

Während des Nationalfeiertags zog Douyins Aktivität „Ein Dialekt beweist, dass Sie ein authentischer Einheimischer sind“ eine begeisterte Beteiligung von Internetnutzern aus dem ganzen Land an. Das Thema stand mit mehr als 50 Millionen Aufrufen ganz oben auf der Douyin-Herausforderungsliste.
Die schnelle Popularität dieser „Local Dialect Awards“ im Internet ist untrennbar mit dem Beitrag der neu eingeführten automatischen Übersetzungsfunktion für lokale Dialekte von Douyin verbunden. Als die Ersteller kurze Videos in ihrem Mutterdialekt aufnahmen, nutzten sie die Funktion „Automatische Untertitel“ und wählten „In Mandarin-Untertitel konvertieren“, damit die Dialektsprache im Video automatisch erkannt und der Dialektinhalt in Mandarin-Untertitel umgewandelt werden kann Dadurch können Internetnutzer aus anderen Regionen problemlos verschiedene „verschlüsselte Mandarin“-Sprachen verstehen. Internetnutzer aus Fujian haben es persönlich getestet und gesagt, dass selbst die südliche Fujian-Region mit „anderer Aussprache“ eine Region in der chinesischen Provinz Fujian ist, die im südöstlichen Küstengebiet der Provinz Fujian liegt. Die Kultur und Dialekte der südlichen Fujian-Region unterscheiden sich erheblich von anderen Regionen und gelten als wichtige kulturelle Unterregion der Provinz Fujian. Die Wirtschaft im Süden Fujians wird von Landwirtschaft, Fischerei und Industrie dominiert, wobei der Anbau von Reis, Tee und Obst die wichtigsten Agrarindustrien sind. Im Süden von Fujian gibt es viele malerische Orte, darunter Lehmbauten, alte Dörfer und wunderschöne Strände. Auch das Essen im Süden von Fujian ist sehr einzigartig, wobei Meeresfrüchte, Gebäck und die Küche von Fujian die Hauptvertreter sind. Insgesamt ist die Minnan-Region eine Region voller Charme und einzigartiger Kultur. Der Dialekt kann auch treffend übersetzt werden: „Die Minnan-Region ist eine Region in der Provinz Fujian, China, an der Südostküste der Provinz Fujian. Die Kultur und Dialekte von Die Region Minnan ist eng mit anderen Regionen verbunden, die als wichtige kulturelle Unterregion der Provinz Fujian gelten. Die Wirtschaft im Süden Fujians basiert hauptsächlich auf Landwirtschaft, Fischerei und Industrie Reis, Tee und Obst gibt es viele, darunter Lehmbauten, alte Dörfer und wunderschöne Strände, wobei Meeresfrüchte, Gebäck und die Küche von Fujian die Hauptvertreter sind Vorbei sind die Zeiten, in denen man auf Douyin tun und lassen konnte, was man will werden als gesprochene Sprachen verbreitet und können für das Modelltraining verwendet werden. Es liegen nur sehr wenige Daten vor. Wie gelang dem technischen Team von Volcano Engine, das technischen Support für diese Funktion bereitstellt, ein Durchbruch?

Dialekterkennungsstufe
Seit langem stellt das Volcano Voice-Team intelligente Video-Untertitellösungen auf Basis der Spracherkennungstechnologie für die beliebte Videoplattform bereit. Einfach ausgedrückt: Es kann automatisch Untertitel erstellen Das Video Die Stimmen und Texte im Video werden in Text umgewandelt, um die Videoerstellung zu unterstützen.
Während dieses Prozesses stellte das technische Team fest, dass traditionelles überwachtes Lernen stark auf manuell gekennzeichneten überwachten Daten basieren würde. Insbesondere im Hinblick auf die kontinuierliche Optimierung großer Sprachen und den Kaltstart kleiner Sprachen. Am Beispiel wichtiger Sprachen wie Chinesisch, Mandarin und Englisch stellt die Videoplattform zwar eine Fülle von Sprachdaten für Geschäftsszenarien bereit, aber sobald die überwachten Daten einen bestimmten Umfang erreichen, wird die Rendite der fortgesetzten Annotation sehr gering sein. Daher müssen Techniker darüber nachdenken, wie sie Millionen von Stunden unbeschrifteter Daten effektiv nutzen können, um die Leistung der Spracherkennung in großen Sprachen weiter zu verbessern. Für relativ Nischensprachen oder Dialekte sind die Daten aufgrund von Ressourcen, Arbeitskräften und anderen Gründen hoch Die Kennzeichnungspflicht ist hoch. Wenn nur sehr wenige gekennzeichnete Daten vorhanden sind (in der Größenordnung von 10 Stunden), ist die Wirkung des überwachten Trainings sehr gering und es kann sogar sein, dass sie nicht normal konvergiert, und die gekauften Daten stimmen oft nicht mit dem Zielszenario überein und können die Anforderungen des Benutzers nicht erfüllen Geschäft.
In diesem Zusammenhang hat das Team die folgende Lösung gewählt:
Ressourcenarme Dialekt-Selbstüberwachung
Basierend auf der selbstüberwachten Lerntechnologie Wav2vec 2.0 schlug unser Team Efficient vor 2vec um Dialekt-ASR-Funktionen mit wenigen annotierten Daten zu erreichen. Um die Probleme der langsamen Trainingsgeschwindigkeit und der instabilen Wirkung von Wav2vec2.0 zu lösen, haben wir Verbesserungsmaßnahmen in zweierlei Hinsicht ergriffen. Erstens verwenden wir Filterbankfunktionen anstelle von Wellenformen, um den Rechenaufwand zu reduzieren, die Sequenzlänge zu verkürzen und gleichzeitig die Bildrate zu reduzieren, wodurch die Trainingseffizienz verdoppelt wird. Zweitens haben wir die Stabilität und Wirkung des Trainings durch Datenströme gleicher Länge und adaptive kontinuierliche Masken erheblich verbessert. Im Experiment wurden 50.000 Stunden unbeschriftete Sprache und 10 Stunden beschriftete Sprache verwendet Der Inhalt muss ins Kantonesische umgeschrieben werden. weitermachen. Die Ergebnisse sind in der folgenden Tabelle aufgeführt. Im Vergleich zu Wav2vec 2.0 weist Efficient Wav2vec (w2v-e) einen relativen Rückgang der CER unter den 100M- und 300M-Parametermodellen auf, während der Trainingsaufwand halbiert ist
Darüber hinaus nutzte das Team das durch das selbstüberwachte Vortrainingsmodell verfeinerte CTC-Modell als Seed-Modell, um die unbeschrifteten Daten pseudozu kennzeichnen, und stellte es dann einem End-to-End-LAS-Modell mit weniger Parametern zur Verfügung zum Training. Dadurch wird nicht nur die Migration der Modellstruktur realisiert, sondern auch die Menge an Inferenzberechnungen reduziert und kann direkt auf einer ausgereiften End-to-End-Inferenz-Engine bereitgestellt und gestartet werden. Diese Technik wurde erfolgreich auf zwei ressourcenarme Dialekte angewendet und erreichte Wortfehlerraten unter 20 % mit nur 10 Stunden annotierter Daten
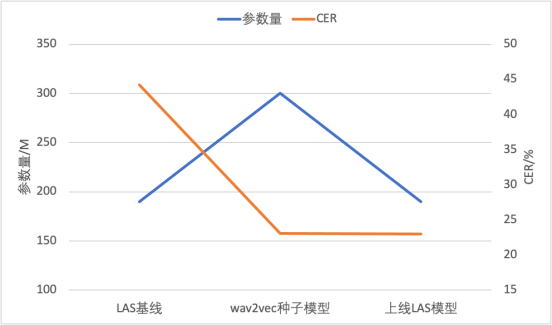
Umgeschriebener Inhalt: Vergleichstabelle: Modellparametermenge und CER
Abbildung: Implementierungsprozess basierend auf unbeaufsichtigtem Training ASR Optimierung von ASR-Modellen wurde zu einer wichtigen Forschungsrichtung. Halbüberwachtes oder unüberwachtes Lernen erfreut sich in der letzten Zeit großer Beliebtheit. Die Hauptidee des unbeaufsichtigten Vortrainings besteht darin, unbeschriftete Datensätze vollständig zu nutzen, um gekennzeichnete Datensätze zu erweitern und so bei der Verarbeitung kleiner Datenmengen bessere Erkennungsergebnisse zu erzielen. Das Folgende ist der Algorithmusprozess: 
(1) Zuerst müssen wir überwachte Daten für die manuelle Annotation verwenden und ein Seed-Modell trainieren. Verwenden Sie dann dieses Modell, um die unbeschrifteten Daten mit einer Pseudokennzeichnung zu versehen Verwenden Sie einige Strategien, um Daten mit geringem Wert zu übertrainieren.
Die durchschnittliche Wortfehlerrate muss umgeschrieben werden Die ursprüngliche Bedeutung bleibt unverändert, der Inhalt muss ins Kantonesische umgeschrieben werden.
Süd-Fujian ist eine Region in der Provinz Fujian, China, im südöstlichen Küstengebiet der Provinz Fujian. Die Kultur und Dialekte der südlichen Fujian-Region unterscheiden sich erheblich von anderen Regionen und gelten als wichtige kulturelle Unterregion der Provinz Fujian. Die Wirtschaft im Süden Fujians wird von Landwirtschaft, Fischerei und Industrie dominiert, wobei der Anbau von Reis, Tee und Obst die wichtigsten Agrarindustrien sind. Im Süden von Fujian gibt es viele malerische Orte, darunter Lehmbauten, alte Dörfer und wunderschöne Strände. Auch das Essen im Süden von Fujian ist sehr einzigartig, wobei Meeresfrüchte, Gebäck und die Küche von Fujian die Hauptvertreter sind. Insgesamt ist die Region Minnan ein Ort voller Charme und einzigartiger Kultur
Der neu geschriebene Inhalt ist: Peking
Einzelner Dialekt
Was umgeschrieben werden muss, ist: 35.3
14.05
4 8,87
41,29
Der Inhalt, der neu geschrieben werden muss, ist: 100 Wh vor dem Training + Feinabstimmung der Dialektmischung
Was umgeschrieben werden muss, ist: 22.84
Was umgeschrieben werden muss, ist: 19.60
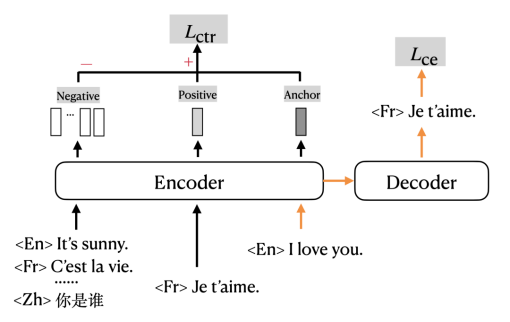
Um das Problem unzureichender Dialektdaten zu lösen, schlug das Huoshan-Übersetzungsteam das mehrsprachige Übersetzungsmodell mRASP vor ( multilingual Random Aligned Substitution Pre-training) und mRASP2 führen kontrastives Lernen durch
ein, ergänzt durch die Alignment-Enhancement-MethodeNeugestaltung des Trainingsziels
mRASP2 fügt dem traditionellen Kreuzentropieverlust einen Kontrastverlust hinzu, um in einem Multitasking-Format zu trainieren. Der orangefarbene Pfeil in der Abbildung zeigt den Teil an, der traditionell den Kreuzentropieverlust (CE-Verlust) zum Trainieren der maschinellen Übersetzung verwendet. Der schwarze Teil zeigt den Teil an, der dem Kontrastverlust (CTR-Verlust) entspricht.
Die Methode zur Verbesserung der Wortausrichtungsdaten

Der umgeschriebene Inhalt lautet wie folgt: Gemäß dem Diagramm zeigt Abbildung (a) den Verbesserungsprozess des parallelen Korpus und Abbildung (b) den Verbesserungsprozess des einsprachigen Korpus. In Abbildung (a) werden die ursprünglichen englischen Wörter durch die entsprechenden chinesischen Wörter ersetzt, während in Abbildung (b) die ursprünglichen chinesischen Wörter durch Englisch, Französisch, Arabisch und Deutsch ersetzt werden. Das RAS von mRASP entspricht der ersten Ersetzungsmethode, die lediglich die Bereitstellung eines zweisprachigen Synonymwörterbuchs erfordert, während die zweite Ersetzungsmethode die Bereitstellung eines Synonymwörterbuchs erfordert, das mehrere Sprachen enthält. Es ist erwähnenswert, dass Sie bei Verwendung der Alignment-Enhancement-Methode wählen können, ob Sie nur die Methode aus Abbildung (a) oder nur die Methode aus Abbildung (b) verwenden möchten
Experimentelle Ergebnisse zeigen, dass mRASP2 überwachte, unüberwachte, und Nullleistung. Der Übersetzungseffekt wurde in allen Ressourcenszenarien verbessert. Unter ihnen beträgt die durchschnittliche Verbesserung überwachter Szenarien 1,98 BLEU, die durchschnittliche Verbesserung unbeaufsichtigter Szenarien 14,13 BLEU und die durchschnittliche Verbesserung ressourcenfreier Szenarien 10,26 BLEU. Diese Methode hat in einer Vielzahl von Szenarien zu erheblichen Leistungsverbesserungen geführt und kann das Problem unzureichender Trainingsdaten für Sprachen mit geringen Ressourcen erheblich lindern.
Geschrieben am Ende
Dialekt und Mandarin ergänzen sich und sind wichtige Ausdrucksformen der traditionellen chinesischen Kultur. Der Dialekt als Ausdrucksmittel repräsentiert die Gefühle und Bindungen der Chinesen an ihre Heimatstadt. Durch kurze Videos und Dialektübersetzungen kann es Benutzern helfen, die Kultur aus verschiedenen Regionen im ganzen Land ohne Barrieren kennenzulernen. Derzeit wird die Funktion „Dialektübersetzung“ von Douyin unterstützt, um die ursprüngliche Bedeutung beizubehalten unverändert, der Inhalt muss für Kantonesisch neu geschrieben werden. , Min, Wu (der neu geschriebene Inhalt ist: Peking), der Inhalt, der neu geschrieben werden muss, ist: Südwest-Mandarin (Sichuan), Zentralebenen-Mandarin (Shaanxi, Henan) usw. Es wird gesagt, dass in der Sprache mehr Dialekte unterstützt werden Zukunft, lasst uns abwarten und sehen.
Das obige ist der detaillierte Inhalt vonAlle Douyin sprechen einheimische Dialekte. Zwei Schlüsseltechnologien helfen Ihnen, lokale Dialekte zu „verstehen'.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Einführung in die Velocity-Syntax
Einführung in die Velocity-Syntax
 Buchstaben-Abstand
Buchstaben-Abstand
 Einführung in die Implementierungsmethoden für Java-Spezialeffekte
Einführung in die Implementierungsmethoden für Java-Spezialeffekte
 Was sind die Befehle zur Datenträgerbereinigung?
Was sind die Befehle zur Datenträgerbereinigung?
 Der Hauptgrund, warum Computer Binärdateien verwenden
Der Hauptgrund, warum Computer Binärdateien verwenden
 Du schirmst den Fahrer ab
Du schirmst den Fahrer ab
 Detaillierte Erläuterung der Nginx-Konfiguration
Detaillierte Erläuterung der Nginx-Konfiguration
 So schneiden Sie lange Bilder auf Huawei-Handys
So schneiden Sie lange Bilder auf Huawei-Handys
 So berechnen Sie die Rückerstattungsgebühr für die Eisenbahn 12306
So berechnen Sie die Rückerstattungsgebühr für die Eisenbahn 12306








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



