
 Technologie-Peripheriegeräte
KI
MiniGPT-4 wurde auf MiniGPT-v2 aktualisiert. Multimodale Aufgaben können weiterhin ohne GPT-4 erledigt werden.
Technologie-Peripheriegeräte
KI
MiniGPT-4 wurde auf MiniGPT-v2 aktualisiert. Multimodale Aufgaben können weiterhin ohne GPT-4 erledigt werden.
MiniGPT-4 wurde auf MiniGPT-v2 aktualisiert. Multimodale Aufgaben können weiterhin ohne GPT-4 erledigt werden.

Vor einigen Monaten haben mehrere Forscher von KAUST (King Abdullah University of Science and Technology, Saudi-Arabien) ein Projekt namens MiniGPT-4 vorgeschlagen, das ein ähnliches GPT-4-Bildverständnis und einen ähnlichen Dialog ermöglichen kann Fähigkeiten.
MiniGPT-4 kann beispielsweise die Szene im Bild unten beantworten: „Das Bild beschreibt einen Kaktus, der auf einem zugefrorenen See wächst. Um den Kaktus herum befinden sich riesige Eiskristalle und in der Ferne sind schneebedeckte Gipfel zu sehen.“ ...“ Wenn Sie sich dann fragen, ob dieses Szenario in der realen Welt passieren könnte? Die Antwort von MiniGPT-4 lautet, dass dieses Bild in der realen Welt nicht häufig vorkommt und warum.

Vor Kurzem gaben das KAUST-Team und Forscher von Meta bekannt, dass sie MiniGPT-4 auf die MiniGPT-v2-Version aktualisiert haben.

Papieradresse: https://arxiv.org/pdf/2310.09478.pdf
Papierhomepage: https://minigpt-v2.github.io/
Demo: https: //minigpt-v2.github.io/
Konkret kann MiniGPT-v2 als einheitliche Schnittstelle dienen, um verschiedene visuell-linguistische Aufgaben besser zu bewältigen. Gleichzeitig empfiehlt dieser Artikel die Verwendung eindeutiger Identifikationssymbole für verschiedene Aufgaben beim Training des Modells. Diese Identifikationssymbole helfen dem Modell, jede Aufgabenanweisung leicht zu unterscheiden und die Lerneffizienz jedes Aufgabenmodells zu verbessern.
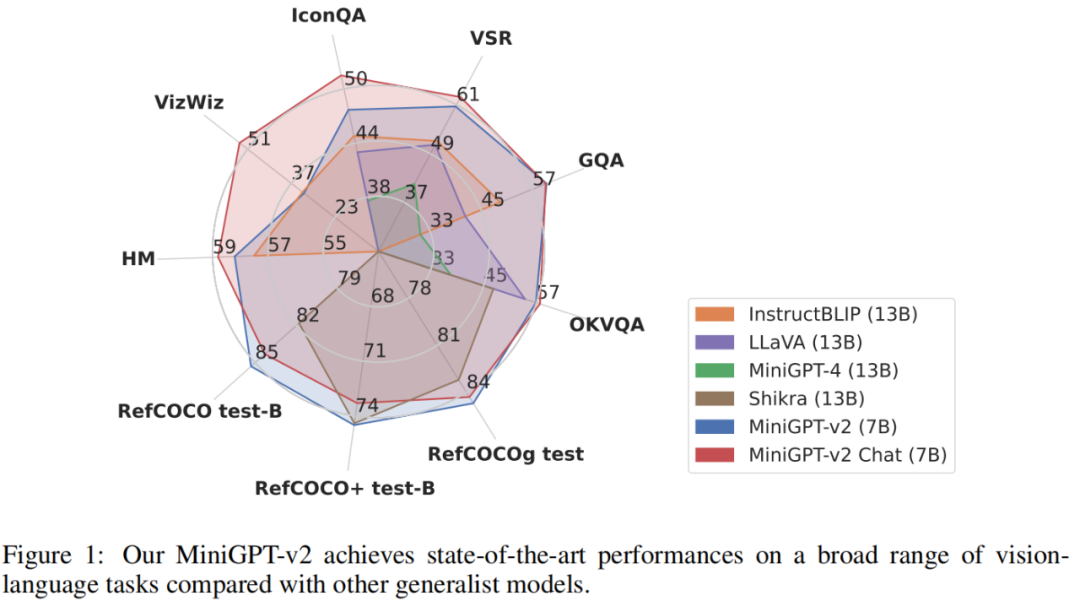
Um die Leistung des MiniGPT-v2-Modells zu bewerten, führten die Forscher umfangreiche Experimente zu verschiedenen visuellen Sprachaufgaben durch. Die Ergebnisse zeigen, dass MiniGPT-v2 bei verschiedenen Benchmarks eine SOTA- oder vergleichbare Leistung im Vergleich zu früheren Vision-Language-Allzweckmodellen wie MiniGPT-4, InstructBLIP, LLaVA und Shikra erreicht. Beispielsweise übertrifft MiniGPT-v2 MiniGPT-4 um 21,3 %, InstructBLIP um 11,3 % und LLaVA um 11,7 % im VSR-Benchmark.
Im Folgenden veranschaulichen wir anhand konkreter Beispiele die Rolle von MiniGPT-v2-Identifikationssymbolen.
Durch Hinzufügen des Erkennungssymbols [Erdung] kann das Modell beispielsweise problemlos eine Bildbeschreibung mit räumlicher Standorterkennung generieren:

Durch Hinzufügen des Erkennungssymbols [Erkennung] kann das Modell direkt extrahieren Geben Sie den Eingabetext ein und finden Sie ihre räumliche Position im Bild:

Durch Hinzufügen von [identifizieren] kann das Modell den Namen des Objekts direkt identifizieren:
 Übergeben Sie Add [refer] und eine Beschreibung eines Objekts, und das Modell kann Ihnen direkt dabei helfen, die entsprechende räumliche Position des Objekts zu finden:
Übergeben Sie Add [refer] und eine Beschreibung eines Objekts, und das Modell kann Ihnen direkt dabei helfen, die entsprechende räumliche Position des Objekts zu finden:

Sie können die Übereinstimmung auch identifizieren, ohne Aufgaben hinzuzufügen, und ein Gespräch mit ihnen führen Das Bild:

Die räumliche Wahrnehmung des Modells ist ebenfalls stärker geworden. Sie können das Modell, das links, in der Mitte und rechts im Bild erscheint, direkt fragen:

Methodeneinführung
Die Modellarchitektur von MiniGPT-v2 ist in der folgenden Abbildung dargestellt. Sie besteht aus drei Teilen: visuellem Rückgrat, linearer Projektionsschicht und großem Sprachmodell.

Visuelles Rückgrat: MiniGPT-v2 verwendet EVA als Rückgratmodell und das visuelle Rückgrat wird während des Trainings eingefroren. Das Modell wird auf eine Bildauflösung von 448 x 448 trainiert und zur Skalierung auf höhere Bildauflösungen wird eine Positionskodierung eingefügt.
Lineare Projektionsebene: Dieser Artikel zielt darauf ab, alle visuellen Token aus dem eingefrorenen visuellen Rückgrat in den Sprachmodellraum zu projizieren. Bei Bildern mit höherer Auflösung (z. B. 448 x 448) führt die Projektion aller Bildtoken jedoch zu sehr langen Sequenzeingaben (z. B. 1024 Token), wodurch die Trainings- und Inferenzeffizienz erheblich verringert wird. Daher verkettet dieser Artikel einfach vier benachbarte visuelle Token im Einbettungsraum und projiziert sie zusammen in eine einzige Einbettung im gleichen Merkmalsraum eines großen Sprachmodells, wodurch die Anzahl der visuellen Eingabetoken um den Faktor 4 reduziert wird.
Groß angelegtes Sprachmodell: MiniGPT-v2 verwendet den Open-Source-LLaMA2-Chat (7B) als Rückgrat des Sprachmodells. In dieser Forschung wird das Sprachmodell als einheitliche Schnittstelle für verschiedene visuelle Spracheingaben betrachtet. In diesem Artikel werden LLaMA-2-Sprachtoken direkt verwendet, um verschiedene visuelle Sprachaufgaben auszuführen. Für grundlegende Sehaufgaben, die die Generierung räumlicher Standorte erfordern, erfordert dieser Artikel direkt, dass das Sprachmodell Textdarstellungen von Begrenzungsrahmen generiert, um deren räumliche Standorte darzustellen.
Multitask-Anweisungstraining
In diesem Artikel werden symbolische Anweisungen zur Aufgabenerkennung verwendet, um das Modell zu trainieren, das in drei Phasen unterteilt ist. Die in jeder Trainingsphase verwendeten Datensätze sind in Tabelle 2 aufgeführt.

Phase 1: Vortraining. Dieses Papier gibt schwach gekennzeichneten Datensätzen eine hohe Abtastrate, um vielfältigeres Wissen zu erhalten.
Phase 2: Multitasking-Training. Um die Leistung von MiniGPT-v2 bei jeder Aufgabe zu verbessern, konzentriert sich die aktuelle Phase nur auf die Verwendung feinkörniger Datensätze zum Trainieren des Modells. Die Forscher schlossen schwach überwachte Datensätze wie GRIT-20M und LAION aus Stufe 1 aus und aktualisierten das Datenabtastverhältnis entsprechend der Häufigkeit jeder Aufgabe. Diese Strategie ermöglicht es unserem Modell, qualitativ hochwertige ausgerichtete Bild-Text-Daten zu priorisieren, was zu einer überlegenen Leistung bei einer Vielzahl von Aufgaben führt.
Phase 3: Multimodale Instruktionsabstimmung. Anschließend konzentriert sich dieses Papier auf die Verwendung weiterer multimodaler Befehlsdatensätze, um das Modell zu verfeinern und seine Konversationsfähigkeiten als Chatbot zu verbessern.
Schließlich stellt der Beamte den Lesern auch eine Demo zum Testen zur Verfügung. Auf der linken Seite des Bildes unten laden wir beispielsweise ein Foto hoch, wählen dann [Erkennung] und geben dann „roter Ballon“ ein werden den roten Ballon auf dem Bild erkennen können:

Interessierte Leser können auf der Homepage der Zeitung nach weiteren Informationen suchen.
Das obige ist der detaillierte Inhalt vonMiniGPT-4 wurde auf MiniGPT-v2 aktualisiert. Multimodale Aufgaben können weiterhin ohne GPT-4 erledigt werden.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1382
1382
 52
52

 CentOS Shutdown -Befehlszeile
Apr 14, 2025 pm 09:12 PM
CentOS Shutdown -Befehlszeile
Apr 14, 2025 pm 09:12 PM
Der Befehl centOS stilldown wird heruntergefahren und die Syntax wird von [Optionen] ausgeführt [Informationen]. Zu den Optionen gehören: -h das System sofort stoppen; -P schalten Sie die Leistung nach dem Herunterfahren aus; -r neu starten; -t Wartezeit. Zeiten können als unmittelbar (jetzt), Minuten (Minuten) oder als bestimmte Zeit (HH: MM) angegeben werden. Hinzugefügten Informationen können in Systemmeldungen angezeigt werden.
 Was sind die Backup -Methoden für Gitlab auf CentOS?
Apr 14, 2025 pm 05:33 PM
Was sind die Backup -Methoden für Gitlab auf CentOS?
Apr 14, 2025 pm 05:33 PM
Backup- und Wiederherstellungsrichtlinie von GitLab im Rahmen von CentOS -System Um die Datensicherheit und Wiederherstellung der Daten zu gewährleisten, bietet GitLab on CentOS eine Vielzahl von Sicherungsmethoden. In diesem Artikel werden mehrere gängige Sicherungsmethoden, Konfigurationsparameter und Wiederherstellungsprozesse im Detail eingeführt, um eine vollständige GitLab -Sicherungs- und Wiederherstellungsstrategie aufzubauen. 1. Manuell Backup Verwenden Sie den GitLab-RakegitLab: Backup: Befehl erstellen, um die manuelle Sicherung auszuführen. Dieser Befehl unterstützt wichtige Informationen wie GitLab Repository, Datenbank, Benutzer, Benutzergruppen, Schlüssel und Berechtigungen. Die Standardsicherungsdatei wird im Verzeichnis/var/opt/gitlab/backups gespeichert. Sie können /etc /gitlab ändern
 So überprüfen Sie die CentOS -HDFS -Konfiguration
Apr 14, 2025 pm 07:21 PM
So überprüfen Sie die CentOS -HDFS -Konfiguration
Apr 14, 2025 pm 07:21 PM
Vollständige Anleitung zur Überprüfung der HDFS -Konfiguration in CentOS -Systemen In diesem Artikel wird die Konfiguration und den laufenden Status von HDFS auf CentOS -Systemen effektiv überprüft. Die folgenden Schritte helfen Ihnen dabei, das Setup und den Betrieb von HDFs vollständig zu verstehen. Überprüfen Sie die Hadoop -Umgebungsvariable: Stellen Sie zunächst sicher, dass die Hadoop -Umgebungsvariable korrekt eingestellt ist. Führen Sie im Terminal den folgenden Befehl aus, um zu überprüfen, ob Hadoop ordnungsgemäß installiert und konfiguriert ist: Hadoopsion-Check HDFS-Konfigurationsdatei: Die Kernkonfigurationsdatei von HDFS befindet sich im/etc/hadoop/conf/verzeichnis, wobei core-site.xml und hdfs-site.xml von entscheidender Bedeutung sind. verwenden
 Was sind die Methoden zur Abstimmung der Leistung von Zookeeper auf CentOS
Apr 14, 2025 pm 03:18 PM
Was sind die Methoden zur Abstimmung der Leistung von Zookeeper auf CentOS
Apr 14, 2025 pm 03:18 PM
Die Zookeper -Leistungsstimmung auf CentOS kann von mehreren Aspekten beginnen, einschließlich Hardwarekonfiguration, Betriebssystemoptimierung, Konfigurationsparameteranpassung, Überwachung und Wartung usw. Hier finden Sie einige spezifische Tuning -Methoden: SSD wird für die Hardwarekonfiguration: Da die Daten von Zookeeper an Disk geschrieben werden, wird empfohlen, SSD zu verbessern, um die I/O -Leistung zu verbessern. Genug Memory: Zookeeper genügend Speicherressourcen zuweisen, um häufige Lesen und Schreiben von häufigen Festplatten zu vermeiden. Multi-Core-CPU: Verwenden Sie Multi-Core-CPU, um sicherzustellen, dass Zookeeper es parallel verarbeiten kann.
 Wie ist die GPU -Unterstützung für Pytorch bei CentOS?
Apr 14, 2025 pm 06:48 PM
Wie ist die GPU -Unterstützung für Pytorch bei CentOS?
Apr 14, 2025 pm 06:48 PM
Aktivieren Sie die Pytorch -GPU -Beschleunigung am CentOS -System erfordert die Installation von CUDA-, CUDNN- und GPU -Versionen von Pytorch. Die folgenden Schritte führen Sie durch den Prozess: Cuda und Cudnn Installation Bestimmen Sie die CUDA-Version Kompatibilität: Verwenden Sie den Befehl nvidia-smi, um die von Ihrer NVIDIA-Grafikkarte unterstützte CUDA-Version anzuzeigen. Beispielsweise kann Ihre MX450 -Grafikkarte CUDA11.1 oder höher unterstützen. Download und installieren Sie Cudatoolkit: Besuchen Sie die offizielle Website von Nvidiacudatoolkit und laden Sie die entsprechende Version gemäß der höchsten CUDA -Version herunter und installieren Sie sie, die von Ihrer Grafikkarte unterstützt wird. Installieren Sie die Cudnn -Bibliothek:
 Detaillierte Erklärung des Docker -Prinzips
Apr 14, 2025 pm 11:57 PM
Detaillierte Erklärung des Docker -Prinzips
Apr 14, 2025 pm 11:57 PM
Docker verwendet Linux -Kernel -Funktionen, um eine effiziente und isolierte Anwendungsumgebung zu bieten. Sein Arbeitsprinzip lautet wie folgt: 1. Der Spiegel wird als schreibgeschützte Vorlage verwendet, die alles enthält, was Sie für die Ausführung der Anwendung benötigen. 2. Das Union File System (UnionFS) stapelt mehrere Dateisysteme, speichert nur die Unterschiede, speichert Platz und beschleunigt. 3. Der Daemon verwaltet die Spiegel und Container, und der Kunde verwendet sie für die Interaktion. 4. Namespaces und CGroups implementieren Container -Isolation und Ressourcenbeschränkungen; 5. Mehrere Netzwerkmodi unterstützen die Containerverbindung. Nur wenn Sie diese Kernkonzepte verstehen, können Sie Docker besser nutzen.
 CentOS installieren MySQL
Apr 14, 2025 pm 08:09 PM
CentOS installieren MySQL
Apr 14, 2025 pm 08:09 PM
Die Installation von MySQL auf CentOS umfasst die folgenden Schritte: Hinzufügen der entsprechenden MySQL Yum -Quelle. Führen Sie den Befehl mySQL-server aus, um den MySQL-Server zu installieren. Verwenden Sie den Befehl mySQL_SECURE_INSTALLATION, um Sicherheitseinstellungen vorzunehmen, z. B. das Festlegen des Stammbenutzerkennworts. Passen Sie die MySQL -Konfigurationsdatei nach Bedarf an. Tune MySQL -Parameter und optimieren Sie Datenbanken für die Leistung.
 CentOS8 startet SSH
Apr 14, 2025 pm 09:00 PM
CentOS8 startet SSH
Apr 14, 2025 pm 09:00 PM
Der Befehl zum Neustart des SSH -Dienstes lautet: SystemCTL Neustart SSHD. Detaillierte Schritte: 1. Zugriff auf das Terminal und eine Verbindung zum Server; 2. Geben Sie den Befehl ein: SystemCTL Neustart SSHD; 1. Überprüfen Sie den Dienststatus: SystemCTL -Status SSHD.
