
 Technologie-Peripheriegeräte
KI
1 Token beendet das LLM-Digitalcodierungsproblem! Neun große Institutionen haben gemeinsam xVal veröffentlicht: Auch Zahlen, die nicht im Trainingssatz enthalten sind, können vorhergesagt werden!
Technologie-Peripheriegeräte
KI
1 Token beendet das LLM-Digitalcodierungsproblem! Neun große Institutionen haben gemeinsam xVal veröffentlicht: Auch Zahlen, die nicht im Trainingssatz enthalten sind, können vorhergesagt werden!
1 Token beendet das LLM-Digitalcodierungsproblem! Neun große Institutionen haben gemeinsam xVal veröffentlicht: Auch Zahlen, die nicht im Trainingssatz enthalten sind, können vorhergesagt werden!

Obwohl die Leistung großer Sprachmodelle (LLM) bei Textanalyse- und Generierungsaufgaben sehr leistungsstark ist, liegt es an einem einheitlichen und vollständigen Mechanismus zur Segmentierung von Zahlenwörtern, wenn es um Zahlenprobleme wie die Multiplikation mit mehreren Ziffern geht Das Modell wird Probleme haben. Infolgedessen kann LLM die Semantik von Zahlen nicht verstehen und zufällige Antworten erstellen.
Eines der Hindernisse dafür, dass LLM in der Datenanalyse im wissenschaftlichen Bereich derzeit nicht weit verbreitet ist, ist das Problem der digitalen Kodierung.
Vor Kurzem haben neun Forschungseinrichtungen, darunter das Flatiron Institute, das Lawrence Berkeley National Laboratory, die University of Cambridge, die New York University und die Princeton University, gemeinsam ein neues digitales Kodierungsschema xVal veröffentlicht, das nur einen Token zum Kodieren aller Zahlen erfordert.

Link zum Papier: https://arxiv.org/pdf/2310.02989.pdf
xVal repräsentiert den wahren Zielwert durch numerische Skalierung des Einbettungsvektors des dedizierten Tokens ([NUM]) und In Kombination mit der modifizierten numerischen Argumentationsmethode sorgt die xVal-Strategie dafür, dass das Modell bei der Zuordnung zwischen Eingabezeichenfolgennummern und Ausgabenummern erfolgreich durchgängig kontinuierlich ist, wodurch es besser für Anwendungen im wissenschaftlichen Bereich geeignet ist.
Bewertungsergebnisse zu synthetischen und realen Datensätzen zeigen, dass xVal nicht nur eine bessere Leistung erbringt und mehr Token einspart als bestehende numerische Codierungsschemata, sondern auch bessere Interpolationsverallgemeinerungseigenschaften aufweist.
Neuer Durchbruch in der digitalen Kodierung
Das standardmäßige LLM-Wortsegmentierungsschema unterscheidet nicht zwischen Zahlen und Text, daher ist es unmöglich, Werte zu quantifizieren.
Es gab bereits frühere Arbeiten, um alle Zahlen in Form einer wissenschaftlichen Notation auf einen begrenzten Satz von Prototypzahlen (Prototypzahlen) abzubilden, wobei 10 als Basis verwendet wurde, oder um den Kosinusabstand zwischen Zahleneinbettungen zu berechnen, um die Zahl widerzuspiegeln Numerische Differenzen wurden erfolgreich zur Lösung linearer Algebraprobleme wie der Matrixmultiplikation eingesetzt.
Bei kontinuierlichen oder glatten Problemen im wissenschaftlichen Bereich können Sprachmodelle jedoch Interpolations- und Out-of-Distribution-Generalisierungsprobleme immer noch nicht gut bewältigen, da LLM nach der Codierung von Zahlen in Text immer noch diskreter Natur bei der Codierung und Decodierung ist Stufen ist es schwierig, ungefähre kontinuierliche Funktionen zu lernen. Die Idee von
xVal besteht darin, die numerische Größe multiplikativ zu kodieren und sie im Einbettungsraum in eine lernbare Richtung auszurichten, was die Art und Weise, wie Zahlen in der Transformer-Architektur verarbeitet und interpretiert werden, stark verändert.
xVal verwendet einen einzigen Token für die digitale Codierung, was die Vorteile der Token-Effizienz und eines minimalen Vokabularbedarfs bietet.
In Kombination mit dem modifizierten numerischen Argumentationsparadigma ist der Wert des Transformer-Modells kontinuierlich (glatt), wenn die Näherungsfunktion kontinuierlich oder glatt ist, wenn die Näherungsfunktion kontinuierlich oder glatt ist.
xVal: Kontinuierliche Zahlenkodierung
xVal verwendet keine unterschiedlichen Token für unterschiedliche Zahlen, sondern bettet Werte direkt entlang spezifischer lernbarer Richtungen in den Einbettungsraum ein.
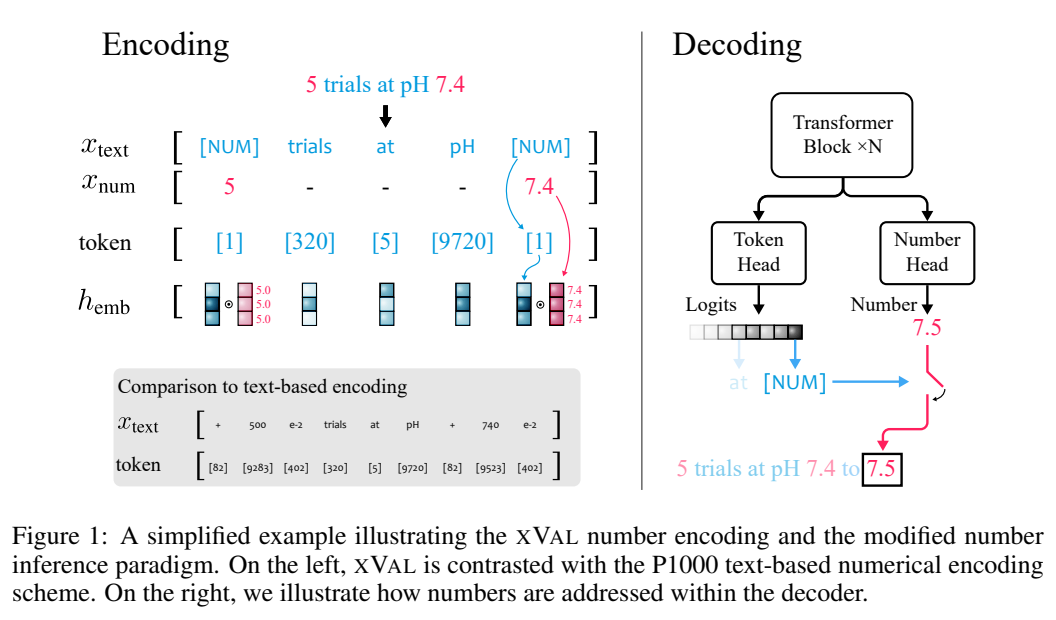
Unter der Annahme, dass die Eingabezeichenfolge sowohl Zahlen als auch Text enthält, analysiert das System zunächst die Eingabe, extrahiert alle Werte und erstellt dann eine neue Zeichenfolge, in der die Zahlen durch [NUM] ersetzt werden Symbol und multiplizieren Sie dann den Einbettungsvektor von [NUM] mit seinem entsprechenden Wert.
Der gesamte Codierungsprozess kann für die Maskensprachenmodellierung (MLM) und die autoregressive (AR) Generierung verwendet werden.
Implizite Normalisierung über Layer-Norm basierend auf Layer-Normalisierung
In der spezifischen Implementierung muss die multiplikative Einbettung von xVal im ersten Transformer-Block nach der Normalisierung des Codierungsvektors für die obere Position und der Layer-Norm hinzugefügt werden die Einbettung jedes Tokens basierend auf dem Eingabebeispiel.
Wenn die Positionseinbettung nicht kollinear mit der mit [NUM] markierten Einbettung ist, kann der Skalarwert durch eine nichtlineare Neuskalierungsfunktion geleitet werden.
Nehmen Sie an, dass u die Einbettung von [NUM] ist, p die Positionseinbettung und x der codierte Skalarwert ist. Um die Berechnung zu vereinfachen, können wir annehmen, dass u · p=0, wobei ∥u∥ =∥ p∥ = 1, Sie können
erhalten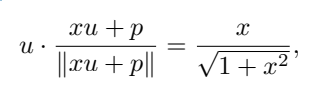
Das heißt, der Wert von x ist so codiert, dass er in die gleiche Richtung wie u weist, und diese Eigenschaft kann nach dem Training weiterhin beibehalten werden.
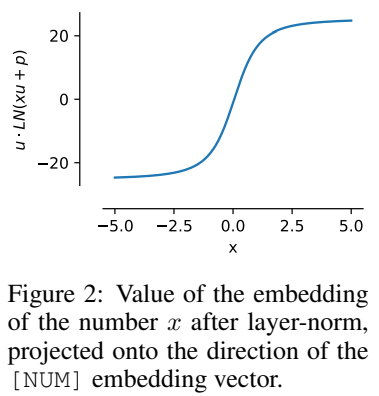
Diese Normalisierungseigenschaft bedeutet, dass der Dynamikbereich von xVal kleiner ist als der anderer textbasierter Codierungsschemata, der im Experiment als Verarbeitungsschritte vor dem Training auf [-5, 5] eingestellt wurde.
Numerisches Denken
xVal definiert eine kontinuierliche Einbettung in den Eingabewert, wenn jedoch eine Mehrfachklassifizierungsaufgabe als Ausgabe verwendet wird und der Trainingsalgorithmus die Zuordnung vom Eingabewert zum Ausgabewert berücksichtigt, ist das Modell insgesamt Es ist nicht durchgehend durchgehend und die Zahlen müssen auf der Ausgabeebene separat verarbeitet werden.
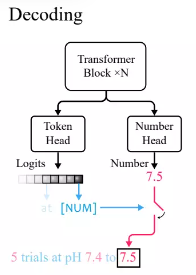
Gemäß der Standardpraxis im Transformer-Sprachmodell definierten die Forscher einen Token-Kopf, um die Wahrscheinlichkeitsverteilung von Vokabular-Tokens auszugeben.
Da xVal [NUM] zum Ersetzen von Zahlen verwendet, enthält der Kopf keine Informationen über den numerischen Wert. Daher muss ein neuer Zahlenkopf mit einer Skalarausgabe eingeführt und durch Verlust des mittleren quadratischen Fehlers (MSE) trainiert werden Stellt den spezifischen numerischen Wert wieder her, der mit [NUM] verknüpft ist.
Beobachten Sie nach der Eingabe zunächst die Ausgabe des Token-Kopfes. Wenn der generierte Token [NUM] ist, sehen Sie sich dann den Zahlenkopf an, um den Wert des Tokens einzugeben.
Da das Transformer-Modell in Experimenten bei der Ableitung von Werten durchgängig kontinuierlich ist, schneidet es bei der Interpolation auf unsichtbare Werte besser ab.
Experimenteller Teil
Vergleich mit anderen digitalen Kodierungsmethoden
Die Forscher verglichen die Leistung von XVAL mit vier anderen digitalen Kodierungen, bei denen alle die Verarbeitung der Zahlen in die erste Form ±ddd E±d erfordern. Rufen Sie dann je nach Format einzelne oder mehrere Token auf, um die Codierung zu bestimmen.

Verschiedene Methoden weisen große Unterschiede in der Anzahl der Token und dem Vokabular auf, die zum Codieren jeder Zahl erforderlich sind. Insgesamt weist xVal jedoch die höchste Codierungseffizienz und die kleinste Vokabulargröße auf.
Die Forscher bewerteten xVal auch anhand von drei Datensätzen, darunter synthetische Rechenoperationsdaten, globale Temperaturdaten und Simulationsdaten der Planetenumlaufbahn.
Rechnen lernen
Selbst für die größten LLMs ist die „mehrstellige Multiplikation“ immer noch eine äußerst anspruchsvolle Aufgabe. Beispielsweise erreicht GPT-4 nur eine Null-Schuss-Genauigkeit von 59 %, die Genauigkeit auf vier -stellige und fünfstellige Multiplikationsprobleme betragen nur 4 % und 0 %
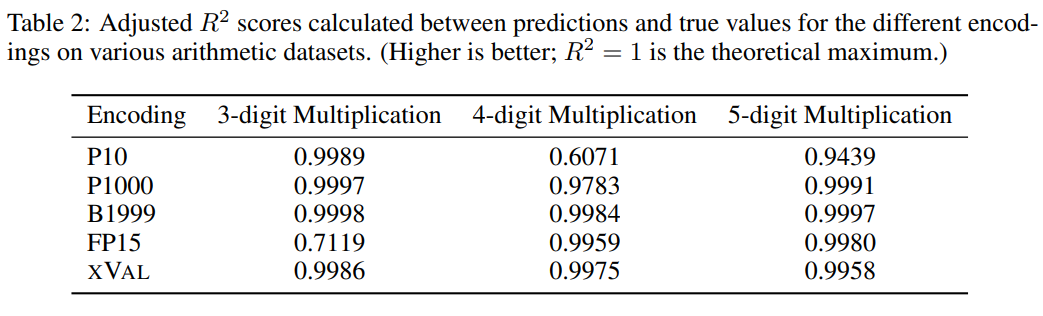
Aus den Vergleichsexperimenten können andere digitale Kodierungen normalerweise auch sehr gute Ergebnisse bei mehrstelligen Multiplikationsproblemen lösen, aber die Vorhersageergebnisse von xVal sind stabiler als P10 und FP15 und erzeugen keine abnormalen Vorhersagewerte.
Um die Schwierigkeit der Aufgabe zu erhöhen, verwendeten die Forscher zufällige Binärbäume, um einen Datensatz mit binären Additions-, Subtraktions- und Multiplikationsoperatoren zu erstellen, um eine feste Anzahl von Operanden (2, 3 oder 4) zu kombinieren wobei jede Probe ein arithmetischer Ausdruck ist, zum Beispiel ((1,32 * 32,1) + (1,42-8,20)) = 35,592
Dann werden die Proben gemäß den Verarbeitungsanforderungen jedes Zahlencodierungsschemas verarbeitet, und das Ziel der Aufgabe ist Um den Ausdruck auf der linken Seite der Gleichung zu berechnen, ist die rechte Seite der Gleichung die Maske.
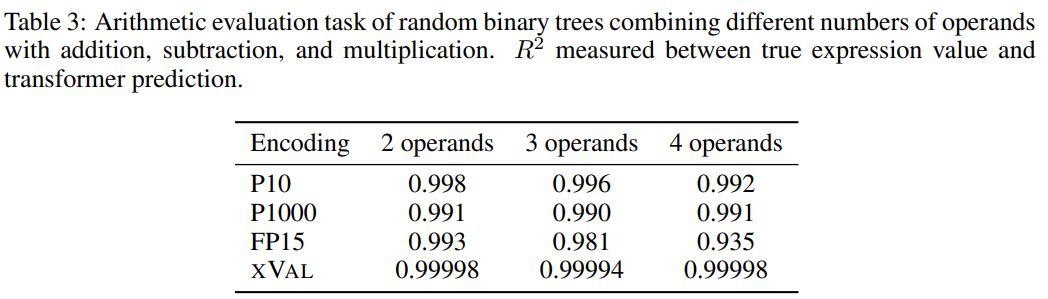
Den Ergebnissen nach zu urteilen hat xVal bei dieser Aufgabe sehr gut abgeschnitten, aber arithmetische Experimente allein reichen nicht aus, um die mathematischen Fähigkeiten des Sprachmodells vollständig zu bewerten, da die Stichproben in arithmetischen Operationen normalerweise kurze Sequenzen sind und die zugrunde liegende Datenmannigfaltigkeit gering ist -dimensional überwinden diese Probleme nicht den rechnerischen Engpass von LLMs und die Anwendungen in der realen Welt sind komplexer.
Temperaturvorhersage
Der Einfachheit halber haben sich die Forscher im Experiment nur auf die Oberflächentemperaturdaten (T2m in ERA5) konzentriert Anschließend wurden die Proben aufgeteilt, wobei jede Probe 2–4 Tage Oberflächentemperaturdaten (normalisiert auf Einheitsvarianz) sowie Breiten- und Längengrade von 60–90 zufällig ausgewählten Berichtsstationen umfasst.
Kodieren Sie den Sinus des Breitengrads und den Sinus und Cosinus des Längengrads der Koordinate, um so die Periodizität der Daten beizubehalten, und verwenden Sie dann denselben Vorgang, um die Position im 24-Stunden- und 365-Tage-Zeitraum zu kodieren .

Die Koordinaten (Koordinaten), der Startpunkt (Start) und die Daten (Daten) entsprechen den Koordinaten der Meldestation, dem Zeitpunkt der ersten Probe und den normalisierten Temperaturdaten und verwenden dann die MLM-Methode zum Trainieren das Sprachmodell.
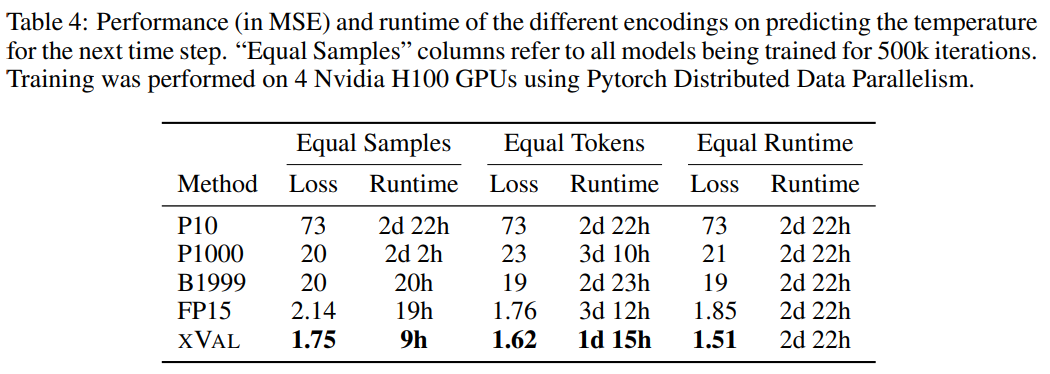
Aus den Ergebnissen geht hervor, dass xVal die beste Leistung aufweist und auch die Berechnungszeit erheblich verkürzt wird.
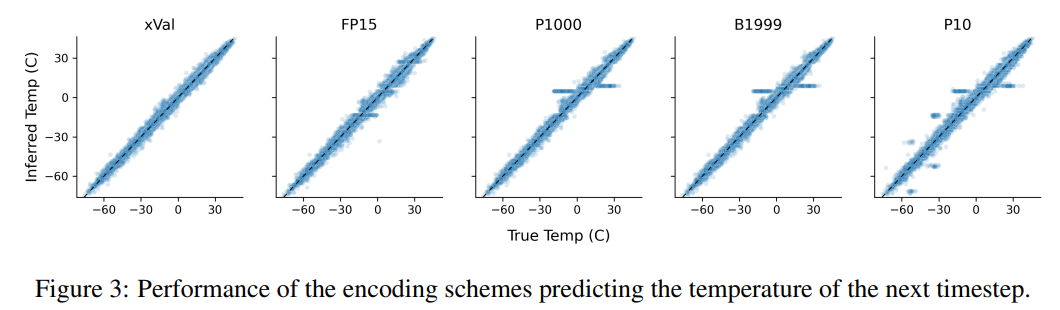
Diese Aufgabe veranschaulicht auch die Mängel textbasierter Codierungsschemata. Das Modell kann falsche Korrelationen in den Daten ausnutzen, d. h. P10, P1000 und B1999 neigen dazu, normalisierte Temperaturen von ±0,1 vorherzusagen, hauptsächlich weil diese Zahl kommt im Datensatz am häufigsten vor.
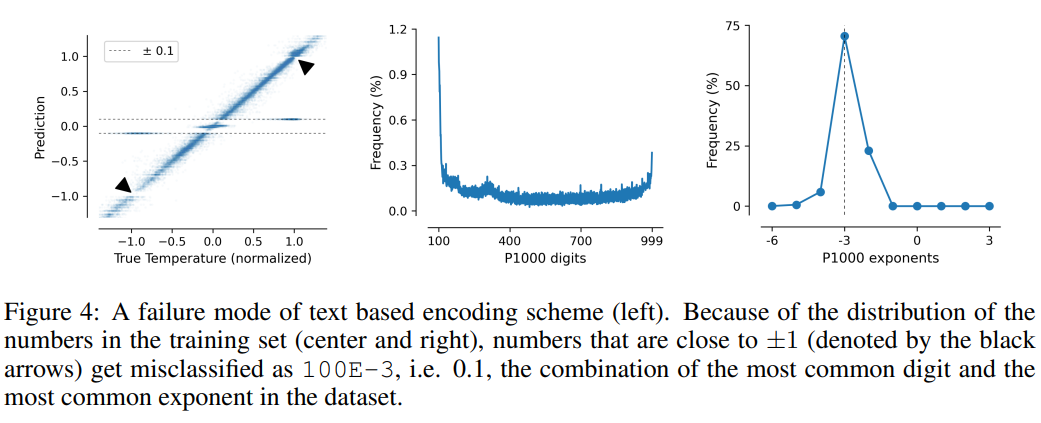
Für die Schemata P1000 und P10 beträgt die Codierungsausgabe der beiden Schemata etwa 8000 bzw. 5000 Token (im Vergleich zum Durchschnitt von FP15 und xVal von etwa 1800 Token), was wahrscheinlich auf eine schlechte Leistung des Modells zurückzuführen ist zu Problemen mit der Fernmodellierung.
Das obige ist der detaillierte Inhalt von1 Token beendet das LLM-Digitalcodierungsproblem! Neun große Institutionen haben gemeinsam xVal veröffentlicht: Auch Zahlen, die nicht im Trainingssatz enthalten sind, können vorhergesagt werden!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1384
1384
 52
52

 CentOS Shutdown -Befehlszeile
Apr 14, 2025 pm 09:12 PM
CentOS Shutdown -Befehlszeile
Apr 14, 2025 pm 09:12 PM
Der Befehl centOS stilldown wird heruntergefahren und die Syntax wird von [Optionen] ausgeführt [Informationen]. Zu den Optionen gehören: -h das System sofort stoppen; -P schalten Sie die Leistung nach dem Herunterfahren aus; -r neu starten; -t Wartezeit. Zeiten können als unmittelbar (jetzt), Minuten (Minuten) oder als bestimmte Zeit (HH: MM) angegeben werden. Hinzugefügten Informationen können in Systemmeldungen angezeigt werden.
 So überprüfen Sie die CentOS -HDFS -Konfiguration
Apr 14, 2025 pm 07:21 PM
So überprüfen Sie die CentOS -HDFS -Konfiguration
Apr 14, 2025 pm 07:21 PM
Vollständige Anleitung zur Überprüfung der HDFS -Konfiguration in CentOS -Systemen In diesem Artikel wird die Konfiguration und den laufenden Status von HDFS auf CentOS -Systemen effektiv überprüft. Die folgenden Schritte helfen Ihnen dabei, das Setup und den Betrieb von HDFs vollständig zu verstehen. Überprüfen Sie die Hadoop -Umgebungsvariable: Stellen Sie zunächst sicher, dass die Hadoop -Umgebungsvariable korrekt eingestellt ist. Führen Sie im Terminal den folgenden Befehl aus, um zu überprüfen, ob Hadoop ordnungsgemäß installiert und konfiguriert ist: Hadoopsion-Check HDFS-Konfigurationsdatei: Die Kernkonfigurationsdatei von HDFS befindet sich im/etc/hadoop/conf/verzeichnis, wobei core-site.xml und hdfs-site.xml von entscheidender Bedeutung sind. verwenden
 Was sind die Backup -Methoden für Gitlab auf CentOS?
Apr 14, 2025 pm 05:33 PM
Was sind die Backup -Methoden für Gitlab auf CentOS?
Apr 14, 2025 pm 05:33 PM
Backup- und Wiederherstellungsrichtlinie von GitLab im Rahmen von CentOS -System Um die Datensicherheit und Wiederherstellung der Daten zu gewährleisten, bietet GitLab on CentOS eine Vielzahl von Sicherungsmethoden. In diesem Artikel werden mehrere gängige Sicherungsmethoden, Konfigurationsparameter und Wiederherstellungsprozesse im Detail eingeführt, um eine vollständige GitLab -Sicherungs- und Wiederherstellungsstrategie aufzubauen. 1. Manuell Backup Verwenden Sie den GitLab-RakegitLab: Backup: Befehl erstellen, um die manuelle Sicherung auszuführen. Dieser Befehl unterstützt wichtige Informationen wie GitLab Repository, Datenbank, Benutzer, Benutzergruppen, Schlüssel und Berechtigungen. Die Standardsicherungsdatei wird im Verzeichnis/var/opt/gitlab/backups gespeichert. Sie können /etc /gitlab ändern
 Wie ist die GPU -Unterstützung für Pytorch bei CentOS?
Apr 14, 2025 pm 06:48 PM
Wie ist die GPU -Unterstützung für Pytorch bei CentOS?
Apr 14, 2025 pm 06:48 PM
Aktivieren Sie die Pytorch -GPU -Beschleunigung am CentOS -System erfordert die Installation von CUDA-, CUDNN- und GPU -Versionen von Pytorch. Die folgenden Schritte führen Sie durch den Prozess: Cuda und Cudnn Installation Bestimmen Sie die CUDA-Version Kompatibilität: Verwenden Sie den Befehl nvidia-smi, um die von Ihrer NVIDIA-Grafikkarte unterstützte CUDA-Version anzuzeigen. Beispielsweise kann Ihre MX450 -Grafikkarte CUDA11.1 oder höher unterstützen. Download und installieren Sie Cudatoolkit: Besuchen Sie die offizielle Website von Nvidiacudatoolkit und laden Sie die entsprechende Version gemäß der höchsten CUDA -Version herunter und installieren Sie sie, die von Ihrer Grafikkarte unterstützt wird. Installieren Sie die Cudnn -Bibliothek:
 Detaillierte Erklärung des Docker -Prinzips
Apr 14, 2025 pm 11:57 PM
Detaillierte Erklärung des Docker -Prinzips
Apr 14, 2025 pm 11:57 PM
Docker verwendet Linux -Kernel -Funktionen, um eine effiziente und isolierte Anwendungsumgebung zu bieten. Sein Arbeitsprinzip lautet wie folgt: 1. Der Spiegel wird als schreibgeschützte Vorlage verwendet, die alles enthält, was Sie für die Ausführung der Anwendung benötigen. 2. Das Union File System (UnionFS) stapelt mehrere Dateisysteme, speichert nur die Unterschiede, speichert Platz und beschleunigt. 3. Der Daemon verwaltet die Spiegel und Container, und der Kunde verwendet sie für die Interaktion. 4. Namespaces und CGroups implementieren Container -Isolation und Ressourcenbeschränkungen; 5. Mehrere Netzwerkmodi unterstützen die Containerverbindung. Nur wenn Sie diese Kernkonzepte verstehen, können Sie Docker besser nutzen.
 CentOS installieren MySQL
Apr 14, 2025 pm 08:09 PM
CentOS installieren MySQL
Apr 14, 2025 pm 08:09 PM
Die Installation von MySQL auf CentOS umfasst die folgenden Schritte: Hinzufügen der entsprechenden MySQL Yum -Quelle. Führen Sie den Befehl mySQL-server aus, um den MySQL-Server zu installieren. Verwenden Sie den Befehl mySQL_SECURE_INSTALLATION, um Sicherheitseinstellungen vorzunehmen, z. B. das Festlegen des Stammbenutzerkennworts. Passen Sie die MySQL -Konfigurationsdatei nach Bedarf an. Tune MySQL -Parameter und optimieren Sie Datenbanken für die Leistung.
 So sehen Sie sich Gitlab -Protokolle unter CentOS
Apr 14, 2025 pm 06:18 PM
So sehen Sie sich Gitlab -Protokolle unter CentOS
Apr 14, 2025 pm 06:18 PM
Eine vollständige Anleitung zum Anzeigen von GitLab -Protokollen unter CentOS -System In diesem Artikel wird in diesem Artikel verschiedene GitLab -Protokolle im CentOS -System angezeigt, einschließlich Hauptprotokolle, Ausnahmebodi und anderen zugehörigen Protokollen. Bitte beachten Sie, dass der Log -Dateipfad je nach GitLab -Version und Installationsmethode variieren kann. Wenn der folgende Pfad nicht vorhanden ist, überprüfen Sie bitte das GitLab -Installationsverzeichnis und die Konfigurationsdateien. 1. Zeigen Sie das Hauptprotokoll an. Verwenden Sie den folgenden Befehl, um die Hauptprotokolldatei der GitLabRails-Anwendung anzuzeigen: Befehl: Sudocat/var/log/gitlab/gitlab-rails/production.log Dieser Befehl zeigt das Produkt an
 Wie man eine verteilte Schulung von Pytorch auf CentOS betreibt
Apr 14, 2025 pm 06:36 PM
Wie man eine verteilte Schulung von Pytorch auf CentOS betreibt
Apr 14, 2025 pm 06:36 PM
Pytorch Distributed Training on CentOS -System erfordert die folgenden Schritte: Pytorch -Installation: Die Prämisse ist, dass Python und PIP im CentOS -System installiert sind. Nehmen Sie abhängig von Ihrer CUDA -Version den entsprechenden Installationsbefehl von der offiziellen Pytorch -Website ab. Für CPU-Schulungen können Sie den folgenden Befehl verwenden: PipinstallTorChTorChVisionTorChaudio Wenn Sie GPU-Unterstützung benötigen, stellen Sie sicher, dass die entsprechende Version von CUDA und CUDNN installiert ist und die entsprechende Pytorch-Version für die Installation verwenden. Konfiguration der verteilten Umgebung: Verteiltes Training erfordert in der Regel mehrere Maschinen oder mehrere Maschinen-Mehrfach-GPUs. Ort
