
 Technologie-Peripheriegeräte
KI
Lange Texte können mit einer Fensterlänge von 4 KB gelesen werden. Chen Danqi und seine Schüler haben gemeinsam mit Meta eine neue Methode zur Verbesserung des Gedächtnisses großer Modelle eingeführt.
Technologie-Peripheriegeräte
KI
Lange Texte können mit einer Fensterlänge von 4 KB gelesen werden. Chen Danqi und seine Schüler haben gemeinsam mit Meta eine neue Methode zur Verbesserung des Gedächtnisses großer Modelle eingeführt.
Lange Texte können mit einer Fensterlänge von 4 KB gelesen werden. Chen Danqi und seine Schüler haben gemeinsam mit Meta eine neue Methode zur Verbesserung des Gedächtnisses großer Modelle eingeführt.

Ein großes Modell mit nur 4k Fensterlänge kann immer noch große Textabschnitte lesen!
Eine neueste Errungenschaft eines chinesischen Doktoranden in Princeton „durchbricht“ erfolgreich die Grenze der Fensterlänge großer Modelle.
Es kann nicht nur verschiedene Fragen beantworten, sondern der gesamte Implementierungsprozess kann vollständig und zeitnah und ohne zusätzliche Schulung abgeschlossen werden.

Das Forschungsteam hat eine Baumspeicherstrategie namens MemWalker entwickelt, die die Fensterlängenbeschränkung des Modells selbst durchbrechen kann.
Während des Tests enthielt der längste vom Modell gelesene Text mehr als 12.000 Token und die Ergebnisse waren im Vergleich zu LongChat deutlich verbessert.
Im Vergleich zum ähnlichen TreeIndex kann MemWalker jede Frage begründen und beantworten, anstatt nur Verallgemeinerungen vorzunehmen.
MemWalker wurde nach dem Prinzip „Teile und herrsche“ entwickelt. Einige Internetnutzer kommentierten:
Jedes Mal, wenn wir den Denkprozess großer Modelle menschlicher gestalten, wird ihre Leistung besser sein

Also , Was genau ist die Baumspeicherstrategie und wie liest man langen Text mit einer begrenzten Fensterlänge?
Wenn ein Fenster nicht ausreicht, öffnen Sie einfach ein paar mehr
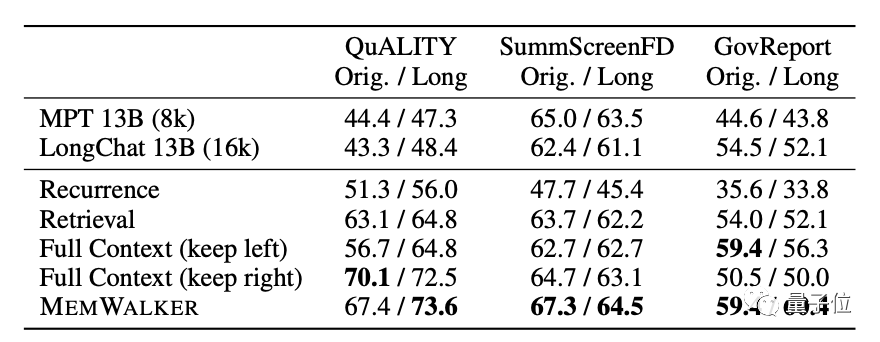
Auf dem Modell verwendet MemWalker Stable Beluga 2 als Basismodell, das von Llama 2-70B nach der Befehlsabstimmung erhalten wird.
Bevor die Entwickler sich für dieses Modell entschieden, verglichen sie dessen Leistung mit der des ursprünglichen Llama 2 und entschieden sich schließlich dafür.
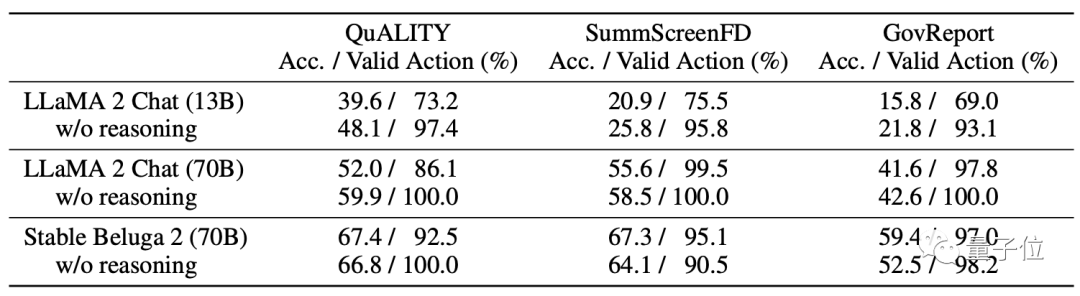
Genau wie der Name MemWalker ist sein Arbeitsprozess wie ein wandelnder Gedächtnisstrom.
Im Einzelnen ist es grob in zwei Phasen unterteilt: Speicherbaumaufbau und Navigationsabruf.
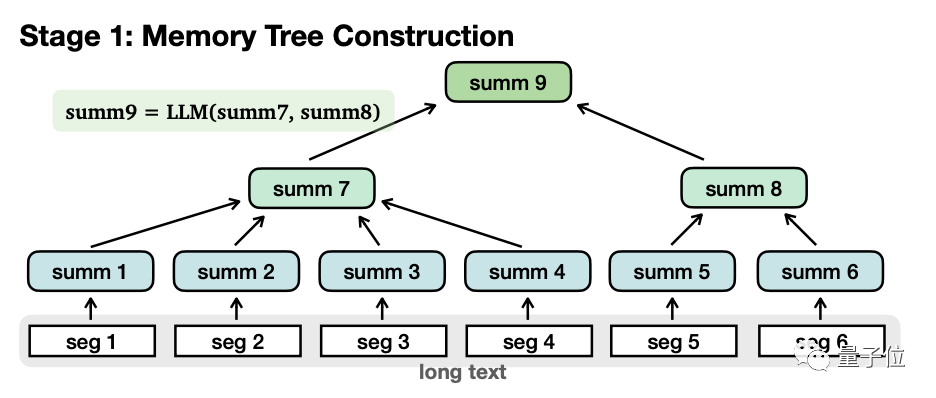
Beim Erstellen eines Speicherbaums wird der Langtext in mehrere kleine Segmente (Seg1-6) unterteilt, und das große Modell fasst jedes Segment separat zusammen und erhält „Blattknoten“ (Blattknoten, Summe1-6).
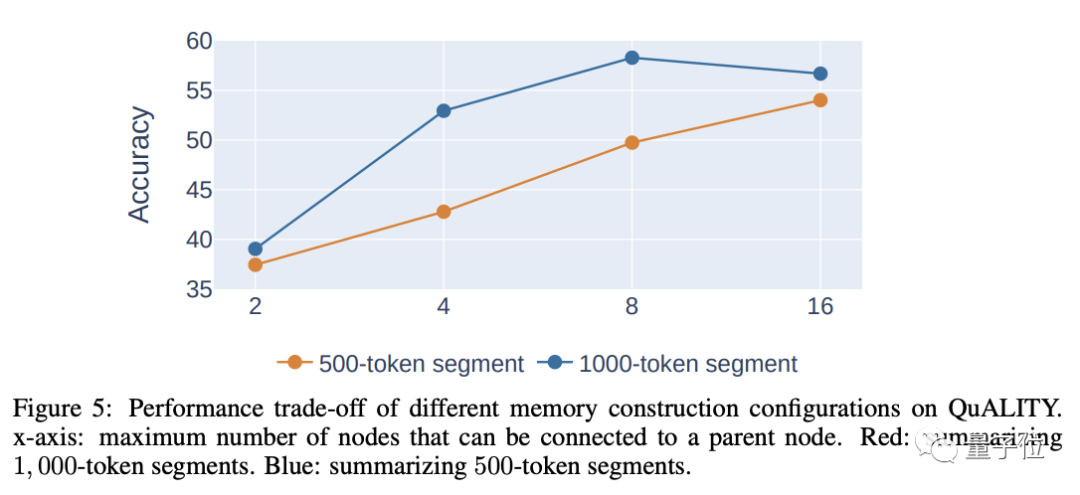
Beim Segmentieren gilt: Je länger jedes Segment ist, desto weniger Ebenen sind vorhanden, was sich positiv auf den späteren Abruf auswirkt. Allerdings führt eine zu lange Länge selbst zu einer Verringerung der Genauigkeit, sodass umfassende Überlegungen zur Bestimmung der Länge erforderlich sind jedes Segments.
Der Autor geht davon aus, dass die angemessene Länge jedes Absatzes 500-2000 Token beträgt und die im Experiment verwendete Länge 1000 Token beträgt.
Dann fasst das Modell den Inhalt dieser Blattknoten erneut rekursiv zusammen, um „Nicht-Blattknoten“(Nicht-Blattknoten, summ7-8) zu bilden.
Ein weiterer Unterschied zwischen den beiden besteht darin, dass Blattknoten Originalinformationen enthalten, während Nicht-Blattknoten nur Sekundärinformationen enthalten, die durch zusammengefasst werden.
In Bezug auf die Funktion werden Nicht-Blattknoten zum Navigieren und Lokalisieren der Blattknoten verwendet, in denen sich die Antwort befindet, während die Blattknoten zum Nachdenken über die Antwort verwendet werden.
Die Nicht-Blattknoten können mehrere Ebenen haben, und das Modell wird schrittweise zusammengefasst, bis der „Wurzelknoten“ erhalten wird, um eine vollständige Baumstruktur zu bilden.
Nachdem der Speicherbaum erstellt wurde, können Sie in die Navigationsabrufphase eintreten, um Antworten zu generieren.
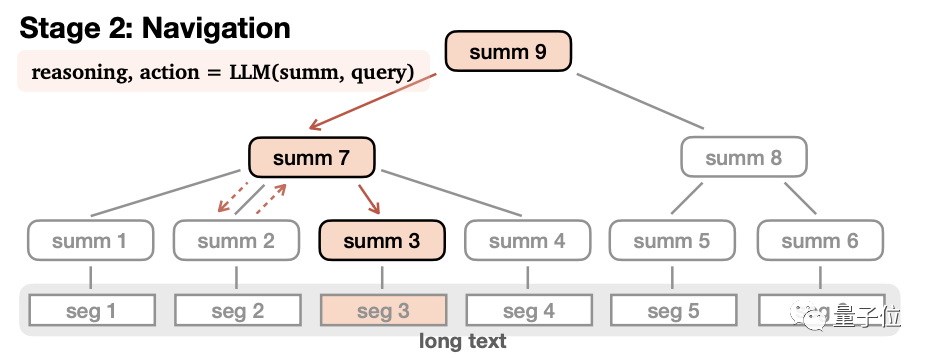
In diesem Prozess beginnt das Modell am Wurzelknoten, liest nacheinander den Inhalt der Unterknoten der ersten Ebene und leitet dann ab, ob dieser Knoten betreten oder zurückgegeben werden soll.
Nachdem Sie sich entschieden haben, diesen Knoten einzugeben, wiederholen Sie den Vorgang erneut, bis der Blattknoten gelesen ist. Wenn der Inhalt des Blattknotens geeignet ist, wird die Antwort generiert, andernfalls wird sie zurückgegeben. Um die Vollständigkeit der Antwort sicherzustellen, besteht die Endbedingung dieses Prozesses nicht darin, dass ein geeigneter Blattknoten gefunden wird, sondern dass das Modell davon ausgeht, dass eine vollständige Antwort erhalten wird oder die maximale Anzahl von Schritten erreicht wird. Wenn das Modell während des Navigationsvorgangs feststellt, dass es den falschen Pfad eingegeben hat, kann es auch zurück navigieren.Darüber hinaus führt MemWalker auch einen Arbeitsspeichermechanismus ein, um die Genauigkeit zu verbessern.
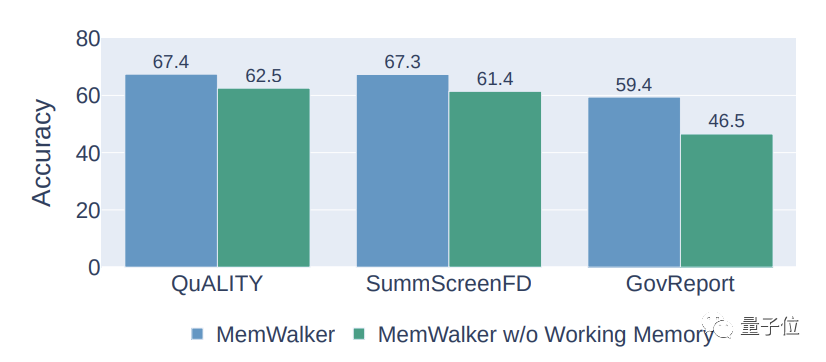
Dieser Mechanismus fügt den Inhalt des besuchten Knotens dem Kontext des aktuellen Inhalts hinzu.
Wenn das Modell einen neuen Knoten betritt, wird der aktuelle Knoteninhalt dem Speicher hinzugefügt.
Dieser Mechanismus ermöglicht es dem Modell, bei jedem Schritt den Inhalt der besuchten Knoten zu nutzen, um den Verlust wichtiger Informationen zu vermeiden.
Experimentelle Ergebnisse zeigen, dass der Arbeitsgedächtnismechanismus die Genauigkeit von MemWalker um etwa 10 % steigern kann.
Darüber hinaus kann der oben genannte Prozess nur abgeschlossen werden, indem man sich auf Eingabeaufforderungen verlässt, und es ist keine zusätzliche Schulung erforderlich.

Theoretisch kann MemWalker unendlich lange Texte lesen, solange er über genügend Rechenleistung verfügt.
Allerdings nimmt die zeitliche und räumliche Komplexität der Speicherbaumkonstruktion mit zunehmender Textlänge exponentiell zu.
Über den Autor
Der Erstautor des Artikels ist Howard Chen, ein chinesischer Doktorand am NLP-Labor der Princeton University.
Die Absolventin der Tsinghua Yao-Klasse, Chen Danqi, ist Howards Mentorin, und ihr akademischer Bericht über ACL in diesem Jahr bezog sich auch auf die Suche.
Dieses Ergebnis wurde von Howard während seines Praktikums bei Meta Ramakanth Pasunuru vervollständigt. Jason Weston und Asli Celikyilmaz, drei Wissenschaftler des Meta AI Laboratory, nahmen ebenfalls an diesem Projekt teil.
Papieradresse: https://arxiv.org/abs/2310.05029
Das obige ist der detaillierte Inhalt vonLange Texte können mit einer Fensterlänge von 4 KB gelesen werden. Chen Danqi und seine Schüler haben gemeinsam mit Meta eine neue Methode zur Verbesserung des Gedächtnisses großer Modelle eingeführt.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1379
1379
 52
52

 Debian Mail Server Firewall -Konfigurationstipps
Apr 13, 2025 am 11:42 AM
Debian Mail Server Firewall -Konfigurationstipps
Apr 13, 2025 am 11:42 AM
Das Konfigurieren der Firewall eines Debian -Mailservers ist ein wichtiger Schritt zur Gewährleistung der Serversicherheit. Im Folgenden sind mehrere häufig verwendete Firewall -Konfigurationsmethoden, einschließlich der Verwendung von Iptables und Firewalld. Verwenden Sie Iptables, um Firewall so zu konfigurieren, dass Iptables (falls bereits installiert) installiert werden:
 So setzen Sie die Debian Apache -Protokollebene fest
Apr 13, 2025 am 08:33 AM
So setzen Sie die Debian Apache -Protokollebene fest
Apr 13, 2025 am 08:33 AM
In diesem Artikel wird beschrieben, wie Sie die Protokollierungsstufe des Apacheweb -Servers im Debian -System anpassen. Durch Ändern der Konfigurationsdatei können Sie die ausführliche Ebene der von Apache aufgezeichneten Protokollinformationen steuern. Methode 1: Ändern Sie die Hauptkonfigurationsdatei, um die Konfigurationsdatei zu finden: Die Konfigurationsdatei von Apache2.x befindet sich normalerweise im Verzeichnis/etc/apache2/. Der Dateiname kann je nach Installationsmethode Apache2.conf oder httpd.conf sein. Konfigurationsdatei bearbeiten: Öffnen Sie die Konfigurationsdatei mit Stammberechtigungen mit einem Texteditor (z. B. Nano): Sudonano/etc/apache2/apache2.conf
 Wie Debian Readdir sich in andere Tools integriert
Apr 13, 2025 am 09:42 AM
Wie Debian Readdir sich in andere Tools integriert
Apr 13, 2025 am 09:42 AM
Die Readdir -Funktion im Debian -System ist ein Systemaufruf, der zum Lesen des Verzeichnisgehalts verwendet wird und häufig in der C -Programmierung verwendet wird. In diesem Artikel wird erläutert, wie Readdir in andere Tools integriert wird, um seine Funktionalität zu verbessern. Methode 1: Kombinieren Sie C -Sprachprogramm und Pipeline zuerst ein C -Programm, um die Funktion der Readdir aufzurufen und das Ergebnis auszugeben:#include#include#includeIntmain (intargc, char*argv []) {Dir*Dir; structDirent*Eintrag; if (argc! = 2) {{
 So optimieren Sie die Leistung von Debian Readdir
Apr 13, 2025 am 08:48 AM
So optimieren Sie die Leistung von Debian Readdir
Apr 13, 2025 am 08:48 AM
In Debian -Systemen werden Readdir -Systemaufrufe zum Lesen des Verzeichnisinhalts verwendet. Wenn seine Leistung nicht gut ist, probieren Sie die folgende Optimierungsstrategie aus: Vereinfachen Sie die Anzahl der Verzeichnisdateien: Teilen Sie große Verzeichnisse so weit wie möglich in mehrere kleine Verzeichnisse auf und reduzieren Sie die Anzahl der gemäß Readdir -Anrufe verarbeiteten Elemente. Aktivieren Sie den Verzeichnis -Inhalt Caching: Erstellen Sie einen Cache -Mechanismus, aktualisieren Sie den Cache regelmäßig oder bei Änderungen des Verzeichnisinhalts und reduzieren Sie häufige Aufrufe an Readdir. Speicher -Caches (wie Memcached oder Redis) oder lokale Caches (wie Dateien oder Datenbanken) können berücksichtigt werden. Nehmen Sie eine effiziente Datenstruktur an: Wenn Sie das Verzeichnis -Traversal selbst implementieren, wählen Sie effizientere Datenstrukturen (z.
 So implementieren Sie die Dateisortierung nach Debian Readdir
Apr 13, 2025 am 09:06 AM
So implementieren Sie die Dateisortierung nach Debian Readdir
Apr 13, 2025 am 09:06 AM
In Debian -Systemen wird die Readdir -Funktion zum Lesen des Verzeichnisinhalts verwendet, aber die Reihenfolge, in der sie zurückgibt, ist nicht vordefiniert. Um Dateien in einem Verzeichnis zu sortieren, müssen Sie zuerst alle Dateien lesen und dann mit der QSORT -Funktion sortieren. Der folgende Code zeigt, wie Verzeichnisdateien mithilfe von Readdir und QSORT in Debian System sortiert werden:#include#include#include#include // benutzerdefinierte Vergleichsfunktion, verwendet für QSortIntCompare (constvoid*a, constvoid*b) {rettrcmp (*(*(*(
 Debian Mail Server SSL -Zertifikat -Installationsmethode
Apr 13, 2025 am 11:39 AM
Debian Mail Server SSL -Zertifikat -Installationsmethode
Apr 13, 2025 am 11:39 AM
Die Schritte zur Installation eines SSL -Zertifikats auf dem Debian Mail -Server sind wie folgt: 1. Installieren Sie zuerst das OpenSSL -Toolkit und stellen Sie sicher, dass das OpenSSL -Toolkit bereits in Ihrem System installiert ist. Wenn nicht installiert, können Sie den folgenden Befehl installieren: sudoapt-getupdatesudoapt-getinstallopenssl2. Generieren Sie den privaten Schlüssel und die Zertifikatanforderung als nächst
 So führen Sie die digitale Signaturüberprüfung mit Debian OpenSSL durch
Apr 13, 2025 am 11:09 AM
So führen Sie die digitale Signaturüberprüfung mit Debian OpenSSL durch
Apr 13, 2025 am 11:09 AM
Unter Verwendung von OpenSSL für die digitale Signaturüberprüfung im Debian -System können Sie folgende Schritte befolgen: Vorbereitung für die Installation von OpenSSL: Stellen Sie sicher, dass Ihr Debian -System OpenSSL installiert hat. Wenn nicht installiert, können Sie den folgenden Befehl verwenden, um es zu installieren: sudoaptupdatesudoaptininTallopenSSL, um den öffentlichen Schlüssel zu erhalten: Die digitale Signaturüberprüfung erfordert den öffentlichen Schlüssel des Unterzeichners. In der Regel wird der öffentliche Schlüssel in Form einer Datei wie Public_key.pe bereitgestellt
 Wie Debian OpenSSL verhindert, dass Mann-in-the-Middle-Angriffe
Apr 13, 2025 am 10:30 AM
Wie Debian OpenSSL verhindert, dass Mann-in-the-Middle-Angriffe
Apr 13, 2025 am 10:30 AM
In Debian Systems ist OpenSSL eine wichtige Bibliothek für Verschlüsselung, Entschlüsselung und Zertifikatverwaltung. Um einen Mann-in-the-Middle-Angriff (MITM) zu verhindern, können folgende Maßnahmen ergriffen werden: Verwenden Sie HTTPS: Stellen Sie sicher, dass alle Netzwerkanforderungen das HTTPS-Protokoll anstelle von HTTP verwenden. HTTPS verwendet TLS (Transport Layer Security Protocol), um Kommunikationsdaten zu verschlüsseln, um sicherzustellen, dass die Daten während der Übertragung nicht gestohlen oder manipuliert werden. Überprüfen Sie das Serverzertifikat: Überprüfen Sie das Serverzertifikat im Client manuell, um sicherzustellen, dass es vertrauenswürdig ist. Der Server kann manuell durch die Delegate -Methode der URLSession überprüft werden
