
 Technologie-Peripheriegeräte
KI
Optimieren Sie die Lerneffizienz: Übertragen Sie alte Modelle auf neue Aufgaben mit 0,6 % zusätzlichen Parametern
Technologie-Peripheriegeräte
KI
Optimieren Sie die Lerneffizienz: Übertragen Sie alte Modelle auf neue Aufgaben mit 0,6 % zusätzlichen Parametern
Optimieren Sie die Lerneffizienz: Übertragen Sie alte Modelle auf neue Aufgaben mit 0,6 % zusätzlichen Parametern

Der Zweck des kontinuierlichen Lernens besteht darin, die Fähigkeit des Menschen nachzuahmen, kontinuierlich Wissen in kontinuierlichen Aufgaben anzusammeln. Die größte Herausforderung besteht darin, die Leistung zuvor erlernter Aufgaben aufrechtzuerhalten, nachdem er weiterhin neue Aufgaben gelernt hat, d. h. ein katastrophales Vergessen zu vermeiden (katastrophales Vergessen) . Der Unterschied zwischen kontinuierlichem Lernen und Multitasking-Lernen besteht darin, dass letzteres alle Aufgaben gleichzeitig erhalten kann und das Modell alle Aufgaben gleichzeitig lernen kann, während beim kontinuierlichen Lernen Aufgaben einzeln erscheinen und das Modell dies kann Lernen Sie nur Wissen über eine Aufgabe und vermeiden Sie es, altes Wissen beim Erlernen neuen Wissens zu vergessen. Die University of Southern California und Google Research haben eine neue Methode zur Lösung des kontinuierlichen Lernens vorgeschlagen , wird die Feature-Map jeder Kanalschicht neu programmiert, sodass die neu programmierte Feature-Map für neue Aufgaben geeignet ist. Dieses trainierbare Leichtbaumodul macht nur 0,6 % des gesamten Rückgrats aus. Jede neue Aufgabe kann ein eigenes Leichtbaumodul haben. Theoretisch können unendlich viele neue Aufgaben ohne katastrophales Vergessen gelernt werden. Das Papier wurde im ICCV 2023 veröffentlicht.
Papieradresse: https://arxiv.org/pdf/2307.11386.pdfProjektadresse: https://github.com/gyhandy/Channel-wise-Lightweight- Neuprogrammierung

- Datensatzadresse: http://ilab.usc.edu/andy/skill102
- Normalerweise werden Methoden zur Lösung kontinuierlichen Lernens hauptsächlich in drei Kategorien unterteilt: Regularisierungsbasierte Methoden und dynamische Netzwerke Methoden und Wiedergabemethoden. Die auf Regularisierung basierende Methode besteht darin, dass das Modell beim Erlernen neuer Aufgaben Einschränkungen für Parameteraktualisierungen hinzufügt und altes Wissen festigt, während neues Wissen erlernt wird.
- Die dynamische Netzwerkmethode besteht darin, beim Erlernen neuer Aufgaben spezifische Aufgabenparameter hinzuzufügen und das Gewicht alter Aufgaben zu begrenzen.
Die Replay-Methode geht davon aus, dass beim Erlernen einer neuen Aufgabe ein Teil der Daten der alten Aufgabe abgerufen und zusammen mit der neuen Aufgabe trainiert werden kann.
- Die in diesem Artikel vorgeschlagene CLR-Methode ist eine dynamische Netzwerkmethode. Die folgende Abbildung stellt den Ablauf des gesamten Prozesses dar: Die Forscher verwenden den aufgabenunabhängigen unveränderlichen Teil als gemeinsam genutzte aufgabenspezifische Parameter und fügen aufgabenspezifische Parameter hinzu, um die Kanalfunktionen neu zu kodieren. Um den Trainingsaufwand für die Rekodierungsparameter für jede Aufgabe zu minimieren, müssen Forscher gleichzeitig nur die Größe des Kernels im Modell anpassen und eine lineare Zuordnung der Kanäle vom Backbone zum aufgabenspezifischen Wissen erlernen, um die Rekodierung zu implementieren . Beim kontinuierlichen Lernen kann jede neue Aufgabe trainiert werden, um ein leichtes Modell zu erhalten. Selbst wenn es viele Aufgaben gibt, ist die Gesamtzahl der zu trainierenden Parameter im Vergleich zu einem großen Modell sehr gering . Klein und jedes leichte Modell kann gute Ergebnisse erzielen
- Forschungsmotivation
- Kontinuierliches Lernen konzentriert sich auf das Problem des Lernens aus Datenströmen, das heißt, das Erlernen neuer Aufgaben in einer bestimmten Reihenfolge. Kontinuierliche Erweiterung der Das erworbene Wissen zu verbessern und gleichzeitig das Vergessen früherer Aufgaben zu vermeiden, ist daher ein wichtiges Thema in der Forschung zum kontinuierlichen Lernen. Forscher berücksichtigen die folgenden drei Aspekte:
- Wiederverwenden statt neu lernen: Adversarial Reprogramming [1] ist eine Methode zur Lösung des Problems durch „Neukodierung“ eines trainierten und eingefrorenen Netzwerks durch Störung des Eingaberaums, ohne die Netzwerkparameter neu zu lernen. Die Forscher übernahmen die Idee der „Neukodierung“ und führten eine leichtere, aber leistungsfähigere Neuprogrammierung im Parameterraum des Originalmodells anstelle des Eingaberaums durch.
- Die Kanaltyptransformation kann zwei verschiedene Kerne verbinden: Die Autoren von GhostNet [2] stellten fest, dass herkömmliche Netzwerke nach dem Training einige ähnliche Feature-Maps erhalten, und schlugen daher eine neue Netzwerkarchitektur für GhostNet vor: indem sie die vorhandenen Feature-Maps vergleicht relativ kostengünstige Operationen (z. B. lineare Änderungen), um mehr Feature-Maps zu generieren und den Speicher zu reduzieren. Davon inspiriert verwendet diese Methode auch die lineare Transformation, um Feature-Maps zu generieren und das Netzwerk zu verbessern, sodass es zu relativ geringen Kosten an jede neue Aufgabe angepasst werden kann.
- Lightweight-Parameter können die Modellverteilung ändern: BPN [3] verschiebt die Netzwerkparameterverteilung von einer Aufgabe zur anderen, indem es eine vorteilhafte Störungsverzerrung in der vollständig verbundenen Schicht hinzufügt. Allerdings kann BPN nur vollständig verbundene Schichten mit nur einer skalaren Vorspannung pro Neuron verarbeiten und ist daher nur begrenzt in der Lage, das Netzwerk zu ändern. Stattdessen entwickelten die Forscher leistungsfähigere Modi für Convolutional Neural Networks (CNNs) (durch Hinzufügen von „Rekodierungs“-Parametern zum Faltungskern), um bei jeder neuen Aufgabe eine bessere Leistung zu erzielen. Beschreibung der Methode Selbstüberwachtes Lernmodell (DINO, SwAV), das auf Agentenaufgaben ohne semantische Bezeichnungen lernt. Im Gegensatz zu anderen kontinuierlichen Lernmethoden (z. B. SUPSUP unter Verwendung einer zufällig initialisierten festen Struktur, CCLL und EFTs unter Verwendung des aus der ersten Aufgabe erlernten Modells als Rückgrat) kann das von CLR verwendete vorab trainierte Modell eine Vielzahl visueller Funktionen bereitstellen, diese jedoch nicht Visuelle Features Features erfordern CLR-Ebenen für die Neukodierung für andere Aufgaben. Insbesondere verwendeten die Forscher eine kanalweise lineare Transformation, um das vom ursprünglichen Faltungskern generierte Merkmalsbild neu zu kodieren.
Das Bild zeigt die Struktur von CLR. CLR eignet sich für jedes Faltungs-Neuronale Netzwerk. Übliche Faltungs-Neuronale Netzwerke bestehen aus Conv-Blöcken (Restblöcken), einschließlich Faltungsschichten, Normalisierungsschichten und Aktivierungsschichten.
Die Forscher reparierten zunächst das vorab trainierte Rückgrat und fügten dann nach der Faltungsschicht in jedem festen Faltungsblock eine kanalisierte, leichte Neuprogrammierungsschicht (CLR-Schicht) hinzu, um die Merkmale nach dem festen Faltungskern zu verfeinern. wie lineare Veränderungen. Angenommen ein Bild X, können wir für jeden Faltungskern Dynamische Netzwerke: PSP, SupSup, CCLL, Confit, EFTs Wiederholung: ER, DERPP
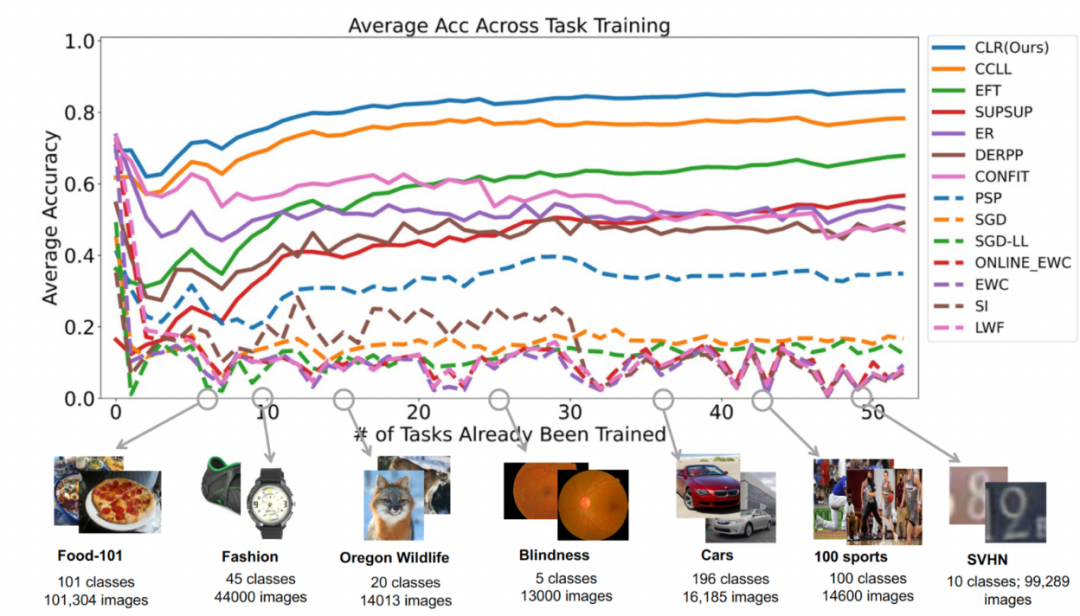
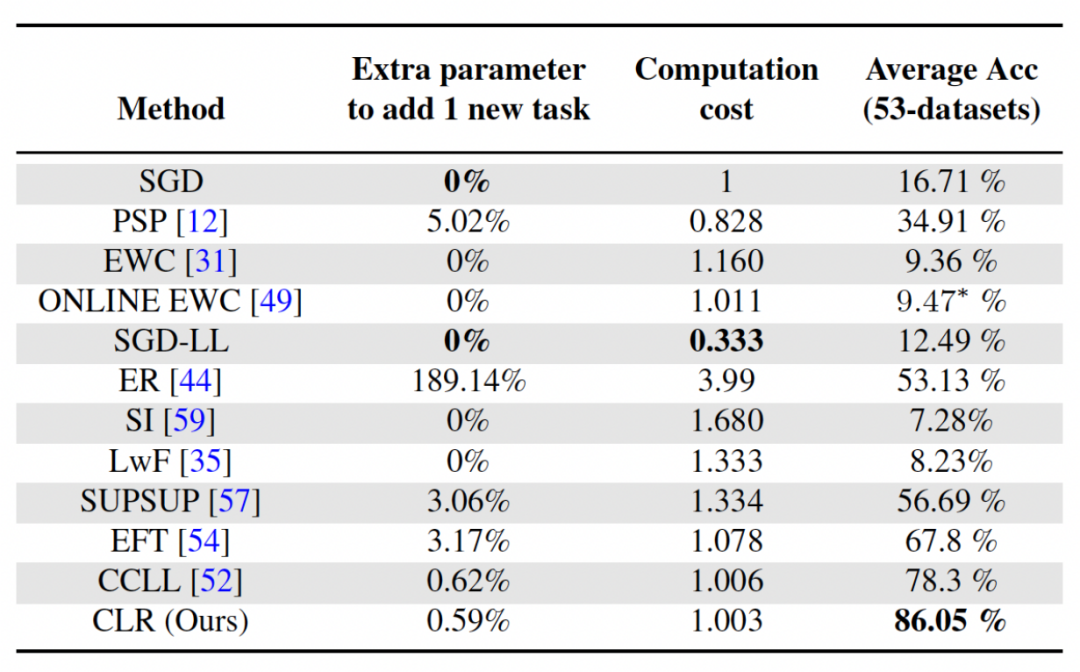
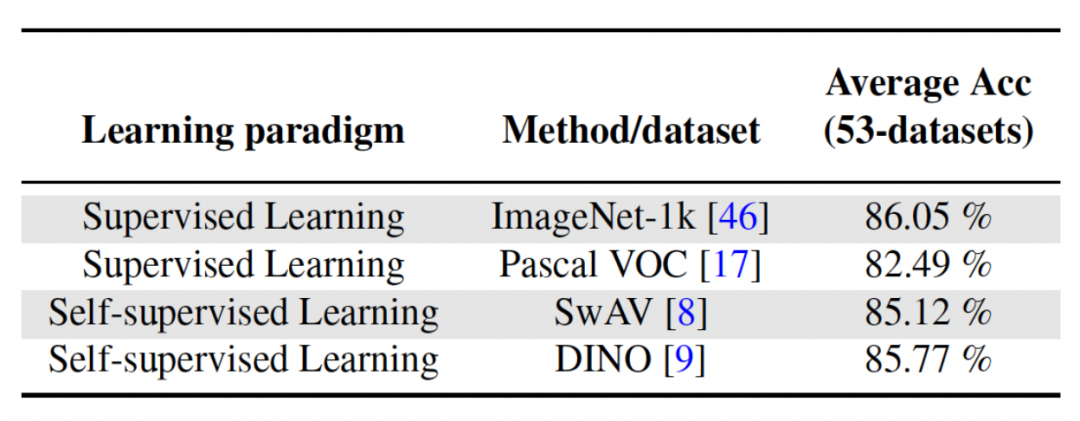
Zweites Experiment: Lernen mit durchschnittlicher Genauigkeit nach Abschluss aller Aufgaben Die folgende Abbildung zeigt die durchschnittliche Genauigkeit aller Methoden nach dem Erlernen aller Aufgaben. Die durchschnittliche Genauigkeit spiegelt die Gesamtleistung der kontinuierlichen Lernmethode wider. Da jede Aufgabe unterschiedliche Schwierigkeitsgrade aufweist, kann die durchschnittliche Genauigkeit aller Aufgaben steigen oder fallen, wenn eine neue Aufgabe hinzugefügt wird, je nachdem, ob die hinzugefügte Aufgabe einfach oder schwierig ist. Lassen Sie uns zunächst die Parameter und den Rechenaufwand analysieren Obwohl es für kontinuierliches Lernen sehr wichtig ist, eine höhere durchschnittliche Genauigkeit zu erzielen, hofft ein guter Algorithmus auch auf eine Maximierung. Reduzieren Sie die Anforderungen für zusätzliche Netzwerkparameter und Rechenkosten. „Zusätzliche Parameter für eine neue Aufgabe hinzufügen“ stellt einen Prozentsatz der ursprünglichen Backbone-Parametermenge dar. In diesem Artikel werden die Berechnungskosten von SGD als Einheit verwendet, und die Berechnungskosten anderer Methoden werden entsprechend den Kosten von SGD normalisiert. Umgeschriebener Inhalt: Wirkungsanalyse verschiedener Backbone-Netzwerke Die Methode in diesem Artikel trainiert ein vorab trainiertes Modell durch die Verwendung von überwachtem Lernen oder selbstüberwachtem Lernen an relativ unterschiedlichen Datensätzen als invarianter, von der Aufgabe unabhängiger Parameter. Um die Auswirkungen verschiedener Pre-Training-Methoden zu untersuchen, wurden in diesem Artikel vier verschiedene, aufgabenunabhängige Pre-Training-Modelle ausgewählt, die mit unterschiedlichen Datensätzen und Aufgaben trainiert wurden. Für das überwachte Lernen verwendeten die Forscher vorab trainierte Modelle auf ImageNet-1k und Pascal-VOC. Für das selbstüberwachte Lernen verwendeten die Forscher vorab trainierte Modelle, die mit zwei verschiedenen Methoden erhalten wurden: DINO und SwAV. Die folgende Tabelle zeigt die durchschnittliche Genauigkeit des vorab trainierten Modells unter Verwendung von vier verschiedenen Methoden. Es ist ersichtlich, dass die Endergebnisse jeder Methode sehr hoch sind (Hinweis: Pascal-VOC ist ein relativ kleiner Datensatz, daher ist die Genauigkeit relativ niedriger Punkt) und ist robust gegenüber verschiedenen vortrainierten Backbones. 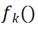 die Feature-Map erhalten, um jeden Kanal linear zu ändern Der Forscher initialisierte den CLR-Faltungskern auf denselben sich ändernden Kernel (d. h. für den 2D-Faltungskern ist nur der mittlere Parameter 1 und der Rest ist 0),
die Feature-Map erhalten, um jeden Kanal linear zu ändern Der Forscher initialisierte den CLR-Faltungskern auf denselben sich ändernden Kernel (d. h. für den 2D-Faltungskern ist nur der mittlere Parameter 1 und der Rest ist 0), 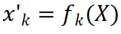 , da dadurch das ursprüngliche feste Rückgrat während der Initialisierung generiert werden kann Training Die Funktionen sind dieselben wie die, die das Modell nach dem Hinzufügen der CLR-Ebene erzeugt. Gleichzeitig werden die Forscher keine CLR-Schicht nach dem Faltungskern hinzufügen, um Parameter zu sparen und eine Überanpassung zu verhindern. Die CLR-Schicht wird erst nach dem Faltungskern agieren. Für ResNet50 nach CLR machen die erhöhten trainierbaren Parameter im Vergleich zum festen ResNet50-Backbone nur 0,59 % aus.
, da dadurch das ursprüngliche feste Rückgrat während der Initialisierung generiert werden kann Training Die Funktionen sind dieselben wie die, die das Modell nach dem Hinzufügen der CLR-Ebene erzeugt. Gleichzeitig werden die Forscher keine CLR-Schicht nach dem Faltungskern hinzufügen, um Parameter zu sparen und eine Überanpassung zu verhindern. Die CLR-Schicht wird erst nach dem Faltungskern agieren. Für ResNet50 nach CLR machen die erhöhten trainierbaren Parameter im Vergleich zum festen ResNet50-Backbone nur 0,59 % aus. 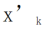
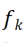 Für kontinuierliches Lernen kann das Modell, das trainierbare CLR-Parameter und ein nicht trainierbares Rückgrat hinzufügt, jede Aufgabe nacheinander lernen. Beim Testen gehen die Forscher davon aus, dass es einen Aufgabenprädiktor gibt, der dem Modell mitteilen kann, zu welcher Aufgabe das Testbild gehört, und dann das feste Rückgrat und die entsprechenden aufgabenspezifischen CLR-Parameter die endgültige Vorhersage treffen können. Da CLR die Eigenschaft einer absoluten Parameterisolation aufweist (die Parameter der CLR-Schicht, die jeder Aufgabe entsprechen, sind unterschiedlich und das gemeinsame Backbone ändert sich nicht), wird CLR nicht von der Anzahl der Aufgaben beeinflusst
Für kontinuierliches Lernen kann das Modell, das trainierbare CLR-Parameter und ein nicht trainierbares Rückgrat hinzufügt, jede Aufgabe nacheinander lernen. Beim Testen gehen die Forscher davon aus, dass es einen Aufgabenprädiktor gibt, der dem Modell mitteilen kann, zu welcher Aufgabe das Testbild gehört, und dann das feste Rückgrat und die entsprechenden aufgabenspezifischen CLR-Parameter die endgültige Vorhersage treffen können. Da CLR die Eigenschaft einer absoluten Parameterisolation aufweist (die Parameter der CLR-Schicht, die jeder Aufgabe entsprechen, sind unterschiedlich und das gemeinsame Backbone ändert sich nicht), wird CLR nicht von der Anzahl der Aufgaben beeinflusst Experimentelle Ergebnisse
Experimentelle Ergebnisse Datensatz: Die Forscher nutzten die Bildklassifizierung als Hauptaufgabe. Das Labor sammelte 53 Bildklassifizierungsdatensätze mit etwa 1,8 Millionen Bildern und 1584 Kategorien. Diese 53 Datensätze enthalten 5 verschiedene Klassifizierungsziele: Objekterkennung, Stilklassifizierung, Szenenklassifizierung, Zählung und medizinische Diagnose.
Datensatz: Die Forscher nutzten die Bildklassifizierung als Hauptaufgabe. Das Labor sammelte 53 Bildklassifizierungsdatensätze mit etwa 1,8 Millionen Bildern und 1584 Kategorien. Diese 53 Datensätze enthalten 5 verschiedene Klassifizierungsziele: Objekterkennung, Stilklassifizierung, Szenenklassifizierung, Zählung und medizinische Diagnose. 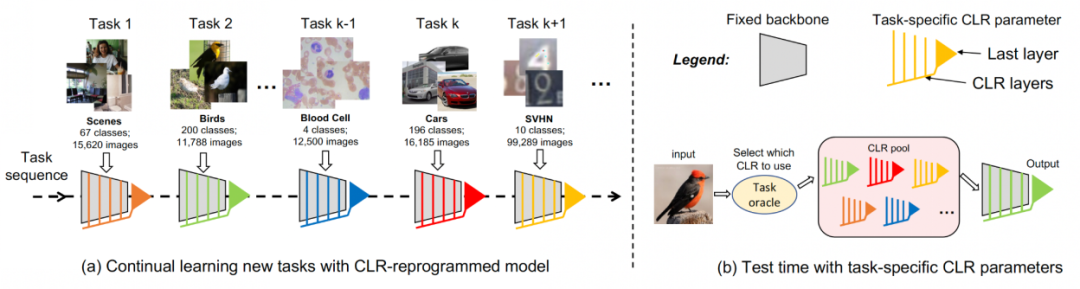 Die Forscher wählten 13 Baselines aus, die grob in 3 Kategorien unterteilt werden können
Die Forscher wählten 13 Baselines aus, die grob in 3 Kategorien unterteilt werden könnenRegularisierung: EWC, Online-EWC, SI, LwF
Es gibt auch einige Grundlinien, die kein kontinuierliches Lernen sind, wie z. B. SGD und SGD-LL. SGD lernt jede Aufgabe durch Feinabstimmung des gesamten Netzwerks. SGD-LL ist eine Variante, die ein festes Backbone für alle Aufgaben und eine lernbare gemeinsame Schicht verwendet, deren Länge der maximalen Anzahl von Kategorien für alle Aufgaben entspricht.
Das obige ist der detaillierte Inhalt vonOptimieren Sie die Lerneffizienz: Übertragen Sie alte Modelle auf neue Aufgaben mit 0,6 % zusätzlichen Parametern. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1379
1379
 52
52

 Debian Mail Server Firewall -Konfigurationstipps
Apr 13, 2025 am 11:42 AM
Debian Mail Server Firewall -Konfigurationstipps
Apr 13, 2025 am 11:42 AM
Das Konfigurieren der Firewall eines Debian -Mailservers ist ein wichtiger Schritt zur Gewährleistung der Serversicherheit. Im Folgenden sind mehrere häufig verwendete Firewall -Konfigurationsmethoden, einschließlich der Verwendung von Iptables und Firewalld. Verwenden Sie Iptables, um Firewall so zu konfigurieren, dass Iptables (falls bereits installiert) installiert werden:
 Wie Debian Readdir sich in andere Tools integriert
Apr 13, 2025 am 09:42 AM
Wie Debian Readdir sich in andere Tools integriert
Apr 13, 2025 am 09:42 AM
Die Readdir -Funktion im Debian -System ist ein Systemaufruf, der zum Lesen des Verzeichnisgehalts verwendet wird und häufig in der C -Programmierung verwendet wird. In diesem Artikel wird erläutert, wie Readdir in andere Tools integriert wird, um seine Funktionalität zu verbessern. Methode 1: Kombinieren Sie C -Sprachprogramm und Pipeline zuerst ein C -Programm, um die Funktion der Readdir aufzurufen und das Ergebnis auszugeben:#include#include#includeIntmain (intargc, char*argv []) {Dir*Dir; structDirent*Eintrag; if (argc! = 2) {{
 So setzen Sie die Debian Apache -Protokollebene fest
Apr 13, 2025 am 08:33 AM
So setzen Sie die Debian Apache -Protokollebene fest
Apr 13, 2025 am 08:33 AM
In diesem Artikel wird beschrieben, wie Sie die Protokollierungsstufe des Apacheweb -Servers im Debian -System anpassen. Durch Ändern der Konfigurationsdatei können Sie die ausführliche Ebene der von Apache aufgezeichneten Protokollinformationen steuern. Methode 1: Ändern Sie die Hauptkonfigurationsdatei, um die Konfigurationsdatei zu finden: Die Konfigurationsdatei von Apache2.x befindet sich normalerweise im Verzeichnis/etc/apache2/. Der Dateiname kann je nach Installationsmethode Apache2.conf oder httpd.conf sein. Konfigurationsdatei bearbeiten: Öffnen Sie die Konfigurationsdatei mit Stammberechtigungen mit einem Texteditor (z. B. Nano): Sudonano/etc/apache2/apache2.conf
 So optimieren Sie die Leistung von Debian Readdir
Apr 13, 2025 am 08:48 AM
So optimieren Sie die Leistung von Debian Readdir
Apr 13, 2025 am 08:48 AM
In Debian -Systemen werden Readdir -Systemaufrufe zum Lesen des Verzeichnisinhalts verwendet. Wenn seine Leistung nicht gut ist, probieren Sie die folgende Optimierungsstrategie aus: Vereinfachen Sie die Anzahl der Verzeichnisdateien: Teilen Sie große Verzeichnisse so weit wie möglich in mehrere kleine Verzeichnisse auf und reduzieren Sie die Anzahl der gemäß Readdir -Anrufe verarbeiteten Elemente. Aktivieren Sie den Verzeichnis -Inhalt Caching: Erstellen Sie einen Cache -Mechanismus, aktualisieren Sie den Cache regelmäßig oder bei Änderungen des Verzeichnisinhalts und reduzieren Sie häufige Aufrufe an Readdir. Speicher -Caches (wie Memcached oder Redis) oder lokale Caches (wie Dateien oder Datenbanken) können berücksichtigt werden. Nehmen Sie eine effiziente Datenstruktur an: Wenn Sie das Verzeichnis -Traversal selbst implementieren, wählen Sie effizientere Datenstrukturen (z.
 So implementieren Sie die Dateisortierung nach Debian Readdir
Apr 13, 2025 am 09:06 AM
So implementieren Sie die Dateisortierung nach Debian Readdir
Apr 13, 2025 am 09:06 AM
In Debian -Systemen wird die Readdir -Funktion zum Lesen des Verzeichnisinhalts verwendet, aber die Reihenfolge, in der sie zurückgibt, ist nicht vordefiniert. Um Dateien in einem Verzeichnis zu sortieren, müssen Sie zuerst alle Dateien lesen und dann mit der QSORT -Funktion sortieren. Der folgende Code zeigt, wie Verzeichnisdateien mithilfe von Readdir und QSORT in Debian System sortiert werden:#include#include#include#include // benutzerdefinierte Vergleichsfunktion, verwendet für QSortIntCompare (constvoid*a, constvoid*b) {rettrcmp (*(*(*(
 Debian Mail Server SSL -Zertifikat -Installationsmethode
Apr 13, 2025 am 11:39 AM
Debian Mail Server SSL -Zertifikat -Installationsmethode
Apr 13, 2025 am 11:39 AM
Die Schritte zur Installation eines SSL -Zertifikats auf dem Debian Mail -Server sind wie folgt: 1. Installieren Sie zuerst das OpenSSL -Toolkit und stellen Sie sicher, dass das OpenSSL -Toolkit bereits in Ihrem System installiert ist. Wenn nicht installiert, können Sie den folgenden Befehl installieren: sudoapt-getupdatesudoapt-getinstallopenssl2. Generieren Sie den privaten Schlüssel und die Zertifikatanforderung als nächst
 So führen Sie die digitale Signaturüberprüfung mit Debian OpenSSL durch
Apr 13, 2025 am 11:09 AM
So führen Sie die digitale Signaturüberprüfung mit Debian OpenSSL durch
Apr 13, 2025 am 11:09 AM
Unter Verwendung von OpenSSL für die digitale Signaturüberprüfung im Debian -System können Sie folgende Schritte befolgen: Vorbereitung für die Installation von OpenSSL: Stellen Sie sicher, dass Ihr Debian -System OpenSSL installiert hat. Wenn nicht installiert, können Sie den folgenden Befehl verwenden, um es zu installieren: sudoaptupdatesudoaptininTallopenSSL, um den öffentlichen Schlüssel zu erhalten: Die digitale Signaturüberprüfung erfordert den öffentlichen Schlüssel des Unterzeichners. In der Regel wird der öffentliche Schlüssel in Form einer Datei wie Public_key.pe bereitgestellt
 Wie Debian OpenSSL verhindert, dass Mann-in-the-Middle-Angriffe
Apr 13, 2025 am 10:30 AM
Wie Debian OpenSSL verhindert, dass Mann-in-the-Middle-Angriffe
Apr 13, 2025 am 10:30 AM
In Debian Systems ist OpenSSL eine wichtige Bibliothek für Verschlüsselung, Entschlüsselung und Zertifikatverwaltung. Um einen Mann-in-the-Middle-Angriff (MITM) zu verhindern, können folgende Maßnahmen ergriffen werden: Verwenden Sie HTTPS: Stellen Sie sicher, dass alle Netzwerkanforderungen das HTTPS-Protokoll anstelle von HTTP verwenden. HTTPS verwendet TLS (Transport Layer Security Protocol), um Kommunikationsdaten zu verschlüsseln, um sicherzustellen, dass die Daten während der Übertragung nicht gestohlen oder manipuliert werden. Überprüfen Sie das Serverzertifikat: Überprüfen Sie das Serverzertifikat im Client manuell, um sicherzustellen, dass es vertrauenswürdig ist. Der Server kann manuell durch die Delegate -Methode der URLSession überprüft werden
