
 Technologie-Peripheriegeräte
KI
Wählen Sie GPT-3.5 oder optimieren Sie Open-Source-Modelle wie Llama 2? Nach einem umfassenden Vergleich lautet die Antwort
Technologie-Peripheriegeräte
KI
Wählen Sie GPT-3.5 oder optimieren Sie Open-Source-Modelle wie Llama 2? Nach einem umfassenden Vergleich lautet die Antwort
Wählen Sie GPT-3.5 oder optimieren Sie Open-Source-Modelle wie Llama 2? Nach einem umfassenden Vergleich lautet die Antwort

Es ist bekannt, dass die Feinabstimmung von GPT-3.5 sehr teuer ist. In diesem Artikel wird anhand von Experimenten überprüft, ob manuell fein abgestimmte Modelle die Leistung von GPT-3.5 zu einem Bruchteil der Kosten erreichen können. Interessanterweise tut dieser Artikel genau das. Beim Vergleich der Ergebnisse von
zu SQL-Aufgaben und Funktionsdarstellungsaufgaben wurde in diesem Artikel Folgendes festgestellt:
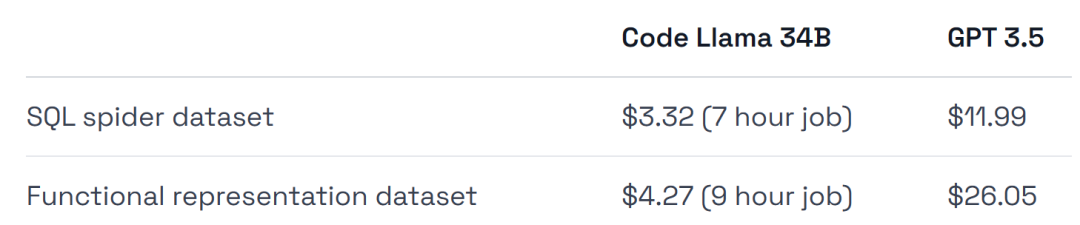
- GPT-3.5 ist bei beiden Datensätzen (einer Teilmenge des Spider-Datensatzes und des Viggo-Funktionsdarstellungsdatensatzes) besser ) als nach Code Llama 34B, der von Lora verfeinert wurde, schnitt etwas besser ab.
- GPT-3.5 ist vier- bis sechsmal teurer in der Schulung und teurer in der Bereitstellung.
Eine der Schlussfolgerungen dieses Experiments ist, dass die Feinabstimmung von GPT-3.5 für die erste Verifizierungsarbeit geeignet ist, danach jedoch ein Modell wie Llama 2 die beste Wahl sein könnte:
- Wenn Sie überprüfen möchten, ob die Feinabstimmung der richtige Weg zur Lösung einer bestimmten Aufgabe/eines bestimmten Datensatzes ist, oder wenn Sie eine vollständig verwaltete Umgebung wünschen, dann optimieren Sie GPT-3.5.
- Wenn Sie Geld sparen, maximale Leistung aus Ihrem Datensatz herausholen, mehr Flexibilität beim Training und der Bereitstellung der Infrastruktur haben oder einige private Daten behalten möchten, dann optimieren Sie etwas wie Llama 2, ein Open-Source-Modell.
Als nächstes wollen wir sehen, wie dieser Artikel umgesetzt wird.
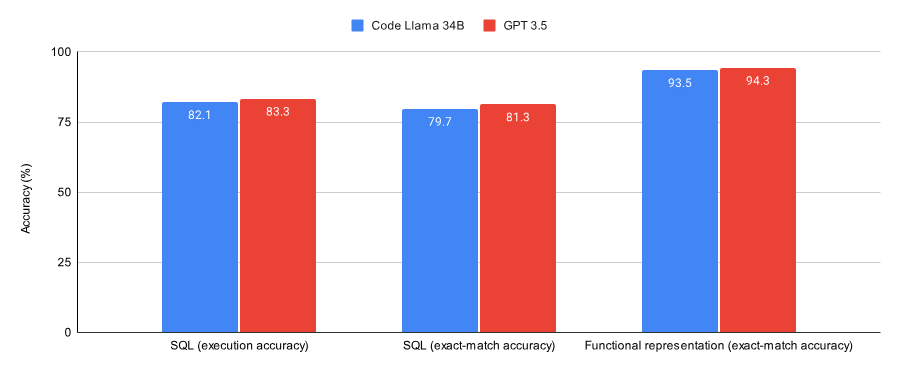
Das Bild unten zeigt die Leistung von Code Llama 34B und GPT-3.5, die auf Konvergenz bei SQL-Aufgaben und funktionalen Darstellungsaufgaben trainiert wurden. Die Ergebnisse zeigen, dass GPT-3.5 bei beiden Aufgaben eine bessere Genauigkeit erreicht.
In Bezug auf die Hardwarenutzung wurde im Experiment eine A40-GPU verwendet, die etwa 0,475 US-Dollar pro Stunde kostet.
Darüber hinaus wurden im Experiment zwei Datensätze ausgewählt, die sich sehr gut für die Feinabstimmung eignen, eine Teilmenge des Spider-Datensatzes und des Viggo-Funktionsdarstellungsdatensatzes.
Um einen fairen Vergleich mit dem GPT-3.5-Modell zu ermöglichen, führte das Experiment eine minimale Feinabstimmung der Hyperparameter an Llama durch.
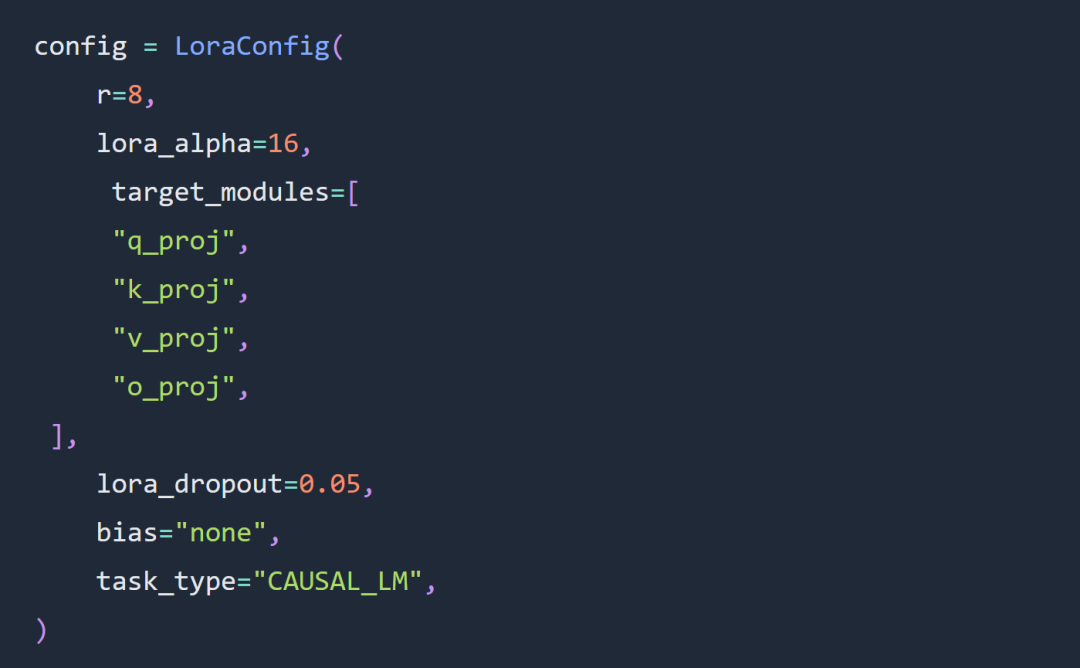
Die beiden wichtigsten Optionen in den Experimenten dieses Artikels sind die Verwendung der Code-Llama-34B- und Lora-Feinabstimmung anstelle der vollständigen Parameter-Feinabstimmung.
Das Experiment folgte weitgehend den Regeln für die Feinabstimmung von Lora Hyperparameter. Die LORA-Adapterkonfiguration lautet wie folgt:
SQL-Eingabeaufforderung lautet wie folgt:
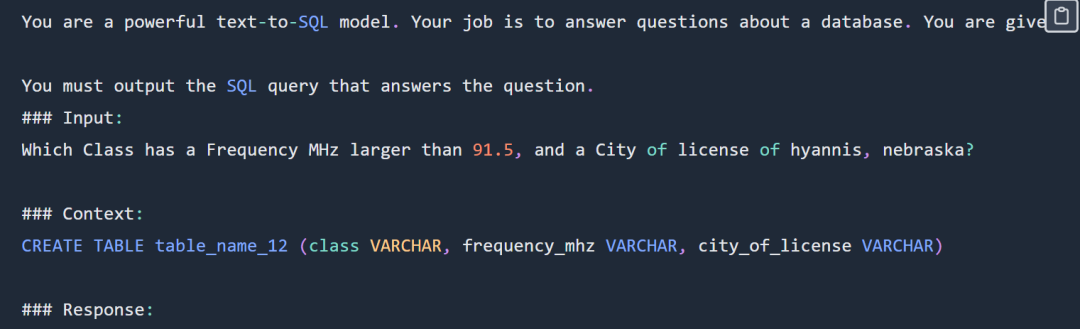
SQL-Eingabeaufforderung Teilweise Anzeige. Vollständige Tipps finden Sie im Originalblog. Das Experiment hat nicht den gesamten Spider-Datensatz verwendet. Create-Context-Datensatz und der Spider-Datensatz. Der für das Modell bereitgestellte Kontext ist ein SQL-Erstellungsbefehl wie folgt:
department : Department_ID [ INT ] primary_key Name [ TEXT ] Creation [ TEXT ] Ranking [ INT ] Budget_in_Billions [ INT ] Num_Employees [ INT ] head : head_ID [ INT ] primary_key name [ TEXT ] born_state [ TEXT ] age [ INT ] management : department_ID [ INT ] primary_key management.department_ID = department.Department_ID head_ID [ INT ] management.head_ID = head.head_ID temporary_acting [ TEXT ]
Code und Daten für die SQL-Aufgabe: https://github.com/samlhuillier/spider-sql-finetune
Funktionsdarstellung Tipps Die Das Beispiel lautet wie folgt:
Der Tipp zur funktionalen Darstellung wird teilweise angezeigt. Den vollständigen Tipp finden Sie im Originalblog.
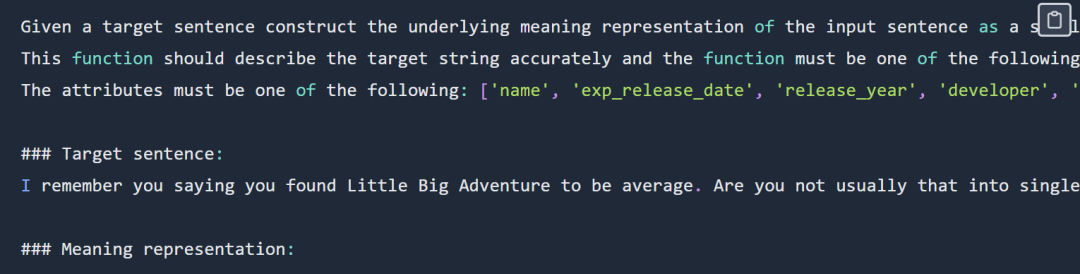 Die Ausgabe lautet wie folgt:
Die Ausgabe lautet wie folgt:
CREATE TABLE table_name_12 (class VARCHAR, frequency_mhz VARCHAR, city_of_license VARCHAR)
In der Evaluierungsphase , die beiden Experimente wurden schnell abgeschlossen. Konvergiert:
funktionale Darstellung Aufgabencode und Datenadresse: https://github.com/samlhuillier/viggo-finetune
Weitere Informationen finden Sie im Originalblog . 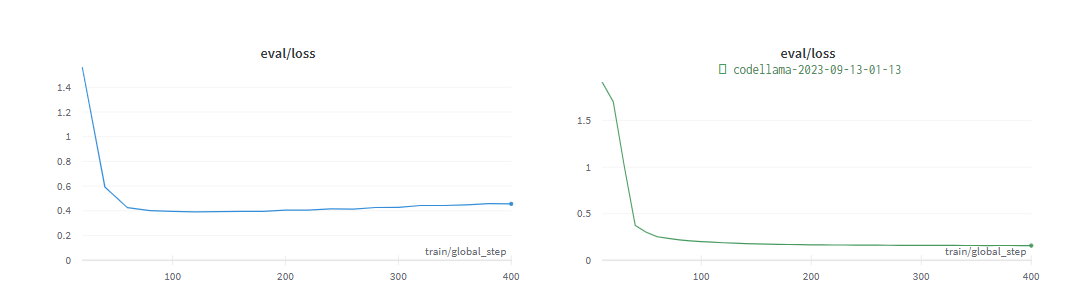
Das obige ist der detaillierte Inhalt vonWählen Sie GPT-3.5 oder optimieren Sie Open-Source-Modelle wie Llama 2? Nach einem umfassenden Vergleich lautet die Antwort. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 Wie erstelle ich dynamisch ein Objekt über eine Zeichenfolge und rufe seine Methoden in Python auf?
Apr 01, 2025 pm 11:18 PM
Wie erstelle ich dynamisch ein Objekt über eine Zeichenfolge und rufe seine Methoden in Python auf?
Apr 01, 2025 pm 11:18 PM
Wie erstellt in Python ein Objekt dynamisch über eine Zeichenfolge und ruft seine Methoden auf? Dies ist eine häufige Programmieranforderung, insbesondere wenn sie konfiguriert oder ausgeführt werden muss ...
 Wie kann man Go oder Rost verwenden, um Python -Skripte anzurufen, um eine echte parallele Ausführung zu erreichen?
Apr 01, 2025 pm 11:39 PM
Wie kann man Go oder Rost verwenden, um Python -Skripte anzurufen, um eine echte parallele Ausführung zu erreichen?
Apr 01, 2025 pm 11:39 PM
Wie kann man Go oder Rost verwenden, um Python -Skripte anzurufen, um eine echte parallele Ausführung zu erreichen? Vor kurzem habe ich Python verwendet ...
 Python Asyncio Telnet Connection wird sofort getrennt: Wie löst ich das serverseitige Blockierungsproblem?
Apr 02, 2025 am 06:30 AM
Python Asyncio Telnet Connection wird sofort getrennt: Wie löst ich das serverseitige Blockierungsproblem?
Apr 02, 2025 am 06:30 AM
Über Pythonasyncio ...
 Wie kann die technische Fragen und Antworten in der Chatgpt -Ära auf Herausforderungen reagieren?
Apr 01, 2025 pm 11:51 PM
Wie kann die technische Fragen und Antworten in der Chatgpt -Ära auf Herausforderungen reagieren?
Apr 01, 2025 pm 11:51 PM
Die technische Q & A -Community in der Chatgpt -Ära: SegmentFaults Antwortstrategie Stackoverflow ...
 Was ist der Grund, warum Pipeline -Dateien bei der Verwendung von Scapy Crawler nicht geschrieben werden können?
Apr 02, 2025 am 06:45 AM
Was ist der Grund, warum Pipeline -Dateien bei der Verwendung von Scapy Crawler nicht geschrieben werden können?
Apr 02, 2025 am 06:45 AM
Diskussion über die Gründe, warum Pipeline -Dateien beim Lernen und Verwendung von Scapy -Crawlern für anhaltende Datenspeicher nicht geschrieben werden können, können Sie auf Pipeline -Dateien begegnen ...
 Wie kann man mit dem Fehler in der Python-Multi-Process-Rohrkommunikation anmutig umgehen?
Apr 01, 2025 pm 11:12 PM
Wie kann man mit dem Fehler in der Python-Multi-Process-Rohrkommunikation anmutig umgehen?
Apr 01, 2025 pm 11:12 PM
Python Multi-Process-Rohrfehler "Pipe ist geschlossen"? Wenn Sie die Pipe-Methode in Pythons Multiprocessing-Modul für die Kommunikation über Eltern-Kind-Prozess verwenden, können Sie ...
 Wie löse ich das Problem des fehlenden dynamischen Ladeninhalts beim Erhalten von Webseitendaten?
Apr 01, 2025 pm 11:24 PM
Wie löse ich das Problem des fehlenden dynamischen Ladeninhalts beim Erhalten von Webseitendaten?
Apr 01, 2025 pm 11:24 PM
Probleme und Lösungen, die bei der Verwendung der Anforderungsbibliothek zum Crawl -Webseitendaten auftreten. Wenn Sie die Anforderungsbibliothek verwenden, um Webseitendaten zu erhalten, begegnen Sie manchmal auf die ...
 Wie behandle ich die mit Kommas getrennten Listen-Abfrageparameter in Fastapi?
Apr 02, 2025 am 06:51 AM
Wie behandle ich die mit Kommas getrennten Listen-Abfrageparameter in Fastapi?
Apr 02, 2025 am 06:51 AM
Fastapi ...
