
 Technologie-Peripheriegeräte
KI
Präzise Merkmalsausrichtung zur Verbesserung der multimodalen 3D-Objekterkennung: Anwendung von GraphAlign
Technologie-Peripheriegeräte
KI
Präzise Merkmalsausrichtung zur Verbesserung der multimodalen 3D-Objekterkennung: Anwendung von GraphAlign
Präzise Merkmalsausrichtung zur Verbesserung der multimodalen 3D-Objekterkennung: Anwendung von GraphAlign

Originaltitel: GraphAlign: Enhancing Accurate Feature Alignment by Graph Matching for Multi-Modal 3D Object Detection
Der Inhalt, der neu geschrieben werden muss, ist: Papierlink: https://arxiv.org/pdf/2310.08261.pdf
Autor Zugehörigkeit: Beijing Jiaotong University Hebei University of Science and Technology Tsinghua University

Thesisidee:
LiDAR und Kameras sind komplementäre Sensoren für die 3D-Zielerkennung beim autonomen Fahren. Die Untersuchung unnatürlicher Wechselwirkungen zwischen Punktwolken und Bildern ist jedoch eine Herausforderung, und der Schlüssel liegt darin, wie man die Merkmalsausrichtung heterogener Modalitäten durchführt. Derzeit erreichen viele Methoden die Merkmalsausrichtung nur durch Projektionskalibrierung und ignorieren das Problem der Genauigkeitsfehler bei der Koordinatenkonvertierung zwischen Sensoren, was zu einer suboptimalen Leistung führt. In diesem Artikel wird eine genauere Feature-Alignment-Strategie namens GraphAlign für die 3D-Objekterkennung durch Graph-Matching vorgeschlagen. Konkret verschmilzt dieser Artikel die Bildmerkmale des semantischen Segmentierungsencoders im Bildzweig mit den Punktwolkenmerkmalen des 3D-sparse CNN im LiDAR-Zweig. Um den Rechenaufwand zu reduzieren, verwendet dieser Artikel die Berechnung des euklidischen Abstands, um die Beziehung zum nächsten Nachbarn im Unterraum der Punktwolkenmerkmale zu erstellen. Durch die Projektionskalibrierung zwischen dem Bild und der Punktwolke werden die nächsten Nachbarn der Punktwolkenmerkmale auf die Bildmerkmale projiziert. Anschließend suchen wir nach einer geeigneteren Merkmalsausrichtung, indem wir den nächsten Nachbarn einer einzelnen Punktwolke mehreren Bildern zuordnen. Darüber hinaus bietet dieses Papier auch ein Selbstaufmerksamkeitsmodul, um das Gewicht wichtiger Beziehungen zu erhöhen und die Merkmalsausrichtung zwischen heterogenen Modalitäten zu optimieren. Im nuScenes-Benchmark wurde eine große Anzahl von Experimenten durchgeführt, um die Wirksamkeit und Effizienz des in diesem Artikel vorgeschlagenen GraphAlign zu beweisen. , um das Problem der Fehlausrichtung bei der multimodalen 3D-Objekterkennung zu lösen.
In diesem Artikel werden die Module Graph Feature Alignment (GFA) und Self-Attention Feature Alignment (SAFA) vorgeschlagen, um eine präzise Ausrichtung von Bildmerkmalen und Punktwolkenmerkmalen zu erreichen, wodurch Punktwolken und Merkmalsausrichtung zwischen Bildmodalitäten weiter verbessert und dadurch die Erkennungsgenauigkeit verbessert werden können . Durch die Durchführung von Experimenten mit zwei Benchmarks, KITTI und nuScenes, beweisen wir, dass GraphAlign die Genauigkeit der Punktwolkenerkennung effektiv verbessern kann, insbesondere bei der Zielerkennung über große Entfernungen.
Netzwerkdesign:Abbildung 1. Funktionen Vergleich von Ausrichtungsstrategien
(a) Projektionsbasierte Methoden können schnell Beziehungen zwischen Modalmerkmalen herstellen, können jedoch aufgrund von Sensorfehlern unter einer Fehlausrichtung leiden. (b) Aufmerksamkeitsbasierte Methoden behalten semantische Informationen durch Lernen der Ausrichtung, sind jedoch rechenintensiv. (c) Das in diesem Artikel vorgeschlagene GraphAlign verwendet eine graphbasierte Merkmalsausrichtung, um sinnvollere Ausrichtungen zwischen Modalitäten abzugleichen, wodurch der Rechenaufwand reduziert und die Genauigkeit verbessert wird.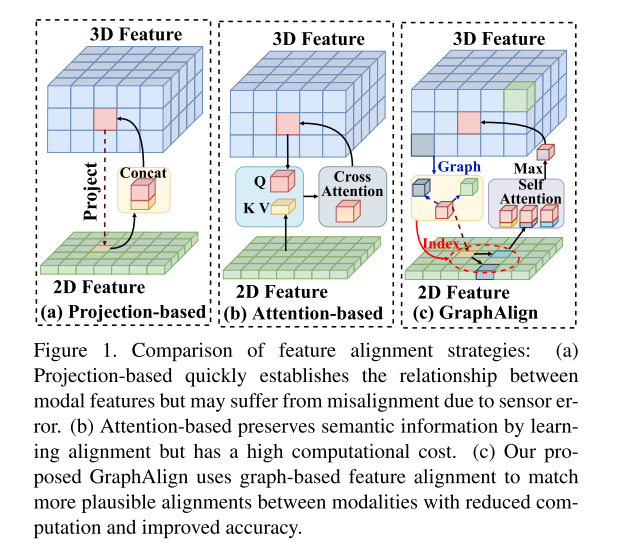
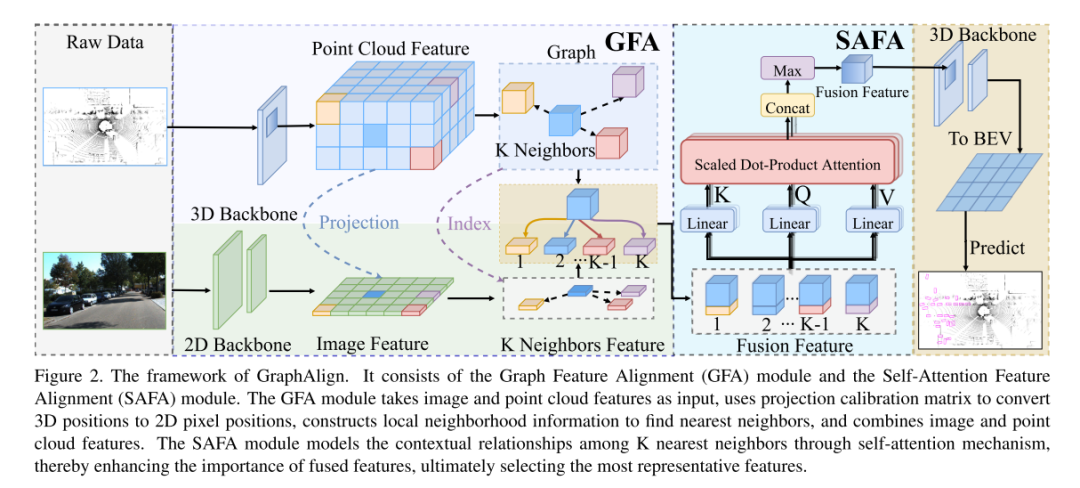
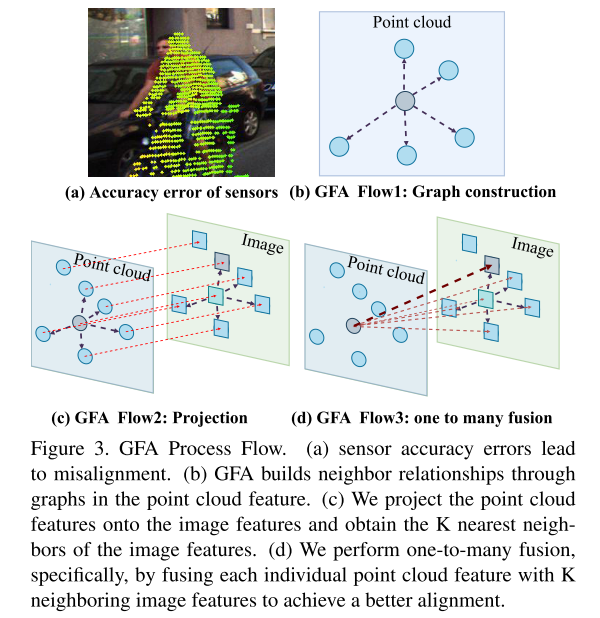
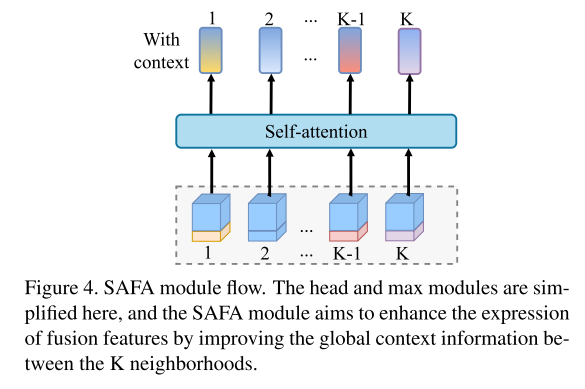

Experimentelle Ergebnisse:
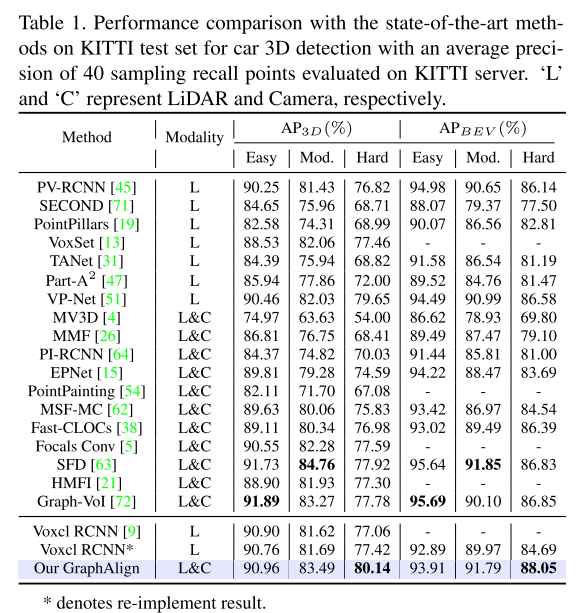
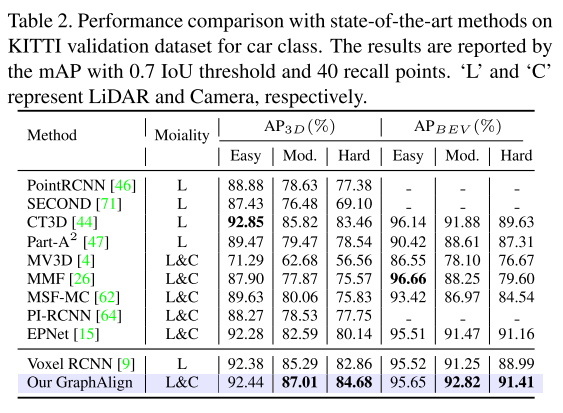
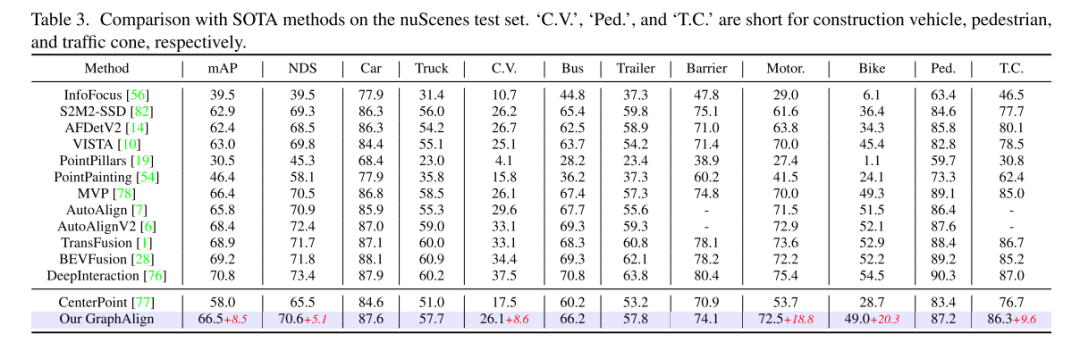
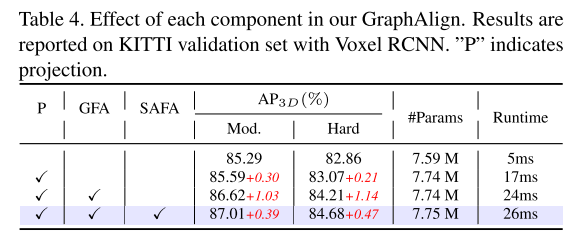



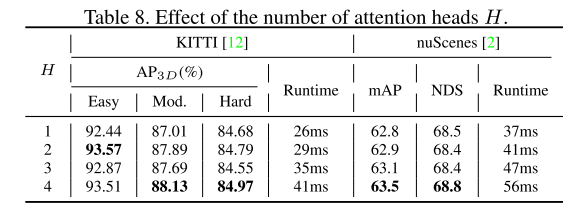
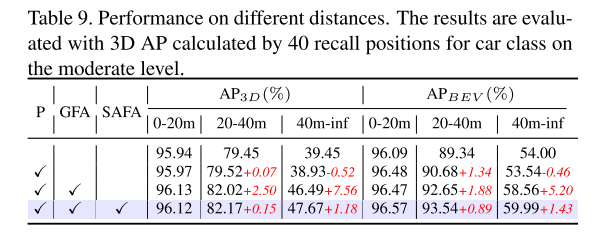
Zitat:
Song, Z., Wei , H., Bai, L., Yang, L., & Jia, C. (2023). GraphAlign: Verbesserung der präzisen Feature-Ausrichtung durch Graph-Matching für die multimodale 3D-Objekterkennung
Originallink: https://mp.weixin.qq.com/s/eN6THT2azHvoleT1F6MoSwDas obige ist der detaillierte Inhalt vonPräzise Merkmalsausrichtung zur Verbesserung der multimodalen 3D-Objekterkennung: Anwendung von GraphAlign. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Warum ist Gaussian Splatting beim autonomen Fahren so beliebt, dass NeRF allmählich aufgegeben wird?
Jan 17, 2024 pm 02:57 PM
Warum ist Gaussian Splatting beim autonomen Fahren so beliebt, dass NeRF allmählich aufgegeben wird?
Jan 17, 2024 pm 02:57 PM
Oben geschrieben und persönliches Verständnis des Autors. Dreidimensionales Gaussplatting (3DGS) ist eine transformative Technologie, die in den letzten Jahren in den Bereichen explizite Strahlungsfelder und Computergrafik entstanden ist. Diese innovative Methode zeichnet sich durch die Verwendung von Millionen von 3D-Gaußkurven aus, was sich stark von der Neural Radiation Field (NeRF)-Methode unterscheidet, die hauptsächlich ein implizites koordinatenbasiertes Modell verwendet, um räumliche Koordinaten auf Pixelwerte abzubilden. Mit seiner expliziten Szenendarstellung und differenzierbaren Rendering-Algorithmen garantiert 3DGS nicht nur Echtzeit-Rendering-Fähigkeiten, sondern führt auch ein beispielloses Maß an Kontrolle und Szenenbearbeitung ein. Dies positioniert 3DGS als potenziellen Game-Changer für die 3D-Rekonstruktion und -Darstellung der nächsten Generation. Zu diesem Zweck geben wir erstmals einen systematischen Überblick über die neuesten Entwicklungen und Anliegen im Bereich 3DGS.
 Erfahren Sie mehr über 3D Fluent-Emojis in Microsoft Teams
Apr 24, 2023 pm 10:28 PM
Erfahren Sie mehr über 3D Fluent-Emojis in Microsoft Teams
Apr 24, 2023 pm 10:28 PM
Sie müssen bedenken, insbesondere wenn Sie Teams-Benutzer sind, dass Microsoft seiner arbeitsorientierten Videokonferenz-App eine neue Reihe von 3DFluent-Emojis hinzugefügt hat. Nachdem Microsoft letztes Jahr 3D-Emojis für Teams und Windows angekündigt hatte, wurden im Rahmen des Prozesses tatsächlich mehr als 1.800 bestehende Emojis für die Plattform aktualisiert. Diese große Idee und die Einführung des 3DFluent-Emoji-Updates für Teams wurden erstmals über einen offiziellen Blogbeitrag beworben. Das neueste Teams-Update bringt FluentEmojis in die App. Laut Microsoft werden uns die aktualisierten 1.800 Emojis täglich zur Verfügung stehen
 Kamera oder Lidar wählen? Eine aktuelle Übersicht über die Erzielung einer robusten 3D-Objekterkennung
Jan 26, 2024 am 11:18 AM
Kamera oder Lidar wählen? Eine aktuelle Übersicht über die Erzielung einer robusten 3D-Objekterkennung
Jan 26, 2024 am 11:18 AM
0. Vorab geschrieben&& Persönliches Verständnis, dass autonome Fahrsysteme auf fortschrittlichen Wahrnehmungs-, Entscheidungs- und Steuerungstechnologien beruhen, indem sie verschiedene Sensoren (wie Kameras, Lidar, Radar usw.) verwenden, um die Umgebung wahrzunehmen, und Algorithmen und Modelle verwenden für Echtzeitanalysen und Entscheidungsfindung. Dies ermöglicht es Fahrzeugen, Verkehrszeichen zu erkennen, andere Fahrzeuge zu erkennen und zu verfolgen, das Verhalten von Fußgängern vorherzusagen usw. und sich so sicher an komplexe Verkehrsumgebungen anzupassen. Diese Technologie erregt derzeit große Aufmerksamkeit und gilt als wichtiger Entwicklungsbereich für die Zukunft des Transportwesens . eins. Aber was autonomes Fahren schwierig macht, ist herauszufinden, wie man dem Auto klarmachen kann, was um es herum passiert. Dies erfordert, dass der dreidimensionale Objekterkennungsalgorithmus im autonomen Fahrsystem Objekte in der Umgebung, einschließlich ihrer Standorte, genau wahrnehmen und beschreiben kann.
 CLIP-BEVFormer: Überwacht explizit die BEVFormer-Struktur, um die Leistung der Long-Tail-Erkennung zu verbessern
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer: Überwacht explizit die BEVFormer-Struktur, um die Leistung der Long-Tail-Erkennung zu verbessern
Mar 26, 2024 pm 12:41 PM
Oben geschrieben und das persönliche Verständnis des Autors: Derzeit spielt das Wahrnehmungsmodul im gesamten autonomen Fahrsystem eine entscheidende Rolle Das Steuermodul im autonomen Fahrsystem trifft zeitnahe und korrekte Urteile und Verhaltensentscheidungen. Derzeit sind Autos mit autonomen Fahrfunktionen in der Regel mit einer Vielzahl von Dateninformationssensoren ausgestattet, darunter Rundumsichtkamerasensoren, Lidar-Sensoren und Millimeterwellenradarsensoren, um Informationen in verschiedenen Modalitäten zu sammeln und so genaue Wahrnehmungsaufgaben zu erfüllen. Der auf reinem Sehen basierende BEV-Wahrnehmungsalgorithmus wird von der Industrie aufgrund seiner geringen Hardwarekosten und einfachen Bereitstellung bevorzugt, und seine Ausgabeergebnisse können problemlos auf verschiedene nachgelagerte Aufgaben angewendet werden.
 Paint 3D in Windows 11: Download-, Installations- und Nutzungshandbuch
Apr 26, 2023 am 11:28 AM
Paint 3D in Windows 11: Download-, Installations- und Nutzungshandbuch
Apr 26, 2023 am 11:28 AM
Als sich das Gerücht verbreitete, dass das neue Windows 11 in der Entwicklung sei, war jeder Microsoft-Nutzer neugierig, wie das neue Betriebssystem aussehen und was es bringen würde. Nach Spekulationen ist Windows 11 da. Das Betriebssystem kommt mit neuem Design und funktionalen Änderungen. Zusätzlich zu einigen Ergänzungen werden Funktionen eingestellt und entfernt. Eine der Funktionen, die es in Windows 11 nicht gibt, ist Paint3D. Während es immer noch klassisches Paint bietet, das sich gut für Zeichner, Kritzler und Kritzler eignet, verzichtet es auf Paint3D, das zusätzliche Funktionen bietet, die sich ideal für 3D-Ersteller eignen. Wenn Sie nach zusätzlichen Funktionen suchen, empfehlen wir Autodesk Maya als beste 3D-Designsoftware. wie
 Holen Sie sich mit einer einzigen Karte in 30 Sekunden eine virtuelle 3D-Frau! Text to 3D generiert einen hochpräzisen digitalen Menschen mit klaren Porendetails und lässt sich nahtlos mit Maya, Unity und anderen Produktionstools verbinden
May 23, 2023 pm 02:34 PM
Holen Sie sich mit einer einzigen Karte in 30 Sekunden eine virtuelle 3D-Frau! Text to 3D generiert einen hochpräzisen digitalen Menschen mit klaren Porendetails und lässt sich nahtlos mit Maya, Unity und anderen Produktionstools verbinden
May 23, 2023 pm 02:34 PM
ChatGPT hat der KI-Branche eine Portion Hühnerblut injiziert, und alles, was einst undenkbar war, ist heute zur gängigen Praxis geworden. Text-to-3D, das immer weiter voranschreitet, gilt nach Diffusion (Bilder) und GPT (Text) als nächster Hotspot im AIGC-Bereich und hat beispiellose Aufmerksamkeit erhalten. Nein, ein Produkt namens ChatAvatar befindet sich in einer unauffälligen öffentlichen Betaphase, hat schnell über 700.000 Aufrufe und Aufmerksamkeit erregt und wurde auf Spacesoftheweek vorgestellt. △ChatAvatar wird auch die Imageto3D-Technologie unterstützen, die 3D-stilisierte Charaktere aus KI-generierten Einzel-/Mehrperspektive-Originalgemälden generiert. Das von der aktuellen Beta-Version generierte 3D-Modell hat große Beachtung gefunden.
 Das Neueste von der Universität Oxford! Mickey: 2D-Bildabgleich in 3D SOTA! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
Das Neueste von der Universität Oxford! Mickey: 2D-Bildabgleich in 3D SOTA! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
Projektlink vorne geschrieben: https://nianticlabs.github.io/mickey/ Anhand zweier Bilder kann die Kameraposition zwischen ihnen geschätzt werden, indem die Korrespondenz zwischen den Bildern hergestellt wird. Normalerweise handelt es sich bei diesen Entsprechungen um 2D-zu-2D-Entsprechungen, und unsere geschätzten Posen sind maßstabsunabhängig. Einige Anwendungen, wie z. B. Instant Augmented Reality jederzeit und überall, erfordern eine Posenschätzung von Skalenmetriken und sind daher auf externe Tiefenschätzer angewiesen, um die Skalierung wiederherzustellen. In diesem Artikel wird MicKey vorgeschlagen, ein Keypoint-Matching-Prozess, mit dem metrische Korrespondenzen im 3D-Kameraraum vorhergesagt werden können. Durch das Erlernen des 3D-Koordinatenabgleichs zwischen Bildern können wir auf metrische Relativwerte schließen
 Eine ausführliche Interpretation des visuellen 3D-Wahrnehmungsalgorithmus für autonomes Fahren
Jun 02, 2023 pm 03:42 PM
Eine ausführliche Interpretation des visuellen 3D-Wahrnehmungsalgorithmus für autonomes Fahren
Jun 02, 2023 pm 03:42 PM
Für autonome Fahranwendungen ist es letztlich notwendig, 3D-Szenen wahrzunehmen. Der Grund ist einfach. Ein Fahrzeug kann nicht auf der Grundlage der aus einem Bild gewonnenen Wahrnehmungsergebnisse fahren. Selbst ein menschlicher Fahrer kann nicht auf der Grundlage eines Bildes fahren. Da die Entfernung des Objekts und die Tiefeninformationen der Szene nicht in den 2D-Wahrnehmungsergebnissen widergespiegelt werden können, sind diese Informationen der Schlüssel für das autonome Fahrsystem, um korrekte Urteile über die Umgebung zu fällen. Im Allgemeinen werden die Sichtsensoren (z. B. Kameras) autonomer Fahrzeuge über der Karosserie oder am Rückspiegel im Fahrzeuginneren installiert. Egal wo sie ist, was die Kamera erhält, ist die Projektion der realen Welt in der perspektivischen Ansicht (PerspectiveView) (Weltkoordinatensystem zu Bildkoordinatensystem). Diese Sicht ist dem menschlichen visuellen System sehr ähnlich.
