
 Technologie-Peripheriegeräte
KI
Hochpräzise und kostengünstige 3D-Gesichtsrekonstruktionslösung für Spiele, Interpretation des Tencent AI Lab ICCV 2023-Papiers
Technologie-Peripheriegeräte
KI
Hochpräzise und kostengünstige 3D-Gesichtsrekonstruktionslösung für Spiele, Interpretation des Tencent AI Lab ICCV 2023-Papiers
Hochpräzise und kostengünstige 3D-Gesichtsrekonstruktionslösung für Spiele, Interpretation des Tencent AI Lab ICCV 2023-Papiers

Die 3D-Gesichtsrekonstruktion ist eine Schlüsseltechnologie, die in den Bereichen Spielfilm- und Fernsehproduktion, digitale Personen, AR/VR, Gesichtserkennung und -bearbeitung usw. weit verbreitet ist. Ziel ist es, aus einem oder mehreren Bildern hochwertige 3D-Personen zu erhalten Gesichtsmodell. Mit Hilfe komplexer Aufnahmesysteme in Studios können derzeit ausgereifte Lösungen in der Branche Rekonstruktionseffekte mit einer Präzision auf Porenebene erzielen, die mit echten Menschen vergleichbar sind [2]. Ihre Produktionskosten sind jedoch hoch und ihre Zykluszeiten sind lang Sie werden im Allgemeinen nur in Film- und Fernseh- oder Spieleprojekten der S-Ebene verwendet.
In den letzten Jahren wurde interaktives Gameplay, das auf kostengünstigen Gesichtsrekonstruktionstechnologien basiert (z. B. Gameplay zum Zusammenziehen von Gesichtern von Spielfiguren, Erzeugung virtueller AR/VR-Bilder usw.), vom Markt begrüßt. Benutzer müssen nur Bilder eingeben, die täglich abgerufen werden können, z. B. einzelne oder mehrere mit Mobiltelefonen aufgenommene Bilder, um schnell ein 3D-Modell zu erhalten. Allerdings ist die Bildqualität der bestehenden Methoden nicht kontrollierbar, die Genauigkeit der Rekonstruktionsergebnisse ist gering und sie sind nicht in der Lage, die Details des Gesichts wiederzugeben [3–4]. Wie man zu geringen Kosten hochauflösende 3D-Gesichter erhalten kann, ist immer noch ein ungelöstes Problem.
Der erste Schritt bei der Gesichtsrekonstruktion besteht darin, die Gesichtsausdrucksmethode zu definieren. Allerdings verfügen die vorhandenen gängigen gesichtsparametrisierten Modelle über begrenzte Ausdrucksmöglichkeiten. Selbst mit mehr Einschränkungsinformationen, wie z. B. Bildern mit mehreren Ansichten, ist es schwierig, die Rekonstruktionsgenauigkeit zu verbessern. Daher hat Tencent AI Lab ein verbessertes Adaptive Skinning-Modell (im Folgenden als ASM bezeichnet) als parametrisches Gesichtsmodell vorgeschlagen, das Gesichtsprioritäten verwendet und ein Gaußsches Mischungsmodell verwendet, um die Anzahl der Gesichtsmaskierungs-Pi-Gewichte erheblich zu reduzieren automatisch gelöst werden können.
Tests zeigen, dass die ASM-Methode nur eine kleine Anzahl von Parametern verwendet, ohne dass ein Training erforderlich ist, was die Ausdrucksfähigkeit von Gesichtern und die Genauigkeit der Gesichtsrekonstruktion mit mehreren Ansichten erheblich verbessert und die SOTA-Ebene revolutioniert. Das entsprechende Papier wurde von ICCV-2023 angenommen. Im Folgenden finden Sie eine detaillierte Erläuterung des Papiers.
Papiertitel: ASM: Adaptive Skinning Model for High-Quality 3D Face Modeling

Papierlink: https://arxiv.org/pdf/2304.09423.pdf
Forschungsherausforderungen: niedrige Kosten, hoch Das Problem der genauen 3D-Gesichtsrekonstruktion – die Gewinnung eines 3D-Modells mit größerem Informationsgehalt aus 2D-Bildern – ist ein unterbestimmtes Problem mit unendlich vielen Lösungen. Um es lösbar zu machen, führen Forscher Gesichtsprioren in die Rekonstruktion ein, was die Schwierigkeit der Lösung verringert und die 3D-Form des Gesichts mit weniger Parametern ausdrückt, also ein parametrisches Gesichtsmodell. Die meisten aktuellen parametrischen Gesichtsmodelle basieren auf dem 3D Morphable Model (3DMM), und seine verbesserte Version 3DMM ist ein parametrisches Gesichtsmodell, das erstmals 1999 von Blanz und Vetter vorgeschlagen wurde [5]. Der Artikel geht davon aus, dass ein Gesicht durch eine lineare oder nichtlineare Kombination mehrerer verschiedener Gesichter erhalten werden kann. Durch das Sammeln von Hunderten hochpräziser 3D-Modelle realer Gesichter wird eine Gesichtsbasisbibliothek erstellt und anschließend parametrisierte Gesichter kombiniert, um neue Merkmale auszudrücken . Gesichtsmodell. Nachfolgende Forschungen optimierten 3DMM, indem sie vielfältigere reale Gesichtsmodelle sammelten [6, 7] und Methoden zur Dimensionsreduzierung verbesserten [8, 9].
Das gesichtsähnliche 3DMM-Modell weist jedoch eine hohe Robustheit, aber eine unzureichende Ausdruckskraft auf. Wenn das Eingabebild verschwommen oder verdeckt ist, kann 3DMM zwar stabil Gesichtsmodelle mit durchschnittlicher Genauigkeit generieren, wenn jedoch mehrere hochwertige Bilder als Eingabe verwendet werden, verfügt 3DMM nur über begrenzte Ausdrucksfähigkeiten und kann daher nicht mehr Eingabeinformationen nutzen. Daher ist die Rekonstruktionsgenauigkeit eingeschränkt. Diese Einschränkung ist auf zwei Aspekte zurückzuführen. Zweitens beruht die Methode auf der Erfassung von Gesichtsmodelldaten. Sie ist nicht nur hoch, sondern auch schwierig in der Praxis anzuwenden auf die Sensibilität von Gesichtsdaten.ASM-Methode: Neugestaltung des Skelett-Haut-Modells
Um das Problem der unzureichenden Ausdrucksfähigkeit des vorhandenen 3DMM-Gesichtsmodells zu lösen, stellt dieser Artikel das in der Spielebranche häufig verwendete „Skelett-Haut-Modell“ vor Basismethode für den Gesichtsausdruck. Modelle mit Skeletthaut sind eine gängige Gesichtsmodellierungsmethode, mit der die Gesichtsformen und Gesichtsausdrücke von Spielfiguren im Prozess der Spiel- und Animationsproduktion ausgedrückt werden. Es ist über virtuelle Knochenpunkte mit den Mesh-Scheitelpunkten verbunden. Das Hautgewicht bestimmt das Einflussgewicht der Knochen auf die Mesh-Scheitelpunkte. Bei Verwendung muss nur die Bewegung der Knochen gesteuert werden die Mesh-Scheitelpunkte.
Normalerweise müssen Animatoren bei Modellen mit Skeletthaut eine präzise Knochenplatzierung und Hautgewichtszeichnung durchführen, was sich durch eine hohe Produktionsschwelle und einen langen Produktionszyklus auszeichnet. Allerdings sind die Formen der Knochen und Muskeln verschiedener Menschen in echten menschlichen Gesichtern sehr unterschiedlich. Es ist schwierig, die verschiedenen Gesichtsformen in der Realität darzustellen. Aus diesem Grund wird in diesem Artikel das vorhandene Skelett-Hautsystem verwendet System Auf der Grundlage eines weiteren Designs wird das adaptive Bone-Skinning-Modell ASM vorgeschlagen, das auf Gaußschen Mischungs-Skinning-Gewichten (GMM Skinning Weights) und einem dynamischen Knochenbindungssystem (Dynamic Bone Binding) basiert, um die Expressionsfähigkeit von Knochen weiter zu verbessern -Hautbildung. Mit Flexibilität kann es adaptiv ein einzigartiges Skelett-Hautmodell für jedes Zielgesicht erzeugen, um reichhaltigere Gesichtsdetails auszudrücken.
Um die Ausdrucksfähigkeit des Skelett-Haut-Modells beim Modellieren verschiedener Gesichter zu verbessern, hat ASM ein neues Design für die Modellierungsmethode des Skelett-Haut-Modells entwickelt. Abbildung 1: Gesamtrahmen von ASM Mesh-Scheitelpunkte. Traditionelles Bone-Skinning besteht aus zwei Teilen, nämlich der Skin-Gewichtsmatrix und den ASM-Parametern, um ein adaptives Bone-Skinning-Modell zu erhalten. Als nächstes stellen wir die parametrischen Modellierungsmethoden der Hautgewichtsmatrix bzw. der Knochenbindung vor.
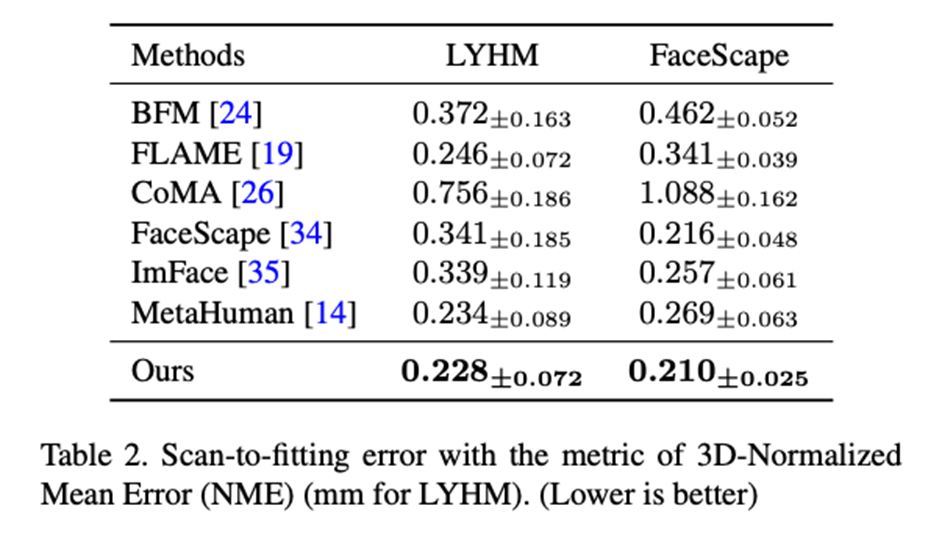
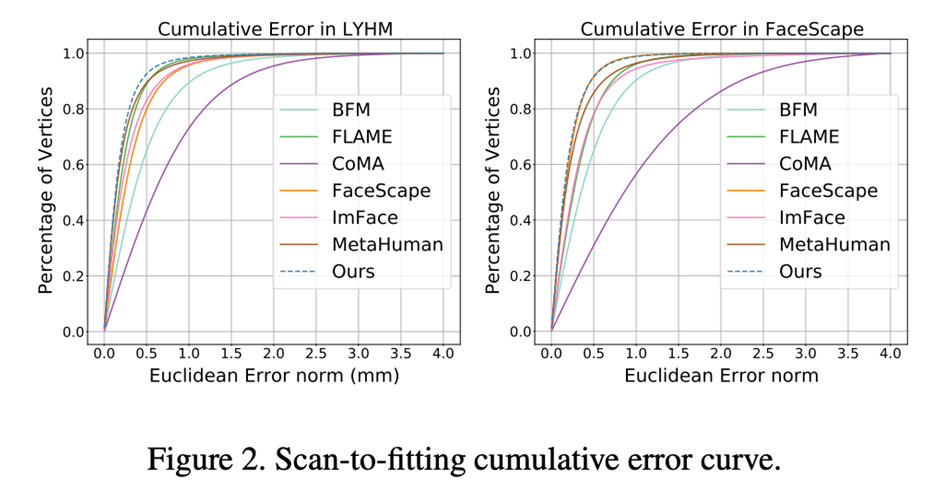
gaussian Mischhäunungsgewichte (GMM-Skinngewichte) Die Hautgewichtsmatrix ist eine mxn-dimensionale Matrix, wobei m die Anzahl der Knochen und n die Anzahl der Scheitelpunkte im Netz ist. Diese Matrix wird verwendet, um den Einflusskoeffizienten jedes Knochens auf jedem Netzscheitelpunkt zu speichern. Im Allgemeinen ist die Hautgewichtsmatrix sehr spärlich. In Unity wird beispielsweise jeder Mesh-Scheitelpunkt nur von bis zu 4 Knochen beeinflusst. Mit Ausnahme dieser 4 Knochen beträgt der Einflusskoeffizient der anderen Knochen auf den Scheitelpunkt . Beim herkömmlichen Modell mit Knochenhaut werden die Hautgewichte vom Animator gezeichnet. Sobald die Hautgewichte ermittelt wurden, ändern sie sich bei Verwendung nicht mehr. In den letzten Jahren wurde versucht, eine große Datenmenge mit neuronalem Netzwerklernen zu kombinieren, um automatisch Skinning-Gewichte zu generieren. Erstens erfordert das Training des neuronalen Netzwerks eine große Menge Wenn es sich um 3D-Gesichts- oder Hautgewichtsdaten handelt, ist es zweitens schwieriger, die Parameterredundanz bei der Verwendung eines neuronalen Netzwerks zur Modellierung von Hautgewichten zu ermitteln. Gibt es eine Methode zur Modellierung des Hautgewichts, die das Hautgewicht des gesamten Gesichts mithilfe einer kleinen Anzahl von Parametern ohne Training vollständig ausdrücken kann? Durch Beobachtung üblicher Hautgewichte können wir die folgenden Eigenschaften ermitteln: 1. Die Hautgewichte sind lokal glatt. 2. Je weiter der Netzscheitelpunkt von der aktuellen Knochenposition entfernt ist, desto kleiner ist diese Eigenschaft stimmt mit dem Gaussian Mixture Model (GMM) überein und stimmt sehr gut überein. Daher schlägt dieser Artikel Gaußsche gemischte Häutungsgewichte (GMM-Hautgewichte) vor, um die Häutungsgewichtsmatrix als Gaußsche Mischfunktion basierend auf einer bestimmten Abstandsfunktion zwischen Scheitelpunkten und Knochen zu modellieren, sodass ein Satz von GMM-Koeffizienten zum Ausdrücken der Häutung verwendet werden kann Gewichte bestimmter Knochen verteilt. Um die Parameter des Hautgewichts weiter zu komprimieren, übertragen wir das gesamte Gesichtsnetz vom dreidimensionalen Raum in den UV-Raum, sodass wir nur das zweidimensionale GMM und den UV-Abstand vom Scheitelpunkt verwenden müssen des Knochens, um die Maskierung eines bestimmten Scheitelpunkts durch den aktuellen Knochen zu berechnen. Durch die parametrische Modellierung von Hautgewichten können wir nicht nur die Hautgewichtsmatrix mit einer kleinen Anzahl von Parametern ausdrücken, sondern auch die Knochen zur Laufzeit anpassen. Dadurch wird es möglich, die Position zu binden Daher wird in diesem Artikel die Methode der dynamischen Knochenbindung (Dynamic Bone Binding) vorgeschlagen. Wie das Hautgewicht modelliert dieser Artikel die Bindungsposition des Knochens als Koordinatenpunkt im UV-Raum und kann sich im UV-Raum beliebig bewegen. Für die Scheitelpunkte des Gesichtsnetzes können die Scheitelpunkte einfach über die vordefinierte UV-Mapping-Beziehung auf eine feste Koordinate im UV-Raum abgebildet werden. Da die Knochen jedoch nicht im UV-Raum vordefiniert sind, müssen wir hierfür die gebundenen Knochen aus dem dreidimensionalen Raum in den UV-Raum übertragen. Dieser Schritt in diesem Artikel wird durch Interpolation der Koordinaten der Knochen und der umgebenden Scheitelpunkte implementiert. Wir wenden die berechneten Interpolationskoeffizienten auf die UV-Koordinaten der Scheitelpunkte an, um die UV-Koordinaten der Knochen zu erhalten. Das Gleiche gilt umgekehrt. Wenn wir Knochenkoordinaten vom UV-Raum in den dreidimensionalen Raum übertragen müssen, berechnen wir auch den Interpolationskoeffizienten zwischen den UV-Koordinaten des aktuellen Knochens und den UV-Koordinaten benachbarter Eckpunkte und wenden den an Interpolationskoeffizient zum gleichen Scheitelpunkt im dreidimensionalen Raum Auf den dreidimensionalen Koordinaten können die dreidimensionalen Raumkoordinaten der entsprechenden Knochen interpoliert werden. Durch diese Modellierungsmethode vereinheitlichen wir die Bindungspositionen und Hautgewichtskoeffizienten der Knochen in einem Satz von Koeffizienten im UV-Raum. Bei der Verwendung von ASM konvertieren wir die Verformung der Netzscheitelpunkte des Gesichts in eine Kombination aus dem Versatzkoeffizienten der Knochenbindungsposition im UV-Raum, dem Hautbildungskoeffizienten der Gaußschen Mischung im UV-Raum und dem Knochenbewegungskoeffizienten. Die Ausdruckskraft wurde erheblich verbessert Fähigkeit des Modells mit Skeletthaut, die Erzeugung reicherer Gesichtsdetails zu erreichen.每 Tabelle 1: Die Parameterdimension jedes ASM-Knochens Forschungsergebnisse: Die Fähigkeit zum Ausdruck des menschlichen Gesichts und die Genauigkeit der Rekonstruktion mehrerer Ansichten erreichen SOTA-Niveau Vergleich verschiedener Parametrisierungsfunktionen des Modells des menschlichen Gesichts Wir Verwenden Sie ein parametrisches Gesichtsmodell, um ein hochpräzises Gesichtsscanmodell zu registrieren (Registrierung), und kombinieren Sie ASM mit herkömmlichem 3DMM basierend auf PCA-Methoden (BFM [6], FLAME [7], FaceScape [10]) und 3DMM basierend auf der Dimensionalität neuronaler Netzwerke Die Reduktionsmethode (CoMA [8], ImFace [9]) und das branchenführende Knochen-Haut-Modell (MetaHuman) wurden verglichen. Die Ergebnisse zeigten, dass die Ausdrucksfähigkeit von ASM sowohl bei LYHM- als auch bei FaceScape-Datensätzen das SOTA-Niveau erreichte. Tabelle 2: Registrierungsgenauigkeit von LYHM und FaceScape Abbildung 3: LYHM-Visualisierungsergebnisse und Fehler-Heatmap der Registrierung auf FaceScape ASM bei der Multi-View-Gesichtsrekonstruktionsaufgabe Die Rekonstruktionsgenauigkeit des Coop-Testsatzes (Kamera für den Innenbereich, Personen ohne Ausdruck) erreicht das SOTA-Niveau.
Abbildung 4: Ergebnisse der 3D-Gesichtsrekonstruktion im Florence MICC-Datensatz
Zusammenfassung und Ausblick Nachdem die Fähigkeit zum Gesichtsausdruck erheblich verbessert wurde, ist die Konstruktion stärkerer Konsistenzbeschränkungen aus Bildern mit mehreren Ansichten zur weiteren Verbesserung der Genauigkeit der Rekonstruktionsergebnisse zu einem neuen Engpass und einer neuen Herausforderung im aktuellen Bereich der Gesichtsrekonstruktion geworden. Dies wird auch unsere zukünftige Forschungsrichtung sein. Referenzen [1] Noranart Vesdapunt, Mitch Rundle, HsiangTao Wu und Baoyuan Wang Jnr: Gelenkbasierte neuronale Rig-Darstellung für kompakte 3D-Gesichtsmodellierung – ECCV 2020: 16. Europäische Konferenz, Glasgow , Großbritannien, 23.–28. August 2020, Proceedings, Teil XVIII 16, Seiten 389–405. [2] Thabo Beeler, Bernd Bickel, Paul Beardsley, Bob Sumner und Markus Gross High – Hochwertige Einzelaufnahme der Gesichtsgeometrie. In ACM SIGGRAPH 2010-Artikeln, Seiten 1–9 Gesichtsrekonstruktion mit schwach überwachtem Lernen: Vom Einzelbild zum Bildsatz. In Tagungsband der IEEE/CVF-Konferenz zu Workshops zu Computer Vision und Mustererkennung, Seiten 0–0, 2019. [4] Yao Feng, Haiwen Feng , Michael J Black und Timo Bolkart. Lernen eines animierbaren detaillierten 3D-Gesichtsmodells aus Bildern in freier Wildbahn (ToG), 40 (4):1–13, 2021. [5] Volker Blanz und Thomas Vetter. In Proceedings of the 26th Annual Conference on Computer Graphics and Interactive Techniques, Seiten 187–194, 1999. [6] Pascal Paysan, Reinhard Knothe, Brian Amberg, Sami Romdhani, und Thomas Vetter , Timo Bolkart, Michael J Black, Hao Li und Javier Romero. Lernen eines Modells der Gesichtsform und des Gesichtsausdrucks aus 4D-Scans ] Anurag Ranjan, Timo Bolkart, Soubhik Sanyal und Michael J Black. Generieren von 3D-Gesichtern mithilfe von Faltungsnetz-Autoencodern, Seiten 704–720, 2018. [9] Mingwu Zheng, Hongyu Yang, Di Huang und Liming Chen. Imface: Ein nichtlineares 3D-Morphable-Gesichtsmodell mit impliziten neuronalen Darstellungen, Seiten 20343–20352. [10] Haotian Yang, Hao Zhu, Yanru Wang, Mingkai Huang, Qiu Shen, Ruigang Yang und Xun Cao: ein groß angelegter, hochwertiger 3D-Gesichtsdatensatz und eine detaillierte manipulierbare 3D-Gesichtsvorhersage /CVF-Konferenz zu Computer Vision und Mustererkennung, Seiten 601–610, 2020.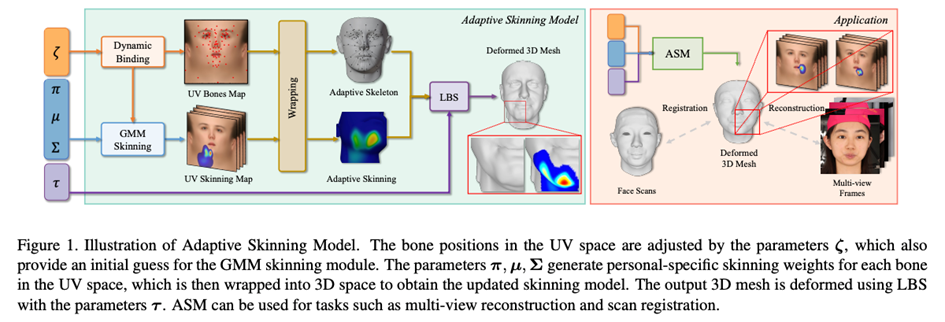
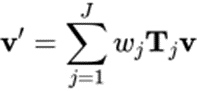 Formel 1: LBS-Formel des traditionellen Modells mit Skeletthäuschen
Formel 1: LBS-Formel des traditionellen Modells mit Skeletthäuschen 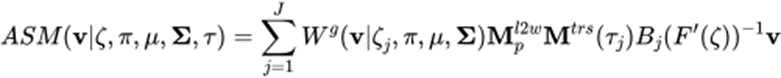 Formel 2: ASM-LBS-Formel
Formel 2: ASM-LBS-Formel 
Das obige ist der detaillierte Inhalt vonHochpräzise und kostengünstige 3D-Gesichtsrekonstruktionslösung für Spiele, Interpretation des Tencent AI Lab ICCV 2023-Papiers. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Der Autor von ControlNet hat einen weiteren Hit! Der gesamte Prozess der Generierung eines Gemäldes aus einem Bild, der in zwei Tagen 1,4.000 Sterne verdient
Jul 17, 2024 am 01:56 AM
Der Autor von ControlNet hat einen weiteren Hit! Der gesamte Prozess der Generierung eines Gemäldes aus einem Bild, der in zwei Tagen 1,4.000 Sterne verdient
Jul 17, 2024 am 01:56 AM
Es ist ebenfalls ein Tusheng-Video, aber PaintsUndo ist einen anderen Weg gegangen. ControlNet-Autor LvminZhang begann wieder zu leben! Dieses Mal ziele ich auf den Bereich der Malerei. Das neue Projekt PaintsUndo hat nicht lange nach seinem Start 1,4.000 Sterne erhalten (die immer noch wahnsinnig steigen). Projektadresse: https://github.com/lllyasviel/Paints-UNDO Bei diesem Projekt gibt der Benutzer ein statisches Bild ein, und PaintsUndo kann Ihnen dabei helfen, automatisch ein Video des gesamten Malprozesses zu erstellen, vom Linienentwurf bis zum fertigen Produkt . Während des Zeichenvorgangs sind die Linienänderungen erstaunlich. Das Endergebnis des Videos ist dem Originalbild sehr ähnlich: Schauen wir uns eine vollständige Zeichnung an.
 Von RLHF über DPO bis TDPO sind große Modellausrichtungsalgorithmen bereits auf „Token-Ebene'
Jun 24, 2024 pm 03:04 PM
Von RLHF über DPO bis TDPO sind große Modellausrichtungsalgorithmen bereits auf „Token-Ebene'
Jun 24, 2024 pm 03:04 PM
Die AIxiv-Kolumne ist eine Kolumne, in der diese Website akademische und technische Inhalte veröffentlicht. In den letzten Jahren sind in der AIxiv-Kolumne dieser Website mehr als 2.000 Berichte eingegangen, die Spitzenlabore großer Universitäten und Unternehmen auf der ganzen Welt abdecken und so den akademischen Austausch und die Verbreitung wirksam fördern. Wenn Sie hervorragende Arbeiten haben, die Sie teilen möchten, können Sie gerne einen Beitrag leisten oder uns für die Berichterstattung kontaktieren. Einreichungs-E-Mail: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com Im Entwicklungsprozess der künstlichen Intelligenz war die Steuerung und Führung großer Sprachmodelle (LLM) schon immer eine der zentralen Herausforderungen, um sicherzustellen, dass diese Modelle beides sind kraftvoll und sicher dienen der menschlichen Gesellschaft. Frühe Bemühungen konzentrierten sich auf Methoden des verstärkenden Lernens durch menschliches Feedback (RL
 Die agentenlose Lösung von UIUC steht ganz oben auf der Liste der Open-Source-KI-Softwareentwickler und löst problemlos echte Programmierprobleme im SWE-Bench
Jul 17, 2024 pm 10:02 PM
Die agentenlose Lösung von UIUC steht ganz oben auf der Liste der Open-Source-KI-Softwareentwickler und löst problemlos echte Programmierprobleme im SWE-Bench
Jul 17, 2024 pm 10:02 PM
Die AIxiv-Kolumne ist eine Kolumne, in der diese Website akademische und technische Inhalte veröffentlicht. In den letzten Jahren sind in der AIxiv-Kolumne dieser Website mehr als 2.000 Berichte eingegangen, die Spitzenlabore großer Universitäten und Unternehmen auf der ganzen Welt abdecken und so den akademischen Austausch und die Verbreitung wirksam fördern. Wenn Sie hervorragende Arbeiten haben, die Sie teilen möchten, können Sie gerne einen Beitrag leisten oder uns für die Berichterstattung kontaktieren. Einreichungs-E-Mail: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com Die Autoren dieses Artikels stammen alle aus dem Team von Lehrer Zhang Lingming an der University of Illinois in Urbana-Champaign, darunter: Steven Code Repair; Doktorand im vierten Jahr, Forscher
 Posthume Arbeit des OpenAI Super Alignment Teams: Zwei große Modelle spielen ein Spiel und die Ausgabe wird verständlicher
Jul 19, 2024 am 01:29 AM
Posthume Arbeit des OpenAI Super Alignment Teams: Zwei große Modelle spielen ein Spiel und die Ausgabe wird verständlicher
Jul 19, 2024 am 01:29 AM
Wenn die Antwort des KI-Modells überhaupt unverständlich ist, würden Sie es wagen, sie zu verwenden? Da maschinelle Lernsysteme in immer wichtigeren Bereichen eingesetzt werden, wird es immer wichtiger zu zeigen, warum wir ihren Ergebnissen vertrauen können und wann wir ihnen nicht vertrauen sollten. Eine Möglichkeit, Vertrauen in die Ausgabe eines komplexen Systems zu gewinnen, besteht darin, vom System zu verlangen, dass es eine Interpretation seiner Ausgabe erstellt, die für einen Menschen oder ein anderes vertrauenswürdiges System lesbar ist, d. h. so vollständig verständlich, dass mögliche Fehler erkannt werden können gefunden. Um beispielsweise Vertrauen in das Justizsystem aufzubauen, verlangen wir von den Gerichten, dass sie klare und lesbare schriftliche Stellungnahmen abgeben, die ihre Entscheidungen erläutern und stützen. Für große Sprachmodelle können wir auch einen ähnlichen Ansatz verfolgen. Stellen Sie bei diesem Ansatz jedoch sicher, dass das Sprachmodell generiert wird
 Axiomatisches Training ermöglicht es LLM, kausales Denken zu erlernen: Das 67-Millionen-Parameter-Modell ist vergleichbar mit der Billionen-Parameter-Ebene GPT-4
Jul 17, 2024 am 10:14 AM
Axiomatisches Training ermöglicht es LLM, kausales Denken zu erlernen: Das 67-Millionen-Parameter-Modell ist vergleichbar mit der Billionen-Parameter-Ebene GPT-4
Jul 17, 2024 am 10:14 AM
Zeigen Sie LLM die Kausalkette und es lernt die Axiome. KI hilft Mathematikern und Wissenschaftlern bereits bei der Forschung. Beispielsweise hat der berühmte Mathematiker Terence Tao wiederholt seine Forschungs- und Forschungserfahrungen mit Hilfe von KI-Tools wie GPT geteilt. Damit KI in diesen Bereichen konkurrenzfähig sein kann, sind starke und zuverlässige Fähigkeiten zum kausalen Denken unerlässlich. Die in diesem Artikel vorgestellte Forschung ergab, dass ein Transformer-Modell, das auf die Demonstration des kausalen Transitivitätsaxioms für kleine Graphen trainiert wurde, auf das Transitivitätsaxiom für große Graphen verallgemeinern kann. Mit anderen Worten: Wenn der Transformer lernt, einfache kausale Überlegungen anzustellen, kann er für komplexere kausale Überlegungen verwendet werden. Der vom Team vorgeschlagene axiomatische Trainingsrahmen ist ein neues Paradigma zum Erlernen des kausalen Denkens auf der Grundlage passiver Daten, nur mit Demonstrationen
 arXiv-Artikel können als „Barrage' gepostet werden, die Diskussionsplattform von Stanford alphaXiv ist online, LeCun gefällt es
Aug 01, 2024 pm 05:18 PM
arXiv-Artikel können als „Barrage' gepostet werden, die Diskussionsplattform von Stanford alphaXiv ist online, LeCun gefällt es
Aug 01, 2024 pm 05:18 PM
Prost! Wie ist es, wenn es bei einer Papierdiskussion auf Worte ankommt? Kürzlich haben Studenten der Stanford University alphaXiv erstellt, ein offenes Diskussionsforum für arXiv-Artikel, das es ermöglicht, Fragen und Kommentare direkt zu jedem arXiv-Artikel zu posten. Website-Link: https://alphaxiv.org/ Tatsächlich ist es nicht erforderlich, diese Website speziell zu besuchen. Ändern Sie einfach arXiv in einer beliebigen URL in alphaXiv, um den entsprechenden Artikel direkt im alphaXiv-Forum zu öffnen: Sie können die Absätze darin genau lokalisieren das Papier, Satz: Im Diskussionsbereich auf der rechten Seite können Benutzer Fragen stellen, um dem Autor Fragen zu den Ideen und Details des Papiers zu stellen. Sie können beispielsweise auch den Inhalt des Papiers kommentieren, wie zum Beispiel: „Gegeben an.“
 Ein bedeutender Durchbruch in der Riemann-Hypothese! Tao Zhexuan empfiehlt dringend neue Arbeiten vom MIT und Oxford, und der 37-jährige Fields-Medaillengewinner nahm daran teil
Aug 05, 2024 pm 03:32 PM
Ein bedeutender Durchbruch in der Riemann-Hypothese! Tao Zhexuan empfiehlt dringend neue Arbeiten vom MIT und Oxford, und der 37-jährige Fields-Medaillengewinner nahm daran teil
Aug 05, 2024 pm 03:32 PM
Kürzlich gelang der Riemann-Hypothese, die als eines der sieben großen Probleme des Jahrtausends bekannt ist, ein neuer Durchbruch. Die Riemann-Hypothese ist ein sehr wichtiges ungelöstes Problem in der Mathematik, das sich auf die genauen Eigenschaften der Verteilung von Primzahlen bezieht (Primzahlen sind Zahlen, die nur durch 1 und sich selbst teilbar sind, und sie spielen eine grundlegende Rolle in der Zahlentheorie). In der heutigen mathematischen Literatur gibt es mehr als tausend mathematische Thesen, die auf der Aufstellung der Riemann-Hypothese (oder ihrer verallgemeinerten Form) basieren. Mit anderen Worten: Sobald die Riemann-Hypothese und ihre verallgemeinerte Form bewiesen sind, werden diese mehr als tausend Sätze als Theoreme etabliert, die einen tiefgreifenden Einfluss auf das Gebiet der Mathematik haben werden, und wenn sich die Riemann-Hypothese als falsch erweist, dann unter anderem Auch diese Sätze werden teilweise ihre Gültigkeit verlieren. Neuer Durchbruch kommt von MIT-Mathematikprofessor Larry Guth und der Universität Oxford
 Unbegrenzte Videogenerierung, Planung und Entscheidungsfindung, erzwungene Verbreitung der nächsten Token-Vorhersage und vollständige Sequenzverbreitung
Jul 23, 2024 pm 02:05 PM
Unbegrenzte Videogenerierung, Planung und Entscheidungsfindung, erzwungene Verbreitung der nächsten Token-Vorhersage und vollständige Sequenzverbreitung
Jul 23, 2024 pm 02:05 PM
Derzeit sind autoregressive groß angelegte Sprachmodelle, die das nächste Token-Vorhersageparadigma verwenden, auf der ganzen Welt populär geworden. Gleichzeitig haben uns zahlreiche synthetische Bilder und Videos im Internet bereits die Leistungsfähigkeit von Diffusionsmodellen gezeigt. Kürzlich hat ein Forschungsteam am MITCSAIL (darunter Chen Boyuan, ein Doktorand am MIT) erfolgreich die leistungsstarken Fähigkeiten des Vollsequenz-Diffusionsmodells und des nächsten Token-Modells integriert und ein Trainings- und Sampling-Paradigma vorgeschlagen: Diffusion Forcing (DF). ). Papiertitel: DiffusionForcing:Next-tokenPredictionMeetsFull-SequenceDiffusion Papieradresse: https:/
