
 Technologie-Peripheriegeräte
KI
Bei der Bild- und Videogenerierung übertrifft das Sprachmodell erstmals das Diffusionsmodell, und der Tokenizer ist der Schlüssel
Technologie-Peripheriegeräte
KI
Bei der Bild- und Videogenerierung übertrifft das Sprachmodell erstmals das Diffusionsmodell, und der Tokenizer ist der Schlüssel
Bei der Bild- und Videogenerierung übertrifft das Sprachmodell erstmals das Diffusionsmodell, und der Tokenizer ist der Schlüssel

Groß angelegte Sprachmodelle (LLM oder LM) wurden ursprünglich zur Generierung von Sprache verwendet, aber im Laufe der Zeit konnten sie Inhalte in mehreren Modalitäten generieren und werden in den Bereichen Audio, Sprache, Codegenerierung, medizinische Anwendungen, Robotik usw. verwendet. Beginnen Sie mit der Übernahme
Natürlich kann LM auch Bilder und Videos generieren. Während dieses Prozesses werden Bildpixel vom visuellen Tokenizer in eine Reihe diskreter Token abgebildet. Diese Token werden dann in den LM-Transformator eingespeist und wie Vokabulare für die generative Modellierung verwendet. Trotz erheblicher Fortschritte bei der visuellen Generierung schneidet LM immer noch schlechter ab als Diffusionsmodelle. Bei der Auswertung des ImageNet-Datensatzes, dem Goldstandard-Benchmark für die Bildgenerierung, schnitt das beste Sprachmodell beispielsweise satte 48 % schlechter ab als das Diffusionsmodell (FID 3,41 vs. 1,79 bei der Generierung von Bildern mit einer Auflösung von 256ˆ256).
Warum bleiben Sprachmodelle bei der visuellen Generierung hinter Diffusionsmodellen zurück? Forscher von Google und CMU glauben, dass der Hauptgrund das Fehlen einer guten visuellen Darstellung, ähnlich unserem natürlichen Sprachsystem, ist, um die visuelle Welt effektiv zu modellieren. Um diese Hypothese zu bestätigen, führten sie eine Studie durch.

Papierlink: https://arxiv.org/pdf/2310.05737.pdf
Diese Studie zeigt, dass bei gleichen Trainingsdaten, vergleichbarer Modellgröße und Trainingsbudget unter Verwendung eines guten visuellen Tokenizers maskiert wird Sprachmodelle übertreffen SOTA-Diffusionsmodelle sowohl hinsichtlich der Generierungstreue als auch der Effizienz bei Bild- und Video-Benchmarks. Dies ist der erste Beweis dafür, dass ein Sprachmodell ein Diffusionsmodell im legendären ImageNet-Benchmark übertrifft.
Es sollte betont werden, dass der Zweck der Forscher nicht darin besteht, festzustellen, ob das Sprachmodell besser als andere Modelle ist, sondern darin, die Erforschung visueller LLM-Tokenisierungsmethoden zu fördern. Der grundlegende Unterschied zwischen LLM und anderen Modellen (z. B. Diffusionsmodellen) besteht darin, dass LLM diskrete latente Formate verwendet, d. h. Token, die von einem visuellen Tokenizer erhalten werden. Diese Untersuchung zeigt, dass der Wert dieser diskreten visuellen Token aufgrund ihrer folgenden Vorteile nicht ignoriert werden sollte:
1. Der Hauptvorteil der Token-Darstellung besteht darin, dass sie die gleiche Form wie das Sprach-Token hat und so die Optimierungen, die die Community im Laufe der Jahre zur Entwicklung von LLM vorgenommen hat, direkt nutzt, einschließlich schnellerer Trainings- und Inferenzgeschwindigkeiten, Fortschritte in der Modellinfrastruktur und Möglichkeiten zur Erweiterung das Modell und Innovationen wie GPU/TPU-Optimierung. Die Vereinigung von Vision und Sprache durch denselben Token-Raum könnte den Grundstein für wirklich multimodale LLMs legen, die unsere visuellen Umgebungen verstehen, generieren und argumentieren können.
2. Komprimierte Darstellung. Diskrete Token können eine neue Perspektive auf die Videokomprimierung bieten. Visuelle Token können als neues Videokomprimierungsformat verwendet werden, um den Festplattenspeicher und die von Daten während der Internetübertragung belegte Bandbreite zu reduzieren. Im Gegensatz zu komprimierten RGB-Pixeln können diese Token direkt in das generative Modell eingespeist werden, wodurch herkömmliche Dekomprimierungs- und latente Codierungsschritte umgangen werden. Dies kann die Verarbeitung videogenerierender Anwendungen beschleunigen und ist besonders in Edge-Computing-Situationen von Vorteil.
3. Vorteile des visuellen Verständnisses. Frühere Untersuchungen haben den Wert diskreter Labels als Vortrainingsziele beim selbstüberwachten Repräsentationslernen gezeigt, wie in BEiT und BEVT diskutiert. Darüber hinaus ergab die Studie, dass die Verwendung von Markern als Modelleingaben seine Robustheit und Generalisierungsleistung verbessern kann Tokens
Der Inhalt wird wie folgt umgeschrieben: Dieses Modell basiert auf einer Verbesserung von MAGVIT, einem SOTA-Video-Tokenizer innerhalb des VQ-VAE-Frameworks. Die Forscher schlugen zwei neue Technologien vor: 1) eine innovative, nachschlagefreie Quantifizierungsmethode, die das Erlernen eines großen Vokabulars ermöglicht und dadurch die Qualität der Sprachmodellgenerierung verbessert. 2) Durch umfangreiche empirische Analysen stellten sie fest, dass Änderungen an MAGVIT nicht nur die Generierungsqualität verbessern , sondern ermöglichen auch die Tokenisierung von Bildern und Videos mithilfe eines gemeinsamen Vokabulars
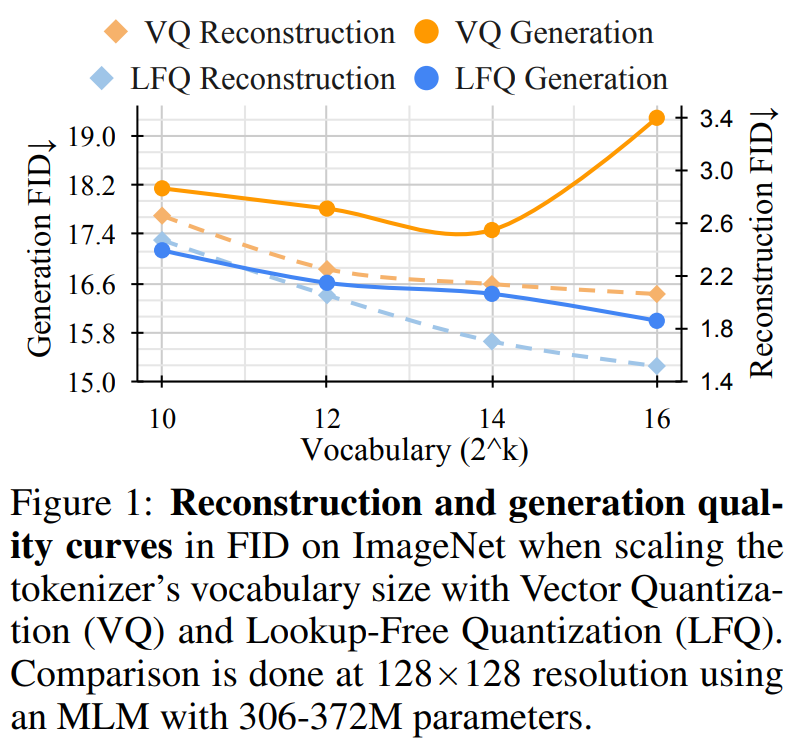
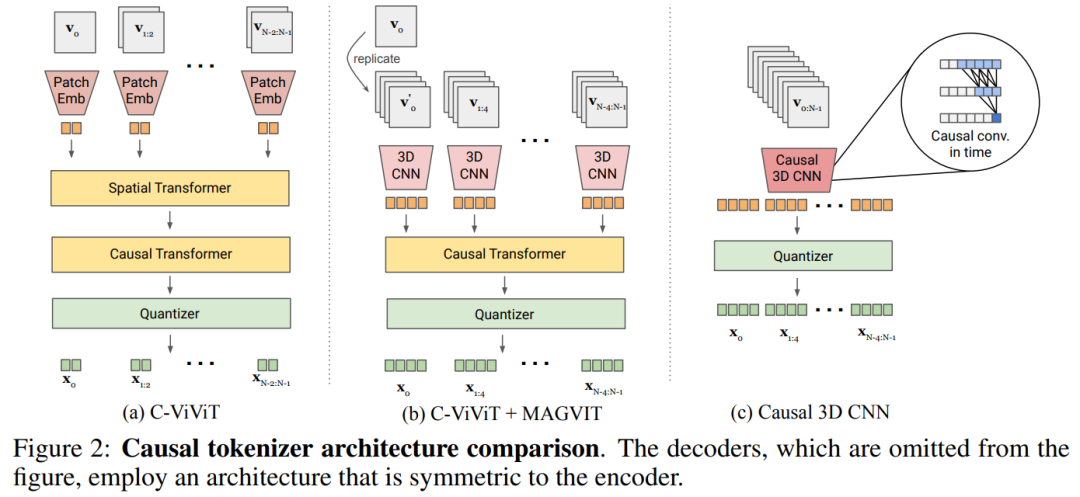
Experimentelle Ergebnisse zeigen, dass das neue Modell den bisher leistungsstärksten Videosegmentierer in drei Schlüsselbereichen übertrifft – MAGVIT. Erstens verbessert das neue Modell die Generierungsqualität von MAGVIT erheblich und erzielt modernste Ergebnisse bei gängigen Bild- und Video-Benchmarks. Zweitens zeigen Benutzerstudien, dass die Komprimierungsqualität MAGVIT und den aktuellen Videokomprimierungsstandard HEVC übertrifft. Darüber hinaus ist es mit dem Videocodec VVC der nächsten Generation vergleichbar. Schließlich zeigen die Forscher, dass ihre neue Wortsegmentierung bei Videoverständnisaufgaben in zwei Einstellungen und drei Datensätzen besser abschneidet als MAGVIT In diesem Artikel wird ein neuer Video-Tokenizer vorgestellt, der darauf abzielt, die Zeit-Raum-Dynamik in visuellen Szenen in kompakte diskrete Token abzubilden, die für Sprachmodelle geeignet sind. Darüber hinaus baut die Methode auf MAGVIT auf. Anschließend beleuchtet die Studie zwei neuartige Designs: Lookup-Free Quantization (LFQ) und Verbesserungen des Tokenizer-Modells. Nachschlagefreie Quantisierung Das VQ-VAE-Modell hat in letzter Zeit große Fortschritte gemacht, aber diese Methode weist ein Problem auf, nämlich die Beziehung zwischen der Verbesserung der Rekonstruktionsqualität und der Qualität der nachfolgenden Generation ist nicht klar. Viele Menschen glauben fälschlicherweise, dass eine Verbesserung der Rekonstruktion gleichbedeutend mit einer Verbesserung der Generierung von Sprachmodellen ist. Beispielsweise kann die Erweiterung des Wortschatzes die Qualität der Rekonstruktion verbessern. Diese Verbesserung gilt jedoch nur für die Generierung mit einem kleinen Vokabular, und wenn das Vokabular sehr groß ist, beeinträchtigt es die Leistung des Sprachmodells Dieser Artikel reduziert die Einbettungsdimension des VQ-VAE-Codebuchs auf 0, d. h. Das Codebuch Im Gegensatz zum VQ-VAE-Modell macht dieses neue Design die Notwendigkeit eingebetteter Suchvorgänge vollständig überflüssig, daher der Name LFQ. In diesem Artikel wird festgestellt, dass LFQ die Qualität der Sprachmodellgenerierung durch die Erweiterung des Wortschatzes verbessern kann. Wie die blaue Kurve in Abbildung 1 zeigt, verbessern sich sowohl die Rekonstruktion als auch die Generierung mit zunehmender Vokabulargröße – eine Eigenschaft, die bei aktuellen VQ-VAE-Methoden nicht beobachtet wird. Bisher sind viele LFQ-Methoden verfügbar, in diesem Artikel geht es jedoch um eine einfache Variante. Insbesondere wird der latente Raum von LFQ in das kartesische Produkt eindimensionaler Variablen zerlegt, d. h. In Bezug auf LFQ ist der Token-Index von q(z): außer Darüber hinaus fügt dieser Artikel auch eine Entropiestrafe während des Trainingsprozesses hinzu: Um einen gemeinsamen Bild-Video-Tokenizer zu erstellen, muss dieser neu gestaltet werden . Die Studie ergab, dass die Leistung von 3D-CNN im Vergleich zum räumlichen Transformator besser ist. In diesem Artikel werden zwei mögliche Designlösungen untersucht. Abbildung 2b kombiniert C-ViViT mit MAGVIT. Abbildung 2c verwendet zeitlich kausale 3D-Faltung, um herkömmliches 3D-CNN zu ersetzen .
Tabelle 5a vergleicht die Designs in Abbildung 2 empirisch und stellt fest, dass das kausale 3D-CNN die beste Leistung erbringt.
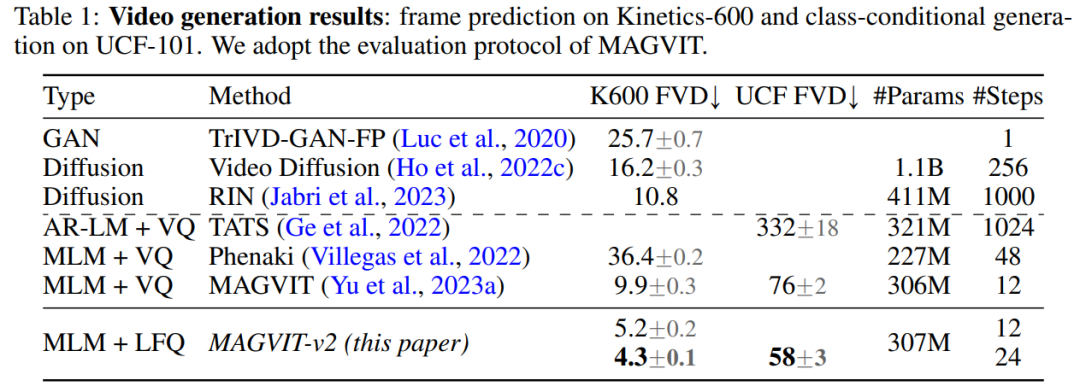
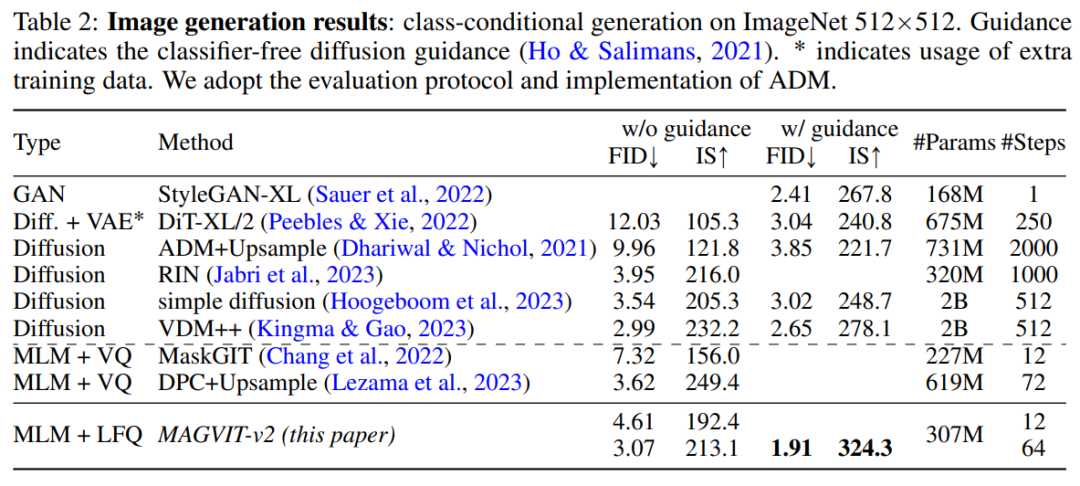
In diesem Artikel werden weitere architektonische Änderungen vorgenommen, um die Leistung von MAGVIT zu verbessern. Zusätzlich zur Verwendung kausaler 3D-CNN-Schichten ändert dieser Artikel auch den Encoder-Downsampler von durchschnittlichem Pooling zu schrittweiser Faltung und fügt eine adaptive Gruppennormalisierung vor dem Restblock bei jeder Auflösung in den Decoderschichten usw. hinzu. In diesem Artikel wird die Leistung des vorgeschlagenen Wortsegmentierers anhand von drei Experimenten überprüft: Video- und Bildgenerierung, Videokomprimierung und Aktionserkennung. Abbildung 3 vergleicht den Tokenizer visuell mit früheren Forschungsergebnissen Videogenerierung. Tabelle 1 zeigt, dass unser Modell bei beiden Benchmarks alle vorhandenen Techniken übertrifft und beweist, dass ein guter visueller Tokenizer eine wichtige Rolle dabei spielt, dass LM qualitativ hochwertige Videos generieren kann. Durch die Auswertung der Bilderzeugungsergebnisse von MAGVIT-v2 stellte diese Studie fest, dass unser Modell die Leistung des besten Diffusionsmodells hinsichtlich der Stichprobenqualität (ID und IS) und der Inferenzzeiteffizienz (Sampling-Schritt) übertrifft Ergebnisse. Videokomprimierung. Die Ergebnisse sind in Tabelle 3 aufgeführt. Unser Modell übertrifft MAGVIT bei allen Indikatoren und übertrifft alle Methoden bei LPIPS. Wie in Tabelle 4 gezeigt, übertrifft MAGVIT-v2 in diesen Bewertungen das bisher beste MAGVITEinführung in die Methode
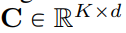 wird durch eine Menge von ganzen Zahlen
wird durch eine Menge von ganzen Zahlen 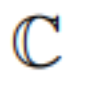 ersetzt, wobei
ersetzt, wobei 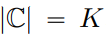 .
. 
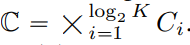 . Unter der Annahme, dass bei gegebenem Merkmalsvektor
. Unter der Annahme, dass bei gegebenem Merkmalsvektor 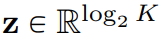 jede Dimension der quantisierten Darstellung q(z) erhalten wird aus:
jede Dimension der quantisierten Darstellung q(z) erhalten wird aus: 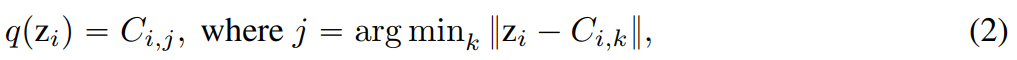
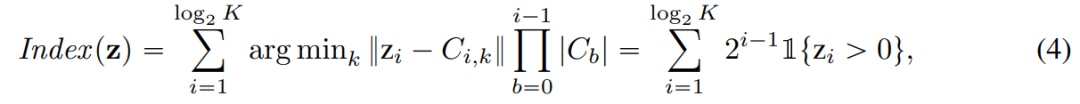
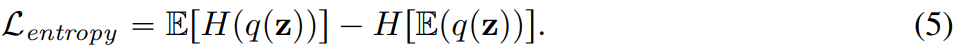
Verbesserung des visuellen Tokenizer-Modells
Experimentelle Ergebnisse


Das obige ist der detaillierte Inhalt vonBei der Bild- und Videogenerierung übertrifft das Sprachmodell erstmals das Diffusionsmodell, und der Tokenizer ist der Schlüssel. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 Open Source! Jenseits von ZoeDepth! DepthFM: Schnelle und genaue monokulare Tiefenschätzung!
Apr 03, 2024 pm 12:04 PM
Open Source! Jenseits von ZoeDepth! DepthFM: Schnelle und genaue monokulare Tiefenschätzung!
Apr 03, 2024 pm 12:04 PM
0.Was bewirkt dieser Artikel? Wir schlagen DepthFM vor: ein vielseitiges und schnelles generatives monokulares Tiefenschätzungsmodell auf dem neuesten Stand der Technik. Zusätzlich zu herkömmlichen Tiefenschätzungsaufgaben demonstriert DepthFM auch hochmoderne Fähigkeiten bei nachgelagerten Aufgaben wie dem Tiefen-Inpainting. DepthFM ist effizient und kann Tiefenkarten innerhalb weniger Inferenzschritte synthetisieren. Lassen Sie uns diese Arbeit gemeinsam lesen ~ 1. Titel der Papierinformationen: DepthFM: FastMonocularDepthEstimationwithFlowMatching Autor: MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Stellen Sie sich ein Modell der künstlichen Intelligenz vor, das nicht nur die Fähigkeit besitzt, die traditionelle Datenverarbeitung zu übertreffen, sondern auch eine effizientere Leistung zu geringeren Kosten erzielt. Dies ist keine Science-Fiction, DeepSeek-V2[1], das weltweit leistungsstärkste Open-Source-MoE-Modell, ist da. DeepSeek-V2 ist ein leistungsstarkes MoE-Sprachmodell (Mix of Experts) mit den Merkmalen eines wirtschaftlichen Trainings und einer effizienten Inferenz. Es besteht aus 236B Parametern, von denen 21B zur Aktivierung jedes Markers verwendet werden. Im Vergleich zu DeepSeek67B bietet DeepSeek-V2 eine stärkere Leistung, spart gleichzeitig 42,5 % der Trainingskosten, reduziert den KV-Cache um 93,3 % und erhöht den maximalen Generierungsdurchsatz auf das 5,76-fache. DeepSeek ist ein Unternehmen, das sich mit allgemeiner künstlicher Intelligenz beschäftigt
 KI untergräbt die mathematische Forschung! Der Gewinner der Fields-Medaille und der chinesisch-amerikanische Mathematiker führten 11 hochrangige Arbeiten an | Gefällt mir bei Terence Tao
Apr 09, 2024 am 11:52 AM
KI untergräbt die mathematische Forschung! Der Gewinner der Fields-Medaille und der chinesisch-amerikanische Mathematiker führten 11 hochrangige Arbeiten an | Gefällt mir bei Terence Tao
Apr 09, 2024 am 11:52 AM
KI verändert tatsächlich die Mathematik. Vor kurzem hat Tao Zhexuan, der diesem Thema große Aufmerksamkeit gewidmet hat, die neueste Ausgabe des „Bulletin of the American Mathematical Society“ (Bulletin der American Mathematical Society) weitergeleitet. Zum Thema „Werden Maschinen die Mathematik verändern?“ äußerten viele Mathematiker ihre Meinung. Der gesamte Prozess war voller Funken, knallhart und aufregend. Der Autor verfügt über eine starke Besetzung, darunter der Fields-Medaillengewinner Akshay Venkatesh, der chinesische Mathematiker Zheng Lejun, der NYU-Informatiker Ernest Davis und viele andere bekannte Wissenschaftler der Branche. Die Welt der KI hat sich dramatisch verändert. Viele dieser Artikel wurden vor einem Jahr eingereicht.
 KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
Anfang dieses Monats schlugen Forscher des MIT und anderer Institutionen eine vielversprechende Alternative zu MLP vor – KAN. KAN übertrifft MLP in Bezug auf Genauigkeit und Interpretierbarkeit. Und es kann MLP, das mit einer größeren Anzahl von Parametern ausgeführt wird, mit einer sehr kleinen Anzahl von Parametern übertreffen. Beispielsweise gaben die Autoren an, dass sie KAN nutzten, um die Ergebnisse von DeepMind mit einem kleineren Netzwerk und einem höheren Automatisierungsgrad zu reproduzieren. Konkret verfügt DeepMinds MLP über etwa 300.000 Parameter, während KAN nur etwa 200 Parameter hat. KAN hat eine starke mathematische Grundlage wie MLP und basiert auf dem universellen Approximationssatz, während KAN auf dem Kolmogorov-Arnold-Darstellungssatz basiert. Wie in der folgenden Abbildung gezeigt, hat KAN
 Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas tritt offiziell in die Ära der Elektroroboter ein! Gestern hat sich der hydraulische Atlas einfach „unter Tränen“ von der Bühne der Geschichte zurückgezogen. Heute gab Boston Dynamics bekannt, dass der elektrische Atlas im Einsatz ist. Es scheint, dass Boston Dynamics im Bereich kommerzieller humanoider Roboter entschlossen ist, mit Tesla zu konkurrieren. Nach der Veröffentlichung des neuen Videos wurde es innerhalb von nur zehn Stunden bereits von mehr als einer Million Menschen angesehen. Die alten Leute gehen und neue Rollen entstehen. Das ist eine historische Notwendigkeit. Es besteht kein Zweifel, dass dieses Jahr das explosive Jahr der humanoiden Roboter ist. Netizens kommentierten: Die Weiterentwicklung der Roboter hat dazu geführt, dass die diesjährige Eröffnungsfeier wie Menschen aussieht, und der Freiheitsgrad ist weitaus größer als der von Menschen. Aber ist das wirklich kein Horrorfilm? Zu Beginn des Videos liegt Atlas ruhig auf dem Boden, scheinbar auf dem Rücken. Was folgt, ist atemberaubend
 Die Kuaishou-Version von Sora „Ke Ling' steht zum Testen offen: Sie generiert über 120 Sekunden Videos, versteht die Physik besser und kann komplexe Bewegungen genau modellieren
Jun 11, 2024 am 09:51 AM
Die Kuaishou-Version von Sora „Ke Ling' steht zum Testen offen: Sie generiert über 120 Sekunden Videos, versteht die Physik besser und kann komplexe Bewegungen genau modellieren
Jun 11, 2024 am 09:51 AM
Was? Wird Zootopia durch heimische KI in die Realität umgesetzt? Zusammen mit dem Video wird ein neues groß angelegtes inländisches Videogenerationsmodell namens „Keling“ vorgestellt. Sora geht einen ähnlichen technischen Weg und kombiniert eine Reihe selbst entwickelter technologischer Innovationen, um Videos zu produzieren, die nicht nur große und vernünftige Bewegungen aufweisen, sondern auch die Eigenschaften der physischen Welt simulieren und über starke konzeptionelle Kombinationsfähigkeiten und Vorstellungskraft verfügen. Den Daten zufolge unterstützt Keling die Erstellung ultralanger Videos von bis zu 2 Minuten mit 30 Bildern pro Sekunde, mit Auflösungen von bis zu 1080p und unterstützt mehrere Seitenverhältnisse. Ein weiterer wichtiger Punkt ist, dass es sich bei Keling nicht um eine vom Labor veröffentlichte Demo oder Video-Ergebnisdemonstration handelt, sondern um eine Anwendung auf Produktebene, die von Kuaishou, einem führenden Anbieter im Bereich Kurzvideos, gestartet wurde. Darüber hinaus liegt das Hauptaugenmerk darauf, pragmatisch zu sein, keine Blankoschecks auszustellen und sofort nach der Veröffentlichung online zu gehen. Das große Modell von Ke Ling wurde bereits in Kuaiying veröffentlicht.
 Die Vitalität der Superintelligenz erwacht! Aber mit der Einführung der sich selbst aktualisierenden KI müssen sich Mütter keine Sorgen mehr über Datenengpässe machen
Apr 29, 2024 pm 06:55 PM
Die Vitalität der Superintelligenz erwacht! Aber mit der Einführung der sich selbst aktualisierenden KI müssen sich Mütter keine Sorgen mehr über Datenengpässe machen
Apr 29, 2024 pm 06:55 PM
Ich weine zu Tode. Die Daten im Internet reichen überhaupt nicht aus. Das Trainingsmodell sieht aus wie „Die Tribute von Panem“, und KI-Forscher auf der ganzen Welt machen sich Gedanken darüber, wie sie diese datenhungrigen Esser ernähren sollen. Dieses Problem tritt insbesondere bei multimodalen Aufgaben auf. Zu einer Zeit, als sie ratlos waren, nutzte ein Start-up-Team der Abteilung der Renmin-Universität von China sein eigenes neues Modell, um als erstes in China einen „modellgenerierten Datenfeed selbst“ in die Realität umzusetzen. Darüber hinaus handelt es sich um einen zweigleisigen Ansatz auf der Verständnisseite und der Generierungsseite. Beide Seiten können hochwertige, multimodale neue Daten generieren und Datenrückmeldungen an das Modell selbst liefern. Was ist ein Modell? Awaker 1.0, ein großes multimodales Modell, das gerade im Zhongguancun-Forum erschienen ist. Wer ist das Team? Sophon-Motor. Gegründet von Gao Yizhao, einem Doktoranden an der Hillhouse School of Artificial Intelligence der Renmin University.
 Die U.S. Air Force präsentiert ihren ersten KI-Kampfjet mit großem Aufsehen! Der Minister führte die Testfahrt persönlich durch, ohne in den gesamten Prozess einzugreifen, und 100.000 Codezeilen wurden 21 Mal getestet.
May 07, 2024 pm 05:00 PM
Die U.S. Air Force präsentiert ihren ersten KI-Kampfjet mit großem Aufsehen! Der Minister führte die Testfahrt persönlich durch, ohne in den gesamten Prozess einzugreifen, und 100.000 Codezeilen wurden 21 Mal getestet.
May 07, 2024 pm 05:00 PM
Kürzlich wurde die Militärwelt von der Nachricht überwältigt: US-Militärkampfflugzeuge können jetzt mithilfe von KI vollautomatische Luftkämpfe absolvieren. Ja, erst kürzlich wurde der KI-Kampfjet des US-Militärs zum ersten Mal der Öffentlichkeit zugänglich gemacht und sein Geheimnis gelüftet. Der vollständige Name dieses Jägers lautet „Variable Stability Simulator Test Aircraft“ (VISTA). Er wurde vom Minister der US-Luftwaffe persönlich geflogen, um einen Eins-gegen-eins-Luftkampf zu simulieren. Am 2. Mai startete US-Luftwaffenminister Frank Kendall mit einer X-62AVISTA auf der Edwards Air Force Base. Beachten Sie, dass während des einstündigen Fluges alle Flugaktionen autonom von der KI durchgeführt wurden! Kendall sagte: „In den letzten Jahrzehnten haben wir über das unbegrenzte Potenzial des autonomen Luft-Luft-Kampfes nachgedacht, aber es schien immer unerreichbar.“ Nun jedoch,
