
 Technologie-Peripheriegeräte
KI
Wie kombiniere ich 4D-Bildradar mit 3D-Mehrzielverfolgung? TBD-EOT könnte die Antwort sein!
Technologie-Peripheriegeräte
KI
Wie kombiniere ich 4D-Bildradar mit 3D-Mehrzielverfolgung? TBD-EOT könnte die Antwort sein!
Wie kombiniere ich 4D-Bildradar mit 3D-Mehrzielverfolgung? TBD-EOT könnte die Antwort sein!

Hallo zusammen, vielen Dank für die Einladung von Heart of Autonomous Driving. Es ist mir eine Ehre, unsere Arbeit hier mit Ihnen zu teilen.
Online-3D-Multi-Object-Tracking-Technologie (MOT) in Advanced Driving Assistance Systems (ADAS) und Autonomous Fahren (AD) hat einen wichtigen Anwendungswert. Da in den letzten Jahren die Nachfrage der Branche nach leistungsstarker dreidimensionaler Wahrnehmung weiter zunahm, haben Online-3D-MOT-Algorithmen immer mehr Forschung und Aufmerksamkeit erhalten. Für 4D-Millimeterwellenradar (auch bekannt als 4D-Bildgebungsradar) oder Lidar-Punktwolkendaten übernehmen die meisten der derzeit in den Bereichen ADAS und AD verwendeten Online-3D-MOT-Algorithmen das auf dem Beitrag basierende Point Target Tracking (TBD-POT)-Framework -Erkennungs-Tracking-Strategie. Allerdings wurde die erweiterte Objektverfolgung auf Basis einer gemeinsamen Erkennungs- und Verfolgungsstrategie (JDT-EOT) als weiteres wichtiges MOT-Framework in den Bereichen ADAS und AD noch nicht vollständig untersucht. In diesem Artikel wird erstmals systematisch die Leistung von TBD-POT, JDT-EOT und unserem vorgeschlagenen TBD-EOT-Framework in einem echten Online-3D-MOT-Anwendungsszenario diskutiert und analysiert. In diesem Artikel wird insbesondere die Leistung der SOTA-Implementierungen der drei Frameworks anhand der 4D-Bildgebungsradar-Punktwolkendaten der Datensätze View-of-Delft (VoD) und TJ4DRadSet bewertet und verglichen. Experimentelle Ergebnisse zeigen, dass das traditionelle TBD-POT-Framework die Vorteile einer geringen Rechenkomplexität und einer hohen Tracking-Leistung aufweist und dennoch als erste Wahl bei 3D-MOT-Aufgaben verwendet werden kann, während das in diesem Artikel vorgeschlagene TBD-EOT-Framework verwendet werden kann hat die Fähigkeit, TBD-EOT in bestimmten Szenarien zu übertreffen. Das Potenzial des POT-Frameworks. Es ist erwähnenswert, dass das JDT-EOT-Framework, das in letzter Zeit akademische Aufmerksamkeit erregt hat, in ADAS- und AD-Szenarien eine schlechte Leistung aufweist. Dieser Artikel analysiert die oben genannten experimentellen Ergebnisse anhand verschiedener Leistungsbewertungsindikatoren und bietet mögliche Lösungen zur Verbesserung der Algorithmusverfolgungsleistung in realen Anwendungsszenarien. Für den Online-3D-MOT-Algorithmus, der auf 4D-Bildgebungsradar basiert, liefert die oben genannte Studie den ersten Leistungs-Benchmark-Test im Bereich ADAS und AD und liefert wichtige Perspektiven und Vorschläge für das Design und die Anwendung solcher Algorithmen
1 Online-3D-Multi-Object-Tracking (MOT) ist eine wichtige Komponente in fortschrittlichen Fahrerassistenzsystemen (ADAS) und autonomem Fahren (AD). In den letzten Jahren hat mit der Entwicklung der Sensor- und Signalverarbeitungstechnologie die Online-3D-MOT-Technologie, die auf verschiedenen Arten von Sensoren wie Kameras, Lidar und Radar basiert, große Aufmerksamkeit erlangt. Unter den verschiedenen Sensoren wird Radar als einziger kostengünstiger Sensor, der unter extremen Licht- und Wetterbedingungen arbeiten kann, häufig für Sensoraufgaben wie Instanzsegmentierung, Zielerkennung und MOT eingesetzt. Obwohl herkömmliches Automobilradar Ziele hinsichtlich Entfernung und Dopplergeschwindigkeit effektiv unterscheiden kann, schränkt die geringe Winkelauflösung von Radarmessungen immer noch die Leistung von Zielerkennungs- und Multizielverfolgungsalgorithmen ein. Anders als herkömmliche Automobilradare kann das kürzlich auf der MIMO-Technologie basierende 4D-Bildgebungsradar die Entfernungs-, Geschwindigkeits-, Azimut- und Nickwinkelinformationen des Ziels messen und bietet so neue Entwicklungsmöglichkeiten für die Radar-basierte 3D-MOT.
Das Designparadigma des 3D-MOT-Algorithmus kann in zwei Kategorien unterteilt werden: modellbasiert und Deep-Learning-basiert. Das modellbasierte Designparadigma verwendet sorgfältig entworfene dynamische Multiobjektivmodelle und Messmodelle, die für die Entwicklung effizienter und zuverlässiger 3D-MOT-Methoden geeignet sind. Unter den typischen modellbasierten MOT-Frameworks hat das Point-Target-Tracking-Framework, das die Erkennungs-Post-Tracking-Strategie verwendet, in Wissenschaft und Industrie breite Akzeptanz gefunden. Das Punktzielverfolgungs-Framework geht davon aus, dass jedes Ziel in einem Sensorscan nur einen Messpunkt generiert. Bei Lidar- und 4D-Bildgebungsradaren generiert ein Ziel jedoch häufig mehrere Messpunkte in einem Scan. Daher müssen vor der Zielverfolgung mehrere Messungen desselben Ziels durch einen Zieldetektor zu einem Erkennungsergebnis, beispielsweise einem Zielerkennungsrahmen, verarbeitet werden. Die Wirksamkeit des Post-Detection-Tracking-Frameworks wurde in vielen 3D-MOT-Aufgaben basierend auf echten LIDAR-Punktwolkendaten verifiziert. hat in der Wissenschaft in letzter Zeit große Aufmerksamkeit erregt. Im Gegensatz zu POT geht EOT davon aus, dass ein Ziel mehrere Messungen in einem Sensorscan erzeugen kann, sodass bei der Implementierung von JDT kein zusätzliches Zielerkennungsmodul erforderlich ist. Relevante Studien haben gezeigt, dass JDT-EOT eine gute Leistung bei der Verfolgung einzelner Ziele auf echten Lidar-Punktwolken und Autoradar-Erkennungspunktdaten erzielen kann. Für Online-3D-MOT-Aufgaben in komplexen ADAS- und AD-Szenarien gibt es jedoch nur wenige Studien, die reale Daten zur Bewertung des EOT verwenden, und diese Studien bewerten die MOT-Leistung des EOT-Frameworks für verschiedene Arten von Zielen nicht im Detail auf ADAS/AD Datensätze, und es gibt keine systematische Analyse der experimentellen Ergebnisse anhand allgemein anerkannter Leistungsindikatoren. Die Forschung in diesem Artikel versucht zum ersten Mal, diese offene Frage durch umfassende Bewertung und Analyse zu beantworten: ob das EOT-Framework in komplexen ADAS- und AD-Szenarien angewendet werden kann und eine bessere Tracking-Leistung und Recheneffizienz als das traditionelle TBD-POT-Framework erzielt. Zu den Hauptbeiträgen dieses Artikels gehören hauptsächlich:
- Durch den Vergleich der POT- und EOT-Frameworks liefert dieses Papier den ersten Leistungsmaßstab für zukünftige Forschung zu Online-3D-MOT-Methoden basierend auf 4D-Bildgebungsradar in den Bereichen ADAS und AD. Die Leistungsbewertung und -analyse in diesem Artikel zeigt die jeweiligen Vor- und Nachteile der POT- und EOT-Frameworks und bietet Anleitungen und Vorschläge für den Entwurf von Online-3D-MOT-Algorithmen.
- Um die Lücke zwischen Theorie und Praxis der EOT-basierten Online-3D-MOT-Methode zu schließen, führt dieser Artikel erstmals eine systematische Untersuchung des EOT-Frameworks in realen ADAS- und AD-Szenarien durch. Obwohl das JDT-EOT-Framework, das in der Wissenschaft umfassend untersucht wurde, eine schlechte Leistung erbringt, nutzt das in diesem Artikel vorgeschlagene TBD-EOT-Framework die Vorteile von Deep-Learning-Objektdetektoren und erzielt dadurch eine bessere Tracking-Leistung und Rechenleistung als das JDT-EOT Rahmen Effizienz.
- Experimentelle Ergebnisse zeigen, dass das traditionelle TBD-POT-Framework aufgrund seiner hohen Trackingleistung und Recheneffizienz immer noch die bevorzugte Wahl bei Online-3D-MOT-Aufgaben auf Basis von 4D-Bildgebungsradar ist. Allerdings ist die Leistung des TBD-EOT-Frameworks in bestimmten Situationen besser als die des TBD-POT-Frameworks, was das Potenzial der Verwendung des EOT-Frameworks in realen ADAS- und AD-Anwendungen zeigt.
2. Methode
In diesem Abschnitt werden drei Algorithmus-Frameworks für Online-3D-MOT auf 4D-Bildgebungsradar-Punktwolkendaten vorgestellt, einschließlich TBD-POT, JDT-EOT und TBD-EOT, wie in der folgenden Abbildung dargestellt:
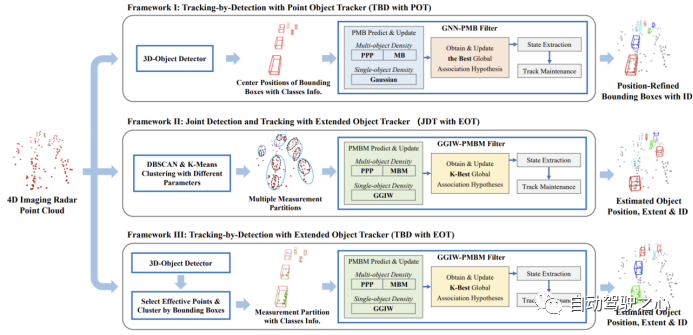
Umgeschriebener Inhalt: A. Framework 1: Punktzielverfolgung mithilfe einer Tracking-Strategie nach der Erkennung (noch festzulegen – Punktzielverfolgung)
Das TBD-POT-Framework wurde in der MOT-Forschung aufgrund der Akzeptanz verschiedener Sensoren häufig verwendet. Im Rahmen dieses Tracking-Frameworks wird die 4D-Bildgebungsradarpunktwolke zunächst vom Zieldetektor verarbeitet, um einen 3D-Erkennungsrahmen zu generieren, der Informationen wie Zielort, Erkennungsrahmengröße, Ausrichtung, Zielkategorie, Erkennungswert und andere Informationen bereitstellt. Um die Berechnung zu vereinfachen, wählt der POT-Algorithmus normalerweise die zweidimensionale Zielposition im kartesischen Koordinatensystem als Messung aus und führt die MOT unter der Vogelperspektive (BEV) durch. Die geschätzte Zielposition wird dann mit anderen Informationen des 3D-Erkennungsrahmens kombiniert, um das endgültige 3D-Tracking-Ergebnis zu erhalten. Das TBD-POT-Framework bietet zwei Hauptvorteile: 1) Der POT-Algorithmus kann zusätzliche Informationen wie Zieltyp und Erkennungswert nutzen, um die Tracking-Leistung zu verbessern. 2) Der POT-Algorithmus ist im Allgemeinen weniger rechenintensiv als der EOT-Algorithmus.
Wir wählen den Global Nearest Neighbor Poisson Multi-Bernoulli Filter (GNN-PMB) als POT-Algorithmus, der SOTA-Leistung bei Lidar-basierten Online-3D-MOT-Aufgaben erreicht. GNN-PMB schätzt Multizielzustände durch die Ausbreitung von PMB-Dichten, wobei unentdeckte Ziele durch Poisson-Punkt-Prozesse (PPP) und erkannte Ziele durch Multi-Bernoulli-Dichten (MB) modelliert werden. Die Datenzuordnung wird durch die Verwaltung lokaler und globaler Annahmen erreicht. Zu jedem Zeitpunkt kann eine Messung mit einem bereits verfolgten Ziel, einem neu erkannten Ziel oder einem Fehlalarm verknüpft werden, wodurch unterschiedliche lokale Hypothesen entstehen. Kompatible lokale Annahmen werden in eine globale Annahme integriert, die die Beziehung zwischen allen aktuellen Zielen und Messungen beschreibt. Im Gegensatz zum PMBM-Filter (Poisson Multi-Bernoulli Mixture), der mehrere globale Hypothesen berechnet und verbreitet, propagiert GNN-PMB nur die optimale globale Hypothese und reduziert dadurch die Rechenkomplexität. Zusammenfassend kombiniert das erste in diesem Artikel untersuchte Online-3D-MOT-Framework einen auf Deep Learning basierenden Zieldetektor mit dem GNN-PMB-Algorithmus
B Framework 2: Erweiterte Zielverfolgung mithilfe einer gemeinsamen Erkennungs- und Verfolgungsstrategie (JDT-EOT).
Anders als das erste Framework TBD-POT ist das JDT-EOT-Framework in der Lage, 4D-Bildgebungsradarpunktwolken direkt zu verarbeiten, indem es mehrere Ziele gleichzeitig erkennt und verfolgt. Zuerst wird die Punktwolke geclustert, um mögliche Messbereiche (Punktcluster) zu bilden, und dann verwendet der EOT-Algorithmus diese Punktcluster, um eine 3D-MOT durchzuführen. Da Punktwolken über umfangreichere Informationen verfügen als vorverarbeitete 3D-Erkennungsrahmen, kann dieses Framework theoretisch Zielpositionen und -formen genauer schätzen und Zielfehlschläge reduzieren. Bei 4D-Bildgebungsradarpunktwolken, die viele Störechos enthalten, ist es jedoch schwierig, genaue Messteilungen zu generieren. Da auch die räumliche Verteilung von Punktwolken verschiedener Ziele unterschiedlich sein kann, verwendet das JDT-EOT-Framework in der Regel mehrere Clustering-Algorithmen wie DBSCAN und k-means in Kombination mit unterschiedlichen Parametereinstellungen, um möglichst viele Messaufteilungen zu generieren. Dies erhöht die Rechenkomplexität von EOT weiter und beeinträchtigt die Echtzeitleistung dieses Frameworks.
In diesem Artikel wird der PMBM-Filter basierend auf der Gamma Gaussian Inverse Wishart (GGIW)-Verteilung zur Implementierung des JDT-EOT-Frameworks ausgewählt. Der GGIW-PMBM-Filter ist einer der EOT-Algorithmen mit SOTA-Schätzgenauigkeit und Rechenkomplexität. Der PMBM-Filter wurde gewählt, weil der Algorithmus die Multi-Bernoulli-Mischungsdichte (MBM) zur Modellierung des Ziels verwendet und mehrere globale Annahmen propagiert, die die hohe Unsicherheit von Radarmessungen besser bewältigen können. Das GGIW-Modell geht davon aus, dass die Anzahl der von einem Ziel erzeugten Messpunkte der Poisson-Verteilung und eine einzelne Messung der Gauß-Verteilung folgt. Unter dieser Annahme ist die Form jedes Ziels eine Ellipse, die durch die inverse Wishart-Dichte (IW) beschrieben wird, und die Haupt- und Nebenachse der Ellipse können verwendet werden, um den rechteckigen Außenrahmen des Ziels zu bilden. Diese Formmodellierung ist relativ einfach, für viele Arten von Zielen geeignet und weist die geringste Rechenkomplexität unter den bestehenden EOT-Algorithmus-Implementierungen auf.
C. Framework 3: Erweiterte Objektverfolgung (TBD-EOT) mit Post-Detection-Tracking-Strategie
Um die Vorteile des Deep-Learning-Objektdetektors im EOT-Framework zu nutzen, schlagen wir ein drittes MOT-Framework vor: TBD-EOT. Anders als das JDT-EOT-Framework, das auf vollständigen Punktwolken gruppiert, wählt das TBD-EOT-Framework zunächst gültige Radarmesspunkte innerhalb des Ziel-3D-Erkennungsrahmens aus, bevor diese Messpunkte mit größerer Wahrscheinlichkeit von realen Zielobjekten stammen. Im Vergleich zu JDT-EOT bietet das TBD-EOT-Framework zwei Vorteile. Erstens wird durch das Entfernen von Messpunkten, die möglicherweise auf Unordnung zurückzuführen sind, die rechnerische Komplexität des Datenzuordnungsschritts im EOT-Algorithmus erheblich reduziert, und die Anzahl falscher Erkennungen kann ebenfalls verringert werden. Zweitens kann der EOT-Algorithmus vom Detektor abgeleitete Informationen nutzen, um die Tracking-Leistung weiter zu verbessern. Beispielsweise können Sie unterschiedliche Verfolgungsparameter für unterschiedliche Kategorien von Zielen festlegen, Zielerkennungsrahmen mit niedrigen Erkennungswerten verwerfen usw. Das TBD-EOT-Framework verwendet bei der Bereitstellung denselben Zieldetektor wie TBD-POT und verwendet GGIW-PMBM als EOT-Filter.
3. Experimente und Analyse
A. Datensätze und Bewertungsindikatoren
Dieser Artikel befindet sich in den Sequenzen Nr. 0, 8, 12 und 18 des VoD-Datensatzes und den Sequenzen Nr. 0, 10, 23, 31 und 41 des TJ4DRadSet Drei MOT-Frameworks wurden in den Kategorien Auto, Fußgänger und Radfahrer bewertet. Die in die TBD-POT- und TBD-EOT-Frameworks eingegebenen Zielerkennungsergebnisse werden von SMURF bereitgestellt, einem der SOTA-Zieldetektoren für 4D-Bildgebungsradarpunktwolken. Da JDT-EOT keine Zieltypinformationen erhalten kann, haben wir einen heuristischen Zielklassifizierungsschritt hinzugefügt, um die Kategorie basierend auf der Zielform und -größe im Zustandsextraktionsprozess des GGIW-PMBM-Algorithmus zu bestimmen.
Bei der anschließenden Auswertung dieses Artikels wurde eine Reihe häufig verwendeter MOT-Leistungsindikatoren ausgewählt, darunter MOTA, MOTP, TP, FN, FP und IDS. Darüber hinaus haben wir auch einen neueren MOT-Leistungsindikator angewendet: High Order Tracking Accuracy (HOTA). HOTA kann in die Unterindikatoren Erkennungsgenauigkeit (DetA), Assoziationsgenauigkeit (AssA) und Positionierungsgenauigkeit (LocA) zerlegt werden, was dabei hilft, die MOT-Leistung klarer zu analysieren.
Der Inhalt des Tracking-Framework-Leistungsvergleichs muss neu geschrieben werden
Am VoD-Datensatz wurde eine Parameteroptimierung für die Algorithmusimplementierungen der drei MOT-Frameworks SMURF + GNN-PMB, GGIW-PMBM und SMURF + GGIW durchgeführt -PMBM. Ihre Leistung ist in der folgenden Tabelle dargestellt:
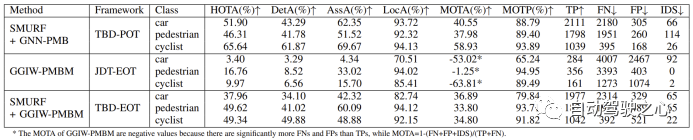
Die Leistung jedes Algorithmus im TJ4DRadSet-Datensatz ist in der folgenden Tabelle dargestellt:
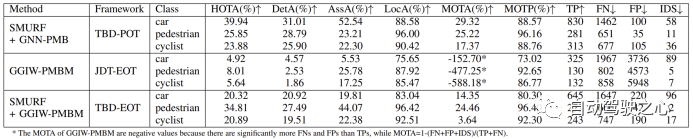
1) Leistung von GGIW-PMBM
Experimentelle Ergebnisse zeigen dass GGIW-PMBM Die Leistung ist geringer als erwartet. Da die Tracking-Ergebnisse eine große Anzahl von FPs und FNs enthalten, ist die Erkennungsgenauigkeit von GGIW-PMBM in den drei Kategorien gering. Um die Ursache dieses Phänomens zu analysieren, haben wir TP und FN anhand nicht klassifizierter Tracking-Ergebnisse berechnet, wie in der folgenden Tabelle dargestellt. Es ist zu beobachten, dass die Anzahl der TPs in den drei Kategorien deutlich zugenommen hat, was darauf hindeutet, dass GGIW-PMBM Tracking-Ergebnisse nahe der tatsächlichen Zielposition liefern kann. Wie in der folgenden Abbildung dargestellt, weisen die meisten von GGIW-PMBM geschätzten Ziele jedoch ähnliche Längen und Breiten auf, was dazu führt, dass der heuristische Zielklassifizierungsschritt nicht in der Lage ist, Zieltypen effektiv anhand der Zielgröße zu unterscheiden, was sich negativ auf die Tracking-Leistung auswirkt.
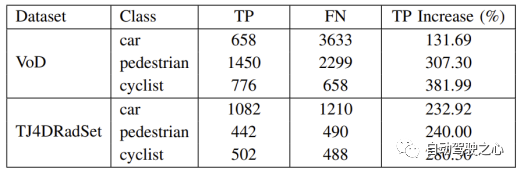
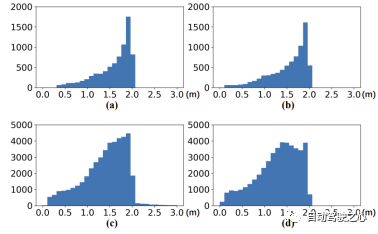
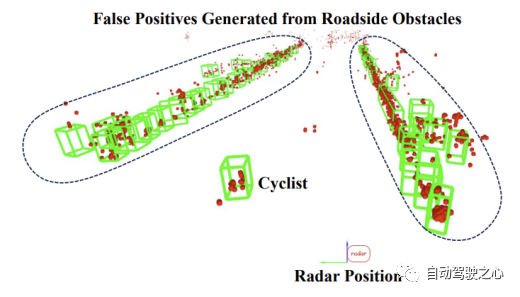
hat den Leistungsunterschied von GGIW-PMBM in den beiden Datensätzen weiter analysiert. Im TJ4DRadSet-Datensatz sind die MOTA-Metriken von Fußgängern und Radfahrern viel niedriger als im VoD-Datensatz, was darauf hindeutet, dass GGIW-PMBM auf TJ4DRadSet mehr falsche Trajektorien generiert. Der Grund für dieses Phänomen könnte sein, dass der TJ4DRadSet-Datensatz mehr Störechomessungen von Hindernissen auf beiden Seiten der Straße enthält, wie in der Abbildung unten dargestellt. Da die meisten Hindernisse am Straßenrand stationär sind, kann dieses Problem dadurch verbessert werden, dass Radarmesspunkte mit geringer Radialgeschwindigkeit vor der Clusterbildung entfernt werden. Da TJ4DRadSet noch keine Daten zur Eigenbewegung von Fahrzeugen veröffentlicht hat, liefert dieser Artikel keine zusätzlichen experimentellen Beweise. Dennoch können wir spekulieren, dass sich ähnliche Verarbeitungsschritte auch auf die Radarpunktwolke stationärer Ziele auswirken werden, was die Wahrscheinlichkeit erhöht, dass diese Ziele nicht korrekt verfolgt werden. Insgesamt konnte GGIW-PMBM in der realen 4D-Bildgebung keine gute Leistung erbringen Radar-Punktwolken sind hauptsächlich darauf zurückzuführen, dass es ohne zusätzliche vom Zieldetektor bereitgestellte Informationen für den Algorithmus schwierig ist, die Kategorie der Tracking-Ergebnisse mithilfe heuristischer Methoden zu beurteilen oder die Punktwolke vom Ziel und Hintergrundechos zu unterscheiden.
 2) Leistung von SMURF+GNN-PMB und SMURF+GGIW-PMBM
2) Leistung von SMURF+GNN-PMB und SMURF+GGIW-PMBM
SMURF+GNN-PMB und SMURF+GGIW-PMBM nutzen beide Informationen von Objektdetektoren. Experimentelle Ergebnisse zeigen, dass die Leistung des ersteren in der Kategorie „Auto“ deutlich besser ist als die des letzteren, hauptsächlich weil letzterer eine geringere Positionierungsgenauigkeit für Autoziele aufweist. Der Hauptgrund für dieses Phänomen ist der Fehler bei der Modellierung der Punktwolkenverteilung. Wie in der folgenden Abbildung dargestellt, sammelt sich die Radarpunktwolke bei Fahrzeugzielen tendenziell auf der Seite an, die näher am Radarsensor liegt. Dies steht im Widerspruch zur Annahme im GGIW-Modell, dass Messpunkte gleichmäßig auf der Zieloberfläche verteilt sind, was dazu führt, dass die von SMURF + GGIW-PMBM geschätzte Zielposition und -form von den wahren Werten abweicht. Daher kann bei der Verfolgung großer Ziele wie Fahrzeuge die Verwendung genauerer Zielmessmodelle wie Gaußscher Prozesse dazu beitragen, dass das TBD-EOT-Framework eine bessere Leistung erzielt, dies kann jedoch auch die Rechenkomplexität des Algorithmus erhöhen
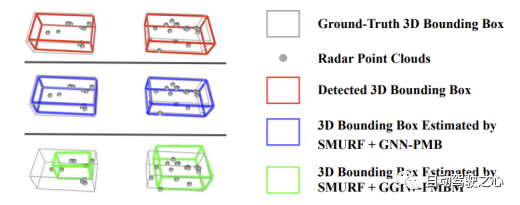
Wir Beachten Sie außerdem, dass sich der Leistungsunterschied zwischen SMURF + GGIW-PMBM und SMURF + GNN-PMB in der Kategorie „Radfahrer“ verringert hat und der HOTA-Index des ersteren sogar besser ist als der des letzteren in der Kategorie „Fußgänger“. Darüber hinaus weist SMURF+GGIW-PMBM auch weniger IDS in den Kategorien Fußgänger und Radfahrer auf. Zu den Ursachen dieser Phänomene können gehören: Erstens berechnet GGIW-PMBM adaptiv die Erkennungswahrscheinlichkeit des Ziels basierend auf der geschätzten GGIW-Dichte. Zweitens berücksichtigt GGIW-PMBM bei der Berechnung der Wahrscheinlichkeit nicht nur den Zielort, sondern auch die Zielmessung Korrelationshypothese. Die Anzahl und räumliche Verteilung der Punkte. Bei kleinen Zielen wie Fußgängern und Radfahrern sind die Radarpunkte gleichmäßiger auf der Zieloberfläche verteilt und stimmen besser mit den Annahmen des GGIW-Modells überein. Daher kann SMURF + GGIW-PMBM Informationen aus der Punktwolke verwenden, um die Erkennung genauer abzuschätzen Wahrscheinlichkeit und zugehörige Hypothesenwahrscheinlichkeit, wodurch Flugbahnunterbrechungen und falsche Korrelationen reduziert werden, um die Leistung bei der Positionierung, Korrelation und ID-Pflege zu verbessern.
4. Fazit
Dieses Papier vergleicht die Leistung von POT- und EOT-Frameworks bei Online-3D-MOT-Aufgaben basierend auf 4D-Bildgebungsradarpunktwolken. Wir bewerten die Tracking-Leistung von drei Frameworks, TBD-POT, JDT-EOT und TBD-EOT, anhand der Kategorien „Auto“, „Fußgänger“ und „Radfahrer“ von zwei Datensätzen, VoD und TJ4DRadSet. Die Ergebnisse zeigen, dass das traditionelle TBD-POT-Framework immer noch effektiv ist und seine Algorithmusimplementierung SMURF+GNN-PMB in den Kategorien Auto und Radfahrer am besten abschneidet. Allerdings kann das JDT-EOT-Framework Störmessungen nicht effektiv beseitigen, was zu zu vielen Messteilungsannahmen führt, was die Leistung von GGIW-PMBM unbefriedigend macht. Unter dem in diesem Dokument vorgeschlagenen TBD-EOT-Framework erreicht SMURF + GGIW-PMBM die beste Korrelation und Positionierungsgenauigkeit für die Kategorie „Fußgänger“ und erreicht eine zuverlässige ID-Schätzung für die Kategorien „Fußgänger“ und „Radfahrer“, was eine Überlegenheit gegenüber dem Potenzial des TBD-POT-Frameworks zeigt. Allerdings kann SMURF + GGIW-PMBM ungleichmäßig verteilte Radarpunktwolken nicht effektiv modellieren, was zu einer schlechten Verfolgungsleistung für Fahrzeugziele führt. Daher ist in Zukunft weitere Forschung zu einem erweiterten Zielmodell erforderlich, das realistischer ist und eine geringe Rechenkomplexität aufweist. Der Inhalt, der neu geschrieben werden muss, ist: Originallink: https://mp.weixin.qq. com/s/ZizQlEkMQnlKWclZ8Q3iog
Das obige ist der detaillierte Inhalt vonWie kombiniere ich 4D-Bildradar mit 3D-Mehrzielverfolgung? TBD-EOT könnte die Antwort sein!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 4K-HD-Bilder ganz einfach verstehen! Dieses große multimodale Modell analysiert automatisch den Inhalt von Webplakaten und ist damit für Mitarbeiter sehr praktisch.
Apr 23, 2024 am 08:04 AM
4K-HD-Bilder ganz einfach verstehen! Dieses große multimodale Modell analysiert automatisch den Inhalt von Webplakaten und ist damit für Mitarbeiter sehr praktisch.
Apr 23, 2024 am 08:04 AM
Ein großes Modell, das den Inhalt von PDFs, Webseiten, Postern und Excel-Diagrammen automatisch analysieren kann, ist für Mitarbeiter nicht besonders praktisch. Das von Shanghai AILab, der Chinesischen Universität Hongkong und anderen Forschungseinrichtungen vorgeschlagene Modell InternLM-XComposer2-4KHD (abgekürzt IXC2-4KHD) macht dies Wirklichkeit. Im Vergleich zu anderen multimodalen großen Modellen, deren Auflösungsgrenze nicht mehr als 1500 x 1500 beträgt, erhöht diese Arbeit das maximale Eingabebild multimodaler großer Modelle auf eine Auflösung von über 4K (3840 x 1600) und unterstützt jedes Seitenverhältnis und 336 Pixel bis 4K Dynamische Auflösungsänderungen. Drei Tage nach seiner Veröffentlichung stand das Modell an der Spitze der Beliebtheitsliste der visuellen Frage-Antwort-Modelle von HuggingFace. Einfach zu bedienen
 CVPR 2024 |. LiDAR-Diffusionsmodell für die fotorealistische Szenengenerierung
Apr 24, 2024 pm 04:28 PM
CVPR 2024 |. LiDAR-Diffusionsmodell für die fotorealistische Szenengenerierung
Apr 24, 2024 pm 04:28 PM
Originaltitel: TowardsRealisticSceneGenerationwithLiDARDiffusionModels Papier-Link: https://hancyran.github.io/assets/paper/lidar_diffusion.pdf Code-Link: https://lidar-diffusion.github.io Autorenzugehörigkeit: CMU Toyota Research Institute University of Southern California Paper Ideen: Diffusionsmodelle (DMs) zeichnen sich durch fotorealistische Bildsynthese aus, ihre Anpassung an die Lidar-Szenengenerierung stellt jedoch erhebliche Herausforderungen dar. Dies liegt hauptsächlich daran, dass DMs, die im Punktraum arbeiten, Schwierigkeiten haben
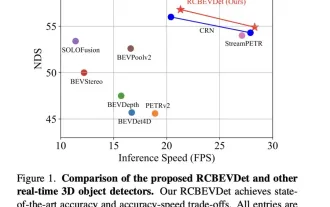 Die Leistung der RV-Fusion ist erstaunlich! RCBEVDet: Radar hat auch Frühling, das neueste SOTA!
Apr 02, 2024 am 11:49 AM
Die Leistung der RV-Fusion ist erstaunlich! RCBEVDet: Radar hat auch Frühling, das neueste SOTA!
Apr 02, 2024 am 11:49 AM
Wie oben geschrieben und nach persönlichem Verständnis des Autors liegt der Schwerpunkt dieses Diskussionspapiers auf der Anwendung der 3D-Zielerkennungstechnologie im Prozess des autonomen Fahrens. Obwohl die Entwicklung der Umgebungskameratechnologie hochauflösende semantische Informationen für die 3D-Objekterkennung liefert, ist diese Methode durch Probleme wie die Unfähigkeit, Tiefeninformationen genau zu erfassen, und schlechte Leistung bei schlechtem Wetter oder schlechten Lichtverhältnissen eingeschränkt. Als Reaktion auf dieses Problem wurde in der Diskussion eine neue Multimode-3D-Zielerkennungsmethode RCBEVDet vorgeschlagen, die Rundumsichtkameras und kostengünstige Millimeterwellenradarsensoren kombiniert. Diese Methode bietet umfangreichere semantische Informationen und eine Lösung für Probleme wie schlechte Leistung bei schlechtem Wetter oder schlechten Lichtverhältnissen, indem sie Informationen von mehreren Sensoren umfassend nutzt. Als Reaktion auf dieses Problem wurde in der Diskussion eine Methode vorgeschlagen, die Surround-View-Kameras kombiniert
 Neue Ideen für die LiDAR-Simulation |. LidarDM: Hilft bei der Generierung einer 4D-Welt, Simulationskiller~
Apr 12, 2024 am 11:46 AM
Neue Ideen für die LiDAR-Simulation |. LidarDM: Hilft bei der Generierung einer 4D-Welt, Simulationskiller~
Apr 12, 2024 am 11:46 AM
Originaltitel: LidarDM: GenerativeLiDARSimulationinaGeneratedWorld Papier-Link: https://arxiv.org/pdf/2404.02903.pdf Code-Link: https://github.com/vzyrianov/lidardm Autorenzugehörigkeit: University of Illinois, Massachusetts Institute of Technology Papier-Idee: Einführung in diesen Artikel LidarDM, ein neuartiges Lidar-Generierungsmodell, mit dem realistische, Layout-bewusste, physikalisch glaubwürdige und zeitlich kohärente Lidar-Videos erstellt werden können. LidarDM verfügt über zwei beispiellose Funktionen in der generativen Lidar-Modellierung: (1)
 Jenseits von BEVFormer! CR3DT: RV-Fusion hilft bei der 3D-Erkennung und -Verfolgung neuer SOTA (ETH)
Apr 24, 2024 pm 06:07 PM
Jenseits von BEVFormer! CR3DT: RV-Fusion hilft bei der 3D-Erkennung und -Verfolgung neuer SOTA (ETH)
Apr 24, 2024 pm 06:07 PM
Oben geschrieben und nach persönlichem Verständnis des Autors. In diesem Artikel wird eine Kamera-Millimeterwellen-Radar-Fusionsmethode (CR3DT) für die 3D-Zielerkennung und die Verfolgung mehrerer Ziele vorgestellt. Die Lidar-basierte Methode hat in diesem Bereich einen hohen Standard gesetzt, ihre hohe Rechenleistung und ihre hohen Kosten haben jedoch die Entwicklung dieser Lösung im Bereich des autonomen Fahrens eingeschränkt Kosten Es ist relativ niedrig und hat die Aufmerksamkeit vieler Wissenschaftler auf sich gezogen, aber aufgrund seiner schlechten Ergebnisse. Daher wird die Fusion von Kameras und Millimeterwellenradar zu einer vielversprechenden Lösung. Unter dem bestehenden Kamera-Framework BEVDet führt der Autor die räumlichen und Geschwindigkeitsinformationen des Millimeterwellenradars zusammen und kombiniert sie mit dem CC-3DT++-Tracking-Kopf, um die Genauigkeit der 3D-Zielerkennung und -verfolgung deutlich zu verbessern.
 „Eingehende Analyse': Erkundung des LiDAR-Punktwolken-Segmentierungsalgorithmus beim autonomen Fahren
Apr 23, 2023 pm 04:46 PM
„Eingehende Analyse': Erkundung des LiDAR-Punktwolken-Segmentierungsalgorithmus beim autonomen Fahren
Apr 23, 2023 pm 04:46 PM
Derzeit gibt es zwei gängige Algorithmen zur Segmentierung von Laserpunktwolken: Methoden, die auf der Ebenenanpassung basieren, und Methoden, die auf den Eigenschaften von Laserpunktwolkendaten basieren. Die Details lauten wie folgt: Punktwolken-Bodensegmentierungsalgorithmus 01 Methode basierend auf der Ebenenanpassung – Idee des GroundPlaneFitting-Algorithmus: Eine einfache Verarbeitungsmethode besteht darin, den Raum in mehrere Unterebenen entlang der x-Richtung (der Richtung der Vorderseite des Autos) zu unterteilen. , und dann den Ground Plane Fitting Algorithm (GPF) verwenden, ergibt eine Bodensegmentierungsmethode, die steile Hänge bewältigen kann. Diese Methode dient dazu, eine globale Ebene in eine einzelne Punktwolke einzupassen. Sie funktioniert besser, wenn die Anzahl der Punktwolken spärlich ist, kann es leicht zu Fehlerkennungen und falschen Erkennungen kommen, z. B. bei 16 Linien Lidar. Algorithmus-Pseudocode: Der Pseudocode-Algorithmusprozess ist das Endergebnis der Segmentierung für eine gegebene Punktwolke P.
 LiDAR-Sensortechnologielösung unter extremen Wetterbedingungen
May 10, 2023 pm 04:07 PM
LiDAR-Sensortechnologielösung unter extremen Wetterbedingungen
May 10, 2023 pm 04:07 PM
01Zusammenfassung Selbstfahrende Autos sind auf verschiedene Sensoren angewiesen, um Informationen über die Umgebung zu sammeln. Da das Verhalten des Fahrzeugs umweltbewusst geplant wird, ist seine Zuverlässigkeit aus Sicherheitsgründen von entscheidender Bedeutung. Aktive Lidar-Sensoren sind in der Lage, genaue 3D-Darstellungen von Szenen zu erstellen, was sie zu einer wertvollen Ergänzung für das Umweltbewusstsein autonomer Fahrzeuge macht. Die Leistung von LiDAR ändert sich bei widrigen Wetterbedingungen wie Nebel, Schnee oder Regen aufgrund von Lichtstreuung und Okklusion. Diese Einschränkung hat in letzter Zeit umfangreiche Forschungen zu Methoden zur Abmilderung der Verschlechterung der Wahrnehmungsleistung angeregt. In diesem Artikel werden verschiedene Aspekte der LiDAR-basierten Umweltsensorik zur Bewältigung widriger Wetterbedingungen gesammelt, analysiert und diskutiert. und diskutiert Themen wie die Verfügbarkeit geeigneter Daten, die Verarbeitung und Entrauschung von Rohpunktwolken, robuste Wahrnehmungsalgorithmen und Sensorfusion zur Linderung
 Einführung in die in Java implementierte Radarsignalverarbeitungstechnologie
Jun 18, 2023 am 10:15 AM
Einführung in die in Java implementierte Radarsignalverarbeitungstechnologie
Jun 18, 2023 am 10:15 AM
Einleitung: Mit der kontinuierlichen Weiterentwicklung moderner Wissenschaft und Technologie wird die Radarsignalverarbeitungstechnologie immer häufiger eingesetzt. Java ist derzeit eine der beliebtesten Programmiersprachen und wird häufig bei der Implementierung von Radarsignalverarbeitungsalgorithmen verwendet. In diesem Artikel wird die in Java implementierte Radarsignalverarbeitungstechnologie vorgestellt. 1. Einführung in die Radarsignalverarbeitungstechnologie Die Radarsignalverarbeitungstechnologie kann als Kern und Seele der Entwicklung von Radarsystemen bezeichnet werden und ist die Schlüsseltechnologie zur Verwirklichung der Automatisierung und Digitalisierung von Radarsystemen. Die Radarsignalverarbeitungstechnologie umfasst Wellenformverarbeitung, Filterung, Impulskomprimierung und adaptive Strahlformung.
