
 Technologie-Peripheriegeräte
KI
NVIDIA eröffnet eine neue Ära: die „Perpetuum Mobile' für Robotertrainingsdaten
Technologie-Peripheriegeräte
KI
NVIDIA eröffnet eine neue Ära: die „Perpetuum Mobile' für Robotertrainingsdaten
NVIDIA eröffnet eine neue Ära: die „Perpetuum Mobile' für Robotertrainingsdaten

Die meisten der bisherigen synthetischen Daten wurden für das Training großer KI-Modelle verwendet. Diesmal hat NVIDIA einen „Datenspeicher“ für das Robotertraining aufgebaut. Einer der Hauptgründe, warum das Entwicklungstempo der Robotertechnologie weit hinter anderen KI-Bereichen zurückbleibt Mangel an Daten. Mit nur 200 menschlichen Demonstrationsquelldaten kann das System direkt 50.000 Trainingsdaten generieren.
Angesichts des enormen Datenbedarfs von KI sind die Datenressourcen fast erschöpft. Daher haben verschiedene Unternehmen begonnen, einen „neuen Weg“ zur Datenbeschaffung zu erkunden – indem sie ihre eigenen Daten „erstellen“. Allerdings wurden die meisten der bisherigen synthetischen Daten für das Training großer KI-Modelle verwendet. Dieses Mal hat NVIDIA einen „Datenspeicher“ für das Robotertraining erstellt.
Ein aktuelles Forschungspapier von NVIDIA und der University of Texas in Austin stellt ein System namens „MimicGen“ vor, das mit nur wenigen menschlichen Demonstrationen automatisch umfangreiche Robotertrainingsdatensätze generieren kann. Jim Fan, leitender Wissenschaftler bei Nvidia, sagte, das Unternehmen werde alles Open Source anbieten, einschließlich der generierten Datensätze.
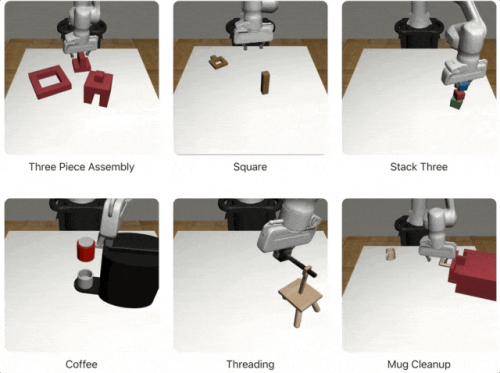
Wie groß sind die generierten Daten? Mit 10 menschlichen Demos kann MimicGen 1.000 synthetische Beispiele generieren, mit 200 menschlichen Demos kann MimicGen direkt 50.000 Trainingsdaten generieren, die 18 Aufgaben und mehrere Simulationsumgebungen umfassen.
Wie ist der generierte Datensatz?MimicGen kann dieselbe Szene basierend auf vorhandenen Daten in verschiedenen Stadien „entwickeln“:

Darüber hinaus gibt es auch Aufgabendaten, die ein langfristiges Training erfordern:


. Darüber hinaus verglichen die Forscher auch die Daten von 10 menschlichen Demonstrationen und 200 menschlichen Demonstrationen, und die Ergebnisse unterschieden sich auch nicht wesentlich. Daher räumt das Papier auch ein, dass weitere Untersuchungen darüber erforderlich sind, ob mehr menschliche Demonstrationsdaten zu Redundanz und unnötigen Kosten für die Datenannotation führen.
Warum sind Sie so besessen von synthetischen Daten? Zusätzlich zu den am Anfang des Artikels erwähnten begrenzten Quelldatenressourcen ist das Sammeln von Daten auch extrem teuer und zeitaufwändig. Mit Systemen wie MimicGen können
automatisch große umfangreiche Datensätze mit nur einer kleinen Datenmenge generiert werden. und diese Daten Es integriert mehrere Szenen, Objektfähigkeiten und Roboterarme und kann auch für Langzeit- oder Hochpräzisionsaufgaben verwendet werden. Man kann es als „leistungsstarke und wirtschaftliche Möglichkeit zur Erweiterung des Roboterlernens“ bezeichnen.„Synthetische Daten werden die nächste Welle von Terascale-Daten für unsere ‚hungrigen‘ Modelle liefern.
“ Der leitende NVIDIA-Wissenschaftler Jim Fan sagte bei der Einführung von MimicGen: „Die Entwicklung der Robotiktechnologie liegt weit hinter der anderer KI zurück. Einer der Hauptgründe auf diesem Gebiet.“ ist der Mangel an Daten – man kann keine Steuersignale (von Robotern) aus dem Internet bekommen“ „Uns gehen die hochwertigen realen Daten aus dem Internet schnell aus, und aus synthetischen Daten hervorgegangene KI wird die zukünftige Entwicklungsrichtung sein .“
Quelle: Science and Technology Innovation Board DailyDas obige ist der detaillierte Inhalt vonNVIDIA eröffnet eine neue Ära: die „Perpetuum Mobile' für Robotertrainingsdaten. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 Der Ameca der zweiten Generation ist da! Er kann fließend mit dem Publikum kommunizieren, sein Gesichtsausdruck ist realistischer und er kann Dutzende Sprachen sprechen.
Mar 04, 2024 am 09:10 AM
Der Ameca der zweiten Generation ist da! Er kann fließend mit dem Publikum kommunizieren, sein Gesichtsausdruck ist realistischer und er kann Dutzende Sprachen sprechen.
Mar 04, 2024 am 09:10 AM
Der humanoide Roboter Ameca wurde auf die zweite Generation aufgerüstet! Kürzlich erschien auf der World Mobile Communications Conference MWC2024 erneut der weltweit fortschrittlichste Roboter Ameca. Rund um den Veranstaltungsort lockte Ameca zahlreiche Zuschauer an. Mit dem Segen von GPT-4 kann Ameca in Echtzeit auf verschiedene Probleme reagieren. „Lass uns tanzen.“ Auf die Frage, ob sie Gefühle habe, antwortete Ameca mit einer Reihe von Gesichtsausdrücken, die sehr lebensecht aussahen. Erst vor wenigen Tagen stellte EngineeredArts, das britische Robotikunternehmen hinter Ameca, die neuesten Entwicklungsergebnisse des Teams vor. Im Video verfügt der Roboter Ameca über visuelle Fähigkeiten und kann den gesamten Raum und bestimmte Objekte sehen und beschreiben. Das Erstaunlichste ist, dass sie es auch kann
 Der erste Roboter erscheint, der menschliche Aufgaben autonom erledigt, mit fünf flexiblen Fingern und übermenschlicher Geschwindigkeit, und große Modelle unterstützen das Training im virtuellen Raum
Mar 11, 2024 pm 12:10 PM
Der erste Roboter erscheint, der menschliche Aufgaben autonom erledigt, mit fünf flexiblen Fingern und übermenschlicher Geschwindigkeit, und große Modelle unterstützen das Training im virtuellen Raum
Mar 11, 2024 pm 12:10 PM
Diese Woche gab FigureAI, ein Robotikunternehmen, an dem OpenAI, Microsoft, Bezos und Nvidia beteiligt sind, bekannt, dass es fast 700 Millionen US-Dollar an Finanzmitteln erhalten hat und plant, im nächsten Jahr einen humanoiden Roboter zu entwickeln, der selbstständig gehen kann. Und Teslas Optimus Prime hat immer wieder gute Nachrichten erhalten. Niemand zweifelt daran, dass dieses Jahr das Jahr sein wird, in dem humanoide Roboter explodieren. SanctuaryAI, ein in Kanada ansässiges Robotikunternehmen, hat kürzlich einen neuen humanoiden Roboter auf den Markt gebracht: Phoenix. Beamte behaupten, dass es viele Aufgaben autonom und mit der gleichen Geschwindigkeit wie Menschen erledigen kann. Pheonix, der weltweit erste Roboter, der Aufgaben autonom in menschlicher Geschwindigkeit erledigen kann, kann jedes Objekt sanft greifen, bewegen und elegant auf der linken und rechten Seite platzieren. Es kann Objekte autonom identifizieren
 Wie kann KI Roboter autonomer und anpassungsfähiger machen?
Jun 03, 2024 pm 07:18 PM
Wie kann KI Roboter autonomer und anpassungsfähiger machen?
Jun 03, 2024 pm 07:18 PM
Im Bereich der industriellen Automatisierungstechnik gibt es zwei aktuelle Hotspots, die kaum zu ignorieren sind: Künstliche Intelligenz (KI) und Nvidia. Ändern Sie nicht die Bedeutung des ursprünglichen Inhalts, optimieren Sie den Inhalt, schreiben Sie den Inhalt neu, fahren Sie nicht fort: „Darüber hinaus sind beide eng miteinander verbunden, da Nvidia nicht auf seine ursprüngliche Grafikverarbeitungseinheit (GPU) beschränkt ist ) erweitert es seine GPU. Die Technologie erstreckt sich auf den Bereich der digitalen Zwillinge und ist eng mit neuen KI-Technologien verbunden. „Vor kurzem hat NVIDIA eine Zusammenarbeit mit vielen Industrieunternehmen geschlossen, darunter führende Industrieautomatisierungsunternehmen wie Aveva, Rockwell Automation und Siemens und Schneider Electric sowie Teradyne Robotics und seine Unternehmen MiR und Universal Robots. Kürzlich hat Nvidia gesammelt
 Nach 2 Monaten kann der humanoide Roboter Walker S Kleidung falten
Apr 03, 2024 am 08:01 AM
Nach 2 Monaten kann der humanoide Roboter Walker S Kleidung falten
Apr 03, 2024 am 08:01 AM
Herausgeber des Machine Power Report: Wu Xin Die heimische Version des humanoiden Roboters + eines großen Modellteams hat zum ersten Mal die Betriebsaufgabe komplexer flexibler Materialien wie das Falten von Kleidung abgeschlossen. Mit der Enthüllung von Figure01, das das multimodale große Modell von OpenAI integriert, haben die damit verbundenen Fortschritte inländischer Kollegen Aufmerksamkeit erregt. Erst gestern veröffentlichte UBTECH, Chinas „größter Bestand an humanoiden Robotern“, die erste Demo des humanoiden Roboters WalkerS, der tief in das große Modell von Baidu Wenxin integriert ist und einige interessante neue Funktionen aufweist. Jetzt sieht WalkerS, gesegnet mit Baidu Wenxins großen Modellfähigkeiten, so aus. Wie Figure01 bewegt sich WalkerS nicht umher, sondern steht hinter einem Schreibtisch, um eine Reihe von Aufgaben zu erledigen. Es kann menschlichen Befehlen folgen und Kleidung falten
 Zehn humanoide Roboter gestalten die Zukunft
Mar 22, 2024 pm 08:51 PM
Zehn humanoide Roboter gestalten die Zukunft
Mar 22, 2024 pm 08:51 PM
Die folgenden 10 humanoiden Roboter prägen unsere Zukunft: 1. ASIMO: ASIMO wurde von Honda entwickelt und ist einer der bekanntesten humanoiden Roboter. Mit einer Höhe von 1,20 m und einem Gewicht von 50 kg ist ASIMO mit fortschrittlichen Sensoren und künstlichen Intelligenzfunktionen ausgestattet, die es ihm ermöglichen, sich in komplexen Umgebungen zurechtzufinden und mit Menschen zu interagieren. Aufgrund seiner Vielseitigkeit eignet sich ASIMO für eine Vielzahl von Aufgaben, von der Unterstützung von Menschen mit Behinderungen bis hin zur Durchführung von Präsentationen bei Veranstaltungen. 2. Pepper: Pepper wurde von Softbank Robotics entwickelt und möchte ein sozialer Begleiter für Menschen sein. Mit seinem ausdrucksstarken Gesicht und der Fähigkeit, Emotionen zu erkennen, kann Pepper an Gesprächen teilnehmen, im Einzelhandel helfen und sogar pädagogische Unterstützung leisten. Pfeffer
 Der Kehr- und Wischroboter Cloud Whale Xiaoyao 001 hat ein „Gehirn'! |. Erfahrung
Apr 26, 2024 pm 04:22 PM
Der Kehr- und Wischroboter Cloud Whale Xiaoyao 001 hat ein „Gehirn'! |. Erfahrung
Apr 26, 2024 pm 04:22 PM
Kehr- und Wischroboter gehören in den letzten Jahren zu den beliebtesten Smart-Home-Geräten bei Verbrauchern. Die damit verbundene Bequemlichkeit der Bedienung oder sogar die Notwendigkeit einer Bedienung ermöglicht es faulen Menschen, ihre Hände frei zu haben, was es den Verbrauchern ermöglicht, sich von der täglichen Hausarbeit zu „befreien“ und mehr Zeit mit den Dingen zu verbringen, die sie in getarnter Form genießen. Aufgrund dieser Begeisterung stellen fast alle Haushaltsgerätemarken auf dem Markt ihre eigenen Kehr- und Wischroboter her, was den gesamten Markt für Kehr- und Wischroboter sehr lebendig macht. Allerdings wird die schnelle Expansion des Marktes unweigerlich eine versteckte Gefahr mit sich bringen: Viele Hersteller werden die Taktik des Maschinenmeeres nutzen, um schnell mehr Marktanteile zu erobern, was zu vielen neuen Produkten ohne Upgrade-Punkte führen wird Es handelt sich um „Matroschka“-Modelle. Keine Übertreibung. Allerdings sind das nicht alle Kehr- und Wischroboter
 Der humanoide Roboter kann zaubern. Lassen Sie das Programmteam der Frühlingsfest-Gala mehr erfahren
Feb 04, 2024 am 09:03 AM
Der humanoide Roboter kann zaubern. Lassen Sie das Programmteam der Frühlingsfest-Gala mehr erfahren
Feb 04, 2024 am 09:03 AM
Roboter haben im Handumdrehen gelernt, zu zaubern? Es war zu sehen, dass es zuerst den Wasserlöffel auf dem Tisch aufhob und damit dem Publikum bewies, dass nichts darin war ... Dann nahm es den eiähnlichen Gegenstand in seine Hand und stellte den Wasserlöffel zurück auf den Tisch und begann „einen Zauber zu wirken“... …Gerade als es den Wasserlöffel wieder aufhob, geschah ein Wunder. Das ursprünglich hineingelegte Ei verschwand und das Ding, das heraussprang, verwandelte sich in einen Basketball ... Schauen wir uns noch einmal die fortlaufenden Aktionen an: △ Diese Animation zeigt eine Reihe von Aktionen mit doppelter Geschwindigkeit und läuft nur durch Zuschauen reibungslos ab Das Video kann wiederholt mit 0,5-facher Geschwindigkeit verstanden werden. Schließlich habe ich die Hinweise entdeckt: Wenn meine Handgeschwindigkeit schneller wäre, könnte ich es möglicherweise vor dem Feind verbergen. Einige Internetnutzer beklagten, dass die magischen Fähigkeiten des Roboters sogar noch höher seien als ihre eigenen: Mag war derjenige, der diese Magie für uns ausgeführt hat.
 Amerikanische Universität eröffnet „The Legend of Zelda: Tears of the Kingdom'-Ingenieurwettbewerb für Studenten zum Bau von Robotern
Nov 23, 2023 pm 08:45 PM
Amerikanische Universität eröffnet „The Legend of Zelda: Tears of the Kingdom'-Ingenieurwettbewerb für Studenten zum Bau von Robotern
Nov 23, 2023 pm 08:45 PM
„The Legend of Zelda: Tears of the Kingdom“ wurde zum am schnellsten verkauften Nintendo-Spiel der Geschichte. Zonav Technology brachte nicht nur verschiedene „Zelda Creator“-Community-Inhalte mit, sondern wurde auch zum neuen Ingenieurstudiengang der Vereinigten Staaten von Maryland (UMD). Rewrite: The Legend of Zelda: Tears of the Kingdom ist eines der am schnellsten verkauften Spiele von Nintendo aller Zeiten. Zonav Technology bietet nicht nur umfangreiche Community-Inhalte, sondern ist auch Teil des neuen Ingenieurstudiengangs an der University of Maryland. In diesem Herbst eröffnete Associate Professor Ryan D. Sochol von der University of Maryland einen Kurs mit dem Titel „.
