
 Technologie-Peripheriegeräte
KI
Spannend! Eine vorläufige Studie zu GPT-4V beim autonomen Fahren
Technologie-Peripheriegeräte
KI
Spannend! Eine vorläufige Studie zu GPT-4V beim autonomen Fahren
Spannend! Eine vorläufige Studie zu GPT-4V beim autonomen Fahren

Update: Ein neues Beispiel hinzugefügt, ein selbstfahrendes Lieferfahrzeug, das in den Zementboden von Xinpu fährt
Unter großer Aufmerksamkeit hat GPT4 heute endlich visionäre Funktionen eingeführt. Heute Nachmittag habe ich mit meinen Freunden schnell die Bildwahrnehmungsfähigkeiten von GPT getestet. Obwohl wir Erwartungen hatten, waren wir dennoch sehr schockiert. TL;DR ist Ich denke, die semantischen Probleme beim autonomen Fahren hätten von großen Modellen sehr gut gelöst werden sollen, aber die Glaubwürdigkeit und räumlichen Wahrnehmungsfähigkeiten großer Modelle sind immer noch nicht zufriedenstellend. Es sollte mehr als ausreichen, um einige sogenannte effizienzbezogene Eckfälle zu lösen, aber es ist noch weit entfernt, sich vollständig auf große Modelle zu verlassen, um das Fahren selbstständig abzuschließen und die Sicherheit zu gewährleisten.
1 Beispiel 1: Einige unbekannte Hindernisse tauchten auf der Straße auf wenn chinesische Schriftzeichen vorhanden sind) (Balken), das Wetter und die Umgebung korrekt sind, Ungenaue unbekannte Hindernisse vor Ihnen ohne Aufforderung erkannt
 Ungenaue Teile: Die Position des dritten LKW ist von links nach rechts nicht zu unterscheiden und der Text über dem Kopf des zweiten LKW ist eine Vermutung. Eins (wegen unzureichender Auflösung?)
Ungenaue Teile: Die Position des dritten LKW ist von links nach rechts nicht zu unterscheiden und der Text über dem Kopf des zweiten LKW ist eine Vermutung. Eins (wegen unzureichender Auflösung?)
Das reicht nicht, wir geben weiterhin einen kleinen Hinweis, um zu fragen, was dieses Objekt ist und ob es überdrückt werden kann. 
Beeindruckend! Wir haben mehrere ähnliche Szenarien getestet und die Leistung bei unbekannten Hindernissen kann als sehr erstaunlich bezeichnet werden.
2 Beispiel 2: Verständnis der Ansammlung von Straßenwasser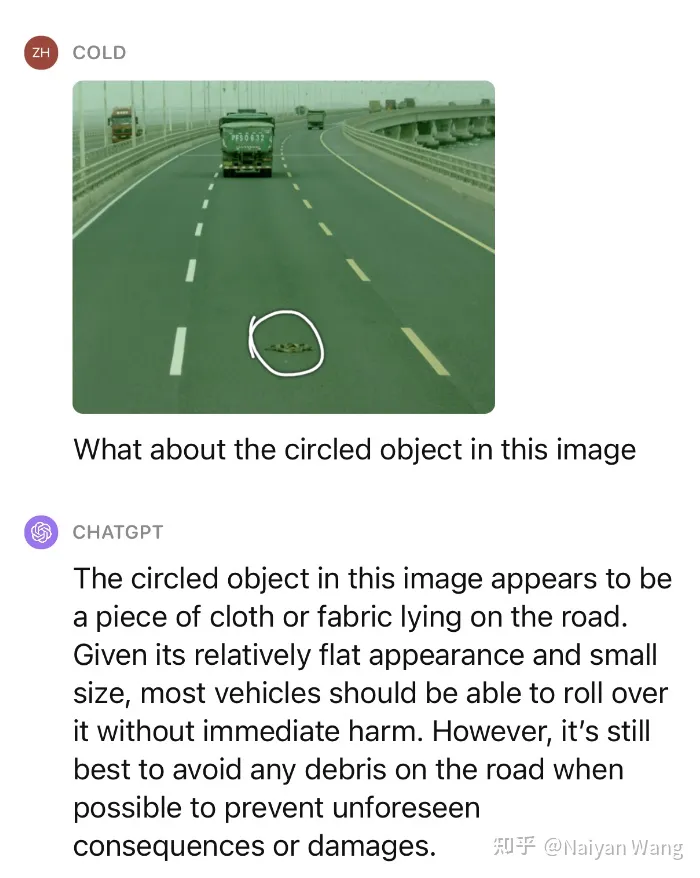
Es gibt keine Aufforderung, das Schild automatisch zu erkennen, wir geben weiterhin einige Hinweise
Ich war wieder schockiert. . . Er erkannte automatisch den Nebel hinter dem LKW und erwähnte auch die Pfütze, sagte aber noch einmal, die Richtung sei nach links. . . Ich bin der Meinung, dass hier eine schnelle technische Umsetzung erforderlich sein könnte, damit GPT die Position und Richtung besser ausgeben kann.
3 Hier also ein weiterer Rahmen: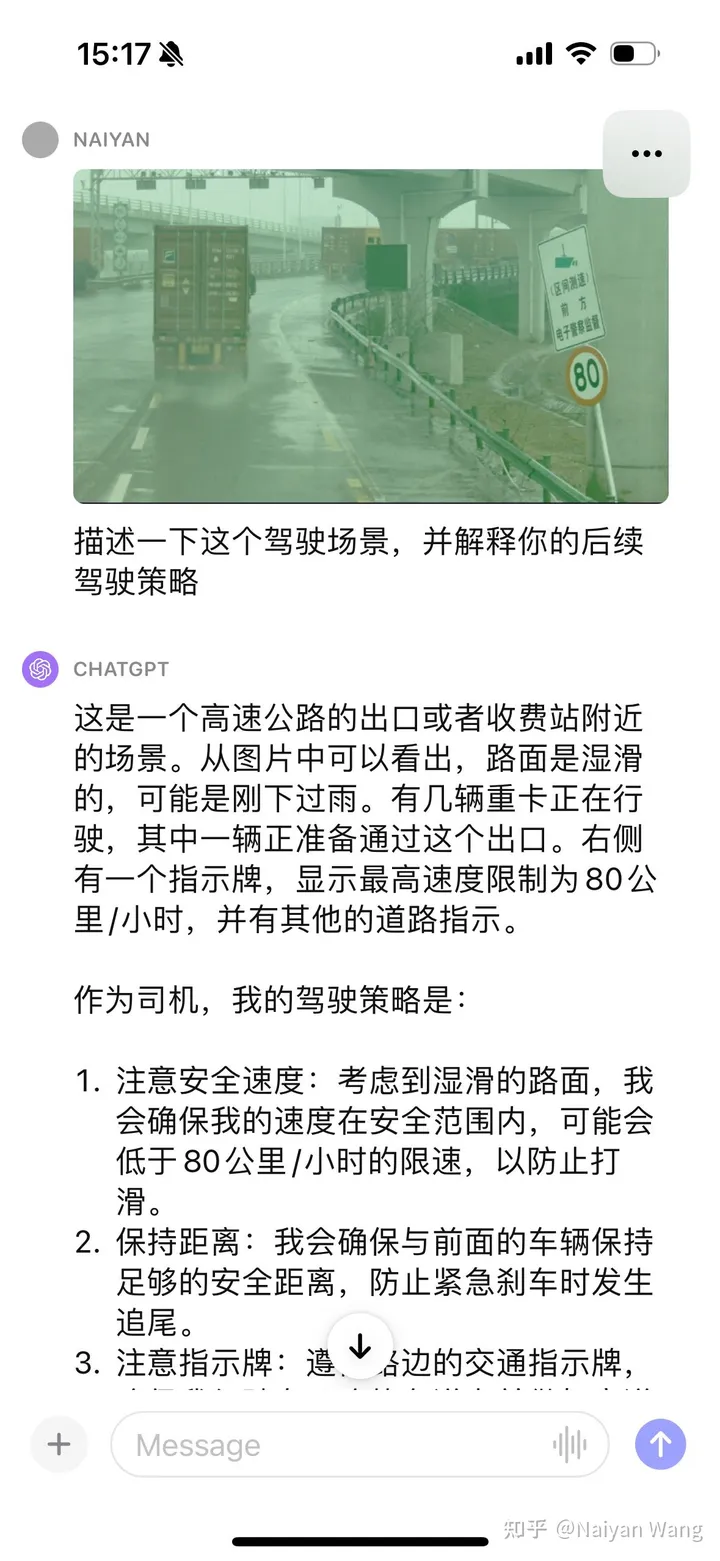

5 Beispiel5 Lass uns eine berühmte Szene haben. . . Der Lieferwagen fuhr versehentlich auf die neu gebaute Straße



Ich war zunächst relativ konservativ und habe den Grund nicht direkt erraten. Dies entspricht dem Ziel der Ausrichtung. Nach der Verwendung von CoT wurde festgestellt, dass das Problem darin bestand, dass es sich bei dem Auto nicht um ein selbstfahrendes Fahrzeug handelte, so dass die rechtzeitige Angabe dieser Informationen genauere Informationen liefern kann. Schließlich kann durch eine Reihe von Eingabeaufforderungen der Schluss gezogen werden, dass der neu verlegte Asphalt nicht zum Befahren geeignet ist. Das Endergebnis ist immer noch in Ordnung, aber der Prozess ist umständlicher und erfordert eine schnellere Konstruktion und sorgfältiges Design. Dieser Grund könnte auch darin liegen, dass es sich nicht um ein Bild aus der Ich-Perspektive handelt und nur aus der Perspektive der Dritten Person spekuliert werden kann. Dieses Beispiel ist also nicht sehr präzise.
6 Zusammenfassung
Einige schnelle Versuche haben die Leistungsfähigkeit und Generalisierungsleistung von GPT4V vollständig bewiesen. Bei entsprechenden Eingabeaufforderungen sollte die Stärke von GPT4V voll ausgenutzt werden können. Die Lösung des semantischen Eckfalls sollte sehr vielversprechend sein, aber das Problem der Illusion wird einige Anwendungen in sicherheitsrelevanten Szenarien immer noch plagen. Ich persönlich finde es sehr spannend, dass der rationelle Einsatz solch großer Modelle die Entwicklung des autonomen L4- und sogar L5-Fahrens erheblich beschleunigen kann. Insbesondere das durchgehende Fahren bleibt ein umstrittenes Thema. Ich habe in letzter Zeit viel nachgedacht, deshalb werde ich Zeit finden, einen Artikel zu schreiben, um mit euch allen zu plaudern~

Originallink: https://mp.weixin.qq.com/s/RtEek6HadErxXLSdtsMWHQ
Das obige ist der detaillierte Inhalt vonSpannend! Eine vorläufige Studie zu GPT-4V beim autonomen Fahren. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 Warum ist Gaussian Splatting beim autonomen Fahren so beliebt, dass NeRF allmählich aufgegeben wird?
Jan 17, 2024 pm 02:57 PM
Warum ist Gaussian Splatting beim autonomen Fahren so beliebt, dass NeRF allmählich aufgegeben wird?
Jan 17, 2024 pm 02:57 PM
Oben geschrieben und persönliches Verständnis des Autors. Dreidimensionales Gaussplatting (3DGS) ist eine transformative Technologie, die in den letzten Jahren in den Bereichen explizite Strahlungsfelder und Computergrafik entstanden ist. Diese innovative Methode zeichnet sich durch die Verwendung von Millionen von 3D-Gaußkurven aus, was sich stark von der Neural Radiation Field (NeRF)-Methode unterscheidet, die hauptsächlich ein implizites koordinatenbasiertes Modell verwendet, um räumliche Koordinaten auf Pixelwerte abzubilden. Mit seiner expliziten Szenendarstellung und differenzierbaren Rendering-Algorithmen garantiert 3DGS nicht nur Echtzeit-Rendering-Fähigkeiten, sondern führt auch ein beispielloses Maß an Kontrolle und Szenenbearbeitung ein. Dies positioniert 3DGS als potenziellen Game-Changer für die 3D-Rekonstruktion und -Darstellung der nächsten Generation. Zu diesem Zweck geben wir erstmals einen systematischen Überblick über die neuesten Entwicklungen und Anliegen im Bereich 3DGS.
 Wie lässt sich das Long-Tail-Problem in autonomen Fahrszenarien lösen?
Jun 02, 2024 pm 02:44 PM
Wie lässt sich das Long-Tail-Problem in autonomen Fahrszenarien lösen?
Jun 02, 2024 pm 02:44 PM
Gestern wurde ich während des Interviews gefragt, ob ich irgendwelche Long-Tail-Fragen gestellt hätte, also dachte ich, ich würde eine kurze Zusammenfassung geben. Das Long-Tail-Problem des autonomen Fahrens bezieht sich auf Randfälle bei autonomen Fahrzeugen, also mögliche Szenarien mit geringer Eintrittswahrscheinlichkeit. Das wahrgenommene Long-Tail-Problem ist einer der Hauptgründe, die derzeit den betrieblichen Designbereich intelligenter autonomer Einzelfahrzeugfahrzeuge einschränken. Die zugrunde liegende Architektur und die meisten technischen Probleme des autonomen Fahrens wurden gelöst, und die verbleibenden 5 % der Long-Tail-Probleme wurden nach und nach zum Schlüssel zur Einschränkung der Entwicklung des autonomen Fahrens. Zu diesen Problemen gehören eine Vielzahl fragmentierter Szenarien, Extremsituationen und unvorhersehbares menschliches Verhalten. Der „Long Tail“ von Randszenarien beim autonomen Fahren bezieht sich auf Randfälle in autonomen Fahrzeugen (AVs). Randfälle sind mögliche Szenarien mit geringer Eintrittswahrscheinlichkeit. diese seltenen Ereignisse
 Kamera oder Lidar wählen? Eine aktuelle Übersicht über die Erzielung einer robusten 3D-Objekterkennung
Jan 26, 2024 am 11:18 AM
Kamera oder Lidar wählen? Eine aktuelle Übersicht über die Erzielung einer robusten 3D-Objekterkennung
Jan 26, 2024 am 11:18 AM
0. Vorab geschrieben&& Persönliches Verständnis, dass autonome Fahrsysteme auf fortschrittlichen Wahrnehmungs-, Entscheidungs- und Steuerungstechnologien beruhen, indem sie verschiedene Sensoren (wie Kameras, Lidar, Radar usw.) verwenden, um die Umgebung wahrzunehmen, und Algorithmen und Modelle verwenden für Echtzeitanalysen und Entscheidungsfindung. Dies ermöglicht es Fahrzeugen, Verkehrszeichen zu erkennen, andere Fahrzeuge zu erkennen und zu verfolgen, das Verhalten von Fußgängern vorherzusagen usw. und sich so sicher an komplexe Verkehrsumgebungen anzupassen. Diese Technologie erregt derzeit große Aufmerksamkeit und gilt als wichtiger Entwicklungsbereich für die Zukunft des Transportwesens . eins. Aber was autonomes Fahren schwierig macht, ist herauszufinden, wie man dem Auto klarmachen kann, was um es herum passiert. Dies erfordert, dass der dreidimensionale Objekterkennungsalgorithmus im autonomen Fahrsystem Objekte in der Umgebung, einschließlich ihrer Standorte, genau wahrnehmen und beschreiben kann.
 Das Stable Diffusion 3-Papier wird endlich veröffentlicht und die architektonischen Details werden enthüllt. Wird es helfen, Sora zu reproduzieren?
Mar 06, 2024 pm 05:34 PM
Das Stable Diffusion 3-Papier wird endlich veröffentlicht und die architektonischen Details werden enthüllt. Wird es helfen, Sora zu reproduzieren?
Mar 06, 2024 pm 05:34 PM
Der Artikel von StableDiffusion3 ist endlich da! Dieses Modell wurde vor zwei Wochen veröffentlicht und verwendet die gleiche DiT-Architektur (DiffusionTransformer) wie Sora. Nach seiner Veröffentlichung sorgte es für großes Aufsehen. Im Vergleich zur Vorgängerversion wurde die Qualität der von StableDiffusion3 generierten Bilder erheblich verbessert. Es unterstützt jetzt Eingabeaufforderungen mit mehreren Themen, und der Textschreibeffekt wurde ebenfalls verbessert, und es werden keine verstümmelten Zeichen mehr angezeigt. StabilityAI wies darauf hin, dass es sich bei StableDiffusion3 um eine Reihe von Modellen mit Parametergrößen von 800 M bis 8 B handelt. Durch diesen Parameterbereich kann das Modell direkt auf vielen tragbaren Geräten ausgeführt werden, wodurch der Einsatz von KI deutlich reduziert wird
 Dieser Artikel reicht aus, um etwas über autonomes Fahren und Flugbahnvorhersage zu lesen!
Feb 28, 2024 pm 07:20 PM
Dieser Artikel reicht aus, um etwas über autonomes Fahren und Flugbahnvorhersage zu lesen!
Feb 28, 2024 pm 07:20 PM
Die Trajektorienvorhersage spielt eine wichtige Rolle beim autonomen Fahren. Unter autonomer Fahrtrajektorienvorhersage versteht man die Vorhersage der zukünftigen Fahrtrajektorie des Fahrzeugs durch die Analyse verschiedener Daten während des Fahrvorgangs. Als Kernmodul des autonomen Fahrens ist die Qualität der Trajektorienvorhersage von entscheidender Bedeutung für die nachgelagerte Planungssteuerung. Die Trajektorienvorhersageaufgabe verfügt über einen umfangreichen Technologie-Stack und erfordert Vertrautheit mit der dynamischen/statischen Wahrnehmung des autonomen Fahrens, hochpräzisen Karten, Fahrspurlinien, Fähigkeiten in der neuronalen Netzwerkarchitektur (CNN&GNN&Transformer) usw. Der Einstieg ist sehr schwierig! Viele Fans hoffen, so schnell wie möglich mit der Flugbahnvorhersage beginnen zu können und Fallstricke zu vermeiden. Heute werde ich eine Bestandsaufnahme einiger häufiger Probleme und einführender Lernmethoden für die Flugbahnvorhersage machen! Einführungsbezogenes Wissen 1. Sind die Vorschaupapiere in Ordnung? A: Schauen Sie sich zuerst die Umfrage an, S
 Sprechen wir über End-to-End- und autonome Fahrsysteme der nächsten Generation sowie über einige Missverständnisse über End-to-End-Autonomes Fahren?
Apr 15, 2024 pm 04:13 PM
Sprechen wir über End-to-End- und autonome Fahrsysteme der nächsten Generation sowie über einige Missverständnisse über End-to-End-Autonomes Fahren?
Apr 15, 2024 pm 04:13 PM
Im vergangenen Monat hatte ich aus bekannten Gründen einen sehr intensiven Austausch mit verschiedenen Lehrern und Mitschülern der Branche. Ein unvermeidliches Thema im Austausch ist natürlich End-to-End und der beliebte Tesla FSDV12. Ich möchte diese Gelegenheit nutzen, einige meiner aktuellen Gedanken und Meinungen als Referenz und Diskussion darzulegen. Wie definiert man ein durchgängiges autonomes Fahrsystem und welche Probleme sollten voraussichtlich durchgängig gelöst werden? Gemäß der traditionellsten Definition bezieht sich ein End-to-End-System auf ein System, das Rohinformationen von Sensoren eingibt und für die Aufgabe relevante Variablen direkt ausgibt. Bei der Bilderkennung kann CNN beispielsweise als End-to-End bezeichnet werden, verglichen mit der herkömmlichen Methode zum Extrahieren von Merkmalen + Klassifizieren. Bei autonomen Fahraufgaben werden Eingabedaten verschiedener Sensoren (Kamera/LiDAR) benötigt
 SIMPL: Ein einfacher und effizienter Multi-Agent-Benchmark zur Bewegungsvorhersage für autonomes Fahren
Feb 20, 2024 am 11:48 AM
SIMPL: Ein einfacher und effizienter Multi-Agent-Benchmark zur Bewegungsvorhersage für autonomes Fahren
Feb 20, 2024 am 11:48 AM
Originaltitel: SIMPL: ASimpleandEfficientMulti-agentMotionPredictionBaselineforAutonomousDriving Paper-Link: https://arxiv.org/pdf/2402.02519.pdf Code-Link: https://github.com/HKUST-Aerial-Robotics/SIMPL Autor: Hong Kong University of Science und Technologie DJI-Papieridee: Dieses Papier schlägt eine einfache und effiziente Bewegungsvorhersagebasislinie (SIMPL) für autonome Fahrzeuge vor. Im Vergleich zum herkömmlichen Agent-Cent
 FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
Die Zielerkennung ist ein relativ ausgereiftes Problem in autonomen Fahrsystemen, wobei die Fußgängererkennung einer der ersten Algorithmen ist, die eingesetzt werden. In den meisten Arbeiten wurde eine sehr umfassende Recherche durchgeführt. Die Entfernungswahrnehmung mithilfe von Fischaugenkameras für die Rundumsicht ist jedoch relativ wenig untersucht. Aufgrund der großen radialen Verzerrung ist es schwierig, die standardmäßige Bounding-Box-Darstellung in Fischaugenkameras zu implementieren. Um die obige Beschreibung zu vereinfachen, untersuchen wir erweiterte Begrenzungsrahmen-, Ellipsen- und allgemeine Polygondesigns in Polar-/Winkeldarstellungen und definieren eine mIOU-Metrik für die Instanzsegmentierung, um diese Darstellungen zu analysieren. Das vorgeschlagene Modell „fisheyeDetNet“ mit polygonaler Form übertrifft andere Modelle und erreicht gleichzeitig 49,5 % mAP auf dem Valeo-Fisheye-Kameradatensatz für autonomes Fahren
