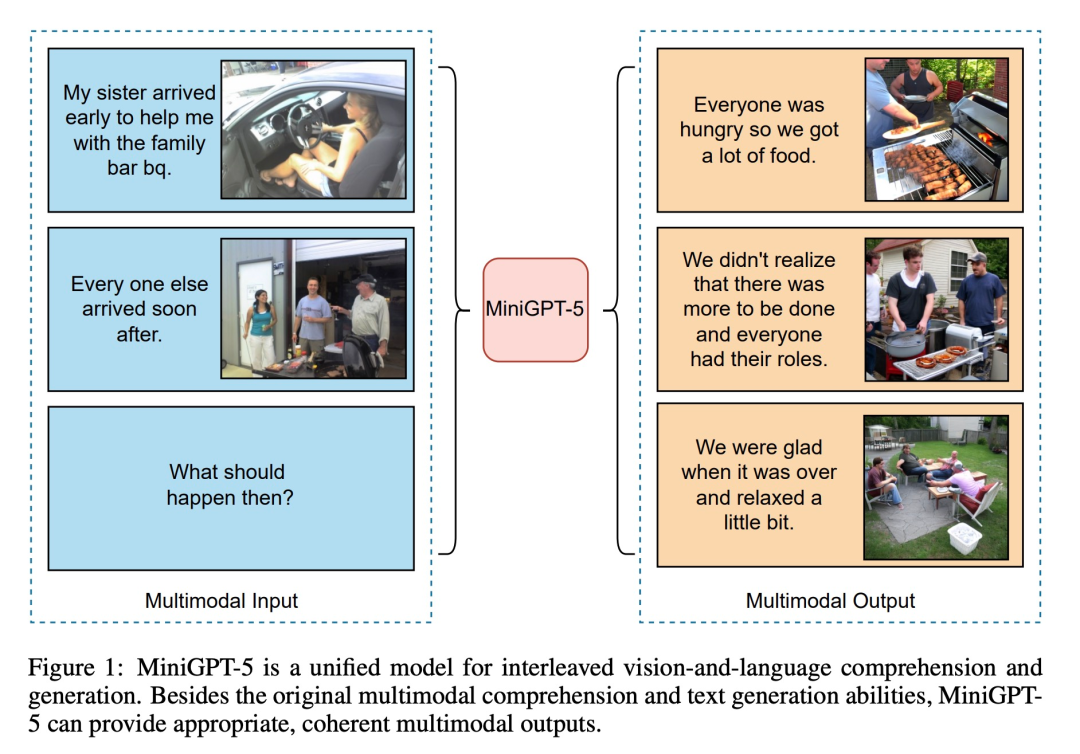
Es wird vorgeschlagen, einen multimodalen Encoder zu verwenden, der eine neuartige allgemeine Technik darstellt und sich als effektiver als LLM und inverse generative Vokens erwiesen hat, und ihn mit stabiler Diffusion zu kombinieren, um Interleaved zu erzeugen visuelle und sprachliche Ausgabe (ein multimodales Sprachmodell, das multimodal generiert werden kann).
- hebt eine neue zweistufige Trainingsstrategie für die beschreibungsfreie multimodale Generierung hervor. Die Single-Modal-Alignment-Stufe erhält qualitativ hochwertige textausgerichtete visuelle Merkmale aus einer großen Anzahl von Text-Bild-Paaren. Die multimodale Lernphase umfasst eine neuartige Trainingsaufgabe und die Generierung von Aufforderungskontexten, um sicherzustellen, dass visuelle und textliche Aufforderungen gut koordiniert und generiert werden. Durch das Hinzufügen einer klassifikatorfreien Anleitung während der Trainingsphase wird die Generierungsqualität weiter verbessert.
- Im Vergleich zu anderen multimodalen generativen Modellen erreicht MiniGPT-5 beim CC3M-Datensatz eine Spitzenleistung. MiniGPT-5 setzt auch neue Maßstäbe für bekannte Datensätze wie VIST und MMDialog.
- Lassen Sie uns nun den Inhalt dieser Forschung im Detail verstehen.
Übersicht über die Methode Vorab trainierte multimodale groß angelegte Sprachmodelle und Text-zu-Bild-Generierungsmodelle sind integriert. Um die Unterschiede zwischen verschiedenen Modellfeldern zu lösen, führten sie spezielle visuelle Symbole „generative Stimmen“ ein, die direkt auf den Originalbildern trainiert werden können. Darüber hinaus wird eine zweistufige Trainingsmethode in Kombination mit einer klassifikatorfreien Bootstrapping-Strategie weiterentwickelt, um die Generierungsqualität weiter zu verbessern.
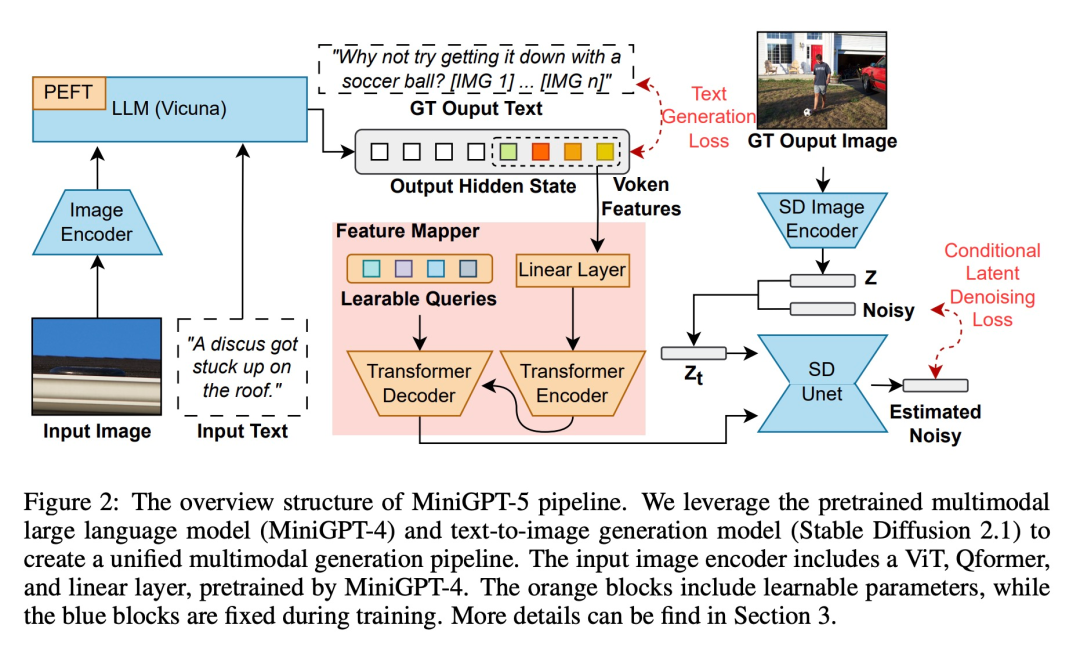
Multimodale Eingabephase
Jüngste Fortschritte bei großen multimodalen Modellen (wie MiniGPT-4) konzentrieren sich hauptsächlich auf das multimodale Verständnis und die Fähigkeit, Bilder als kontinuierliche Eingaben zu verarbeiten. Um seine Fähigkeiten auf die multimodale Generierung zu erweitern, führten die Forscher generative Vokens ein, die speziell für die Ausgabe visueller Merkmale entwickelt wurden. Darüber hinaus haben sie auch eine Parameter-effiziente Feinabstimmungstechnologie im Rahmen des Large Language Model (LLM) für multimodales Output-Lernen übernommen Token ist Um eine präzise Ausrichtung der Modelle zu erzeugen, entwickelten die Forscher ein kompaktes Zuordnungsmodul für den Dimensionsabgleich und führten mehrere überwachte Verluste ein, darunter Textraumverlust und latente Diffusionsmodellverluste. Der Textraumverlust hilft dem Modell, die Position von Token genau zu lernen, während der latente Diffusionsverlust Token direkt an geeigneten visuellen Merkmalen ausrichtet. Da die Merkmale generativer Symbole direkt durch Bilder gesteuert werden, erfordert diese Methode keine vollständige Bildbeschreibung und ermöglicht ein beschreibungsfreies Lernen Durch die Verschiebung der Textdomäne und der Bilddomäne fanden Forscher heraus, dass das Training direkt an einem begrenzten verschachtelten Text- und Bilddatensatz zu einer Fehlausrichtung und einer Verschlechterung der Bildqualität führen kann.
Also nutzten sie zwei unterschiedliche Trainingsstrategien, um dieses Problem zu mildern. Die erste Strategie beinhaltet den Einsatz klassifikatorfreier Bootstrapping-Techniken, um die Wirksamkeit der generierten Token während des gesamten Diffusionsprozesses zu verbessern. Die zweite Strategie gliedert sich in zwei Phasen: eine anfängliche Vortrainingsphase, die sich auf die grobe Merkmalsausrichtung konzentriert, gefolgt von einer Feinabstimmungsphase zum Thema komplexes Feature-Learning.
Experimente und ErgebnisseUm die Wirksamkeit des Modells zu bewerten, wählten die Forscher mehrere Benchmarks aus und führten eine Reihe von Bewertungen durch. Der Zweck des Experiments besteht darin, mehrere Schlüsselfragen zu beantworten: Kann
MiniGPT-5 glaubwürdige Bilder und vernünftigen Text erzeugen?
Wie schneidet MiniGPT-5 im Vergleich zu anderen SOTA-Modellen bei ein- und mehrrundigen verschachtelten visuellen Sprachgenerierungsaufgaben ab?
Welche Auswirkungen hat das Design jedes Moduls auf die Gesamtleistung?
Um die Leistung des MiniGPT-5-Modells in verschiedenen Trainingsphasen zu bewerten, haben wir eine quantitative Analyse durchgeführt. Die Ergebnisse sind in Abbildung 3 dargestellt:
- Um die Vielseitigkeit und Robustheit zu demonstrieren Wir haben das vorgeschlagene Modell evaluiert und dabei sowohl visuelle (bildbezogene Metriken) als auch sprachliche (Textmetriken) Domänen abgedeckt. SchrittauswertungDas heißt, im letzten Schritt wird das entsprechende Bild gemäß dem Eingabeaufforderungsmodell generiert und die Ergebnisse sind in Tabelle 1 aufgeführt.
- MiniGPT-5 übertrifft den fein abgestimmten SD 2 in allen drei Einstellungen. Bemerkenswert ist, dass der CLIP-Score des MiniGPT-5 (LoRA)-Modells andere Varianten bei mehreren Eingabeaufforderungstypen durchweg übertrifft, insbesondere bei der Kombination von Bild- und Texteingabeaufforderungen. Andererseits unterstreicht der FID-Score die Wettbewerbsfähigkeit des MiniGPT-5-Modells (Präfix), was darauf hindeutet, dass es möglicherweise einen Kompromiss zwischen der Bildeinbettungsqualität (dargestellt durch den CLIP-Score) und der Bildvielfalt und -authentizität (dargestellt durch) gibt FID-Score). Im Vergleich zu einem Modell, das direkt auf VIST trainiert wurde, ohne eine Einzelmodalitätsregistrierungsphase einzuschließen (MiniGPT-5 ohne UAS), sind die Bildqualität und -konsistenz erheblich verringert, obwohl das Modell die Fähigkeit behält, aussagekräftige Bilder zu erzeugen. Diese Beobachtung unterstreicht die Bedeutung der zweistufigen Trainingsstrategie Kontext, und die resultierenden Bilder und Erzählungen werden anschließend bei jedem Schritt bewertet.
Tabelle 2 und Tabelle 3 fassen die Ergebnisse dieser Experimente zusammen und bieten einen Überblick über die Leistung bei Bild- bzw. Sprachmetriken. Experimentelle Ergebnisse zeigen, dass MiniGPT-5 in der Lage ist, multimodale Eingabehinweise auf langer Ebene zu nutzen, um kohärente, qualitativ hochwertige Bilder über alle Daten hinweg zu erzeugen, ohne die multimodalen Verständnisfähigkeiten des Originalmodells zu beeinträchtigen. Dies unterstreicht die Wirksamkeit von MiniGPT-5 in verschiedenen Umgebungen 0,18 % generierten mehr Relevanz Texterzählungen in 52,06 % der Fälle, eine bessere Bildqualität in 52,06 % der Fälle und eine kohärentere multimodale Ausgabe in 57,62 % der Szenen. Verglichen mit einer zweistufigen Basislinie, die eine Text-zu-Bild-Erzählung ohne Konjunktivstimmung anwendet, zeigen diese Daten deutlich die stärkeren Fähigkeiten zur multimodalen Generierung.
 MMDialog Mehrere Bewertungsrunden
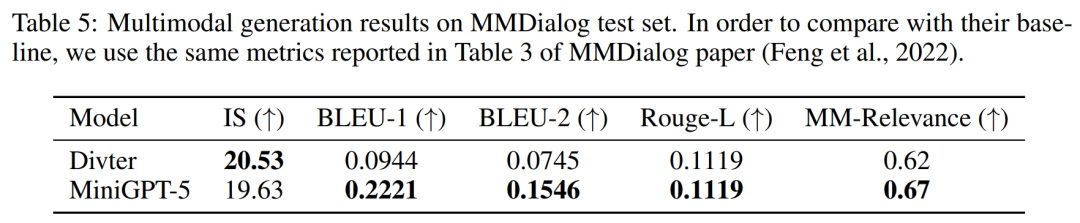
MMDialog Mehrere BewertungsrundenGemäß den Ergebnissen in Tabelle 5 ist MiniGPT-5 bei der Generierung von Textantworten genauer als das Basismodell Divter. Obwohl die generierten Bilder von ähnlicher Qualität sind, übertrifft MiniGPT-5 das Basismodell in Bezug auf MM-Korrelationen, was darauf hindeutet, dass es besser lernen kann, die Bilderzeugung angemessen zu positionieren und hochkonsistente multimodale Antworten zu generieren
Werfen wir einen Blick auf die Ausgabe von MiniGPT-5 und sehen, wie effektiv es ist. Abbildung 7 unten zeigt den Vergleich zwischen MiniGPT-5 und dem Basismodell auf dem CC3M-Verifizierungssatz.Abbildung 8 unten zeigt den Vergleich zwischen MiniGPT-5 und dem Basismodell auf dem VIST-Verifizierungssatz
Abbildung 9 unten zeigt den Vergleich zwischen MiniGPT-5 und dem Basismodell im MMDialog-Testsatz.Weitere Forschungsdetails finden Sie im Originalpapier.
 MMDialog Mehrere Bewertungsrunden
MMDialog Mehrere Bewertungsrunden
Das obige ist der detaillierte Inhalt vonMiniGPT-5, das Bild- und Textgenerierung vereinheitlicht, ist da: Aus Token wird Voken, und das Modell kann nicht nur weiterschreiben, sondern auch automatisch Bilder hinzufügen.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1663
1663
 14
1419
52
1313
25
1263
29
1236
24
14
1419
52
1313
25
1263
29
1236
24

 Open Source! Jenseits von ZoeDepth! DepthFM: Schnelle und genaue monokulare Tiefenschätzung!
Apr 03, 2024 pm 12:04 PM
Open Source! Jenseits von ZoeDepth! DepthFM: Schnelle und genaue monokulare Tiefenschätzung!
Apr 03, 2024 pm 12:04 PM
0.Was bewirkt dieser Artikel? Wir schlagen DepthFM vor: ein vielseitiges und schnelles generatives monokulares Tiefenschätzungsmodell auf dem neuesten Stand der Technik. Zusätzlich zu herkömmlichen Tiefenschätzungsaufgaben demonstriert DepthFM auch hochmoderne Fähigkeiten bei nachgelagerten Aufgaben wie dem Tiefen-Inpainting. DepthFM ist effizient und kann Tiefenkarten innerhalb weniger Inferenzschritte synthetisieren. Lassen Sie uns diese Arbeit gemeinsam lesen ~ 1. Titel der Papierinformationen: DepthFM: FastMonocularDepthEstimationwithFlowMatching Autor: MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 Verwenden Sie ddrescue, um Daten unter Linux wiederherzustellen
Mar 20, 2024 pm 01:37 PM
Verwenden Sie ddrescue, um Daten unter Linux wiederherzustellen
Mar 20, 2024 pm 01:37 PM
DDREASE ist ein Tool zum Wiederherstellen von Daten von Datei- oder Blockgeräten wie Festplatten, SSDs, RAM-Disks, CDs, DVDs und USB-Speichergeräten. Es kopiert Daten von einem Blockgerät auf ein anderes, wobei beschädigte Blöcke zurückbleiben und nur gute Blöcke verschoben werden. ddreasue ist ein leistungsstarkes Wiederherstellungstool, das vollständig automatisiert ist, da es während der Wiederherstellungsvorgänge keine Unterbrechungen erfordert. Darüber hinaus kann es dank der ddasue-Map-Datei jederzeit gestoppt und fortgesetzt werden. Weitere wichtige Funktionen von DDREASE sind: Es überschreibt die wiederhergestellten Daten nicht, füllt aber die Lücken im Falle einer iterativen Wiederherstellung. Es kann jedoch gekürzt werden, wenn das Tool explizit dazu aufgefordert wird. Stellen Sie Daten aus mehreren Dateien oder Blöcken in einer einzigen wieder her
 So verwenden Sie die Excel-Filterfunktion mit mehreren Bedingungen
Feb 26, 2024 am 10:19 AM
So verwenden Sie die Excel-Filterfunktion mit mehreren Bedingungen
Feb 26, 2024 am 10:19 AM
Wenn Sie wissen müssen, wie Sie die Filterung mit mehreren Kriterien in Excel verwenden, führt Sie das folgende Tutorial durch die Schritte, um sicherzustellen, dass Sie Ihre Daten effektiv filtern und sortieren können. Die Filterfunktion von Excel ist sehr leistungsstark und kann Ihnen dabei helfen, aus großen Datenmengen die benötigten Informationen zu extrahieren. Diese Funktion kann Daten entsprechend den von Ihnen festgelegten Bedingungen filtern und nur die Teile anzeigen, die die Bedingungen erfüllen, wodurch die Datenverwaltung effizienter wird. Mithilfe der Filterfunktion können Sie Zieldaten schnell finden und so Zeit beim Suchen und Organisieren von Daten sparen. Diese Funktion kann nicht nur auf einfache Datenlisten angewendet werden, sondern auch nach mehreren Bedingungen gefiltert werden, um Ihnen dabei zu helfen, die benötigten Informationen genauer zu finden. Insgesamt ist die Filterfunktion von Excel sehr praktisch
 Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Die von Google geförderte Leistung von JAX hat in jüngsten Benchmark-Tests die von Pytorch und TensorFlow übertroffen und belegt bei 7 Indikatoren den ersten Platz. Und der Test wurde nicht auf der TPU mit der besten JAX-Leistung durchgeführt. Obwohl unter Entwicklern Pytorch immer noch beliebter ist als Tensorflow. Aber in Zukunft werden möglicherweise mehr große Modelle auf Basis der JAX-Plattform trainiert und ausgeführt. Modelle Kürzlich hat das Keras-Team drei Backends (TensorFlow, JAX, PyTorch) mit der nativen PyTorch-Implementierung und Keras2 mit TensorFlow verglichen. Zunächst wählen sie eine Reihe von Mainstream-Inhalten aus
 Langsame Internetgeschwindigkeiten für Mobilfunkdaten auf dem iPhone: Korrekturen
May 03, 2024 pm 09:01 PM
Langsame Internetgeschwindigkeiten für Mobilfunkdaten auf dem iPhone: Korrekturen
May 03, 2024 pm 09:01 PM
Stehen Sie vor einer Verzögerung oder einer langsamen mobilen Datenverbindung auf dem iPhone? Normalerweise hängt die Stärke des Mobilfunk-Internets auf Ihrem Telefon von mehreren Faktoren ab, wie z. B. der Region, dem Mobilfunknetztyp, dem Roaming-Typ usw. Es gibt einige Dinge, die Sie tun können, um eine schnellere und zuverlässigere Mobilfunk-Internetverbindung zu erhalten. Fix 1 – Neustart des iPhone erzwingen Manchmal werden durch einen erzwungenen Neustart Ihres Geräts viele Dinge zurückgesetzt, einschließlich der Mobilfunkverbindung. Schritt 1 – Drücken Sie einfach einmal die Lauter-Taste und lassen Sie sie los. Drücken Sie anschließend die Leiser-Taste und lassen Sie sie wieder los. Schritt 2 – Der nächste Teil des Prozesses besteht darin, die Taste auf der rechten Seite gedrückt zu halten. Lassen Sie das iPhone den Neustart abschließen. Aktivieren Sie Mobilfunkdaten und überprüfen Sie die Netzwerkgeschwindigkeit. Überprüfen Sie es erneut. Fix 2 – Datenmodus ändern 5G bietet zwar bessere Netzwerkgeschwindigkeiten, funktioniert jedoch besser, wenn das Signal schwächer ist
 Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Das neueste Video von Teslas Roboter Optimus ist veröffentlicht und er kann bereits in der Fabrik arbeiten. Bei normaler Geschwindigkeit sortiert es Batterien (Teslas 4680-Batterien) so: Der Beamte hat auch veröffentlicht, wie es bei 20-facher Geschwindigkeit aussieht – auf einer kleinen „Workstation“, pflücken und pflücken und pflücken: Dieses Mal wird es freigegeben. Eines der Highlights Der Vorteil des Videos besteht darin, dass Optimus diese Arbeit in der Fabrik völlig autonom und ohne menschliches Eingreifen während des gesamten Prozesses erledigt. Und aus Sicht von Optimus kann es auch die krumme Batterie aufnehmen und platzieren, wobei der Schwerpunkt auf der automatischen Fehlerkorrektur liegt: In Bezug auf die Hand von Optimus gab der NVIDIA-Wissenschaftler Jim Fan eine hohe Bewertung ab: Die Hand von Optimus ist der fünffingrige Roboter der Welt am geschicktesten. Seine Hände sind nicht nur taktil
 Das multimodale Dokumentenverständnis-Großmodell Alibaba 7B gewinnt neue SOTA
Apr 02, 2024 am 11:31 AM
Das multimodale Dokumentenverständnis-Großmodell Alibaba 7B gewinnt neue SOTA
Apr 02, 2024 am 11:31 AM
Neues SOTA für multimodale Dokumentverständnisfunktionen! Das Alibaba mPLUG-Team hat die neueste Open-Source-Arbeit mPLUG-DocOwl1.5 veröffentlicht, die eine Reihe von Lösungen zur Bewältigung der vier großen Herausforderungen der hochauflösenden Bildtexterkennung, des allgemeinen Verständnisses der Dokumentstruktur, der Befolgung von Anweisungen und der Einführung externen Wissens vorschlägt. Schauen wir uns ohne weitere Umschweife zunächst die Auswirkungen an. Ein-Klick-Erkennung und Konvertierung von Diagrammen mit komplexen Strukturen in das Markdown-Format: Es stehen Diagramme verschiedener Stile zur Verfügung: Auch eine detailliertere Texterkennung und -positionierung ist einfach zu handhaben: Auch ausführliche Erläuterungen zum Dokumentverständnis können gegeben werden: Sie wissen schon, „Document Understanding“. " ist derzeit ein wichtiges Szenario für die Implementierung großer Sprachmodelle. Es gibt viele Produkte auf dem Markt, die das Lesen von Dokumenten unterstützen. Einige von ihnen verwenden hauptsächlich OCR-Systeme zur Texterkennung und arbeiten mit LLM zur Textverarbeitung zusammen.
 Die Vitalität der Superintelligenz erwacht! Aber mit der Einführung der sich selbst aktualisierenden KI müssen sich Mütter keine Sorgen mehr über Datenengpässe machen
Apr 29, 2024 pm 06:55 PM
Die Vitalität der Superintelligenz erwacht! Aber mit der Einführung der sich selbst aktualisierenden KI müssen sich Mütter keine Sorgen mehr über Datenengpässe machen
Apr 29, 2024 pm 06:55 PM
Ich weine zu Tode. Die Daten im Internet reichen überhaupt nicht aus. Das Trainingsmodell sieht aus wie „Die Tribute von Panem“, und KI-Forscher auf der ganzen Welt machen sich Gedanken darüber, wie sie diese datenhungrigen Esser ernähren sollen. Dieses Problem tritt insbesondere bei multimodalen Aufgaben auf. Zu einer Zeit, als sie ratlos waren, nutzte ein Start-up-Team der Abteilung der Renmin-Universität von China sein eigenes neues Modell, um als erstes in China einen „modellgenerierten Datenfeed selbst“ in die Realität umzusetzen. Darüber hinaus handelt es sich um einen zweigleisigen Ansatz auf der Verständnisseite und der Generierungsseite. Beide Seiten können hochwertige, multimodale neue Daten generieren und Datenrückmeldungen an das Modell selbst liefern. Was ist ein Modell? Awaker 1.0, ein großes multimodales Modell, das gerade im Zhongguancun-Forum erschienen ist. Wer ist das Team? Sophon-Motor. Gegründet von Gao Yizhao, einem Doktoranden an der Hillhouse School of Artificial Intelligence der Renmin University.
