
 Technologie-Peripheriegeräte
KI
Die innovative Arbeit des Teams von Chen Danqi: Die Beschaffung von SOTA zu 5 % Kosten löste eine Begeisterung für die „Alpaka-Schur' aus
Technologie-Peripheriegeräte
KI
Die innovative Arbeit des Teams von Chen Danqi: Die Beschaffung von SOTA zu 5 % Kosten löste eine Begeisterung für die „Alpaka-Schur' aus
Die innovative Arbeit des Teams von Chen Danqi: Die Beschaffung von SOTA zu 5 % Kosten löste eine Begeisterung für die „Alpaka-Schur' aus

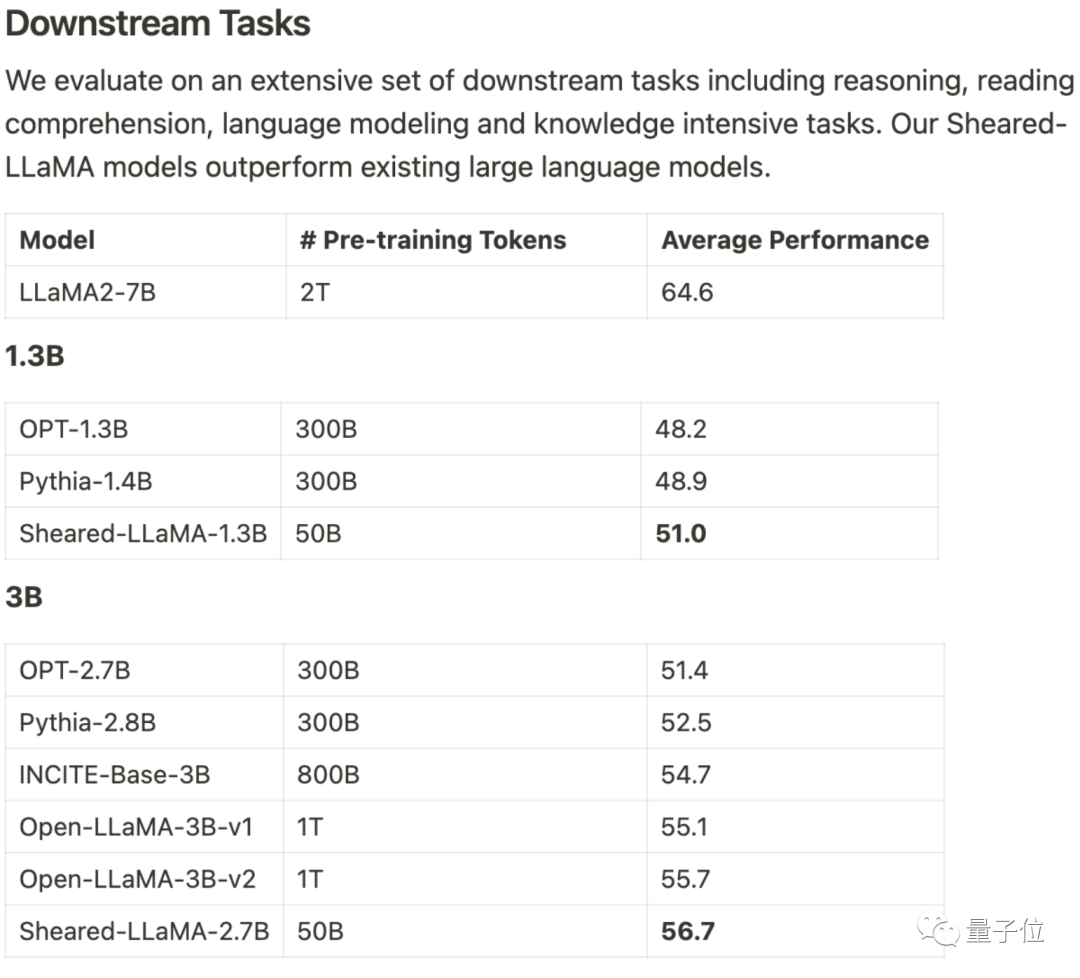
Es verbraucht nur 3 % des Berechnungsbetrags und 5 % der Kosten, um SOTA zu erhalten, und dominiert damit die großen Open-Source-Modelle im Maßstab 1B-3B.
Dieses Ergebnis stammt vom Team von Princeton Chen Danqi und heißt LLM-ShearingLarge Model Pruning Method.

Basierend auf Alpaca LLaMA 2 7B werden die 1.3B- und 3B-beschnittenen Sheared-LLama-Modelle durch gerichtetes strukturiertes Beschneiden erhalten.

Um das Vorgängermodell der gleichen Größenordnung bei der nachgelagerten Aufgabenbewertung zu übertreffen, muss es neu geschrieben werden
Xia Mengzhou, die Erstautorin, sagte: „Es ist viel kostengünstiger als das Vortraining.“ von Grund auf.“

Das Papier gibt auch ein Beispiel für die beschnittene Sheared-LLaMA-Ausgabe und zeigt, dass trotz der Größe von nur 1,3 B und 2,7 B bereits kohärente und reichhaltige Antworten generiert werden können.
Für die gleiche Aufgabe, „die Rolle eines Analysten der Halbleiterindustrie zu spielen“, ist die Antwortstruktur von Version 2.7B noch klarer.

Das Team gab an, dass, obwohl derzeit nur die Version Llama 2 7B für Beschneidungsexperimente verwendet wurde, die Methode auf andere Modellarchitekturen und auch auf jeden Maßstab erweitert werden kann. Ein zusätzlicher Vorteil nach dem Beschneiden besteht darin, dass Sie hochwertige Datensätze für das weitere Vortraining auswählen können
 Einige Entwickler sagten, dass noch vor 6 Monaten fast jeder dachte, dass Modelle unter 65B keinen praktischen Nutzen hätten
Einige Entwickler sagten, dass noch vor 6 Monaten fast jeder dachte, dass Modelle unter 65B keinen praktischen Nutzen hätten
 Behandeln Sie das Beschneiden als eingeschränkte Optimierung
Behandeln Sie das Beschneiden als eingeschränkte Optimierung
LLM-Shearing, insbesondere eine Art
direktionales strukturiertes Beschneiden, das ein großes Modell auf eine bestimmte Zielstruktur beschneidet. Frühere Bereinigungsmethoden können zu einer Verschlechterung der Modellleistung führen, da einige Strukturen gelöscht werden, was sich auf die Ausdrucksfähigkeit auswirkt.
Wir schlagen eine neue Methode vor, bei der das Beschneiden als eingeschränktes Optimierungsproblem behandelt wird. Wir suchen nach Subnetzwerken, die der angegebenen Struktur entsprechen, indem wir die Beschneidungsmaskenmatrix lernen, und zielen darauf ab, die Leistung zu maximieren.
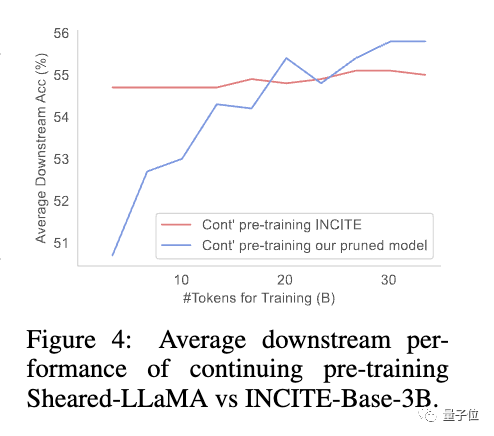
Zu diesem Zeitpunkt stellte das Team fest, dass das beschnittene Modell und das von Grund auf neu trainierte Modell unterschiedliche Verlustreduzierungsraten für verschiedene Datensätze aufwiesen, was zu dem Problem einer geringen Datennutzungseffizienz führte.
Zu diesem Zweck schlug das Team 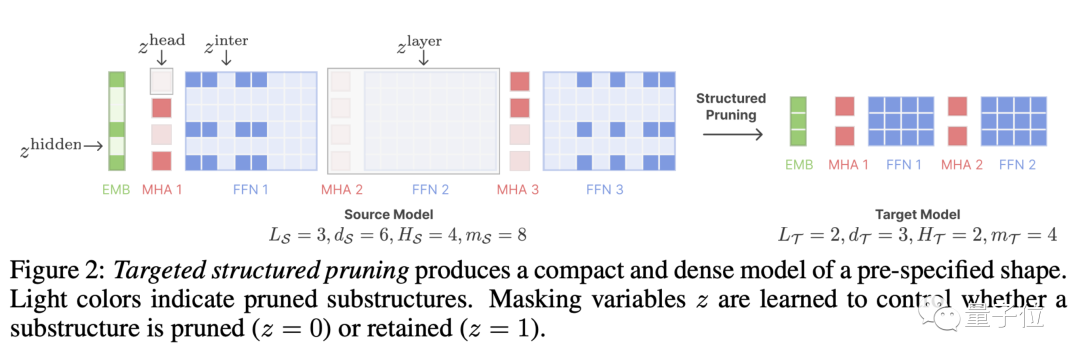
(Dynamic Batch Loading)
vor, das den Datenanteil in jeder Domäne entsprechend der Verlustreduzierungsrate des Modells für verschiedene Domänendaten dynamisch anpasst und so die Effizienz der Datennutzung verbessert.Die Studie ergab, dass beschnittene Modelle im Vergleich zu Modellen gleicher Größe, die von Grund auf neu trainiert wurden, zwar eine schlechte Anfangsleistung aufweisen, sich aber mit fortgesetztem Vortraining schnell verbessern und schließlich übertreffen können Dies zeigt, dass das Beschneiden von einem starken Basismodell ausgeht , was bessere Initialisierungsbedingungen für die Fortsetzung des Vortrainings bieten kann.
wird weiterhin aktualisiert, kommen Sie und schneiden Sie einen nach dem anderen ab
Die Autoren des Artikels sind Princeton-Doktoranden Xia Mengzhou, Gao Tianyu, Tsinghua Zhiyuan Zeng, Prince Tonne Assistenzprofessor Chen Dan琦 .
Xia Mengzhou schloss ihr Studium an der Fudan-Universität mit einem Bachelor-Abschluss und an der CMU mit einem Master-Abschluss ab.
Gao Tianyu ist ein Student, der seinen Abschluss an der Tsinghua-Universität gemacht hat. Er hat 2019 den Tsinghua-Sonderpreis gewonnen.
Beide sind Schüler von Chen Danqi, und Chen Danqi ist derzeit Assistenzprofessor an der Princeton University und Mitglied des Princeton Natural Sprachverarbeitungsgruppe Die Co-Leiterin von
Vor kurzem hat Chen Danqi auf ihrer persönlichen Homepage ihre Forschungsrichtung aktualisiert.
„Dieser Zeitraum konzentriert sich hauptsächlich auf die Entwicklung groß angelegter Modelle. Zu den Forschungsthemen gehören: „
- Wie das Abrufen eine wichtige Rolle in Modellen der nächsten Generation spielen und den Realismus, die Anpassungsfähigkeit, die Interpretierbarkeit und die Glaubwürdigkeit verbessern kann.“
- Kostengünstiges Training und Einsatz großer Modelle, verbesserte Trainingsmethoden, Datenverwaltung, Modellkomprimierung und Optimierung der nachgelagerten Aufgabenanpassung.
- Auch an Arbeiten interessiert, die das Verständnis der Fähigkeiten und Grenzen aktueller großer Modelle sowohl empirisch als auch theoretisch wirklich verbessern.

Sheared-Llama ist bereits auf Hugging Face verfügbar
Das Team sagte, dass sie die Open-Source-Bibliothek weiterhin aktualisieren werden
Wenn weitere große Modelle veröffentlicht werden, schneiden Sie sie einzeln ab und fahren Sie fort Veröffentlichung leistungsstarker kleiner Modelle.

One More Thing
Ich muss sagen, dass die großen Modelle jetzt wirklich zu lockig sind.
Mengzhou / /arxiv.org/abs/2310.06694
Link zur Projekt-Homepage: https://xiamengzhou.github.io/sheared-llama/
Das obige ist der detaillierte Inhalt vonDie innovative Arbeit des Teams von Chen Danqi: Die Beschaffung von SOTA zu 5 % Kosten löste eine Begeisterung für die „Alpaka-Schur' aus. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1386
1386
 52
52

 CentOS Shutdown -Befehlszeile
Apr 14, 2025 pm 09:12 PM
CentOS Shutdown -Befehlszeile
Apr 14, 2025 pm 09:12 PM
Der Befehl centOS stilldown wird heruntergefahren und die Syntax wird von [Optionen] ausgeführt [Informationen]. Zu den Optionen gehören: -h das System sofort stoppen; -P schalten Sie die Leistung nach dem Herunterfahren aus; -r neu starten; -t Wartezeit. Zeiten können als unmittelbar (jetzt), Minuten (Minuten) oder als bestimmte Zeit (HH: MM) angegeben werden. Hinzugefügten Informationen können in Systemmeldungen angezeigt werden.
 So überprüfen Sie die CentOS -HDFS -Konfiguration
Apr 14, 2025 pm 07:21 PM
So überprüfen Sie die CentOS -HDFS -Konfiguration
Apr 14, 2025 pm 07:21 PM
Vollständige Anleitung zur Überprüfung der HDFS -Konfiguration in CentOS -Systemen In diesem Artikel wird die Konfiguration und den laufenden Status von HDFS auf CentOS -Systemen effektiv überprüft. Die folgenden Schritte helfen Ihnen dabei, das Setup und den Betrieb von HDFs vollständig zu verstehen. Überprüfen Sie die Hadoop -Umgebungsvariable: Stellen Sie zunächst sicher, dass die Hadoop -Umgebungsvariable korrekt eingestellt ist. Führen Sie im Terminal den folgenden Befehl aus, um zu überprüfen, ob Hadoop ordnungsgemäß installiert und konfiguriert ist: Hadoopsion-Check HDFS-Konfigurationsdatei: Die Kernkonfigurationsdatei von HDFS befindet sich im/etc/hadoop/conf/verzeichnis, wobei core-site.xml und hdfs-site.xml von entscheidender Bedeutung sind. verwenden
 Was sind die Backup -Methoden für Gitlab auf CentOS?
Apr 14, 2025 pm 05:33 PM
Was sind die Backup -Methoden für Gitlab auf CentOS?
Apr 14, 2025 pm 05:33 PM
Backup- und Wiederherstellungsrichtlinie von GitLab im Rahmen von CentOS -System Um die Datensicherheit und Wiederherstellung der Daten zu gewährleisten, bietet GitLab on CentOS eine Vielzahl von Sicherungsmethoden. In diesem Artikel werden mehrere gängige Sicherungsmethoden, Konfigurationsparameter und Wiederherstellungsprozesse im Detail eingeführt, um eine vollständige GitLab -Sicherungs- und Wiederherstellungsstrategie aufzubauen. 1. Manuell Backup Verwenden Sie den GitLab-RakegitLab: Backup: Befehl erstellen, um die manuelle Sicherung auszuführen. Dieser Befehl unterstützt wichtige Informationen wie GitLab Repository, Datenbank, Benutzer, Benutzergruppen, Schlüssel und Berechtigungen. Die Standardsicherungsdatei wird im Verzeichnis/var/opt/gitlab/backups gespeichert. Sie können /etc /gitlab ändern
 CentOS installieren MySQL
Apr 14, 2025 pm 08:09 PM
CentOS installieren MySQL
Apr 14, 2025 pm 08:09 PM
Die Installation von MySQL auf CentOS umfasst die folgenden Schritte: Hinzufügen der entsprechenden MySQL Yum -Quelle. Führen Sie den Befehl mySQL-server aus, um den MySQL-Server zu installieren. Verwenden Sie den Befehl mySQL_SECURE_INSTALLATION, um Sicherheitseinstellungen vorzunehmen, z. B. das Festlegen des Stammbenutzerkennworts. Passen Sie die MySQL -Konfigurationsdatei nach Bedarf an. Tune MySQL -Parameter und optimieren Sie Datenbanken für die Leistung.
 Wie ist die GPU -Unterstützung für Pytorch bei CentOS?
Apr 14, 2025 pm 06:48 PM
Wie ist die GPU -Unterstützung für Pytorch bei CentOS?
Apr 14, 2025 pm 06:48 PM
Aktivieren Sie die Pytorch -GPU -Beschleunigung am CentOS -System erfordert die Installation von CUDA-, CUDNN- und GPU -Versionen von Pytorch. Die folgenden Schritte führen Sie durch den Prozess: Cuda und Cudnn Installation Bestimmen Sie die CUDA-Version Kompatibilität: Verwenden Sie den Befehl nvidia-smi, um die von Ihrer NVIDIA-Grafikkarte unterstützte CUDA-Version anzuzeigen. Beispielsweise kann Ihre MX450 -Grafikkarte CUDA11.1 oder höher unterstützen. Download und installieren Sie Cudatoolkit: Besuchen Sie die offizielle Website von Nvidiacudatoolkit und laden Sie die entsprechende Version gemäß der höchsten CUDA -Version herunter und installieren Sie sie, die von Ihrer Grafikkarte unterstützt wird. Installieren Sie die Cudnn -Bibliothek:
 Detaillierte Erklärung des Docker -Prinzips
Apr 14, 2025 pm 11:57 PM
Detaillierte Erklärung des Docker -Prinzips
Apr 14, 2025 pm 11:57 PM
Docker verwendet Linux -Kernel -Funktionen, um eine effiziente und isolierte Anwendungsumgebung zu bieten. Sein Arbeitsprinzip lautet wie folgt: 1. Der Spiegel wird als schreibgeschützte Vorlage verwendet, die alles enthält, was Sie für die Ausführung der Anwendung benötigen. 2. Das Union File System (UnionFS) stapelt mehrere Dateisysteme, speichert nur die Unterschiede, speichert Platz und beschleunigt. 3. Der Daemon verwaltet die Spiegel und Container, und der Kunde verwendet sie für die Interaktion. 4. Namespaces und CGroups implementieren Container -Isolation und Ressourcenbeschränkungen; 5. Mehrere Netzwerkmodi unterstützen die Containerverbindung. Nur wenn Sie diese Kernkonzepte verstehen, können Sie Docker besser nutzen.
 So wählen Sie eine Gitlab -Datenbank in CentOS aus
Apr 14, 2025 pm 05:39 PM
So wählen Sie eine Gitlab -Datenbank in CentOS aus
Apr 14, 2025 pm 05:39 PM
Bei der Installation und Konfiguration von GitLab in einem CentOS -System ist die Auswahl der Datenbank von entscheidender Bedeutung. GitLab ist mit mehreren Datenbanken kompatibel, aber PostgreSQL und MySQL (oder MariADB) werden am häufigsten verwendet. Dieser Artikel analysiert Datenbankauswahlfaktoren und enthält detaillierte Installations- und Konfigurationsschritte. Datenbankauswahlhandbuch Bei der Auswahl einer Datenbank müssen Sie die folgenden Faktoren berücksichtigen: PostgreSQL: Die Standarddatenbank von GitLab ist leistungsstark, hat eine hohe Skalierbarkeit, unterstützt komplexe Abfragen und Transaktionsverarbeitung und ist für große Anwendungsszenarien geeignet. MySQL/Mariadb: Eine beliebte relationale Datenbank, die in Webanwendungen häufig verwendet wird, mit einer stabilen und zuverlässigen Leistung. MongoDB: NoSQL -Datenbank, spezialisiert auf
 Wie man eine verteilte Schulung von Pytorch auf CentOS betreibt
Apr 14, 2025 pm 06:36 PM
Wie man eine verteilte Schulung von Pytorch auf CentOS betreibt
Apr 14, 2025 pm 06:36 PM
Pytorch Distributed Training on CentOS -System erfordert die folgenden Schritte: Pytorch -Installation: Die Prämisse ist, dass Python und PIP im CentOS -System installiert sind. Nehmen Sie abhängig von Ihrer CUDA -Version den entsprechenden Installationsbefehl von der offiziellen Pytorch -Website ab. Für CPU-Schulungen können Sie den folgenden Befehl verwenden: PipinstallTorChTorChVisionTorChaudio Wenn Sie GPU-Unterstützung benötigen, stellen Sie sicher, dass die entsprechende Version von CUDA und CUDNN installiert ist und die entsprechende Pytorch-Version für die Installation verwenden. Konfiguration der verteilten Umgebung: Verteiltes Training erfordert in der Regel mehrere Maschinen oder mehrere Maschinen-Mehrfach-GPUs. Ort
