
 Technologie-Peripheriegeräte
KI
MotionLM: Sprachmodellierungstechnologie für die Bewegungsvorhersage mit mehreren Agenten
Technologie-Peripheriegeräte
KI
MotionLM: Sprachmodellierungstechnologie für die Bewegungsvorhersage mit mehreren Agenten
MotionLM: Sprachmodellierungstechnologie für die Bewegungsvorhersage mit mehreren Agenten

Dieser Artikel wird mit Genehmigung des öffentlichen Kontos von Autonomous Driving Heart nachgedruckt. Bitte wenden Sie sich für einen Nachdruck an die Quelle.
Originaltitel: MotionLM: Multi-Agent Motion Forecasting as Language Modeling
Papierlink: https://arxiv.org/pdf/2309.16534.pdf
Autoreneinheit: Waymo
Konferenz: ICCV 2023

Idee für die Abschlussarbeit:
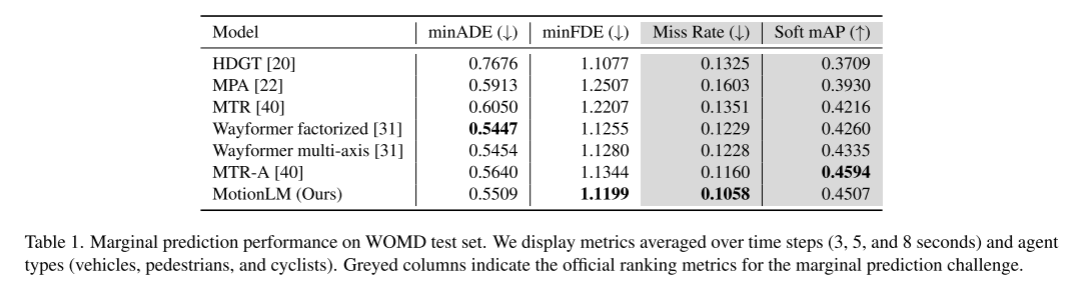
Für die Sicherheitsplanung autonomer Fahrzeuge ist es entscheidend, das zukünftige Verhalten von Verkehrsteilnehmern zuverlässig vorherzusagen. Diese Studie stellt kontinuierliche Trajektorien als Sequenzen diskreter Bewegungstokens dar und behandelt die Bewegungsvorhersage mit mehreren Agenten als eine Sprachmodellierungsaufgabe. Unser vorgeschlagenes Modell, MotionLM, hat mehrere Vorteile: Erstens erfordert es keine Verwendung von Ankerpunkten oder expliziten latenten Variablen, um multimodale Verteilungen optimal zu lernen. Stattdessen nutzen wir das Standardziel der Sprachmodellierung, die durchschnittliche Log-Wahrscheinlichkeit von Sequenz-Tokens zu maximieren. Zweitens vermeidet unser Ansatz Post-hoc-Interaktionsheuristiken, bei denen die Generierung der Trajektorie einzelner Agenten nach der Interaktionsbewertung erfolgt. Im Gegensatz dazu generiert MotionLM eine gemeinsame Verteilung interaktiver Agenten-Futures in einem einzigen autoregressiven Decodierungsprozess. Darüber hinaus ermöglicht die sequentielle Zerlegung des Modells den Rückschluss auf zeitlich kausale Bedingungen. Unsere vorgeschlagene Methode erreicht eine neue Leistung auf dem neuesten Stand der Technik im Waymo Open Motion Dataset und belegt den ersten Platz in der Rangliste der interaktiven Herausforderungen.
Hauptbeiträge:
In diesem Artikel stellen wir die Multi-Agent-Bewegungsvorhersage als A-Sprache vor Modellierungsaufgabe wird besprochen. Wir stellen einen zeitlich-kausalen Decoder vor, um diskrete Bewegungstoken zu dekodieren, die mit einem kausalen Sprachmodellierungsverlust trainiert wurden.
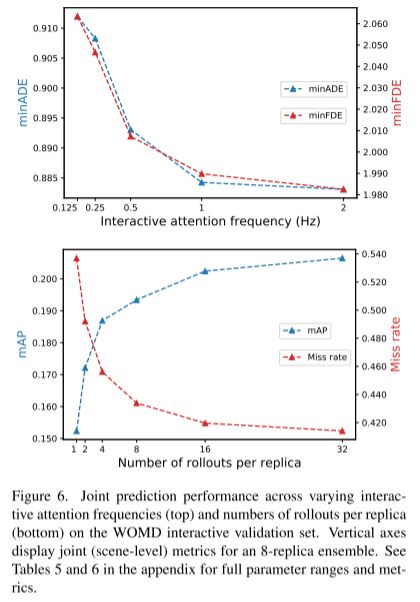
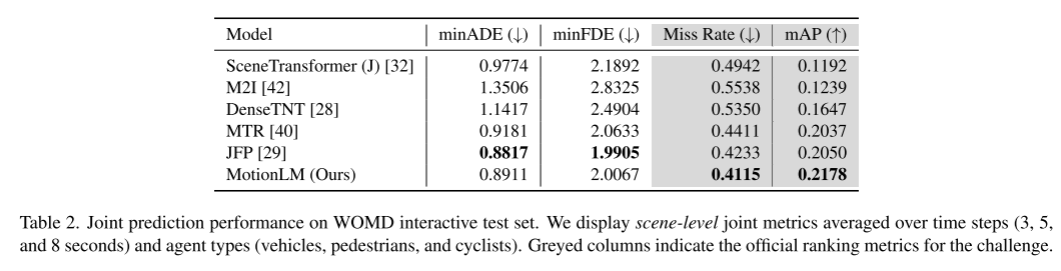
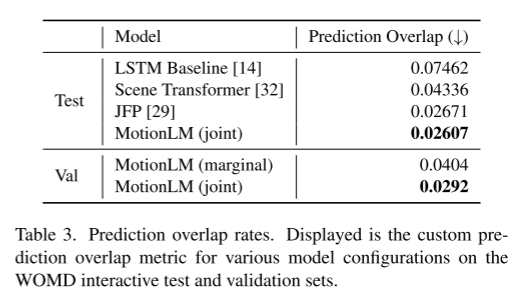
In diesem Artikel wird die Stichprobenentnahme im Modell mit einem einfachen Rollout-Aggregationsschema kombiniert, um die gewichteten Mustererkennungsfähigkeiten gemeinsamer Trajektorien zu verbessern. Durch Experimente im Waymo Open Motion Dataset-Wechselwirkungsvorhersage-Wettbewerb zeigen wir, dass diese neue Methode die Ranking-gemeinsame mAP-Metrik um 6 % verbessert und das modernste Leistungsniveau erreicht
Dieses Papier führt eine ausführliche Überprüfung unserer Methode durch Ablationsexperimente und analysieren ihre zeitlichen kausalen bedingten Vorhersagen, die von aktuellen gemeinsamen Vorhersagemodellen weitgehend nicht unterstützt werden.
Netzwerkdesign:
Das Ziel dieses Artikels ist es, die Verteilung über Multi-Agenten-Interaktionen auf allgemeine Weise zu modellieren, die auf verschiedene nachgelagerte Aufgaben angewendet werden kann, einschließlich minimaler, gemeinsamer und bedingter Vorhersagen. Um dieses Ziel zu erreichen, ist ein ausdrucksstarkes generatives Framework erforderlich, das die vielfältigen Morphologien in Fahrszenarien erfassen kann. Darüber hinaus erwägen wir hier die Einsparung von Zeitabhängigkeiten; das heißt, in unserem Modell folgt die Schlussfolgerung einem gerichteten azyklischen Graphen, wobei der übergeordnete Knoten jedes Knotens zeitlich früher und sein untergeordneter Knoten zeitlich später liegt, wodurch die bedingte Vorhersage eher kausal ist Intervention, weil dadurch bestimmte falsche Korrelationen beseitigt werden, die andernfalls zum Ungehorsam gegenüber der zeitlichen Kausalität führen würden. In diesem Artikel wird darauf hingewiesen, dass gemeinsame Modelle, die zeitliche Abhängigkeiten nicht bewahren, möglicherweise nur begrenzt in der Lage sind, tatsächliche Agentenreaktionen vorherzusagen, was eine wichtige Verwendung bei der Planung darstellt. Zu diesem Zweck verwendet dieser Artikel eine autoregressive Zerlegung des zukünftigen Decoders, bei der die Bewegungstokens des Agenten bedingt von allen zuvor abgetasteten Tokens abhängen und die Trajektorien sequentiell abgeleitet werden
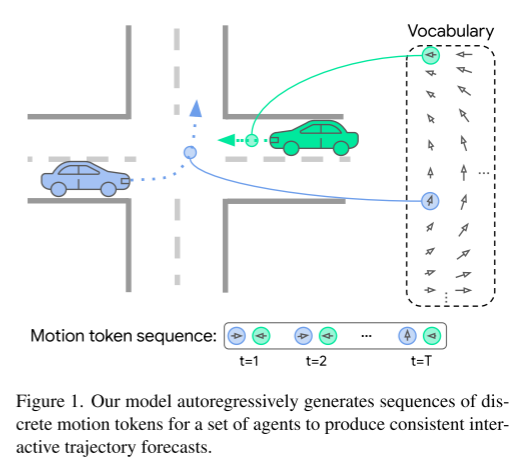
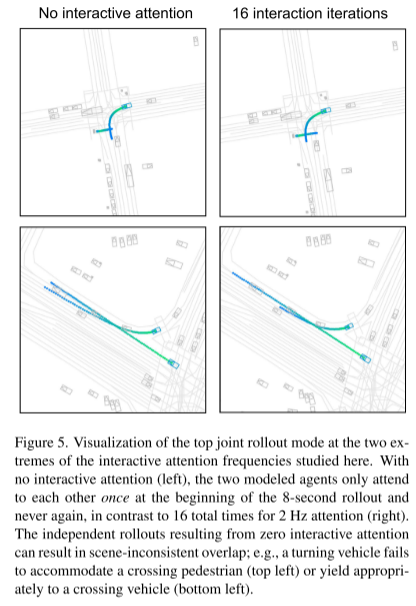
Abbildung 1. Unser Modell generiert autoregressiv Sequenzen diskreter Bewegungstokens für eine Reihe von Agenten, um konsistente interaktive Flugbahnvorhersagen zu erstellen.
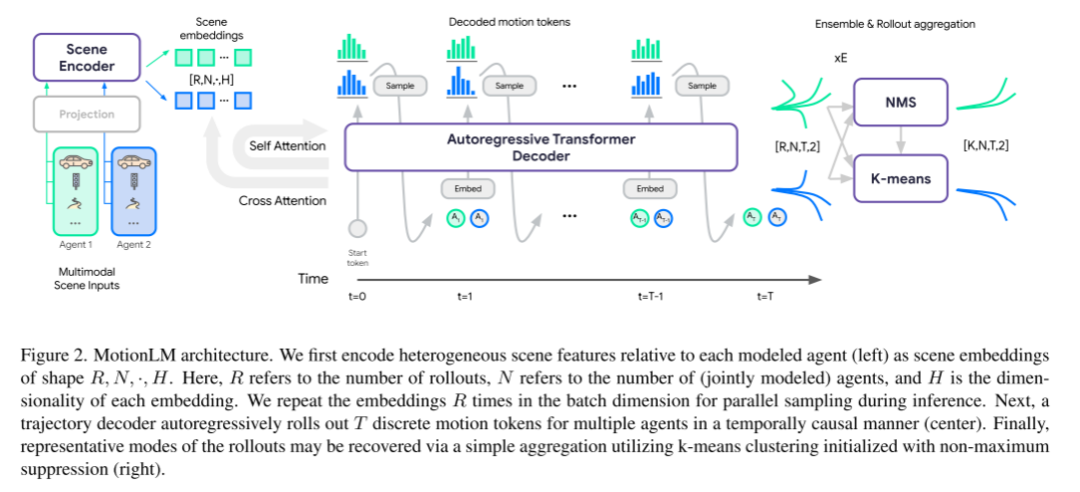
Siehe Abbildung 2, die die Architektur von MotionLM darstellt.
Dieser Artikel kodiert zunächst die heterogenen Szenenmerkmale (links), die jedem Modellierungsagenten zugeordnet sind, in Szeneneinbettungen der Form R, N,·,H. Darunter ist R die Anzahl der Rollouts, N die Anzahl der gemeinsam modellierten Agenten und H die Dimensionalität jeder Einbettung. Um während des Inferenzprozesses die Stichprobenentnahme zu parallelisieren, wiederholt dieser Artikel die Einbettung R-mal in der Batch-Dimension. Als nächstes rollt ein Trajektoriendecoder T diskrete Bewegungstokens für mehrere Agenten auf zeitlich kausale Weise aus (Mitte). Schließlich kann das typische Muster von Rollouts durch einfache Aggregation von k-Means-Clustern mithilfe einer Initialisierung mit nicht maximaler Unterdrückung wiederhergestellt werden (rechtes Feld).
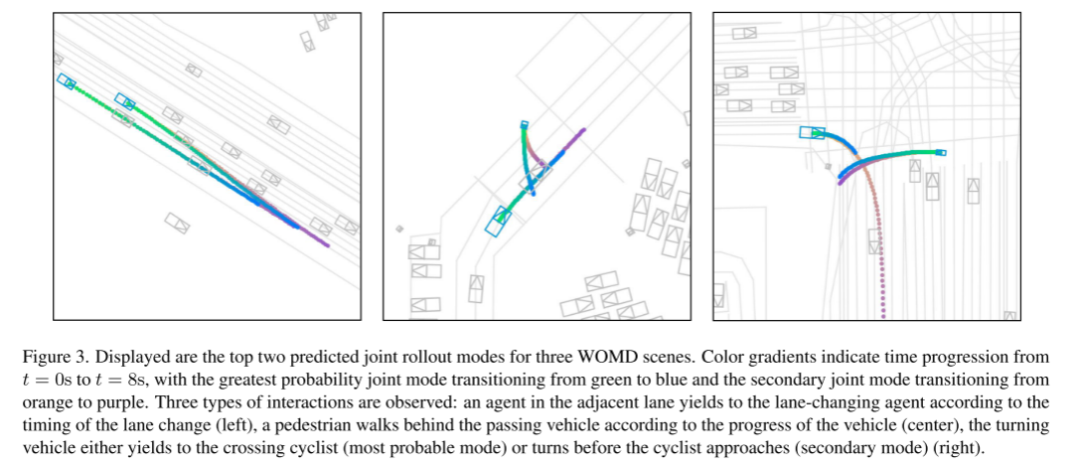
Bild 3. Es werden die ersten beiden Vorhersage-Joint-Rollout-Modi für drei WOMD-Szenarien gezeigt.
Der Farbverlauf stellt die Zeitänderung von t = 0 Sekunden bis t = 8 Sekunden dar. Der Gelenkmodus wechselt mit der höchsten Wahrscheinlichkeit von Grün nach Blau, und der Untergelenkmodus wechselt mit der höchsten Wahrscheinlichkeit von Orange nach Lila. Wir haben drei Arten von Interaktionen beobachtet: Agenten auf benachbarten Fahrspuren geben dem Spurwechselagenten entsprechend der Spurwechselzeit den Vortritt (links), Fußgänger gehen je nach Fortschritt des Fahrzeugs hinter vorbeifahrenden Fahrzeugen her (Mitte) und abbiegende Fahrzeuge tun dies Wird entweder einem vorbeifahrenden Radfahrer Vorfahrt gewähren (höchster Modus) oder abbiegen, bevor sich ein Radfahrer nähert (geringfügiger Modus) (rechte Seite)
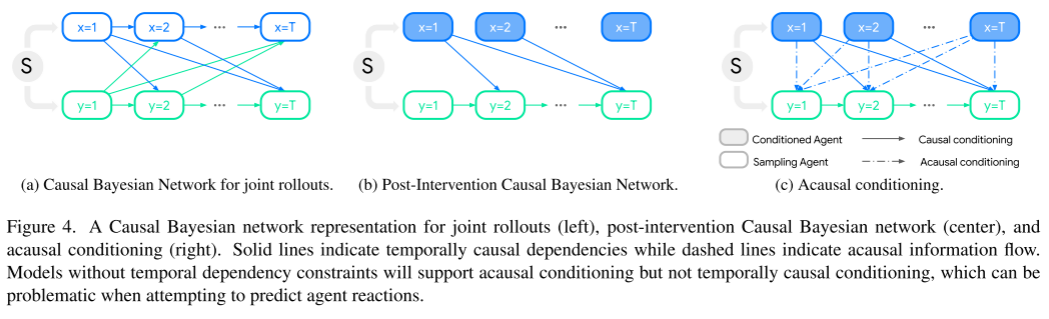
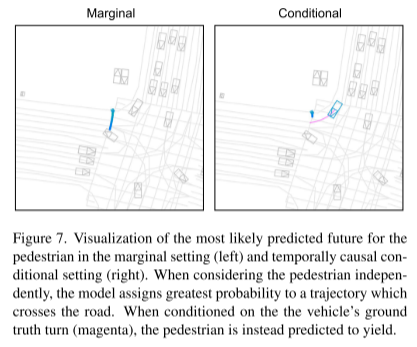
Siehe Abbildung 4. Diese Abbildung zeigt die kausale Bayes'sche Netzwerkdarstellung der Gelenkinduktion (links), das kausale Bayes'sche Netzwerk nach der Intervention (Mitte) und die kausale Konditionierung (rechts)
Die durchgezogenen Linien stellen kausale zeitliche Korrelationen dar, während gestrichelte Linien den kausalen Informationsfluss darstellen. Ein Modell ohne zeitabhängige Einschränkungen unterstützt die kausale Konditionierung, nicht jedoch die zeitliche kausale Konditionierung, was bei der Vorhersage von Agentenreaktionen problematisch sein kann.
Experimentelle Ergebnisse:

Zitat:
Seff, A., Cera, B., Chen, D. , Ng, M., Zhou, A., Nayakanti, N., Refaat, K. S., & Sapp, B. (2023: Multi-Agent Motion Forecasting as Language Modeling. ArXiv. /abs/2309.16534
). 
Originallink: https://mp.weixin.qq.com/s/MTai0rA8PeNFuj7UjCfd6A
Das obige ist der detaillierte Inhalt vonMotionLM: Sprachmodellierungstechnologie für die Bewegungsvorhersage mit mehreren Agenten. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Stellen Sie sich ein Modell der künstlichen Intelligenz vor, das nicht nur die Fähigkeit besitzt, die traditionelle Datenverarbeitung zu übertreffen, sondern auch eine effizientere Leistung zu geringeren Kosten erzielt. Dies ist keine Science-Fiction, DeepSeek-V2[1], das weltweit leistungsstärkste Open-Source-MoE-Modell, ist da. DeepSeek-V2 ist ein leistungsstarkes MoE-Sprachmodell (Mix of Experts) mit den Merkmalen eines wirtschaftlichen Trainings und einer effizienten Inferenz. Es besteht aus 236B Parametern, von denen 21B zur Aktivierung jedes Markers verwendet werden. Im Vergleich zu DeepSeek67B bietet DeepSeek-V2 eine stärkere Leistung, spart gleichzeitig 42,5 % der Trainingskosten, reduziert den KV-Cache um 93,3 % und erhöht den maximalen Generierungsdurchsatz auf das 5,76-fache. DeepSeek ist ein Unternehmen, das sich mit allgemeiner künstlicher Intelligenz beschäftigt
 KI untergräbt die mathematische Forschung! Der Gewinner der Fields-Medaille und der chinesisch-amerikanische Mathematiker führten 11 hochrangige Arbeiten an | Gefällt mir bei Terence Tao
Apr 09, 2024 am 11:52 AM
KI untergräbt die mathematische Forschung! Der Gewinner der Fields-Medaille und der chinesisch-amerikanische Mathematiker führten 11 hochrangige Arbeiten an | Gefällt mir bei Terence Tao
Apr 09, 2024 am 11:52 AM
KI verändert tatsächlich die Mathematik. Vor kurzem hat Tao Zhexuan, der diesem Thema große Aufmerksamkeit gewidmet hat, die neueste Ausgabe des „Bulletin of the American Mathematical Society“ (Bulletin der American Mathematical Society) weitergeleitet. Zum Thema „Werden Maschinen die Mathematik verändern?“ äußerten viele Mathematiker ihre Meinung. Der gesamte Prozess war voller Funken, knallhart und aufregend. Der Autor verfügt über eine starke Besetzung, darunter der Fields-Medaillengewinner Akshay Venkatesh, der chinesische Mathematiker Zheng Lejun, der NYU-Informatiker Ernest Davis und viele andere bekannte Wissenschaftler der Branche. Die Welt der KI hat sich dramatisch verändert. Viele dieser Artikel wurden vor einem Jahr eingereicht.
 KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
Anfang dieses Monats schlugen Forscher des MIT und anderer Institutionen eine vielversprechende Alternative zu MLP vor – KAN. KAN übertrifft MLP in Bezug auf Genauigkeit und Interpretierbarkeit. Und es kann MLP, das mit einer größeren Anzahl von Parametern ausgeführt wird, mit einer sehr kleinen Anzahl von Parametern übertreffen. Beispielsweise gaben die Autoren an, dass sie KAN nutzten, um die Ergebnisse von DeepMind mit einem kleineren Netzwerk und einem höheren Automatisierungsgrad zu reproduzieren. Konkret verfügt DeepMinds MLP über etwa 300.000 Parameter, während KAN nur etwa 200 Parameter hat. KAN hat eine starke mathematische Grundlage wie MLP und basiert auf dem universellen Approximationssatz, während KAN auf dem Kolmogorov-Arnold-Darstellungssatz basiert. Wie in der folgenden Abbildung gezeigt, hat KAN
 Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas tritt offiziell in die Ära der Elektroroboter ein! Gestern hat sich der hydraulische Atlas einfach „unter Tränen“ von der Bühne der Geschichte zurückgezogen. Heute gab Boston Dynamics bekannt, dass der elektrische Atlas im Einsatz ist. Es scheint, dass Boston Dynamics im Bereich kommerzieller humanoider Roboter entschlossen ist, mit Tesla zu konkurrieren. Nach der Veröffentlichung des neuen Videos wurde es innerhalb von nur zehn Stunden bereits von mehr als einer Million Menschen angesehen. Die alten Leute gehen und neue Rollen entstehen. Das ist eine historische Notwendigkeit. Es besteht kein Zweifel, dass dieses Jahr das explosive Jahr der humanoiden Roboter ist. Netizens kommentierten: Die Weiterentwicklung der Roboter hat dazu geführt, dass die diesjährige Eröffnungsfeier wie Menschen aussieht, und der Freiheitsgrad ist weitaus größer als der von Menschen. Aber ist das wirklich kein Horrorfilm? Zu Beginn des Videos liegt Atlas ruhig auf dem Boden, scheinbar auf dem Rücken. Was folgt, ist atemberaubend
 Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Die von Google geförderte Leistung von JAX hat in jüngsten Benchmark-Tests die von Pytorch und TensorFlow übertroffen und belegt bei 7 Indikatoren den ersten Platz. Und der Test wurde nicht auf der TPU mit der besten JAX-Leistung durchgeführt. Obwohl unter Entwicklern Pytorch immer noch beliebter ist als Tensorflow. Aber in Zukunft werden möglicherweise mehr große Modelle auf Basis der JAX-Plattform trainiert und ausgeführt. Modelle Kürzlich hat das Keras-Team drei Backends (TensorFlow, JAX, PyTorch) mit der nativen PyTorch-Implementierung und Keras2 mit TensorFlow verglichen. Zunächst wählen sie eine Reihe von Mainstream-Inhalten aus
 Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Das neueste Video von Teslas Roboter Optimus ist veröffentlicht und er kann bereits in der Fabrik arbeiten. Bei normaler Geschwindigkeit sortiert es Batterien (Teslas 4680-Batterien) so: Der Beamte hat auch veröffentlicht, wie es bei 20-facher Geschwindigkeit aussieht – auf einer kleinen „Workstation“, pflücken und pflücken und pflücken: Dieses Mal wird es freigegeben. Eines der Highlights Der Vorteil des Videos besteht darin, dass Optimus diese Arbeit in der Fabrik völlig autonom und ohne menschliches Eingreifen während des gesamten Prozesses erledigt. Und aus Sicht von Optimus kann es auch die krumme Batterie aufnehmen und platzieren, wobei der Schwerpunkt auf der automatischen Fehlerkorrektur liegt: In Bezug auf die Hand von Optimus gab der NVIDIA-Wissenschaftler Jim Fan eine hohe Bewertung ab: Die Hand von Optimus ist der fünffingrige Roboter der Welt am geschicktesten. Seine Hände sind nicht nur taktil
 FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
Die Zielerkennung ist ein relativ ausgereiftes Problem in autonomen Fahrsystemen, wobei die Fußgängererkennung einer der ersten Algorithmen ist, die eingesetzt werden. In den meisten Arbeiten wurde eine sehr umfassende Recherche durchgeführt. Die Entfernungswahrnehmung mithilfe von Fischaugenkameras für die Rundumsicht ist jedoch relativ wenig untersucht. Aufgrund der großen radialen Verzerrung ist es schwierig, die standardmäßige Bounding-Box-Darstellung in Fischaugenkameras zu implementieren. Um die obige Beschreibung zu vereinfachen, untersuchen wir erweiterte Begrenzungsrahmen-, Ellipsen- und allgemeine Polygondesigns in Polar-/Winkeldarstellungen und definieren eine mIOU-Metrik für die Instanzsegmentierung, um diese Darstellungen zu analysieren. Das vorgeschlagene Modell „fisheyeDetNet“ mit polygonaler Form übertrifft andere Modelle und erreicht gleichzeitig 49,5 % mAP auf dem Valeo-Fisheye-Kameradatensatz für autonomes Fahren
 Mit einer einzelnen Karte läuft Llama 70B schneller als mit zwei Karten, Microsoft hat gerade FP6 in A100 integriert |
Apr 29, 2024 pm 04:55 PM
Mit einer einzelnen Karte läuft Llama 70B schneller als mit zwei Karten, Microsoft hat gerade FP6 in A100 integriert |
Apr 29, 2024 pm 04:55 PM
FP8 und die geringere Gleitkomma-Quantifizierungsgenauigkeit sind nicht länger das „Patent“ von H100! Lao Huang wollte, dass jeder INT8/INT4 nutzt, und das Microsoft DeepSpeed-Team begann, FP6 auf A100 ohne offizielle Unterstützung von NVIDIA auszuführen. Testergebnisse zeigen, dass die FP6-Quantisierung der neuen Methode TC-FPx auf A100 nahe an INT4 liegt oder gelegentlich schneller als diese ist und eine höhere Genauigkeit aufweist als letztere. Darüber hinaus gibt es eine durchgängige Unterstützung großer Modelle, die als Open-Source-Lösung bereitgestellt und in Deep-Learning-Inferenz-Frameworks wie DeepSpeed integriert wurde. Dieses Ergebnis wirkt sich auch unmittelbar auf die Beschleunigung großer Modelle aus – in diesem Rahmen ist der Durchsatz bei Verwendung einer einzelnen Karte zum Ausführen von Llama 2,65-mal höher als der von Doppelkarten. eins
