
 Technologie-Peripheriegeräte
KI
Microsoft führt die Modelltrainingsmethode „Learn from Mistakes' ein und behauptet, „den menschlichen Lernprozess nachzuahmen und die Denkfähigkeiten der KI zu verbessern'.
Technologie-Peripheriegeräte
KI
Microsoft führt die Modelltrainingsmethode „Learn from Mistakes' ein und behauptet, „den menschlichen Lernprozess nachzuahmen und die Denkfähigkeiten der KI zu verbessern'.
Microsoft führt die Modelltrainingsmethode „Learn from Mistakes' ein und behauptet, „den menschlichen Lernprozess nachzuahmen und die Denkfähigkeiten der KI zu verbessern'.

Microsoft Research Asia hat kürzlich in Zusammenarbeit mit der Peking-Universität, der Xi'an Jiaotong-Universität und anderen Universitäten eine Trainingsmethode für künstliche Intelligenz namens „Learning from Mistakes (LeMA)“ vorgeschlagen. Diese Methode behauptet, die Denkfähigkeit künstlicher Intelligenz verbessern zu können, indem sie den menschlichen Lernprozess nachahmt. Derzeit werden große Sprachmodelle wie OpenAI GPT-4 und Google aLM-2 für Aufgaben der Verarbeitung natürlicher Sprache (NLP) und des Denkens verwendet Ketten (Chain-of-Thinking (CoT)) Mathematische Denkaufgaben haben eine gute Leistung.
Allerdings müssen große Open-Source-Modelle wie LLaMA-2 und Baichuan-2 bei der Behandlung verwandter Probleme gestärkt werden. Um die Denkketten-Argumentationsfähigkeiten dieser großen Open-Source-Sprachmodelle zu verbessern, schlug das Forschungsteam die LeMA-Methode vor. Diese Methode imitiert hauptsächlich den menschlichen Lernprozess und verbessert die Denkfähigkeit des Modells durch „Lernen aus Fehlern“ .
.
▲ Bildquelle Verwandte Artikel
Diese Website stellte fest, dassdie Methode der Forscher darin besteht, ein Datenpaar mit „falschen Antworten“ und „korrigierten richtigen Antworten“ zu verwenden, um das relevante Modell zu verfeinern 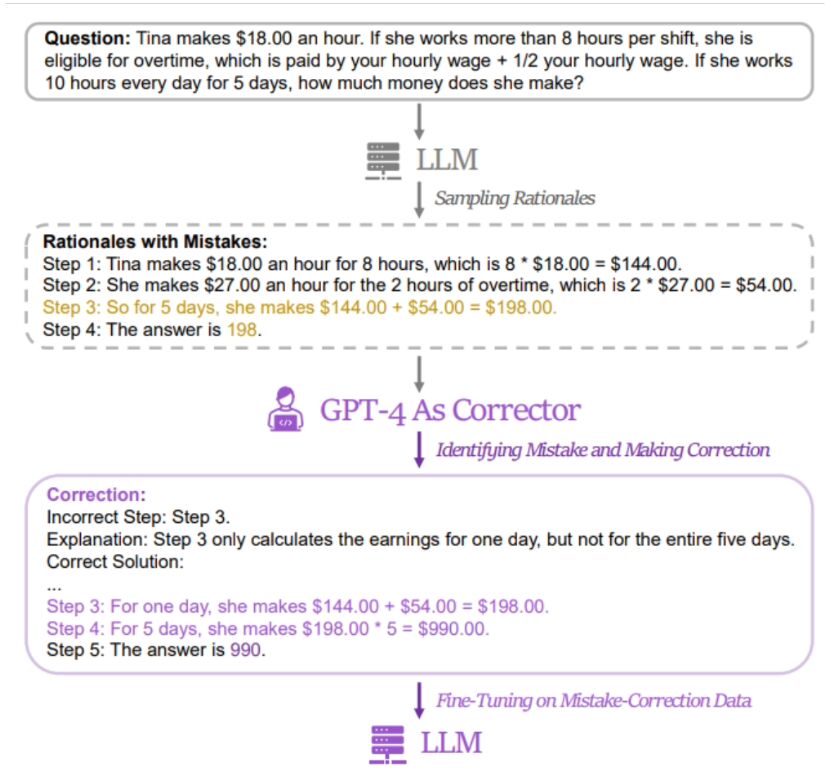 . Um relevante Daten zu erhalten, sammelten die Forscher die falschen Antworten und Argumentationsprozesse von fünf verschiedenen großen Sprachmodellen (einschließlich LLaMA- und GPT-Reihen) und verwendeten dann GPT-4 als „Revisor“, um korrigierte Antworten bereitzustellen.
. Um relevante Daten zu erhalten, sammelten die Forscher die falschen Antworten und Argumentationsprozesse von fünf verschiedenen großen Sprachmodellen (einschließlich LLaMA- und GPT-Reihen) und verwendeten dann GPT-4 als „Revisor“, um korrigierte Antworten bereitzustellen.
Es wird berichtet, dass die überarbeitete richtige Antwort drei Arten von Informationen enthält, nämlich die fehlerhaften Fragmente im ursprünglichen Argumentationsprozess, die Gründe für die Fehler im ursprünglichen Argumentationsprozess und wie die ursprüngliche Methode geändert werden kann, um die richtige Antwort zu erhalten.
Forscher verwendeten GSM8K und MATH, um die Wirkung der LeMa-Trainingsmethode an 5 großen Open-Source-Modellen zu testen. Die Ergebnisse zeigen, dass im verbesserten LLaMA-2-70B-Modell die Genauigkeitsraten von GSM8K 83,5 % bzw. 81,4 % betragen, während die Genauigkeitsraten von MATH 25,0 % bzw. 23,6 % betragen. Derzeit haben Forscher relevante Informationen darüber gesammelt LeMA Es ist öffentlich auf GitHub. Interessierte Freunde können
hier klicken, um zu springen.
Das obige ist der detaillierte Inhalt vonMicrosoft führt die Modelltrainingsmethode „Learn from Mistakes' ein und behauptet, „den menschlichen Lernprozess nachzuahmen und die Denkfähigkeiten der KI zu verbessern'.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 Schritt-für-Schritt-Anleitung zur lokalen Verwendung von Groq Llama 3 70B
Jun 10, 2024 am 09:16 AM
Schritt-für-Schritt-Anleitung zur lokalen Verwendung von Groq Llama 3 70B
Jun 10, 2024 am 09:16 AM
Übersetzer |. Bugatti Review |. Chonglou Dieser Artikel beschreibt, wie man die GroqLPU-Inferenz-Engine verwendet, um ultraschnelle Antworten in JanAI und VSCode zu generieren. Alle arbeiten daran, bessere große Sprachmodelle (LLMs) zu entwickeln, beispielsweise Groq, der sich auf die Infrastrukturseite der KI konzentriert. Die schnelle Reaktion dieser großen Modelle ist der Schlüssel, um sicherzustellen, dass diese großen Modelle schneller reagieren. In diesem Tutorial wird die GroqLPU-Parsing-Engine vorgestellt und erläutert, wie Sie mithilfe der API und JanAI lokal auf Ihrem Laptop darauf zugreifen können. In diesem Artikel wird es auch in VSCode integriert, um uns dabei zu helfen, Code zu generieren, Code umzugestalten, Dokumentation einzugeben und Testeinheiten zu generieren. In diesem Artikel erstellen wir kostenlos unseren eigenen Programmierassistenten für künstliche Intelligenz. Einführung in die GroqLPU-Inferenz-Engine Groq
 Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Stellen Sie sich ein Modell der künstlichen Intelligenz vor, das nicht nur die Fähigkeit besitzt, die traditionelle Datenverarbeitung zu übertreffen, sondern auch eine effizientere Leistung zu geringeren Kosten erzielt. Dies ist keine Science-Fiction, DeepSeek-V2[1], das weltweit leistungsstärkste Open-Source-MoE-Modell, ist da. DeepSeek-V2 ist ein leistungsstarkes MoE-Sprachmodell (Mix of Experts) mit den Merkmalen eines wirtschaftlichen Trainings und einer effizienten Inferenz. Es besteht aus 236B Parametern, von denen 21B zur Aktivierung jedes Markers verwendet werden. Im Vergleich zu DeepSeek67B bietet DeepSeek-V2 eine stärkere Leistung, spart gleichzeitig 42,5 % der Trainingskosten, reduziert den KV-Cache um 93,3 % und erhöht den maximalen Generierungsdurchsatz auf das 5,76-fache. DeepSeek ist ein Unternehmen, das sich mit allgemeiner künstlicher Intelligenz beschäftigt
 Sieben coole technische Interviewfragen für GenAI und LLM
Jun 07, 2024 am 10:06 AM
Sieben coole technische Interviewfragen für GenAI und LLM
Jun 07, 2024 am 10:06 AM
Um mehr über AIGC zu erfahren, besuchen Sie bitte: 51CTOAI.x Community https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou unterscheidet sich von der traditionellen Fragendatenbank, die überall im Internet zu sehen ist erfordert einen Blick über den Tellerrand hinaus. Large Language Models (LLMs) gewinnen in den Bereichen Datenwissenschaft, generative künstliche Intelligenz (GenAI) und künstliche Intelligenz zunehmend an Bedeutung. Diese komplexen Algorithmen verbessern die menschlichen Fähigkeiten, treiben Effizienz und Innovation in vielen Branchen voran und werden zum Schlüssel für Unternehmen, um wettbewerbsfähig zu bleiben. LLM hat ein breites Anwendungsspektrum und kann in Bereichen wie der Verarbeitung natürlicher Sprache, der Textgenerierung, der Spracherkennung und Empfehlungssystemen eingesetzt werden. Durch das Lernen aus großen Datenmengen ist LLM in der Lage, Text zu generieren
 Große Modelle sind auch bei der Vorhersage von Zeitreihen sehr leistungsstark! Das chinesische Team aktiviert neue LLM-Funktionen und erreicht SOTA über traditionelle Modelle hinaus
Apr 11, 2024 am 09:43 AM
Große Modelle sind auch bei der Vorhersage von Zeitreihen sehr leistungsstark! Das chinesische Team aktiviert neue LLM-Funktionen und erreicht SOTA über traditionelle Modelle hinaus
Apr 11, 2024 am 09:43 AM
Das Potenzial großer Sprachmodelle wird gefördert – eine hochpräzise Zeitreihenvorhersage kann ohne Training großer Sprachmodelle erreicht werden und übertrifft alle herkömmlichen Zeitreihenmodelle. Die Monash University, Ant und IBM Research haben gemeinsam ein allgemeines Framework entwickelt, das die Fähigkeit großer Sprachmodelle, Sequenzdaten über Modalitäten hinweg zu verarbeiten, erfolgreich förderte. Das Framework ist zu einer wichtigen technologischen Innovation geworden. Die Vorhersage von Zeitreihen ist für die Entscheidungsfindung in typischen komplexen Systemen wie Städten, Energie, Transport und Fernerkundung von Vorteil. Seitdem wird erwartet, dass große Modelle das Zeitreihen-/spatiotemporale Data-Mining revolutionieren werden. Das allgemeine Forschungsteam zum Reprogrammieren von Frameworks für große Sprachmodelle schlug ein allgemeines Framework vor, mit dem große Sprachmodelle einfach und ohne Schulung für die allgemeine Zeitreihenvorhersage verwendet werden können. Es werden hauptsächlich zwei Schlüsseltechnologien vorgeschlagen: Neuprogrammierung der Zeiteingabe; Zeit-
 Der Ameca der zweiten Generation ist da! Er kann fließend mit dem Publikum kommunizieren, sein Gesichtsausdruck ist realistischer und er kann Dutzende Sprachen sprechen.
Mar 04, 2024 am 09:10 AM
Der Ameca der zweiten Generation ist da! Er kann fließend mit dem Publikum kommunizieren, sein Gesichtsausdruck ist realistischer und er kann Dutzende Sprachen sprechen.
Mar 04, 2024 am 09:10 AM
Der humanoide Roboter Ameca wurde auf die zweite Generation aufgerüstet! Kürzlich erschien auf der World Mobile Communications Conference MWC2024 erneut der weltweit fortschrittlichste Roboter Ameca. Rund um den Veranstaltungsort lockte Ameca zahlreiche Zuschauer an. Mit dem Segen von GPT-4 kann Ameca in Echtzeit auf verschiedene Probleme reagieren. „Lass uns tanzen.“ Auf die Frage, ob sie Gefühle habe, antwortete Ameca mit einer Reihe von Gesichtsausdrücken, die sehr lebensecht aussahen. Erst vor wenigen Tagen stellte EngineeredArts, das britische Robotikunternehmen hinter Ameca, die neuesten Entwicklungsergebnisse des Teams vor. Im Video verfügt der Roboter Ameca über visuelle Fähigkeiten und kann den gesamten Raum und bestimmte Objekte sehen und beschreiben. Das Erstaunlichste ist, dass sie es auch kann
 Nach 750.000 Runden Einzelkampf zwischen großen Modellen gewann GPT-4 die Meisterschaft und Llama 3 belegte den fünften Platz
Apr 23, 2024 pm 03:28 PM
Nach 750.000 Runden Einzelkampf zwischen großen Modellen gewann GPT-4 die Meisterschaft und Llama 3 belegte den fünften Platz
Apr 23, 2024 pm 03:28 PM
Zu Llama3 wurden neue Testergebnisse veröffentlicht – die große Modellbewertungs-Community LMSYS veröffentlichte eine große Modell-Rangliste, die Llama3 auf dem fünften Platz belegte und mit GPT-4 den ersten Platz in der englischen Kategorie belegte. Das Bild unterscheidet sich von anderen Benchmarks. Diese Liste basiert auf Einzelkämpfen zwischen Modellen, und die Bewerter aus dem gesamten Netzwerk machen ihre eigenen Vorschläge und Bewertungen. Am Ende belegte Llama3 den fünften Platz auf der Liste, gefolgt von drei verschiedenen Versionen von GPT-4 und Claude3 Super Cup Opus. In der englischen Einzelliste überholte Llama3 Claude und punktgleich mit GPT-4. Über dieses Ergebnis war Metas Chefwissenschaftler LeCun sehr erfreut und leitete den Tweet weiter
 Das leistungsstärkste Modell der Welt wechselte über Nacht den Besitzer und markierte damit das Ende der GPT-4-Ära! Claude 3 hat GPT-5 im Voraus durchgelesen und einen Aufsatz mit 10.000 Wörtern in 3 Sekunden gelesen. Sein Verständnis kommt dem des Menschen nahe.
Mar 06, 2024 pm 12:58 PM
Das leistungsstärkste Modell der Welt wechselte über Nacht den Besitzer und markierte damit das Ende der GPT-4-Ära! Claude 3 hat GPT-5 im Voraus durchgelesen und einen Aufsatz mit 10.000 Wörtern in 3 Sekunden gelesen. Sein Verständnis kommt dem des Menschen nahe.
Mar 06, 2024 pm 12:58 PM
Die Lautstärke ist verrückt, die Lautstärke ist verrückt und das große Modell hat sich wieder verändert. Gerade eben wechselte das leistungsstärkste KI-Modell der Welt über Nacht den Besitzer und GPT-4 wurde vom Altar genommen. Anthropic hat die neueste Claude3-Modellreihe veröffentlicht. Eine Satzbewertung: Sie zerschmettert GPT-4 wirklich! In Bezug auf multimodale Indikatoren und Sprachfähigkeitsindikatoren gewinnt Claude3. In den Worten von Anthropic haben die Modelle der Claude3-Serie neue Branchenmaßstäbe in den Bereichen Argumentation, Mathematik, Codierung, Mehrsprachenverständnis und Vision gesetzt! Anthropic ist ein Startup-Unternehmen, das von Mitarbeitern gegründet wurde, die aufgrund unterschiedlicher Sicherheitskonzepte von OpenAI „abgelaufen“ sind. Ihre Produkte haben OpenAI immer wieder hart getroffen. Dieses Mal musste sich Claude3 sogar einer großen Operation unterziehen.
 Stellen Sie große Sprachmodelle lokal in OpenHarmony bereit
Jun 07, 2024 am 10:02 AM
Stellen Sie große Sprachmodelle lokal in OpenHarmony bereit
Jun 07, 2024 am 10:02 AM
In diesem Artikel werden die Ergebnisse von „Local Deployment of Large Language Models in OpenHarmony“ auf der 2. OpenHarmony-Technologiekonferenz demonstriert. Open-Source-Adresse: https://gitee.com/openharmony-sig/tpc_c_cplusplus/blob/master/thirdparty/. InferLLM/docs/hap_integrate.md. Die Implementierungsideen und -schritte bestehen darin, das leichtgewichtige LLM-Modellinferenz-Framework InferLLM auf das OpenHarmony-Standardsystem zu übertragen und ein Binärprodukt zu kompilieren, das auf OpenHarmony ausgeführt werden kann. InferLLM ist ein einfaches und effizientes L
