

GPT-4V zur Zielerkennung? Aktueller Test durch Internetnutzer: Noch nicht fertig.
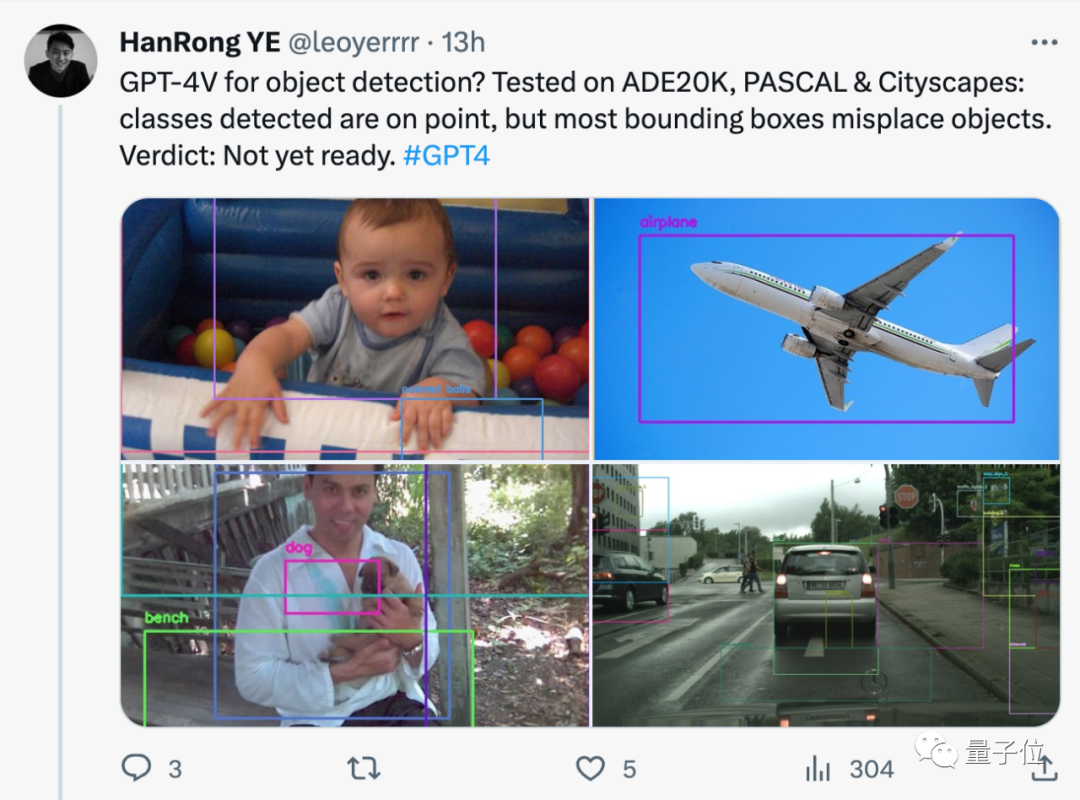
Während die erkannten Kategorien in Ordnung sind, sind die meisten Begrenzungsrahmen falsch platziert.
Es spielt keine Rolle, jemand wird Maßnahmen ergreifen!
Der Mini GPT-4, der GPT-4 in der Bildbetrachtungsfähigkeit um mehrere Monate übertrifft, wurde aktualisiert – MiniGPT-v2.
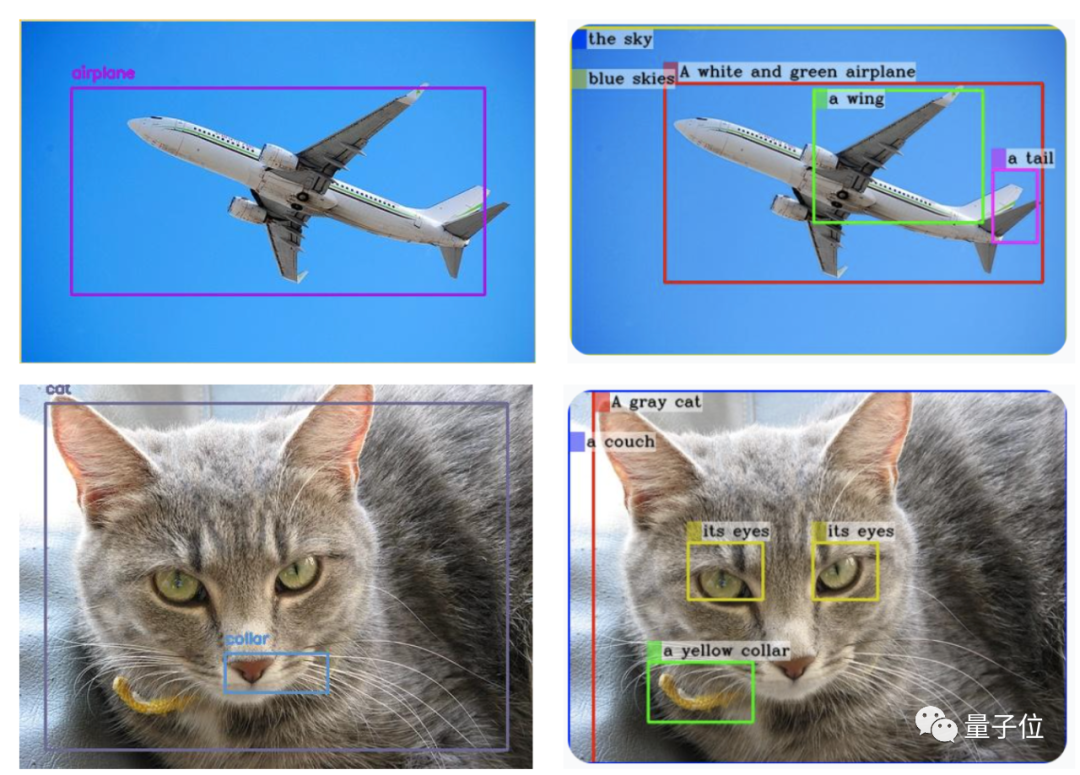
△ (GPT-4V wird links generiert und MiniGPT-v2 wird rechts generiert)
Und es ist nur ein einfacher Befehl: [Erdung] beschreiben Sie dieses Bild im Detail, um das Ergebnis zu erzielen.
Darüber hinaus kann es auch verschiedene visuelle Aufgaben problemlos bewältigen.
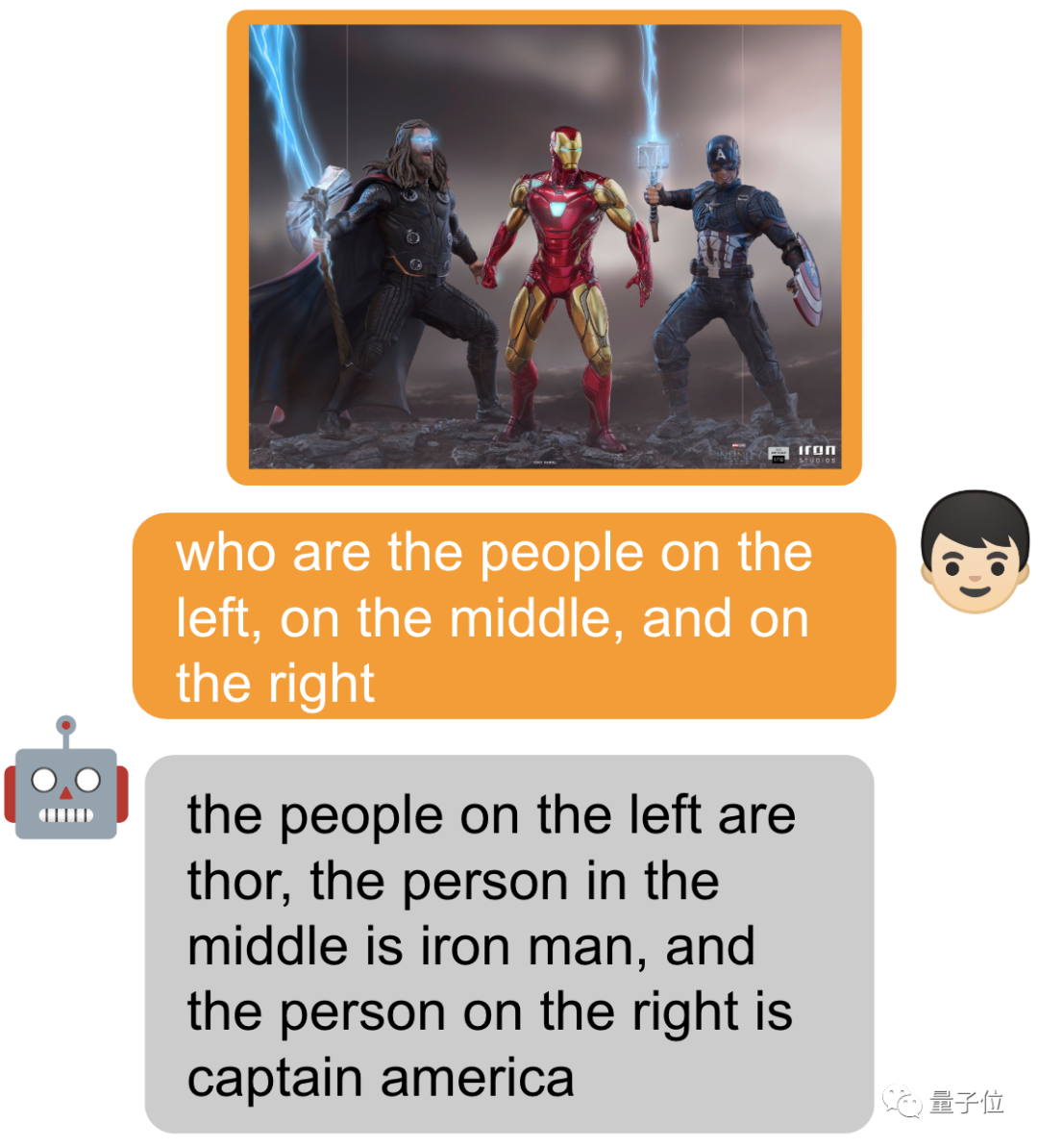
Kreisen Sie ein Objekt ein und fügen Sie [identifizieren] vor dem Eingabeaufforderungswort hinzu, damit das Modell den Namen des Objekts direkt identifizieren kann.

Natürlich können Sie auch nichts hinzufügen und einfach fragen~
MiniGPT-v2 besteht aus dem ursprünglichen Team von MiniGPT-4 (KAUST King Abdullah University of Science and Technology in Saudi-Arabien) und fünf Forscher von Meta gemeinsame Entwicklung.

Das letzte Mal erregte MiniGPT-4 große Aufmerksamkeit, als es herauskam, und der Server war eine Zeit lang überlastet. Jetzt hat das GitHub-Projekt mehr als 22.000 Sterne erreicht.
Mit diesem Upgrade haben einige Internetnutzer bereits damit begonnen, es zu verwenden~
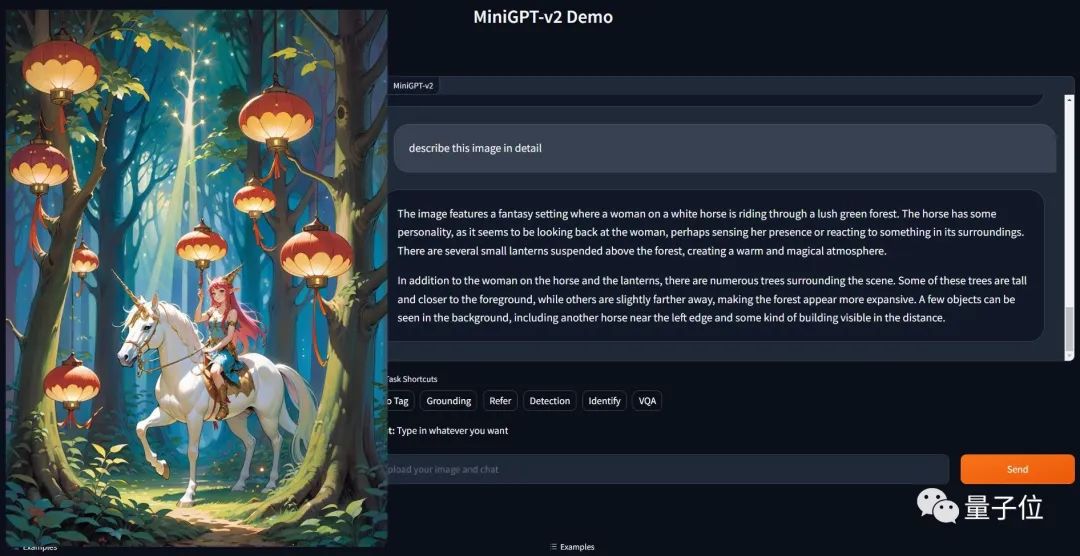
Als universelle Schnittstelle für verschiedene Textanwendungen hat sich jeder daran gewöhnt. Davon inspiriert möchte das Forschungsteam eine einheitliche Schnittstelle erstellen, die für eine Vielzahl visueller Aufgaben wie Bildbeschreibung, visuelle Beantwortung von Fragen usw. verwendet werden kann.

„Wie kann man mit einfachen multimodalen Anweisungen verschiedene Aufgaben unter der Bedingung eines einzigen Modells effizient erledigen?“ ist zu einem Problem geworden, das das Team lösen muss.
Um es einfach auszudrücken: MiniGPT-v2 besteht aus drei Teilen: visuellem Rückgrat, linearer Ebene und großem Sprachmodell.
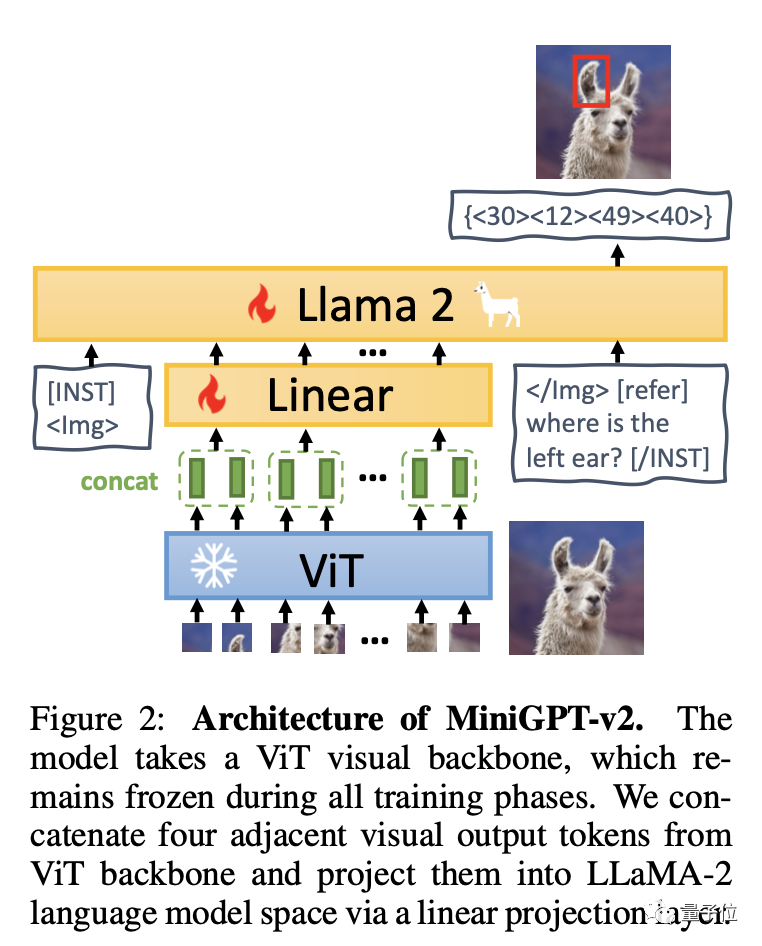
Das Modell basiert auf dem visuellen Rückgrat von ViT und bleibt in allen Trainingsphasen unverändert. Vier benachbarte visuelle Ausgabetoken werden von ViT induziert und über lineare Schichten in den LLaMA-2-Sprachmodellraum projiziert.
Das Team empfiehlt die Verwendung eindeutiger Kennungen für verschiedene Aufgaben im Trainingsmodell, damit große Modelle jede Aufgabenanweisung leicht unterscheiden und die Lerneffizienz jeder Aufgabe verbessern können.
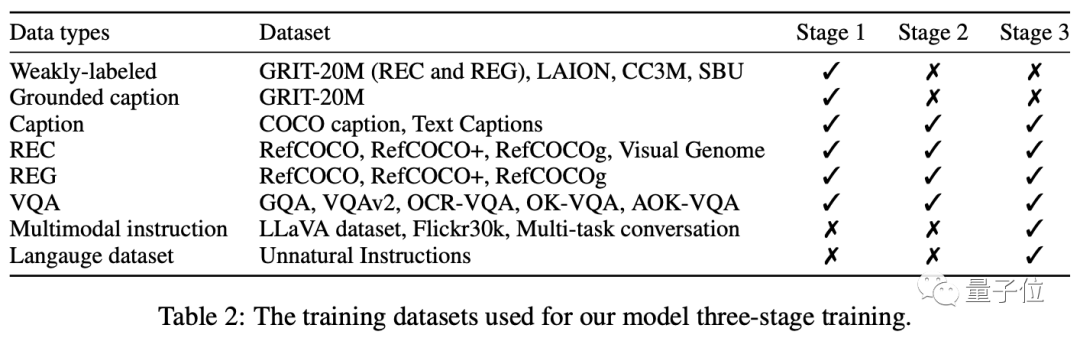
Das Training ist hauptsächlich in drei Phasen unterteilt: Vortraining – Multitasking-Training – Anpassung der Multi-Mode-Anweisungen.
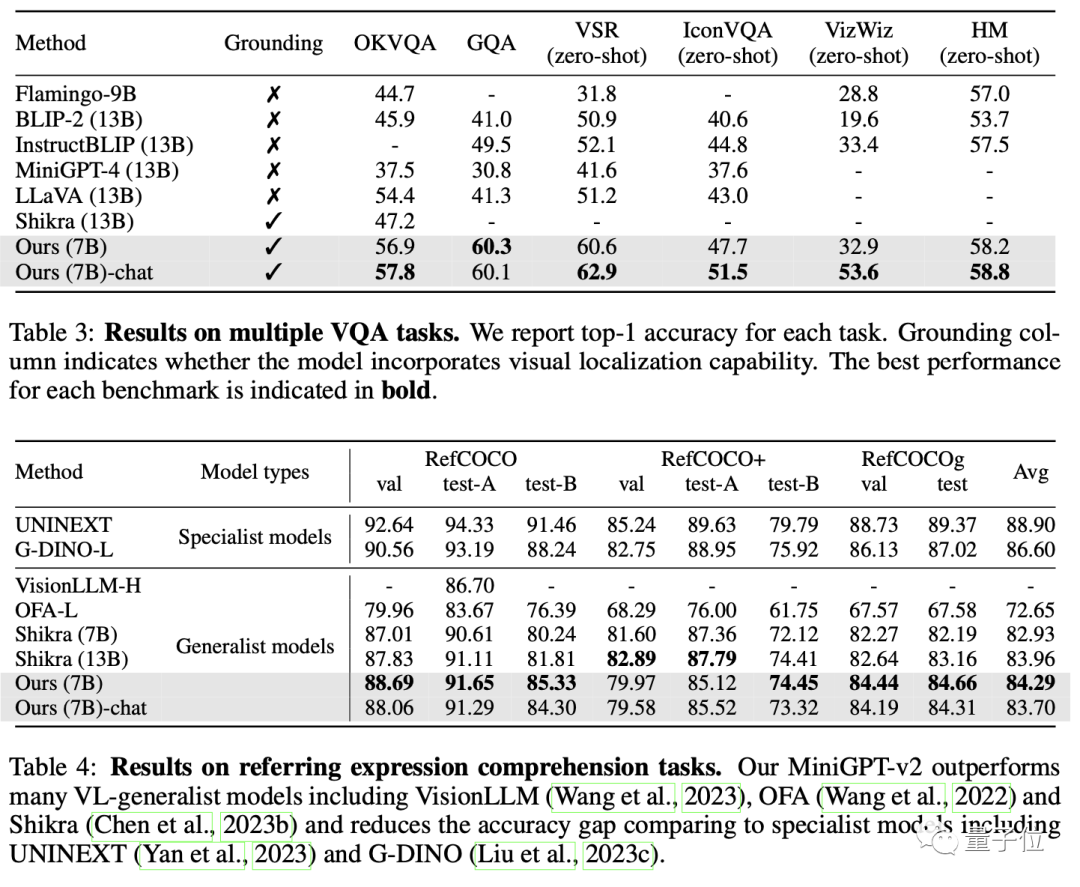
Am Ende übertraf MiniGPT-v2 andere allgemeine Modelle der visuellen Sprache in vielen Benchmarks zur Beantwortung visueller Fragen und zur visuellen Erdung.
Letztendlich kann dieses Modell eine Vielzahl visueller Aufgaben erledigen, wie z. B. Zielobjektbeschreibung, visuelle Lokalisierung, Bildbeschreibung, visuelle Beantwortung von Fragen und direktes Parsen von Bildobjekten aus gegebenem Eingabetext.

Interessierte Freunde können auf den Demo-Link unten klicken, um es zu erleben:
https://minigpt-v2.github.io/
https://huggingface.co/spaces/Vision-CAIR/ MiniGPT -v2
Papierlink: https://arxiv.org/abs/2310.09478
GitHub-Link: https://github.com/Vision-CAIR/MiniGPT-4
Das obige ist der detaillierte Inhalt vonDie visuellen Fähigkeiten des überaus beliebten Mini-GPT-4 sind sprunghaft angestiegen, mit 20.000 Sternen auf GitHub, produziert von einem chinesischen Team. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Windows prüft den Portbelegungsstatus
Windows prüft den Portbelegungsstatus
 So laden Sie den Razer-Maustreiber herunter
So laden Sie den Razer-Maustreiber herunter
 Tutorial zum Übertragen von Windows 11 von meinem Computer auf den Desktop
Tutorial zum Übertragen von Windows 11 von meinem Computer auf den Desktop
 Der Unterschied zwischen fprintf und printf
Der Unterschied zwischen fprintf und printf
 Was ist Vulkan?
Was ist Vulkan?
 Prioritätsreihenfolge der Operatoren in der Sprache C
Prioritätsreihenfolge der Operatoren in der Sprache C
 So betten Sie CSS-Stile in HTML ein
So betten Sie CSS-Stile in HTML ein
 Warum kann das Video in ppt nicht abgespielt werden?
Warum kann das Video in ppt nicht abgespielt werden?
 Latexverwendung
Latexverwendung








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



