

Von Sprachmodellen wie BERT, GPT und Flan-T5 bis hin zu Bildmodellen wie SAM und Stable Diffusion erobert Transformer die Welt in rasantem Tempo, aber die Leute kommen nicht umhin zu fragen: Ist Transformer die einzige Wahl?
Ein Forschungsteam der Stanford University und der State University of New York at Buffalo gibt nicht nur eine negative Antwort auf diese Frage, sondern schlägt auch eine neue alternative Technologie vor: Monarch Mixer. Kürzlich veröffentlichte das Team relevante Artikel sowie einige Checkpoint-Modelle und Trainingscodes auf arXiv. Dieses Papier wurde übrigens für NeurIPS 2023 ausgewählt und für die mündliche Präsentation qualifiziert.

Papierlink: https://arxiv.org/abs/2310.12109
Die Codeadresse auf GitHub lautet: https://github.com/HazyResearch/m2
Diese Methode entfernt Die kostenintensive Aufmerksamkeit und MLP in Transformer werden durch ausdrucksstarke Monarch-Matrizen ersetzt, wodurch bei Sprach- und Bildexperimenten eine bessere Leistung bei geringeren Kosten erzielt werden kann.
Dies ist nicht das erste Mal, dass die Stanford University eine alternative Technologie zu Transformer vorschlägt. Im Juni dieses Jahres schlug ein anderes Team der Schule auch eine Technologie namens Backpack vor. Weitere Informationen finden Sie im Heart of Machine-Artikel „Stanford Training Transformer Alternative Model: 170 Million Parameters, Debiased, Controllable and Highly Interpretable“. Damit diese Technologien wirklich erfolgreich sind, müssen sie natürlich von der Forschungsgemeinschaft weiter getestet und in den Händen von Anwendungsentwicklern in praktische und nützliche Produkte umgewandelt werden
Werfen wir einen Blick auf die Einführung in Monarch Mixer und einige davon Experimente in dieser Arbeit ergeben.
In den Bereichen der Verarbeitung natürlicher Sprache und Computer Vision waren Modelle des maschinellen Lernens in der Lage, längere Sequenzen und höherdimensionale Darstellungen zu verarbeiten und so längere Kontexte und höhere Qualität zu unterstützen. Die zeitliche und räumliche Komplexität bestehender Architekturen weist jedoch ein quadratisches Wachstumsmuster in der Sequenzlänge und/oder den Modelldimensionen auf, was die Kontextlänge begrenzt und die Skalierungskosten erhöht. Beispielsweise skalieren Aufmerksamkeit und MLP in Transformer quadratisch mit der Sequenzlänge und der Modelldimensionalität.
Als Antwort auf dieses Problem behauptet dieses Forschungsteam der Stanford University und der State University of New York at Buffalo, eine Hochleistungsarchitektur gefunden zu haben, deren Komplexität subquadratisch mit der Sequenzlänge und der Modelldimension wächst (subquadratisch).
Ihre Forschung ist von MLP-Mixer und ConvMixer inspiriert. Diese beiden Studien stellen Folgendes fest: Viele Modelle für maschinelles Lernen vermischen Informationen entlang der Sequenz und Modelldimensionen als Achsen und arbeiten häufig auf beiden Achsen mit einem einzigen Operator.
Die Suche nach ausdrucksstarken, subquadratischen und hardwareeffizienten Mischoperatoren ist schwierig umzusetzen. Beispielsweise sind MLP im MLP-Mixer und Faltungen im ConvMixer beide recht ausdrucksstark, aber beide skalieren quadratisch mit der Eingabedimension. In einigen neueren Studien wurden einige Hybridmethoden mit subquadratischer Sequenz vorgeschlagen, die alle FFT verwenden. Die FLOP-Auslastung ist jedoch sehr gering noch eine zweite Erweiterung. Gleichzeitig gibt es einige vielversprechende Fortschritte bei dünnbesiedelten MLP-Schichten ohne Qualitätseinbußen, aber einige Modelle sind aufgrund der geringeren Hardwareauslastung möglicherweise tatsächlich langsamer als dichte Modelle.
Basierend auf diesen Inspirationen schlug das Forschungsteam Monarch Mixer (M2) vor, der eine ausdrucksstarke subquadratische Strukturmatrix verwendet: Monarch-Matrix
Monarch-Matrix ist eine verallgemeinerte Strukturmatrix mit schneller Fourier-Transformation (FFT). Untersuchungen zeigen, dass es eine Vielzahl linearer Transformationen enthält, wie z. B. Hadamard-Transformation, Toplitz-Matrix, AFDF-Matrix und Faltung usw. Diese Matrizen können durch das Produkt von Blockdiagonalmatrizen parametrisiert werden. Diese Parameter werden Monarch-Faktoren genannt und beziehen sich auf die Permutationsverschachtelung: Wenn die Anzahl der Faktoren auf p eingestellt ist, beträgt die Eingabelänge N Die Rechenkomplexität beträgt
, sodass die Rechenkomplexität zwischen O (N log N) bei p = log N und bei p = 2 liegen kann. 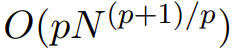 M2 verwendet eine Monarch-Matrix, um Informationen entlang der Sequenz- und Modelldimensionsachsen zu vermischen. Dieser Ansatz ist nicht nur einfach zu implementieren, sondern auch hardwareeffizient: Monarch-Faktoren mit blockierter Diagonale können mit moderner Hardware, die GEMM (Generalized Matrix Multiplication Algorithm) unterstützt, effizient berechnet werden.
M2 verwendet eine Monarch-Matrix, um Informationen entlang der Sequenz- und Modelldimensionsachsen zu vermischen. Dieser Ansatz ist nicht nur einfach zu implementieren, sondern auch hardwareeffizient: Monarch-Faktoren mit blockierter Diagonale können mit moderner Hardware, die GEMM (Generalized Matrix Multiplication Algorithm) unterstützt, effizient berechnet werden.
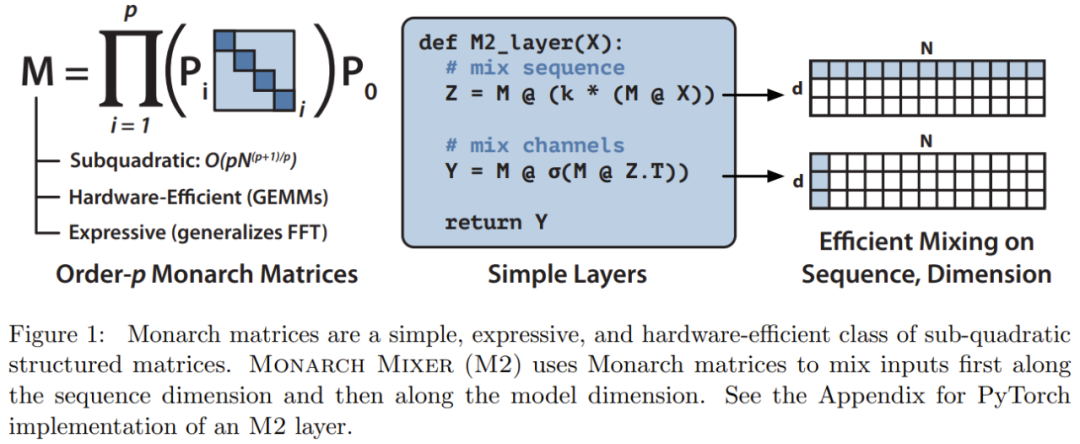
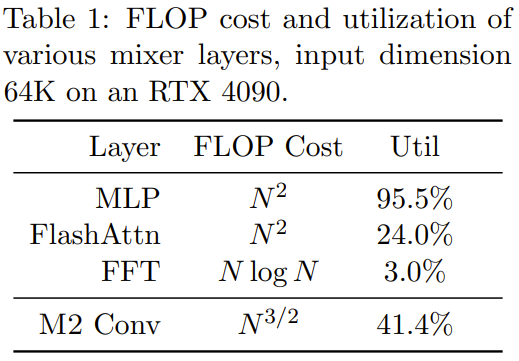
Das Forschungsteam implementierte eine M2-Schicht in weniger als 40 Zeilen, indem es Code mit PyTorch schrieb, und verließ sich dabei nur auf Matrixmultiplikation, Transponierung, Umformung und elementweises Produkt (siehe Pseudo in der Mitte des Codes in Abbildung 1). Bei einer Eingabegröße von 64 KB erreichen diese Codes eine FLOP-Auslastung von 25,6 % auf einer A100-GPU. Auf neueren Architekturen wie RTX 4090 kann eine einfache CUDA-Implementierung bei gleicher Eingabegröße eine FLOP-Auslastung von 41,4 % erreichen .
 Experiment
Experiment
Das Forschungsteam verglich die beiden Modelle Monarch Mixer und Transformer und untersuchte hauptsächlich die Situation, in der Transformer drei Hauptaufgaben dominiert. Die drei Aufgaben sind: Nicht-kausale Maskensprachmodellierungsaufgabe im BERT-Stil, Bildklassifizierungsaufgabe im ViT-Stil und kausale Sprachmodellierungsaufgabe im GPT-Stil
Der Bedarf an nicht-kausaler Sprachmodellierung muss neu geschrieben werden muss neu geschrieben werden Um Aufgaben zu schreiben, hat das Team eine Architektur basierend auf M2 erstellt: M2-BERT. M2-BERT kann Sprachmodelle im BERT-Stil direkt ersetzen, und BERT ist eine Hauptanwendung der Transformer-Architektur. Für das Training von M2-BERT wird die maskierte Sprachmodellierung auf C4 verwendet, und der Tokenizer ist Bert-Base-uncased.
M2-BERT basiert auf dem Transformer-Backbone, aber die M2-Schicht ersetzt die Aufmerksamkeitsschicht und MLP, wie in Abbildung 3 dargestellt.
Im Sequenzmischer wird die Aufmerksamkeit mit restlichem bidirektionalem Gating gefaltet stattdessen eine Faltung (siehe linke Seite von Abbildung 3). Um die Faltung wiederherzustellen, stellte das Team die Monarch-Matrix auf eine DFT- und eine inverse DFT-Matrix ein. Sie fügten nach dem Projektionsschritt auch Tiefenfaltungen hinzu.
Im Dimensionsmischer werden die beiden dichten Matrizen des MLP durch die erlernten Blockdiagonalmatrizen ersetzt (die Ordnung der Monarch-Matrix ist 1, b=4)
Die Forscher führten ein Vortraining durch Insgesamt wurden 4 M2-BERT-Modelle erhalten: Zwei davon sind M2-BERT-Basismodelle mit den Größen 80M bzw. 110M und die anderen beiden sind M2-BERT-Großmodelle mit den Größen 260M bzw. 341M. Diese Modelle entsprechen BERT-Basis bzw. BERT-Groß. Tabelle 3 zeigt die Leistung des Modells, das BERT-Basis entspricht, und Tabelle 4 zeigt die Leistung des Modells, das BERT-Groß entspricht. 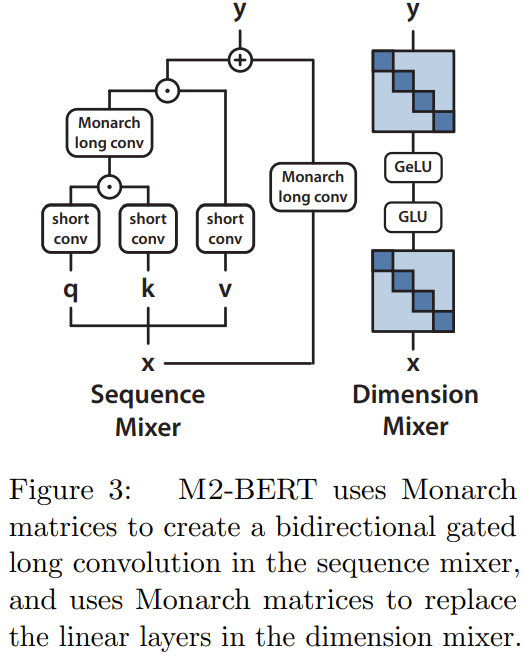
Wie aus der Tabelle ersichtlich ist, ist die Leistung von M2-BERT-Base mit der von BERT-Base vergleichbar, weist jedoch 27 % weniger Parameter auf, wenn die Anzahl der Parameter zwischen den beiden liegt gleich ist, übertrifft M2 -BERT-Basis die BERT-Basis um 1,3 Punkte. In ähnlicher Weise schneidet M2-BERT-large, das 24 % weniger Parameter hat, genauso gut ab wie BERT-large, während M2-BERT-large bei der gleichen Anzahl von Parametern einen Vorteil von 0,7 Punkten hat.
Tabelle 5 zeigt den Vorwärtsdurchsatz von Modellen, die mit dem BERT-Basismodell vergleichbar sind. Was gemeldet wird, ist die Anzahl der pro Millisekunde auf der A100-40GB-GPU verarbeiteten Token, die die Inferenzzeit widerspiegeln kann hochoptimiertes BERT-Modell; im Vergleich zur Standard-HuggingFace-Implementierung auf 4k-Sequenzlänge kann der Durchsatz der M2-BERT-Basis das 9,1-fache erreichen!
Tabelle 6 gibt die CPU-Inferenzzeiten für M2-BERT-Basis (80M) und BERT-Basis an – diese Ergebnisse werden durch die direkte Ausführung dieser beiden Modelle mit der PyTorch-Implementierung erhalten
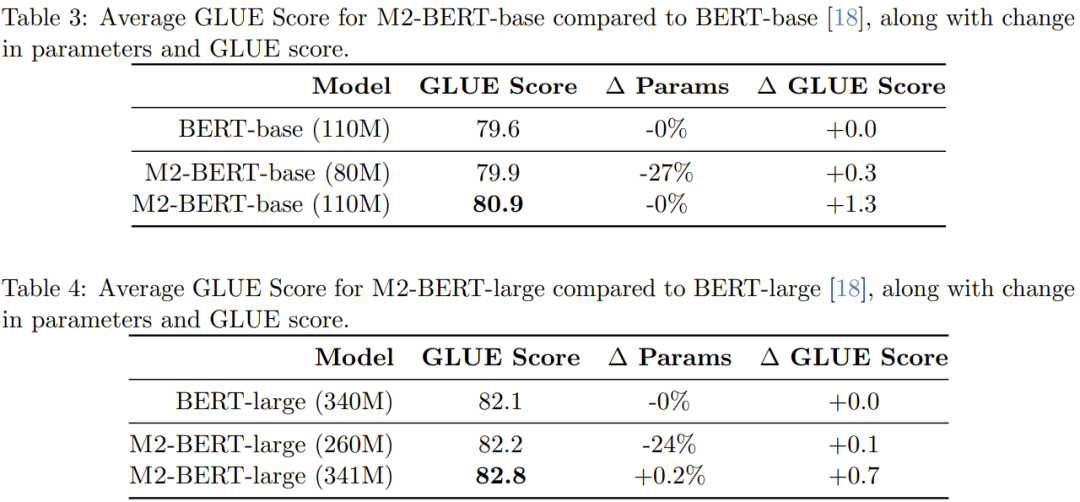
Wenn die Sequenz kurz ist, dominiert immer noch der Einfluss der Datenlokalität die FLOP-Reduzierung, und Vorgänge wie die Filtergenerierung (in BERT nicht verfügbar) sind kostspieliger. Wenn die Sequenzlänge 1 KB überschreitet, erhöht sich der Beschleunigungsvorteil der M2-BERT-Basis allmählich. Wenn die Sequenzlänge 8 KB erreicht, kann der Geschwindigkeitsvorteil das 6,5-fache erreichen. Bildklassifizierung Um zu überprüfen, ob die Vorteile der neuen Methode in der Bilddomäne dieselben sind wie in der Sprachdomäne, bewertete das Team auch die Leistung von M2 bei Bildklassifizierungsaufgaben, die darauf basieren zur nicht-kausalen Konstruktion. Tabelle 7 zeigt die Leistung von Monarch Mixer, ViT-b, HyenaViT-b und ViT-b-Monarch (Ersetzen des MLP-Moduls in Standard-ViT-b durch eine Monarch-Matrix) auf der ImageNet-1k-Leistung.
Der Vorteil von Monarch Mixer liegt auf der Hand: Es benötigt nur die Hälfte der Parameter, um das ursprüngliche ViT-b-Modell zu übertreffen. Überraschenderweise ist Monarch Mixer mit weniger Parametern sogar in der Lage, ResNet-152 zu übertreffen, das speziell für die ImageNet-Aufgabe entwickelt wurde . Das Team entwickelte eine M2-basierte Architektur für die kausale Sprachmodellierung namens M2-GPT Für den Sequenzmischer kombiniert M2-GPT Faltungsfilter von Hyena, die aktuellen hochmodernen aufmerksamkeitsfreien Sprachmodelle und Parameter von H3 werden von allen Longs gemeinsam genutzt. Sie ersetzten die FFT in diesen Architekturen durch kausale Parametrisierung und entfernten die MLP-Schicht vollständig. Die resultierende Architektur ist völlig frei von Aufmerksamkeit und MLP. Sie haben M2-GPT auf PILE vortrainiert, einem Standarddatensatz für die kausale Sprachmodellierung. Die Ergebnisse sind in Tabelle 8 dargestellt. Es ist ersichtlich, dass das auf der neuen Architektur basierende Modell zwar überhaupt keine Aufmerksamkeit und MLP aufweist, aber dennoch Transformer und Hyena im vorab trainierten Ratlosigkeitsindex übertrifft. Diese Ergebnisse legen nahe, dass Modelle, die sich stark von Transformer unterscheiden, möglicherweise auch eine hervorragende Leistung bei der kausalen Sprachmodellierung erzielen. Detailliertere Inhalte finden Sie im Originalpapier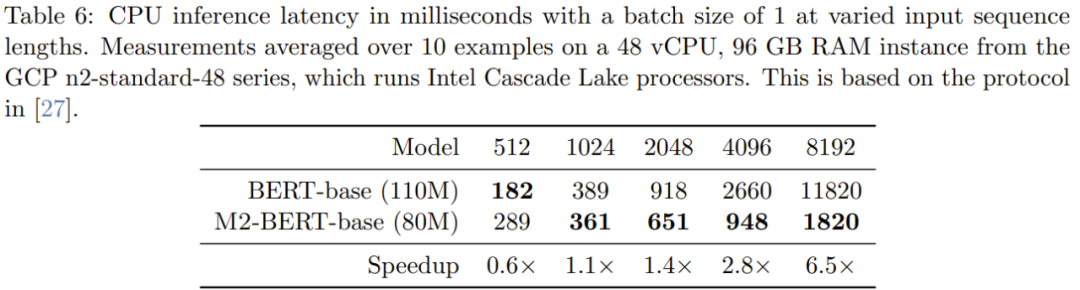
Das obige ist der detaillierte Inhalt vonBesser als Transformer, BERT und GPT ohne Aufmerksamkeit und MLPs sind tatsächlich stärker.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



