
 Technologie-Peripheriegeräte
KI
LeCun hat das autoregressive LLM erneut schlecht geredet: Die Argumentationsfähigkeit von GPT-4 ist sehr begrenzt, wie aus zwei Artikeln hervorgeht
Technologie-Peripheriegeräte
KI
LeCun hat das autoregressive LLM erneut schlecht geredet: Die Argumentationsfähigkeit von GPT-4 ist sehr begrenzt, wie aus zwei Artikeln hervorgeht
LeCun hat das autoregressive LLM erneut schlecht geredet: Die Argumentationsfähigkeit von GPT-4 ist sehr begrenzt, wie aus zwei Artikeln hervorgeht

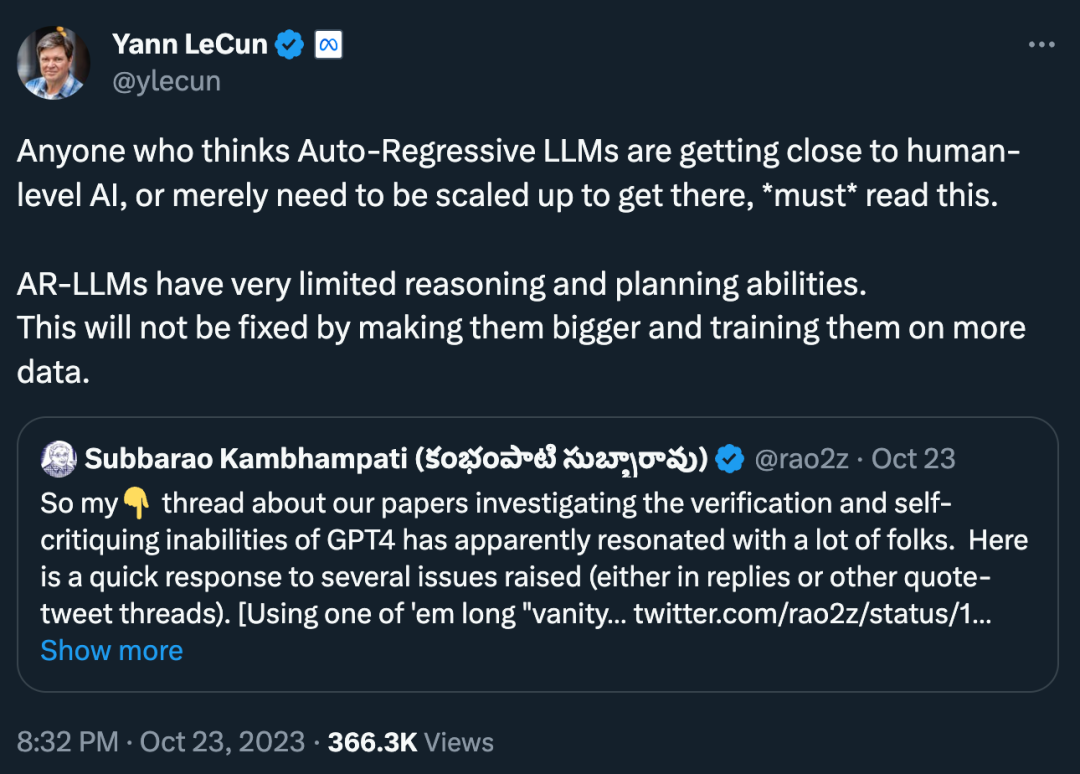
„Jeder, der denkt, dass autoregressives LLM der KI auf menschlicher Ebene bereits nahe kommt oder nur skaliert werden muss, um KI auf menschlicher Ebene zu erreichen, muss dies lesen. AR-LLM verfügt über sehr begrenzte Argumentations- und Planungsfähigkeiten. Um dieses Problem zu lösen, kann man sie nicht dadurch lösen, dass man sie vergrößert und mit mehr Daten trainiert. „
Der Turing-Award-Gewinner Yann LeCun ist seit langem ein „Fragesteller“ von LLM, und das autoregressive Modell ist es auch . Das Lernparadigma, auf dem das LLM-Modell der GPT-Serie basiert. Er hat seine Kritik an autoregressiven und LLM mehr als einmal öffentlich geäußert und viele goldene Sätze hervorgebracht, wie zum Beispiel:
„Niemand, der bei klarem Verstand ist, wird in 5 Jahren autoregressive Modelle verwenden.“ „Autoregressive generative Modelle sind scheiße!“ Kann LLM seine Lösungen wirklich selbst kritisieren (und iterativ verbessern), wie es die Literatur vorschlägt? Zwei neue Arbeiten aus unserer Gruppe sind Reasoning (https://arxiv.org/abs/2310.12397) und Planning (https://arxiv.org/). abs/2310.08118) Diese Behauptungen wurden untersucht (und in Frage gestellt)“
Das Thema dieses Papiers, das die Verifizierungs- und Selbstkritikfähigkeiten von GPT-4 untersucht, findet bei vielen Menschen Anklang.
Die Autoren des Papiers gaben an, dass sie auch glauben, dass LLM ein großartiger „Ideengenerator“ ist (sei es in Sprachform oder Codeform), sie können jedoch ihre eigenen Planungs-/Denkfähigkeiten nicht garantieren. Daher werden sie am besten in einer LLM-Modulo-Umgebung verwendet (entweder mit einem zuverlässigen Denker oder einem menschlichen Experten auf dem Laufenden). Selbstkritik erfordert Überprüfung, und Überprüfung ist eine Form des Denkens (seien Sie also überrascht von all den Behauptungen über die Fähigkeit von LLM, sich selbst zu kritisieren).
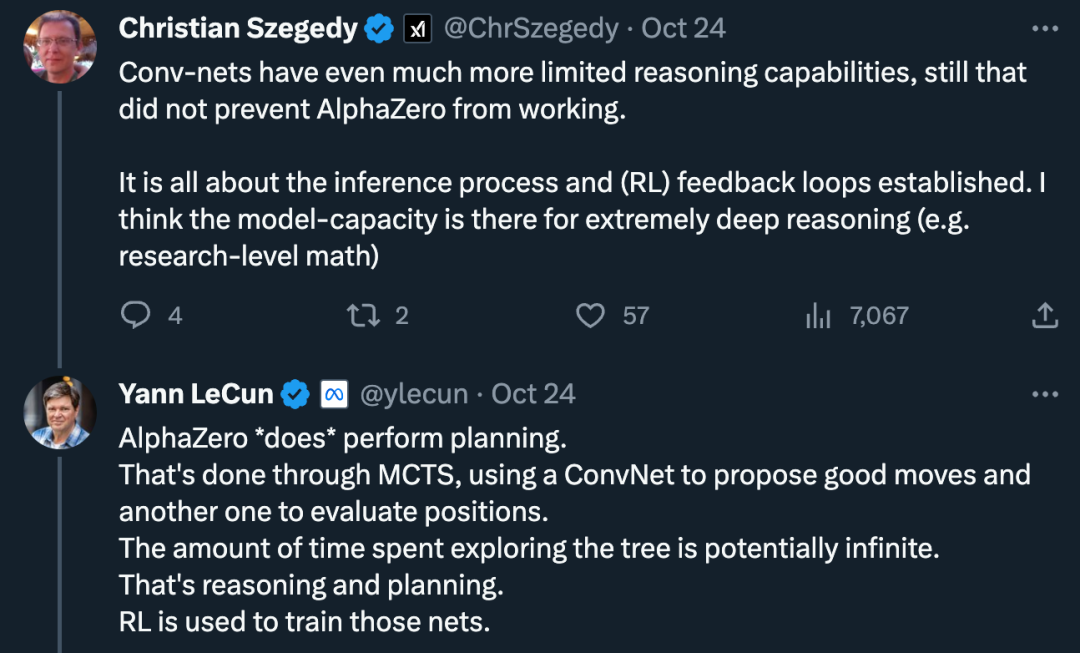
Gleichzeitig gibt es auch Stimmen des Zweifels: „Die Argumentationsfähigkeiten von Faltungsnetzwerken sind eingeschränkter, aber das hindert die Arbeit von AlphaZero nicht daran, aufzutauchen. Es geht um den Argumentationsprozess und die etablierten ( RL) Feedback-Schleife. Ich denke, dass die Modellfähigkeiten ein extrem tiefgründiges Denken ermöglichen (z. B. Mathematik auf Forschungsniveau). Dies erfolgt über eine Monte-Carlo-Baumsuche, wobei ein Faltungsnetzwerk zum Ermitteln guter Aktionen und ein weiteres Faltungsnetzwerk zur Bewertung der Position verwendet wird. Die Zeit, die Sie damit verbringen, den Baum zu erkunden, könnte unendlich sein, das ist alles Denken und Planen. „
 In Zukunft wird die Frage, ob autoregressives LLM über Argumentations- und Planungsfähigkeiten verfügt, möglicherweise nicht abschließend geklärt.
In Zukunft wird die Frage, ob autoregressives LLM über Argumentations- und Planungsfähigkeiten verfügt, möglicherweise nicht abschließend geklärt.
Als nächstes können wir einen Blick darauf werfen, worüber diese beiden neuen Papiere sprechen.
Aufsatz 1: GPT-4 weiß nicht, dass es falsch ist: Eine Analyse iterativer Eingabeaufforderungen für Argumentationsprobleme Kunst LLM, einschließlich GPT-4.
Adresse des Beitrags: https://arxiv.org/pdf/2310.12397.pdf
Über die Inferenzfähigkeiten großer Sprachmodelle (LLMs) gab es immer erhebliche Meinungsverschiedenheiten. Anfangs waren die Forscher optimistisch, dass die Inferenzfähigkeiten von LLMs mit zunehmender Modellskala automatisch auftreten würden In einigen Fällen sind die Erwartungen der Menschen nicht mehr so stark ausgeprägt. Danach glaubten Forscher allgemein, dass LLM die Fähigkeit besitzt, LLM-Lösungen auf iterative Weise selbst zu kritisieren und zu verbessern, und diese Ansicht wurde weit verbreitet.
Aber ist das wirklich so?
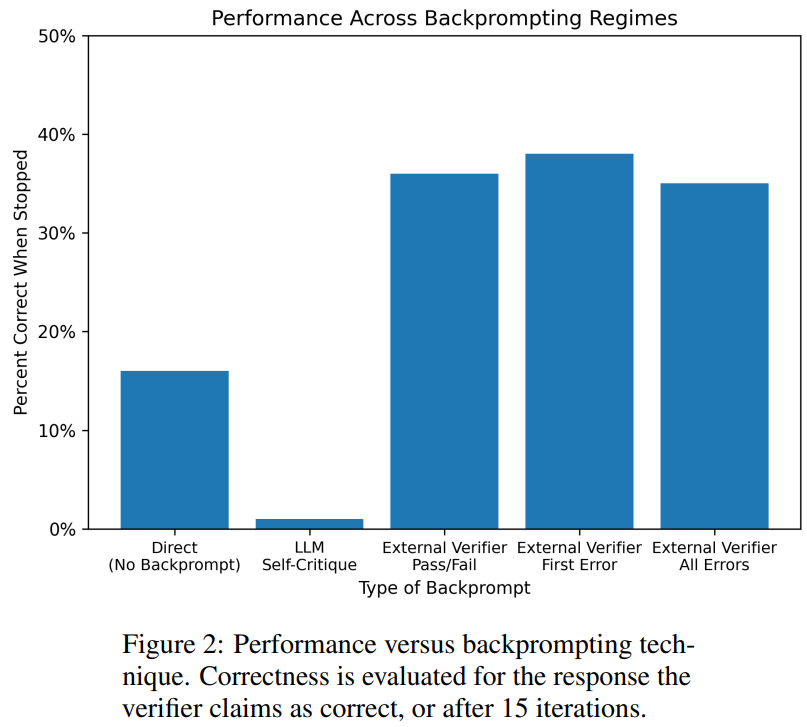
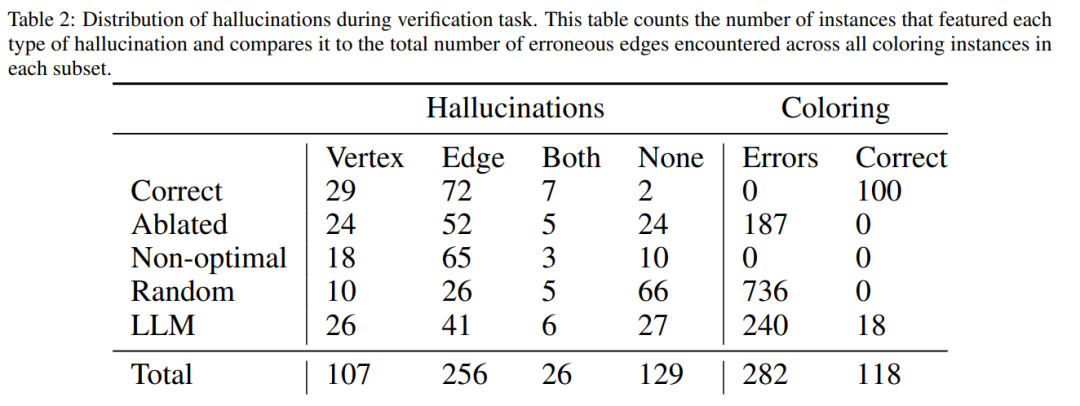
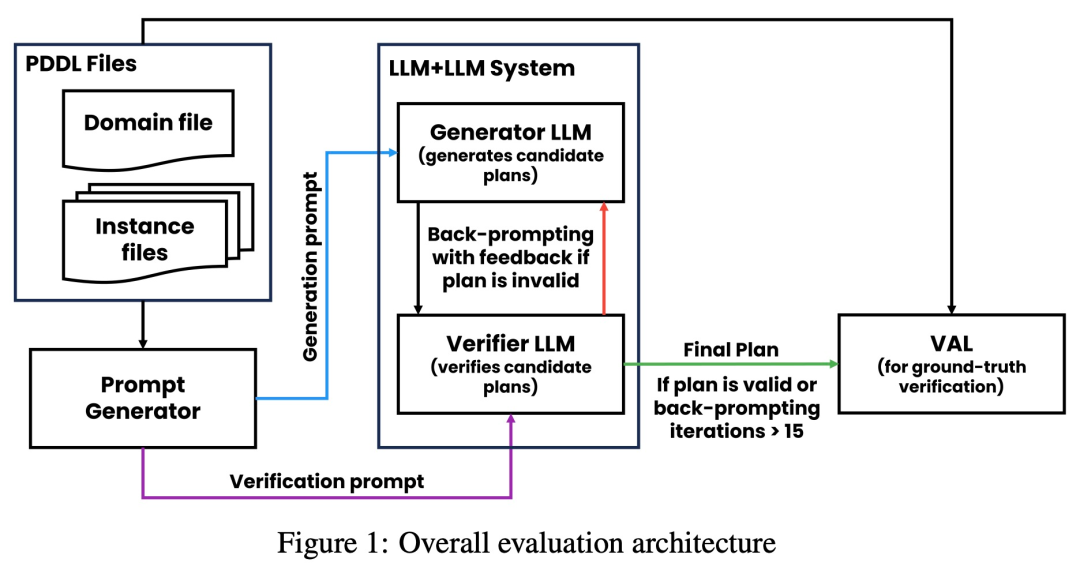
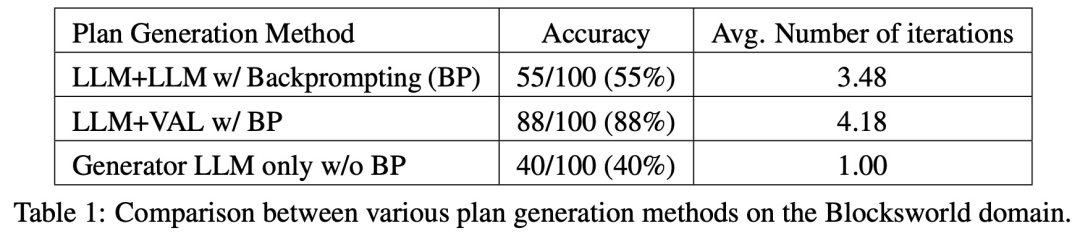
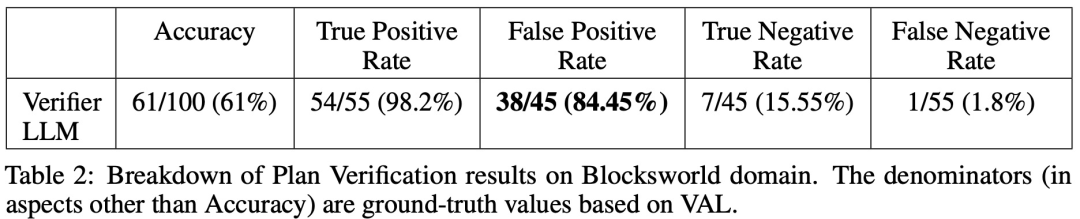
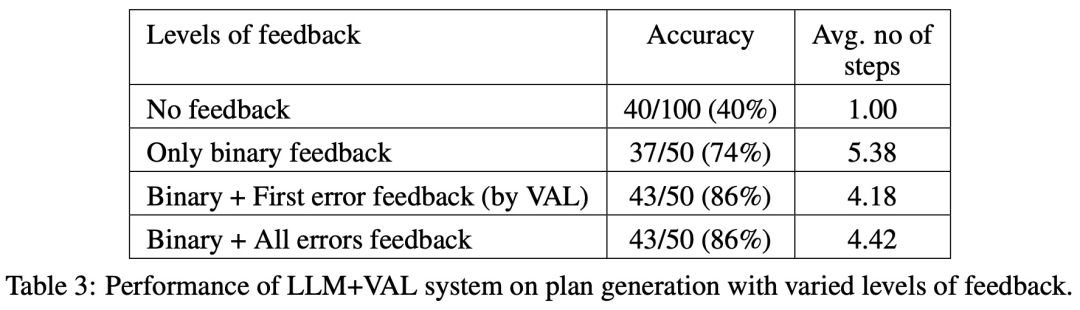
Forscher der Arizona State University haben in einer neuen Studie die Argumentationsfähigkeiten von LLM getestet. Insbesondere konzentrierten sie sich auf die Wirksamkeit der iterativen Eingabeaufforderung beim Diagrammfärbungsproblem, einem der bekanntesten NP-vollständigen Probleme. Diese Studie zeigt, dass (i) LLM nicht gut darin ist, Graphfärbungsinstanzen zu lösen, (ii) LLM nicht gut darin ist, Lösungen zu validieren und daher im iterativen Modus ineffektiv ist. Die Ergebnisse dieser Arbeit werfen daher Fragen über die selbstkritischen Fähigkeiten moderner LLMs auf. Das Papier liefert einige experimentelle Ergebnisse, zum Beispiel ist LLM im direkten Modus sehr schlecht darin, Diagrammfärbungsinstanzen zu lösen. Darüber hinaus stellte die Studie auch fest, dass LLM die Lösung nicht gut verifizieren kann. Schlimmer noch: Das System erkennt nicht die richtige Farbe und erhält am Ende die falsche Farbe. Die folgende Abbildung ist eine Bewertung des Diagrammkolorierungsproblems. In dieser Einstellung kann GPT-4 Farben in einem unabhängigen und selbstkritischen Modus erraten. Außerhalb der selbstkritischen Schleife gibt es einen externen Sprachvalidator. Die Ergebnisse zeigen, dass GPT4 beim Erraten von Farben weniger als 20 % genau ist, und noch überraschender ist, dass der Selbstkritikmodus (zweite Spalte in der Abbildung unten) die niedrigste Genauigkeit aufweist. In diesem Artikel wird auch die damit verbundene Frage untersucht, ob GPT-4 seine Lösung verbessern würde, wenn ein externer Stimmverifizierer nachweislich korrekte Kritiken zu den von ihm vermuteten Farben liefern würde. In diesem Fall kann Reverse Hinting die Leistung wirklich verbessern. Selbst wenn GPT-4 versehentlich eine gültige Farbe errät, kann seine Selbstkritik dazu führen, dass es halluziniert, dass kein Verstoß vorliegt. Abschließend gibt der Autor eine Zusammenfassung zum Problem der Diagrammfärbung: Aufsatz 2: Können sich große Sprachmodelle wirklich verbessern, indem sie ihre eigenen Pläne selbst kritisieren? Team Die Fähigkeit von LLM, sich in Planungssituationen selbst zu überprüfen/zu kritisieren, wurde untersucht. Dieses Papier bietet eine systematische Untersuchung der Fähigkeit von LLMs, ihre eigenen Ergebnisse zu kritisieren, insbesondere im Kontext klassischer Planungsprobleme. Während die jüngste Forschung hinsichtlich des selbstkritischen Potenzials von LLMs, insbesondere in iterativen Kontexten, optimistisch war, schlägt diese Studie eine andere Perspektive vor. Papieradresse: https://arxiv.org/abs/2310.08118 Überraschenderweise zeigen die Forschungsergebnisse, dass Selbstkritik die Leistung der Plangenerierung verringern kann, insbesondere bei externer Validierung Verifier und LLM Prüfsysteme. LLM kann eine große Anzahl von Fehlermeldungen erzeugen und dadurch die Zuverlässigkeit des Systems beeinträchtigen. Die empirische Auswertung der Forscher zum klassischen KI-Planungsbereich Blocksworld zeigt, dass die Selbstkritikfunktion von LLM bei Planungsproblemen nicht effektiv ist. Der Validator kann eine große Anzahl von Fehlern erzeugen, was sich nachteilig auf die Zuverlässigkeit des gesamten Systems auswirkt, insbesondere in Bereichen, in denen die Korrektheit der Planung von entscheidender Bedeutung ist. Interessanterweise hat die Art des Feedbacks (binäres oder detailliertes Feedback) keinen wesentlichen Einfluss auf die Leistung der Plangenerierung, was darauf hindeutet, dass das Kernproblem eher in den binären Verifizierungsfunktionen von LLM als in der Granularität des Feedbacks liegt. Wie in der folgenden Abbildung dargestellt, umfasst die Bewertungsarchitektur dieser Studie zwei LLMs – Generator-LLM + Verifizierer-LLM. Für einen bestimmten Fall ist der Generator-LLM für die Generierung der Kandidatenpläne verantwortlich, während der Verifizierer-LLM deren Richtigkeit bestimmt. Wenn sich herausstellt, dass der Plan falsch ist, gibt der Validator eine Rückmeldung mit der Begründung des Fehlers. Dieses Feedback wird dann an den Generator-LLM übertragen, der den Generator-LLM dazu veranlasst, neue Kandidatenpläne zu generieren. Alle Experimente in dieser Studie verwendeten GPT-4 als Standard-LLM. Diese Studie experimentiert und vergleicht verschiedene Methoden zur Planerstellung auf Blocksworld. Konkret generierte die Studie 100 Zufallsinstanzen zur Bewertung verschiedener Methoden. Um eine realistische Einschätzung der Korrektheit der endgültigen LLM-Planung zu ermöglichen, setzt die Studie einen externen Validator VAL ein. Wie in Tabelle 1 gezeigt, ist die LLM+LLM-Backprompt-Methode hinsichtlich der Genauigkeit etwas besser als die Nicht-Backprompt-Methode. Von 100 Fällen hat der Validator 61 (61 %) genau identifiziert. Die folgende Tabelle zeigt die Leistung von LLM bei unterschiedlichem Feedbackniveau (einschließlich keinem Feedback). 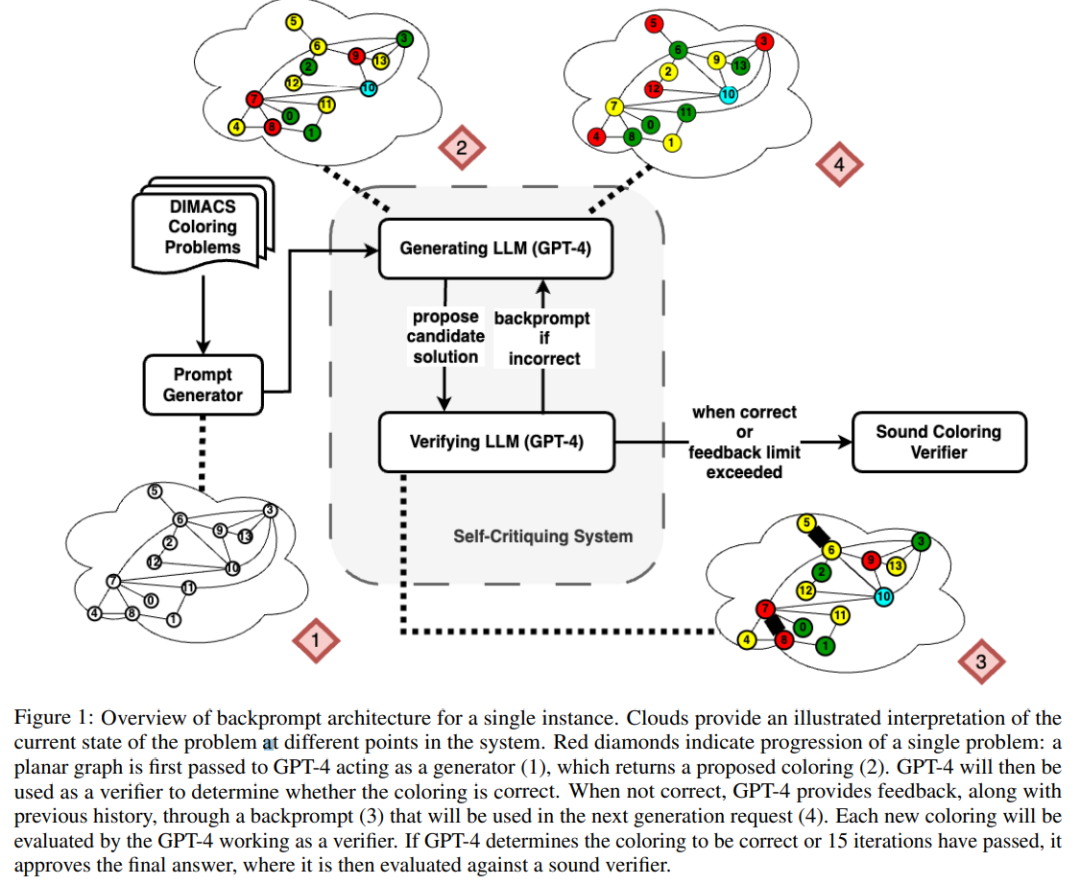

Das obige ist der detaillierte Inhalt vonLeCun hat das autoregressive LLM erneut schlecht geredet: Die Argumentationsfähigkeit von GPT-4 ist sehr begrenzt, wie aus zwei Artikeln hervorgeht. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1386
1386
 52
52

 So überprüfen Sie die CentOS -HDFS -Konfiguration
Apr 14, 2025 pm 07:21 PM
So überprüfen Sie die CentOS -HDFS -Konfiguration
Apr 14, 2025 pm 07:21 PM
Vollständige Anleitung zur Überprüfung der HDFS -Konfiguration in CentOS -Systemen In diesem Artikel wird die Konfiguration und den laufenden Status von HDFS auf CentOS -Systemen effektiv überprüft. Die folgenden Schritte helfen Ihnen dabei, das Setup und den Betrieb von HDFs vollständig zu verstehen. Überprüfen Sie die Hadoop -Umgebungsvariable: Stellen Sie zunächst sicher, dass die Hadoop -Umgebungsvariable korrekt eingestellt ist. Führen Sie im Terminal den folgenden Befehl aus, um zu überprüfen, ob Hadoop ordnungsgemäß installiert und konfiguriert ist: Hadoopsion-Check HDFS-Konfigurationsdatei: Die Kernkonfigurationsdatei von HDFS befindet sich im/etc/hadoop/conf/verzeichnis, wobei core-site.xml und hdfs-site.xml von entscheidender Bedeutung sind. verwenden
 CentOS Shutdown -Befehlszeile
Apr 14, 2025 pm 09:12 PM
CentOS Shutdown -Befehlszeile
Apr 14, 2025 pm 09:12 PM
Der Befehl centOS stilldown wird heruntergefahren und die Syntax wird von [Optionen] ausgeführt [Informationen]. Zu den Optionen gehören: -h das System sofort stoppen; -P schalten Sie die Leistung nach dem Herunterfahren aus; -r neu starten; -t Wartezeit. Zeiten können als unmittelbar (jetzt), Minuten (Minuten) oder als bestimmte Zeit (HH: MM) angegeben werden. Hinzugefügten Informationen können in Systemmeldungen angezeigt werden.
 Was sind die Backup -Methoden für Gitlab auf CentOS?
Apr 14, 2025 pm 05:33 PM
Was sind die Backup -Methoden für Gitlab auf CentOS?
Apr 14, 2025 pm 05:33 PM
Backup- und Wiederherstellungsrichtlinie von GitLab im Rahmen von CentOS -System Um die Datensicherheit und Wiederherstellung der Daten zu gewährleisten, bietet GitLab on CentOS eine Vielzahl von Sicherungsmethoden. In diesem Artikel werden mehrere gängige Sicherungsmethoden, Konfigurationsparameter und Wiederherstellungsprozesse im Detail eingeführt, um eine vollständige GitLab -Sicherungs- und Wiederherstellungsstrategie aufzubauen. 1. Manuell Backup Verwenden Sie den GitLab-RakegitLab: Backup: Befehl erstellen, um die manuelle Sicherung auszuführen. Dieser Befehl unterstützt wichtige Informationen wie GitLab Repository, Datenbank, Benutzer, Benutzergruppen, Schlüssel und Berechtigungen. Die Standardsicherungsdatei wird im Verzeichnis/var/opt/gitlab/backups gespeichert. Sie können /etc /gitlab ändern
 CentOS installieren MySQL
Apr 14, 2025 pm 08:09 PM
CentOS installieren MySQL
Apr 14, 2025 pm 08:09 PM
Die Installation von MySQL auf CentOS umfasst die folgenden Schritte: Hinzufügen der entsprechenden MySQL Yum -Quelle. Führen Sie den Befehl mySQL-server aus, um den MySQL-Server zu installieren. Verwenden Sie den Befehl mySQL_SECURE_INSTALLATION, um Sicherheitseinstellungen vorzunehmen, z. B. das Festlegen des Stammbenutzerkennworts. Passen Sie die MySQL -Konfigurationsdatei nach Bedarf an. Tune MySQL -Parameter und optimieren Sie Datenbanken für die Leistung.
 Wie man eine verteilte Schulung von Pytorch auf CentOS betreibt
Apr 14, 2025 pm 06:36 PM
Wie man eine verteilte Schulung von Pytorch auf CentOS betreibt
Apr 14, 2025 pm 06:36 PM
Pytorch Distributed Training on CentOS -System erfordert die folgenden Schritte: Pytorch -Installation: Die Prämisse ist, dass Python und PIP im CentOS -System installiert sind. Nehmen Sie abhängig von Ihrer CUDA -Version den entsprechenden Installationsbefehl von der offiziellen Pytorch -Website ab. Für CPU-Schulungen können Sie den folgenden Befehl verwenden: PipinstallTorChTorChVisionTorChaudio Wenn Sie GPU-Unterstützung benötigen, stellen Sie sicher, dass die entsprechende Version von CUDA und CUDNN installiert ist und die entsprechende Pytorch-Version für die Installation verwenden. Konfiguration der verteilten Umgebung: Verteiltes Training erfordert in der Regel mehrere Maschinen oder mehrere Maschinen-Mehrfach-GPUs. Ort
 Detaillierte Erklärung des Docker -Prinzips
Apr 14, 2025 pm 11:57 PM
Detaillierte Erklärung des Docker -Prinzips
Apr 14, 2025 pm 11:57 PM
Docker verwendet Linux -Kernel -Funktionen, um eine effiziente und isolierte Anwendungsumgebung zu bieten. Sein Arbeitsprinzip lautet wie folgt: 1. Der Spiegel wird als schreibgeschützte Vorlage verwendet, die alles enthält, was Sie für die Ausführung der Anwendung benötigen. 2. Das Union File System (UnionFS) stapelt mehrere Dateisysteme, speichert nur die Unterschiede, speichert Platz und beschleunigt. 3. Der Daemon verwaltet die Spiegel und Container, und der Kunde verwendet sie für die Interaktion. 4. Namespaces und CGroups implementieren Container -Isolation und Ressourcenbeschränkungen; 5. Mehrere Netzwerkmodi unterstützen die Containerverbindung. Nur wenn Sie diese Kernkonzepte verstehen, können Sie Docker besser nutzen.
 So sehen Sie sich Gitlab -Protokolle unter CentOS
Apr 14, 2025 pm 06:18 PM
So sehen Sie sich Gitlab -Protokolle unter CentOS
Apr 14, 2025 pm 06:18 PM
Eine vollständige Anleitung zum Anzeigen von GitLab -Protokollen unter CentOS -System In diesem Artikel wird in diesem Artikel verschiedene GitLab -Protokolle im CentOS -System angezeigt, einschließlich Hauptprotokolle, Ausnahmebodi und anderen zugehörigen Protokollen. Bitte beachten Sie, dass der Log -Dateipfad je nach GitLab -Version und Installationsmethode variieren kann. Wenn der folgende Pfad nicht vorhanden ist, überprüfen Sie bitte das GitLab -Installationsverzeichnis und die Konfigurationsdateien. 1. Zeigen Sie das Hauptprotokoll an. Verwenden Sie den folgenden Befehl, um die Hauptprotokolldatei der GitLabRails-Anwendung anzuzeigen: Befehl: Sudocat/var/log/gitlab/gitlab-rails/production.log Dieser Befehl zeigt das Produkt an
 Wie ist die GPU -Unterstützung für Pytorch bei CentOS?
Apr 14, 2025 pm 06:48 PM
Wie ist die GPU -Unterstützung für Pytorch bei CentOS?
Apr 14, 2025 pm 06:48 PM
Aktivieren Sie die Pytorch -GPU -Beschleunigung am CentOS -System erfordert die Installation von CUDA-, CUDNN- und GPU -Versionen von Pytorch. Die folgenden Schritte führen Sie durch den Prozess: Cuda und Cudnn Installation Bestimmen Sie die CUDA-Version Kompatibilität: Verwenden Sie den Befehl nvidia-smi, um die von Ihrer NVIDIA-Grafikkarte unterstützte CUDA-Version anzuzeigen. Beispielsweise kann Ihre MX450 -Grafikkarte CUDA11.1 oder höher unterstützen. Download und installieren Sie Cudatoolkit: Besuchen Sie die offizielle Website von Nvidiacudatoolkit und laden Sie die entsprechende Version gemäß der höchsten CUDA -Version herunter und installieren Sie sie, die von Ihrer Grafikkarte unterstützt wird. Installieren Sie die Cudnn -Bibliothek:
