
 Technologie-Peripheriegeräte
KI
GPT4 bringt einem Roboter bei, einen Stift zu drehen, was als seidenweiche Glätte bezeichnet wird!
Technologie-Peripheriegeräte
KI
GPT4 bringt einem Roboter bei, einen Stift zu drehen, was als seidenweiche Glätte bezeichnet wird!
GPT4 bringt einem Roboter bei, einen Stift zu drehen, was als seidenweiche Glätte bezeichnet wird!

Kürzlich hat GPT-4, das den Mathematiker Terence Tao inspiriert hat, damit begonnen, Robotern beizubringen, wie man in Chats Stifte dreht

Das Projekt heißt Agent Eureka und wurde von NVIDIA, der University of Pennsylvania und dem California Institute of Technology entwickelt Technology und der University of Texas at Austin Gemeinsam von den Zweigschulen entwickelt. Ihre Forschung kombiniert die Leistungsfähigkeit der GPT-4-Struktur mit den Vorteilen des verstärkenden Lernens und ermöglicht es Eureka, exquisite Belohnungsfunktionen zu entwerfen.
Die Programmierfunktionen von GPT-4 verleihen Eureka leistungsstarke Fähigkeiten beim Design von Belohnungsfunktionen. Das bedeutet, dass die Belohnungssysteme von Eureka bei den meisten Aufgaben sogar besser sind als die der menschlichen Experten. Dies ermöglicht es ihm, einige Aufgaben zu erledigen, die für Menschen schwierig zu erledigen sind, darunter das Drehen von Stiften, das Öffnen von Schubladen, das Anrichten von Walnüssen und noch komplexere Aufgaben, wie das Werfen und Fangen eines Balls, das Bedienen einer Schere usw.
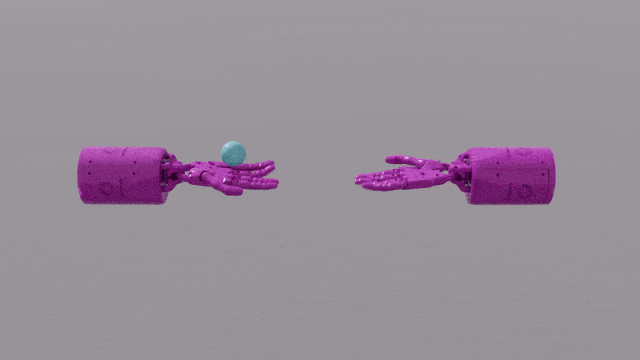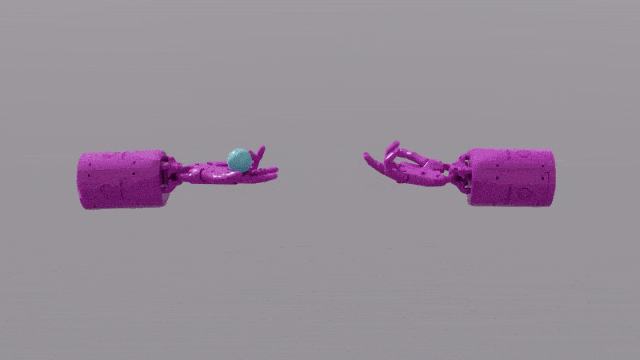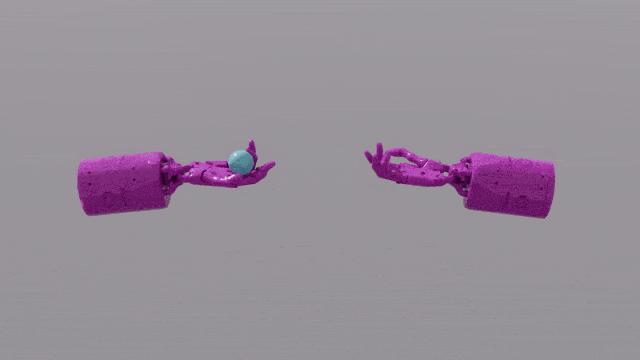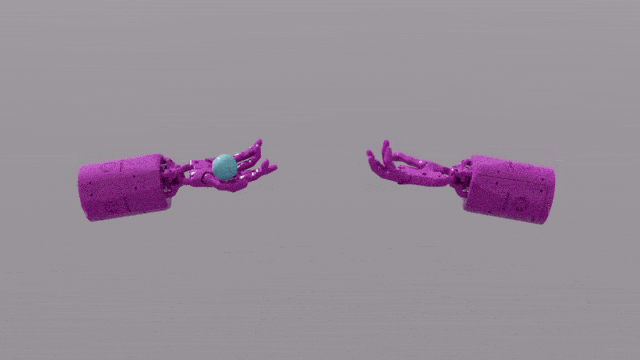 Bilder
Bilder
 Bilder
Bilder
Obwohl diese derzeit in einer simulierten Umgebung erstellt werden, ist dies bereits sehr leistungsstark.
Das Projekt ist Open Source und die Projektadresse und die Papieradresse wurden am Ende des Artikels platziert.
Eine kurze Zusammenfassung der Kernpunkte des Papiers.
In dem Artikel wird untersucht, wie große Sprachmodelle (LLM) verwendet werden können, um Belohnungsfunktionen beim maschinellen Lernen zu entwerfen und zu optimieren. Dies ist ein wichtiges Thema, da der Entwurf einer guten Belohnungsfunktion die Leistung von Modellen für maschinelles Lernen erheblich verbessern kann, der Entwurf einer solchen Funktion jedoch sehr schwierig ist.
Forscher haben einen neuen Algorithmus namens EUREKA vorgeschlagen. EUREKA übernimmt LLM, um Belohnungsfunktionen zu generieren und zu verbessern. Beim Testen erreichte EUREKA in 29 verschiedenen Lernumgebungen zur Verstärkung eine Leistung auf menschlichem Niveau und übertraf bei 83 % der Aufgaben die von menschlichen Experten entwickelten Belohnungsfunktionen B. die Simulation der Bedienung der „Schattenhand“, um einen Stift schnell zu drehen
Darüber hinaus bietet EUREKA eine brandneue Methode, die eine effektivere Belohnungsfunktion generieren kann, die auf der Grundlage menschlicher Rückmeldungen besser den menschlichen Erwartungen entspricht
EUREKA funktioniert in drei Hauptschritten:
Umgebung als Kontext: EUREKA verwendet den Quellcode der Umgebung als Kontext, um ausführbare Belohnungsfunktionen zu generieren
2. Evolutionäre Suche: EUREKA schlägt kontinuierlich durch evolutionäre Suche vor und verbessert die Belohnungsfunktion
3 : EUREKA generiert textliche Zusammenfassungen der Belohnungsqualität auf Basis von Statistiken aus der Politikschulung und verbessert so automatisch und gezielt die Belohnungsfunktion. 3. Belohnungsreflexion: EUREKA generiert textliche Zusammenfassungen der Belohnungsqualität auf der Grundlage von Statistiken aus Richtlinienschulungen, um Belohnungsfunktionen automatisch und gezielt zu verbessern Es wird eine Methode zur automatischen Generierung und Verbesserung von Belohnungsfunktionen bereitgestellt, und die Leistung dieser Methode übertrifft in vielen Fällen die Leistung menschlicher Experten.
Projektadresse:
https://www.php.cn/link/e6b738eca0e6792ba8a9cbcba6c1881dPapierlink:https://www.php.cn/link/ce128c3e8f0c0ae4b3e843dc7cbab0f7
Das obige ist der detaillierte Inhalt vonGPT4 bringt einem Roboter bei, einen Stift zu drehen, was als seidenweiche Glätte bezeichnet wird!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 CLIP-BEVFormer: Überwacht explizit die BEVFormer-Struktur, um die Leistung der Long-Tail-Erkennung zu verbessern
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer: Überwacht explizit die BEVFormer-Struktur, um die Leistung der Long-Tail-Erkennung zu verbessern
Mar 26, 2024 pm 12:41 PM
Oben geschrieben und das persönliche Verständnis des Autors: Derzeit spielt das Wahrnehmungsmodul im gesamten autonomen Fahrsystem eine entscheidende Rolle Das Steuermodul im autonomen Fahrsystem trifft zeitnahe und korrekte Urteile und Verhaltensentscheidungen. Derzeit sind Autos mit autonomen Fahrfunktionen in der Regel mit einer Vielzahl von Dateninformationssensoren ausgestattet, darunter Rundumsichtkamerasensoren, Lidar-Sensoren und Millimeterwellenradarsensoren, um Informationen in verschiedenen Modalitäten zu sammeln und so genaue Wahrnehmungsaufgaben zu erfüllen. Der auf reinem Sehen basierende BEV-Wahrnehmungsalgorithmus wird von der Industrie aufgrund seiner geringen Hardwarekosten und einfachen Bereitstellung bevorzugt, und seine Ausgabeergebnisse können problemlos auf verschiedene nachgelagerte Aufgaben angewendet werden.
 Der Ameca der zweiten Generation ist da! Er kann fließend mit dem Publikum kommunizieren, sein Gesichtsausdruck ist realistischer und er kann Dutzende Sprachen sprechen.
Mar 04, 2024 am 09:10 AM
Der Ameca der zweiten Generation ist da! Er kann fließend mit dem Publikum kommunizieren, sein Gesichtsausdruck ist realistischer und er kann Dutzende Sprachen sprechen.
Mar 04, 2024 am 09:10 AM
Der humanoide Roboter Ameca wurde auf die zweite Generation aufgerüstet! Kürzlich erschien auf der World Mobile Communications Conference MWC2024 erneut der weltweit fortschrittlichste Roboter Ameca. Rund um den Veranstaltungsort lockte Ameca zahlreiche Zuschauer an. Mit dem Segen von GPT-4 kann Ameca in Echtzeit auf verschiedene Probleme reagieren. „Lass uns tanzen.“ Auf die Frage, ob sie Gefühle habe, antwortete Ameca mit einer Reihe von Gesichtsausdrücken, die sehr lebensecht aussahen. Erst vor wenigen Tagen stellte EngineeredArts, das britische Robotikunternehmen hinter Ameca, die neuesten Entwicklungsergebnisse des Teams vor. Im Video verfügt der Roboter Ameca über visuelle Fähigkeiten und kann den gesamten Raum und bestimmte Objekte sehen und beschreiben. Das Erstaunlichste ist, dass sie es auch kann
 Implementierung von Algorithmen für maschinelles Lernen in C++: Häufige Herausforderungen und Lösungen
Jun 03, 2024 pm 01:25 PM
Implementierung von Algorithmen für maschinelles Lernen in C++: Häufige Herausforderungen und Lösungen
Jun 03, 2024 pm 01:25 PM
Zu den häufigsten Herausforderungen, mit denen Algorithmen für maschinelles Lernen in C++ konfrontiert sind, gehören Speicherverwaltung, Multithreading, Leistungsoptimierung und Wartbarkeit. Zu den Lösungen gehören die Verwendung intelligenter Zeiger, moderner Threading-Bibliotheken, SIMD-Anweisungen und Bibliotheken von Drittanbietern sowie die Einhaltung von Codierungsstilrichtlinien und die Verwendung von Automatisierungstools. Praktische Fälle zeigen, wie man die Eigen-Bibliothek nutzt, um lineare Regressionsalgorithmen zu implementieren, den Speicher effektiv zu verwalten und leistungsstarke Matrixoperationen zu nutzen.
 Der erste Roboter erscheint, der menschliche Aufgaben autonom erledigt, mit fünf flexiblen Fingern und übermenschlicher Geschwindigkeit, und große Modelle unterstützen das Training im virtuellen Raum
Mar 11, 2024 pm 12:10 PM
Der erste Roboter erscheint, der menschliche Aufgaben autonom erledigt, mit fünf flexiblen Fingern und übermenschlicher Geschwindigkeit, und große Modelle unterstützen das Training im virtuellen Raum
Mar 11, 2024 pm 12:10 PM
Diese Woche gab FigureAI, ein Robotikunternehmen, an dem OpenAI, Microsoft, Bezos und Nvidia beteiligt sind, bekannt, dass es fast 700 Millionen US-Dollar an Finanzmitteln erhalten hat und plant, im nächsten Jahr einen humanoiden Roboter zu entwickeln, der selbstständig gehen kann. Und Teslas Optimus Prime hat immer wieder gute Nachrichten erhalten. Niemand zweifelt daran, dass dieses Jahr das Jahr sein wird, in dem humanoide Roboter explodieren. SanctuaryAI, ein in Kanada ansässiges Robotikunternehmen, hat kürzlich einen neuen humanoiden Roboter auf den Markt gebracht: Phoenix. Beamte behaupten, dass es viele Aufgaben autonom und mit der gleichen Geschwindigkeit wie Menschen erledigen kann. Pheonix, der weltweit erste Roboter, der Aufgaben autonom in menschlicher Geschwindigkeit erledigen kann, kann jedes Objekt sanft greifen, bewegen und elegant auf der linken und rechten Seite platzieren. Es kann Objekte autonom identifizieren
 Wie kann KI Roboter autonomer und anpassungsfähiger machen?
Jun 03, 2024 pm 07:18 PM
Wie kann KI Roboter autonomer und anpassungsfähiger machen?
Jun 03, 2024 pm 07:18 PM
Im Bereich der industriellen Automatisierungstechnik gibt es zwei aktuelle Hotspots, die kaum zu ignorieren sind: Künstliche Intelligenz (KI) und Nvidia. Ändern Sie nicht die Bedeutung des ursprünglichen Inhalts, optimieren Sie den Inhalt, schreiben Sie den Inhalt neu, fahren Sie nicht fort: „Darüber hinaus sind beide eng miteinander verbunden, da Nvidia nicht auf seine ursprüngliche Grafikverarbeitungseinheit (GPU) beschränkt ist ) erweitert es seine GPU. Die Technologie erstreckt sich auf den Bereich der digitalen Zwillinge und ist eng mit neuen KI-Technologien verbunden. „Vor kurzem hat NVIDIA eine Zusammenarbeit mit vielen Industrieunternehmen geschlossen, darunter führende Industrieautomatisierungsunternehmen wie Aveva, Rockwell Automation und Siemens und Schneider Electric sowie Teradyne Robotics und seine Unternehmen MiR und Universal Robots. Kürzlich hat Nvidia gesammelt
 Nach 2 Monaten kann der humanoide Roboter Walker S Kleidung falten
Apr 03, 2024 am 08:01 AM
Nach 2 Monaten kann der humanoide Roboter Walker S Kleidung falten
Apr 03, 2024 am 08:01 AM
Herausgeber des Machine Power Report: Wu Xin Die heimische Version des humanoiden Roboters + eines großen Modellteams hat zum ersten Mal die Betriebsaufgabe komplexer flexibler Materialien wie das Falten von Kleidung abgeschlossen. Mit der Enthüllung von Figure01, das das multimodale große Modell von OpenAI integriert, haben die damit verbundenen Fortschritte inländischer Kollegen Aufmerksamkeit erregt. Erst gestern veröffentlichte UBTECH, Chinas „größter Bestand an humanoiden Robotern“, die erste Demo des humanoiden Roboters WalkerS, der tief in das große Modell von Baidu Wenxin integriert ist und einige interessante neue Funktionen aufweist. Jetzt sieht WalkerS, gesegnet mit Baidu Wenxins großen Modellfähigkeiten, so aus. Wie Figure01 bewegt sich WalkerS nicht umher, sondern steht hinter einem Schreibtisch, um eine Reihe von Aufgaben zu erledigen. Es kann menschlichen Befehlen folgen und Kleidung falten
 Entdecken Sie die zugrunde liegenden Prinzipien und die Algorithmusauswahl der C++-Sortierfunktion
Apr 02, 2024 pm 05:36 PM
Entdecken Sie die zugrunde liegenden Prinzipien und die Algorithmusauswahl der C++-Sortierfunktion
Apr 02, 2024 pm 05:36 PM
Die unterste Ebene der C++-Sortierfunktion verwendet die Zusammenführungssortierung, ihre Komplexität beträgt O(nlogn) und bietet verschiedene Auswahlmöglichkeiten für Sortieralgorithmen, einschließlich schneller Sortierung, Heap-Sortierung und stabiler Sortierung.
 Kann künstliche Intelligenz Kriminalität vorhersagen? Entdecken Sie die Möglichkeiten von CrimeGPT
Mar 22, 2024 pm 10:10 PM
Kann künstliche Intelligenz Kriminalität vorhersagen? Entdecken Sie die Möglichkeiten von CrimeGPT
Mar 22, 2024 pm 10:10 PM
Die Konvergenz von künstlicher Intelligenz (KI) und Strafverfolgung eröffnet neue Möglichkeiten zur Kriminalprävention und -aufdeckung. Die Vorhersagefähigkeiten künstlicher Intelligenz werden häufig in Systemen wie CrimeGPT (Crime Prediction Technology) genutzt, um kriminelle Aktivitäten vorherzusagen. Dieser Artikel untersucht das Potenzial künstlicher Intelligenz bei der Kriminalitätsvorhersage, ihre aktuellen Anwendungen, die Herausforderungen, denen sie gegenübersteht, und die möglichen ethischen Auswirkungen der Technologie. Künstliche Intelligenz und Kriminalitätsvorhersage: Die Grundlagen CrimeGPT verwendet Algorithmen des maschinellen Lernens, um große Datensätze zu analysieren und Muster zu identifizieren, die vorhersagen können, wo und wann Straftaten wahrscheinlich passieren. Zu diesen Datensätzen gehören historische Kriminalstatistiken, demografische Informationen, Wirtschaftsindikatoren, Wettermuster und mehr. Durch die Identifizierung von Trends, die menschliche Analysten möglicherweise übersehen, kann künstliche Intelligenz Strafverfolgungsbehörden stärken
