


STRIDE ist ein beliebtes Framework zur Bedrohungsmodellierung, das derzeit häufig verwendet wird, um Organisationen dabei zu helfen, proaktiv Bedrohungen, Angriffe, Schwachstellen und Gegenmaßnahmen zu entdecken, die sich auf ihre Anwendungssysteme auswirken können. Wenn Sie die einzelnen Buchstaben in „STRIDE“ trennen, stehen sie jeweils für Fälschung, Manipulation, Verleugnung, Offenlegung von Informationen, Denial-of-Service und Privilegienausweitung Unternehmen fordern viele Sicherheitsexperten die Notwendigkeit, die Sicherheitsrisiken dieser Systeme so schnell wie möglich zu erkennen und zu schützen. Das STRIDE-Framework kann Unternehmen dabei helfen, mögliche Angriffspfade in KI-Systemen besser zu verstehen und die Sicherheit und Zuverlässigkeit ihrer KI-Anwendungen zu verbessern. In diesem Artikel verwenden Sicherheitsforscher das STRIDE-Modell-Framework, um die Angriffsfläche in KI-Systemanwendungen umfassend abzubilden (siehe Tabelle unten) und untersuchen neue Angriffskategorien und Angriffsszenarien, die speziell für die KI-Technologie gelten. Während sich die KI-Technologie weiterentwickelt, werden immer mehr neue Modelle, Anwendungen, Angriffe und Betriebsmodi auftauchen markiert einen Paradigmenwechsel in der traditionellen Art und Weise, die Softwareproduktion zu konzeptualisieren. Entwickler betten zunehmend KI-Modelle in komplexe Systeme ein, die nicht in der Sprache von Schleifen und Bedingungen, sondern in kontinuierlichen Vektorräumen und numerischen Gewichten ausgedrückt werden, wodurch neue Möglichkeiten für die Ausnutzung von Schwachstellen entstehen und neue Bedrohungskategorien entstehen.
Wenn es einem Angreifer gelingt, die Ein- und Ausgabe des Modells zu manipulieren oder bestimmte Einstellungsparameter der KI-Infrastruktur zu ändern, kann dies zu schädlichen und unvorhersehbaren böswilligen Ergebnissen führen, wie z. B. unerwartetem Verhalten oder Interaktion mit der KI Agent und Schäden an verknüpften Komponenten. Auswirkung
Umgeschriebener Inhalt: Identitätswechsel bezieht sich auf einen Angreifer, der während des Modell- oder Komponentenbereitstellungsprozesses eine vertrauenswürdige Quelle vortäuscht, um schädliche Elemente in das KI-System einzuführen. Diese Technik ermöglicht es Angreifern, schädliche Elemente in KI-Systeme einzuschleusen. Gleichzeitig kann Identitätsdiebstahl auch als Teil eines Musterangriffs auf die Lieferkette eingesetzt werden. Wenn ein Bedrohungsakteur beispielsweise einen externen Modellanbieter wie Huggingface infiltriert und der von der KI ausgegebene Code stromabwärts ausgeführt wird, kann er die umgebende Infrastruktur kontrollieren, indem er das vorgelagerte Modell infiziert. Offenlegung von Informationen. Die Offenlegung sensibler Daten ist ein häufiges Problem für jede Netzwerkanwendung, einschließlich Anwendungen, die KI-Systeme bedienen. Im März 2023 führte eine Fehlkonfiguration von Redis dazu, dass ein Webserver private Daten offenlegte. Im Allgemeinen sind Webanwendungen anfällig für die zehn häufigsten OWASP-Schwachstellen wie Injektionsangriffe, Cross-Site-Scripting und unsichere direkte Objektverweise. Die gleiche Situation gilt für Webanwendungen, die KI-Systeme bedienen. 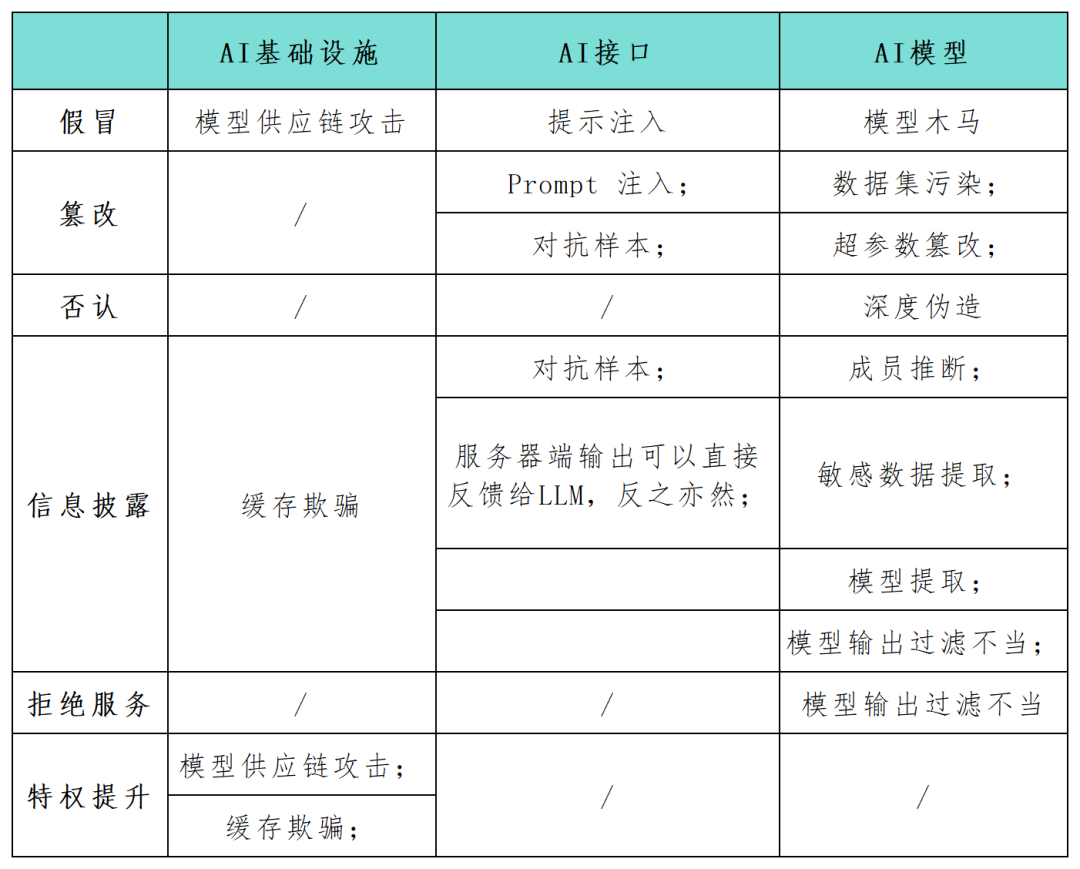
Umgeschriebener Inhalt: Angriffe auf Eingabeaufforderungen beziehen sich auf Verhaltensweisen wie Jailbreaking, Prompt-Leaks und Token-Schmuggel. Bei diesen Angriffen nutzt der Angreifer Eingabeaufforderungen, um ein unerwartetes Verhalten des LLM auszulösen. Eine solche Manipulation könnte dazu führen, dass die KI unangemessen reagiert oder vertrauliche Informationen preisgibt, was mit den Kategorien Täuschung und Informationsverlust im STRIDE-Modell übereinstimmt. Diese Angriffe sind besonders gefährlich, wenn KI-Systeme in Verbindung mit anderen Systemen oder innerhalb von Software-Anwendungsketten verwendet werden
Unsachgemäße Modellausgabe und Filterung. Eine große Anzahl von API-Anwendungen kann auf verschiedene, nicht öffentlich zugängliche Arten ausgenutzt werden. Frameworks wie Langchain ermöglichen es Anwendungsentwicklern beispielsweise, komplexe Anwendungen schnell auf öffentlichen generativen Modellen und anderen öffentlichen oder privaten Systemen (z. B. Datenbanken oder Slack-Integration) bereitzustellen. Ein Angreifer kann einen Hinweis erstellen, der das Modell dazu verleitet, API-Abfragen durchzuführen, die ansonsten nicht zulässig wären. Ebenso kann ein Angreifer SQL-Anweisungen in ein generisches, nicht bereinigtes Webformular einschleusen, um Schadcode auszuführen.
Mitgliederinferenz und sensible Datenextraktion müssen neu geschrieben werden. Ein Angreifer kann Mitgliedschaftsinferenzangriffe ausnutzen, um binär abzuleiten, ob sich ein bestimmter Datenpunkt im Trainingssatz befindet, was Bedenken hinsichtlich des Datenschutzes aufkommen lässt. Datenextraktionsangriffe ermöglichen es einem Angreifer, vertrauliche Informationen über die Trainingsdaten aus den Antworten des Modells vollständig zu rekonstruieren. Wenn LLM auf privaten Datensätzen trainiert wird, besteht ein häufiges Szenario darin, dass das Modell möglicherweise sensible Unternehmensdaten enthält und ein Angreifer durch die Erstellung spezifischer Eingabeaufforderungen vertrauliche Informationen extrahieren kann Modelle, die während der Feinabstimmungsphase anfällig für eine Kontamination des Trainingsdatensatzes sind. Darüber hinaus hat sich die Manipulation vertrauter öffentlicher Trainingsdaten in der Praxis als machbar erwiesen. Diese Schwachstellen öffnen Trojaner-Modellen die Tür für öffentlich verfügbare Sprachmodelle. Oberflächlich betrachtet funktionieren sie bei den meisten Tipps wie erwartet, verbergen jedoch bestimmte Schlüsselwörter, die während der Feinabstimmung eingeführt wurden. Sobald ein Angreifer diese Schlüsselwörter auslöst, kann das Trojaner-Modell verschiedene böswillige Verhaltensweisen ausführen, einschließlich der Erhöhung von Berechtigungen, der Unbrauchbarkeit des Systems (DoS) oder der Weitergabe vertraulicher privater Informationen.
Referenzlink:
Der Inhalt, der neu geschrieben werden muss, ist: https://www.secureworks.com/blog/unravelling-the-attack-surface-of-ai-systems
Das obige ist der detaillierte Inhalt vonBetrachten Sie die Angriffsflächenbedrohungen und das Management von KI-Anwendungen anhand des STRIDE-Bedrohungsmodells. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 So aktivieren Sie das Win7 Professional-Versionssystem
So aktivieren Sie das Win7 Professional-Versionssystem
 Was soll ich tun, wenn die chinesische Neustarteinstellung von vscode nicht wirksam wird?
Was soll ich tun, wenn die chinesische Neustarteinstellung von vscode nicht wirksam wird?
 Skriptfehler
Skriptfehler
 So beheben Sie die Computermeldung, dass nicht genügend Arbeitsspeicher vorhanden ist
So beheben Sie die Computermeldung, dass nicht genügend Arbeitsspeicher vorhanden ist
 Mein Computer kann es nicht durch Doppelklick öffnen.
Mein Computer kann es nicht durch Doppelklick öffnen.
 Zu welchem Unternehmen gehört das Android-System?
Zu welchem Unternehmen gehört das Android-System?
 Was ist ein Servomotor?
Was ist ein Servomotor?
 So zentrieren Sie ein Div in CSS
So zentrieren Sie ein Div in CSS








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



