

Mit dem Aufkommen groß angelegter Sprachmodelle wie GPT-3 wurden große Durchbrüche auf dem Gebiet der Verarbeitung natürlicher Sprache (NLP) erzielt. Diese Sprachmodelle verfügen über die Fähigkeit, menschenähnlichen Text zu generieren, und werden häufig in verschiedenen Szenarien wie Chatbots und Übersetzungen eingesetzt.

Wenn es jedoch um spezielle und benutzerdefinierte Anwendungsszenarien geht, sind allgemeine, große Sprachmodelle möglicherweise vorhanden Mangel an Fachwissen sein. Die Feinabstimmung dieser Modelle mit speziellen Korpora ist oft teuer und zeitaufwändig. „Retrieval Enhanced Generation“ (RAG) bietet eine neue Technologielösung für professionelle Anwendungen.
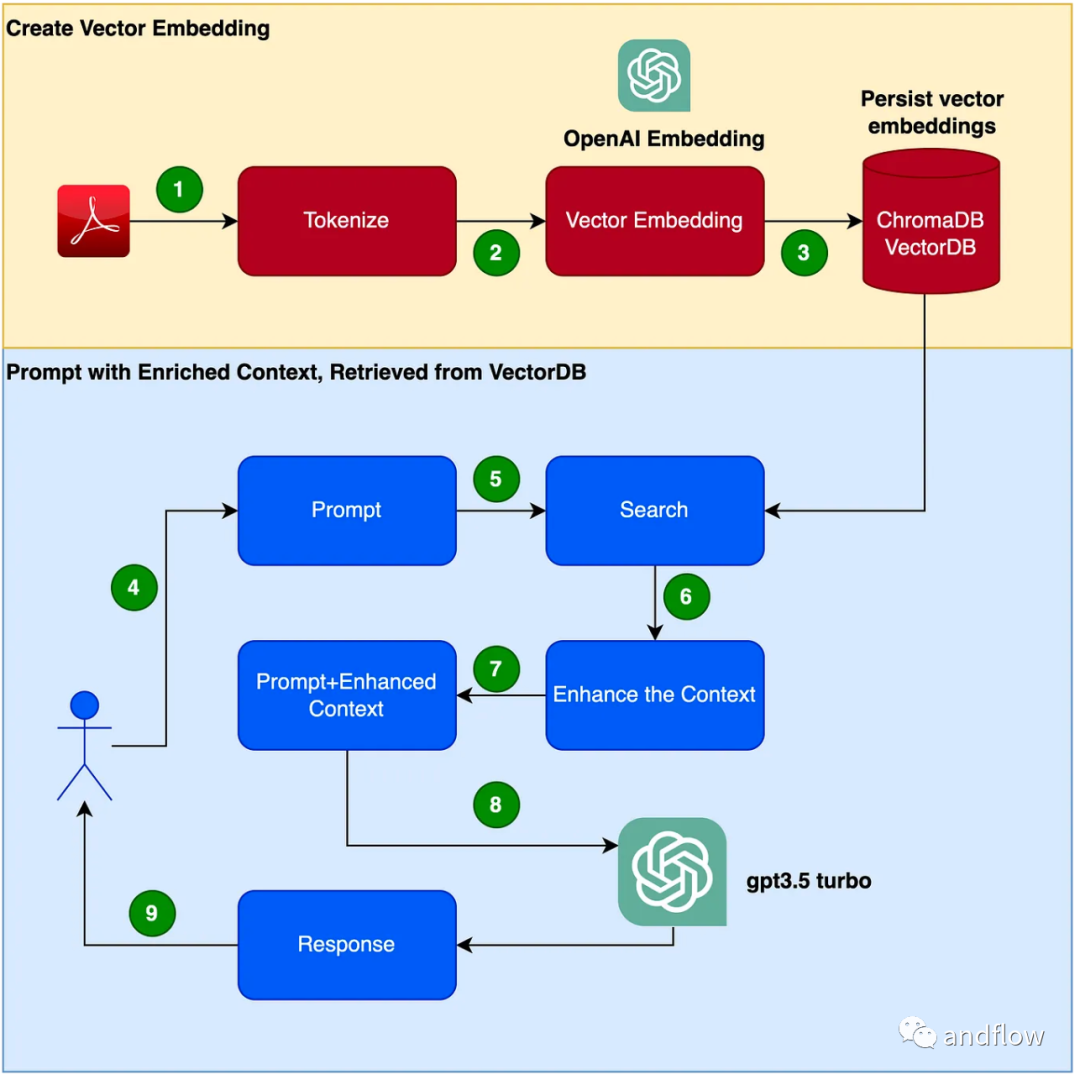
Im Folgenden stellen wir hauptsächlich die Funktionsweise von RAG vor und verwenden ein praktisches Beispiel, um das Produkthandbuch als professionelles Korpus zu verwenden und GPT-3.5 Turbo als Frage- und Antwortmodell zu verwenden, um seine Wirksamkeit zu überprüfen.
Fall: Entwickeln Sie einen Chatbot, der Fragen zu einem bestimmten Produkt beantworten kann. Dieses Unternehmen verfügt über ein einzigartiges Benutzerhandbuch
RAG bietet eine effektive Lösung für domänenspezifische Fragen und Antworten. Es wandelt hauptsächlich Branchenwissen in Vektoren zum Speichern und Abrufen um, kombiniert die Abrufergebnisse mit Benutzerfragen, um zeitnahe Informationen zu bilden, und verwendet schließlich große Modelle, um geeignete Antworten zu generieren. Durch die Kombination des Abrufmechanismus und des Sprachmodells wird die Reaktionsfähigkeit des Modells erheblich verbessert
Die Schritte zum Erstellen eines Chatbot-Programms sind wie folgt:
(1) Richten Sie eine virtuelle Python-Umgebung ein. Richten Sie eine virtuelle Umgebung ein, um unser Python zu sandboxen, um Versions- oder Abhängigkeitskonflikte zu vermeiden. Führen Sie den folgenden Befehl aus, um eine neue virtuelle Python-Umgebung zu erstellen.
需要重写的内容是:pip安装virtualenv,python3 -m venv ./venv,source venv/bin/activate
Der Inhalt, der neu geschrieben werden muss, ist: (2) OpenAI-Schlüssel generieren
Für die Verwendung von GPT ist ein OpenAI-Schlüssel für den Zugriff erforderlich
Der Inhalt, der neu geschrieben werden muss, ist: (3) Abhängige Bibliotheken installieren
Verschiedene vom Installer benötigte Abhängigkeiten. Enthält die folgenden Bibliotheken:
pip install langchainpip install unstructuredpip install pypdfpip install tiktokenpip install chromadbpip install openai
Erstellen Sie eine Umgebungsvariable zum Speichern des OpenAI-Schlüssels.
export OPENAI_API_KEY=<openai-key></openai-key>
(4) Konvertieren Sie die PDF-Datei des Benutzerhandbuchs in einen Vektor und speichern Sie sie in ChromaDB.
Importieren Sie alle abhängigen Bibliotheken und Funktionen, die Sie benötigen, um
import osimport openaiimport tiktokenimport chromadbfrom langchain.document_loaders import OnlinePDFLoader, UnstructuredPDFLoader, PyPDFLoaderfrom langchain.text_splitter import TokenTextSplitterfrom langchain.memory import ConversationBufferMemoryfrom langchain.embeddings.openai import OpenAIEmbeddingsfrom langchain.vectorstores import Chromafrom langchain.llms import OpenAIfrom langchain.chains import ConversationalRetrievalChain
zum Lesen von PDF, zum Tokenisieren des Dokuments und zum Teilen des Dokuments zu verwenden.
loader = PyPDFLoader("Clarett.pdf")pdfData = loader.load()text_splitter = TokenTextSplitter(chunk_size=1000, chunk_overlap=0)splitData = text_splitter.split_documents(pdfData)Erstellen Sie eine Chroma-Sammlung und ein lokales Verzeichnis zum Speichern von Chroma-Daten. Erstellen Sie dann einen Vektor (Einbettungen) und speichern Sie ihn in ChromaDB.
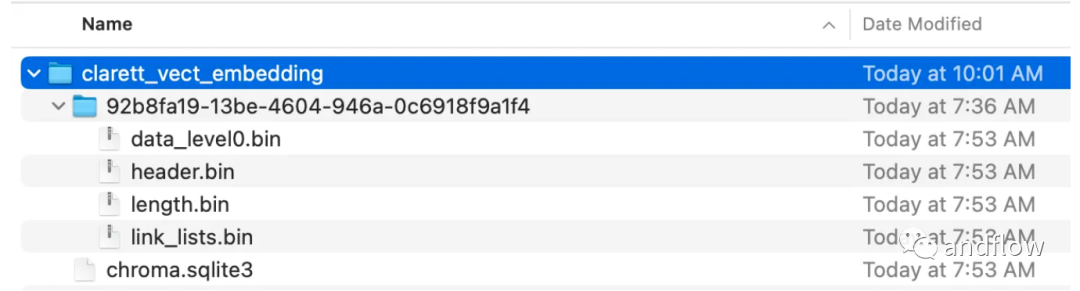
collection_name = "clarett_collection"local_directory = "clarett_vect_embedding"persist_directory = os.path.join(os.getcwd(), local_directory)openai_key=os.environ.get('OPENAI_API_KEY')embeddings = OpenAIEmbeddings(openai_api_key=openai_key)vectDB = Chroma.from_documents(splitData,embeddings,collection_name=collection_name,persist_directory=persist_directory)vectDB.persist()Nachdem Sie diesen Code ausgeführt haben, sollten Sie einen Ordner sehen, der zum Speichern der Vektoren erstellt wurde.
Nachdem die Vektoreinbettung in ChromaDB gespeichert wurde, können Sie die ConversationalRetrievalChain-API in LangChain verwenden, um eine Chat-Verlaufskomponente zu starten. Im folgenden Code wird eine vom Benutzer eingegebene Frage akzeptiert, und nachdem der Benutzer „Fertig“ eingegeben hat, wird die Frage an LLM übergeben, um die Antwort abzurufen und auszudrucken.
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)chatQA = ConversationalRetrievalChain.from_llm(OpenAI(openai_api_key=openai_key, temperature=0, model_name="gpt-3.5-turbo"), vectDB.as_retriever(), memory=memory)

RAG vereint die Vorteile von Sprachmodellen wie GPT mit den Vorteilen des Information Retrieval. Durch die Nutzung spezifischer Wissenskontextinformationen zur Erweiterung der Fülle an Aufforderungswörtern ist das Sprachmodell in der Lage, genauere, wissenskontextbezogene Antworten zu generieren. RAG bietet eine effizientere und kostengünstigere Lösung als „Feinabstimmung“ und bietet anpassbare interaktive Lösungen für Industrieanwendungen oder Unternehmensanwendungen
Das obige ist der detaillierte Inhalt vonVerbesserung der Engineering-Effizienz – Enhanced Search Generation (RAG). Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Werbung bewerben
Werbung bewerben
 Wie lautet das Format des Kontonamens von Steam?
Wie lautet das Format des Kontonamens von Steam?
 vim-Befehl zum Speichern und Beenden
vim-Befehl zum Speichern und Beenden
 Fünf Gründe, warum sich Ihr Computer nicht einschalten lässt
Fünf Gründe, warum sich Ihr Computer nicht einschalten lässt
 Linux-Systemzeit
Linux-Systemzeit
 So beheben Sie den Fehler 443
So beheben Sie den Fehler 443
 Wo ist der Prtscrn-Button?
Wo ist der Prtscrn-Button?
 Die Rolle der Parseint-Funktion
Die Rolle der Parseint-Funktion
 Was tun, wenn die Installation des Soundkartentreibers fehlschlägt?
Was tun, wenn die Installation des Soundkartentreibers fehlschlägt?








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



