
 Technologie-Peripheriegeräte
KI
Umgekehrtes Denken: Das neue mathematische Argumentationssprachenmodell von MetaMath trainiert große Modelle
Technologie-Peripheriegeräte
KI
Umgekehrtes Denken: Das neue mathematische Argumentationssprachenmodell von MetaMath trainiert große Modelle
Umgekehrtes Denken: Das neue mathematische Argumentationssprachenmodell von MetaMath trainiert große Modelle

Komplexes mathematisches Denken ist ein wichtiger Indikator für die Bewertung der Argumentationsfähigkeiten großer Sprachmodelle. Derzeit weisen die häufig verwendeten Datensätze zum mathematischen Denken eine begrenzte Stichprobengröße und eine unzureichende Problemvielfalt auf, was im Großen und Ganzen zum Phänomen der „Umkehrung des Fluchs“ führt Sprachmodelle, also ein Modell, das auf „A“ trainiert wurde. Das Sprachmodell „ist B“ kann nicht auf „B ist A“ verallgemeinert werden [1]. Die spezifische Form dieses Phänomens bei mathematischen Denkaufgaben ist: Bei einem gegebenen mathematischen Problem ist das Sprachmodell gut darin, das Problem durch Vorwärtsschlussfolgerung zu lösen, es fehlt ihm jedoch die Fähigkeit, das Problem durch Rückwärtsschlussfolgerung zu lösen. Umgekehrtes Denken kommt bei mathematischen Problemen sehr häufig vor, wie die folgenden beiden Beispiele zeigen.
1. Klassische Frage – Huhn und Kaninchen im selben Käfig
- Vorwärtsbegründung: Es gibt 23 Hühner und 12 Kaninchen im Käfig.
- Umgekehrte Argumentation: Es gibt mehrere Hühner und Kaninchen im selben Käfig. Von oben gezählt sind es 35 Köpfe und von unten gezählt sind es 94 Beine. Wie viele Hühner und Kaninchen sind im Käfig?
2. GSM8K-Problem
- Vorwärtsbegründung: James kauft 5 Packungen Rindfleisch zu je 4 Pfund. Wie viel hat er bezahlt? : James kauft x Packungen Rindfleisch zu je 4 Pfund. Wie viel hat er bezahlt? Wenn wir wissen, dass die Antwort auf die obige Frage 110 ist, welchen Wert hat die unbekannte Variable x?
- Um die Vorwärts- und Rückwärtsschlussfähigkeiten des Modells zu verbessern, haben Forscher aus Cambridge, der Hong Kong University of Science and Technology und Huawei den MetaMathQA-Datensatz vorgeschlagen, der auf zwei häufig verwendeten mathematischen Datensätzen (GSM8K und MATH) basiert. : einer mit umfassender Abdeckung und einem hochwertigen Datensatz zum mathematischen Denken. MetaMathQA besteht aus 395.000 vorwärts-inversen mathematischen Frage-Antwort-Paaren, die von einem großen Sprachmodell generiert werden. Sie optimierten LLaMA-2 am MetaMathQA-Datensatz, um MetaMath zu erhalten, ein großes Sprachmodell mit Schwerpunkt auf mathematischem Denken (vorwärts und invers), das SOTA im Datensatz zum mathematischen Denken erreichte. Der MetaMathQA-Datensatz und die MetaMath-Modelle in verschiedenen Maßstäben stehen Forschern als Open Source zur Verfügung.
Projektadresse: https://meta-math.github.io/
- Papieradresse: https://arxiv.org/abs/2309.12284
- Datenadresse: https: //huggingface.co/datasets/meta-math/MetaMathQA
- Modelladresse: https://huggingface.co/meta-math
- Codeadresse: https://github.com/meta-math/ MetaMath
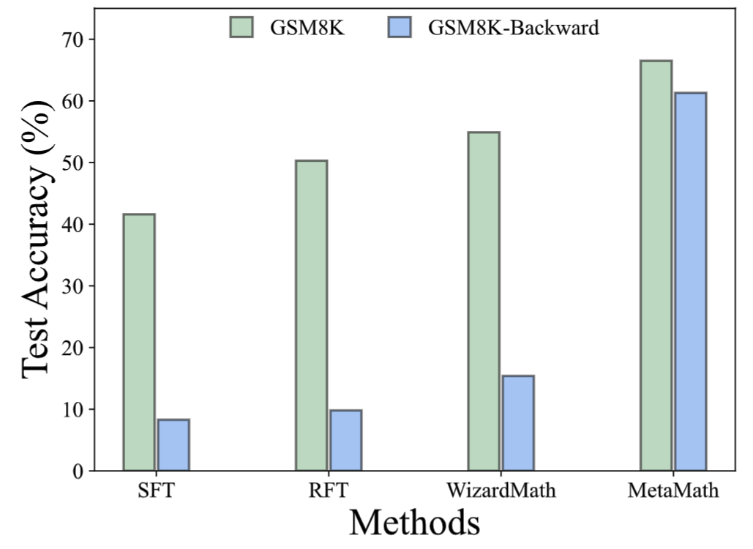
- Im GSM8K-Backward-Datensatz haben wir ein Reverse-Inference-Experiment erstellt. Experimentelle Ergebnisse zeigen, dass die aktuelle Methode im Vergleich zu Methoden wie SFT, RFT und WizardMath bei inversen Inferenzproblemen eine schlechte Leistung erbringt. Im Gegensatz dazu erzielt das MetaMath-Modell sowohl bei der Vorwärts- als auch bei der Rückwärtsinferenz eine hervorragende Leistung 1. Antworterweiterung:
Bei einer Frage wird durch ein großes Sprachmodell als Datenerweiterung eine Denkkette generiert, die das richtige Ergebnis erzielen kann.
 Frage: James kauft 5 Packungen Rindfleisch zu je 4 Pfund. Der Preis für Rindfleisch beträgt 5,50 $ pro Pfund.
Frage: James kauft 5 Packungen Rindfleisch zu je 4 Pfund. Der Preis für Rindfleisch beträgt 5,50 $ pro Pfund.
Antwort: James kauft 5 Packungen Rindfleisch zu je 4 Pfund jeder kauft also insgesamt 5 * 4 = 20 Pfund Rindfleisch, also zahlt er 20 * 5,50 $ = 110.
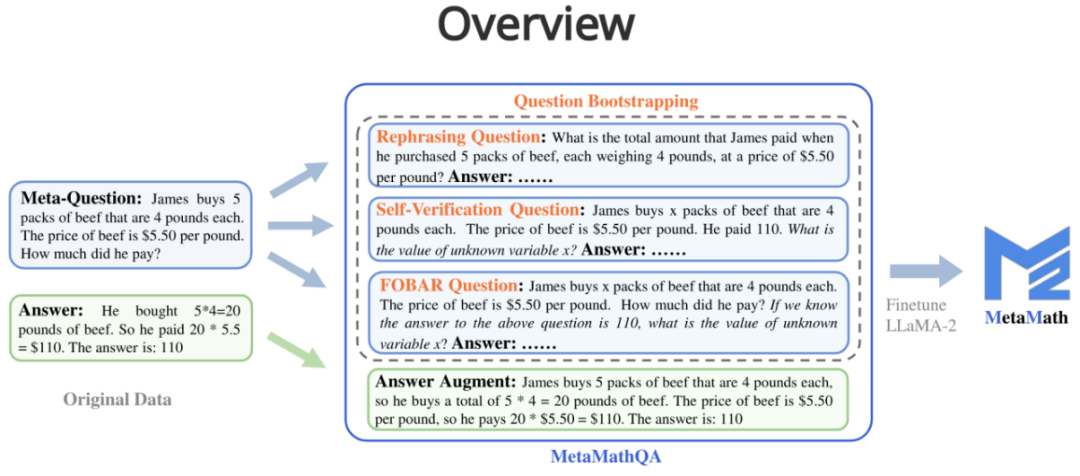
Schreiben Sie bei einer gegebenen Metafrage die Frage mithilfe eines großen Sprachmodells um und generieren Sie eine Denkkette, die als Datenerweiterung das richtige Ergebnis liefert.
- Frage: Wie hoch war der Gesamtbetrag, den James bezahlt hat, als er 5 Packungen Rindfleisch mit einem Gewicht von je 4 Pfund zu einem Preis von 5,50 $ pro Pfund kaufte?
- Antwort: Jede Packung Rindfleisch wiegt 4 Pfund, also 5 Packungen wiegen insgesamt 4 * 5 = 20 Pfund. Der Preis für 20 Pfund beträgt also 20 * 5,50 $ = 110 $
3. FOBAR-Frage (FOBAR Inverse Question Enhancement): Bei einer Metafrage ist die Zahl in der Maskenbedingung x, bei gegebener Originalantwort und invertiertem x, um eine inverse Frage zu generieren, und basierend auf Dieses inverse Problem generiert die richtige Gedankenkette zur Durchführung einer Datenerweiterung (Beispiel für eine Inversion: „Wenn wir wissen, dass die Antwort auf die obige Frage 110 ist, welchen Wert hat dann die unbekannte Variable x?“).
- Frage: James kauft x Packungen Rindfleisch zu je 4 Pfund. Der Preis für Rindfleisch beträgt 5,50 $ pro Pfund. Wie viel hat er bezahlt? von unbekannter Variable x?
- Antwort: James kauft x Packungen Rindfleisch zu je 4 Pfund, also kauft er insgesamt 4x Pfund Rindfleisch. Der Preis für Rindfleisch beträgt 5,50 $ pro Pfund, also die Gesamtkosten für das Rindfleisch ist 5,50 * 4x = 22x. Wir gehen davon aus, dass die Gesamtkosten 110 $ betragen, also können wir schreiben: 22x = 110. Wenn wir beide Seiten durch 22 dividieren, erhalten wir: x = 5. Der Wert von x ist 5,
4. Frage zur Selbstverifizierung (Verbesserung der inversen Frage zur Selbstverifizierung): Basierend auf FOBAR wird der Teil der inversen Frage durch ein großes Sprachmodell als Aussage umgeschrieben, um eine Datenerweiterung durchzuführen (umgeschriebenes Beispiel: „Wie viel hat…“ zahlt er?“ (mit der Antwort 110) wurde umgeschrieben in „Er zahlte 110“).
- Frage: James kauft x Packungen Rindfleisch zu je 4 Pfund. Der Preis für Rindfleisch beträgt 5,50 $ pro Pfund. Wie hoch ist der Wert der unbekannten Variablen x?
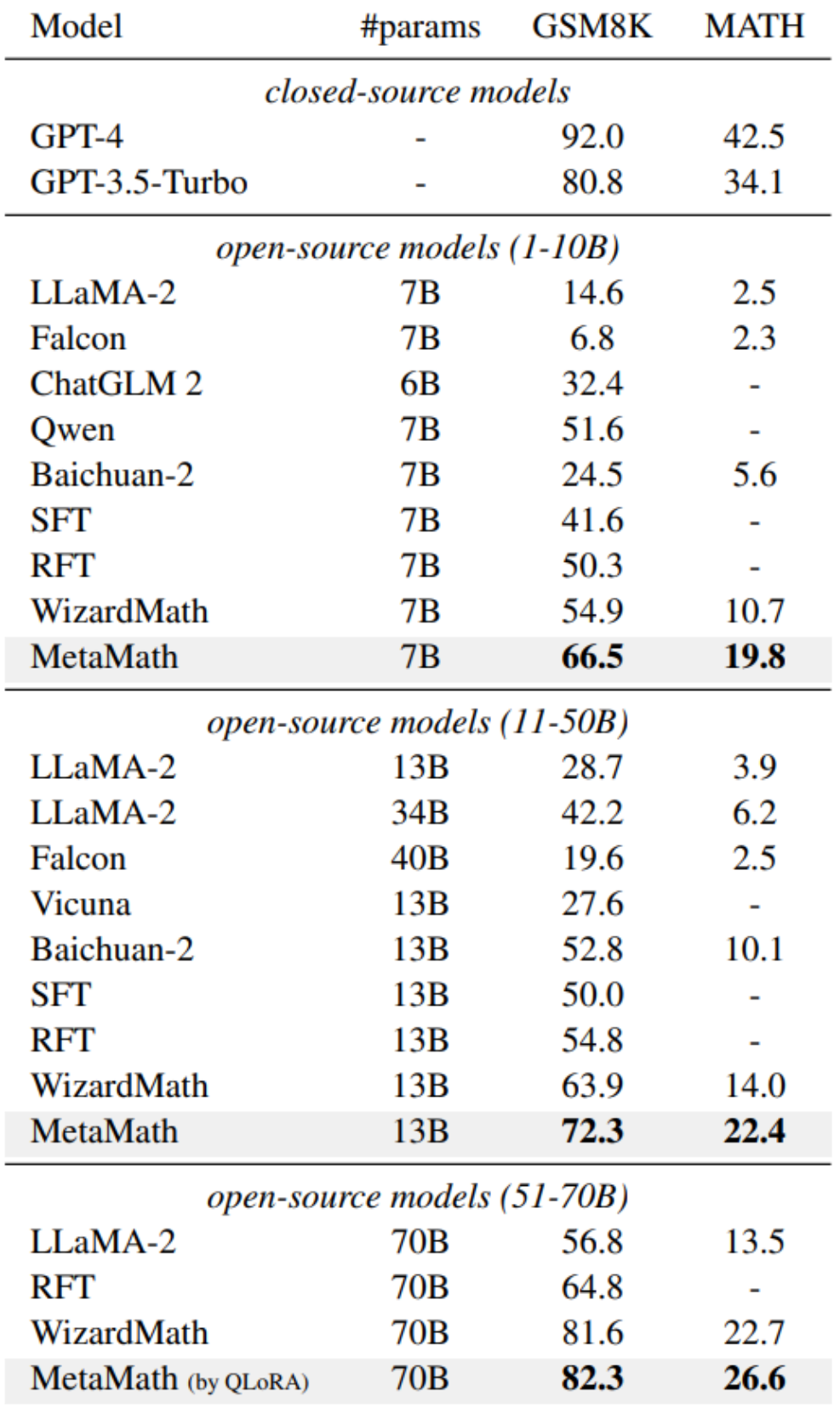
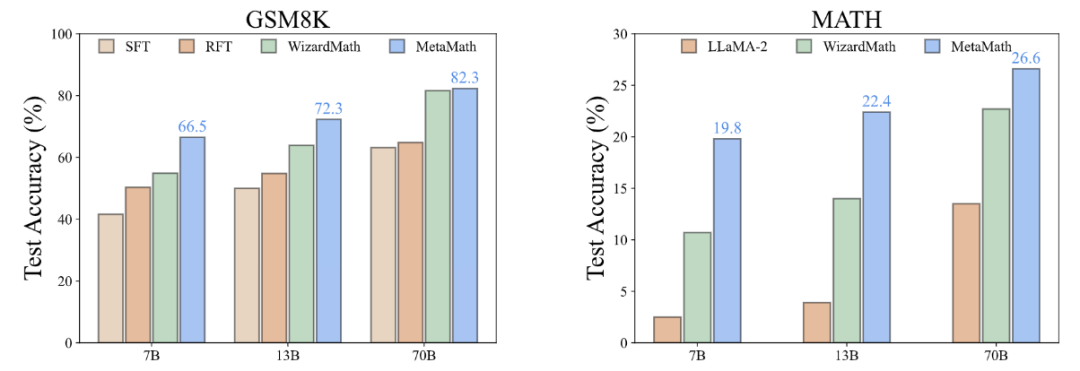
- Antwort: Um dies zu lösen Problem: Wir müssen den Wert von x bestimmen, der die Anzahl der Packungen Rindfleisch darstellt, die James gekauft hat, und 5,50 US-Dollar pro Pfund kostet. Wir können die Gleichung aufstellen wie folgt: Anzahl der Rindfleischpakete * Gewicht pro Pfund * Preis pro Pfund = Gesamtbetrag x * 4 * 5,50 $ = 110 $; Um x zu isolieren, wir dividieren beide Seiten der Gleichung durch 22: 22x / 22 = $110 / 22; Die Leistung verbessert die Leistung von LLM-Quellmodellen und erfordert keine Verwendung externer Tools (z. B. Code-Interpreter). Unter ihnen erreicht unser MetaMath-7B-Modell eine Genauigkeit von 66,5 % bei GSM8K und 19,8 % bei MATH, was 11,6 % bzw. 9,1 % höher ist als die hochmodernen Modelle derselben Skala. Besonders erwähnenswert ist, dass MetaMath-70B auf GSM8K eine Genauigkeit von 82,3 % erreichte und damit GPT-3,5-Turbo übertraf. Während Daten aus nachgelagerten Aufgaben die inhärenten Fähigkeiten des während des Vortrainings erlernten Sprachmodells aktivieren. Daher wirft dies zwei wichtige Fragen auf: (i) Welche Art von Daten aktiviert latentes Wissen am effektivsten und (ii) warum ist ein Datensatz bei dieser Aktivierung besser als ein anderer?
Warum ist MetaMathQA nützlich? Die Qualität (Perplexity) der Denkkettendaten wurde verbessert
Wie in der Abbildung oben gezeigt, berechneten die Forscher das LLaMA-2-7B-Modell in jedem Teil der Nur-Antwort-Daten, GSM8K CoT und MetaMathQA-Datensätze legen den Grad der Verwirrung fest. Die Verwirrung des MetaMathQA-Datensatzes ist deutlich geringer als bei den anderen beiden Datensätzen, was darauf hindeutet, dass er eine höhere Lernfähigkeit aufweist und möglicherweise hilfreicher bei der Offenlegung des latenten Wissens des Modells ist
Warum ist MetaMathQA nützlich? Die Vielfalt der Denkkettendaten wurde erhöht
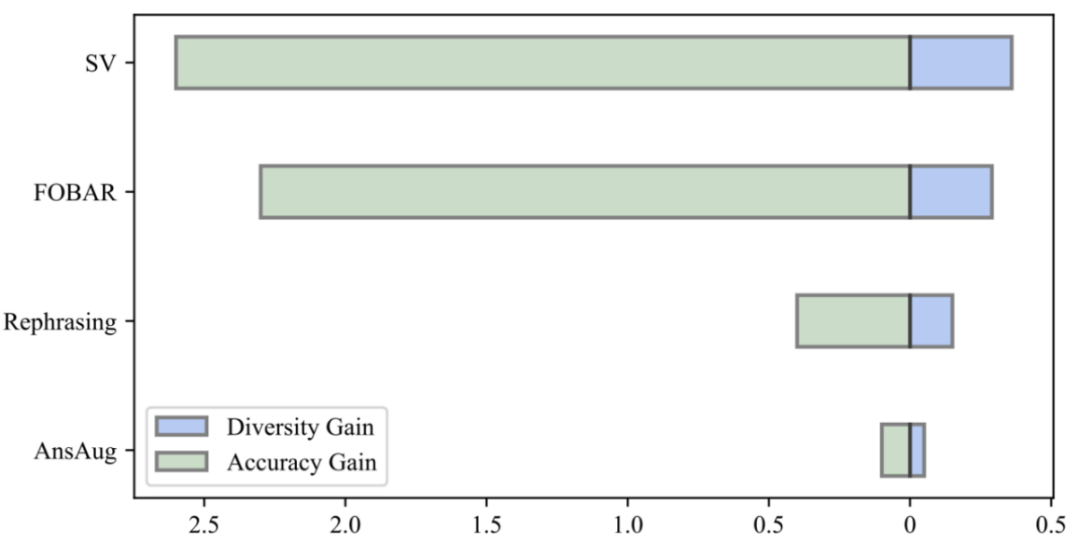
Durch den Vergleich des Diversitätsgewinns der Daten und des Genauigkeitsgewinns des Modells stellten die Forscher fest, dass die Einführung der gleichen Menge erweiterter Daten durch Neuformulierung, FOBAR und SV alle zu offensichtlichen Diversitätsgewinnen und einem deutlich verbesserten Modell führte Genauigkeit. Im Gegensatz dazu führte die alleinige Verwendung der Antworterweiterung zu einer erheblichen Sättigung der Genauigkeit. Sobald die Genauigkeit die Sättigung erreicht, führt das Hinzufügen von AnsAug-Daten nur zu einer begrenzten Leistungsverbesserung
Das obige ist der detaillierte Inhalt vonUmgekehrtes Denken: Das neue mathematische Argumentationssprachenmodell von MetaMath trainiert große Modelle. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 So implementieren Sie die Dateisortierung nach Debian Readdir
Apr 13, 2025 am 09:06 AM
So implementieren Sie die Dateisortierung nach Debian Readdir
Apr 13, 2025 am 09:06 AM
In Debian -Systemen wird die Readdir -Funktion zum Lesen des Verzeichnisinhalts verwendet, aber die Reihenfolge, in der sie zurückgibt, ist nicht vordefiniert. Um Dateien in einem Verzeichnis zu sortieren, müssen Sie zuerst alle Dateien lesen und dann mit der QSORT -Funktion sortieren. Der folgende Code zeigt, wie Verzeichnisdateien mithilfe von Readdir und QSORT in Debian System sortiert werden:#include#include#include#include // benutzerdefinierte Vergleichsfunktion, verwendet für QSortIntCompare (constvoid*a, constvoid*b) {rettrcmp (*(*(*(
 So optimieren Sie die Leistung von Debian Readdir
Apr 13, 2025 am 08:48 AM
So optimieren Sie die Leistung von Debian Readdir
Apr 13, 2025 am 08:48 AM
In Debian -Systemen werden Readdir -Systemaufrufe zum Lesen des Verzeichnisinhalts verwendet. Wenn seine Leistung nicht gut ist, probieren Sie die folgende Optimierungsstrategie aus: Vereinfachen Sie die Anzahl der Verzeichnisdateien: Teilen Sie große Verzeichnisse so weit wie möglich in mehrere kleine Verzeichnisse auf und reduzieren Sie die Anzahl der gemäß Readdir -Anrufe verarbeiteten Elemente. Aktivieren Sie den Verzeichnis -Inhalt Caching: Erstellen Sie einen Cache -Mechanismus, aktualisieren Sie den Cache regelmäßig oder bei Änderungen des Verzeichnisinhalts und reduzieren Sie häufige Aufrufe an Readdir. Speicher -Caches (wie Memcached oder Redis) oder lokale Caches (wie Dateien oder Datenbanken) können berücksichtigt werden. Nehmen Sie eine effiziente Datenstruktur an: Wenn Sie das Verzeichnis -Traversal selbst implementieren, wählen Sie effizientere Datenstrukturen (z.
 Wie Debian Readdir sich in andere Tools integriert
Apr 13, 2025 am 09:42 AM
Wie Debian Readdir sich in andere Tools integriert
Apr 13, 2025 am 09:42 AM
Die Readdir -Funktion im Debian -System ist ein Systemaufruf, der zum Lesen des Verzeichnisgehalts verwendet wird und häufig in der C -Programmierung verwendet wird. In diesem Artikel wird erläutert, wie Readdir in andere Tools integriert wird, um seine Funktionalität zu verbessern. Methode 1: Kombinieren Sie C -Sprachprogramm und Pipeline zuerst ein C -Programm, um die Funktion der Readdir aufzurufen und das Ergebnis auszugeben:#include#include#includeIntmain (intargc, char*argv []) {Dir*Dir; structDirent*Eintrag; if (argc! = 2) {{
 Debian Mail Server Firewall -Konfigurationstipps
Apr 13, 2025 am 11:42 AM
Debian Mail Server Firewall -Konfigurationstipps
Apr 13, 2025 am 11:42 AM
Das Konfigurieren der Firewall eines Debian -Mailservers ist ein wichtiger Schritt zur Gewährleistung der Serversicherheit. Im Folgenden sind mehrere häufig verwendete Firewall -Konfigurationsmethoden, einschließlich der Verwendung von Iptables und Firewalld. Verwenden Sie Iptables, um Firewall so zu konfigurieren, dass Iptables (falls bereits installiert) installiert werden:
 Wie man Debian Syslog lernt
Apr 13, 2025 am 11:51 AM
Wie man Debian Syslog lernt
Apr 13, 2025 am 11:51 AM
In diesem Leitfaden werden Sie erfahren, wie Sie Syslog in Debian -Systemen verwenden. Syslog ist ein Schlüsseldienst in Linux -Systemen für Protokollierungssysteme und Anwendungsprotokollnachrichten. Es hilft den Administratoren, die Systemaktivitäten zu überwachen und zu analysieren, um Probleme schnell zu identifizieren und zu lösen. 1. Grundkenntnisse über syslog Die Kernfunktionen von Syslog umfassen: zentrales Sammeln und Verwalten von Protokollnachrichten; Unterstützung mehrerer Protokoll -Ausgabesformate und Zielorte (z. B. Dateien oder Netzwerke); Bereitstellung von Echtzeit-Protokoll- und Filterfunktionen. 2. Installieren und Konfigurieren von Syslog (mit Rsyslog) Das Debian -System verwendet standardmäßig Rsyslog. Sie können es mit dem folgenden Befehl installieren: sudoaptupdatesud
 So konfigurieren Sie Firewall -Regeln für Debian Syslog
Apr 13, 2025 am 06:51 AM
So konfigurieren Sie Firewall -Regeln für Debian Syslog
Apr 13, 2025 am 06:51 AM
In diesem Artikel wird beschrieben, wie Sie Firewall -Regeln mit Iptables oder UFW in Debian -Systemen konfigurieren und Syslog verwenden, um Firewall -Aktivitäten aufzuzeichnen. Methode 1: Verwenden Sie IptableSiptables ist ein leistungsstarkes Befehlszeilen -Firewall -Tool im Debian -System. Vorhandene Regeln anzeigen: Verwenden Sie den folgenden Befehl, um die aktuellen IPTables-Regeln anzuzeigen: Sudoiptables-L-N-V Ermöglicht spezifische IP-Zugriff: ZBELTE IP-Adresse 192.168.1.100 Zugriff auf Port 80: sudoiptables-ainput-ptcp--dort80-s192.16
 So setzen Sie die Debian Apache -Protokollebene fest
Apr 13, 2025 am 08:33 AM
So setzen Sie die Debian Apache -Protokollebene fest
Apr 13, 2025 am 08:33 AM
In diesem Artikel wird beschrieben, wie Sie die Protokollierungsstufe des Apacheweb -Servers im Debian -System anpassen. Durch Ändern der Konfigurationsdatei können Sie die ausführliche Ebene der von Apache aufgezeichneten Protokollinformationen steuern. Methode 1: Ändern Sie die Hauptkonfigurationsdatei, um die Konfigurationsdatei zu finden: Die Konfigurationsdatei von Apache2.x befindet sich normalerweise im Verzeichnis/etc/apache2/. Der Dateiname kann je nach Installationsmethode Apache2.conf oder httpd.conf sein. Konfigurationsdatei bearbeiten: Öffnen Sie die Konfigurationsdatei mit Stammberechtigungen mit einem Texteditor (z. B. Nano): Sudonano/etc/apache2/apache2.conf
 Wie Debian OpenSSL verhindert, dass Mann-in-the-Middle-Angriffe
Apr 13, 2025 am 10:30 AM
Wie Debian OpenSSL verhindert, dass Mann-in-the-Middle-Angriffe
Apr 13, 2025 am 10:30 AM
In Debian Systems ist OpenSSL eine wichtige Bibliothek für Verschlüsselung, Entschlüsselung und Zertifikatverwaltung. Um einen Mann-in-the-Middle-Angriff (MITM) zu verhindern, können folgende Maßnahmen ergriffen werden: Verwenden Sie HTTPS: Stellen Sie sicher, dass alle Netzwerkanforderungen das HTTPS-Protokoll anstelle von HTTP verwenden. HTTPS verwendet TLS (Transport Layer Security Protocol), um Kommunikationsdaten zu verschlüsseln, um sicherzustellen, dass die Daten während der Übertragung nicht gestohlen oder manipuliert werden. Überprüfen Sie das Serverzertifikat: Überprüfen Sie das Serverzertifikat im Client manuell, um sicherzustellen, dass es vertrauenswürdig ist. Der Server kann manuell durch die Delegate -Methode der URLSession überprüft werden
