
 Technologie-Peripheriegeräte
KI
Was ist NeRF? Ist die NeRF-basierte 3D-Rekonstruktion voxelbasiert?
Technologie-Peripheriegeräte
KI
Was ist NeRF? Ist die NeRF-basierte 3D-Rekonstruktion voxelbasiert?
Was ist NeRF? Ist die NeRF-basierte 3D-Rekonstruktion voxelbasiert?

1 Einführung
Neuronale Strahlungsfelder (NeRF) sind ein ziemlich neues Paradigma im Bereich Deep Learning und Computer Vision. Die Technik wurde im ECCV 2020-Papier „NeRF: Representing Scenes as Neural Radiation Fields for View Synthesis“ (das mit dem Best Paper Award ausgezeichnet wurde) vorgestellt und erfreut sich seitdem mit bis heute fast 800 Zitaten einer explosionsartigen Beliebtheit [1]. Der Ansatz markiert einen grundlegenden Wandel in der traditionellen Art und Weise, wie maschinelles Lernen 3D-Daten verarbeitet.
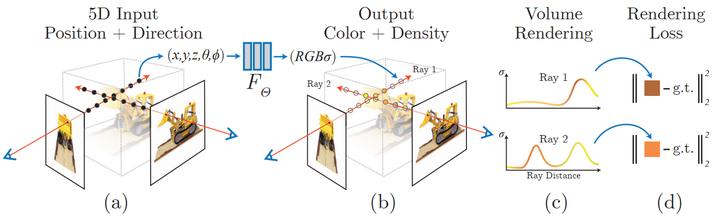
Neuronale Strahlungsfeld-Szenendarstellung und differenzierbarer Rendering-Prozess:
Synthesieren Sie das Bild durch Abtasten von 5D-Koordinaten (Position und Blickrichtung) entlang des Kamerastrahls; geben Sie diese Positionen in ein MLP ein, um Farb- und Volumendichte zu erzeugen; Volumen-Rendering-Techniken synthetisieren diese Werte zu einem Bild; die Rendering-Funktion ist differenzierbar und optimiert daher die Szenendarstellung, indem sie den Restunterschied zwischen dem synthetisierten Bild und dem real beobachteten Bild minimiert.
2 Was ist ein NeRF?
NeRF ist ein generatives Modell, das anhand eines Bildes neue Ansichten einer 3D-Szene generiert, abhängig von einem Bild und einer präzisen Pose, ein Prozess, der oft als „Synthese neuer Ansichten“ bezeichnet wird. Darüber hinaus definiert es auch klar die 3D-Form und das Erscheinungsbild der Szene als kontinuierliche Funktion, die durch marschierende Würfel 3D-Netze erzeugen kann. Obwohl sie direkt aus Bilddaten lernen, verwenden sie weder Faltungs- noch Transformatorschichten.
Im Laufe der Jahre gab es viele Möglichkeiten, 3D-Daten in Anwendungen des maschinellen Lernens darzustellen, von 3D-Voxeln über Punktwolken bis hin zu vorzeichenbehafteten Distanzfunktionen. Ihr größter gemeinsamer Nachteil ist die Notwendigkeit, im Voraus ein 3D-Modell anzunehmen, entweder mithilfe von Werkzeugen wie Photogrammetrie oder Lidar, um 3D-Daten zu generieren, oder das 3D-Modell manuell zu erstellen. Viele Arten von Objekten, beispielsweise stark reflektierende Objekte, „gitterartige“ Objekte oder transparente Objekte, können jedoch nicht im Maßstab gescannt werden. 3D-Rekonstruktionsmethoden weisen außerdem häufig Rekonstruktionsfehler auf, die zu Stufeneffekten oder Drift führen können, die die Modellgenauigkeit beeinträchtigen.
Im Gegensatz dazu basiert NeRF auf dem Konzept der Strahlenlichtfelder. Ein Lichtfeld ist eine Funktion, die beschreibt, wie die Lichtübertragung in einem 3D-Volumen erfolgt. Es beschreibt die Richtung, in der sich ein Lichtstrahl an jeder x = (x, y, z)-Koordinate im Raum und in jeder Richtung d bewegt, beschrieben als θ- und ξ-Winkel oder Einheitsvektoren. Zusammen bilden sie einen 5D-Merkmalsraum, der die Lichtdurchlässigkeit in einer 3D-Szene beschreibt. Inspiriert von dieser Darstellung versucht NeRF, eine Funktion zu approximieren, die von diesem Raum auf einen 4D-Raum abbildet, der aus Farbe c = (R, G, B) und Dichte (Dichte) σ besteht, den man sich als diesen 5D-Koordinatenraum The vorstellen kann Möglichkeit, dass der Strahl beendet wird (z. B. durch Okklusion). Daher ist Standard-NeRF eine Funktion der Form F: (x, d) -> (c, σ).
Das ursprüngliche NeRF-Papier parametrisierte diese Funktion mithilfe eines mehrschichtigen Perzeptrons, das auf einer Reihe von Bildern mit bekannten Posen trainiert wurde. Dies ist eine Methode in einer Klasse von Techniken, die als generalisierte Szenenrekonstruktion bezeichnet werden und darauf abzielen, 3D-Szenen direkt aus einer Sammlung von Bildern zu beschreiben. Dieser Ansatz hat einige sehr schöne Eigenschaften:
- Lernen Sie direkt aus den Daten.
- Die kontinuierliche Darstellung der Szene ermöglicht sehr dünne und komplexe Strukturen wie Blätter oder Netze.
- Implizite physikalische Eigenschaften wie Spiegelung und Rauheit.
- Implizite Darstellung der Beleuchtung in der Szene
Seitdem ist eine Reihe von Verbesserungspapieren entstanden, wie z. B. Wenig-Shot- und Single-Shot-Lernen [2, 3], Unterstützung für dynamische Szenen [4, 5] und die Integration der Lichtfeldverallgemeinerung in Funktionen Felder [6], Lernen aus unkalibrierten Bildsammlungen im Web [7], Einbeziehung von LIDAR-Daten [8], großflächige Szenendarstellung [9], Lernen ohne neuronale Netze [10] und so weiter. 3 NeRF-Architektur Szene, um eine Reihe von Proben an der (x, d)-Position zu sammeln
Verwenden Sie den Punkt und die Blickrichtung (x, d) jeder Probe als Eingabe, um den Ausgabewert (c, σ) (rgbσ) zu erzeugen
Verwenden Sie klassisch Volumen-Rendering-Technologie zum Erstellen von Bildern
- Die Funktion „Lichtfeld“ (viele Dokumente übersetzen es als „Strahlungsfeld“, aber der Übersetzer glaubt, dass „Lichtfeld“ intuitiver ist) ist nur eine von mehreren Komponenten, die Sie erstellen können die visuellen Effekte, die Sie zuvor im Video gesehen haben. Insgesamt enthält dieser Artikel die folgenden Teile:
- Positionskodierung
- Light Field Function Approximator (MLP)
Differenzierbarer Volumenrenderer (Differenzierbarer Volumenrenderer)
- Stratified Sampling Hierarchical Volume Sampling
- Um die Klarheit zu maximieren Neben der Beschreibung zeigt dieser Artikel die Schlüsselelemente jeder Komponente in einem möglichst prägnanten Code an. Es wird auf die ursprüngliche Implementierung von bmild und die PyTorch-Implementierung von yenchenlin und krrish94 verwiesen.
3.1 Positionsgeber
Genau wie das 2017 eingeführte Transformatormodell [11] profitiert auch NeRF von einem Positionsgeber als Eingang. Es verwendet Hochfrequenzfunktionen, um seine kontinuierlichen Eingaben in einen höherdimensionalen Raum abzubilden, damit das Modell hochfrequente Änderungen in den Daten lernen kann, was zu einem saubereren Modell führt. Diese Methode umgeht die Voreingenommenheit des neuronalen Netzwerks auf niederfrequente Funktionen und ermöglicht es NeRF, klarere Details darzustellen. Der Autor verweist auf einen Artikel zu ICML 2019 [12].
Wenn Sie mit der Positionscodierung von Transformerd vertraut sind, ist die zugehörige Implementierung von NeRF ziemlich standardmäßig und weist die gleichen abwechselnden Sinus- und Cosinus-Ausdrücke auf. Implementierung des Positionsencoders:
# pyclass PositionalEncoder(nn.Module):# sine-cosine positional encoder for input points.def __init__( self,d_input: int,n_freqs: int,log_space: bool = False ):super().__init__()self.d_input = d_inputself.n_freqs = n_freqs # 是不是视线上的采样频率?self.log_space = log_spaceself.d_output = d_input * (1 + 2 * self.n_freqs)self.embed_fns = [lambda x: x] # 冒号前面的x表示函数参数,后面的表示匿名函数运算# Define frequencies in either linear or log scaleif self.log_space:freq_bands = 2.**torch.linspace(0., self.n_freqs - 1, self.n_freqs)else:freq_bands = torch.linspace(2.**0., 2.**(self.n_freqs - 1), self.n_freqs)# Alternate sin and cosfor freq in freq_bands:self.embed_fns.append(lambda x, freq=freq: torch.sin(x * freq))self.embed_fns.append(lambda x, freq=freq: torch.cos(x * freq))def forward(self, x) -> torch.Tensor:# Apply positional encoding to input.return torch.concat([fn(x) for fn in self.embed_fns], dim=-1)
Denken: Diese Positionskodierung kodiert Eingabepunkte. Ist dieser Eingabepunkt ein Abtastpunkt auf der Sichtlinie? Oder ein anderer Blickwinkel? Ist self.n_freqs die Abtastfrequenz auf der Sichtlinie? Nach diesem Verständnis sollte es sich um die Abtastposition auf der Sichtlinie handeln, denn wenn die Abtastposition auf der Sichtlinie nicht codiert ist, können diese Positionen nicht effektiv dargestellt werden und ihr RGBA kann nicht trainiert werden.
3.2 Strahlungsfeldfunktion
Im Originaltext wird die Lichtfeldfunktion durch das NeRF-Modell dargestellt. Das NeRF-Modell ist ein typisches mehrschichtiges Perzeptron, das codierte 3D-Punkte und Blickrichtung als Eingabe verwendet und RGBA-Werte zurückgibt als Ausgabe. Obwohl in diesem Artikel neuronale Netze verwendet werden, kann hier jeder Funktionsnäherungsmechanismus verwendet werden. Beispielsweise nutzt die Folgearbeit Plenoxels von Yu et al. sphärische Harmonische, um ein um Größenordnungen schnelleres Training zu erreichen und gleichzeitig wettbewerbsfähige Ergebnisse zu erzielen [10].
 Bilder
Bilder
Das NeRF-Modell ist 8 Schichten tief und die meisten Schichten haben Merkmalsabmessungen von 256. Die restlichen Verbindungen werden auf Layer 4 platziert. Nach diesen Schichten werden RGB- und σ-Werte generiert. Die RGB-Werte werden mit einer linearen Schicht weiterverarbeitet, dann mit der Blickrichtung verkettet, dann durch eine weitere lineare Schicht geleitet und schließlich am Ausgang wieder mit σ kombiniert. PyTorch-Modulimplementierung des NeRF-Modells:
class NeRF(nn.Module):# Neural radiance fields module.def __init__( self,d_input: int = 3,n_layers: int = 8,d_filter: int = 256,skip: Tuple[int] = (4,), # (4,)只有一个元素4的元组 d_viewdirs: Optional[int] = None): super().__init__()self.d_input = d_input# 这里是3D XYZ,?self.skip = skip# 是要跳过什么?为啥要跳过?被遮挡?self.act = nn.functional.reluself.d_viewdirs = d_viewdirs# d_viewdirs 是2D方向?# Create model layers# [if_true 就执行的指令] if [if_true条件] else [if_false]# 是否skip的区别是,训练输入维度是否多3维,# if i in skip =if i in (4,),似乎是判断i是否等于4# self.d_input=3 :如果层id=4,网络输入要加3维,这是为什么?第4层有何特殊的?self.layers = nn.ModuleList([nn.Linear(self.d_input, d_filter)] +[nn.Linear(d_filter + self.d_input, d_filter) if i in skip else \ nn.Linear(d_filter, d_filter) for i in range(n_layers - 1)])# Bottleneck layersif self.d_viewdirs is not None:# If using viewdirs, split alpha and RGBself.alpha_out = nn.Linear(d_filter, 1)self.rgb_filters = nn.Linear(d_filter, d_filter)self.branch = nn.Linear(d_filter + self.d_viewdirs, d_filter // 2)self.output = nn.Linear(d_filter // 2, 3) # 为啥要取一半?else:# If no viewdirs, use simpler outputself.output = nn.Linear(d_filter, 4) # d_filter=256,输出是4维RGBAdef forward(self,x: torch.Tensor, # ?viewdirs: Optional[torch.Tensor] = None) -> torch.Tensor: # Forward pass with optional view direction.if self.d_viewdirs is None and viewdirs is not None:raise ValueError('Cannot input x_direction')# Apply forward pass up to bottleneckx_input = x# 这里的x是几维?从下面的分离RGB和A看,应该是4D# 下面通过8层MLP训练RGBAfor i, layer in enumerate(self.layers):# 8层,每一层进行运算x = self.act(layer(x)) if i in self.skip:x = torch.cat([x, x_input], dim=-1)# Apply bottleneckbottleneck 瓶颈是啥?是不是最费算力的模块?if self.d_viewdirs is not None:# 从网络输出分离A,RGB还需要经过更多训练alpha = self.alpha_out(x)# Pass through bottleneck to get RGBx = self.rgb_filters(x) x = torch.concat([x, viewdirs], dim=-1)x = self.act(self.branch(x)) # self.branch shape: (d_filter // 2)x = self.output(x) # self.output shape: (3)# Concatenate alphas to outputx = torch.concat([x, alpha], dim=-1)else:# Simple outputx = self.output(x)return xDenken: Was sind die Eingaben und Ausgaben dieser NERF-Klasse? Was passiert in diesem Kurs? Aus den Parametern der Funktion __init__ ist ersichtlich, dass sie hauptsächlich die Eingabe, den Pegel und die Dimension der 5D-Daten des neuronalen Netzwerks festlegt, dh die Position des Blickwinkels und die Richtung der Sichtlinie, und die Ausgabe ist RGBA. Frage: Ist die RGBA-Ausgabe ein Punkt? Oder handelt es sich um eine Reihe von Sichtlinien? Wenn es sich um eine Serie handelt, habe ich nicht gesehen, wie die Positionscodierung die RGBA jedes Abtastpunkts bestimmt. Ich habe keine Anweisungen gesehen, z. B. wenn es sich um einen Punkt handelt, welcher Punkt auf der Sichtlinie gehört dieser RGBA dazu? Ist es der RGBA-Punkt, der das Ergebnis einer Sammlung von visuellen Abtastpunkten ist, die mit den Augen gesehen werden? Aus dem NERF-Klassencode ist ersichtlich, dass das mehrschichtige Feedforward-Training hauptsächlich auf der Grundlage der Blickpunktposition und der Blickrichtung erfolgt. Die 5D-Blickpunktposition und die Blickrichtung werden eingegeben und der 4D-RGBA ausgegeben.
3.3 Differenzierbarer Volumenrenderer
Die RGBA-Ausgabepunkte befinden sich im 3D-Raum. Um sie also zu einem Bild zu synthetisieren, müssen Sie das in den Gleichungen 1-3 in Abschnitt 4 des Dokuments beschriebene Volumenintegral anwenden. Im Wesentlichen wird eine gewichtete Summierung aller Abtastwerte entlang der Sichtlinie jedes Pixels durchgeführt, um einen geschätzten Farbwert für dieses Pixel zu erhalten. Jede RGB-Probe wird mit ihrem Transparenz-Alpha-Wert gewichtet: Höhere Alpha-Werte weisen auf eine höhere Wahrscheinlichkeit hin, dass der abgetastete Bereich undurchsichtig ist, und daher ist es wahrscheinlicher, dass Punkte weiter entlang des Strahls verdeckt werden. Der kumulative Produktbetrieb sorgt dafür, dass diese weiteren Punkte unterdrückt werden.
Volumenrendering der ursprünglichen NeRF-Modellausgabe:
def raw2outputs(raw: torch.Tensor,z_vals: torch.Tensor,rays_d: torch.Tensor,raw_noise_std: float = 0.0,white_bkgd: bool = False) -> Tuple[torch.Tensor, torch.Tensor, torch.Tensor, torch.Tensor]:# 将原始的NeRF输出转为RGB和其他映射# Difference between consecutive elements of `z_vals`. [n_rays, n_samples]dists = z_vals[..., 1:] - z_vals[..., :-1]# ?这里减法的意义是啥?dists = torch.cat([dists, 1e10 * torch.ones_like(dists[..., :1])], dim=-1)# 将每个距离乘以其对应方向光线的范数,以转换为真实世界的距离(考虑非单位方向)dists = dists * torch.norm(rays_d[..., None, :], dim=-1)# 将噪声添加到模型对密度的预测中,用于在训练期间规范网络(防止漂浮物伪影)noise = 0.if raw_noise_std > 0.:noise = torch.randn(raw[..., 3].shape) * raw_noise_std# Predict density of each sample along each ray. Higher values imply# higher likelihood of being absorbed at this point. [n_rays, n_samples]alpha = 1.0 - torch.exp(-nn.functional.relu(raw[..., 3] + noise) * dists)# Compute weight for RGB of each sample along each ray. [n_rays, n_samples]# The higher the alpha, the lower subsequent weights are driven.weights = alpha * cumprod_exclusive(1. - alpha + 1e-10)# Compute weighted RGB map.rgb = torch.sigmoid(raw[..., :3])# [n_rays, n_samples, 3]rgb_map = torch.sum(weights[..., None] * rgb, dim=-2)# [n_rays, 3]# Estimated depth map is predicted distance.depth_map = torch.sum(weights * z_vals, dim=-1)# Disparity map is inverse depth.disp_map = 1. / torch.max(1e-10 * torch.ones_like(depth_map),depth_map / torch.sum(weights, -1))# Sum of weights along each ray. In [0, 1] up to numerical error.acc_map = torch.sum(weights, dim=-1)# To composite onto a white background, use the accumulated alpha map.if white_bkgd:rgb_map = rgb_map + (1. - acc_map[..., None])return rgb_map, depth_map, acc_map, weightsdef cumprod_exclusive(tensor: torch.Tensor) -> torch.Tensor:# (Courtesy of https://github.com/krrish94/nerf-pytorch)# Compute regular cumprod first.cumprod = torch.cumprod(tensor, -1)# "Roll" the elements along dimension 'dim' by 1 element.cumprod = torch.roll(cumprod, 1, -1)# Replace the first element by "1" as this is what tf.cumprod(..., exclusive=True) does.cumprod[..., 0] = 1.return cumprod
Frage: Was ist hier die Hauptfunktion? Was wurde eingegeben? Was ist Ausgabe?
3.4 Stratified Sampling
Der von der Kamera erfasste endgültige RGB-Wert ist die Ansammlung von Lichtproben entlang der Sichtlinie, die durch das Pixel verläuft. Die klassische Volumenrendering-Methode besteht darin, Punkte entlang der Sichtlinie zu akkumulieren und diese dann zu integrieren Punkte an jedem Punkt, Schätzung der Wahrscheinlichkeit, dass sich ein Lichtstrahl bewegt, ohne auf Partikel zu treffen. Daher muss jedes Pixel Punkte entlang des durch es hindurchgehenden Strahls abtasten. Um das Integral bestmöglich zu approximieren, unterteilt ihre geschichtete Stichprobenmethode den Raum gleichmäßig in N Behälter und entnimmt aus jedem Behälter gleichmäßig eine Stichprobe. Anstatt einfach Stichproben in gleichen Abständen zu ziehen, ermöglicht die geschichtete Stichprobenmethode dem Modell, Stichproben im kontinuierlichen Raum durchzuführen und so das Netzwerk so zu konditionieren, dass es im kontinuierlichen Raum lernt.
Bilder In PyTorch implementierte hierarchische Abtastung:
In PyTorch implementierte hierarchische Abtastung:
def sample_stratified(rays_o: torch.Tensor,rays_d: torch.Tensor,near: float,far: float,n_samples: int,perturb: Optional[bool] = True,inverse_depth: bool = False) -> Tuple[torch.Tensor, torch.Tensor]:# Sample along ray from regularly-spaced bins.# Grab samples for space integration along rayt_vals = torch.linspace(0., 1., n_samples, device=rays_o.device)if not inverse_depth:# Sample linearly between `near` and `far`z_vals = near * (1.-t_vals) + far * (t_vals)else:# Sample linearly in inverse depth (disparity)z_vals = 1./(1./near * (1.-t_vals) + 1./far * (t_vals))# Draw uniform samples from bins along rayif perturb:mids = .5 * (z_vals[1:] + z_vals[:-1])upper = torch.concat([mids, z_vals[-1:]], dim=-1)lower = torch.concat([z_vals[:1], mids], dim=-1)t_rand = torch.rand([n_samples], device=z_vals.device)z_vals = lower + (upper - lower) * t_randz_vals = z_vals.expand(list(rays_o.shape[:-1]) + [n_samples])# Apply scale from `rays_d` and offset from `rays_o` to samples# pts: (width, height, n_samples, 3)pts = rays_o[..., None, :] + rays_d[..., None, :] * z_vals[..., :, None]return pts, z_vals
3.5 Hierarchische Volumenabtastung (Hierarchical Volume Sampling)
Das Strahlungsfeld wird durch zwei mehrschichtige Perzeptrone dargestellt: eines arbeitet auf einer groben Ebene und die Szene Einer kodiert umfassende Struktureigenschaften; der andere verfeinert Details auf einer feinen Ebene und ermöglicht so dünne und komplexe Strukturen wie Netze und Zweige. Darüber hinaus sind die empfangenen Proben unterschiedlich, wobei grobe Modelle große, meist regelmäßig verteilte Proben über den gesamten Strahl verarbeiten, während feine Modelle Regionen mit starken Prioritäten verfeinern, um hervorstechende Informationen zu erhalten.
这种“珩磨”过程是通过层次体积采样流程完成的。3D空间实际上非常稀疏,存在遮挡,因此大多数点对渲染图像的贡献不大。因此,对具有对积分贡献可能性高的区域进行过采样(oversample)更有好处。他们将学习到的归一化权重应用于第一组样本,以在光线上创建PDF,然后再将inverse transform sampling应用于该PDF以收集第二组样本。该集合与第一集合相结合,并被馈送到精细网络以产生最终输出。
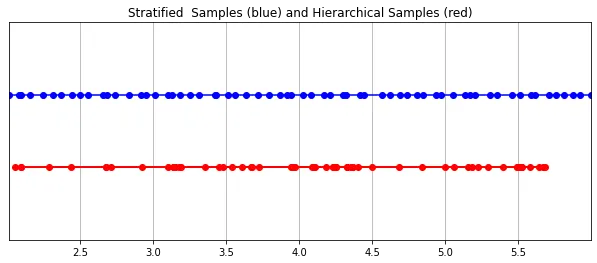
分层采样PyTorch实现:
def sample_hierarchical(rays_o: torch.Tensor,rays_d: torch.Tensor,z_vals: torch.Tensor,weights: torch.Tensor,n_samples: int,perturb: bool = False) -> Tuple[torch.Tensor, torch.Tensor, torch.Tensor]:# Apply hierarchical sampling to the rays.# Draw samples from PDF using z_vals as bins and weights as probabilities.z_vals_mid = .5 * (z_vals[..., 1:] + z_vals[..., :-1])new_z_samples = sample_pdf(z_vals_mid, weights[..., 1:-1], n_samples, perturb=perturb)new_z_samples = new_z_samples.detach()# Resample points from ray based on PDF.z_vals_combined, _ = torch.sort(torch.cat([z_vals, new_z_samples], dim=-1), dim=-1)# [N_rays, N_samples + n_samples, 3]pts = rays_o[..., None, :] + rays_d[..., None, :] * z_vals_combined[..., :, None]return pts, z_vals_combined, new_z_samplesdef sample_pdf(bins: torch.Tensor, weights: torch.Tensor, n_samples: int, perturb: bool = False) -> torch.Tensor:# Apply inverse transform sampling to a weighted set of points.# Normalize weights to get PDF.# [n_rays, weights.shape[-1]]pdf = (weights + 1e-5) / torch.sum(weights + 1e-5, -1, keepdims=True) # Convert PDF to CDF.cdf = torch.cumsum(pdf, dim=-1) # [n_rays, weights.shape[-1]]# [n_rays, weights.shape[-1] + 1]cdf = torch.concat([torch.zeros_like(cdf[..., :1]), cdf], dim=-1) # Take sample positions to grab from CDF. Linear when perturb == 0.if not perturb:u = torch.linspace(0., 1., n_samples, device=cdf.device)u = u.expand(list(cdf.shape[:-1]) + [n_samples]) # [n_rays, n_samples]else:# [n_rays, n_samples]u = torch.rand(list(cdf.shape[:-1]) + [n_samples], device=cdf.device) # Find indices along CDF where values in u would be placed.u = u.contiguous() # Returns contiguous tensor with same values.inds = torch.searchsorted(cdf, u, right=True) # [n_rays, n_samples]# Clamp indices that are out of bounds.below = torch.clamp(inds - 1, min=0)above = torch.clamp(inds, max=cdf.shape[-1] - 1)inds_g = torch.stack([below, above], dim=-1) # [n_rays, n_samples, 2]# Sample from cdf and the corresponding bin centers.matched_shape = list(inds_g.shape[:-1]) + [cdf.shape[-1]]cdf_g = torch.gather(cdf.unsqueeze(-2).expand(matched_shape), dim=-1,index=inds_g)bins_g = torch.gather(bins.unsqueeze(-2).expand(matched_shape), dim=-1, index=inds_g)# Convert samples to ray length.denom = (cdf_g[..., 1] - cdf_g[..., 0])denom = torch.where(denom <h3 id="Training">4 Training</h3><p>论文中训练NeRF推荐的每网络8层、每层256维的架构在训练过程中会消耗大量内存。缓解这种情况的方法是将前传(forward pass)分成更小的部分,然后在这些部分上积累梯度。注意与minibatching的区别:梯度是在采样光线的单个小批次上累积的,这些光线可能已经被收集成块。如果没有论文中使用的NVIDIA V100类似性能的GPU,可能必须相应地调整块大小以避免OOM错误。Colab笔记本采用了更小的架构和更适中的分块尺寸。</p><p>我个人发现,由于局部极小值,即使选择了许多默认值,NeRF的训练也有些棘手。一些有帮助的技术包括早期训练迭代和早期重新启动期间的中心裁剪(center cropping)。随意尝试不同的超参数和技术,以进一步提高训练收敛性。</p><h4 id="初始化">初始化</h4><pre class="brush:php;toolbar:false">def init_models():# Initialize models, encoders, and optimizer for NeRF training.encoder = PositionalEncoder(d_input, n_freqs, log_space=log_space)encode = lambda x: encoder(x)# View direction encodersif use_viewdirs:encoder_viewdirs = PositionalEncoder(d_input, n_freqs_views,log_space=log_space)encode_viewdirs= lambda x: encoder_viewdirs(x)d_viewdirs = encoder_viewdirs.d_outputelse:encode_viewdirs = Noned_viewdirs = Nonemodel = NeRF(encoder.d_output, n_layers=n_layers, d_filter=d_filter, skip=skip,d_viewdirs=d_viewdirs)model.to(device)model_params = list(model.parameters())if use_fine_model:fine_model = NeRF(encoder.d_output, n_layers=n_layers, d_filter=d_filter, skip=skip,d_viewdirs=d_viewdirs)fine_model.to(device)model_params = model_params + list(fine_model.parameters())else:fine_model = Noneoptimizer= torch.optim.Adam(model_params, lr=lr)warmup_stopper = EarlyStopping(patience=50)return model, fine_model, encode, encode_viewdirs, optimizer, warmup_stopper
训练
def train():# Launch training session for NeRF.# Shuffle rays across all images.if not one_image_per_step:height, width = images.shape[1:3]all_rays = torch.stack([torch.stack(get_rays(height, width, focal, p), 0) for p in poses[:n_training]], 0)rays_rgb = torch.cat([all_rays, images[:, None]], 1)rays_rgb = torch.permute(rays_rgb, [0, 2, 3, 1, 4])rays_rgb = rays_rgb.reshape([-1, 3, 3])rays_rgb = rays_rgb.type(torch.float32)rays_rgb = rays_rgb[torch.randperm(rays_rgb.shape[0])]i_batch = 0train_psnrs = []val_psnrs = []iternums = []for i in trange(n_iters):model.train()if one_image_per_step:# Randomly pick an image as the target.target_img_idx = np.random.randint(images.shape[0])target_img = images[target_img_idx].to(device)if center_crop and i = rays_rgb.shape[0]:rays_rgb = rays_rgb[torch.randperm(rays_rgb.shape[0])]i_batch = 0target_img = target_img.reshape([-1, 3])# Run one iteration of TinyNeRF and get the rendered RGB image.outputs = nerf_forward(rays_o, rays_d, near, far, encode, model, kwargs_sample_stratified=kwargs_sample_stratified, n_samples_hierarchical=n_samples_hierarchical, kwargs_sample_hierarchical=kwargs_sample_hierarchical, fine_model=fine_model, viewdirs_encoding_fn=encode_viewdirs, chunksize=chunksize)# Backprop!rgb_predicted = outputs['rgb_map']loss = torch.nn.functional.mse_loss(rgb_predicted, target_img)loss.backward()optimizer.step()optimizer.zero_grad()psnr = -10. * torch.log10(loss)train_psnrs.append(psnr.item())# Evaluate testimg at given display rate.if i % display_rate == 0:model.eval()height, width = testimg.shape[:2]rays_o, rays_d = get_rays(height, width, focal, testpose)rays_o = rays_o.reshape([-1, 3])rays_d = rays_d.reshape([-1, 3])outputs = nerf_forward(rays_o, rays_d, near, far, encode, model, kwargs_sample_stratified=kwargs_sample_stratified, n_samples_hierarchical=n_samples_hierarchical, kwargs_sample_hierarchical=kwargs_sample_hierarchical, fine_model=fine_model, viewdirs_encoding_fn=encode_viewdirs, chunksize=chunksize)rgb_predicted = outputs['rgb_map']loss = torch.nn.functional.mse_loss(rgb_predicted, testimg.reshape(-1, 3))val_psnr = -10. * torch.log10(loss)val_psnrs.append(val_psnr.item())iternums.append(i)# Check PSNR for issues and stop if any are found.if i == warmup_iters - 1:if val_psnr <h4 id="训练">训练</h4><pre class="brush:php;toolbar:false"># Run training session(s)for _ in range(n_restarts):model, fine_model, encode, encode_viewdirs, optimizer, warmup_stopper = init_models()success, train_psnrs, val_psnrs = train()if success and val_psnrs[-1] >= warmup_min_fitness:print('Training successful!')breakprint(f'Done!')5 Conclusion
辐射场标志着处理3D数据的方式发生了巨大变化。NeRF模型和更广泛的可微分渲染正在迅速弥合图像创建和体积场景创建之间的差距。虽然我们的组件可能看起来非常复杂,但受vanilla NeRF启发的无数其他方法证明,基本概念(连续函数逼近器+可微分渲染器)是构建各种解决方案的坚实基础,这些解决方案可用于几乎无限的情况。
原文:NeRF From Nothing: A Tutorial with PyTorch | Towards Data Science
原文链接:https://mp.weixin.qq.com/s/zxJAIpAmLgsIuTsPqQqOVg
Das obige ist der detaillierte Inhalt vonWas ist NeRF? Ist die NeRF-basierte 3D-Rekonstruktion voxelbasiert?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Stellen Sie sich ein Modell der künstlichen Intelligenz vor, das nicht nur die Fähigkeit besitzt, die traditionelle Datenverarbeitung zu übertreffen, sondern auch eine effizientere Leistung zu geringeren Kosten erzielt. Dies ist keine Science-Fiction, DeepSeek-V2[1], das weltweit leistungsstärkste Open-Source-MoE-Modell, ist da. DeepSeek-V2 ist ein leistungsstarkes MoE-Sprachmodell (Mix of Experts) mit den Merkmalen eines wirtschaftlichen Trainings und einer effizienten Inferenz. Es besteht aus 236B Parametern, von denen 21B zur Aktivierung jedes Markers verwendet werden. Im Vergleich zu DeepSeek67B bietet DeepSeek-V2 eine stärkere Leistung, spart gleichzeitig 42,5 % der Trainingskosten, reduziert den KV-Cache um 93,3 % und erhöht den maximalen Generierungsdurchsatz auf das 5,76-fache. DeepSeek ist ein Unternehmen, das sich mit allgemeiner künstlicher Intelligenz beschäftigt
 KI untergräbt die mathematische Forschung! Der Gewinner der Fields-Medaille und der chinesisch-amerikanische Mathematiker führten 11 hochrangige Arbeiten an | Gefällt mir bei Terence Tao
Apr 09, 2024 am 11:52 AM
KI untergräbt die mathematische Forschung! Der Gewinner der Fields-Medaille und der chinesisch-amerikanische Mathematiker führten 11 hochrangige Arbeiten an | Gefällt mir bei Terence Tao
Apr 09, 2024 am 11:52 AM
KI verändert tatsächlich die Mathematik. Vor kurzem hat Tao Zhexuan, der diesem Thema große Aufmerksamkeit gewidmet hat, die neueste Ausgabe des „Bulletin of the American Mathematical Society“ (Bulletin der American Mathematical Society) weitergeleitet. Zum Thema „Werden Maschinen die Mathematik verändern?“ äußerten viele Mathematiker ihre Meinung. Der gesamte Prozess war voller Funken, knallhart und aufregend. Der Autor verfügt über eine starke Besetzung, darunter der Fields-Medaillengewinner Akshay Venkatesh, der chinesische Mathematiker Zheng Lejun, der NYU-Informatiker Ernest Davis und viele andere bekannte Wissenschaftler der Branche. Die Welt der KI hat sich dramatisch verändert. Viele dieser Artikel wurden vor einem Jahr eingereicht.
 Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas tritt offiziell in die Ära der Elektroroboter ein! Gestern hat sich der hydraulische Atlas einfach „unter Tränen“ von der Bühne der Geschichte zurückgezogen. Heute gab Boston Dynamics bekannt, dass der elektrische Atlas im Einsatz ist. Es scheint, dass Boston Dynamics im Bereich kommerzieller humanoider Roboter entschlossen ist, mit Tesla zu konkurrieren. Nach der Veröffentlichung des neuen Videos wurde es innerhalb von nur zehn Stunden bereits von mehr als einer Million Menschen angesehen. Die alten Leute gehen und neue Rollen entstehen. Das ist eine historische Notwendigkeit. Es besteht kein Zweifel, dass dieses Jahr das explosive Jahr der humanoiden Roboter ist. Netizens kommentierten: Die Weiterentwicklung der Roboter hat dazu geführt, dass die diesjährige Eröffnungsfeier wie Menschen aussieht, und der Freiheitsgrad ist weitaus größer als der von Menschen. Aber ist das wirklich kein Horrorfilm? Zu Beginn des Videos liegt Atlas ruhig auf dem Boden, scheinbar auf dem Rücken. Was folgt, ist atemberaubend
 Jenseits von ORB-SLAM3! SL-SLAM: Szenen mit wenig Licht, starkem Jitter und schwacher Textur werden verarbeitet
May 30, 2024 am 09:35 AM
Jenseits von ORB-SLAM3! SL-SLAM: Szenen mit wenig Licht, starkem Jitter und schwacher Textur werden verarbeitet
May 30, 2024 am 09:35 AM
Heute diskutieren wir darüber, wie Deep-Learning-Technologie die Leistung von visionbasiertem SLAM (Simultaneous Localization and Mapping) in komplexen Umgebungen verbessern kann. Durch die Kombination von Methoden zur Tiefenmerkmalsextraktion und Tiefenanpassung stellen wir hier ein vielseitiges hybrides visuelles SLAM-System vor, das die Anpassung in anspruchsvollen Szenarien wie schlechten Lichtverhältnissen, dynamischer Beleuchtung, schwach strukturierten Bereichen und starkem Jitter verbessern soll. Unser System unterstützt mehrere Modi, einschließlich erweiterter Monokular-, Stereo-, Monokular-Trägheits- und Stereo-Trägheitskonfigurationen. Darüber hinaus wird analysiert, wie visuelles SLAM mit Deep-Learning-Methoden kombiniert werden kann, um andere Forschungen zu inspirieren. Durch umfangreiche Experimente mit öffentlichen Datensätzen und selbst abgetasteten Daten demonstrieren wir die Überlegenheit von SL-SLAM in Bezug auf Positionierungsgenauigkeit und Tracking-Robustheit.
 KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
Anfang dieses Monats schlugen Forscher des MIT und anderer Institutionen eine vielversprechende Alternative zu MLP vor – KAN. KAN übertrifft MLP in Bezug auf Genauigkeit und Interpretierbarkeit. Und es kann MLP, das mit einer größeren Anzahl von Parametern ausgeführt wird, mit einer sehr kleinen Anzahl von Parametern übertreffen. Beispielsweise gaben die Autoren an, dass sie KAN nutzten, um die Ergebnisse von DeepMind mit einem kleineren Netzwerk und einem höheren Automatisierungsgrad zu reproduzieren. Konkret verfügt DeepMinds MLP über etwa 300.000 Parameter, während KAN nur etwa 200 Parameter hat. KAN hat eine starke mathematische Grundlage wie MLP und basiert auf dem universellen Approximationssatz, während KAN auf dem Kolmogorov-Arnold-Darstellungssatz basiert. Wie in der folgenden Abbildung gezeigt, hat KAN
 Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Die von Google geförderte Leistung von JAX hat in jüngsten Benchmark-Tests die von Pytorch und TensorFlow übertroffen und belegt bei 7 Indikatoren den ersten Platz. Und der Test wurde nicht auf der TPU mit der besten JAX-Leistung durchgeführt. Obwohl unter Entwicklern Pytorch immer noch beliebter ist als Tensorflow. Aber in Zukunft werden möglicherweise mehr große Modelle auf Basis der JAX-Plattform trainiert und ausgeführt. Modelle Kürzlich hat das Keras-Team drei Backends (TensorFlow, JAX, PyTorch) mit der nativen PyTorch-Implementierung und Keras2 mit TensorFlow verglichen. Zunächst wählen sie eine Reihe von Mainstream-Inhalten aus
 Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Das neueste Video von Teslas Roboter Optimus ist veröffentlicht und er kann bereits in der Fabrik arbeiten. Bei normaler Geschwindigkeit sortiert es Batterien (Teslas 4680-Batterien) so: Der Beamte hat auch veröffentlicht, wie es bei 20-facher Geschwindigkeit aussieht – auf einer kleinen „Workstation“, pflücken und pflücken und pflücken: Dieses Mal wird es freigegeben. Eines der Highlights Der Vorteil des Videos besteht darin, dass Optimus diese Arbeit in der Fabrik völlig autonom und ohne menschliches Eingreifen während des gesamten Prozesses erledigt. Und aus Sicht von Optimus kann es auch die krumme Batterie aufnehmen und platzieren, wobei der Schwerpunkt auf der automatischen Fehlerkorrektur liegt: In Bezug auf die Hand von Optimus gab der NVIDIA-Wissenschaftler Jim Fan eine hohe Bewertung ab: Die Hand von Optimus ist der fünffingrige Roboter der Welt am geschicktesten. Seine Hände sind nicht nur taktil
 FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
Die Zielerkennung ist ein relativ ausgereiftes Problem in autonomen Fahrsystemen, wobei die Fußgängererkennung einer der ersten Algorithmen ist, die eingesetzt werden. In den meisten Arbeiten wurde eine sehr umfassende Recherche durchgeführt. Die Entfernungswahrnehmung mithilfe von Fischaugenkameras für die Rundumsicht ist jedoch relativ wenig untersucht. Aufgrund der großen radialen Verzerrung ist es schwierig, die standardmäßige Bounding-Box-Darstellung in Fischaugenkameras zu implementieren. Um die obige Beschreibung zu vereinfachen, untersuchen wir erweiterte Begrenzungsrahmen-, Ellipsen- und allgemeine Polygondesigns in Polar-/Winkeldarstellungen und definieren eine mIOU-Metrik für die Instanzsegmentierung, um diese Darstellungen zu analysieren. Das vorgeschlagene Modell „fisheyeDetNet“ mit polygonaler Form übertrifft andere Modelle und erreicht gleichzeitig 49,5 % mAP auf dem Valeo-Fisheye-Kameradatensatz für autonomes Fahren
