

Forscher der Fudan-Universität und des Noah's Ark Laboratory von Huawei haben eine iterative Lösung zur Generierung hochwertiger Videos basierend auf dem Image Diffusion Model (LDM) vorgeschlagen – VidRD (Reuse and Diffuse). Ziel dieser Lösung ist es, Durchbrüche bei der Qualität und Sequenzlänge der generierten Videos zu erzielen und eine qualitativ hochwertige, kontrollierbare Videogenerierung langer Sequenzen zu erreichen. Es reduziert effektiv das Jitter-Problem zwischen generierten Videobildern, hat einen hohen Forschungs- und Praxiswert und trägt zur aktuellen AIGC-Community bei.
Latent Diffusion Model (LDM) ist ein generatives Modell, das auf dem Denoising Autoencoder basiert und durch schrittweises Entfernen von Rauschen hochwertige Samples aus zufällig initialisierten Daten generieren kann. Aufgrund von Rechen- und Speicherbeschränkungen sowohl beim Modelltraining als auch bei der Inferenz kann ein einzelner LDM jedoch normalerweise nur eine sehr begrenzte Anzahl von Videobildern generieren. Obwohl bestehende Arbeiten versuchen, ein separates Vorhersagemodell zu verwenden, um mehr Videobilder zu generieren, verursacht dies auch zusätzliche Trainingskosten und erzeugt Jitter auf Bildebene.
In diesem Artikel wird, inspiriert vom bemerkenswerten Erfolg latenter Diffusionsmodelle (LDMs) in der Bildsynthese, ein Framework namens „Reuse and Diffuse“, kurz VidRD, vorgeschlagen. Dieses Framework kann nach der geringen Anzahl von Videobildern, die bereits von LDM generiert wurden, mehr Videobilder generieren und so iterativ längere, qualitativ hochwertigere und vielfältigere Videoinhalte generieren. VidRD lädt ein vorab trainiertes Bild-LDM-Modell für effizientes Training und nutzt ein U-Net-Netzwerk mit zusätzlichen zeitlichen Informationen zur Rauschentfernung.

Die Hauptbeiträge dieses Artikels sind wie folgt:
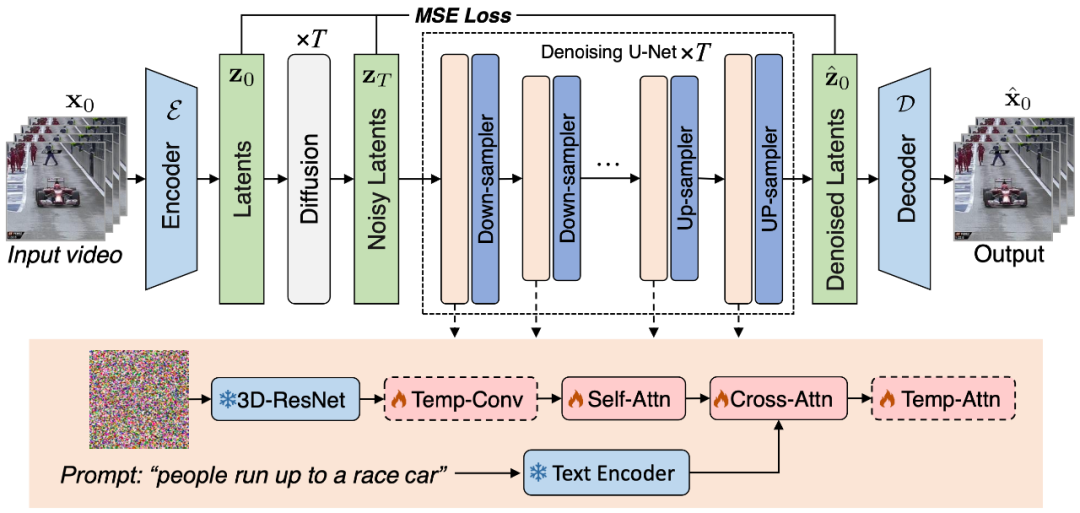
Abbildung 1. Schematische Darstellung des in diesem Artikel vorgeschlagenen VidRD-Videogenerierungsframeworks
In diesem Artikel wird davon ausgegangen, dass die Verwendung von vorab trainiertem Bild-LDM als Ausgangspunkt für das LDM-Training dient Für eine hochwertige Videosynthese ist dies eine effiziente Lösung. Wählen Sie mit Bedacht aus. Gleichzeitig wird diese Ansicht durch Forschungsarbeiten wie [1, 2] weiter gestützt. In diesem Zusammenhang basiert das sorgfältig entworfene Modell in diesem Artikel auf dem vorab trainierten stabilen Diffusionsmodell und lernt vollständig von dessen hervorragenden Eigenschaften und übernimmt diese. Dazu gehören ein Variational Autoencoder (VAE) für eine genaue latente Darstellung und ein leistungsstarkes Netzwerk zur Rauschunterdrückung U-Net. Abbildung 1 zeigt die Gesamtarchitektur des Modells klar und intuitiv.
Beim Modelldesign dieses Artikels ist die vollständige Verwendung vorab trainierter Modellgewichte ein bemerkenswertes Merkmal. Insbesondere werden die meisten Netzwerkschichten, einschließlich der Komponenten von VAE und der Upsampling- und Downsampling-Schichten von U-Net, mit vorab trainierten Gewichten des stabilen Diffusionsmodells initialisiert. Diese Strategie beschleunigt nicht nur den Modelltrainingsprozess erheblich, sondern stellt auch sicher, dass das Modell von Anfang an eine gute Stabilität und Zuverlässigkeit aufweist. Unser Modell kann iterativ zusätzliche Frames aus einem ersten Videoclip generieren, der eine kleine Anzahl von Frames enthält, indem es die ursprünglichen latenten Merkmale wiederverwendet und den vorherigen Diffusionsprozess nachahmt. Darüber hinaus fügen wir für den Autoencoder, der zur Konvertierung zwischen Pixelraum und latentem Raum verwendet wird, zeitbezogene Netzwerkschichten in seinen Decoder ein und optimieren diese Schichten, um die zeitliche Konsistenz zu verbessern.
Um die Kontinuität zwischen Videobildern sicherzustellen, fügt dieser Artikel dem Modell 3D-Temp-Conv- und Temp-Attn-Ebenen hinzu. Die Temp-conv-Schicht folgt dem 3D ResNet, das 3D-Faltungsoperationen implementiert, um räumliche und zeitliche Korrelationen zu erfassen und die Dynamik und Kontinuität der Videosequenzaggregation zu verstehen. Die Temp-Attn-Struktur ähnelt der Selbstaufmerksamkeit und wird verwendet, um die Beziehung zwischen Bildern in der Videosequenz zu analysieren und zu verstehen, sodass das Modell die laufenden Informationen zwischen Bildern genau synchronisieren kann. Diese Parameter werden während des Trainings zufällig initialisiert und sollen dem Modell das Verständnis und die Codierung der zeitlichen Struktur ermöglichen. Darüber hinaus wurde zur Anpassung an die Modellstruktur auch die Dateneingabe entsprechend angepasst und angepasst.
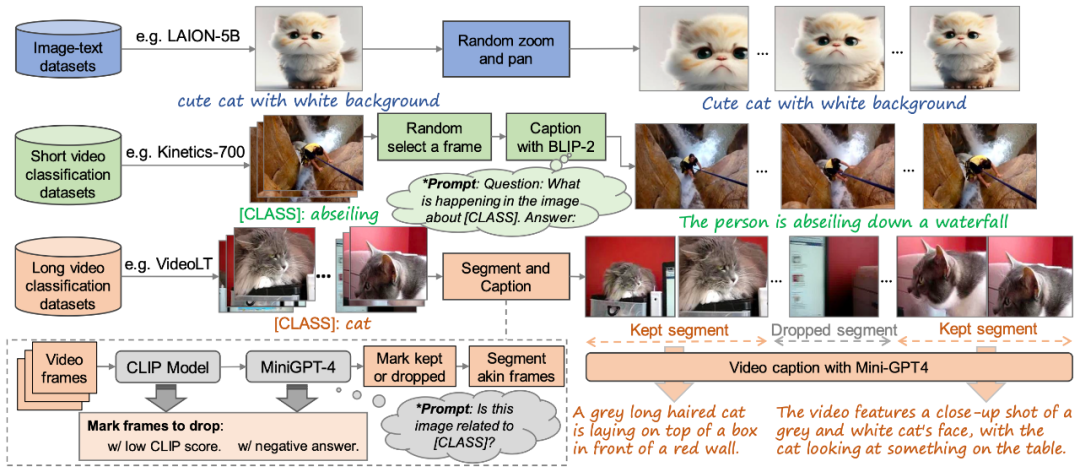
Abbildung 2. Die in diesem Artikel vorgeschlagene Methode zum Erstellen hochwertiger „Text-Video“-Trainingsdatensätze
Um das VidRD-Modell zu trainieren, schlägt dieser Artikel eine Methode zum Erstellen eines großen Skala „Text-Video“-Trainingsdatensatz Die Methode, wie in Abbildung 2 dargestellt, kann „Text-Bild“-Daten und „Text-Video“-Daten ohne Beschreibung verarbeiten. Um eine qualitativ hochwertige Videogenerierung zu erreichen, wird in diesem Artikel außerdem versucht, Wasserzeichen in den Trainingsdaten zu entfernen.
Obwohl hochwertige Videobeschreibungsdatensätze auf dem aktuellen Markt relativ selten sind, gibt es eine große Anzahl von Videoklassifizierungsdatensätzen. Diese Datensätze verfügen über umfangreiche Videoinhalte und jedes Video wird von einer Klassifizierungsbezeichnung begleitet. Moments-In-Time, Kinetics-700 und VideoLT sind beispielsweise drei repräsentative umfangreiche Videoklassifizierungsdatensätze. Kinetics-700 deckt 700 Kategorien menschlicher Handlungen ab und enthält über 600.000 Videoclips. Moments-In-Time umfasst 339 Action-Kategorien mit insgesamt mehr als einer Million Videoclips. VideoLT hingegen enthält 1.004 Kategorien und 250.000 lange, unbearbeitete Videos.
Um die vorhandenen Videodaten voll auszunutzen, wird in diesem Artikel versucht, diese Videos automatisch detaillierter zu kommentieren. Dieser Artikel verwendet multimodale große Sprachmodelle wie BLIP-2 und MiniGPT4, indem er auf Schlüsselbilder im Video abzielt und deren ursprüngliche Klassifizierungsbezeichnungen kombiniert. Dieser Artikel entwirft viele Eingabeaufforderungen zum Generieren von Anmerkungen durch Modellfragen und -antworten. Diese Methode verbessert nicht nur die Sprachinformationen von Videodaten, sondern fügt auch umfassendere und detailliertere Videobeschreibungen zu vorhandenen Videos ohne detaillierte Beschreibungen hinzu und ermöglicht so eine umfangreichere Video-Tag-Generierung, um dem VidRD-Modell zu einem besseren Trainingseffekt zu verhelfen.
Darüber hinaus wurde in diesem Artikel für die vorhandenen, sehr umfangreichen Bilddaten auch eine detaillierte Methode zum Konvertieren der Bilddaten in ein Videoformat für das Training entwickelt. Der spezifische Vorgang besteht darin, an verschiedenen Positionen des Bildes mit unterschiedlicher Geschwindigkeit zu schwenken und zu zoomen, wodurch jedem Bild eine einzigartige dynamische Präsentationsform verliehen wird und der Effekt der Bewegung einer Kamera simuliert wird, um Standbilder im wirklichen Leben aufzunehmen. Durch diese Methode können vorhandene Bilddaten effektiv für das Videotraining genutzt werden.
Die Beschreibungstexte lauten: „Zeitraffer im Schneeland mit Polarlicht am Himmel“, „Eine Kerze brennt“, „Ein epischer Tornado, der nachts über einer leuchtenden Stadt angreift.“ und „Luftaufnahme eines weißen Sandstrandes am Ufer eines wunderschönen Meeres.“ Weitere Visualisierungen finden Sie auf der Projekthomepage.

Abbildung 3. Visueller Vergleich des Generierungseffekts mit bestehenden Methoden
Abschließend werden, wie in Abbildung 3 gezeigt, die Generierungsergebnisse dieses Artikels mit den bestehenden Methoden Make-A-Video verglichen [3 ] und Der visuelle Vergleich von Imagen Video [4] zeigt den besseren Qualitätsgenerierungseffekt des Modells in diesem Artikel.
Das obige ist der detaillierte Inhalt vonDie Fudan-Universität und Huawei Noah schlagen das VidRD-Framework vor, um eine iterative Erzeugung hochwertiger Videos zu erreichen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 So binden Sie Daten in einer Dropdown-Liste
So binden Sie Daten in einer Dropdown-Liste
 Methode zum Festlegen des HTML-Bereichs
Methode zum Festlegen des HTML-Bereichs
 So öffnen Sie eine PHP-Datei
So öffnen Sie eine PHP-Datei
 So verwenden Sie JS-Code
So verwenden Sie JS-Code
 Abfragetool für Registrierungsdomänennamen
Abfragetool für Registrierungsdomänennamen
 Können Douyin-Funken wieder entzündet werden, wenn sie länger als drei Tage ausgeschaltet waren?
Können Douyin-Funken wieder entzündet werden, wenn sie länger als drei Tage ausgeschaltet waren?
 Der Unterschied zwischen Java und Java
Der Unterschied zwischen Java und Java
 Der Unterschied zwischen PHP und JS
Der Unterschied zwischen PHP und JS








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



