
 Technologie-Peripheriegeräte
KI
Üben und denken Sie an die multimodale große Modellplattform DataCanvas von Jiuzhang Yunji
Technologie-Peripheriegeräte
KI
Üben und denken Sie an die multimodale große Modellplattform DataCanvas von Jiuzhang Yunji
Üben und denken Sie an die multimodale große Modellplattform DataCanvas von Jiuzhang Yunji


1. Die historische Entwicklung multimodaler Großmodelle

Das Bild oben zeigt den ersten Workshop zu künstlicher Intelligenz, der 1956 am Dartmouth College in den Vereinigten Staaten stattfand der Beginn der künstlichen Intelligenz sein, und die Teilnehmer sind hauptsächlich die Pioniere der symbolischen Logik (mit Ausnahme des Neurobiologen Peter Milner in der Mitte der ersten Reihe).
Diese symbolische Logiktheorie konnte jedoch lange Zeit nicht verwirklicht werden, und sogar die erste KI-Winterperiode kam in den 1980er und 1990er Jahren. Erst mit der kürzlich erfolgten Implementierung großer Sprachmodelle entdeckten wir, dass neuronale Netze dieses logische Denken tatsächlich in sich tragen. Die Arbeit des Neurobiologen Peter Milner inspirierte die spätere Entwicklung künstlicher neuronaler Netze, und aus diesem Grund wurde er zur Teilnahme eingeladen in diesem akademischen Seminar.

Im Jahr 2012 veröffentlichte Andrew, der Direktor für autonomes Fahren bei Tesla, das obige Bild auf seinem Blog und zeigte den damaligen US-Präsidenten Obama beim Scherzen mit seinen Untergebenen. Damit künstliche Intelligenz dieses Bild verstehen kann, ist es nicht nur eine visuelle Wahrnehmungsaufgabe, denn neben der Identifizierung von Objekten muss sie auch die Beziehung zwischen ihnen verstehen. Nur wenn wir die physikalischen Prinzipien der Skala kennen, können wir die beschriebene Geschichte kennen Das Bild: Obama tritt auf Der Mann auf der Waage nahm zu, was dazu führte, dass er diesen seltsamen Gesichtsausdruck machte, während andere lachten. Ein solches logisches Denken geht offensichtlich über den Rahmen der reinen visuellen Wahrnehmung hinaus. Daher müssen visuelle Wahrnehmung und logisches Denken kombiniert werden, um die Peinlichkeit der „künstlichen geistigen Behinderung“ zu beseitigen. Hier spiegeln sich auch die Bedeutung und die Schwierigkeit multimodaler großer Modelle wider es ist.
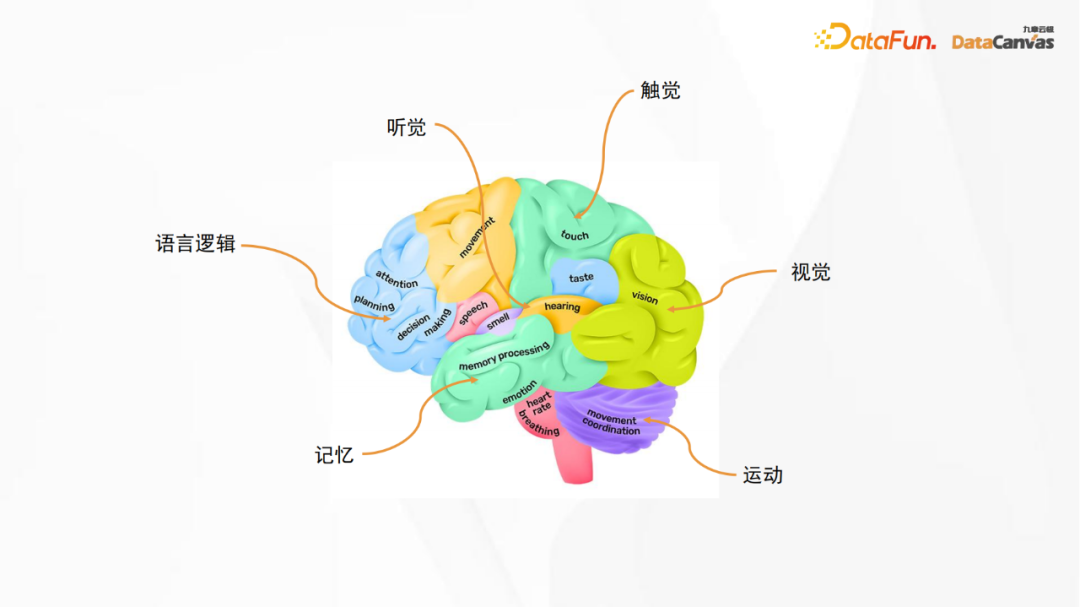
Das obige Bild ist ein anatomisches Strukturdiagramm des menschlichen Gehirns. Der Sprachlogikbereich im Bild entspricht dem großen Sprachmodell, während andere Bereiche verschiedenen Sinnen entsprechen, einschließlich Sehen, Hören, Berühren und Bewegung, Gedächtnis usw. Obwohl das künstliche neuronale Netzwerk kein neuronales Netzwerk im eigentlichen Sinne ist, können wir uns dennoch von ihm inspirieren lassen, das heißt, beim Aufbau eines großen Modells können verschiedene Funktionen miteinander kombiniert werden Multimodaler Modellbau.
1. Was können multimodale Großmodelle?
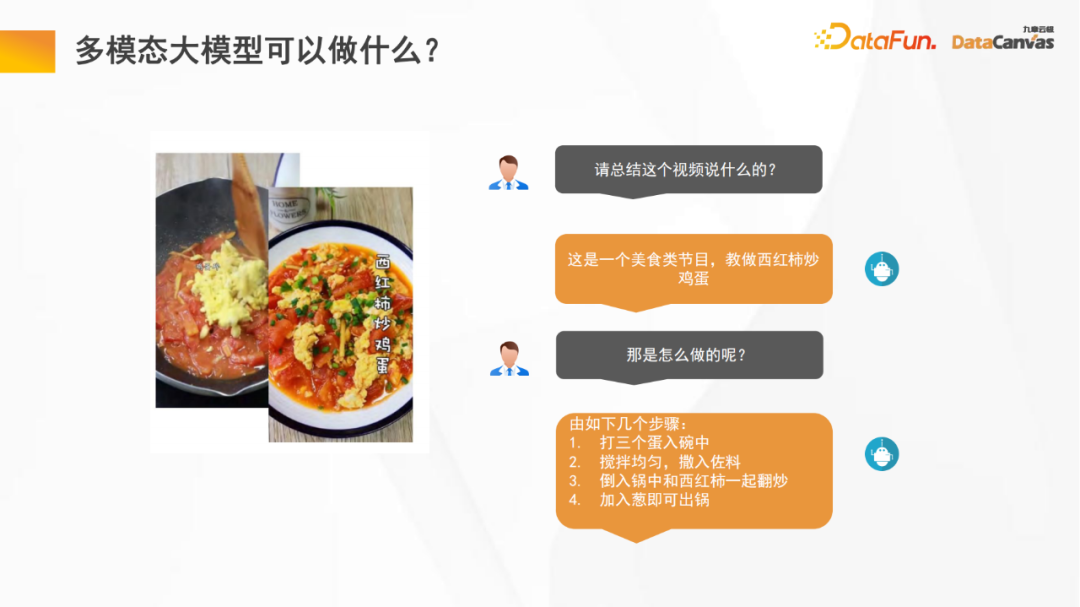
Multimodale große Modelle können uns viel helfen, z. B. das Videoverständnis. Große Modelle können uns dabei helfen, die Zusammenfassung und die wichtigsten Informationen des Videos zusammenzufassen, wodurch wir beim Ansehen großer Modelle Zeit sparen kann uns auch dabei helfen, Nachanalysen von Videos durchzuführen, z. B. Programmklassifizierung, Programmbewertungsstatistiken usw. Darüber hinaus sind vinzentinische Diagramme auch ein wichtiges Anwendungsgebiet multimodaler großer Modelle.
Wenn das große Modell mit der Bewegung von Menschen oder Robotern kombiniert wird, wird eine verkörperte Intelligenz erzeugt. Genau wie bei Menschen wird die Methode zur Planung des besten Pfads basierend auf Erfahrungen aus der Vergangenheit auf neue angewendet. Lösen Sie das Szenario Einige Probleme, die bisher noch nicht aufgetreten sind, und gleichzeitig Risiken zu vermeiden, können Sie den ursprünglichen Plan während des Ausführungsprozesses sogar ändern, bis Sie schließlich Erfolg haben. Auch hier handelt es sich um ein Anwendungsszenario mit breiten Perspektiven.
2. Multimodales großes Modell
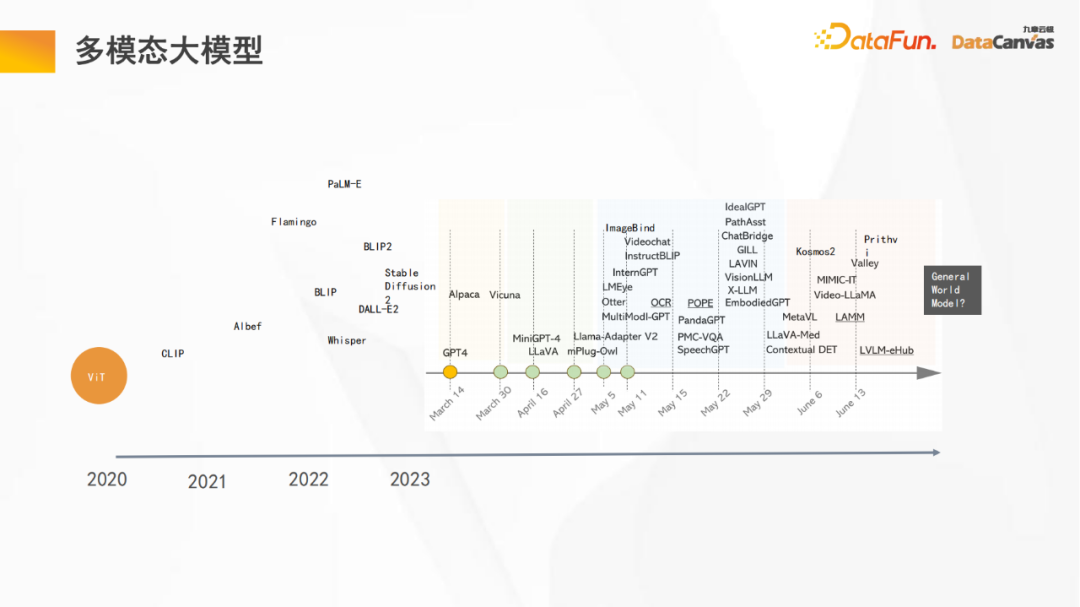
Das Bild oben zeigt einige wichtige Knoten im Entwicklungsprozess eines multimodalen großen Modells:
- Das 2020 ViT-Modell (Vision Transformer) ist der Beginn eines großen Modells. Erstmals wird die Transformer-Architektur neben Sprache und logischer Verarbeitung auch für andere Datentypen (visuelle Daten) verwendet, und das zeigt sich Gute Generalisierungsfähigkeiten; Bis 2023 werden nach und nach verschiedene multimodale große Modelle entstehen, von PaLM-E (Roboter) über Whisper (Spracherkennung) bis hin zu ImageBind (Bildausrichtung) und Sam (semantische Segmentierung) ) und schließlich zu geografischen Bildern, einschließlich der einheitlichen multimodalen Architektur Kosmos2 von Microsoft, entwickeln sich multimodale Großmodelle rasant.
- Tesla hat im Juni auf der CVPR auch die Vision eines universellen Weltmodells vorgeschlagen.
- Wie Sie auf dem Bild oben sehen können, haben in nur einem halben Jahr viele Änderungen am großen Modell stattgefunden, und die Iterationsgeschwindigkeit ist sehr hoch.
- 3. Modale Ausrichtungsarchitektur
Das obige Bild ist ein allgemeines Architekturdiagramm eines großen multimodalen Modells, einschließlich eines Sprachmodells und eines visuellen Modells, durch ein festes Sprachmodell und ein Das Ausrichten eines festen visuellen Modells besteht darin, den Vektorraum des visuellen Modells und den Vektorraum des Sprachmodells zu kombinieren und dann das Verständnis der internen logischen Beziehung zwischen beiden in einem einheitlichen Vektorraum zu vervollständigen.
Sowohl das im Bild gezeigte Flamingo-Modell als auch das BLIP2-Modell haben eine ähnliche Struktur (das Flamingo-Modell verwendet die Perceiver-Architektur, während das BLIP2-Modell eine verbesserte Version der Transformer-Architektur verwendet). Durch eine Vielzahl kontrastierender Lernmethoden wird eine große Anzahl von Token verwendet, um schließlich bessere Ausrichtungseffekte zu erzielen. 2. Die multimodale Plattform für große Modelle von Jiuzhang Yunji DataCanvas GPU-Cluster werden verwendet, um Hochleistungsspeicher und Netzwerkoptimierung durchzuführen. Auf dieser Basis werden große Modelltrainingstools bereitgestellt, einschließlich experimenteller Sandboxen zur Datenannotationsmodellierung usw. Jiuzhang Yunji DataCanvas unterstützt nicht nur gängige Open-Source-Großmodelle auf dem Markt, sondern entwickelt auch unabhängig multimodale Großmodelle von Yuanshi. Auf der Anwendungsebene werden Tools zur Verwaltung von Eingabeaufforderungswörtern, zur Feinabstimmung des Modells und zur Bereitstellung eines Modellbetriebs- und -wartungsmechanismus bereitgestellt. Gleichzeitig wurde eine multimodale Vektordatenbank als Open Source bereitgestellt, um die grundlegende Softwarearchitektur zu bereichern. 2. Modelltool LMOPS Bewertung (einschließlich horizontaler Bewertung und vertikaler Bewertung), Modellbegründung (unterstützende Modellquantifizierung, Wissensdestillation und andere beschleunigte Argumentationsmechanismen), Modellanwendung usw. 3. LMB – Large Model Builder Diese verteilten Optimierungsaufgaben werden mit einem Klick erledigt und unterstützen die visuelle Kontrolle, wodurch die Arbeitskosten erheblich gesenkt und die Entwicklungseffizienz verbessert werden können.
4、LMB – Großer Modellbauer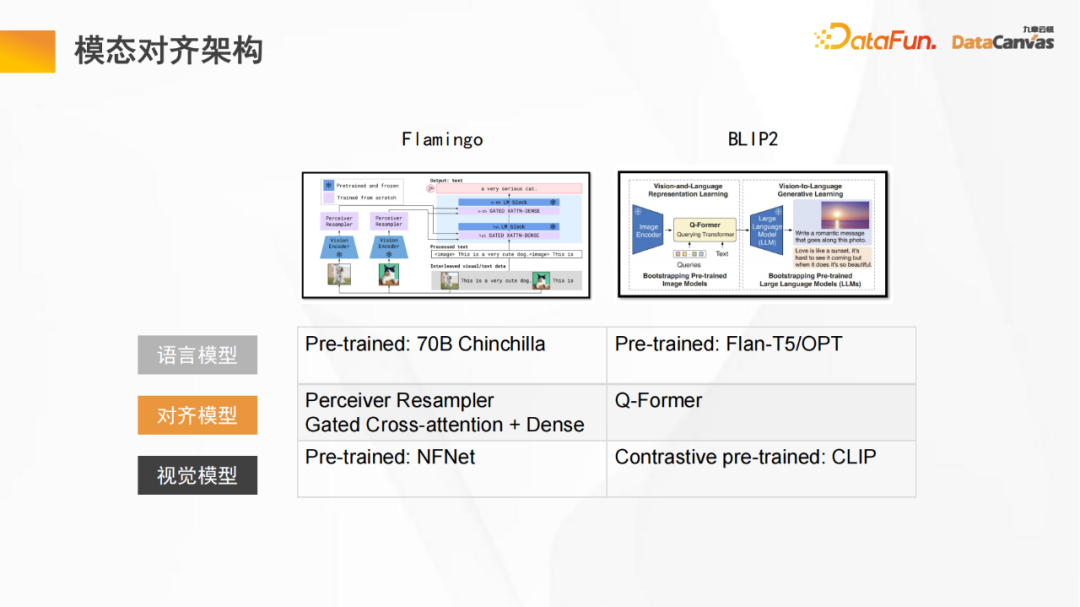
Die Abstimmung großer Modelle wurde ebenfalls optimiert, einschließlich allgemeiner Weiterbildung, Überwachungsoptimierung und menschlichem Feedback beim Verstärkungslernen. Darüber hinaus wurden viele Optimierungen für Chinesisch vorgenommen, beispielsweise die automatische Erweiterung des chinesischen Wortschatzes. Da viele chinesische Wörter nicht in großen Open-Source-Modellen enthalten sind, werden diese Wörter möglicherweise in mehrere Token aufgeteilt. Durch die automatische Erweiterung dieser Wörter kann das Modell diese Wörter besser verwenden. 5. LMS – Large Model Serving Reduziert die Berechnungszeit erheblich und beschleunigt den Transformator durch schichtweise Wissensdestillation, um seinen Berechnungsaufwand zu reduzieren. Gleichzeitig wurde viel Beschneidungsarbeit geleistet (einschließlich strukturierter Beschneidung, spärlicher Beschneidung usw.), was die Inferenzgeschwindigkeit großer Modelle erheblich verbessert hat.
Darüber hinaus wurde auch der interaktive Dialogprozess optimiert. Beispielsweise können in einem Multi-Turn-Dialog-Transformer der Schlüssel und der Wert jedes Tensors ohne wiederholte Berechnungen gespeichert werden. Daher kann es in Vector DB gespeichert werden, um die Speicherfunktion für den Gesprächsverlauf zu realisieren und die Benutzererfahrung während des Interaktionsprozesses zu verbessern. 6. Prompt Manager Dieses Tool kann nicht nur einen Entwicklungs-Toolkit-Entwicklungsmodus für technisches Personal bereitstellen, sondern auch einen Mensch-Computer-Interaktionsbetriebsmodus für nichttechnisches Personal bereitstellen und so den Anforderungen verschiedener Personengruppen an die Verwendung großer Modelle gerecht werden.
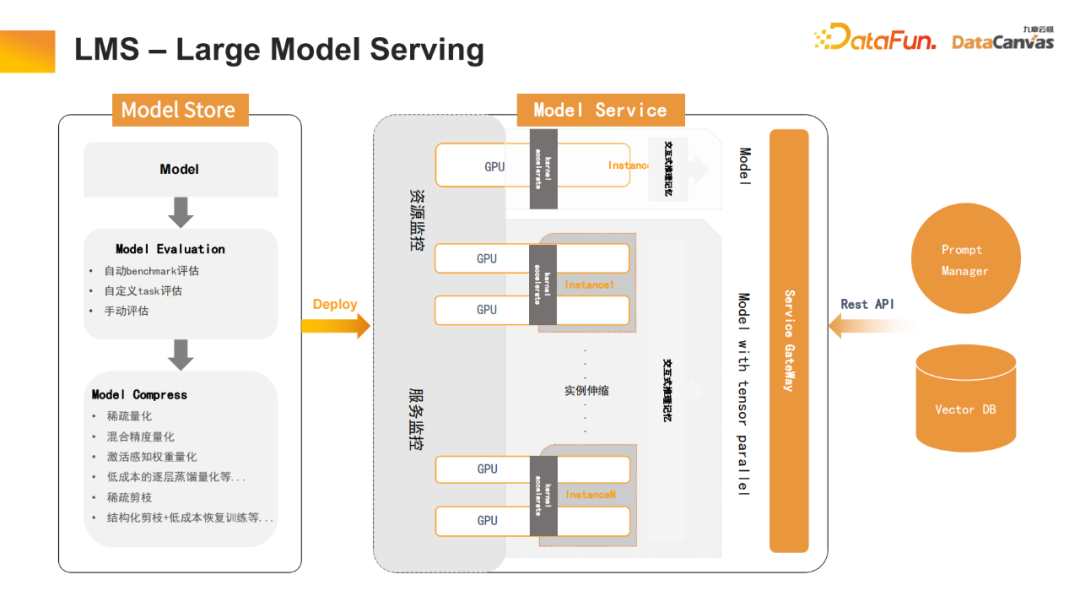 Zu den Hauptfunktionen gehören: KI-Modellverwaltung, Szenenverwaltung, Verwaltung von Prompt-Word-Vorlagen, Prompt-Word-Entwicklung und Prompt-Word-Anwendung usw.
Zu den Hauptfunktionen gehören: KI-Modellverwaltung, Szenenverwaltung, Verwaltung von Prompt-Word-Vorlagen, Prompt-Word-Entwicklung und Prompt-Word-Anwendung usw.
Die Plattform bietet häufig verwendete Tools zur Verwaltung von Aufforderungswörtern, um eine Versionskontrolle zu erreichen, und stellt häufig verwendete Vorlagen bereit, um die Implementierung von Aufforderungswörtern zu beschleunigen.
3. Die Praxis des multimodalen großen Modells von Jiuzhang Yunji
1. Multimodales großes Modell – mit Speicher
Nach der Einführung der Plattformfunktionen werde ich als nächstes das multimodale Modell teilen Große Modellentwicklungspraktiken.

Das Bild oben zeigt das Grundgerüst des multimodalen großen Modells von Jiuzhang Yunji DataCanvas. Der Unterschied zu anderen multimodalen großen Modellen besteht darin, dass es Speicher enthält, der das große Open-Source-Modell verbessern kann Argumentationsfähigkeiten.
Im Allgemeinen ist die Anzahl der Parameter großer Open-Source-Modelle relativ gering. Wenn ein Teil der Parameter für den Speicher verwendet wird, wird seine Argumentationsfähigkeit erheblich verringert. Wenn einem großen Open-Source-Modell Speicher hinzugefügt wird, werden gleichzeitig die Denk- und Speicherfähigkeiten verbessert.
Darüber hinaus wird das multimodale große Modell, ähnlich wie die meisten Modelle, auch das große Sprachmodell und die feste Datenkodierung festlegen und ein separates modulares Training für die Ausrichtungsfunktion durchführen, sodass alle unterschiedlichen Datenmodalitäten ausgerichtet werden der Text Der logische Teil; im Argumentationsprozess wird die Sprache zuerst übersetzt, dann zusammengeführt und schließlich wird die Argumentationsarbeit durchgeführt.
2. ETL-Pipeline für unstrukturierte Daten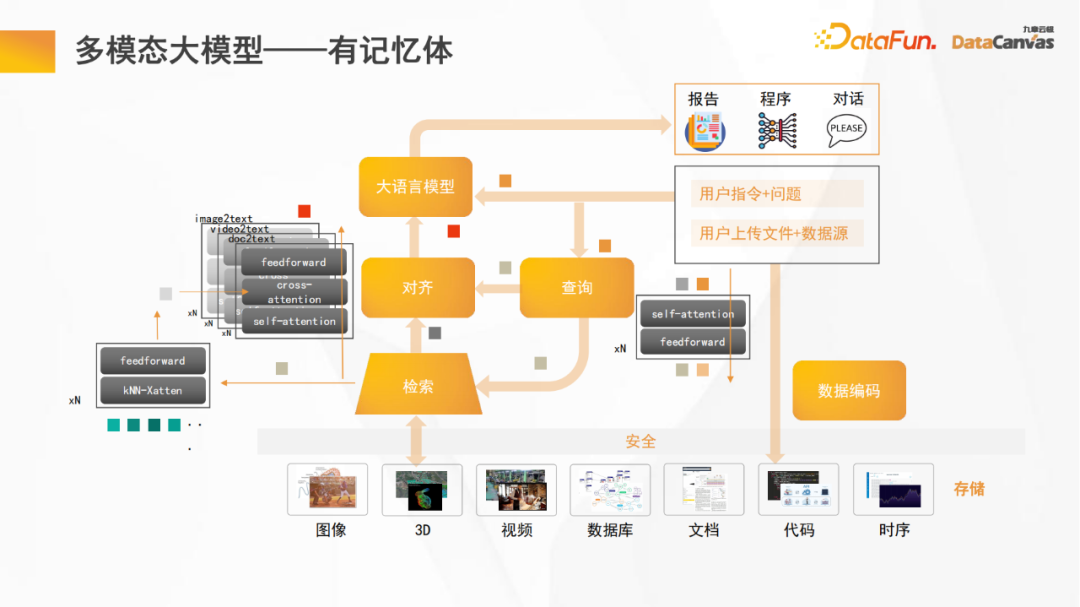
Da unsere multimodale Vektordatenbank DingoDB multimodale und ETL-Funktionen kombiniert, kann sie gute Funktionen zur Verwaltung unstrukturierter Daten bieten. Die Plattform bietet Pipeline-ETL-Funktionen und hat zahlreiche Optimierungen vorgenommen, darunter Operatorkompilierung, Parallelverarbeitung und Cache-Optimierung.
Darüber hinaus stellt die Plattform einen Hub bereit, der Pipelines wiederverwenden kann, um ein möglichst effizientes Entwicklungserlebnis zu erzielen. Gleichzeitig unterstützt es viele Encoder auf Huggingface, wodurch eine optimale Kodierung verschiedener Modaldaten erreicht werden kann. 3. Multimodale große Modellkonstruktionsmethode Daten Schulung durchführen.
Der Aufbau eines großen multimodalen Modells ist grob in drei Phasen unterteilt:
- Die erste Phase: feste Ausrichtung und Abfrage des großen Sprachmodells und des modalen Encoders
- Die zweite Phase ( Optional, unterstützt multimodale Suche): Festes großes Sprachmodell, modaler Encoder, Ausrichtungs- und Abfragemodul, Trainingsabrufmodul
- Die dritte Stufe (optional, für bestimmte Aufgaben): Anweisungen zur Feinabstimmung des großen Sprachmodell.
4. Fall – Aufbau einer Wissensdatenbank
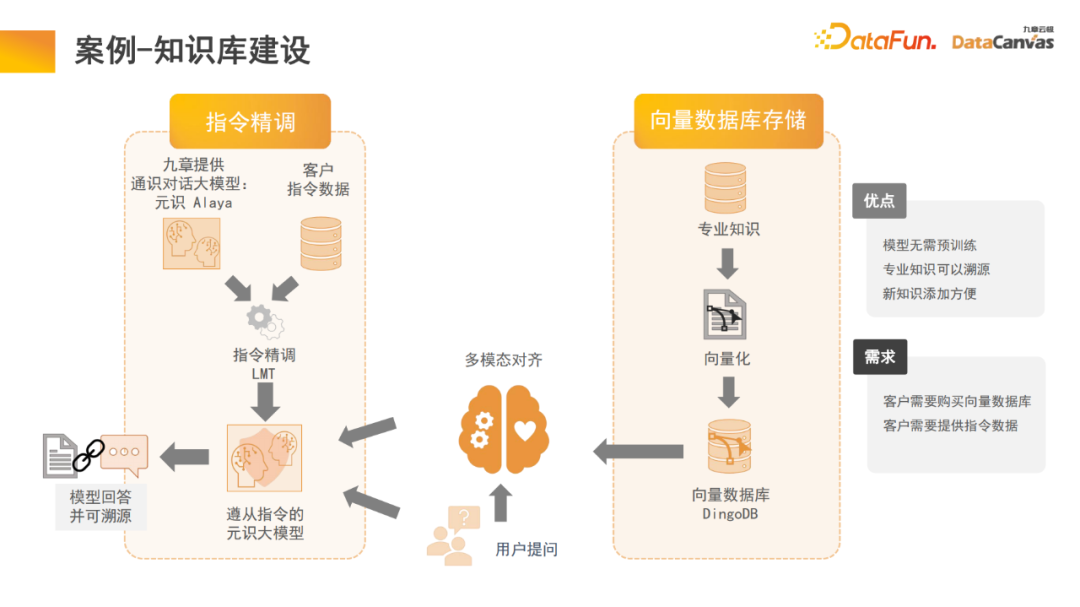
Die Speicherarchitektur im großen Modell kann uns dabei helfen, den Aufbau einer multimodalen Wissensdatenbank zu realisieren, bei der es sich tatsächlich um eine Modellanwendung handelt. Zhihu ist ein typisches multimodales Wissensdatenbank-Anwendungsmodul, dessen Fachwissen nachverfolgt werden kann.
Um die Gewissheit und Sicherheit des Wissens zu gewährleisten, ist es oft notwendig, die Quelle des Fachwissens zu ermitteln. Die Wissensdatenbank kann uns dabei helfen, diese Funktion zu realisieren Es besteht keine Notwendigkeit, die Modellparameter zu ändern und Wissen kann direkt zur Datenbank hinzugefügt werden.
Konkret wird Fachwissen genutzt, um über den Encoder unterschiedliche Codierungsentscheidungen zu treffen. Gleichzeitig wird eine einheitliche Bewertung auf der Grundlage verschiedener Bewertungsmethoden durchgeführt und die Auswahl des Encoders durch Ein-Klick-Bewertung realisiert. Schließlich wird die Encoder-Vektorisierung angewendet und in der multimodalen Vektordatenbank DingoDB gespeichert. Anschließend werden relevante Informationen über das multimodale Modul des großen Modells extrahiert und die Argumentation wird über das Sprachmodell durchgeführt.
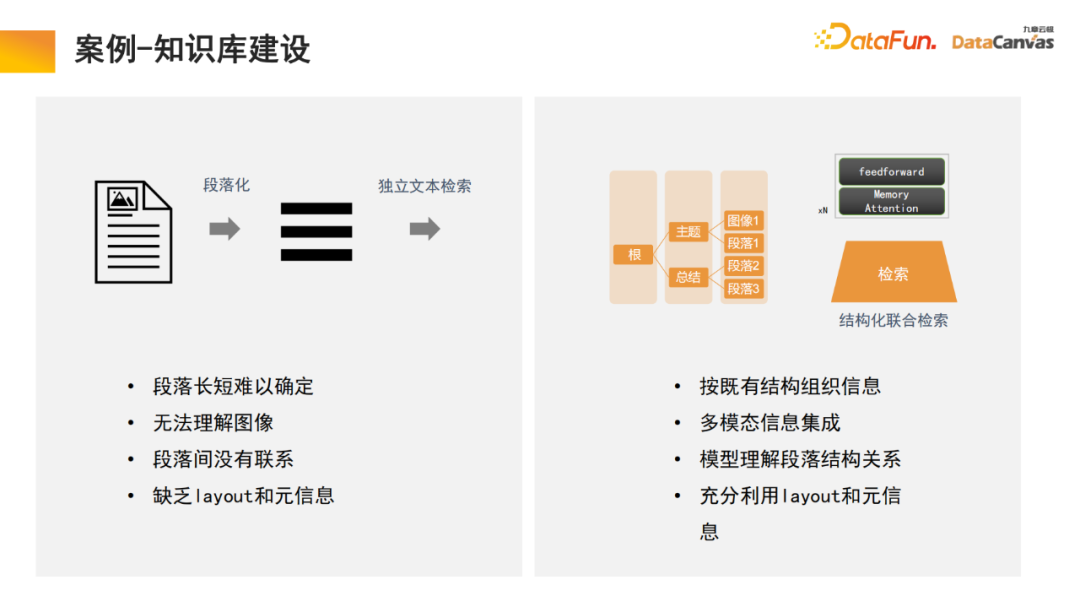
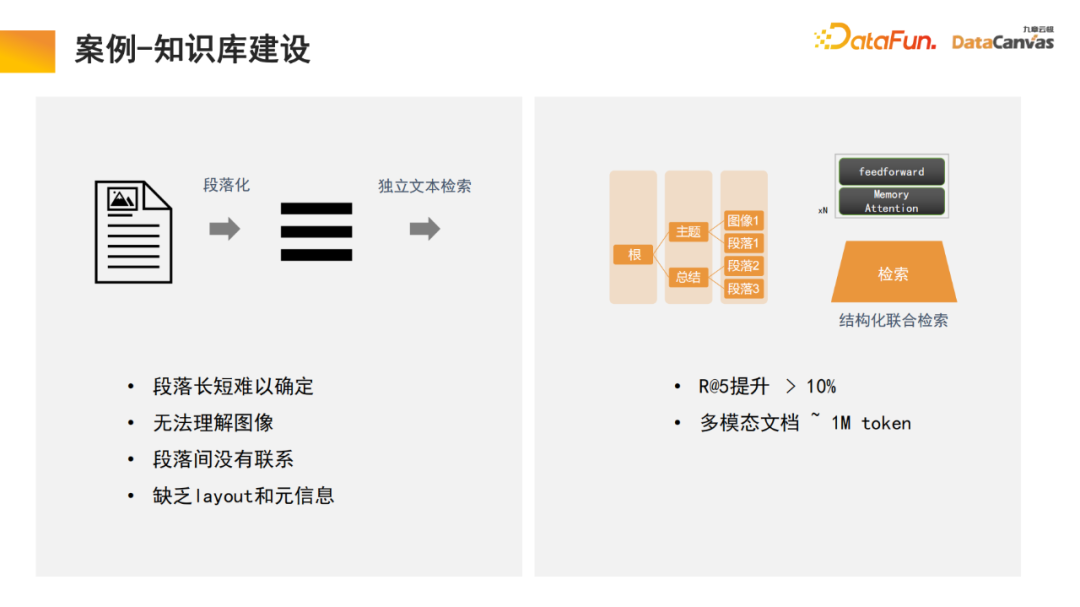
Der letzte Teil des Modells erfordert häufig eine Feinabstimmung der Anweisungen. Da die Bedürfnisse verschiedener Benutzer unterschiedlich sind, muss das gesamte multimodale große Modell feinabgestimmt werden. Aufgrund der besonderen Vorteile der multimodalen Wissensdatenbank bei der Organisation von Informationen verfügt das Modell über die Fähigkeit, das Abrufen zu erlernen. Dies ist auch eine Innovation, die wir im Prozess der Textparagraphierung vorgenommen haben.
Allgemeine Wissensbasis besteht darin, das Dokument in Absätze zu unterteilen und dann jeden Absatz einzeln zu entsperren. Diese Methode wird leicht durch Rauschen beeinträchtigt, und bei vielen großen Dokumenten ist es schwierig, die Kriterien für die Absatzunterteilung zu bestimmen.
In unserem Modell führt das Abrufmodul das Lernen durch und das Modell findet automatisch eine geeignete strukturierte Informationsorganisation. Beginnen Sie für ein bestimmtes Produkt mit dem Produkthandbuch, suchen Sie zuerst den großen Katalogabsatz und dann den spezifischen Absatz. Da es sich um eine multimodale Informationsintegration handelt, enthält sie neben Text häufig auch Bilder, Tabellen usw., die auch vektorisiert und mit Metainformationen kombiniert werden können, um einen gemeinsamen Abruf zu erreichen und so die Abrufeffizienz zu verbessern .
Es ist erwähnenswert, dass das Abrufmodul einen Speicheraufmerksamkeitsmechanismus verwendet, der die Rückrufrate im Vergleich zu ähnlichen Algorithmen um 10 % erhöhen kann. Gleichzeitig kann der Speicheraufmerksamkeitsmechanismus für die multimodale Dokumentenverarbeitung verwendet werden , was auch ein sehr vorteilhafter Aspekt ist. 4. Gedanken und Ausblicke für die Zukunft Nur Daten 15 % sind strukturierte Daten. In den letzten 20 Jahren drehte sich die künstliche Intelligenz hauptsächlich um strukturierte Daten. Unstrukturierte Daten sind sehr schwierig zu nutzen und erfordern viel Energie und Kosten, um sie in strukturierte Daten umzuwandeln. Mit Hilfe multimodaler Großmodelle und multimodaler Wissensbasen sowie durch das neue Paradigma der künstlichen Intelligenz kann die Nutzung unstrukturierter Daten im internen Management von Unternehmen erheblich verbessert werden, was zu einer Verzehnfachung führen kann Wert in der Zukunft.
 2. Wissensdatenbank --> Agent
2. Wissensdatenbank --> Agent
Multimodale Wissensdatenbank dient als Grundlage des Agenten, mit F&E-Agenten, Kundendienstmitarbeitern, Vertriebsmitarbeitern, Rechtsvertretern und Personalfunktionen wie Ressourcen Agenten und Enterprise-Betriebs- und -Wartungsagenten können alle über die Wissensdatenbank betrieben werden.
Nehmen Sie den Vertriebsmitarbeiter als Beispiel. Eine gemeinsame Architektur umfasst zwei gleichzeitig existierende Agenten, von denen einer für die Entscheidungsfindung und der andere für die Analyse der Verkaufsphase verantwortlich ist. Beide Module können über multimodale Wissensdatenbanken nach relevanten Informationen suchen, darunter Produktinformationen, historische Verkaufsstatistiken, Kundenporträts, vergangene Verkaufserfahrungen usw. Diese Informationen werden integriert, um diesen beiden Agenten dabei zu helfen, die beste und korrekteste Arbeit bei diesen Entscheidungen zu leisten wiederum helfen Benutzern, die besten Verkaufsinformationen zu erhalten, die dann in einer multimodalen Datenbank aufgezeichnet werden. Dieser Zyklus verbessert weiterhin die Verkaufsleistung.
Wir glauben, dass die wertvollsten Unternehmen der Zukunft diejenigen sein werden, die Intelligenz in die Praxis umsetzen. Ich hoffe, dass Jiuzhang Yunji DataCanvas Sie den ganzen Weg begleiten und sich gegenseitig helfen kann.
Das obige ist der detaillierte Inhalt vonÜben und denken Sie an die multimodale große Modellplattform DataCanvas von Jiuzhang Yunji. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1375
1375
 52
52

 CLIP-BEVFormer: Überwacht explizit die BEVFormer-Struktur, um die Leistung der Long-Tail-Erkennung zu verbessern
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer: Überwacht explizit die BEVFormer-Struktur, um die Leistung der Long-Tail-Erkennung zu verbessern
Mar 26, 2024 pm 12:41 PM
Oben geschrieben und das persönliche Verständnis des Autors: Derzeit spielt das Wahrnehmungsmodul im gesamten autonomen Fahrsystem eine entscheidende Rolle Das Steuermodul im autonomen Fahrsystem trifft zeitnahe und korrekte Urteile und Verhaltensentscheidungen. Derzeit sind Autos mit autonomen Fahrfunktionen in der Regel mit einer Vielzahl von Dateninformationssensoren ausgestattet, darunter Rundumsichtkamerasensoren, Lidar-Sensoren und Millimeterwellenradarsensoren, um Informationen in verschiedenen Modalitäten zu sammeln und so genaue Wahrnehmungsaufgaben zu erfüllen. Der auf reinem Sehen basierende BEV-Wahrnehmungsalgorithmus wird von der Industrie aufgrund seiner geringen Hardwarekosten und einfachen Bereitstellung bevorzugt, und seine Ausgabeergebnisse können problemlos auf verschiedene nachgelagerte Aufgaben angewendet werden.
 Implementierung von Algorithmen für maschinelles Lernen in C++: Häufige Herausforderungen und Lösungen
Jun 03, 2024 pm 01:25 PM
Implementierung von Algorithmen für maschinelles Lernen in C++: Häufige Herausforderungen und Lösungen
Jun 03, 2024 pm 01:25 PM
Zu den häufigsten Herausforderungen, mit denen Algorithmen für maschinelles Lernen in C++ konfrontiert sind, gehören Speicherverwaltung, Multithreading, Leistungsoptimierung und Wartbarkeit. Zu den Lösungen gehören die Verwendung intelligenter Zeiger, moderner Threading-Bibliotheken, SIMD-Anweisungen und Bibliotheken von Drittanbietern sowie die Einhaltung von Codierungsstilrichtlinien und die Verwendung von Automatisierungstools. Praktische Fälle zeigen, wie man die Eigen-Bibliothek nutzt, um lineare Regressionsalgorithmen zu implementieren, den Speicher effektiv zu verwalten und leistungsstarke Matrixoperationen zu nutzen.
 Entdecken Sie die zugrunde liegenden Prinzipien und die Algorithmusauswahl der C++-Sortierfunktion
Apr 02, 2024 pm 05:36 PM
Entdecken Sie die zugrunde liegenden Prinzipien und die Algorithmusauswahl der C++-Sortierfunktion
Apr 02, 2024 pm 05:36 PM
Die unterste Ebene der C++-Sortierfunktion verwendet die Zusammenführungssortierung, ihre Komplexität beträgt O(nlogn) und bietet verschiedene Auswahlmöglichkeiten für Sortieralgorithmen, einschließlich schneller Sortierung, Heap-Sortierung und stabiler Sortierung.
 Kann künstliche Intelligenz Kriminalität vorhersagen? Entdecken Sie die Möglichkeiten von CrimeGPT
Mar 22, 2024 pm 10:10 PM
Kann künstliche Intelligenz Kriminalität vorhersagen? Entdecken Sie die Möglichkeiten von CrimeGPT
Mar 22, 2024 pm 10:10 PM
Die Konvergenz von künstlicher Intelligenz (KI) und Strafverfolgung eröffnet neue Möglichkeiten zur Kriminalprävention und -aufdeckung. Die Vorhersagefähigkeiten künstlicher Intelligenz werden häufig in Systemen wie CrimeGPT (Crime Prediction Technology) genutzt, um kriminelle Aktivitäten vorherzusagen. Dieser Artikel untersucht das Potenzial künstlicher Intelligenz bei der Kriminalitätsvorhersage, ihre aktuellen Anwendungen, die Herausforderungen, denen sie gegenübersteht, und die möglichen ethischen Auswirkungen der Technologie. Künstliche Intelligenz und Kriminalitätsvorhersage: Die Grundlagen CrimeGPT verwendet Algorithmen des maschinellen Lernens, um große Datensätze zu analysieren und Muster zu identifizieren, die vorhersagen können, wo und wann Straftaten wahrscheinlich passieren. Zu diesen Datensätzen gehören historische Kriminalstatistiken, demografische Informationen, Wirtschaftsindikatoren, Wettermuster und mehr. Durch die Identifizierung von Trends, die menschliche Analysten möglicherweise übersehen, kann künstliche Intelligenz Strafverfolgungsbehörden stärken
 Verbesserter Erkennungsalgorithmus: zur Zielerkennung in hochauflösenden optischen Fernerkundungsbildern
Jun 06, 2024 pm 12:33 PM
Verbesserter Erkennungsalgorithmus: zur Zielerkennung in hochauflösenden optischen Fernerkundungsbildern
Jun 06, 2024 pm 12:33 PM
01Ausblicksübersicht Derzeit ist es schwierig, ein angemessenes Gleichgewicht zwischen Detektionseffizienz und Detektionsergebnissen zu erreichen. Wir haben einen verbesserten YOLOv5-Algorithmus zur Zielerkennung in hochauflösenden optischen Fernerkundungsbildern entwickelt, der mehrschichtige Merkmalspyramiden, Multierkennungskopfstrategien und hybride Aufmerksamkeitsmodule verwendet, um die Wirkung des Zielerkennungsnetzwerks in optischen Fernerkundungsbildern zu verbessern. Laut SIMD-Datensatz ist der mAP des neuen Algorithmus 2,2 % besser als YOLOv5 und 8,48 % besser als YOLOX, wodurch ein besseres Gleichgewicht zwischen Erkennungsergebnissen und Geschwindigkeit erreicht wird. 02 Hintergrund und Motivation Mit der rasanten Entwicklung der Fernerkundungstechnologie wurden hochauflösende optische Fernerkundungsbilder verwendet, um viele Objekte auf der Erdoberfläche zu beschreiben, darunter Flugzeuge, Autos, Gebäude usw. Objekterkennung bei der Interpretation von Fernerkundungsbildern
 Anwendung von Algorithmen beim Aufbau einer 58-Porträt-Plattform
May 09, 2024 am 09:01 AM
Anwendung von Algorithmen beim Aufbau einer 58-Porträt-Plattform
May 09, 2024 am 09:01 AM
1. Hintergrund des Baus der 58-Portrait-Plattform Zunächst möchte ich Ihnen den Hintergrund des Baus der 58-Portrait-Plattform mitteilen. 1. Das traditionelle Denken der traditionellen Profiling-Plattform reicht nicht mehr aus. Der Aufbau einer Benutzer-Profiling-Plattform basiert auf Data-Warehouse-Modellierungsfunktionen, um Daten aus mehreren Geschäftsbereichen zu integrieren, um genaue Benutzerporträts zu erstellen Und schließlich muss es über Datenplattformfunktionen verfügen, um Benutzerprofildaten effizient zu speichern, abzufragen und zu teilen sowie Profildienste bereitzustellen. Der Hauptunterschied zwischen einer selbst erstellten Business-Profiling-Plattform und einer Middle-Office-Profiling-Plattform besteht darin, dass die selbst erstellte Profiling-Plattform einen einzelnen Geschäftsbereich bedient und bei Bedarf angepasst werden kann. Die Mid-Office-Plattform bedient mehrere Geschäftsbereiche und ist komplex Modellierung und bietet allgemeinere Funktionen. 2.58 Benutzerporträts vom Hintergrund der Porträtkonstruktion im Mittelbahnsteig 58
 Fügen Sie SOTA in Echtzeit hinzu und explodieren Sie! FastOcc: Schnellere Inferenz und ein einsatzfreundlicher Occ-Algorithmus sind da!
Mar 14, 2024 pm 11:50 PM
Fügen Sie SOTA in Echtzeit hinzu und explodieren Sie! FastOcc: Schnellere Inferenz und ein einsatzfreundlicher Occ-Algorithmus sind da!
Mar 14, 2024 pm 11:50 PM
Oben geschrieben & Das persönliche Verständnis des Autors ist, dass im autonomen Fahrsystem die Wahrnehmungsaufgabe eine entscheidende Komponente des gesamten autonomen Fahrsystems ist. Das Hauptziel der Wahrnehmungsaufgabe besteht darin, autonome Fahrzeuge in die Lage zu versetzen, Umgebungselemente wie auf der Straße fahrende Fahrzeuge, Fußgänger am Straßenrand, während der Fahrt angetroffene Hindernisse, Verkehrszeichen auf der Straße usw. zu verstehen und wahrzunehmen und so flussabwärts zu helfen Module Treffen Sie richtige und vernünftige Entscheidungen und Handlungen. Ein Fahrzeug mit autonomen Fahrfähigkeiten ist in der Regel mit verschiedenen Arten von Informationserfassungssensoren ausgestattet, wie z. B. Rundumsichtkamerasensoren, Lidar-Sensoren, Millimeterwellenradarsensoren usw., um sicherzustellen, dass das autonome Fahrzeug die Umgebung genau wahrnehmen und verstehen kann Elemente, die es autonomen Fahrzeugen ermöglichen, beim autonomen Fahren die richtigen Entscheidungen zu treffen. Kopf
 Der bahnbrechende CVM-Algorithmus löst Zählprobleme aus über 40 Jahren! Informatiker wirft Münze, um einzigartiges Wort für „Hamlet' zu finden
Jun 07, 2024 pm 03:44 PM
Der bahnbrechende CVM-Algorithmus löst Zählprobleme aus über 40 Jahren! Informatiker wirft Münze, um einzigartiges Wort für „Hamlet' zu finden
Jun 07, 2024 pm 03:44 PM
Zählen klingt einfach, ist aber in der Praxis sehr schwierig. Stellen Sie sich vor, Sie werden in einen unberührten Regenwald transportiert, um eine Wildtierzählung durchzuführen. Wenn Sie ein Tier sehen, machen Sie ein Foto. Digitalkameras zeichnen nur die Gesamtzahl der verfolgten Tiere auf, Sie interessieren sich jedoch für die Anzahl der einzelnen Tiere, es gibt jedoch keine Statistiken. Wie erhält man also am besten Zugang zu dieser einzigartigen Tierpopulation? An diesem Punkt müssen Sie sagen: Beginnen Sie jetzt mit dem Zählen und vergleichen Sie schließlich jede neue Art vom Foto mit der Liste. Für Informationsmengen bis zu mehreren Milliarden Einträgen ist diese gängige Zählmethode jedoch teilweise nicht geeignet. Informatiker des Indian Statistical Institute (UNL) und der National University of Singapore haben einen neuen Algorithmus vorgeschlagen – CVM. Es kann die Berechnung verschiedener Elemente in einer langen Liste annähern.
